Hybrid clustering-classification neural network in the medical diagnostics of reactive arthritis
The hybrid clustering-classification neural network is proposed. This network allows increasing a quality of information processing under the condition of overlapping classes due to the rational choice of a learning rate parameter and introducing a s…
Authors: Yevgeniy Bodyanskiy, Olena Vynokurova, Volodymyr Savvo
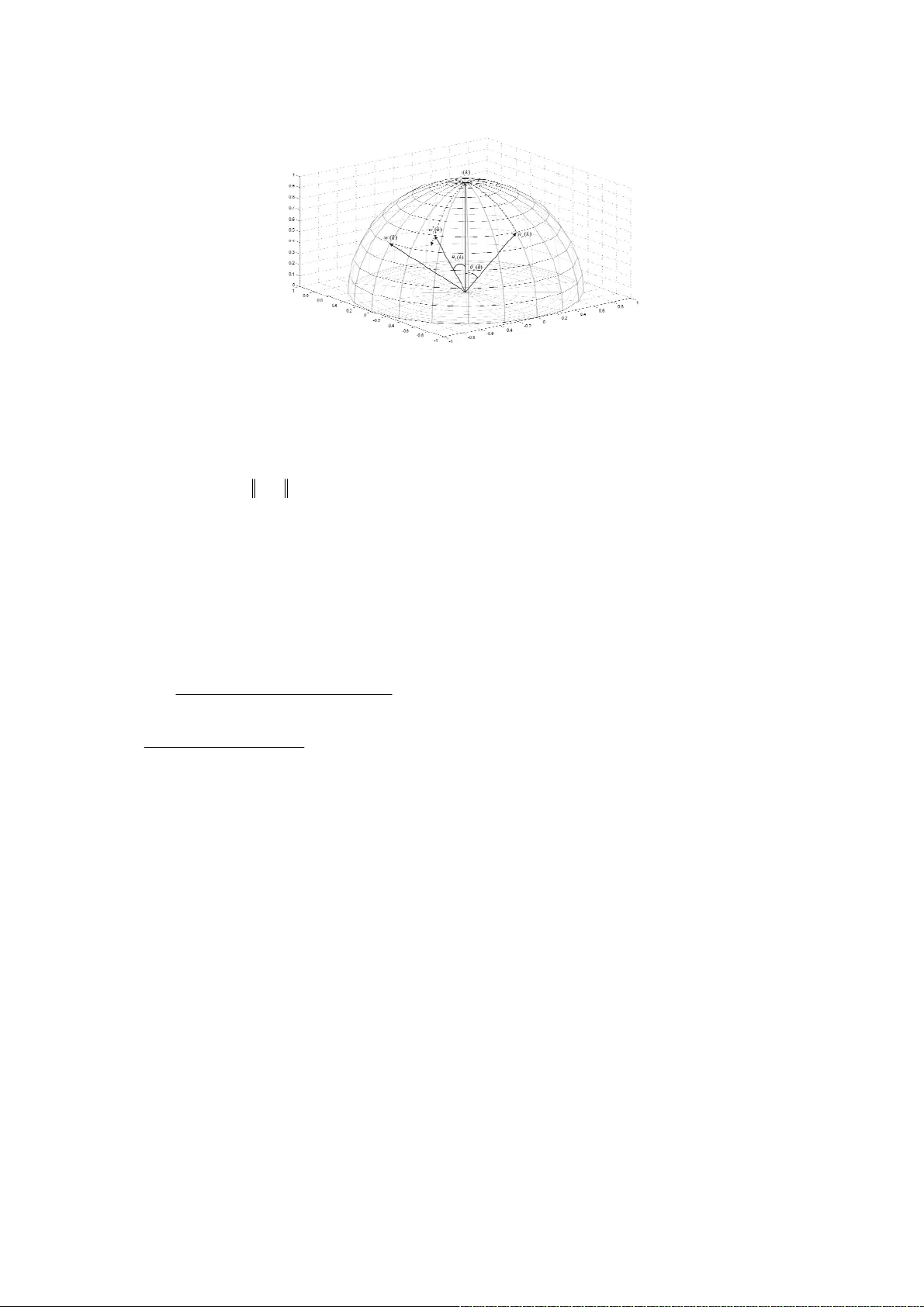
Hybrid clustering-classification neural network in the medical diagnostics of reactive arthritis Yevgeniy Bodyanskiy, Olena Vynokurova Control Systems Rese arch Laboratory, Kharkiv National University of Radio Electronics, Kharkiv, 61166, Ukraine Email: {yevgeniy.b odyanskiy, olen a.vynokurov a}@nure.ua Volodymyr Savvo, Tatiana Tverdokhlib Pediatrics Department, Kharki v Medical Academia of Post-Gra duate Education, Khar kiv, 61176, Ukraine Email: savvov m50@gmail. com, tanyamar 82@gmail.c om Pavlo Mulesa Cybernetics and Applied Mathematics Department, Uzhhorod National University, U zhhorod, 88000, Ukraine Email: ppmulesa@gmail.com Abstract — In the pape r, the hybri d clu ste ring-classification neural network is proposed. This network allows to increase a quality of information processing under the condition of overlapping classes due to the ration al choice of learning rate parameter and introducing special procedure of fuzzy reasoning in the clusteri n g-classification process, which occurs both with external lear ning signal (“supervised”), and without one (“ unsupervised”). As similarit y measure neighborhood function or membership one, cosi ne structures are used, which allow to provide a high flexibility du e to self-learnin g-learning process and to provide some new us eful properties. Many realized experi ments have confirmed the efficiency of proposed hybrid cluster ing-classification neural network ; also, this network was used for s olving diagnostics task of reactiv e arthritis. Index Terms — hybrid clustering ‐ classification ne ural network, supervised/unsupervise d learning, overlapping classes, diagnos tics , reactive arthritis. I. I NTRODUCTION Self-organizin g maps (SOM) and neural networks of l earning vect or quantization (LV Q) have seen extensi ve use for solving differe nt problem s in Data Minin g domain (cl ustering, classifi cation, fault detection and com pression of informat ion etc.). This t ype of neu ral networ ks was propose d by T. Koh onen [1, 2] a nd represe nts, in fact , a single-lay er feedforward architecture, which pr ovides an oper ator for ma pping of input spa ce into the out put spa ce. Operation- wise SOM and LVQ are quite similar to each neuron is fed i nput signal (sam ple) producing output, whi ch is used during competition stage to d etermine winning neuron – usually the one with max imum output signal value. Vector of synaptic weights for winn ing neuron is the one closest to the input sample in terms of th e metric chosen (which is Euclid ian metric in m ost cases). Next is neuro ns adjustm ent phase. Synaptic weights of the win ning neuro n gets moved close r to input sample. Alternatively, a subset of neurons (rather than a single one) can be adjust ed – those determ ined to be “reasonably close” to the input sample are updated. Resulting n etwork output, however, is determin ed exclusively by winning neu ron (this pri nciple is usua lly referre d to as “W inne r-Takes-All ” (WTA)). It is this principle (WTA) which negatively affects accuracy in case when there are overlapping clusters in underlying data . Taking into ac count the a bove ment ioned prope rties of SO M and LVQ networks, i t makes sense to introduce fuzzy classification capabilities on to p of them, while preserving onl ine operation. In [8, 9] fuzzy self-organizing map was proposed, i n which convent ional neuro ns are replaced by fuzzy rules. This ne ural net work shows eno ugh high efficiency, but its learning pr operties were s ignificant ly lost especially in on-line mode. In [5, 10, 11] fuzzy clustering Kohonen net work and fuzzy l inear vector quant ization netw ork are described. I n fact, such network s are neural representation of fuzzy c-m eans (FCM) [3], whic h is far enough fr om SOM and LVQ m athematical tool and designe d for operatio n in batch mode . II. P ROBLEM STATEMENT Let us conside r single-lay er neural net work wi th lateral c onnections containing receptor s and neuron s in the K ohonen layer with each neur on being characterized by a vector of its synaptic weights. Duri ng learning stage input vector is fed to the inputs of all neu rons (usually adaptive lin ear associ ators) (here - either the numbe r of o bservation in a ta ble “object-properties”, or cu rrent discrete tim e for on-line pr ocessing m ode) and neur ons produce t he scalar signal s on their outputs () ()() , 1 , 2 , . . . , T jj y kw k x k j m . (1) Note that neuron’s output depends on cur rent values of synaptic we ights vector, assum ing iterative learnin g algorithm. Each input vector can activate either singl e neuron ( j w ) or a set of neighb oring neur ons – this also depends on learning algori thm chose n. Self-organizati on procedure is based on t he competitive l earning appr oach (self-le arning) a nd begins wi th the initialization of synaptic weights. Selecting in itial values for weights from a uniform random distribu tion over input space has become a comm on practice. In addition, wei ghts ar e usually normalized to re side on unit hypersphere: 2 () () () 1 . T jj j wk w k wk (2) Self-organizing u sually contains three stages [2 ]: comp etition , cooperation, and synaptic adaptation. Th is paper introduces additional stage to th is process – fuzzy inference, which allows an online learning algorithm to classify d ata samples belonging to several classes sim ultaneously. III. L EARNING ALGORITHM FOR SOM The competition process is started to an alysis of current pa ttern () x k , which is fed to all neurons of Koh onen’s layer from receptive (zero) layer. For ea ch ne uron t he distance between input sample and a vector of synaptic weights is computed: (( ) , ( ) ) ( ) ( ) jj Dw k xk xk w k . (3) In case when all inputs and sy naptic weight s are norm alized according to (2), i.e. () () 1 , j wk x k (4) and Euclidian metric is used , the proximity measure between the vectors () j wk and () x k can be written in the following way: ()() () c o s ( () , () ) c o s () T jj j j w k xk y k w k xk k . (5) So the expressio n (3) takes the fo rm (( ) , ( ) ) 2 ( 1 ( ) ) jj Dw k xk y k . (6) Using relation (5), we can replace metric (3) with a sim p ler construction, usually referre d to as a measure of similarity [12] ( ( ), ( ) ) max 0, cos ( ) jj wk x k k , (7) which satisfies softer conditions co mpar ed to classic m easure requirements: (( ) , ( ) ) 0 , (( ) , ( ) ) 1 , (( ) , ( ) ) ( ) , ( ) . j jj jj wk x k wk wk w k xk xk w k (8) Next we look for a winning n euron that has a biggest value of sim ilarity to the inpu t vector in the sense (6) or (7), i. е . * ( ( ), ( )) min ( ( ), ( )) jl l Dw k x k Dw k xk (9) or * (( ) , ( ) )m a x ( ( ) , ( ) ) jl l w k xk w k xk . (10) After that, we tune values of s ynaptic we ig hts using WTA s elf-learning rul e in form ** if – th neuron won i n the com () () (() ( petition )), (1 ) () o t h e r w i , se . jj j j wk k x k wk wk w j k (11) In a nutshell, expression (11) means that synaptic weight s vector of winne r is moved clo ser to the input pattern () x k by a value which is proportional to learni ng rate 0( ) 1 k . Choice of learning rate value () k defines the convergence r ate of self-learning process, and is usually based o n empirical reasons, at that the paramete r must monotonically decrease in on tim e. It is easy to see, that first relation of the rule (11) minimizes the criterion 2 1 () j k k jj Ex w (12) (here j k is a number of data in the sampling with dimensions k , when j -th neuron was winn er), notably in practice as synaptic weights estimation conven tional arithm etic mean is used: 1 1 () ( ) j k j j wk x k . (13) Therefore, in fact, self-lear ning rule (3) is stochastic app roximation pr oce dure [13], and learning rate parame ter () k must be selected according to the conditions of А . Dvoretzky [14]. It is known that using the fo llowing value 1 () j k k (14) leads to slowdown of the learning process . Requirement of m onotonic decreasing of the parameter () k leads to expression in form 1 () () kr k , 2 () ( 1 ) () rk rk x k , 01 . (15) When taking into acc ount norm alization to unit hype rsphere (4) we have: () ( 1 ) 1 rk rk , (16) which with =1 gives a well-kn own expression, t hat was introduced in [ 15]. Changing the forg etting parameter provides enough var iance for the learni ng rate to both satisfy Dvoretz ky condition and adju st for characteristics of different data sets: 1 () 1 j k k . (17) Note that adjusting synaptic weights with (13) in gene ral breaks norm alization (4). In orde r to maintain it, we shoul d modify our lea rning algorithm : ** ** 1 if – neuron won in the com petitio n () () (() () ) , () () (() () ) (1 ) ( ) ( ) , () ( 1 , )1 , 0 1 , () , . jj jj j j wk k x k wk wk k x k wk wk k r k rk rk w k otherwis h e jt (18) In order to better adjust to input data , a so-called “cooperation stage” is frequently introduced to SOM learning process. During this stage, a winnin g neuron defines a local domain of topological nei ghborhood, where weights are adjusted for a set of neurons rather t h an only for a wi nning one. Those neurons cl oser to the winner receive a bigger adjustment. This topological dom ain is defi ned by neighbo rhood func tion (, ) jp , which depends on distance * (( ) , ( ) ) jp Dw k w k between winne r * () j wk and any of Kohonen’s layer n eurons () p wk , 1, 2 , , pm and some parameter , which sets its width. Usually (, ) jp is the bell-shap ed function, symmetrical with re spect to the maximum in point * () j wk ( (, ) 1 jj ) and decreasing when distance * (( ) , ( ) ) jp Dw k w k increases. Gaussian function is com monly use d here: 2 * 2 () () (, ) e x p 2 jp wk w k jp . (19) Adding neighborho od function results in the following learning algorithm: (1 ) ( ) ( ) ( , ) ( ( ) ( ) ) pp p wk wk k j p x k wk , (20) which minimizes criterion 2 1 (, ) () k k pp Ej p x w (21) This criterion is comm only referred to as “Winner Takes M ore” (WTM). The necessity to maintain norma lization to unit hypers phere (4) leads t o the expressi on in form 1 () () (, ) (( ) () ) (1 ) , () () (, ) (( ) () ) 1, 2 , , , () () , () ( 1 ) 1 , 0 1 . pp p pp wk k j p x p wk wk wk k j p x p wk pm kr k r k r k (22) It is possible to skip the entire competition by tuning synaptic we ights of network de pending on their sim ilarity with the current vector-pattern () x k . In this case instead of conventional neighb orhood functio n (, ) jp depending on winner * () j wk , we can use sim ilarity measure (7), that de pends on () x k . In this case instead of (20) we can use the rule in form: (1 ) ( ) () ( () , () ) (() () ) () () m a x0 , () (() () ) , pp pp pp p wk wk kw k x k x k w k wk k y k x k wk (23) which rem inds «INSTAR» le arning rule o f S. Grossber g [16]. For maintaining (4) the rule (23) has t o be rewritten in the form 1 () () ( () , () ) (() () ) (1 ) , () () ( () , () ) (() () ) () () , ( ) ( 1 ) 1 , 0 1 . pp p p pp p wk k wk x k x k wk wk wk k wk x k x k wk kr k r k r k (24) In many real world problems clusters can overlap as sh own on Fig. 1, where * denotes patterns, belonging to j - th clusters, and o – p - th ones. In this case vector () x k belongs j-th cluster with proportio nal m embership level cos ( ) j k , and with proportional level cos ( ) p k - to p- th one. Syna ptic weights conce n trated in crosshatched region, don’t have rela tionship to the pattern () x k according to (7). Fig. 1. The overlapping clusters Using similarity measure, tha t is shown on fig.2, we can introduce the member ship estim ate of pattern () x k to j- th class in form: () 1 (( ) , ( ) ) 0( ( ) ) 1 (( ) , ( ) ) j j wk m l l wk x k xk wk x k . (25) IV. L EARNING ALGORITHM FOR LVQ Learning vector quantization neural netw orks in contra st to self-learning SOM adjust their parameters based on external learning (reference) signal, wh ich fixes the membership of each pattern () x k to a particular class. The main idea of LV Q neural netw ork is to build a com pact represen tation of large data set based on a restr icted set of prototype sam ples (centroids) () j wk , 1, 2 , , jm , that provide sufficie ntly accurate approximat ion of the original space X . For each input vector () x k which is norm alized accordin g to (4), we loo k for a winning ne uron * () j wk that corresponds to a centroid of a certain class. In other words, winner is de fine d as a neuron with mi nimal distance to the input vector (9) or, which is the sam e, with maximal simila rity measure (10). Since the learning is supervised , membershi p of the vector () x k to specific domain j X of the space X is known, which allows considering two ty pical situations, which occ ur in the vector quantization: - the input vect or () x k and neuron-win ner * () j wk belong to the same cell of Voronoy [2]; - the input vect or () x k and neuron-win ner * () j wk belong to the di fferent cells of V oronoy. Than corresponding learning LV Q-rule can be written in form: ** * ** * () () (() () ) , if ( ) and ( ) bel on g to the sam e cel l, () () (() () ) , ( 1 ) i f ( ) and ( ) belon g t o the differen t cells, () f o r n e u r o n s , w hic h ar e n ' t w on in ins ta n t . jj j jj jj j wk k x k wk xk w k wk k x k wk wk x k wk wk k (26) The rule (26) has a clear physical inter pretation: if th e winning neuron and presen ted sample belong to the same class, than prototype * () j wk is moved t o () x k ; otherwise prot otype * () j wk is push ed away f rom () x k , effectively increasing the distance * (( ) , ( ) ) j Dw k xk , i.e. solving the m aximizati on task base d on criter ion (12). As for the choi ce of learning rate parameter () k , that com mon recomm endations a re th e same that for SOM, i.e. the learning rate param eter must monot onically decrease in pro cess controlled learning . In [17] it was pr oved that LVQ t uning a lgorithm converges in case of lear ning rate () k satisfies Dvoretzky conditions. This, in turn, allows choo sing () k according to Goodwi n-Ramadge-Cai nes algorithm [13], or in the previously defined form (16) with 1 , which is essentially the same. When 1 , the algorithm gets tracking properties and handles the case when class c entroids are drifting. For providing to fulfillment of the condition (4) it possible to introduce modification of rule (26) in the form (18): ** ** * ** ** * () () (() () ) , () () (() () ) if ( ) and ( ) belong to the same ce ll, () () (() () ) (1 ) , () () (() () ) f ( ) and ( ) belong to the diffe re nt cel ls, ( ) for neu ron s, wh jj jj j jj j jj j j wk k x k wk wk k x k wk xk w k wk k x k wk wk wk k x k wk ix k w k wk ich a r en o t w o ni ni n s t a n t . k (27) First and third expressions in formula (27) are completely iden tical to WTA – self-learning algorithm, which the second one represents a “push-bac k” scenario. Let’s consider a sit uation, shown in Fi g. 2, when neuron * () j wk won the competition. At the sam e time current sample () x k belongs to a class wit h different centroid () p wk . Now we need t o «push» vect or * () j wk away so, that () x k was equidista nt from * () j wk and from () p wk . Fig. 2. Learning of LVQ Applying elementary transformations , we get the following formulas: ** (1 ) ( ) ( ) ( ( ) ( ) ) jj j wk wk k x k wk , (28) 2 ** () ( 1 ) () () () () () () ( ) T j TT jj xk w k x kw k k x k k x kw k , (29) ** cos( ( 1 ), ( )) cos( ( ), ( )) ( )( 1 cos( ( ), ( ))) j jj wk x k wk x k k wk x k (30) In order to satisfy cos( ( 1 ), ( ) ) cos( ( ), ( ) ) jp w k xk w k xk (31) we need to set () k in form * * * * cos( ( ), ( )) cos( ( ), ( )) () cos( ( ), ( )) 1 () () () () . () () ()() jp j TT jp TT j wk x k w k x k k wk x k xk w k xk w k xk w k xk x k (32) After one step of t he weights t uning the patt ern () x k will belong equally to bo th (1 ) j wk and () ( 1 ) pp wk wk , i. е . (1 ) (1 ) (() ) (( ) ) 0 , 5 jp wk w k xk xk . (33) In case when several classes are ove rlapping, we can use estimat e (25) for computi ng membership le vels. V. H YBRID CLUSTERING - CLASSIFICA TION NEURAL NETWO RK WITH SUPERVIZ ED / UNSUPERVIZED LEAR ING A promising application of Kohonen neural network is adaptive pattern recognition , which implemented by th e systems. The implementation consists of sequentially connected SOM and LVQ [2] layers. First part o f network operates in self-learning mode, while the second on e adds supervised compon e nt to the process. From an input vector () x k which is fed to the input system, SOM network extracts a feature sample () yk in a space with sufficiently reduced dimens ionality. This simplifies a pr oblem in hand without significant loss of information. On the second st age LVQ is trained to classify of i ncoming patt ern () yk using supervised learni ng. A dist inctive feature of proposed system is the co nnection of two identical architectures, t hat are tune d by different learning algorithms. Learning algorithm 1 () xk 2 () xk () n xk M 1 k N 1 () yk 2 () yk () m yk 2 k N k m N w D {0 , 1 } L d = S g g g g g g 1 () k m 2 () k m () m k m M M M M e 1 () yk % 2 () yk % () m yk % Fig. 3. Architecture of hybrid cl u stering-classification neural network For many dat a mining pr oblem s, especially in healthca re domain, substantial shares of input samples lack clear class association. I ndeed, a diagn osis might be either missing, be ambiguo us or yet unkn own. In this case it is possible to tune the synaptic weights with unified architecture with lateral connections using different learni ng methods. E ach learning method is initiali zed according to the level of apriori information about () x k available. Fig. 3 shows the architect ure of hybrid cluste ring-classifica tion neural network. A resulting learning algorithm for combined (SOM+LVQ) ne ural network can be presen ted in the following form [18]: ** ** ** ** () () (() () ) , () () (() () ) () () (() () ) () , () () (() () ) 1 , if the networ k works in super vised mod e (1 ) and sample x(k) does not belong to class j , 0, o t h e jj jj jj L jj j L wk k x k wk wk k x k wk wk k x k wk k wk k x k wk wk rwise, ( ) for neurons, whi ch did not get acti vated by sample ( ). j wk xk (34) where * () j wk is winni ng neuro n. It is clear, that for 0 L , i. е . in self-lear ning mode , the first expressi on of form ula (34) can be replaced by expression (24). VI. RESULTS OF EXPERIMET Reactive arthritis (ReA) is the important medical-social pr oblem of today’s worl d beca use of high prevalence of ReA among people of different age grou ps. ReA occupies one of the to p position among inflamm atory disease of joints [19-2 1]. In different c ountries the freq uency of ReA equal to from 8% to 41%. According to some studi es, ReA is t he result o f overprod uction of proinflam matory cytok ines or un der ReA Th1 - immune res ponse is reduce d in favo r of Th2-i mmune res pon se [22, 23]. There are scien tific studies that prove the participation of cytokin es in the pathogen esis of rheuma tic diseases, the most common confirming the hypoth esis of the pathogenes is of ReA, which is base d on an im balance of cyt okines [24] . However, by now many researche r can’t establish reason s, which the infection process by the cau sative agent one in some indi viduals does n ot lead to medical pr oblem, whil e others l ead to the progress of in fectious and inflammatory diseases in the acute or chroni c form. The study invol ved 150 chil dren, includi ng imm unology research i n 40 pediatri c patients wi th ReA in acut e form and after 9-12 mont hs since the dawn of the disease. Immunologi cal research includes the st udy of measure of c ellular, hum oral, monocyte-phag ocytic compone nts of immune syst em, the content of cytokines ( IL-1 β , IL-6). In cellular c omponent of i mmune system the lym phocyte subpopulations was determined (CD3+, CD4+, CD8 +, CD25 , CD21). Det erminati on of serum im munoglobul in of classes A, M, G is performed by spectrophotometry. Monocyte-pha gocytic com ponent of im mune syst em was evaluat ed based on t he phagocyt ic and me tabolic activity of le ukocytes by determ ining the phag ocytic num ber, spontane ous and stim ulated NBT-te st. For estim ation of cytokine status in the ex amined patients the lev els of IL-1 β and IL-6 in serum is det ermined based on "sandwich"-met hod ELISA (enzym e linked imm unos orbe nt assay) using m onoclonal antibodies . Therefore the data set is pres ented by the t able “object-pro perties” consist s of 40 object s and 12 prope rties. The hybrid clustering-classification neural network with learni ng algorithm (34) was used for solving of diagno sis task of ReA based on imm unological indicators of pediatric pat ients. The initial va lues of synaptic weights were taken in a random way. As the criterion of clustering-classification we used the percent of incorrect classified patterns in test sample. The fig. 4 s hows the results of clusteri ng-classificat ion of data w hich describes imm unological indicat ors of pediatric patie nts with ReA . Fig. 4. Results of clust ering-cl assification dat a based on hybrid clust ering-cl assification net work ( ● – the cluster with prolonged, recrudescent and chronic form of ReA disease, ● – the cl uster with recovering patients after treatment, ● – the protot ypes of clusters) Table 1 shows t he comparative analysi s of clusterin g-classification res ults based o n four approache s: propose d network wit h its learnin g algorithm s, Kohone n self-orga nized map an d LVQ-neural net work wit h conventi onal learning algorithm and fuzzy C- means clustering algorithm . Analysis of clustering-classification results shows the fo rmi ng of two cluste r, which are characterized two group of pediatri c patients: group with prolonged, recrudescent an d chronic fo rm of ReA disease and gro up with recovering pati ents after proposed treat ment. The acute period of ReA in pedi atric patient s is character ized by the changes of im munological homeostasis in form reducin g of the relative conte nt of CD8, CD 25 in serum and increasing level s of CD21, IL- 6, the phagocyt ic number an d sponta neous NBT te st. Table 1. The comparative analysis of clustering-classification results Neural network / Learning m ethods Error of clustering- classification, train set Error of clustering- classification, check set Hybrid clusteri ng- classification neural network / Proposed learning algorithm 3.1 % 4.5 % Kohonen self -organized map / Conve ntional learning algorithm 6.9 % 8.0 % LVQ neural networ k / Conventional learning algorithm 7.9 % 8.5 % Fuzzy C-means clustering algorithm 6,8% 7,4% Therefore, it is apparent t hat propose d approach pr ovides best res ults of clust ering-classi fication am ong considered a pproaches d ue to operat ion in learni ng/self-lear ning mode under m issing of d iagnosis data l abeling or i n the case when the diagnosis was not made be cause of assident disease s of patients. Medical data mining result was d iagnosis task solving for defining of hidden factors of reactive arthritis progression in the ch ildren, which allowed for appropriate treat ment. VII. C ONCLUSIONS The combined self-lear ning procedure for Kohonen neural net work is propose d. Such method al lows data processing under the overlapping classes co ndition, when memberships of training d ata to specific classes can be unknown at al l, and have b oth crisp a nd fuzzy nature. This method is based on using sim ilarity m easure, recurrent optimization and fuzzy inference and diffe rs with high speed , possibility of operating in on-line mode and simplicity of computat ional realizat ion. Medical data mining resul t was diagnosis t ask solving fo r defining of hi dden factors of reactive arthritis progression in the childre n, which allowed for appropriate treatment. R EFERENCES [1]. T. Kohonen, Self-Organizing Maps . Berlin: Springer-Verlag, 1995. DOI: 10.1007/978-3-6 42- 56927-2 [2]. S. Haykin, Neural Ne tworks: A Comprehensive Foundation. Upper Saddle River, N. Y.: Prentice Hall, 1999. [3]. J.C. Bezdek, Pattern Recognition with Fuzzy Objective Function Algorithms . New York: Plenum Press, 1981. DOI: 10.100 7/978-1-4757-045 0-1 [4]. F. Hoeppner, T. Klawon, and R. Kruse, Fuzzy Clusteranalyse: Verfahren fuer die Belderkennung, Klassification und Datenanalyse. – Braunschweig: Vieweg, Reihe Computational Intelligence, 1996. DOI: 10.1007/97 8-3-322-86836- 7 [5]. J.C. Bezdek, J. Keller, R. Krisnapuram, and N. Pal, Fuzzy Models and Algorithms for Pattern Recognition and Image Processing . Springer, 1999. DOI: 10.1007/b106267 [6]. F. Hoeppner, F. Klawonn, R. Kruse, and T. Runkler, Fuzzy Cluster Analysis: Methods for Classification, Data Analysis and Image Recognition . Chichester: John Wiley & Sons, 1999. [7]. M. Sato-Ilic, and L. Jain, Innovations in Fuzzy Clustering: Theory and Applications . Berlin: Springer, 2006. DOI: 10.1007/3-54 0-34357-1 [8]. P. Vuorimaa, “Use of the fuzzy self-organizing map in pattern recognition”, in Proc. 3-rd IEEE Int. Conf. Fuzzy Systems “FUZZ-IEEE’94”, Orlando, USA, 1994, pp. 798-801. DOI: 10.1109/FUZZY.1994.343837 [9]. P. Vuorimaa, Fuzzy self-organizing map. Fuzzy Sets and S ystems, 1994, 66, pp. 223-231. DOI: 10.1016/0165-0114(94) 90312-3 [10]. E.C.-K. Tsao, J.C. Bezdek, and N.R. Pa l, “Fuzzy Kohonen clustering networks,” Pattern recognition, 1994, 27, pp. 757-764. DOI: 10. 1016/0031-3203( 94)90052-3 [11]. R.D. Pascual-Marqui, A.D. Pascual-Mont ano, K. Kochi, and J.M. Caraso “Smoothly distributed fuzzy C-means: a new self-organizing map,” Pattern Recognition, 2001, 34 , pp. 2395- 2402. DOI: 10.1016/S00 31-3203(00)00167-9 [12]. J.J. Sepkovski, “Quantified coefficients of association and measurement of similarity,” J. Int. Assoc. Math ., 1974, 6 (2), pp. 135-152. DOI: 1 0.1007/BF02080152 [13]. M.T. Wasan, Stochastic Approximation . Cambridge: The University Press, 2004. DOI: 10.1002/zamm.19700 500635 [14]. A. Dvoretzky, “Stochas tic approximation revisited,” Advances in Applied Mathematics , 1986, 7(2), pp. 220-227. DOI: 10.10 16/0196-8858(86)900 33-3 [15]. G.C. Goodwin, P.J. Ramadge, and P.E. Caines , “A globally convergent adaptive predictor,” Automatica , 1981, 17(1), pp. 135-1 40. DOI: 10.1016/000 5-1098(81)90089-3 [16]. S. Grossberg, “Classical and instru mental learning by neural ne tworks,” in: Progress in Theoretical Biology, N.Y.: Academic Press , 1974, 3, pp. 51-141. DOI: 10. 1007/978-94-00 9-7758-7_3 [17]. J.C. Baras, and A. La Vigna, “Convergence of the vectors in Kohonen’s learning vector quantization,” in Proc. International Neural Network Confere nce, San Diego, CA, 1990, pp. 1028- 1031. DOI: 10.1007/97 8-94-009-0643- 3_176 [18]. Ye. Bodyanskiy, P. Mulesa, O. Slipchenko , and O. Vynokurova, “Self-organizing map and its learning in the fuzzy clustering-classification tasks,” Bulletin of Lviv Polytechnic National University. Computer Science and Information T ech ology, Lviv: Publishing of Lviv polytechnic, 2014, 800, pp. 83-92. [19]. Т .V. Marushko, “Reactive arthropathy in children,” Heal th of Ukraine , 2012, 2, pp. 43-44. (In Ukrainian). [20]. V.M. Savvo, and Yu.V. Sorokolat, “Reactiv e arthritis in children, which connected with nasopharyngeal infection,” International Medical Journal , 2003, 9(2), pp. 128-131. (in Russian). [21]. T. Hannu, “Reactive arthritis,” Best Practice & Research Clinical Rheumat ology , 2011, 25, pp.347-357. DOI: 10.1016/j.berh.2011.01.018 [22]. C. Selmi, and M.E. Gershwin, “Diagnosis and classification of reactive arthritis,” Autoimmunity Reviews , 2014, 13, pp.546-549. DOI: 10.1016/j .autrev.2014.01.005 [23]. M. Rihl, A. Klos, L.Kohler, and J.G. Kuipers, “Reactive arthritis,” Best Practice & Research Clinical Rheumatology , 2006, 20(6), pp.1119-113 7. DOI: 10.1016/j.berh.2006.08. 008 [24]. P.S. Kim, T.L. Klausmeier, and D.P. Orr, “Reactive arthritis,” Journal of Adolescent Health , 2009, 44, pp. 309-315. D OI: 10.1016/j.jadohe alth.2008.12.007
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment