KeystoneML: Optimizing Pipelines for Large-Scale Advanced Analytics
Modern advanced analytics applications make use of machine learning techniques and contain multiple steps of domain-specific and general-purpose processing with high resource requirements. We present KeystoneML, a system that captures and optimizes the end-to-end large-scale machine learning applications for high-throughput training in a distributed environment with a high-level API. This approach offers increased ease of use and higher performance over existing systems for large scale learning. We demonstrate the effectiveness of KeystoneML in achieving high quality statistical accuracy and scalable training using real world datasets in several domains. By optimizing execution KeystoneML achieves up to 15x training throughput over unoptimized execution on a real image classification application.
💡 Research Summary
KeystoneML addresses the growing need for end‑to‑end optimization of large‑scale machine‑learning pipelines, which typically consist of multiple stages such as preprocessing, feature extraction, dimensionality reduction, and model training. Existing systems either focus narrowly on a single stage (e.g., distributed linear algebra for model training) or require developers to manually stitch together disparate libraries, leading to error‑prone code and poor scalability when data volumes increase.
The authors introduce KeystoneML, a framework that provides a high‑level, type‑safe API built around two abstract operator classes: Transformer and Estimator. A Transformer is a deterministic, side‑effect‑free function that maps an input dataset to an output dataset (e.g., tokenization, PCA). An Estimator consumes a distributed dataset and produces a trained model encapsulated as a Transformer (e.g., LinearSolver). Pipelines are constructed by chaining these operators with andThen and can branch or merge using gather. This declarative representation yields a logical operator DAG that captures the full workflow.
Optimization occurs in two complementary layers.
-
Operator‑level cost‑based optimization: Each logical operator may have several physical implementations (e.g., exact linear solver, block‑wise solver, SGD, L‑BFGS). The system defines a cost model that splits the total cost into execution cost
c_execand coordination costc_coord. Both are functions of input statistics (sparsity, dimensionality, number of classes) and the cluster resource descriptor (CPU FLOP/s, memory bandwidth, network bandwidth, number of workers). By plugging in operator‑specific formulas (derived from parallel algorithm analysis) and cluster‑specific scaling factors (R_exec,R_coord), KeystoneML can predict the runtime of each candidate implementation and select the cheapest one. -
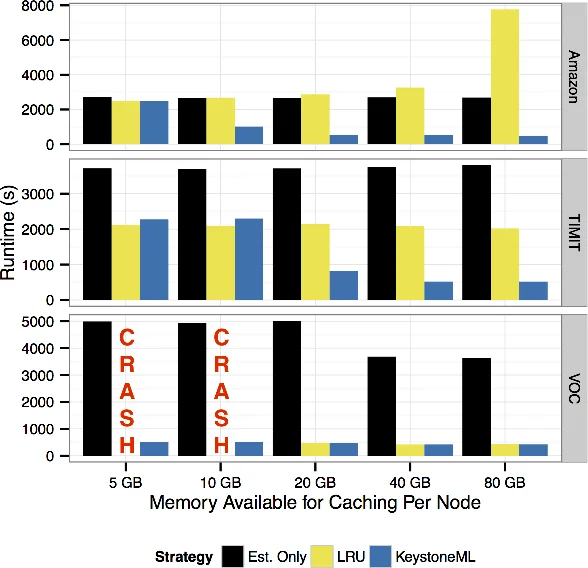
Pipeline‑level optimization: Because many ML operators are iterative and may be invoked multiple times over the same data, the system decides which intermediate results to materialize in memory. This decision is modeled as a subset‑selection problem: materializing a node incurs storage cost but can reduce downstream recomputation and network traffic. The authors propose a greedy algorithm that evaluates the marginal benefit of materializing each node based on the cost model, achieving near‑optimal performance in practice.
The paper presents a detailed cost analysis for three core linear‑solver families (exact QR, distributed QR, L‑BFGS, block solve) and shows how input characteristics (feature count, sparsity, number of passes) shift the optimal choice.
Empirical evaluation spans three domains:
- Image classification on a dataset of over one million images, using a pipeline that includes SIFT, Fisher vectors, and a linear classifier. KeystoneML attains up to 15× speedup over a naïve execution, demonstrates linear scalability across cluster sizes, and matches state‑of‑the‑art accuracy.
- Phoneme classification on speech data, where KeystoneML matches a specialized BlueGene implementation while using eight times fewer resources.
- Text sentiment analysis on Amazon reviews, illustrating that poor physical operator selection can cause up to a 260× slowdown, whereas KeystoneML’s optimizer consistently picks the best implementation.
Key contributions are: (1) a high‑level API that captures the full ML workflow; (2) a cost model that incorporates both algorithmic complexity and hardware characteristics, enabling automatic selection among multiple physical implementations; (3) a pipeline‑wide materialization strategy that reduces redundant computation; (4) extensive experiments demonstrating up to 15× speedup and near‑linear scaling on real‑world workloads; (5) open‑source release of the system, already adopted in scientific projects such as solar physics and genomics.
In summary, KeystoneML shows that principles from relational query optimization—cost‑based operator selection, common‑subexpression elimination, and whole‑query planning—can be successfully transplanted to the domain of large‑scale machine‑learning pipelines. By abstracting away low‑level details while retaining enough statistical metadata, the system delivers both developer productivity and substantial performance gains, paving the way for future extensions to heterogeneous accelerators, automated hyper‑parameter tuning, and online learning scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment