Feature-Augmented Neural Networks for Patient Note De-identification
Patient notes contain a wealth of information of potentially great interest to medical investigators. However, to protect patients' privacy, Protected Health Information (PHI) must be removed from the patient notes before they can be legally released…
Authors: Ji Young Lee, Franck Dernoncourt, Ozlem Uzuner
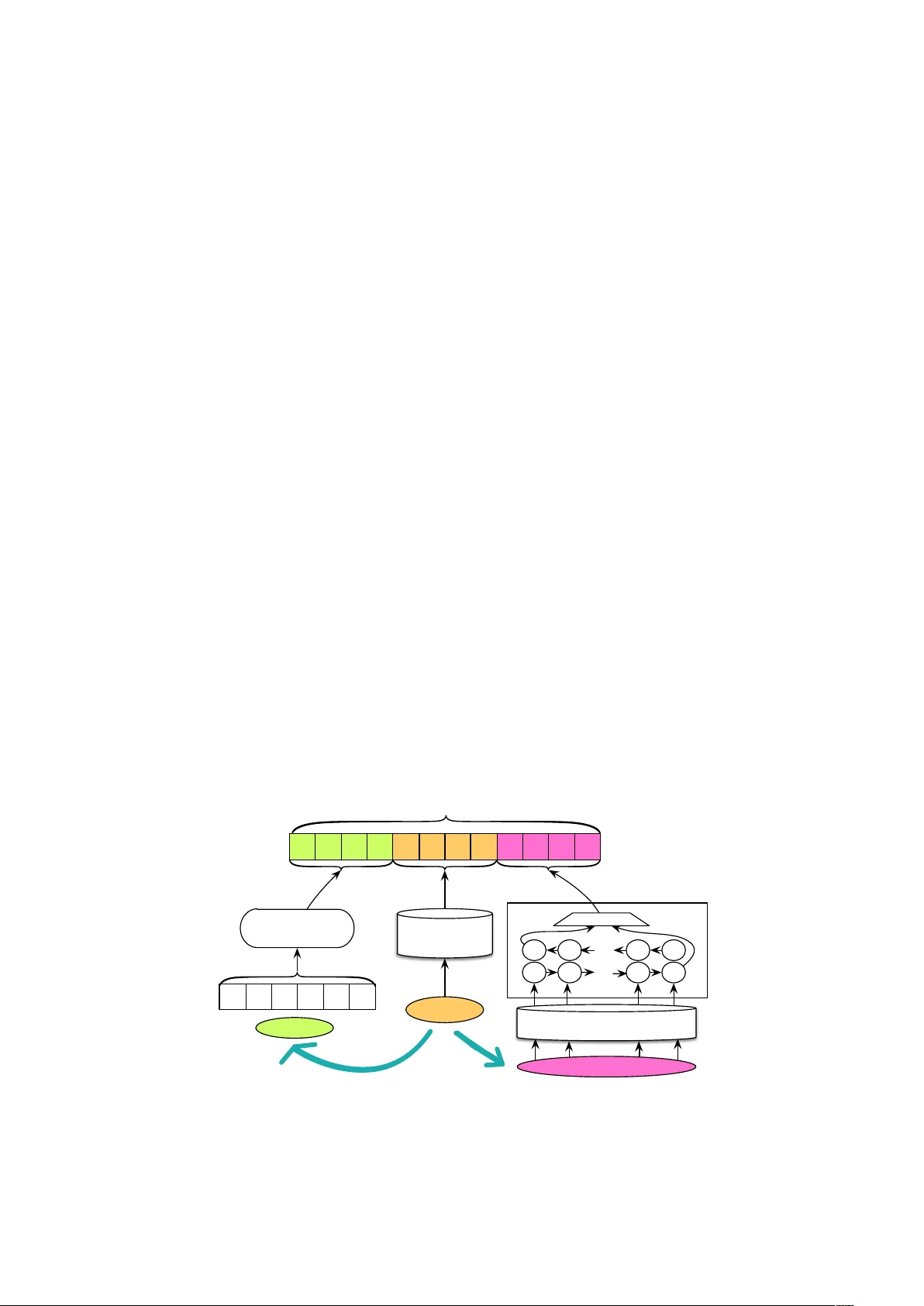
F eatur e-A ugmented Neural Networks f or Patient Note De-identification Ji Y oung Lee 1 ∗ , Franck Dernoncourt 1 ∗ , ¨ Ozlem Uzuner 2 , Peter Szolo vits 1 1 MIT , 2 SUNY Albany { jjylee,francky } @mit.edu, ouzuner@albany.edu, psz@mit.edu ∗ These authors contributed equally to this w ork. Abstract Patient notes contain a wealth of information of potentially great interest to medical inv estigators. Howe ver , to protect patients’ privac y , Protected Health Information (PHI) must be remov ed from the patient notes before they can be legally released, a process kno wn as patient note de-identification. The main objecti ve for a de-identification system is to hav e the highest possible recall. Recently , the first neural-network-based de-identification system has been proposed, yielding state-of-the-art results. Unlike other systems, it does not rely on human-engineered features, which allows it to be quickly deployed, but does not leverage knowledge from human experts or from electronic health records (EHRs). In this work, we explore a method to incorporate human-engineered features as well as features derived from EHRs to a neural-network-based de-identification system. Our results show that the addition of features, especially the EHR-deri ved features, further improv es the state-of-the-art in patient note de-identification, including for some of the most sensitiv e PHI types such as patient names. Since in a real-life setting patient notes typically come with EHRs, we recommend de velopers of de-identification systems to le verage the information EHRs contain. 1 Introduction and r elated work Medical practitioners increasingly store patient data in Electronic Health Records (EHRs) (Hsiao et al., 2011), which represents a considerable opportunity for medical in vestigators to construct novel models and experiments to impro ve patient care. Some gov ernments ev en subsidize the adoption of EHRs, such as the Centers for Medicare & Medicaid Services in the United States who have spent over $30 billion in EHR incenti ve payments to hospitals and medical providers (McCann, 2015). A legal prerequisite for a patient note to be shared with a medical in vestigator is that it must be de- identified. The objectiv e of the de-identification process is to remov e all Protected Health Information (PHI). Not appropriately removing PHI may result in financial penalties (DesRoches et al., 2013; Wright et al., 2013). In the United States, the Health Insurance Portability and Accountability Act (HIP AA) (Of- fice for Ci vil Rights, 2002) defines PHI types that must be removed, ranging from phone numbers to patient names. Failure to accurately de-identify a patient note would jeopardize the patient’ s pri v acy: the performance of a de-identification system is therefore critical. A nai ve approach to de-identification is to manually identify PHI. Howe ver , this is costly (Douglass et al., 2005; Douglas et al., 2004) and unreliable (Neamatullah et al., 2008). Consequently , there has been much work de veloping automated de-identification systems. These systems are either based on rules or machine-learning models. Rule-based systems typically rely on patterns, expressed as regular expressions and gazetteers, defined and tuned by humans (Berman, 2003; Beckwith et al., 2006; Fielstein et al., 2004; Friedlin and McDonald, 2008; Gupta et al., 2004; Morrison et al., 2009; Neamatullah et al., 2008; Ruch et al., 2000; Sweeney , 1996; Thomas et al., 2002). Machine-learning-based systems train a classifier to label each tok en as PHI or not PHI. Some systems are more fine-grained by detecting which PHI type a token belongs to. Different statistical methods ha ve been explored for patient note de-identification, including decision trees (Szarv as et al., 2006), log-linear models, support vector machines (SVMs) (Guo et al., 2006; Uzuner et al., 2008; Hara, 2006), and conditional random field (CRFs) (Aberdeen et al., 2010). A thorough revie w of existing systems can be found in (Meystre et al., 2010; Stubbs et al., 2015). This work is licenced under a Creati ve Commons Attrib ution 4.0 International License. License details: http://creativecommons.org/licenses/by/4.0/ A more recent system has introduced the use of artificial neural networks (ANNs) for de- identification (Dernoncourt et al., 2016), and obtained state-of-the-art results. The system does not use any manually-curated features. Instead, it solely relies on character and token embeddings. While this allo ws the system to be developed and deployed faster , it fails to giv e users the possibility to add fea- tures engineered by human experts. Additionally , in practical settings of de-identification, patient notes typically come from a hospital EHR database, which contains metadata such as which patient each note pertains to, and other information such as the names of all doctors who work at the hospital where the patient was treated. The features derived from EHR databases may be useful for boosting the perfor- mance of de-identification systems. In this work, we present a method to incorporate features to this ANN-based system, and sho w that it further improves the state-of-the-art. 2 Method The first model based on ANNs for patient note de-identification was introduced in (Dernoncourt et al., 2016): we extend upon their model. They utilized both token and character embeddings to learn ef fectiv e features from data by fine-tuning the parameters. The main components of the ANN model are Long Short T erm Memories (LSTMs) (Hochreiter and Schmidhuber , 1997), which are a type of recurrent neural networks (RNNs). The model is composed of three layers: a character-enhanced token embedding layer, a label predic- tion layer , and a label sequence optimization layer . The character -enhanced tok en embedding layer maps each token into a vector representation. The sequence of vector representations corresponding to a se- quence of tokens are input to the label prediction layer , which outputs the sequence of v ectors containing the probability of each label for each corresponding token. Lastly , the sequence optimization layer out- puts the most likely sequence of predicted labels based on the sequence of probability vectors from the pre vious layer . All layers are learned jointly . For more details on the basic ANN model, see (Dernoncourt et al., 2016). W e augment this ANN model by adding features that are human-engineered or deriv ed from EHR database, as presented in T able 1. The majority of human-engineered features are taken from (Filan- nino and Nenadic, 2015), a few more features come from (Y ang and Garibaldi, 2015), and additional gazetteers are collected using online resources. All features are binary and computed for each token. The binary feature vector comprising all features for a giv en token is fed into a feedforward neural net- work, the output vector of which is concatenated to the corresponding token embeddings, at the output of the character-enhanced tok en embedding layer , as Figure 1 illustrates. bi-LSTM Pre-trained token embeddings Features Characters Character embeddings concatanate 0 1 1 0 0 … T oken Feedforward neural network Feature-augmented token embeddings … … … Figure 1: Feature-augmented token embeddings. Each token is mapped to a token embedding that is the concatenation of three elements: the output of a feedforward neural network that takes the features as input, a pre-trained token embedding, and the output of a bidirectional-LSTM (bi-LSTM) that takes the character embeddings as input. Featur e types Featur es Note metadata Hospital data Patient’ s first name, patient’ s last name Doctor’ s first names, doctor’ s last names ) EHR features Morphological Ends with s, is the first letter capitalized, contains a digit, is numeric, is alphabetic, is alphanu- meric, is title case, is all lower case, is all upper case, is a stop w ord Semantic/W ordnet Hypernyms, senses, lemma names T emporal Seasons, months, weekdays, times of the day , years, years followed by apostrophe, festivity dates, holidays, cardinal numbers, decades, fuzzy quantifier (e.g., “approximately”, “fe w”), future trigger (e.g., “next”, “tomorro w”) Gazetteers Honorifics for doctors, honorifics, medical specialists, medical specialties, first names, last names, last name prefixes, street suffixes, US cities, US states (including abbreviations), coun- tries, nationalities, organizations, professions Regular e xpressions Email, age, date, phone, zip code, id number , medical record number T able 1: Feature list. Note metadata and hospital data are deriv ed from the EHR database. Morphologi- cal, semantic/wordnet, and temporal features are commonly used features for NLP tasks. Gazetteers and regular e xpressions are specifically engineered for the task. 3 Experiments W e e valuate our model on the de-identification dataset introduced in (Dernoncourt et al., 2016), which is a subset of the MIMIC-III dataset (Goldberger et al., 2000; Saeed et al., 2011; Johnson et al., 2016), using the same train/validation/test split (70%/10%/20%). W e chose this dataset as each note comes with metadata, such as the patient’ s name, and it is the largest de-identification dataset a vailable to us. It contains 1,635 discharge summaries, 2,945,228 tok ens, 69,525 unique tokens, and 78,633 PHI tokens. The model is trained using stochastic gradient descent, updating all parameters, i.e., token embed- dings, character embeddings, parameters of bidirectional LSTMs, and transition probabilities, at each gradient step. For re gularization, dropout is applied to the character-enhanced token embeddings before the label prediction layer . W e set the character embedding dimension to 25, the character-based token embedding LSTM dimension to 25, the token embedding dimension to 100, the label prediction LSTM dimension to 100, the dropout probability to 0.5, and we use GloV e embeddings (Pennington et al., 2014) trained on W ikipedia and Gigaword 5 (P arker et al., 2011) articles as pre-trained token embeddings. The hyperparameters were optimized based on the performance on the v alidation set. 4 Results T able 2 presents the main results. The epochs for which the results are reported are optimized based on either the highest F1-score or the highest recall on the validation set. As expected, choosing the epoch based on the recall improves the recall on the test set, while lowering the precision. Overall, adding features consistently improv es the results. T able 3 details the results for each PHI type. The system using only the EHR features yields the highest recall for 6 out of 12 PHI types. Most importantly , the recall for patient and doctor names are higher when using features than when using no feature: this is expected as the patient name of the note and the doctor names are used as features. In fact, the two remaining false negati ves for patient names are annotation errors. For example, in the sentence “The patient responded well to Natr ecor in the past, but the improv ement disappeared soon”, the drug name Natrecor was incorrectly marked as a patient name by the human annotator . This result is highly remarkable as patient names are the most sensiti ve information in a patient note (South et al., 2014). Adding all features often lowers the recall compared to using EHR features only , although the F1- score remains virtually unchanged. This is somewhat surprising, as we had expected that the features would help, as using the same feature set with a CRF to perform de-identification yields state-of-the- art results next to the ANN models (Dernoncourt et al., 2016). This could be explained as follows. Human-engineered features tend to hav e higher precision than recall, as it is often hard to design regular expressions or gazetteers that can detect all possible instances or variations of the desired entities. W e Binary HIP AA (optimized by F1-score) Binary HIP AA (optimized by recall) Precision Recall F1-score Precision Recall F1-score No feature 99.103 99.197 99.150 98.557 99.376 98.965 EHR features 99.100 99.304 99.202 98.771 99.441 99.105 All features 99.213 99.306 99.259 98.880 99.420 99.149 T able 2: Binary HIP AA token-based results (%) for the ANN model, av eraged over 5 runs. The metric refers to the detection of PHI tokens versus non-PHI tokens, amongst PHI types that are defined by HIP AA. “No feature” is the model utilizing only character and word embeddings, without any feature. “EHR features” uses only 4 features deriv ed from EHR database: patient first name, patient last name, doctor first name, and doctor last name. “ All features” makes use of all features, including the EHR features as well as other engineered features listed in T able 1. “Optimized by F1-score” and “optimized by recall” means that the epochs for which the results are reported are optimized based on the highest F1-score or the highest recall on the v alidation set, respectiv ely . No feature EHR features All features P R F1 P R F1 P R F1 Support Zip 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 24 Date 98.90 99.77 99.33 98.95 99.79 99.36 98.99 99.69 99.34 20627 Phone 98.31 99.58 98.94 98.98 99.46 99.22 99.42 99.32 99.37 1438 Patient 96.89 98.34 97.61 98.62 99.14 98.88 99.21 99.27 99.24 302 ID 99.57 98.24 98.90 99.31 98.82 99.07 99.77 97.97 98.86 612 Doctor 1 97.47 98.17 97.82 97.27 98.48 97.87 97.56 98.20 97.88 3676 Location 96.02 95.71 95.86 96.41 96.49 96.45 96.65 96.32 96.46 462 Age ≥ 90 75.12 94.29 83.60 77.04 95.72 85.35 78.93 93.57 84.80 28 Hospital 1 94.78 95.39 95.08 94.77 95.52 95.14 95.53 95.50 95.51 1259 State 1 99.36 94.33 96.76 99.68 94.03 96.73 99.39 91.94 95.49 67 Street 96.77 85.25 90.54 97.63 85.25 90.96 93.91 86.56 89.81 61 Country 1 87.51 85.00 86.11 89.29 82.50 85.67 86.87 95.00 90.56 16 Binary 98.41 99.19 98.80 98.48 99.27 98.87 98.61 99.15 98.88 28572 T able 3: Binary tok en-based results (%) . The reported results are optimized by recall, and a veraged ov er 5 runs. The symbol 1 indicates that the PHI type is not required by HIP AA. The PHI type “location” designates any location that is not a street name, zip code, state or country . P stands for precision, R for recall, and F1 for F1-score. conjecture that as the ANN model learn to rely more on such features, it might lose the ability to learn to pick up tokens that de viate from engineered features, resulting in a lower recall. For example, we notice that the phone PHI tokens that are not detected by the model using all features but are detected by the other two models, are ill-formed phone numbers such as “617-554- | 2395”, or phone extensions such as “617-690-4031 ext 6599”. Since the phone regular expressions do not capture these two examples, they are more likely to be false ne gativ es in the model that uses the phone regular expression features. 5 Conclusion In this paper we presented an extension of the ANN-based model for patient note de-identification that can incorporate features. W e sho wed that adding features results in an increase of the recall, in particular features le veraging information from the associated EHRs, namely patient names and doctor names. Our results suggest that constructing patient note de-identification systems should be performed us- ing structured information from the EHRs, the latter being available in a typical, real-life setting. W e restricted our EHR-derived features to patient and doctor names, but it could be extended to the many other structured fields that EHR contain, such as patients’ addresses, phone numbers, email addresses, professions, and ages. Acknowledgements The project was supported by Philips Research. The content is solely the responsibility of the authors and does not necessarily represent the official views of Philips Research. W e warmly thank Michele Filannino, Alistair Johnson, Li-wei Lehman, Roger Mark, and T om Pollard for their helpful suggestions and technical assistance. References [Aberdeen et al.2010] John Aberdeen, Samuel Bayer , Reyyan Y eniterzi, Ben W ellner, Cheryl Clark, Da vid Hanauer , Bradley Malin, and L ynette Hirschman. 2010. The MITRE Identification Scrubber T oolkit: design, training, and assessment. International journal of medical informatics , 79(12):849–859. [Beckwith et al.2006] Bruce A Beckwith, Rajeshwarri Mahaade van, Ulysses J Balis, and Frank Kuo. 2006. Devel- opment and ev aluation of an open source software tool for deidentification of pathology reports. BMC medical informatics and decision making , 6(1):1. [Berman2003] Jules J Berman. 2003. Concept-match medical data scrubbing: how pathology text can be used in research. Ar chives of pathology & labor atory medicine , 127(6):680–686. [Dernoncourt et al.2016] Franck Dernoncourt, Ji Y oung Lee, Ozlem Uzuner , and Peter Szolovits. 2016. De- identification of patient notes with recurrent neural networks. arXiv preprint . [DesRoches et al.2013] Catherine M DesRoches, Chantal W orzala, and Scott Bates. 2013. Some hospitals are falling behind in meeting meaningful use criteria and could be vulnerable to penalties in 2015. Health Affairs , 32(8):1355–1360. [Douglas et al.2004] Margaret Douglas, Gari Clifford, Andrew Reisner , George Moody , and Roger Mark. 2004. Computer-assisted de-identification of free text in the mimic ii database. In Computers in Car diology , 2004 , pages 341–344. IEEE. [Douglass et al.2005] Margaret Douglass, Gari Cliff ford, Andrew Reisner, W illiam Long, George Moody , and Roger Mark. 2005. De-identification algorithm for free-text nursing notes. In Computers in Cardiology , 2005 , pages 331–334. IEEE. [Fielstein et al.2004] Elliot M. Fielstein, Steven H. Brown, and Theodore Speroff. 2004. Algorithmic de- identification of V A medical exam te xt for HIP AA priv acy compliance: Preliminary findings. Medinfo , 1590. [Filannino and Nenadic2015] Michele Filannino and Goran Nenadic. 2015. T emporal expression extraction with extensi ve feature type selection and a posteriori label adjustment. Data & Knowledge Engineering , 100:19–33. [Friedlin and McDonald2008] Jeff Friedlin and Clement J McDonald. 2008. A software tool for removing patient identifying information from clinical documents. Journal of the American Medical Informatics Association , 15(5):601–610. [Goldberger et al.2000] Ary L Goldberger , Luis AN Amaral, Leon Glass, Jef frey M Hausdorf f, Plamen Ch Ivanov , Roger G Mark, Joseph E Mietus, George B Moody , Chung-Kang Peng, and H Eugene Stanley . 2000. Phys- iobank, physiotoolkit, and physionet components of a new research resource for complex physiologic signals. Cir culation , 101(23):e215–e220. [Guo et al.2006] Y ikun Guo, Robert Gaizauskas, Ian Roberts, George Demetriou, and Mark Hepple. 2006. Iden- tifying personal health information using support vector machines. In i2b2 workshop on challenges in natural language pr ocessing for clinical data , pages 10–11. [Gupta et al.2004] Dilip Gupta, Melissa Saul, and John Gilbertson. 2004. Ev aluation of a deidentification (De-Id) software engine to share pathology reports and clinical documents for research. American journal of clinical pathology , 121(2):176–186. [Hara2006] Kazuo Hara. 2006. Applying a SVM based chunker and a text classifier to the deid challenge. In i2b2 W orkshop on challenges in natural languag e pr ocessing for clinical data , pages 10–11. Am Med Inform Assoc. [Hochreiter and Schmidhuber1997] Sepp Hochreiter and J ¨ urgen Schmidhuber . 1997. Long short-term memory . Neural computation , 9(8):1735–1780. [Hsiao et al.2011] Chun-Ju Hsiao, Esther Hing, Thomas C Socey , and Bill Cai. 2011. Electronic health record systems and intent to apply for meaningful use incentives among office-based physician practices: United states, 2001–2011. system , 18(17.3):17–3. [Johnson et al.2016] Alistair EW Johnson, T om J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody , Peter Szolovits, Leo Anthony Celi, and Roger G Mark. 2016. Mimic-iii, a freely accessible critical care database. Scientific data , 3. [McCann2015] Erin McCann. 2015. EHR vendor marketshare and MU attestations by vendor . Healthcar e IT News . [Meystre et al.2010] Stephane M Meystre, F Jef frey Friedlin, Brett R South, Shuying Shen, and Matthew H Samore. 2010. Automatic de-identification of textual documents in the electronic health record: a revie w of recent research. BMC medical r esear ch methodology , 10(1):1. [Morrison et al.2009] Frances P Morrison, Li Li, Albert M Lai, and George Hripcsak. 2009. Repurposing the clinical record: can an existing natural language processing system de-identify clinical notes? Journal of the American Medical Informatics Association , 16(1):37–39. [Neamatullah et al.2008] Ishna Neamatullah, Marg aret Douglass, H Lehman Li-wei, Andrew Reisner , Mauricio V illarroel, W illiam J Long, Peter Szolovits, George B Moody , Roger G Mark, and Gari D Clif ford. 2008. Au- tomated de-identification of free-text medical records. BMC medical informatics and decision making , 8(1):1. [Office for Ci vil Rights2002] HHS Office for Ci vil Rights. 2002. Standards for priv acy of individually identifiable health information. final rule. F ederal Re gister , 67(157):53181. [Parker et al.2011] Robert Park er , David Graff, Junbo K ong, Ke Chen, and Kazuaki Maeda. 2011. English giga- word fifth edition, linguistic data consortium. T echnical report, T echnical Report. Linguistic Data Consortium, Philadelphia. [Pennington et al.2014] Jeffrey Pennington, Richard Socher , and Christopher D Manning. 2014. GloV e: global vectors for word representation. Pr oceedings of the Empiricial Methods in Natural Language Pr ocessing (EMNLP 2014) , 12:1532–1543. [Ruch et al.2000] Patrick Ruch, Robert H Baud, Anne-Marie Rassinoux, Pierrette Bouillon, and Gilbert Robert. 2000. Medical document anonymization with a semantic lexicon. In Pr oceedings of the AMIA Symposium , page 729. American Medical Informatics Association. [Saeed et al.2011] Mohammed Saeed, Mauricio V illarroel, Andrew T Reisner , Gari Clifford, Li-W ei Lehman, George Moody , Thomas Heldt, T in H Kyaw , Benjamin Moody , and Roger G Mark. 2011. Multiparameter intelligent monitoring in intensiv e care II (MIMIC-II): a public-access intensiv e care unit database. Critical car e medicine , 39(5):952. [South et al.2014] Brett R South, Danielle Mo wery , Y ing Suo, Jianwei Leng, ´ Oscar Ferr ´ andez, Stephane M Meystre, and W endy W Chapman. 2014. Evaluating the ef fects of machine pre-annotation and an interacti ve annotation interface on manual de-identification of clinical text. Journal of biomedical informatics , 50:162–172. [Stubbs et al.2015] Amber Stubbs, Christopher K otfila, and ¨ Ozlem Uzuner . 2015. Automated systems for the de- identification of longitudinal clinical narratives: Overvie w of 2014 i2b2/UTHealth shared task track 1. Journal of biomedical informatics , 58:S11–S19. [Sweeney1996] Latanya Sweeney . 1996. Replacing personally-identifying information in medical records, the Scrub system. In Pr oceedings of the AMIA annual fall symposium , page 333. American Medical Informatics Association. [Szarvas et al.2006] Gy ¨ orgy Szarvas, Rich ´ ard Farkas, and Andr ´ as Kocsor . 2006. A multilingual named entity recognition system using boosting and c4.5 decision tree learning algorithms. In Discovery Science , pages 267–278. Springer . [Thomas et al.2002] Sean M Thomas, Burke Mamlin, Gunther Schadow , and Clement McDonald. 2002. A suc- cessful technique for removing names in pathology reports using an augmented search and replace method. In Pr oceedings of the AMIA Symposium , page 777. American Medical Informatics Association. [Uzuner et al.2008] ¨ Ozlem Uzuner, T awanda C Sibanda, Y uan Luo, and Peter Szolovits. 2008. A de-identifier for medical discharge summaries. Artificial intelligence in medicine , 42(1):13–35. [Wright et al.2013] Adam Wright, Stanislav Henkin, Joshua Feblowitz, Allison B McCoy , David W Bates, and Dean F Sittig. 2013. Early results of the meaningful use program for electronic health records. New England Journal of Medicine , 368(8):779–780. [Y ang and Garibaldi2015] Hui Y ang and Jonathan M Garibaldi. 2015. Automatic detection of protected health information from clinic narrativ es. J ournal of biomedical informatics , 58:S30–S38.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment