PrivLogit: Efficient Privacy-preserving Logistic Regression by Tailoring Numerical Optimizers
Safeguarding privacy in machine learning is highly desirable, especially in collaborative studies across many organizations. Privacy-preserving distributed machine learning (based on cryptography) is popular to solve the problem. However, existing cr…
Authors: Wei Xie, Yang Wang, Steven M. Boker
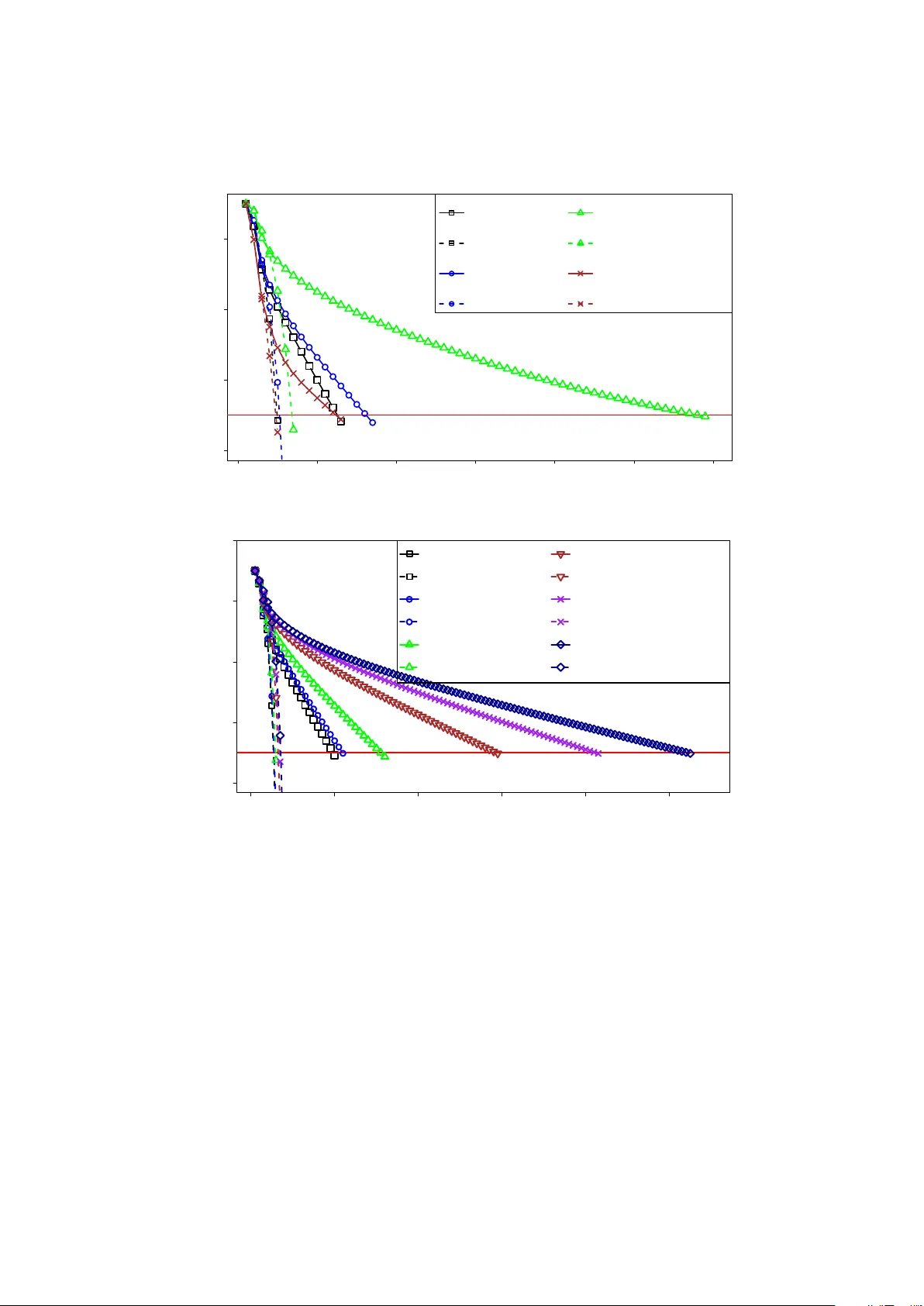
Pri vLogit: Ef ficient Pri v ac y-preserving Logistic Regression by T ailoring Numerical Optimizers W ei Xie V anderbilt Univ ersity Nashville, TN wei.xie@vanderbilt.edu Y ang W ang Uni versity of V irginia Charlottesville, V A yw3xs@virginia.edu Ste ven M. Boker Uni versity of V irginia Charlottesville, V A boker@virginia.edu Donald E. Bro wn Uni versity of V irginia Charlottesville, V A deb@virginia.edu Abstract Safeguarding priv acy in machine learning is highly desirable, especially in collaborati ve studies across many or ganizations. Priv acy-preserving distrib uted machine learning (based on cryptography) is popular to solve the problem. Howe ver , existing cryptographic protocols still incur excess compu- tational overhead. Here, we make a novel observation that this is partially due to naiv e adoption of mainstream numerical optimization (e.g., Ne wton method) and failing to tailor for secure computing. This work presents a contrasting perspecti ve: customizing numerical optimization specifically for secure settings. W e propose a seemingly less-fa vorable optimization method that can in f act significantly accel- erate priv acy-preserving logistic regression. Lev eraging this new method, we propose two ne w secure protocols for conducting logistic regression in a priv acy-preserving and distributed manner . Extensive theoretical and empirical ev aluations prove the competiti ve performance of our two secure proposals while without compromising accuracy or priv acy: with speedup up to 2.3x and 8.1x, respectively , over state-of-the-art; and even faster as data scales up. Such drastic speedup is on top of and in addition to performance improvements from existing (and future) state-of-the-art cryptography . Our work provides a new way to wards efficient and practical pri vac y-preserving logistic regression for large-scale studies which are common for modern science. 1 Intr oduction Data integration and joint analytics (i.e., machine learning) in a distributed network of independent databases (belonging to different or ganizations) is widely used in various disciplines, such as in data management [ Zhang and Zhao , 2005 , V erykios et al. , 2004 , Aggarwal and Philip , 2008 ], biomedical and social sciences [ McCarty et al. , 2011 , Zheng et al. , 2017 ] where data are distributed in nature and single databases only hav e limited samples sizes. The goal of such multi-organization joint analytics is to accumulate lar ge sample sizes across databases/organizations and reach more po werful machine learning conclusions. Such practice of joint analytics across distributed multi-organization databases, ho wev er , is often ham- pered by serious priv acy issues as these studies typically in volv e human subject data (e.g., electronic medical records, human genome) that are sensitiv e and strictly protected by v arious priv acy laws and regulations [ Of- fice for Civil Rights , 2002 , Hudson et al. , 2008 , Daries et al. , 2014 ]. Meanwhile, many participating orga- 1 nizations are also reluctant to rev eal their data content to external entities (due to concerns around priv acy and business secrets), e ven though they still want to contrib ute to collaborative studies. This is increasingly common in many disciplines concerning data management, such as healthcare and biomedicine [ Li et al. , 2015 , W u et al. , 2012b ], business, finance, etc. More formally , we are interested in the following common scenario (traditionally known as privacy- pr eserving distributed data mining in data management and machine learning [ V erykios et al. , 2004 , Zhang and Zhao , 2005 , Aggarwal and Philip , 2008 ]): multiple independent organizations (e.g., dif ferent institu- tions, medical centers) want to conduct joint analytics (such as logistic regression). They each possess their respecti ve private data of a sub-population (e.g., electronic medical records, human genomes, or psychology surve ys), but are not willing or permitted to disclose the data beyond their respectiv e organizations due to pri vac y and proprietary reasons. W e focus on the horizontally partitioned setting [ Aggarwal and Philip , 2008 ], where each independent database contains only a sub-population (i.e., some rows). In such a collab- orati ve study across distributed databases, potential adv ersaries include: distrustful aggregation center (e.g., due to breached servers or malicious employees), distrustful member org anizations (due to curiosity about other organizations’ secrets or business competition), and external curious people or hackers. The adver- sary’ s goal is to learn priv acy-sensitiv e information of indi vidual data records or organizations by peeking into raw and summary-lev el data. The challenge here is on how to support such a collaborative study while preserving priv acy , especially when it is difficult or economically impractical to find a fully entrusted central authority to directly aggregate (“union”) all databases. Pri vac y-preserving distributed data mining le veraging cryptography (secure multi-party computation in particular) and distributed computing is a classical and revi ving solution for tackling the challenge [ Aggar- wal and Philip , 2008 ]. Numerous efforts hav e attempted to support data mining in distributed databases without disclosing raw and intermediate data [ Aggarwal and Philip , 2008 , Nardi et al. , 2012 , Nikolaenko et al. , 2013 , Xie et al. , 2014 , Bok er et al. , 2015 , Li et al. , 2016 ]. Among these, significant attention is dev oted to logistic regression [ W olfson et al. , 2010 , El Emam et al. , 2013 , Nardi et al. , 2012 , Li et al. , 2016 , Aono et al. , 2016 ], one of the most popular statistical methods. Despite encouraging progress, very few proposals hav e seen wide adoption in real world for priv acy- preserving logistic regression. The main reason is still the excess computational overhead of cryptographic methods, despite recent improvements in cryptography alone (represented and partially summarized by [ Liu et al. , 2015 ]). While it is generally expected for secure computation to be slower than non-secure counterparts, we also make a no vel and surprising observation: much of the computational o verhead indeed traces back to the sub-optimal technical decisions made by humans experts (e.g., authors of cryptographic solutions) and could have been avoided. For instance, nearly all existing secure protocols [ El Emam et al. , 2013 , Li et al. , 2016 ] directly apply mainstream (distributed) model estimation algorithms (e.g., the popular Ne wton method for logistic regression [ Harrell , 2015 ]), failing to account for secure computing-specific characteristics and thus missing valuable opportunities for performance improvement. Our work here is moti vated to le verage our nov el observation and correct for a wide-spr ead suboptimal practice in priv acy- preserving data mining. In this work, we propose a dif ferent approach to making pri vac y-preserving logistic regression much more efficient and practical: Instead of following common practice of taking “off-the-shelf” numerical optimization algorithms (e.g., Newton method) and focusing on accelerating the underlying cryptography alone (pervasi ve among nearly all related secure protocols [ Aggarwal and Philip , 2008 ]), we propose to tailor numerical optimization specially for cryptographic computing in general (but not tied to any specific cryptogr aphic schemes or implementations), which then can be built upon whatever state-of-the-art cryp- togr aphy available now and in future . Our new approach significantly accelerates overall computation in 2 addition to enjoying latest advancement from state-of-the-art cryptography , while guaranteeing priv acy and result accuracy . In our proposed new numerical optimizer (termed PrivLogit), we deriv e a constant approximation for the second-order curvature information (i.e., Hessian) in the Newton method for logistic regression. This adapted optimizer seems counter-intuitiv e and “unf av orable” due to its elongated con vergence and increased network interactions, but surprisingly turns out to be highly competitive in overall performance. Follo wing Pri vLogit, we propose and ev aluate two highly-efficient cryptographic protocols for priv acy-preserving dis- tributed logistic re gression, i.e., PrivLogit-Hessian and Pri vLogit-Local. Extensi ve theoretical and experimental ev aluations show that our method is significantly more ef ficient and practical, make secure data management closer to wards real-world deplo yment. Contributions Our contributions are as follo ws: • W e make a nov el observation about a generic performance bottleneck in priv acy-preserving logistic regression, i.e., directly building on de facto optimization algorithms originally designed for non- cryptogr aphy settings. This interesting observation has long been ne glected by the domain. • Based on abov e observ ation, we propose a counter-intuiti ve but surprisingly much better model es- timation method (i.e., Pri vLogit) for priv acy-preserving logistic regression. This provides a entirely dif ferent perspective for priv acy-preserving distributed logistic regression, by showing that tailoring numerical optimizers for secure computing can lead to significant unexpected performance gains. • W e propose two highly-ef ficient secure protocols (i.e., Pri vLogit-Hessian and Pri vLogit-Local) for pri vac y-preserving logistic regression, which significantly outperforms state-of-the-art alternativ es based on the same latest cryptographic schemes and tools. • W e provide detailed theoretical proof and analysis on our proposals. • W e extensi vely ev aluate our proposals on various simulated and real-world studies of very large scale, many of which are significantly larger than pre viously reported in the literature. As a side result, we also present and ev aluate the first comprehensive secure implementation/protocol of Newton method based on latest cryptography (as our baseline). Outlines W e first provide background on logistic regression and model estimation methods in Section 2 . In Sections 3 and 4 , we describe our improved optimization method PrivLogit, and two secure implementa- tions. In Section 5 , we elaborate on theoretical details regarding model con vergence proof, security analysis, and computational complexity of our proposals. This is followed by experimental results in Section 6 . In Section 7 , we surve y related works. W e discuss and conclude in Section 8 . 2 Pr eliminaries This manuscript roughly follo ws the notations in T able 1 . 2.1 Logistic Regression This work concerns conducting logistic regression in a multi-organization (distributed) environment. Lo- gistic regression is a probabilistic model that is often used for binary (i.e., cate gorical) classification [ Harrell , 3 T able 1: Notations. Notations Remarks X ∈ R n × p Regression co variates: n samples, p features y ∈ R n Regression response v ector: n samples β ∈ R p Regression coef ficients H , ˜ H ∈ R p × p Hessian, approximate Hessian matrices g ∈ R p Gradient λ ∈ R Regression re gularization parameter l 2 ( β ) Log-likelihood (objecti ve) E nc ( data ) Encryption of data ⊕ , , ⊗ , Secure arithmetics for + , − , × , ÷ E sq rt ( data ) Secure square root of data 2015 ]. It is among the most utilized statistical models in practice, with wide adoption in biomedicine [ Lowrie and Le w , 1990 ], genetics [ Lewis and Knight , 2012 ], online advertising [ McMahan et al. , 2013 ], etc. Briefly , the logistic regression is defined as: p ( y = 1 | x ; β ) = 1 1 + e − β T x , (1) where p ( . ) denotes the probability of the binary response variable y equal to 1 (i.e., “case” or “success” in practice), x is the p -dimensional cov ariates for a specific data record, and β is the p -dimensional regression coef ficients we want to estimate. In practice, regularization is often applied to the model estimation process to aid feature selection and pre vent overfitting by penalizing extreme parameters [ Nigam , 1999 ]. Here we consider the popular ` 2 - regularization for logistic regression [ Nigam , 1999 ] to make our work generically applicable. The standard logistic regression can be deri ved by simply setting the regularization to 0. The ` 2 -regularized logistic regression imposes an additional regularization term, − λ 2 β T β , to the optimization objectiv e during model estimation. For a dataset ( X ∈ R n × p , y ∈ R n ) = [( x 1 , y 1 ) , ..., ( x n , y n )] with n independent samples and p features, the log-likelihood (i.e., optimization objecti ve) of ` 2 -regularized logistic re gression is: l 2 ( β ) = n X i =1 [ y i ( β T x i ) − log (1 + e β T x i )] − λ 2 β T β , (2) where λ is the predefined penalty parameter to tune the re gularization. 2.2 Distributed Newton Method When fitting a (regularized) logistic regression, the goal is to estimate the coefficients β from existing training data ( X , y ) . Since logistic regression does not hav e a closed form, model estimation is often accomplished by (iterative) numerical optimization over the objectiv e l 2 ( β ) . The de facto approach for estimating the (regularized) logistic regression coefficient β (Equation 1 ) is the Newton method [ Harrell , 2015 ], which is widely implemented in most statistical software and underlying nearly all e xisting protocols for priv acy-preserving logistic regression (e.g., [ W olfson et al. , 2010 , El Emam et al. , 2013 , Li et al. , 2016 ]). Ne wton method iteratively approaches the optimal coefficients, and for each iteration, the coefficient 4 estimates are updated by: β ( t +1) = β ( t ) − H − 1 ( β ( t ) ) g ( β ( t ) ) , (3) where H ( β ( t ) ) and g ( β ( t ) ) denote the Hessian and gradient of the objectiv e l 2 ( β ) (Equation 2 ) ev aluated at the current β ( t ) coef ficient estimate. The superscripts ( t ) , ( t + 1) denote the t th , ( t + 1) th iterations, respecti vely . This updating process iterates until model con ver gence. Based on Equation 2 , the gradient and Hessian for ` 2 -regularized logistic regression can be computed as follo ws (setting λ = 0 will skip regularization and yield the standard logistic re gression): g ( β ) = ∇ β l 2 ( β ) = X T ( y − p ) − λ β = S X j =1 g j ( β ) − λ β , (4) H ( β ) = d 2 l 2 ( β ) d β d β T = − X T AX − λ I = S X j =1 H j ( β ) − λ I , (5) where X represents cov ariates of n samples and p features; y denotes the response v ector of n data records; p ∈ R n is the vector of logistic regression probabilities for n records; A ∈ R n × n is a diagonal matrix with elements defined as a i,i = p i (1 − p i ) ; and g j ( β ) and H j ( β ) are the per-or ganization gradient and Hessian, respectiv ely , that will be introduced afterwards in the distributed version; S is the total number of organizations contrib uting data to the collaborative study . As is also manifested in the last equalities of Equations 4 and 5 , the computation of both g ( β ) and H ( β ) can be decomposed per participating or ganizations (who can freely access their respecti ve pri vate data such as X j , y j ), and thus need not in voke expensi ve cryptographic computation (except for the final summation across organizations). 3 PrivLogit: a T ailored Optimizer f or F ast Priv acy-preser ving Logistic Re- gr ession Here, we first analyze the problems with mainstream secure Newton method that is underlying nearly all existing solutions for priv acy-preserving logistic regression. This moti vates us to customize a better opti- mization method (Pri vLogit) specially for secure computing (but not tied to any particular cryptographic scheme or implementation). W e later analyze the attractive properties of Pri vLogit, which seem obscure at first sight. 3.1 Limitations of Newton Method. T o estimate regression coefficients via the aforementioned Newton method (Equations 3 ), the ev aluation and in version of the Hessian have to be repeated for ev ery iteration until model con ver gence. These two operations can be prohibitivel y expensiv e in computation and network communication especially when im- plemented using cryptography . For (distributed) Newton method in general (e.g., non-secure applications), it has been well acknowl- edged that the ev aluation and in version of the Hessian matrix are the ov erall computational bottleneck due to large data sizes, inherent complexity and repetiti ve nature of these operations [ Liu and Nocedal , 1989 ]. This in fact has motiv ated numerous improv ed optimizers in machine learning and optimization [ Liu and Nocedal , 1989 ]. Unfortunately , most such newer optimizers do not seem amenable to efficient and data- agnostic secur e implementation and thus are not used by the crypto graphy and privacy community) . 5 In data security and priv acy research, the issue of expensiv e Ne wton method is exacerbated as secure in version of Hessian matrix requires complex operations (e.g., secure di vision and square root) which hav e to resort to e xpensiv e primiti ves and approximations from secure multi-party computation [ Nardi et al. , 2012 , El Emam et al. , 2013 ]. As a result, almost all existing secure logistic regression proposals hav e to compromise pri vac y protection or result accuracy to increase performance (e.g., to selectiv ely re veal intermediate data/computations [ Li et al. , 2016 ] or to use approximations [ Nardi et al. , 2012 , Aono et al. , 2016 ]). 3.2 PrivLogit f or Priv acy-preserving Logistic Regression. W e are moti vated to design a tailored optimizer for secure computing by addressing the aforementioned limitations of Newton method. Our proposal is based on the classical work on quadratic function approxi- mation [ B ¨ ohning and Lindsay , 1988 ] (non-secure applications) and with ne w theoretical analysis. In brief, we propose to use one carefully-chosen constant matrix as a surrog ate for the exact Hessian matrices (Equa- tion 5 ) across all iterations. Specifically , the following approximate Hessian (denoted ˜ H ) is proposed: ˜ H = − 1 4 X T X − λ I , (6) here ˜ H is a tight lo wer bound because for all p i ∈ [0 , 1] (the probability in logistic regression), we hav e that: max { a i,i = p i (1 − p i ) } = 1 4 (where a i,i denotes elements of the diagonal matrix A defined in Equation 5 for Hessian). W e highlight that this appr oximation guar antees e xact model con ver gence and r esult accur acy (with theor etical and empirical pr oof later in Sections 5.1 and 6.2 ). The calculation of approximate Hessian ˜ H can be decomposed per -organization (horizontally parti- tioned) and computed in a distributed manner among man y organizations: ˜ H = − 1 4 S X j =1 X j T X j − λ I = S X j =1 ˜ H j − λ I (7) where X j is the (priv acy-sensiti ve) raw data stored locally at Organization j , S is the total number of orga- nizations contributing data, and ˜ H j = − 1 4 X T j X j denotes the approximate Hessian for Organization j . Substituting this approximate Hessian into the Newton method (Equation 3 ), along with the distrib uted e valuation of gradient (Equation 4 ), the iterativ e updating formula for our new optimizer (denoted as PrivLogit) follo ws: β ( t +1) = β ( t ) − [ S X j =1 ˜ H j − λ I ] − 1 [ S X j =1 g j ( β ( t ) ) − λ β ( t ) ] (8) The above iterativ e process continues until model conv ergence. Con vergence can be measured by the relativ e change of log-likelihood and compared against a predefined threshold (e.g., 10 − 6 ): | l ( t +1) 2 − l ( t ) 2 | | l ( t ) 2 | < 10 − 6 , where l ( t +1) 2 , l ( t ) 2 correspond to the log-likelihood of logistic regression for Iterations ( t +1) , ( t ) , respectiv ely . Note that based on Equation 2 , the log-likelihood can also be decomposed per-org anization j (whose share is denoted l sj ): l 2 ( β ) = S X j =1 l sj − λ 2 β T β (9) 6 3.3 Attractive Pr operties of PrivLogit. Our new PrivLogit numerical optimizer enables a few attracti ve properties, which seem highly promising for ef ficient priv acy-preserving logistic re gression. 3.3.1 Asymmetric Computational Complexity in Secure Settings The PrivLogit adaption comes at the cost of more iterations required for con ver gence (and also increased local-organization computation), which seems counter-intuiti ve and less fa vorable as more iterations mean slo wer con ver gence. Howe ver , this view fails to consider computational cost as a whole and the different computational characteristics of distributed model estimation with and without cryptographic protections. In secure implementations, the local computation at each organization is essentially “free” because organi- zations have full control of their respective priv ate data and (extremely) fast non-secure computations are applicable; b ut secure computation at the aggregation center is usually orders of magnitudes slower than non-secure counterparts (due to expensiv e cryptographic protections against an adversarial center). This implies that eliminating comple xity of center -based secure computation (current bottleneck) can potentially lead to significant speedup (as is the case in Pri vLogit). Our method has very cheap per -iteration cost, making it competiti ve in ov erall performance. 3.3.2 Constant Hessian Our proposed Hessian approximation stays constant and independent of the v arying β ( t ) ’ s coefficients across all iterations. This indicates that it only needs to be e valuated and in verted once during preprocessing and can then be reused across all iterations, leading to dramatic reduction in computation compared with traditional Ne wton method. 3.3.3 Decomposition of Computation The ne w optimizer allows for easy decomposition the computation among participating organizations, which can be leveraged to achie ve significant speedup. For instance, the approximate Hessian can be computed in a distributed manner via a series of aggreg ations, as demonstrated in Equation 7 . So is the gradient (Equation 4 ). In addition, further reduction in computation is possible after the approximate Hessian is securely in- verted and properly protected. As will be introduced later in our second implementation PrivLogit-Local (Section 4.2 ), partial Newton update direction can be computed locally by each local nodes (who has priv acy- free access to their respectiv e pri vate data and thus local gradient need not be encrypted). The center only needs to securely aggregate these local Newton steps, which is highly efficient. This performance impr ove- ment is unique to PrivLogit and not possible for Ne wton method due to varying Hessian’ s. 3.3.4 Guaranteed Model Quality Despite the approximation to Hessian, the PrivLogit optimizer is guaranteed to con ver ge to accurate model estimates, i.e., perfect accuracy (Sections 5.1 and 6.2 ). 7 4 Cryptographic Implementations of PrivLogit Based on our new Pri vLogit optimization method, we propose two cryptographic protocols for priv acy- preserving distributed logistic regression. The first is called PrivLogit-Hessian which is a straightforward cryptographic implementation of PrivLogit. Our second proposal, called Pri vLogit-Local, provides ev en more speedup by offsetting some expensiv e matrix operations to local organizations and taking advantage of their fast and pri vac y-free computing power . 4.0.1 Distributed System Architectur e Both our secure protocols adopt the distributed architecture consisting of local Nodes (org anizations) and an aggregation Center (semi-honest), as illustrated in Figure 1 (common for pri vac y-preserving distributed data mining [ Aggarwal and Philip , 2008 ]). In brief, participating organizations (i.e., distributed Nodes) are responsible for protecting their respective data and only generating (safe) summary-lev el data, which would be encrypted and securely consumed by the Center for model estimation. In a strongly protected system such as ours, all data and computations at the Center are encrypted and not visible even to the Center itself . The role of Center is typically played by two or more mutually independent semi-trusted authorities (denoted as different Servers in Figure 1 ), as is common for secure multi-party computation applications [ Aggarwal and Philip , 2008 , Nikolaenk o et al. , 2013 , Xie et al. , 2014 , Li et al. , 2016 ]. In practice, such as in biomedical or social sciences, Center(s) can be the coordinating center (of a consortium, federation or association) in addition to a third-party authority (e.g., audit organizations). W e acknowledge there can be alternativ e architectures, such as Center with 3-parties [ Kamm and W illemson , 2013 ] or ev en more, or fully decentralized. Ho we ver , since this is not the focus of our work and state-of-the-art are still mostly using two-party (Center) architectures, we thus lea ve it as future work. 4.0.2 Choice of Cryptographic Schemes Our proposals are agnostic of specific choices of cryptographic schemes and most existing or future cryp- tographic schemes/primitiv es can be utilized. This is because, as discussed in Section 3.3 , our performance adv antage comes from lev eraging the drastic computational complexity asymmetry between the untrusted Center (whose computation is or ders of magnitude slower [ Liu et al. , 2015 ] due to cryptography) and dis- tributed Nodes (whose computation is often privacy-fr ee and extr emely fast ). This asymmetry is likely to exist for the for eseeable futur e r e gardless of impr ovements in cryptogr aphy alone. In fact, since PrivLogit has much simpler main computations (Equations 8 and 7 ) than Newton method (Equations 3 and 5 ), our pr oposals ar e mor e widely amenable to a variety of cryptographic schemes. Since the focus of our work is not on specific cryptographic protocols and due to space constraint, we directly adopt state-of-the-art cryp- tographic schemes (building blocks) and skip trivial cryptographic details that are common knowledge in pri vac y-preserving (distributed) data mining [ Aggarwal and Philip , 2008 , Nikolaenko et al. , 2013 , Li et al. , 2016 , Xie et al. , 2014 ]. Our current secure implementation b uilds on a hybrid of two widely-used cryptographic schemes: Y ao’ s garbled circuit [ Y ao , 1982 ] (mainly for T ype 2 computations between independent Center servers as depicted in Figure 1 ) and Paillier encryption [ Paillier , 1999 ] (mainly for T ype 1 computations between local Nodes and the Center as depicted in Figure 1 ). Local-node computations are mostly pri vac y-free. The hybrid of garbled cir cuit and P aillier encryption (and the con version between each other) is very efficient and is state-of-the-art cryptographic pr otocol for various closely r elated tasks, including privacy-pr eserving 8 Figure 1: Distributed architecture for priv acy-preserving logistic regression. T wo main types of computa- tions are in volved between: 1) local Nodes and the Center; 2) different Serv ers/authorities at the Center . logistic re gr ession and other machine learning models [ Aggarwal and Philip , 2008 , El Emam et al. , 2013 , Nikolaenko et al. , 2013 , Xie et al. , 2014 ]. 4.0.3 Secure Notations For simplicity , we use intuitive symbols to denote a fe w common secure mathematical arithmetics. Each of these operations take encrypted operands as inputs, and securely compute without decryption to output an encrypted result. As before, encrypted data are represented as E nc ( . ) . And we denote secure addition, subtraction, multiplication, and division as: ⊕ , , ⊗ , , respecti vely (secure square root E sq rt ( . ) is also used in matrix in version whose details are omitted in main text). Across all secure Algorithms 1 , 2 , and 3 introduced below , we flag computations by their location of oc- curr ence in accordance with the distrib uted architecture in Figure 1 . This also explains what cryptographic schemes are underlying what computations, because as mentioned earlier in Section 4 , Center-based com- putations are primarily implemented using garbled circuit, and local node-computations are priv acy-free, and the information exchange between Center and local Nodes is implemented using P aillier encryption. 9 4.1 PrivLogit-Hessian: Secure Distrib uted PrivLogit As presented in Algorithm 1 , PrivLogit-Hessian is our straightforward secure and distributed implementa- tion of our PrivLogit optimizer . This secure protocol consists of two phases of computation: a one-time setup phase of securely approximating and in verting the Hessian, and a repeated (iterati ve) secure model estimation phase. Algorithm 1 PrivLogit-Hessian: Fast and Secure Logistic Re gression. Input: Random initial β (0) ; Regularization parameter λ Output: Globally fit coefficient estimate β [At local or ganizations and Center] : 1: Securely approximate and Cholesky-decompose (neg ated) Hessian: E nc ( L ) = S etupO nce () (where E nc ( LL T ) = E nc ( − ˜ H ) ) (Algorithm 2 ) 2: while regression model not con ver ged do [At local or ganizations] : 3: f or each organization j = 1 to S do [At local Or ganization j] : 4: Compute local gradient g j and encrypt via Paillier (Equation 4 ) 5: Compute local log-likelihood l sj and encrypt via Paillier (Equation 9 ) 6: Securely transmit encryptions E nc ( g j ) , E nc ( l sj ) to Center 7: end f or [At Center] : 8: Securely aggregate gradients across organizations: E nc ( g ) = E nc ( g 1 ) ⊕ ... ⊕ E nc ( g j ) ⊕ ... ⊕ E nc ( g S ) E nc ( λ β ( t ) ) (Equation 4 ) 9: Secure back-substitution: E nc ( ˜ H − 1 g ) ← E nc ( L ) , E nc ( g ) 10: Securely update coef ficient estimates via PrivLogit: β ( t +1) ← β ( t ) (Equation 8 ) 11: Securely aggre gate log-lik elihood across organizations: E nc ( l 2 ) = E nc ( l s 1 ) ⊕ ... ⊕ E nc ( l sj ) ⊕ ... ⊕ E nc ( l sS ) E nc ( λ 2 [ β ( t ) ] T β ( t ) ) (Equation 9 ) 12: Securely check model con ver gence using secure comparison (Section 3.2 ) 13: Securely disseminate ne w coefficient estimates to each local or ganizations: E nc ( β ( t +1) ) 14: end while 15: return β ( t ) (last con verged estimate) The first phase (Step 1 in Algorithm 1 or SetupOnce() function in Algorithm 2 ) focuses on securely approximating and in verting Hessian. Specifically , based on Algorithm 2 , each local organizations com- pute their local Hessian approximation ˜ H j (based on covariance matrix X T j X j ) and encrypt it before sharing with the Center (Steps 1 to 4 in Algorithm 2 ; our current implementation uses Paillier encryp- tion). The Center securely aggregates these encrypted per-or ganization Hessians (and the regularization term as necessary), yielding an encrypted global Hessian approximation E nc ( ˜ H ) (Step 5 in Algorithm 2 and Equation 7 ; encryption is still based on Paillier). Later, the Center needs to securely in vert the Hes- sian, which is typically achieved by secure Cholesky decomposition on the protected (negated) Hessian and obtains its encrypted “in version” (the encrypted Cholesky triangular matrix E nc ( L ) to be precise), such that E nc ( LL T ) = E nc ( − ˜ H ) . Since Cholesky decomposition is a common textbook algorithm and has been implemented before [ Nikolaenko et al. , 2013 ] using the same cryptography as ours (garbled circuit), 10 Algorithm 2 SetupOnce() for securely approximating and in verting Hessian. Input: Local organizations with their respecti ve data Output: Encrypted triangular matrix E nc ( L ) from Cholesk y decomposition (where E nc ( LL T ) = E nc ( − ˜ H ) ) [At local or ganizations] : 1: for each organization j = 1 to S do 2: Approximate local Hessian ˜ H j (Equation 6 ) 3: Encrypt and securely transmit E nc ( ˜ H j ) to Center 4: end f or [At Center] : 5: Securely aggre gate Hessians across organizations: E nc ( ˜ H ) = E nc ( ˜ H 1 ) ⊕ ... ⊕ E nc ( ˜ H j ) ⊕ ... ⊕ E nc ( ˜ H S ) E nc ( λ I ) (Equation 6 ) 6: Secure Cholesky decomposition to obtain: E nc ( L ) (where E nc ( LL T ) = E nc ( − ˜ H ) ) 7: return encryption E nc ( L ) we omit the details for brevity . Con version between Paillier encryption and garbled circuit follo ws popular approaches [ Nikolaenk o et al. , 2013 , Xie et al. , 2014 ]). Note that the whole phase only needs to occur once, which is a significant impr ovement over Ne wton method-based pr otocols. The second phase (Steps 2 to 14 in Algorithm 1 ) of PrivLogit-Hessian resembles that of the widely-used pri vac y-preserving distributed Ne wton method [ Li et al. , 2016 ], except for the substitution of repeated Hes- sian ev aluation and in version. Model estimation proceeds in a secure and iterative process (each execution within while loop constitutes an iteration, as shown in Algorithm 1 ). Model con ver gence is securely checked at each iteration using secure comparison (Steps 12 or 2 in Algorithm 1 ). F or each iteration, local organiza- tions only need to compute their local gradient g j and log-likelihood l sj (where j index es each or ganization) using priv acy-free computation, and securely transmit their (Paillier) encryptions of these summaries to the Center (Steps 3 to 7). The Center securely aggregates the gradient and log-likelihood submissions (using Paillier -based secure addition), and compose the encrypted global gradient (Step 8) and log-likelihood (Step 11). Later on in Step 9, the textbook method back-substitution (similar to [ Nikolaenko et al. , 2013 ]) is se- curely performed to derive the encrypted product E nc ( ˜ H − 1 g ) from previously deriv ed encryptions E nc ( L ) and E nc ( g ) . The Center then updates current coefficient estimates following the PrivLogit updating formula (Step 10 and Equation 8 ). This iterativ e process continues until model con verges. 4.2 PrivLogit-Local: Decentralizing More Computations. Our second and e ven faster secure protocol, PrivLogit-Local, is presented in Algorithm 3 . This proto- col takes advantage of the fact that the centrally aggregated approximate Hessian ˜ H − 1 (or encryption E nc ( ˜ H − 1 ) ) can be regarded as a (pri vate) constant value. F or each local Node j , local gradient g j is pri vac y-free and essentially a public constant . This means that we can further distribute the expensiv e (Center-based) secure matrix-v ector multiplication (Step 9 in Algorithm 1 of Pri vLogit-Hessian) to local Nodes by le veraging much cheaper secure multiplication-by-constant operations locally: i.e., to locally compute multiplication E nc ( ˜ H − 1 ) ⊗ g j at each Node (which can be centrally aggregated efficiently in secure later) instead of at the Center . In greater detail, the first step of Pri vLogit-Local still in volves the local organizations and Center se- curely approximating and “inv erting” the Hessian (Step 1 in Algorithm 3 ; or SetupOnce() in Algorithm 2 ), 11 Algorithm 3 PrivLogit-Local: offsetting partial Ne wton update step to local organizations. Input: Random initial β (0) ; regularization parameter λ Output: Globally fit coefficient estimate β [At local or ganizations and Center] : 1: Securely approximate and Cholesky-decompose Hessian: E nc ( L ) = S etupO nce () (where E nc ( LL T ) = E nc ( − ˜ H ) ) (Algorithm 2 ) 2: Securely in vert Hessian: E nc ( ˜ H − 1 ) ← E nc ( L ) 3: while regression model not con ver ged do [At local or ganizations] : 4: f or each organization j = 1 to S do [At local Or ganization j] : 5: Compute local log-likelihood l sj and encrypt (Equation 9 ) 6: Compute local gradient g j (Equation 4 ) 7: Secure multiplication-by-constant: E nc ( ˜ H − 1 g j ) ← E nc ( ˜ H − 1 ) , g j ; 8: Securely send encryptions E nc ( ˜ H − 1 g j ) , E nc ( l sj ) to Center 9: end f or [At Center] : 10: Securely compose global numerical updating step: E nc ( ˜ H − 1 g ) = E nc ( ˜ H − 1 g 1 ) ⊕ ... ⊕ E nc ( ˜ H − 1 g j ) ⊕ ... ⊕ E nc ( ˜ H − 1 g S ) E nc ( λ ˜ H − 1 β ( t ) ) 11: Securely update coef ficient estimates via PrivLogit: β ( t +1) ← β ( t ) (Equation 8 ) 12: Securely aggregate log-likelihood across or ganizations: E nc ( l 2 ) = E nc ( l s 1 ) ⊕ E nc ( l s 2 ) ⊕ ... ⊕ E nc ( l sj ) E nc ( λ 2 [ β ( t ) ] T β ( t ) ) (Equation 9 ) 13: Securely check model con vergence using secure comparison (Section 3.2 ) 14: Securely disseminate ne w coefficient estimates to each local or ganiztions: E nc ( β ( t +1) ) 15: end while 16: return β ( t ) (last con verged estimate) similar to Phase 1 of PrivLogit-Hessian. Next, we directly materialize the in version of approximate Hes- sian in encrypted form, i.e., E nc ( ˜ H − 1 ) . After that, this encrypted in version is disseminated to each local organizations where local computation of gradients only in volv es priv acy-free operations. Later on, at each iteration, local organizations deriv e their various local summaries (just as the standard secure Newton method or our PrivLogit-Hessian), such as log-likelihood (Step 5) and gradient (Step 6). In addition, per earlier observ ation, they compute their respectiv e versions of (partial) Newton updating step, by using ef ficient secure multiplication primitiv es (Step 7). Since the local gradients g j do not in volve pri- v acy concerns at their respectiv e local organizations (thus can be regarded as a public constant value), the computation is greatly simplified to highly efficient secure multiplication-by-constant primitiv es in Paillier . Afterwards, local organizations securely send their respecti ve encrypted summaries E nc ( ˜ H − 1 g j ) , E nc ( l sj ) back to the Center (Step 8). For regularized logistic regression, the regularization term also needs to be securely composed, which can be prepared by the local or ganizations and then aggregated centrally , i.e., E nc ( λ ˜ H − 1 β ( t ) ) = E nc ( ˜ H − 1 P S j =1 λ β ( t ) j ) . Finally , the Center only needs to perform trivial secure ag- gregation to complete the PrivLogit model updating process and secure con vergence check (Steps 10 to 13). 12 The correctness of Algorithm 3 is straightforward (i.e., offsetting matrix multiplication to local Nodes). Briefly , ˜ H − 1 g = ˜ H − 1 ( P j g j − λ β ) = P j ˜ H − 1 g j − λ ˜ H − 1 β . Building on top of PrivLogit-Hessian, our second protocol Pri vLogit-Local further av oids expensi ve secure matrix multiplication (between encryptions), which leads to significantly simplified computation and less ov erhead than PrivLogit-Hessian and baseline Ne wton. Due to simplicity of computation equation, this also makes PrivLogit-Local mor e widely amenable to a variety of cryptographic sc hemes. 5 Theor etical Proof and Analysis In this section, we present theoretical analysis and proof for our proposals regarding computational com- plexity , and model con ver gence. 5.1 Proof on Model Con vergence and Result Accuracy Since our PrivLogit introduced approximation to Hessian, the con vergence properties of standard Newton no longer apply . W e thus present theoretical proof regarding the con vergence properties of Pri vLogit, which is based on quadratic function approximation [ B ¨ ohning and Lindsay , 1988 ]. W e show that our PrivLogit optimizer is guaranteed to con verg e to the optimum (i.e., it always con ver ges and con verg es with exact model accuracy), and at a linear con ver gence rate . Specifically , we prove the follo wing proposition: Proposition 1. Assume the optimal solution β ∗ to the objective function l 2 ( β ) (Equation 2 ) exists and is unique. Let { β ( t ) } be a sequence generated by PrivLogit with the update formula in Equation 8 . The sequence has the following pr operties: (a) l 2 ( β ( t +1) ) > l 2 ( β ( t ) ) and β ( t ) will con verge to the optimal solution β ∗ . (b) The rate of con verg ence of PrivLogit method is linear . Pr oof. (a) By using the negati ve definiteness of ˜ H and the second-order T aylor expansion of l 2 ( β ) , we hav e, l 2 ( β ( t +1) ) − l 2 ( β ( t ) ) = − g ( β ( t ) ) | ˜ H − 1 g ( β ( t ) )+ 1 2 g ( β ( t ) ) | ˜ H − 1 H ( ˆ β ) ˜ H − 1 g ( β ( t ) ) > − g ( β ( t ) ) | ˜ H − 1 g ( β ( t ) ) + 1 2 g ( β ( t ) ) | ˜ H − 1 ˜ H ˜ H − 1 g ( β ( t ) ) = − 1 2 g ( β ( t ) ) | ˜ H − 1 g ( β ( t ) ) > 0 where ˆ β is between β ( t ) and β ( t +1) . The objectiv e function l 2 ( β ) is strictly concav e with a neg ativ e definite Hessian matrix and therefore is maximized at the optimal solution β ∗ . From the previous deriv ation, we obtain the lower bound of the increment of the objectiv e function at each iteration. If g ( β ( t ) ) is bounded away from 0 for all t , in other words, || g ( β ( t ) ) || > for some positi ve constant , then the increment of each iteration is also bounded abov e 0, which contradicts the upper boundedness of the objective function. Therefore, g ( β ( t ) ) → 0 as t → ∞ , which means the sequence { β ( t ) } con verges to the optimal solution β ∗ . 13 (b) Since X | X is positiv e semi-definite, its eigenv alues are all non-negati ve. Denote the biggest eigen- v alue of X | X as λ max . Furthermore, we also assume X | AX is positiv e definite at e very iteration, with the smallest eigen value λ min > 0 . Then we hav e − 1 1 4 λ max + λ I ˜ H − 1 and − ( λ min + λ ) I H ( β ) − ( 1 4 λ max + λ ) I Let M = 1 4 λ max + λ and m = λ min + λ . By the strong concavity assumption and the second-order T aylor expansion of l 2 , we hav e for any υ and ω in the parameter space, l 2 ( ω ) < l 2 ( υ ) + g ( υ ) | ( ω − υ ) − 1 2 m || ω − υ || 2 2 < l 2 ( υ ) + || g ( υ ) || 2 2 2 m Since the inequality holds e verywhere in the parameter space, we ha ve || g ( υ ) || 2 2 > 2 m ( l 2 ( β ∗ ) − l 2 ( υ )) for any υ . Next we need to in vestigate the relation between l 2 ( β ∗ ) − l 2 ( β ( t +1) ) and l 2 ( β ∗ ) − l 2 ( β ( t ) ) for all t . From part(a), we hav e l 2 ( β ( t +1) ) > l 2 ( β ( t ) ) − 1 2 g ( β ( t ) ) | ˜ H − 1 g ( β ( t ) ) > l 2 ( β ( t ) ) + 1 2 M || g ( β ( t ) ) || 2 2 Subtracting both sides from l 2 ( β ∗ ) , we get l 2 ( β ∗ ) − l 2 ( β ( t +1) ) < l 2 ( β ∗ ) − l 2 ( β ( t ) ) − 1 2 M || g ( β ( t ) ) || 2 2 < (1 − m M )( l 2 ( β ∗ ) − l 2 ( β ( t ) )) < (1 − m M ) t ( l 2 ( β ∗ ) − l 2 ( β (1) )) where the factor 1 − m M < 1 . It shows that l 2 ( β ( t ) ) con verges in a linear rate to β ∗ as t → ∞ . 5.2 Complexity Analysis Here we roughly analyze the computational complexity of the operations in volv ed. Since cryptographic operations are dominating the total computation of secure protocols (often orders of magnitudes more ex- pensi ve than non-secure computations), we thus focus on cryptography-related procedures only . For gradient g ∈ R p and Hessian H ∈ R p × p , the main operations concerning cryptographic protection are: matrix in version or closely related Cholesky decomposition (Equations 3 and 6 ) ( O ( p 3 ) complexity), matrix-vector multiplication (Equations 3 and 6 ) ( O ( p 2 ) complexity), and back-substitution (Step 9 in Al- gorithm 1 ) ( O ( p 2 ) ). State-of-the-art priv acy-preserving Newton method requires repeated Hessian in version and matrix mul- tiplication, with total complexity of O ( p 3 × Newton iterations ) . 14 Pri vLogit in general requires one step of Hessian in version, and many iterations of matrix-vector mul- tiplication, with total complexity of O ( p 3 + p 2 × PrivLogit iterations ) . Note that specifically for Pri vLogit-Local, the second complexity term in volving p 2 is much lo wer (i.e., much smaller constant f actor in terms of empirical complexity) than PrivLogit-Hessian because secure multiplication-by-constant primi- ti ve (the main computation in volv ed) is much more ef ficient than secure multiplication of two encryptions (as in Pri vLogit-Hessian). Since the strict relationship between p and iteration numbers (of Ne wton and Pri vLogit) is not deter- mined, performance improv ement is not strictly guaranteed for directly applying PrivLogit (as in the case of PrivLogit-Hessian) ov er Newton method. This is a limitation of one related alternative [ Nardi et al. , 2012 ]. In practice, we show that PrivLogit tends to have lower amortized cost, since PrivLogit iterations hav e very low cost. And this adv antage grows with data dimensionality p . Our second adaption Pri vLogit- Local is guaranteed to outperform Ne wton and the speedup is significant, because it replaces most iterations of Ne wton with extremely fast secure multiplication-by-constant steps. 5.3 Privacy Leaks and Security Guarantees As is common for priv acy-preserving distributed data mining [ Aggarwal and Philip , 2008 ], our work fol- lo ws the priv acy definition of cryptography and secure multi-party computation, and assumes the honest- but-curious adversary model [ Goldreich , 2001 ], where the adversary always follo ws the prescribed protocol, but may attempt to learn additional knowledge from the information flo wed by . W e emphasize that our se- cure protocols PrivLogit-Hessian and Pri vLogit-Local directly adopt existing secure primiti ves and b uilding blocks (i.e., garbled circuits [ Y ao , 1982 ], Paillier encryption [ Paillier , 1999 ], and efficient con version pro- tocols), which are state-of-the-art and widely-used in the domain and whose security are well understood. Our work simply hybrids them in efficient ways to safeguard Pri vLogit, whose security proof is straight- forward based on security composition theorem [ Goldreich , 2001 ]. Since detailed security analysis of such hybrid protocols is straightforward and widely av ailable in secure Newton baseline and priv acy-preserving (distributed) data mining [ Nikolaenko et al. , 2013 , Aggarwal and Philip , 2008 ] and is not our focus or contribution (i.e., performance improv ement from non-cryptography components), we only provide con- cise security analysis due to space constraint. Also, as is typical for cryptographic protocols [ Aggarw al and Philip , 2008 ], our protocols only focus on protecting raw and intermediate data/computation, b ut not final result/output priv acy . The latter belongs to a separate topic on differential priv acy [ Chaudhuri and Monteleoni , 2009 ] which is beyond the scope of our w ork. Our protocols do disclose the regression coef ficients (model output) to distributed Nodes and the number of iterations in numerical optimization. Most such leaks are inherent to the nature of cryptography in general (e.g., non-linear functions including logistic regression model cannot be directly and efficiently implemented fully in secure, requiring either re vealing regression coefficients or noisy approximations), and numerical optimization (being iterati ve and distributed means that network communication pattern or iterations number is always observable). Since enhancing security of inherently hard problems is beyond the scope of this work and due to space constraint, our analysis only focuses on ne w materials not widely av ailable in literature. In addition, intermediate model outputs (rev ealed to local Nodes) share the same priv acy properties as the final model output of the whole protocol, because they are all simply regression coefficients. By definition, cryptographic protocols do not protect final output, so this practice does not violate security . The only possible way to breach security in Pri vLogit protocols is for local Nodes to accumulate all regression coef ficients across all iterations and form a linear equation system to solve for individual record-lev el input v alues [ O’Keefe and Chipperfield , 2013 , El Emam et al. , 2013 ]. Ho wev er , since the number of iterations is quite small (at most linear in dimensionality p ) and the (priv acy-sensitiv e) data – the attack target – is 15 huge in size ( n × p , where n is extremely large), the system is se verely undetermined and such attacks are infeasible from information theory standpoint. Except for the two aforementioned leaks, our secure protocols provides comprehensiv e security guar- antees, lev eraging proven cryptographic schemes and hybrid protocols. In both PrivLogit-Hessian and Pri vLogit-Local, local-Node summaries are encrypted prior to submission to guarantee priv acy . In PrivLogit- Local, the in verted approximate Hessian is also encrypted before being shared with local Nodes. At the aggregation Center, all incoming inputs are encrypted in Paillier or Y ao’ s garbled circuit shares. All data, computations and results are also encrypted. Based on the composition theorem of security [ Goldreich , 2001 ], the composition of these secure sub-protocols also yield a secure protocol ov erall. 6 Experiments W e implement both PrivLogit-Hessian and PrivLogit-Local in Jav a. Our garbled circuit is executed using state-of-the-art cryptography frame work ObliVM-GC [ Liu et al. , 2015 ], which already provides thousands of times speedup over earlier works in our case. W e use common priv acy-preserving floating-point represen- tations [ Nikolaenko et al. , 2013 ]. W e use 2048-bit security parameter for encryption and other latest security parameters in ObliVM-GC. Secure Newton method and logistic regression has been explored by different communities and with different relaxations (to make computation feasible), but most were proposed prior to the fast ObliVM-GC framework and no open-source code is av ailable as our baseline, making it difficult for direct and fair comparison. T o set a directly comparable baseline, we thus also implement state-of-the- art priv acy-preserving distributed Ne wton method using latest cryptography (same as our protocols), which may be of separate interest. W e run all experiments between two commodity PCs with 2.5 GHz quad-core CPU and 16 GB memory , connected via ethernet. Our empirical e valuations focus on the follo wing criteria: 1) Model estimation quality (the accuracy of estimated coefficients) (in Section 6.2 ); 2) Model con ver gence performance (in Section 6.3 ). Due to space limit, we hav e to omit numerical stability results (that PrivLogit is always guaranteed to con verge, while Ne wton is not), which has already been theoretically proved in Section 5.1 and does not af fect our final conclusions. In our experiments concerning numerical optimizers (i.e., Pri vLogit and Ne wton method), we randomly initialize first coefficient estimates as commonly suggested (e.g., 0 as initial guess). W e use 10 − 6 as our stopping threshold when checking model con vergence (i.e., relative change of likelihood). Other thresholds hav e also been tested, such as 10 − 7 and 10 − 8 , which does not af fect our main conclusions and thus are omitted. 6.1 Datasets Our empirical e valuation includes a series of simulated and real-world studies, co vering a wide spectrum of applications from dif ferent domains and of different scales. Among these, we hav e compiled four real-world studies, including: 1) the W ine quality study (with 6,497 samples and 12 features) [ Cortez et al. , 2009 ] for predicting wine quality from physicochemical tests, 2) online Loans data (with 122, 578 samples and 33 features) from Lending Club [ LengingClub , 2016 ] for studying loan default status from loan application data, 3) compan y Insurance study (of dimension: 9 , 882 × 38 ) for predicting carav an issurance from demographic information and personal finance attrib utes, and 4) News dataset (of dimension 39 , 082 × 52 ) [ Fernandes et al. , 2015 ] for predicting the popularity of Mashable.com ne ws from article features. 16 T o make our ev aluations more comprehensi ve, we have also simulated a series of studies with vary- ing data scales, including: SimuX10 (of dimension 50 , 000 × 10 ), SimuX12 ( 1 , 000 , 000 × 12 ), SimuX50 ( 1 , 000 , 000 × 50 ), SimuX100 ( 3 , 000 , 000 × 100 ), SimuX150 ( 4 , 000 , 000 × 150 ), SimuX200 ( 5 , 000 , 000 × 200 ), SimuX400 ( 50 , 000 , 000 × 400 ), etc. W e also ev aluated on additional studies with v arious data sizes and numbers of participating organizations. Since these factors do not hav e direct influence on the secure computation process (which primarily concerns summary data) both theoretically and empirically , we do not report on them separately . W e following standard data simulation approach, by randomly generating cov ariates X ∈ R n × p and coef ficients β ∈ R p × 1 , and then deri ving responses y ∈ R n × p according to Bernoulli distribution. These ev aluation datasets should be representati ve for most large-scale studies in our focused domains in the foreable future. W e also randomly partition datasets into subsets (by row or horizontally) in order to emulate dif ferent organizations in collaborati ve studies. 6.2 Model Accuracy First, we demonstrate that our proposals obtain accurate results (i.e., regression coefficients). The standard non-secure distributed Newton method serves as the ground truth. Based on our theoretical proof on exact model accuracy (part of Section 5.1 ), our hypothesis is that despite the significant change in our numerical optimizer and reliance on cryptographic operations, the accuracy of our model estimation should still be guaranteed. Numerical results hav e confirmed our hypothesis, as is illustrated in the QQ-plots in Figure 2 . Specifi- cally , our β coef ficient estimates from Pri vLogit-Hessian and PrivLogit-Local are in perfect alignment with the ground-truth Ne wton across all studies, with correlation R 2 = 1 . 00 (perfect correlation and accuracy). This implies that the approximate Hessian adaption we introduced in PrivLogit still maintains e xact model accuracy . Moreover , it also confirms that the v arious cryptographic protections underlying PrivLogit- Hessian and Pri vLogit-Local have no influence on the model quality . 6.3 Computational Perf ormance Next, we ev aluate the computational performance of PrivLogit-Hessian and Pri vLogit-Local in terms of model con ver gence with respect to iterations count and total runtime. W e partition each ev aluation datasets into 4 ∼ 20 blocks horizontally (i.e., by rows) to emulate different data-contributing or ganizations. As it has been demonstrated both theoretically and empirically that cryptographic protections do not af fect the accu- racy of computation in our case, we refer to our two secure protocols as PrivLogit in general for simplicity . Our model con vergence threshold is set at 10 − 6 , as mentioned earlier . Iterations to con vergence As is illustrated in Figure 3 , all protocols managed to conv erge within a rea- sonable number of iterations. For instance, the Loans study (of dimension: 122 , 578 × 33 ) requires 6 and 17 iterations, respecti vely , to con verge for the Newton and our PrivLogit-based secure proposals. For the smaller Insurance study , it takes 7 (for Newton) and 59 (for Pri vLogit) iterations, respectiv ely . As the data size (especially dimensionality) increases, we observ e increases in the number of iterations both for Newton and Pri vLogit, with the former growing slower . For instance, SimuX150 (with 4 millions samples and 150 features) requires 7 iterations for Newton (only 17% increase over Loans ) and 83 iterations for PrivLogit (388% increase ov er Loans ). Judging from model con ver gence iterations, Pri vLogit seems “unfa vorable” to Newton, as PrivLogit often requires a fe w tens of or more iterations, while the latter seems significantly faster with only single- 17 −0.5 0.5 −0.5 0.5 Wine −1 1 3 −1 1 3 Loan −4 −2 0 2 −4 −2 0 2 Insurance −0.5 0.5 −0.5 0.5 News −1.0 0.0 −1.0 0.0 SimuX10 −2 0 1 2 −2 0 1 2 SimuX12 −2 0 1 2 −2 0 1 2 SimuX50 −2 0 1 2 −2 0 1 2 SimuX100 −2 0 1 2 −2 0 1 2 SimuX150 −2 0 1 2 −2 0 1 2 SimuX200 Ne wton PrivLogit Figure 2: Result accuracy comparison across various datasets, as measured by QQ-plot of model coef ficients estimated by ours (PrivLogit-Hessian and PrivLogit-Local; y-axis) vs. “ground-truth” Ne wton baseline (x- axis). Pri vLogit-Hessian (in black) and PrivLogit-Local (in blue) points totally overlapped and both were perfectly aligned along the diagonal, showing exact result accuracy (perfect correlation of R 2 = 1 . 00 against baseline Ne wton). digit number of iterations. The elongated con ver gence rate is perhaps the main reason why methods similar to PrivLogit have nev er been considered in the data security and priv acy community . Howe ver , we will soon refute such a misconception by comparing the total runtime. Con vergence runtime Surprisingly , detailed runtime benchmark in T able 2 manifests that both our secure protocols, i.e., Pri vLogit-Hessian and Pri vLogit-Local, turn out to be quite competitiv e in computational performance. For instance, in the Loans study , while Newton method takes only 6 iterations, its actual runtime reaches as much as 492 seconds (because of expensi ve per-iteration computation); On the other hand, despite requiring substantially more iterations (i.e., 17), our PrivLogit-Hessian and PrivLogit-Local protocols only take around 260 and 104 seconds, respecti vely , leading to 1.9x and 4.7x speedup, respectiv ely . For e ven larger -scale studies such as SimuX150 , Ne wton method takes 42,951 seconds or roughly 12 hours. Pri vLogit-Hessian and Pri vLogit-Local are respecti vely 1.7x and 7.1x times faster than Newton in this case. One interesting observation is that in rare occasions, Pri vLogit-Hessian can be slightly slower than Ne wton. F or instance, the Insurance study requires around 843 seconds for Newton (for 7 iterations), but 978 seconds (1.16x slo wer) for Pri vLogit-Hessian. This indicates that dir ectly applying Pri vLogit (i.e., Pri vLogit-Hessian) does not guarantee improvement. Our second protocol, Pri vLogit-Local, ho wev er , al- ways outperforms Ne wton with dramatic speedup: requiring only 144 seconds (5.9x speedup). Overall, PrivLogit-Local constantly outperforms other methods with significant speedup, while Pri vLogit- Hessian is generally faster than Ne wton most of the time. Furthermore, we also test on datasets with dimensions as high as 400, a scale that has never been r eported before for privacy-pr eserving logistic re gr ession (not even for a muc h simpler linear r e gr ession 18 0 10 20 30 40 50 60 1e−07 1e−05 1e−03 1e−01 # of Iterations Relativ e change of likelihood Wine−PrivLogit Wine−Newton Loan−PrivLogit Loan−Newton Insurance−PrivLogit Insurance−Newton News−PrivLogit News−Ne wton 0 20 40 60 80 100 1e−07 1e−05 1e−03 1e−01 1e+01 # of Iterations Relativ e change of likelihood SimuX10−PrivLogit SimuX10−Newton SimuX12−PrivLogit SimuX12−Newton SimuX50−PrivLogit SimuX50−Newton SimuX100−PrivLogit SimuX100−Newton SimuX150−PrivLogit SimuX150−Newton SimuX200−PrivLogit SimuX200−Newton Figure 3: Conv ergence iterations of Pri vLogit and the Newton method baseline on real-world (upper panel) and simulated (lo wer panel) datasets. Red horizontal line denotes the stopping threshold. model [ Nikolaenko et al. , 2013 ]) . Unfortunately , only Pri vLogit-Local con verges within reasonable time (110,598 seconds or roughly 1.28 days; for 206 iterations). The other two protocols still did not complete after 4 days. While Pri vLogit-Hessian did not complete, its con vergence iterations is expected to be the same as PrivLogit-Local (i.e., 206 iterations) since they implement the same optimization algorithm. F or Ne wton method, a non-secure implementation requires 8 iterations. Relative speedup T o better demonstrate the relativ e performance of PrivLogit-Hessian and PrivLogit- Local o ver existing secure Ne wton methods, we extensi vely benchmark the relati ve speedup of our methods 19 T able 2: Model conv ergence iterations and runtime (in seconds) benchmark for Newton, PrivLogit, Pri vLogit-Hessian, PrivLogit-Local. Dataset Iterations Newton Iterations PrivLogit Time Newton Time (S) PrivLogit-Hessian Time (S) PrivLogit-Local W ine 5 13 32 24 17 Loans 6 17 492 260 104 Insurance 7 59 843 978 144 Ne ws 5 13 1442 621 313 SimuX10 6 20 26 24 13 SimuX12 6 22 38 37 17 SimuX50 6 32 1549 1052 383 SimuX100 7 59 13138 7817 1807 SimuX150 7 83 42951 25030 6055 SimuX200 8 105 114522 56917 14105 SimuX400 8 206 N/A N/A 110598 ov er the baseline Ne wton. As illustrated in Figure 4 , Pri vLogit-Hessian outperforms Newton most of the time (except for one occurrence of Insurance ), and the speedup is between 1.03x ∼ 2.32x. For PrivLogit- Local, the speedup is even more striking, with a speedup of up to 8.1x. For small datasets, PrivLogit-Local is around 2x faster than Newton; for medium datasets such as Loans, Insurance, News , its speedup is around 4x ∼ 6x. The largest increase in relativ e performance is from Pri vLogit-Local on the SimuX200 dataset, with 8.1x speedup. PrivLogit-Hessian also performs well, with 2x speedup. In general, as data dimension increases, we see much more relati ve ef ficiency gain for both Pri vLogit-Hessian and PrivLogit-Local. Overall, this provides further e vidence that our secure PrivLogit proposals hav e better performance compared to state-of-the-art pri vac y-preserving distributed Newton method, and our relativ e competiti ve adv antage increases along with data scale. This indicates that our methods hold much better potential for large-scale studies in the big data era. 7 Related W orks Pri vac y-preserving regression analysis and machine learning in general is activ ely inv estigated. Here we discuss se veral closely related lines of research. 7.1 Cryptographic Protections on Logistic Regr ession and Other Models Extensi ve efforts hav e focused on protecting priv acy in logistic regression, from centralized solutions [ El Emam et al. , 2013 ] to distributed architecture [ Karr et al. , 2007 , W olfson et al. , 2010 , Nardi et al. , 2012 , Li et al. , 2015 , W u et al. , 2012b , a ]. Due to complexity of securely computing logistic function, many existing propos- als compromise on security guarantee by providing no or only weak protections ov er intermediate summary 20 0 1 2 4 6 8 SimuX10 SimuX12 Wine Loans Insurance SimuX50 News SimuX100 SimuX150 SimuX200 Datasets Speedup Pro tocols: PrivLogit-Hessian PrivLogit-Outsource Figure 4: Relativ e speedup of PrivLogit-Hessian and PrivLogit-Local ov er the secure distributed Newton baseline (the y = 1 line), across various datasets. Our protocols can speed-up the computation by up to 2.32x and 8.1x (and e ven more), respecti vely . data [ W olfson et al. , 2010 , W u et al. , 2012a , Li et al. , 2016 ], which can be problematic given various in- ference attacks [ O’Keefe and Chipperfield , 2013 , Xie et al. , 2014 , El Emam et al. , 2013 ]. Other works approximate the logistic function, resulting in accurac y loss [ Nardi et al. , 2012 , El Emam et al. , 2013 , Aono et al. , 2016 ]. Nearly all existing works directly apply mainstream model estimation algorithms (i.e., Ne wton method) without customization. Our proposal, howe ver , provides a secure computing-centric perspective, and proposes a tailored optimizer specifically for cryptography that significantly outperforms alternati ves while guaranteeing accuracy and pri vacy . Hessian approximation was briefly explored by [ Nardi et al. , 2012 ], b ut without justification or ev en (comparati ve) performance ev aluation. Our results show that direct application of the method does not necessarily lead to better performance, and e ven when it does, the improvement is modest. In addition, for datasets of size n × p , Newton method has per-iteration complexity O ( np 2 + p 3 ) (where the first term is 21 dominating the cost). And the main improv ement of approximate Hessian is by limiting the first term np 2 to one occurrence only (as in [ Nardi et al. , 2012 ]). Ho wev er , our use case is different as our local-organization computation is priv acy-free (i.e., independent from sample size n ) and total cost is only determined by the second term O ( p 3 ) , making it not obvious of the benefits of approximate Hessian. In fact, there is no performance guarantee if dir ectly adopting approximate Hessian in our situation. Cryptography is also widely used to safeguard other machine learning models, as partially revie wed by [ Aggarwal and Philip , 2008 ]. 7.2 Perturbation-based Priv acy Protection Perturbing data via artificial noise is also a popular technique for priv acy preservation (e.g., k − anonymity , dif ferential priv acy [ Chaudhuri and Monteleoni , 2009 ]). Ho we ver , since such methods inherently change the data and computation output, their results may no longer be scientifically v alid and thus are not widely accepted in practice. In addition, they do not protect the computation process, which is the central goal of cryptography-based protections. 7.3 Impro ved Numerical Optimization f or Regr ession Numerical optimization for regression analytics is under extensi ve in vestigation. These include v arious ef- forts to approximate or eliminate the Hessian from Newton-style optimizers, such as the Quasi-Newton or Hessian-free optimization (e.g., BFGS and L-BFGS [ Liu and Nocedal , 1989 ]). Howe ver , none of them have seen adoption in data security and priv acy research, partially because they are heavily tailored for priv acy- free scenarios and often data-dependent and thus dif ficult for cryptographic implementation. Hessian ap- proximation was described in the 1980s for maximum likelihood (in priv acy-free applications) [ B ¨ ohning and Lindsay , 1988 ], but only with limited adoption in practice maybe due to their not-obvious efficienc y improv ement for priv acy-free settings. 8 Discussion & Conclusion In PrivLogit-Hessian and PrivLogit-Local, the network bandwidth and transmission cost is small, since the encrypted summary information exchanged has very minimal size even for large studies, especially giv en that Hessian only needs to be preprocessed once. Since these factors are already accounted for in the total runtime benchmark, we omit detailed discussion for bre vity . The PrivLogit optimizer is designed for secure computing in general and agonostic of specific crypto- graphic schemes. Thus our empirical ev aluation is focused on showing further speedup on top of state-of- the-art cryptography . There is room for further acceleration on our protocols as cryptography continues to improve, especially giv en that our computation is significantly simpler than baseline Newton. Ho wev er , since our work focuses on r elative speedup (e xcluding improv ement in cryptography alone) and we aim to provide a direct comparison with state-of-the-art based on the same cryptography primitiv es, we lea ve it as future work to e xplore alternativ e cryptographic schemes. While our work focuses on logistic regression model, our proposal of tailoring optimizers for secure computing seems widely applicable to priv acy-preserving machine learning, as mainstream (distributed) numerical optimizers are not necessarily competiti ve for secure computing despite their wide and “direct” adoption in data security and pri vac y . W e consider extending this no vel approach to other machine learning models, such as other classifiers [ Zheng et al. , 2017 ], regressors, and deep learning [ Beaulieu-Jones and Greene , 2016 ] that are increasingly popular in pri vac y-sensitiv e domains. 22 8.1 Conclusion In this work, we hav e made a nov el observ ation about a generic performance bottleneck in priv acy-preserving logistic regression, and proposed an improved numerical optimizer (i.e., PrivLogit) and demonstrate its ob- scure but surprisingly competitiv e performance for priv acy-preserving logistic regression. This contrasts to common practice in priv acy-preserving data mining (i.e., directly applying mainstream numerical optimiza- tion), which often disregards secure computing-specific characteristics and thus misses valuable opportuni- ties for significant performance boost. Based on PrivLogit, we also propose two secure and highly-efficient protocols for priv acy-preserving logistic regression. W e validate our proposals extensi vely using both an- alytical and empirical e valuations. Results indicate that our proposals outperform alternativ es by several times while ensuring priv acy and accuracy . Our methods should be helpful for making pri vac y-preserving logistic regression more scalable and practical for large collaborativ e studies. And our novel and generic perspecti ve on tailoring optimizers for secure computing should also inspire other research in secure data management in general. Refer ences Charu C Aggarwal and S Y u Philip. A gener al survey of privacy-preserving data mining models and algo- rithms . Springer , 2008. Y oshinori Aono, T akuya Hayashi, Le T rieu Phong, and Lihua W ang. Scalable and secure logistic regression via homomorphic encryption. In Sixth ACM Confer ence on Data and Application Security and Privacy , pages 142–144, 2016. Brett K Beaulieu-Jones and Casey S Greene. Semi-supervised learning of the electronic health record with denoising autoencoders for phenotype stratification. J ournal of Biomedical Informatics , 64:168–178, 2016. Dankmar B ¨ ohning and Bruce G Lindsay . Monotonicity of quadratic-approximation algorithms. Annals of the Institute of Statistical Mathematics , 40(4):641–663, 1988. Ste ven M Boker , Timoth y R Brick, Joshua N Pritikin, Y ang W ang, Timo v on Oertzen, Donald Brown, John Lach, Ryne Estabrook, Michael D Hunter , Hermine H Maes, et al. Maintained indi vidual data distrib uted likelihood estimation (middle). Multivariate behavioral r esear ch , 50(6):706–720, 2015. Kamalika Chaudhuri and Claire Monteleoni. Priv acy-preserving logistic regression. In Advances in Neural Information Pr ocessing Systems , pages 289–296, 2009. Paulo Cortez, Ant ´ onio Cerdeira, Fernando Almeida, T elmo Matos, and Jos ´ e Reis. Modeling wine prefer- ences by data mining from physicochemical properties. Decision Support Systems , 47(4):547–553, 2009. Jon P Daries, Justin Reich, Jim W aldo, Elise M Y oung, Jonathan Whittinghill, Andre w Dean Ho, Daniel Thomas Seaton, and Isaac Chuang. Pri vac y , anonymity , and big data in the social sciences. Com- munications of the A CM , 57(9):56–63, 2014. Khaled El Emam, Saeed Samet, Luk Arbuckle, Robyn T amblyn, Craig Earle, and Murat Kantarcioglu. A secure distrib uted logistic regression protocol for the detection of rare adv erse drug events. J ournal of the American Medical Informatics Association , 20(3):453–461, 2013. 23 K elwin Fernandes, Pedro V inagre, and Paulo Cortez. A proacti ve intelligent decision support system for predicting the popularity of online news. In Pr ogr ess in Artificial Intelligence , pages 535–546. Springer, 2015. Oded Goldreich. Foundation of cryptography (in tw o volumes: Basic tools and basic applications), 2001. Frank Harrell. Re gression modeling strate gies: with applications to linear models, logistic and or dinal r e gr ession, and survival analysis . Springer , 2015. Kathy L Hudson, MK Holohan, and Francis S Collins. Keeping pace with the times–the genetic information nondiscrimination act of 2008. New England J ournal of Medicine , 358(25):2661–2663, 2008. Liina Kamm and Jan W illemson. Secure floating-point arithmetic and priv ate satellite collision analysis. 2013. Alan F Karr , W illiam J Fulp, Francisco V era, S Stanle y Y oung, Xiaodong Lin, and Jerome P Reiter . Secure, pri vac y-preserving analysis of distributed databases. T echnometrics , 49(3):335–345, 2007. LengingClub . Loans data. http://www .lendingclub.com, 2016. Last accessed: 02-02-2016. Cathryn M Le wis and Jo Knight. Introduction to genetic association studies. Cold Spring Harbor Pr otocols , 2012(3):pdb–top068163, 2012. W enfa Li, Hongzhe Liu, Peng Y ang, and W ei Xie. Supporting regularized logistic regression pri vately and ef ficiently . arXiv preprint , 2015. W enfa Li, Hongzhe Liu, Peng Y ang, and W ei Xie. Supporting regularized logistic regression pri vately and ef ficiently . PloS one , 11(6):e0156479, 2016. Chang Liu, Xiao Shaun W ang, Kartik Nayak, Y an Huang, and Elaine Shi. Obli vm: A programming frame- work for secure computation. In Security and Privacy (SP), 2015 IEEE Symposium on , pages 359–376. IEEE, 2015. Dong C Liu and Jorge Nocedal. On the limited memory bfgs method for large scale optimization. Mathe- matical pr ogramming , 45(1-3):503–528, 1989. Edmund G Lo wrie and Nancy L Le w . Death risk in hemodialysis patients: the predicti ve value of commonly measured variables and an ev aluation of death rate differences between facilities. American Journal of Kidne y Diseases , 15(5):458–482, 1990. Catherine A McCarty , Re x L Chisholm, Christopher G Chute, Iftikhar J K ullo, Gail P Jarvik, Eric B Larson, Rongling Li, Daniel R Masys, Marylyn D Ritchie, Dan M Roden, et al. The emerge network: a consortium of biorepositories linked to electronic medical records data for conducting genomic studies. BMC medical genomics , 4(1):13, 2011. H Brendan McMahan, Gary Holt, David Sculley , Michael Y oung, Dietmar Ebner , Julian Grady , Lan Nie, T odd Phillips, Eugene Davydov , Daniel Golovin, et al. Ad click prediction: a view from the trenches. In Pr oceedings of the 19th ACM SIGKDD international confer ence on Knowledge discovery and data mining , pages 1222–1230. A CM, 2013. 24 Y uval Nardi, Stephen E Fienberg, and Robert J Hall. Achieving both valid and secure logistic regression analysis on aggregated data from dif ferent priv ate sources. Journal of Privacy and Confidentiality , 4(1): 9, 2012. K Nigam. Using maximum entropy for text classification. In IJCAI-99 W orkshop on Machine Learning for Information filtering , 1999. V aleria Nikolaenko, Udi W einsberg, Stratis Ioannidis, Marc Joye, Dan Boneh, and Nina T aft. Pri vac y- preserving ridge regression on hundreds of millions of records. In Security and Privacy (SP), 2013 IEEE Symposium on , pages 334–348, 2013. HHS Office for Ci vil Rights. Standards for pri vac y of individually identifiable health information. final rule. F ederal Re gister , 67(157):53181, 2002. Christine M O’Keefe and James O Chipperfield. A summary of attack methods and confidentiality protection measures for fully automated remote analysis systems. International Statistical Revie w , 81(3):426–455, 2013. Pascal Paillier . Public-key cryptosystems based on composite degree residuosity classes. In Advances in cryptology – EUR OCRYPT’99 , pages 223–238. Springer , 1999. V assilios S V erykios, Elisa Bertino, Igor Nai Fovino, Loredana Parasiliti Prov enza, Y ucel Saygin, and Y annis Theodoridis. State-of-the-art in priv acy preserving data mining. ACM Sigmod Recor d , 33(1):50–57, 2004. Michael W olfson, Susan E W allace, Nicholas Masca, Geoff Rowe, Nuala A Sheehan, V incent Ferretti, Philippe LaFlamme, Martin D T obin, John Macleod, Julian Little, et al. Datashield: resolving a conflict in contemporary bioscience – performing a pooled analysis of individual-le vel data without sharing the data. International journal of epidemiology , page dyq111, 2010. Y uan W u, Xiaoqian Jiang, Jihoon Kim, and Lucila Ohno-Machado. Grid binary logistic regression (glore): building shared models without sharing data. Journal of the American Medical Informatics Association , 19(5):758–764, 2012a. Y uan W u, Xiaoqian Jiang, and Lucila Ohno-Machado. Preserving institutional priv acy in distrib uted binary logistic regression. In AMIA Annual Symposium Proceedings , v olume 2012, page 1450, 2012b. W ei Xie, Murat Kantarcioglu, W illiam S Bush, Dana Crawford, Joshua C Denn y , Raymond Heatherly , and Bradley A Malin. Securema: protecting participant priv acy in genetic association meta-analysis. Bioinformatics , 30(23):3334–3341, 2014. Andre w C Y ao. Protocols for secure computations. In 2013 IEEE 54th Annual Symposium on F oundations of Computer Science , pages 160–164. IEEE, 1982. Nan Zhang and W ei Zhao. Distributed priv acy preserving information sharing. In Pr oceedings of the 31st international confer ence on V ery larg e data bases , pages 889–900. VLDB Endowment, 2005. T ao Zheng, W ei Xie, Liling Xu, Xiaoying He, Y a Zhang, Mingrong Y ou, Gong Y ang, and Y ou Chen. A machine learning-based framework to identify type 2 diabetes through electronic health records. Interna- tional J ournal of Medical Informatics , 97:120–127, 2017. 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment