A Bayesian Approach to Estimation of Speaker Normalization Parameters
In this work, a Bayesian approach to speaker normalization is proposed to compensate for the degradation in performance of a speaker independent speech recognition system. The speaker normalization method proposed herein uses the technique of vocal t…
Authors: Dhananjay Ram, Debasis Kundu, Rajesh M. Hegde
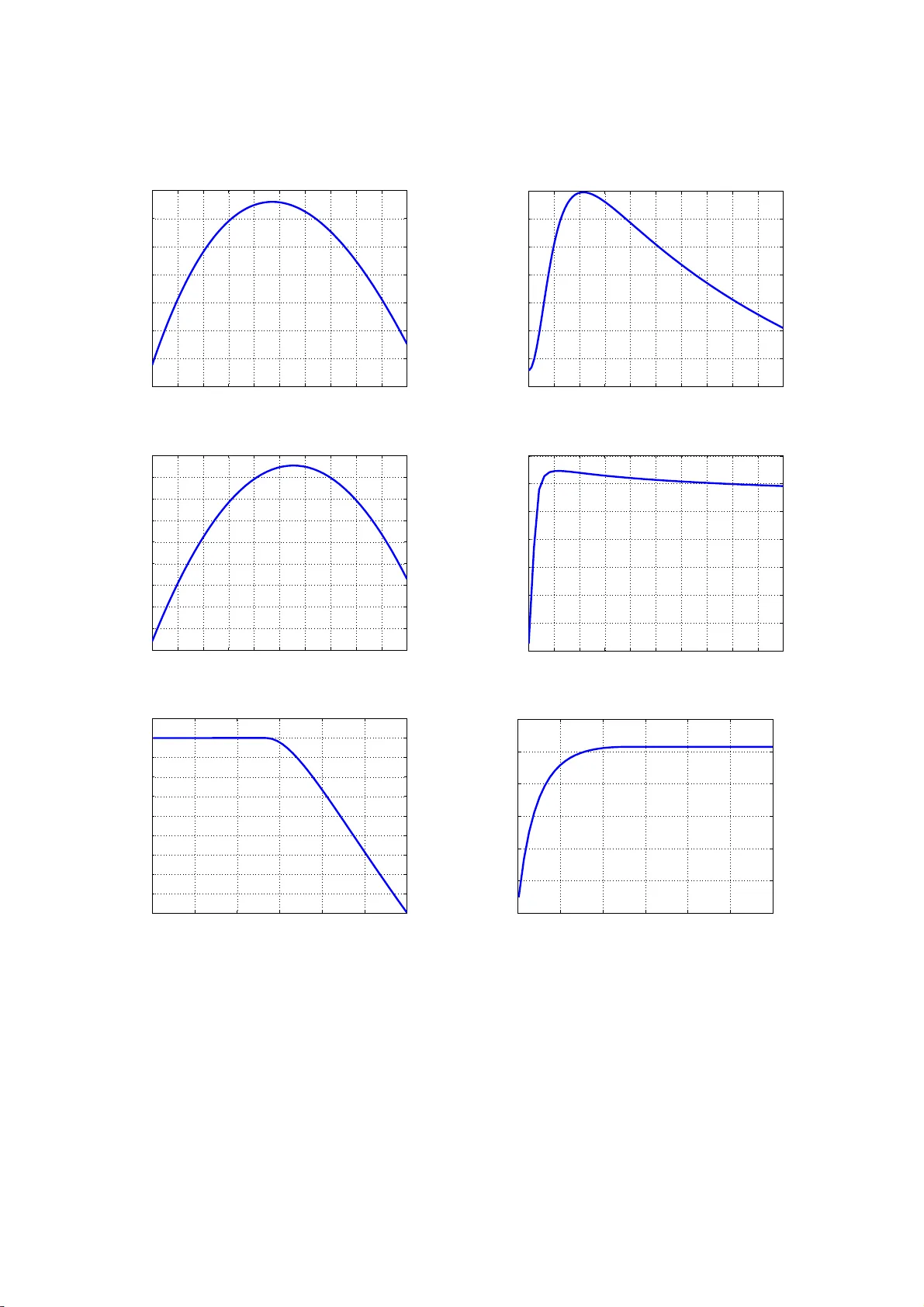
A Ba y esian Approac h to Estima tion of Sp eaker Nor maliza tion P arameter s Dhananjay Ram a,b, ∗ , Debasis K undu c , Ra jesh M. Hegde c dhananjay.r am@idiap.ch { kundu,rhe gde } @iitk.ac.in a Idiap R ese ar c h Institute, Martigny, Switzerland b Ec ole Polyte chnique F´ ed ´ er ale de L ausanne (EPFL), L ausann e, Switzerland c Indian Institute of T e c hnolo gy Kanpur, India Abstract In this work, a Bay esian approa ch to sp eaker norma lization is pro po sed to co mpens a te for the deg radation in performance of a sp eaker indep endent sp eech recognition s ystem. The sp eaker no rmalization metho d prop osed herein uses the technique of vocal tract length no r malization (VTLN). The VTLN parameters are estimated using a nov el Bayesian a pproach which utilizes the Gibbs sampler, a special t ype of Mar kov Chain Monte Car lo metho d. Additionally the h yp e rparameter s are e stimated using maxim um likeliho o d approach. This mo del is used a ssuming tha t h uman vo cal tr act can be modeled as a tub e of uniform cross section. It captures the v aria tion in length o f the voca l tract of different sp eakers more effectiv ely , than the linear model used in literature. The w ork has also inv estigated different metho ds like minimizatio n of Mean Square E r ror (MSE) and Mean Absolute Er ror (MAE) for the estimation of VTLN para meters. Both single pass and t wo pass appr o aches are then used to build a VTLN based sp eech recognizer . Exp erimental results on re c o gnition o f vow els and Hindi phrases fro m a medium vo c abulary indicate that the Bayesian metho d improv es the p er fo rmance by a consider able marg in. Keywor ds: Spea ker Normalizatio n, B ay e sian E stimation, V o cal T ract Length Normaliza tion (VTLN), Mean Squa re E rror (MSE), Mean Absolute Er r or (MAE), Hyp e r parameter s 1. In trodu ctio n One o f the bigg est challenges in the design of an automatic sp eech recognizer (ASR) is to comp ensate for the spea ker v ariability . It is caused b y the a coustic v ariations in tro duced in the sig nals of sa me uttera nce sp oken b y different sp eakers. In s pite of these a coustic v ariations, hu mans ca n recognize uttera nces o f different speakers very easily . But, speech reco gnizer cannot recognize same words uttered by different sp eakers very w ell due to these v aria tions (1). Different types o f sp eaker nor malization methods are used to enhance the recognition accuracy when differen t sp e akers are using same recog nizer (2; 3; 4). Many resear chers hav e approached the problem of no rmalization using only formants of vow e ls . Nordstrom and Lindblom (5) determined a constant sca le factor dep ending o n the ratio of third for mant of sub ject to that of r e ference s pea ker. Later, F ant (6) arg ued that unifor m sca ling is a very simple approximation, so the scale factor should b e dep endent on b oth vo wel category and fo r mant num b er. Then, Miller (7) a pplied formant r atio theo ry to normaliza tion problem, whic h cla ims that vo w els are relative patterns. A detaile d study of these vow e l normalizatio n pro cedures by Nicholas Flynn can b e found in (8). W arping functions ar e also used to reduce differences b etw een the s pec tr a of sub ject and reference sp eakers. Different type s of warping functions have b een used in past, namely L ine a r warping function (9), Piecewise Linear warping function (10), Affine warping function (11), Non- linear warping function (12) etc. ∗ Corresp onding author Pr eprint submitt ed to Elsevier July 3, 2021 Eide and Gish (13) hav e developed a warping function bas ed on the median p os ition of third formant in sp eech of the s p ea ker under consider ation. Stevens and V olkmann (14) have prop osed a non-linea r warping function based on their p erceptual studies on sp eech signa ls. The well known bilinear tra nsform is a lso us ed as a warping function in (15). A likelihoo d ma ximization technique of sp eaker nor malization is pro po sed in (2). In this metho d, warping fa c tor for a particular speaker is chosen by ma ximizing the lik elihoo d of a hypothesis in an iterative manner at the output of a recognizer . In (10), Gaussian Mixture Mo del is used to repres e n t a class of standard speakers. The c lasses a r e a ssigned warping fa ctors from a set of v alues. Different sp eaker are a ssigned to o ne of these cla sses using likeliho o d ma x imization. Lee and Rose (9) hav e prop osed a similar metho d. But, they hav e used maximization of likeliho o d of the Hidden Mar ko v Mo del (HMM) for no rmalization as well as reco gnition. Res e archers have a lso used no r malization in the feature domain. Acero and Ster n (15) hav e prop osed an affine transfor mation of the ce ps tral features . Cox (16) has shown that vocal tr a ct length no rmalization (VTLN) can be implement ed with filter banks and dir e ctly applied this metho d in the feature do main. Later in (17 ), a linear tra nsformation appr oach using Dynamic F requency W a rping (DFW) ha s b een pro p o s ed for no rmalization. In this pa per an a ffine mo del based sp eaker normaliz a tion metho d is present ed. The mo del para meters are estimated using Bay esian estimation as w ell as error function minimization technique. This work justifies the use o f Bay esian metho d of par ameter estimation, whic h is also suppo r ted by the exp er imental results. T echniques like bandwidth a djustmen t a nd frequency bin adjustmen t a re discussed which are r equired for the application of sp eaker nor malization in the sp eech r ecognizer . The rest of the pa per is org anized as follows. Section 2 descr ib es the mode l and err or function minimization technique is used to estimate the mo del parameters . Section 3 prop o ses B ay e sian estimation method to estimate the affine mo del parameters. The need of hyperpar ameters estimation is also discus sed in this Sectio n and the hyperpar ameters are estimated using likeliho o d maximization. Section 4 presents F o rmant frequency based vo wel recog niz e r a nd HMM based sp eech recognizer, and exp erimental condition to p er form different t ypes of exp eriments on these recognizer s. The inco rp oratio n of nor malization metho d with r ecognizer for training as well as testing o n a database is descr ibe d using blo c k dia grams. E xp erimental results for b oth vow el as well as word reco gnition are shown in the same Section. Finally , conclus ions a re presented in Section 5. 2. Sp eak er Normalization using F requency W arping An a ffine mo del (18) for spea ker normalizatio n is introduced in this section. The mo del parameters, α and κ are estima ted using principle of Er ror F unction Minimiza tion. How ever it is found that, for a ra nge o f v alues of α , es timated v a lue of κ is no t reliable . An adjustment technique is sug gested for estimated v alues of par ameters to get more relia ble estimates. 2.1. Affine Mo del for V o c al T r act L ength Normalization The affine mo del used fo r sp ea ker norma lization in an earlier work (1 8 ) is given by Y = α X + κ ( α − 1) 1 (1) where, the vectors, Y and X represent the formant fr e quency v ector for reference and sub ject sp eakers resp ectively . F ormant fr equency vector is c onstructed by concatenating for ma nt s of a ll uttera nce s corr e - sp onding to a particular sp eaker. So, leng th of this vector dep ends on the database under consider a tion. α a nd κ are resp ectively , the sp eaker dep endent and independent para meters. 1 is a vector of 1s, i.e. 1 = [1 1 ..... 1] T . The dimension o f 1 is sa me as the dimension of Y or X . It can be eas ily seen fro m Figure 1, that the a ffine mo del ha s a shift factor in addition to the s caling factor used in the po pular linea r mo del for VTLN. The linear w arping function alwa y s pas s es thro ug h the origin, whereas the affine warp function pa sses through the o rigin only for α = 1. In other cases, it has a po sitive in tercept fo r α > 1 and nega tiv e intercept for α < 1. T he w arp ed sp ectr um g ets s hifted due to non-zero intercept o f the normaliza tion function. The shift is tow ards right or left fo r v alues of α grea ter than 1 o r less than 1 resp ectively . 2 0 1 2 3 4 5 6 7 8 0 1 2 3 4 5 6 7 8 Unwarped Frequency (KHz) Warped Frequency (KHz) α >1 α =1 α <1 (a) Linear Mo del 0 1 2 3 4 5 6 7 8 0 1 2 3 4 5 6 7 8 Unwarped Frequency (KHz) Warped Frequency (KHz) α >1 α =1 α <1 (b) Affine Mo del Figure 1: Comparison of wa rping f unctions for different v alues of α and constant κ The shift factor in Equation (1) is not same for different s ub j ect spea kers. But, the num b er of par ameters has no t b een doubled to achiev e this, co mpared to the n um ber of pa rameters in the linear model. It is achiev ed simply b y mak ing the shift factor , a function o f the sp ea ker dep e ndent s caling factor . In this wa y , the increase in the num ber o f pa rameters is only one, but a n e ffect o f a s many parameter s as the num b er o f sp eakers ha s b een achiev ed. Th us, a lesser accurate mo del is obtained compared to the scenario when the shift factors ar e also sp eaker dep endent . It is implemented to keep a chec k on the n um ber of parameter s to b e estimated, which effectively re duces computational complexity o f the system. This s a me affine mo del was us ed in (18). But, the authors hav e used it to come up w ith a universal warping function ha ving the same pa rametric for m as the mel scale. 0 500 1000 1500 2000 2500 3000 3500 4000 0 5 10 15 20 25 30 35 40 45 Frequency (Hz) Magnitude (dB) Subject Speaker Reference Speaker Normalized Subject(Linear) Normalized Subject(Affine) Figure 2: Normalization of s pectrum of the vo w el ‘ ae’ Figure 2 shows four different LP C smo othed sp ectra o f same vo wel, ‘a e ’. In this figure, t wo s pectr a repre- sent utterances by a sub ject sp eaker and a reference sp eaker, whereas the o ther tw o sp ectra ar e nor malized sp ectra of the sub ject spea ker to make it c lo ser to the reference s pea ker in terms of formant pea ks. The t wo normalized sp ectra are obtained using popular ly use d linear mo del and an a ffine mo del resp ectively . 3 The first and second formant fre quency v alues are giv en in T able 1 . In this table, v alues in first row shows formants of r eference sp eaker. The following r ows indicate for mant of normalized s p ectr a of sub ject sp ea ker using linea r a nd affine mo del, resp ectively . T able 1: T able Showing Fi r st Two F ormant F requencies of Spectra Present ed i n Figure 2 Normalization F unction F orman t F requency First F ormant (Hz) Second F orman t (Hz) Reference 750 1970 Sub j ect 600 1760 Linear F unction 678 2000 Affine F unction 735 1960 The for ma nt frequency v alues of nor malized sp ectra clearly s how that, affine mo del gives a b etter match compared to the linear mo del, in terms of formant frequencies. 2.2. Affine Mo del Par ameter Estimation u sing Err or F unct ion Minimization T e chnique An error function minimizatio n technique is used for estimating the par a meters α and κ o f the affine mo del mentioned ea rlier. The mo del ca n b e written as Y = α X + κ ( α − 1) 1 + ǫ (2) where, ǫ is the error vector. The estimated fo r mant frequency vector after applying thes e par a meters on X is b Y = α X + κ ( α − 1) 1 (3) The parameter κ is assumed to be sp eaker dep endent. Then, the estimated formant frequency vector can be w r itten as b Y ij = α ij X j + κ ij ( α ij − 1) 1 (4) where α ij and κ ij are the parameters for the j -th sub ject s pea ker with r esp ect to i -th refer ence sp eaker. The ab ov e E quation (4), when av eraged ov er all the reference sp eakers gives the following b Y j = α j X j + κ j ( α j − 1) 1 (5) Now, the para meters, κ ij and α ij in Equation (4 ) are estima ted by consider ing every p ossible pair o f sub ject and reference spe a ker and minimizing a n error function. Mea n Squar e Error (MSE) a nd Mean Absolute Er ror (MAE) have b een used as erro r functions. In MSE, the er r or function to b e minimized is ǫ ij = ( Y ij − b Y ij ) T ( Y ij − b Y ij ) = ( Y ij − α ij X j + κ ij ( α ij − 1) 1 ) T ( Y ij − α ij X j + κ ij ( α ij − 1) 1 ) (6) In MAE, the err or function to b e minimized is ǫ ij = | Y ij − b Y ij | T 1 = | Y ij − α ij X j + κ ij ( α ij − 1) 1 | T 1 (7) where, the op erator | ∗ | gives element-wise absolute v alue of corr esp onding vector. Two different estimates of κ ij and α ij are obtained by minimizing Eq ua tions (6) a nd (7). F o r ea ch of the ab ov e mentioned functions, joint optimizatio n ha s b een used for estimating κ ij and α ij . Nelder-Mead metho d (19) is implemented to minimize b oth E quations (6) a nd (7). This is a well defined numerical metho d for pro blem for which 4 0.7 0.8 0.9 1 1.1 1.2 1.3 −2000 −1500 −1000 −500 0 500 1000 1500 2000 2500 3000 3500 Estimated α Estimated κ Figure 3: Illustration of lar ge v ariability of κ near α = 1 deriv atives ma y not b e known. Now, it is assumed that, there are m sub ject spea kers a nd n reference sp eakers. So, the av erage estimated formant freq uency vector fo r the j -th s ub j ect sp eaker will b e b Y j = 1 n n X i =1 α ij ! X j + 1 n n X i =1 κ ij ( α ij − 1) ! 1 (8) Now, co mparison of Equatio ns (5) and (8) g ives the following, α j = 1 n n X i =1 α ij (9) κ j = n X i =1 κ ij ( α ij − 1) n X i =1 ( α ij − 1) (10) The shift fa c tor, κ for the entire databa se is obtained by averaging κ j ov er a ll the sub ject sp ea kers κ = 1 m m X j =1 κ j (11) An ardent o bserv a tio n of Eq uation (1) indica tes that, for α = 1, κ can take any v alue from − ∞ to + ∞ . Hence, κ cannot b e estimated reliably . Also, the estimated v a lue s of κ s how a great a mount of v a riance for v alues of α close to 1. Figure 3 shows the v ar iation of estimated κ with cor resp onding estimates of α . In other words, estimated v alues of κ are also not relia ble for the v alues of α ne a r 1. An outlier adjustment techn iques is applied to deal with this problem. An outlier is defined as an estimated v alue that deviates markedly from other estimated v a lues o f a parameter. In this metho d, a ra nge of [0 , L ] is chosen for estima ted κ ij , for i -th reference s pea ker and j -th sub ject sp eaker. The following expressio n is used to adjust the v alues of κ ij to the bo undary . κ ij = max (0 , min ( κ ij , L )) (12) The adjusted v alues for κ ij are 0 and L for κ ij < 0 and κ ij > L res pectively . The outlier a djustment techn ique discussed her e is a n e mpir ical method bas ed o n o bserv a tions. No te that, the MMSE estimation and corr esp onding o utlier adjustment technique ha s b een prop osed in (18), whereas the MMAE estimation techn ique is prop osed in this pap er. This technique has b een s uccessfully applied in (18) with affine mo del. The same metho d is a pplied he r e in order to compa re its results with the pr op osed Bay esian metho d. Also, the results in Section 4 show that, this metho d improv es p erfo rmance o f vo w el recogniz e r for gender 5 depe ndent no rmalization in mo s t cases but not for all. Now, the alg o rithm to ev aluate affine model parameter s using erro r function minimization tec hnique is given b elow. Algorithm 1 Estimation of Parameter s α and κ using MMSE and MMAE 1: F orman t F requency V ectors : F ormant frequencies a r e extr acted (20) from all utterances to cons truct fromant fr equency vector for sub ject sp eaker ( X ) and referenc e sp eaker ( Y ). 2: Error function : MSE a nd MAE for i -th r eference sp eaker a nd j -th sub ject are constructed as shown in Equations (6) a nd (7) resp ectively . 3: Estimation of α ij and κ ij : α ij and κ ij are estimated b y minimizing Equations (6) and (7) suing Nelder-Mead metho d. These er ror functions g ive tw o different es tima te of the same para meter . 4: Final α : Fina lly , α j for j -th sub ject s pea ker is obta ined by av eraging α ij ov er a ll refer ence sp eakers. 5: Outlier adjustment for κ ij : If κ ij v alues ar e outside a given rang e [0 , L ], its v alues a re adjusted to this range using Eq uation (12). 6: Final κ : First κ j is calculated using E quation (1 0) and then, it is a v eraged ov er all sub ject sp ea kers to obta in fina l κ for the databas e. MMSE a nd MMAE es timation techniques hav e be e n used in this section to estimate the affine mo del parameters . B ut, these technique require κ to be sp eaker dep enden t, which is essentially opp osite to the premise of the mo del, where it is assumed to b e sp eaker independent. Also, the huge v a riance of κ is controlled using an o utlier a djustment technique, in which the adjustment rang e may change dep ending on the databa se. In order to ov ercome these proble ms , Bayesian estimatio n metho d is prop os ed in the following section. 3. Ba y esi an Approac h to Esti mation of Affine Mo del P arameters In this section, Bay esian E stimation ha s bee n in tro duced for estimating the par ameters. First, the motiv ation behind using the Bay es ian estimation is discussed. The mo tiv ation is follo wed by a n elab ora te mathematical descr iption of Bay esian estimation technique for the problem at hand. Additionally , Gibbs sampler is us ed for n umerical estimation of the mo del parameter s. Subsequently , maximum likeliho o d estimation technique is used to estimate hyper parameters of the mo del. 3.1. Motivation The propos ed B ayesian metho d for affine mo del para meter estimation is broadly motiv a ted b y the fol- lowing obse r v ations, • The sp eaker indep enden t par a meter κ of the affine mo del describ ed in Sec tion 2.1 is not estima ble under the frequentist set-up, if true v alue of α = 1. E ven if α 6 = 1 but very close to 1, which is usually the case in pr actice, the le a st square s estimate or the max im um likelihoo d estimate (under the assumption of Gaussian error) o f α beco mes very unr eliable. It has b een observed in the simulation study presented in Figure 3 that the v ariance of the estimator of κ is v ery high in such a situa tion. • On the o ther hand under in Bay esian framework, bec ause of the random nature of α , κ is alwa ys estimable. Since in pr actice α is very clo s e to 1, if we can use our prior k nowledge on α , very relia ble Bay es estimate o f κ ca n b e obtaine d. Even if we do not have any prio r knowledge of α , the da ta driven prior works muc h b etter than the usua l least squar es or maximum likeliho o d es tima tor. • Also, there is no need to assume κ to b e sp e aker dep endent and av erage out ov er a ll sp eakers to obtain fina l estimate of κ , whic h is spea ker indep endent. It c an b e seen later in this section that, the indep endence prop erty of κ is preserved in the Bayesian framework and the larg e v aria nce of κ is reduced in its fina l e stimate. Since, now a days mo dern B ayesian technique like MCMC (21) is a v ailable, in this case Ba y esian inference seems to b e the obvious choice. 6 3.2. Bayesian Estimation T e chnique The mo del parameters are conside r ed to b e ra ndom v ariables for using Bay esian Estimation (22 ) metho d. These ra ndom v ariables ar e assumed to follow a distribution depending on prior k nowledge ab o ut the parameter and hence these are ca lled calle d the prio r distribution. Thereup on the p os terior distr ibutions for mo del parameter s ar e derived using prior distributions and the observed data. The parameter s corresp onding to the prior distributions are called h y per parameters . The h yper parameters ar e estimated first in order to obtain b etter estimate for mo del par ameters. Different kinds of es timates can b e obtained using the p osterior distribution dep ending the lo s s function under co nsideration. The affine mo del for i - th reference sp eaker and a fixed sub ject sp eaker is giv en by Y i = α i X + κ ( α i − 1) 1 + ǫ i (13) where, ǫ i is the error vector. It is assumed to be a m ultiv ariate ga ussian with ze ro mean i.e. ǫ i ∼ N r ( 0 , σ 2 I r , r ). Here, r is the length of formant freq uency vector o f a sp ea ker in the database, 0 is a v ector of zero s of length r and I r , r is an ident ity matrix of siz e ( r × r ). F rom the ab ov e Equation, the mean and v aria nce of Y i can b e calc ulated as µ i = E ( Y i ) = α i X + κ ( α i − 1) 1 (14) Σ Y i = σ 2 I r , r (15) Using Equations (14) a nd (1 5) the pro bability density function of Y i can b e written a s f y ( Y i | κ, α i , σ ) = 1 (2 π σ 2 ) r / 2 e − ( Y i − µ i ) T ( Y i − µ i ) 2 σ 2 (16) Now, the prior distribution of κ is a ssumed to b e Gaussian i.e. κ ∼ N ( a, b 2 ). The c o nditional p osterior distribution o f κ , obtained using Bayes’ rule is given b elow, f κ ( κ | α , Y , σ ) = 1 p 2 π σ 2 κ e − ( κ − µ κ ) 2 2 σ 2 κ (17) where, µ κ = a b 2 + 1 σ 2 P n i =1 ( α i − 1)( Y i − α i X ) . 1 r σ 2 P n i =1 ( α i − 1) 2 + 1 b 2 , σ 2 κ = 1 r σ 2 P n i =1 ( α i − 1) 2 + 1 b 2 Y = ( Y 1 , Y 2 , . . . , Y n ) and α = ( α 1 , α 2 , . . . , α n ) The deriv ation of E quation (17) is given in App endix .1. Now, it is very clear fro m the expression of σ 2 κ that, σ κ ≤ b . The eq uality holds only when α i = 1. So, the v a riance of the pr ior distribution of κ is r educed in its p osterio r distribution. The prior distribution of α i is also a ssumed to be Gaussian i.e. α i ∼ N ( c, d 2 ). So, the conditional po sterior dis tribution of α i is given by , f α ( α i | κ, Y i , σ ) = 1 p 2 π σ 2 α i e − ( α i − µ α i ) 2 2 σ 2 α i (18) where, µ α i = X T Y i + κ ( X + Y i ) 1 + rκ 2 σ 2 + c d 2 1 d 2 + X T X +2 κ X T 1 + rκ 2 σ 2 , σ 2 α i = 1 1 d 2 + X T X +2 κ X T 1 + rκ 2 σ 2 The deriv atio n of Eq uation (1 8) is g iven in App endix .2. Now, σ is ass umed to b e uniformly distributed i.e. σ ∼ U ( θ 1 , θ 2 ), its conditiona l p osterio r distribution is given by , 7 f σ ( σ | κ, α , Y ) = e − 1 2 σ 2 P n i =1 ( Y i − µ i ) T ( Y i − µ i ) σ nr R θ 2 θ 1 e − 1 2 σ 2 P n i =1 ( Y i − µ i ) T ( Y i − µ i ) σ nr dσ (19) where, σ ∈ ( θ 1 , θ 2 ) a nd µ i is given in Eq uation (14). The denominator in the r ig ht hand side of Equa tion (19) can further b e so lved a s the following, Z θ 2 θ 1 e − β σ 2 σ nr dσ = 1 2 β nr − 1 2 γ (1 − γ l − γ u ) (20) where, β , γ , γ l and γ u are given as follows, β = 1 2 n X i =1 ( Y i − µ i ) T ( Y i − µ i ) , γ = Γ nr − 1 2 γ l = Γ low er β θ 2 2 , nr − 1 2 , γ u = Γ upper β θ 1 2 , nr − 1 2 The deriv ation of Equations (19 ) and (20) is pres e nted in App endix .3. Now, consider Ω to b e vector of all the mo del par ameters and Θ to b e vector o f a ll hyperpa rameters i.e. Ω = ( κ, σ, α ) , Θ = ( a, b, c, d, θ 1 , θ 2 ) The joint distribution o f α , κ and σ is g iven by , f (Ω | Θ , Y ) = f 1 ( κ | Θ κ ) f 2 ( σ | Θ σ ) n Y i =1 f y ( Y i | κ, α i , σ ) f 1 ( α i | Θ α ) (21) where, Θ κ = ( a, b ) , Θ α = ( c, d ) , Θ σ = ( θ 1 , θ 2 ) f 1 ( x | m, s ) = 1 √ 2 π s 2 e − ( x − m ) 2 2 s 2 , f 2 ( σ | θ 1 , θ 2 ) = 1 θ 2 − θ 1 Thu s, the joint dis tr ibution as well a s the conditiona l poster ior distributions are obta ined. But, the joint po sterior dis tribution of a ll parameters a re r equired to o btain the Bay es estimates. Even if the joint p oster ior distribution is ev a luated, it will b e very difficult to compute ma rginal p oster ior distributions from the joint distribution, b eca us e it will inv olv e three dimensiona l integration. One alterna tive solution can b e to s imulate the mar g inal p osterio r distributions from the condition p osterio r distributions. Gibbs Sa mpler is used in this work to simulate the distributions. The following sec tio n introduces the Gibbs Sa mpler and discusses the framework of its applicatio n on mo del par ameter estimation. It should b e noted that the final Bayes estimate dep ends on the lo s s function (22) under consideration, e.g . for s quare error loss function the final estimate is given by mean of the distribution, whereas, a ny median of the distr ibution is the final estimate for a bsolute er ror loss function. In this pap er, square err or loss function is considered fo r all e xpe r iment s. 3.3. Mo del Par ameter Estimation using Gibbs Sampler Gibbs sampler (21) is a Ma r ko v Chain Monte Carlo (MCMC) algo rithm which is used to obta in a s equence of obse rv ations from a sp ecified probability distribution. In this a pproach, previous sample v a lue is used to generate ne x t sample in the seque nc e , which constructs a Mar kov Chain. The samples of this Marko v Chain conv erge to the r equired distribution by co nstruction. F or exa mple, supp ose a biv ar iate r andom v a riable ( x, y ) is consider ed, and one wishes to compute the marg inals, p ( x ) and p ( y ). It is far easier to consider a sequence of co nditio na l distributions, p ( x | y ) and p ( y | x ), than it is to obtain the marginals by integration of 8 the jo in t density p ( x, y ), i.e. p ( x ) = Z D y p ( x, y ) dy and p ( y ) = Z D x p ( x, y ) dx where, D x and D y are the domains o f x and y resp ectively . The sampler starts with some initia l v alue y 0 for y and obtains x 1 by generating a random sample from the conditional distribution p ( x | y = y 0 ). The sampler then uses x 1 to generate a new v alue o f y 1 , drawing from the conditiona l distribution p ( y | x = x 1 ). The sampler pro ceeds a s follows x i ∼ p ( x | y = y i − 1 ) , y i ∼ p ( y | x = x i ) Repe a ting this pro c ess N times, generates a Gibbs sequence of length N. First n ( < N ) terms ar e rejected to remo ve the effect o f initial guess y 0 . This Gibbs sequence co n verges to a stationary dis tr ibution tha t is independent of the starting v alues , and by construction, this stationar y distr ibutio n is the target distribution which is b eing simulated. i.e, x ∼ p ( x ) and y ∼ p ( y ). Also , the exp ectation of any function g of the ra ndom v aria ble x ca n b e approximated in a simila r manner. Using the Law of Larg e Numbers, expected v alues of x a nd g ( x ) can b e appr oximated as follows 1 N − n N X i = n +1 x i P − → E ( x ) (22) 1 N − n N X i = n +1 g ( x i ) P − → E [ g ( x )] (23) as N → ∞ for some large n . So, the estimates are o btained by taking average of the generated samples. 3.3.1. Algo rithm for Mo del Par ameter Estimation using Gibbs Sampler The steps inv o lved in calculation of the exp ected v alue of pa rameters of the a ffine mo del us ing Gibbs Sampler a re enumerated in Algor ithm 1. Algorithm 2 Parameter E stimation us ing Gibbs Sampler 1: P o s terior Distributions : The p os terior dis tributions of κ ∼ f κ ( κ | α 1 , . . . , α n , σ , Y ), α i ∼ f α ( α i | κ, σ , Y i ) and σ ∼ f σ ( σ | α 1 , . . . , α n , κ, Y ) are consider ed as given in Equations (17), (18) a nd (19) r esp ectively . 2: Initial Guess : Initial gues s is ma de for κ and σ as κ = κ (0) and σ = σ (0) 3: Sampling of α : The j-th sa mple o f α i , i.e. α ( j ) i is generated from its p os terior distribution, for i = 1 , 2 , . . . , n , 4: α ( j ) i ∼ f α ( α i | κ ( j − 1) , σ ( j − 1) , Y i ) 5: Sampling of κ : The j-th sa mple o f κ , i.e. κ ( j ) is generated fr om its p oster ior distribution, 6: κ ( j ) ∼ f κ ( κ | α ( j ) 1 , . . . , α ( j ) n , σ ( j − 1) , Y ) 7: Sampling of σ : The j-th sa mple of σ , i.e. σ ( j ) is ge ner ated fro m its p osterio r distribution, 8: σ ( j ) ∼ f σ ( σ | α ( j ) 1 , . . . , α ( j ) n , κ ( j ) , Y ) (23) 9: Iteration : The steps 3, 4 and 5 a re rep eated fo r j = 1 , 2 , . . . , M , where, M is the num ber of itera tions. Finally , the exp ected v alues of α i , κ and σ are calculated as follows, E ( α i ) = 1 M − m M X j = m +1 α ( j ) i (24) 9 E ( κ ) = 1 M − m M X j = m +1 κ ( j ) (25) E ( σ ) = 1 M − m M X j = m +1 σ ( j ) (26) for la rge m and M such tha t, m < M . Here, m is burn-in p erio d. 3.3.2. V ariation of Mo del Par ameters with r esp e ct to Hyp erp ar ameters In order to obs e r ve the effects of hyper parameters on the estimated v alues of mo del parameter s, simula- tions are p erformed by v ar ying the v alue of one hyper parameter while keeping others constant. In simulation, the num b er of Gibbs runs are 2000 and the burn in p er io d is 1500, i.e. only last 500 v alues ar e taken into consideratio n among 2000 estimated v alues to get final estimate of κ . The simulation results are shown in Figure 4. The dia grams presented in Figure 4 show the v ar ia tion in estimated v alue of κ with hyperpar am- eters a and b re spe ctively . The plots indica te that, e s timates of κ a re highly dep enden t on b oth a and b . Similar exp eriments show lar ge dep e ndency of e stimates o f κ , α a nd σ o n other hyperpar ameters also. F rom these observ ations it ca n be concluded that, hyper parameter s need to estimated first to get better estimate of the mo del par ameters. The estimatio n of hyperpa rameters is discussed in the ensuing section. 100 150 200 250 300 350 400 450 500 100 150 200 250 300 350 400 450 500 550 Values of Hyperparameter a Estimated κ Estimated κ vs a 5 10 15 20 25 30 35 40 45 50 600 650 700 750 800 850 900 Values of Hyperparameter b Estimated κ Estimated κ vs b Figure 4: Illustration of v ariation of estimated v alues of κ with v arying v alues of hyperparameters 3.4. Maximum Likeliho o d Estimation of Hyp erp ar ameters Hyper parameter s of the affine mo del ar e estimated using Likelihoo d Maximiza tion technique. The likeli- ho o d function is calculated by mult iplying distr ibutions of a ll the par a meters. This function co n tains b oth, mo del parameter s and hyperpar ameters. The mo del parameters ar e in tegrated o ut to obtain a likelihoo d function, depe nden t only on the hyper parameters . The r e quired estimate of the hyperpa rameters are v a lues for which the likelihoo d function is maximized. Under the assumption, κ ∼ N ( a, b 2 ), α i ∼ N ( c, d 2 ) and σ ∼ U ( θ 1 , θ 2 ) a nd ǫ i ∼ N r ( 0 , σ 2 I r , r ), the likelihoo d function is given by , L (Θ | Ω , Y ) = f 1 ( κ | Θ κ ) f 2 ( σ | Θ σ ) n Y i =1 f y ( Y i | κ, α i , σ ) f 1 ( α i | Θ α ) (27) where, Θ , Ω , Y , f 1 ( κ | Θ κ ) , f 2 ( σ | Θ σ ) and f 1 ( α i | Θ α ) are defined in Section 3. The likelihoo d function in Equation (27) contains terms of a , b , c , d , θ 1 , θ 2 , κ , α 1 , . . . , α n , and σ . B ut the r equired likelihoo d function 10 should b e a function of hyperpara meters and it should not con tain mo del parameter s. In order to achiev e this, the mo del para meters κ , α 1 , . . . , α n and σ ar e integrated out from Eq uation (27) to o btain the int egrated likelihoo d ( I L (Θ)) function a s follows, I L (Θ) = Z θ 2 θ 1 Z ∞ −∞ f ( κ, σ, c, d ) ( θ 2 − θ 1 ) √ 2 π b 2 e − ( κ − a ) 2 2 b 2 dκdσ (28) where, f ( κ, σ, c, d ) denotes a part of the likeliho o d function which is o btained after integrating out a ll the α i ’s. f ( κ, σ, c, d ) = n Y i =1 Z ∞ −∞ e − ( α i − c ) 2 2 d 2 + − ( Y i − µ i ) T ( Y i − µ i ) 2 σ 2 √ 2 π d 2 (2 π σ 2 ) r / 2 dα i (29) which simplifies to the following expre ssion, f ( κ, σ, c, d ) = A − n 2 α i 2 n ( r +1) 2 π nr 2 d n σ nr e P n i =1 B 2 α i A α i − C α i ! (30) where, A α i = 1 2 d 2 + X T X +2 κ ( X T 1 )+ r κ 2 2 σ 2 B α i = X T Y i + κ ( X + Y i ) T 1 + r κ 2 2 σ 2 + c 2 d 2 C α i = Y T i Y i +2 κ ( Y T i 1 )+ r κ 2 2 σ 2 + c 2 2 d 2 Now using Equa tion (30), Equa tion (28) can b e written as, I L (Θ) = Z θ 2 θ 1 Z ∞ −∞ A − n 2 α i e − ( κ − a ) 2 2 b 2 P n i =1 B 2 α i A α i − C α i ! 2 n ( r +1)+1 2 π ( nr +1) 2 d n σ nr ( θ 2 − θ 1 ) dκdσ (31) The deriv atio n of Equations (28) thro ugh (31) is given in Appendix .4. The v a lues of a, b, c , d, θ 1 and θ 2 for which the in tegrated likelihoo d displa yed in Equa tion (31) a ttains maximum v alue for given Y , irresp ective o f κ , α 1 , . . . , α n and σ , are the final estimates o f hyper parameters . Note that, the co ns tant in Equation (31) can b e ignor ed, b ecause it do es not affect maximiza tion. So, the int egrated likelihoo d ca n b e written as , I L (Θ) = Z θ 2 θ 1 Z ∞ −∞ A − n 2 α i d n σ nr ( θ 2 − θ 1 ) e − ( κ − a ) 2 2 b 2 P n i =1 B 2 α i A α i − C α i ! dκdσ (32) Now, instead of calcula ting I L (Θ), log( I L (Θ)) is considered for o ptimization, b ecaus e log is a concave func- tion and it will not affect the maximizatio n. The optimum v alue o f pa rameters are obtained by maximizing log( I L (Θ)). Therefore, the task remains to maximize log( I L (Θ)) with resp ect to a , b , c , d , θ 1 and θ 2 . Pr ior to carrying out the maximiza tio n o f lo g( I L (Θ)), nature of the ob jective function needs to b e examined. The v aria tion of log ( I L (Θ)) ag ainst each o f the six hyper parameters a r e shown in Fig ure 5. A car eful obser v ation of these plots indicate that, log( I L (Θ )) is uni-mo dal with resp ect to all hyperpara meters. Hence, log ( I L (Θ)) can b e maximized. A jo int maximizatio n is nee de d ov er these six v ariables to obtain the requir ed hyper parameters . Int erior- p oint algor ithm (24) ha s b een used to so lve this optimizatio n pro blem. This is a sp ecia l kind o f linear programming algorithm in whic h the optimal solution is reached by traversing the interior of the feasible region. Here, the feasible reg ion is the set of a ll p ossible p oints of an optimization problem that satisfy the pr oblem’s co nstraints. 11 0 50 100 150 200 250 300 350 400 450 500 −6502 −6501 −6500 −6499 −6498 −6497 −6496 −6495 Values of a Log Integrated Likelihood (a) log( I L (Θ)) v s a 0 50 100 150 200 250 300 350 400 450 500 −6550.2 −6550 −6549.8 −6549.6 −6549.4 −6549.2 −6549 −6548.8 Values of b Log Integrated Likelihood (b) lo g( I L (Θ)) v s b 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 −6580 −6570 −6560 −6550 −6540 −6530 −6520 −6510 −6500 −6490 Values of c Log Integrated Likelihood (c) lo g( I L (Θ)) v s c 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 −7300 −7200 −7100 −7000 −6900 −6800 −6700 −6600 Values of d Log Integrated Likelihood (d) lo g( I L (Θ)) v s d 0 50 100 150 200 250 300 −7000 −6950 −6900 −6850 −6800 −6750 −6700 −6650 −6600 −6550 −6500 Values of θ 1 Log Integrated Likelihood (e) log( I L (Θ )) v s θ 1 50 100 150 200 250 300 350 −12000 −11000 −10000 −9000 −8000 −7000 −6000 Values of θ 2 Log Integrated Likelihood (f ) lo g( I L (Θ)) v s θ 2 Figure 5: Fi gur es illustrating the v ari ation of Log In tegrated Lik elihoo d (log( I L (Θ))) with resp ect to a , b , c , d , θ 1 and θ 2 resp ectively , v arying one at a time keeping others constant 3.5. Alg orithm to Estimate Mo del Par ameter using Bayesian Estimation T e chnique The steps for calculating the affine mo del para meter s using Bay esian E stimation are enumerated in Algo- rithm 3. T his algor ithm impr oves p erfor mance o f the recognizer by a s ignificant amount. The improv emen t in recognition accuracy is shown in the following section with the help of tw o kinds of recog nition ex per i- men t. Although the num ber of parameter s w ere kept in chec k as describ ed in Sectio n 2.1, the co mputational 12 cost was hig her than the c o nv entional linea r VTLN metho d (3). Thus, b oth no rmalization mo dels will find its applica tion dep ending on the pro blem under considera tion. Algorithm 3 Estimation of Parameter s α and κ using Bay esian Estimation Metho d 1: F orman t F requency V ectors : F ormant frequencies a r e extr acted (20) from all utterances to cons truct fromant fr equency vector for sub ject sp eaker ( X ) and reference sp eaker ( Y ). 2: In teg rated lik eliho o d function : The int egrated likelihoo d function is ca lculated a s shown in E quation (32). 3: Estimation of Hyp erparameters : The hyperpa r ameters a, b, c, d, θ 1 , θ 2 are ca lc ula ted by o ptimizing Equation (32 ) us ing interior p oint algo rithm. 4: Estimation of α and κ : Using the e s timates of hyperpar ameters, the affine mo del para meters α a nd κ ar e calc ula ted using Algorithm2. 4. P erformance Ev aluation In order to ev a luate p erforma nc e of the Bayesian appr o ach for sp eaker normalization prop osed in this pap er, tw o different exper iment s are conducted namely , vo w el reco gnition exp er imen t and s peech recog nition exp eriment. V ow el recog nition exp eriments a re co nducted to v alidate the who le s et-up o f s p ea ker norma l- ization, b eca use it is based on formant frequencies. Afterwards, s peech recognitio n exp eriments are carr ied out to demons trate the scop e of the prop osed approa ch for rea l-life applica tions. 4.1. Exp eriments on V owel Re c o gnition The vow el recognitio n exp eriments are p erformed using a Mahalano bis distance (2 5) bas ed vow el rec- ognizer. A brief des cription is presented on the r e cognizer as well as the da tabases b eing used for v ow e l recognition and the exp erimental set-up is discussed. The r eafter the exp eriments are conducted and recog - nition p erforma nces are sho wn in ter ms of recognition accura cy . Note that, the exp er iments on v o wels a re solely base d on their formant frequencies a nd not on any other acoustic information from the uttera nc e s of vo w els. 4.1.1. F ormant b ase d V owel Re c o gnizer F orma n t frequency vectors cor resp onding to each sp eaker are needed to implemen t the no r malization scheme. The formant frequency vector for a pa rticular s p ea ker is constr uc ted by concatena ting formants of all v ow els sp oken by that sp eaker. Subsequen tly , the metho ds discussed in Sections 2 and 3 are used to compute the no rmalization para meters for each sp e aker. The estimation of normaliza tion par ameters is follow ed b y its a pplication on fo r mant frequencie s of the databa se to obtain no r malized frequencies using Equation (3), as shown in Section 2. First three fo r mant freque nc ie s corr esp onding to a vo w el a re cons ide r ed for recognitio n. The r eference s pea kers’ database co ntains different vo w els sp oken by v arious sp eakers, whic h constitutes v ario us instances for each v o wel. Finally for testing a vo wel utter ance, its formant frequencie s are extracted and its Maha lanobis distance is computed from eac h v ow el group present in the reference sp eakers’ da tabase. The vow el c orresp onding to the minimum distance is the reco g nized vo w el. 4.1.2. V owel Datab ases The following tw o databa ses are used for vo wel recog nition exp eriments. • Peterson & Barney Datab ase (PnB): There are a to tal o f 76 sp eakers (3 3 Males, 28 F emales and 1 5 Children) in PnB data base (26). The utterances were recor ded using magnetic tap e recorder. F or the r ecordings, a list o f 1 0 mono s yllabic words were prepared ea ch star ting with ‘h’ and ending with ‘d’. Spea kers were given a list of words b e fore r ecording. The or der in the lists were ra ndo mized, and each s pea ker was asked to prono unce words using tw o different lists. Randomizing the list avoids the practice effects of the sp eakers. This data base co nsisted o f uttera nces o f 1 0 vow els (/aa/, / ae/, /a h/, 13 /ao/, /eh/, /er/ , /ih/, /iy/, /uh/, /uw/), which are uttered t wice by each of the sp eakers. Alternately , the PnB database can be consider ed to b e having 15 2 sp ea kers (66 Ma le s, 56 F emales and 30 Children), with e a ch of them having uttered 10 vo wels once. • Hil lenbr and Datab ase (Hil): The Hil da tabase (27) effectively consists of a total of 9 8 s pea kers (37 Males, 33 F emales and 28 Childr en). Here each of the sp eakers hav e uttered only once, each of the 12 vow els (/a e/, / ah/, /aw/, /eh/ , /ei/, /er/, /ih/, /iy/, /oa/ , / o o/, /uh/ , /uw/). Thes e vo wels are extracted fro m 12 monosylla bic words starting with ‘h’ and ending with ‘d’, which were uttered by those sp eakers. There were some mo re s p ea kers in this databa se, but they are no t c onsidered for our exp eriments as some of the formants corr esp onding to those sp ea kers ar e mar ked zero. The fo r mants were marked zer o b ecause the authors were unable to calculate them. The aforement ioned da tabases are av a ilable in (28) and (29) resp ectively . 4.1.3. Exp erimental Conditio ns Each spea ker in b oth da ta bases are characterized by using first three formant frequencies ( F 1 , F 2 , F 3 ) of ea ch vow el. F o rmant frequency vector cor resp onding to a sp eaker is co nstructed by co nc a tenating the formant frequencies of all vo w els sp oken by that sp eaker. Since there a re thr ee for ma n t frequencie s for each vo w el, the dimension of the for mant freq uency v ector cor resp onding to each sp eaker will b e 30 for P nB database (co r resp onding to 10 vo wels) and 36 fo r Hil databa se (cor resp onding to 12 vo wels). In b oth databases mentioned a bove there ar e three categ ories o f s pea kers: male , female a nd child. Thus, the norma lization para meters, κ (sp eaker independent) and α (sp eaker dependent) ar e calculated using all combin ations of these three categories, e .g . for male sp eakers, three different kinds of norma lization parameters are o btained by taking male sp eaker as s ub ject and alternately c o nsidering ma le , female a nd child sp eaker as reference. This is follow ed by no rmalization o f the databases using estimated par a meters. Hence, for each kind of sp eaker there will be three cla sses of normaliz e d frequencies co rresp onding to different categorie s of reference sp eakers used. In total, there will b e 9 different combinations of sub ject and r eference sp eaker as MM, MF, MC, FM, FF, FC, CM, CF and CC, wher e M, F, C co rresp ond to Male , F emale and Child sp e aker re spe c tiv ely . Male Female Child 0 10 20 30 40 50 60 70 80 90 Recognition Accuracy (%) Reference Dataset Unnormalized Bayesian Method MSE adjusted outliers MSE no adjustment MAE adjusted outliers MAE no adjustment (a) Male Sub ject Male Female Child 0 10 20 30 40 50 60 70 80 90 Recognition Accuracy (%) Reference Dataset Unnormalized Bayesian Method MSE adjusted outliers MSE no adjustment MAE adjusted outliers MAE no adjustment (b) F emale Sub ject Male Female Child 0 10 20 30 40 50 60 70 80 90 Recognition Accuracy (%) Reference Dataset Unnormalized Bayesian Method MSE adjusted outliers MSE no adjustment MAE adjusted outliers MAE no adjustment (c) Child Sub ject Figure 6: Bar diagrams showing vo wel recognition p erformance on H il database in terms of Recognition Accuracy f or baseline case and using normali zation 4.1.4. V owel R e c o gnition Performanc e The recognitio n exp eriment on vow els ca n b e divided into tw o categ ories, namely • Gender Dep endent Normalizatio n: The reco gnition accura cies a re shown us ing bar diagra ms. Figur es 6 a nd 7 show the vo w el r ecognition p erfor mances for Hil a nd PnB databases respec tively . In each Figure, there are three ba r diagrams corre s po nding to differen t kinds of sub ject sp eakers. Each bar diagram c omprises of three gro ups corres po nding to different ca tegories of reference sp eakers. The groups in turn co nt ain 6 bars each, a mong which the first bar cor resp onds to baseline case and o ther bars corres po nd to v arious no rmalization metho ds. 14 Male Female Child 0 10 20 30 40 50 60 70 80 90 100 Recognition Accuracy (%) Reference Dataset Unnormalized Bayesian Method MSE adjusted outliers MSE no adjustment MAE adjusted outliers MAE no adjustment (a) Male Sub ject Male Female Child 0 10 20 30 40 50 60 70 80 90 100 Recognition Accuracy (%) Reference Dataset Unnormalized Bayesian Method MSE adjusted outliers MSE no adjustment MAE adjusted outliers MAE no adjustment (b) F emale Sub ject Male Female Child 0 10 20 30 40 50 60 70 80 90 Recognition Accuracy (%) Reference Dataset Unnormalized Bayesian Method MSE adjusted outliers MSE no adjustment MAE adjusted outliers MAE no adjustment (c) Child Sub ject Figure 7: Bar diagrams sho wing vo w el r ecognition p erformance on PnB database in terms of Recognition Accuracy for baseline case and using normali zation T able 2: T able illustrating the V ow el Recognition P erformance using normalization in terms of Recognition Accuracy (RA) and i ts improv emen t ov er the baseline case Normalization Metho ds Hillenbrand Database P eterson & Barney Database Recognition Accuracy (%) Impro v ement(%) Recognition Accuracy (%) Impro v emen t(%) Baseline Case 75.2 - 83.9 - Bay esian Estimatio n 80.1 6.5 88.6 5.6 MSE without any adjustment 75.0 -0.3 82.4 -1.9 MSE with adjusted outliers 70.2 -6.6 80.1 -4.5 MAE without any adjustment 78.0 3.7 84.3 0.5 MAE with adjusted outliers 73.3 -2.5 85.6 2.0 • Gender Indep endent Normalization: In this exp eriment, normaliz a tion par ameters for a sp eaker is computed by consider ing a ll other sp eakers pres ent in the data base (not of a particular gender ) as ref- erence sp eakers. The reco g nition accura cy for differ ent e x per iment s a re shown in T able 2 . The relative improv emen ts in per formance ov er the ba seline case (without no r malization) while using nor ma liza- tion, ar e indicated in a separa te column. A negative entry in this column demonstra tes a de g radation in per formance. The exp eriments discussed in this s ection sig nifies that, a gre a ter a mount of performa nce improv emen t can be a chiev ed for gender depe ndent normalization compared to gender independent normalizatio n. It also indicates that, normaliza tion pa rameters estimated using mean abso lute error giver b e tter p erfor mance compared to mea n squa r e erro r. 4.2. Exp eriments on Sp e e ch R e c o gnition A Hidden Markov Mo del (HMM) based sp eech recognizer (30; 31) is used he r e for s peech r e c ognition exp eriments. A brief description is presented on the sp eech recognizer as w ell as the database being us e d and the exp erimental set-up is discussed. Thereafter the exp eriments a re ca rried o ut and r e cognition per- formances a re shown in terms of word erro r r ate. 4.2.1. The R e c o gnizer The standard filter -bank front end introduced by Davis and Mermelstein (32) (which is co nven tiona lly used in HMM based sp eech recog nizer) is mo dified to incorp ora te nor malization metho d for feature extrac - tion. The no rmalization s ch eme is applied on p ow er s p ectr um of window ed sig nal dur ing featur e extraction. Normalized features are extracted from this mo dified front-end signal pro cesso r. This nor malization pro cess changes the bandwidth as well as the frequency bin v alues o f the sp ectrum. Due to these rea sons, normalized sp ectrum needs to b e mo dified b efore feature- extraction. 15 • Bandwi dth A djustment: Depending on the v alue of α , bandwidth of the s p ectr um changes. F or v alues of α > 1, bandwidth increas es, wher eas α < 1 decreas es the bandwidth. This differe nce in bandwidth is adjusted using piecewise linea r warping function. The following function is applied on the warp ed sp ectra, G ′ ( f ) = ( G ( f ) , 0 ≤ f ≤ f 0 f max − G ( f 0 ) f max − f 0 ( f − f 0 ) + G ( f 0 ) , f 0 ≤ f ≤ f max (33) where, f max is the maximu m frequency present in the signal, f 0 is a frequency chosen by the user which falls a bove the highest s ignificant formant in the sp eech and G ( f ) is the warp ed sp ectra, which we get by applying our affine mo del based normaliza tion with para meters estimated using different metho ds discussed earlier. • F r e quency Bin A djustment : In gener al, for the s pec tr um of G ( f ), the a mplitude of the sp ectr um is av a ilable o nly at sp ecific v alues o f f . Due to the ba ndwidth adjustment discussed ear lier, the freq uency v alues co uld no long er be on those sp ecific v alues. Also, due to the shift in warping function, so me of the frequency p oints might b e missing either in the b eginning (for p ositive shift) o r in the end (for negative shift) o f the spectrum. A simple linear interpolatio n metho d is used here to get amplitudes of the sp ectrum at tho se v alues of f (33; 34) wher e amplitude of unnormalize d sp ectrum was defined. The step follow ed by feature extraction from the a coustic da ta is training of the HMM mo dels us ing the features. Subse quent ly the trained HMM mo dels a re used for testing purp os es. The training and testing metho ds a re modified as well to incorpo rate normalization into the reco gnizer. The process of normalized training and testing is discuss ed in the following par a graph. • Normalize d T r aining: The training pro ce ss b egins with the co mputation of forman t frequencies from training utterances (20). Then, the formant frequency vector for a spe a ker is construc ted by con- catenating forma n ts of all uttera nces from that speaker. Subsequently , the nor malization parameters are estimated using the techniques discussed in Sections 2 and 3. Later no rmalized MFCC features are extracted from the uttera nces using normalization par ameters which ar e used to train the HMM mo del. These steps are summarized in a blo ck diag ram shown in Figure 8. • Normalize d T esting: In order to incorp orate normaliza tion pro cess into testing utterances a tw o pass approach through the recog nizer is adopted. In the first pass, features are extracted from a test utterance to obtain an initia l transcript. Utterances corr esp onding to initial tr anscript in the training database helps to construct a class of re fer ence for mant frequency vectors for the test utterance under consideratio n. Subsequently , the nor malization para meters are c o mputed using the cla ss of reference formant frequency vectors. These par ameters are used to extra ct normalized MFCC features which Training Utterances Formant Extraction Formant Frequency Vector Construction Estimation of Parameters α and κ Normalized MFCC Feature Extraction Training HMM model Figure 8: Blo ck D i agram Illustrating Incorp oration of Normalization Metho d for T rai ning the Recognizer 16 Test Utterance Obtain Initial Transcript Reference Formant Frequency Vector Construction Estimation of Parameters α and κ Normalized MFCC Feature Extraction Obtain Final Transcript MFCC Feature Extraction Figure 9: Blo ck Diagram Illustrating Incorporation of Normali zation Method for T esting an Utterance using the Recognizer are again passed through the recognizer to obtain fina l transcript. Figur e 9 summarizes the steps discussed in this mo dule us ing blo ck diagr am. 4.2.2. Hindi L anguage Datab ase The database used here, is part of a bigger database, collected for a pro ject, funded by Ministry of Communication & Information T echnology , Govt. o f India. The goa l of the pr o ject was to develop a s ystem in which queries regar ding pr ices of s ome commo dities in a particula r distr ict c a n b e made thro ug h mobile phones using spe e ch modality . A speech data base was developed for this purp ose, consisting o f the names of different commo dities and distric ts. The original da tabase comprises of sp eech data , collected in six different Indian la nguages. These languag es are sp oken in many regiona l and so cial dia lects, with their own styles. The s pee ch data were collected fro m a bo ut 100 0 far mers for each langua ge a c r oss different districts to capture the v ar iation in dialects. F armers were encoura ged to do the r e cordings using their own mobile phones in the en vironment that they liv e in. The noise level of data are substantially higher due to the surrounding environmen t, which can b e the field or villa ge country side. The recor dings ha ve a sampling rate of 8 kHz and ar e stored in 16 bit PCM format with a Micr osoft .wav header. The challenges po sed by this databa se for the applicatio n of sp eech recog nition technology can b e summar ized as follows, • Accen t and dialect v a riations. • High level of background noise. • Disfluencies a nd pauses, since the user s are naive. • Issues like p o or netw o rk cov erage, interference, fading etc. and their effect on sp eech data. In this work, the exp eriments are p er formed o n a subset of the ab ove men tioned databas e, which are recorded in Hindi language. This subset consists of tw o gro ups. In one group, ther e are 1 07 co mmo dity names (Co mmodity Databas e ), and the o ther g roup co nsists of 71 district names (District Databa se). The Commo dity data base consists of 7431 utterances [ ∼ 38 hrs], whereas District databas e has 4 783 utterance s [ ∼ 24 hr s ]. 4.2.3. Exp erimental Conditio ns The databases are divided into tw o parts, training and testing, as dis cussed ea rlier in this section. F or Commo dity data base, the training data consists of 5899 utterances [ ∼ 30.5 hrs] a nd testing data consists of 1532 utterances [ ∼ 7.5 hrs], whereas the training and testing data bases for District databas e consists of 3798 17 T able 3: T able of sp ecifications for front end signal pro cessing used in the exp eriments of sp eech r ecognition P arameter Default V alue Window Length 20ms Filterbank Type Mel Filterbank Num ber of Mel Filters 40 Num ber of Cepstra 13 DFT siz e 512 Low e r Filter F requency 133.33 Hz Upper Filter F requency 6855.4 9 Hz Pre-E mpha sis F actor 0.97 T able 4: T able ill ustrating the Speech Recognition Performance using normali zation in terms of W ord Err or Rate (WER) and its im pro ve men t ov er the baseline case Normalization Metho ds Commo dity Database District Database W o rd Error Rate (%) Impro v e ment (%) W ord Error Rate (%) Impro vemen t(%) Baseline Case 16.7 - 24.6 - Linear VTLN 15.5 7.2 22.5 8.5 Bay esian Estimation 14.3 14.4 21.1 14.2 MSE without any adjustment 22.4 -34.1 28.3 -15.1 MSE with adjusted outliers 19.8 -18.6 43.2 -75.6 MAE without any adjustment 18.6 -11.4 27.5 -11.8 MAE with adjusted o utliers 17.4 -4.2 38.4 -56 .1 [ ∼ 20 hrs] and 985 [ ∼ 5 hrs] utterances resp ectively . The spe c ifications for front e nd signal pro cessing for feature ex traction is given in T able 3. Exp eriments using context indepe nden t pho nemes have b een car ried out. The pho nemes in each da tabase are represented us ing three state left to right HMM. F urther, each state of the HMM is mo delled using a mix tur e of 16 Gaus s ian densities. The exp eriments are p erformed using the Sphinx3 to olkit. Note that the co nducted exp eriments are gender indep endent i.e. the nor malization parameters ar e extra cted without gender information of the s p ea ker. This metho d was ado pted to increase usability o f the system in rea l life scenario where such information may not b e av ailable. 4.2.4. Sp e e ch R e c o gnition Performanc e The rec o gnition p er formance for different exp er imen ts is ev aluated using W o rd Err or Rate (WER). The results of these experiments a re shown in T able 4. Fir st row of this ta ble corres po nds to the ba seline case, when there is no s pea ker nor malization b eing use d. The following row s hows recognition p e r formance using linear nor malization mo del (3). All the following rows display p erformance us ing affine mo del. The par am- eters of this affine mo del is estimated using v arious techniques discussed in Sections 2 and 3. Performance using normalization is compared with ba seline case and relative improv ement s ar e indicated in a separate column. A neg ative entry in this column signifies p erfor mance degrada tion. Note that, background noise can significantly degrade the recognition p erformance. This fact was presented in a work by Hirsch and Pearce, which can b e found in (35). In the standard Auro ra-2 task for reco gnising the ten digits a nd ‘oh’ in American English (i.e. only 11 word voc a bulary), they hav e shown that the p erformanc e ca n v a ry from 99% to 10% depending on the background no ise. I n this work also, the spee ch data in both database s contain large amount o f ba ckground noise which justifies high WE R. The res ults using norma liz ation indica te that, changing the normaliza tion mo del from linear to affine, pe r formance ca n b e impr ov e d. The parameter esti- mation metho d plays a n imp or tant ro le in determining the recognition per formance using the affine mo del, and the effect ca n b e easily observed in recognition results presented in T able 4. Among a ll estimation techn iques use d, o nly Bayesian estimation metho d improv es p er fo rmance of recognizer. This improv ement is almo st twice than that of using linear mo del. 18 5. Conclusion A Bay esian approach to sp eaker normalizatio n is propo sed in this pap er . The v ar iation of vocal tra ct length among different sp eakers is modelled using an affine mo del. The para meters of the model are es- timated using Err or F unction Minimization technique and its limitations are discussed. Subsequently , a Bay esian method o f par a meter estimation is prop ose d and the framework is describ ed for the pro blem under consideratio n. A s pec ial type of Marko v Chain Monte Ca rlo metho d called Gibbs Sampler is used to imple- men t the Bayesian estimatio n. The need for hyper parameter estimation is also pre sented. Later , maximum likelihoo d e stimation is us e d to estimate the hyperpar ameters cor resp onding to mo del parameters . A Mahalanobis distance based vo w el recog niz e r is intro duced and used for the ex per iment s o n vow el nor- malization. Firs t three formant frequencies of a vo wel ar e consider e d in this kind of recog nizer. Exp eriments are p erformed for b oth Gender dep endent as well as Gender indep endent normaliza tion. It is observed that, the improv emen t in p erforma nce in case of gender dep endent norma liz ation is higher than that of g ender independent no rmalization. This indicates that, the prop osed approach is better suited for cross - gender normalizatio n. The nor malization scheme is further us e d for speech reco gnition exp eriments using Hidden Marko v Mo de ls . T e ch niques like bandwidth and frequency bin adjustment is used for this purp ose. The prop osed nor malization metho d requires prior kno wledge ab out the transcript o f the utterance under test. Therefore, a tw o pass approa ch thr ough the re cognizer is prop os e d to solve this problem. All the exp eri- men ts discus sed in this pap er justifies that, Bay esian estimation metho d gives better p erfor ma nce compare d to other metho ds. The prior distributions used for all exp eriments in this work a re non-infor mative, data -driven priors . Currently , metho ds that use non-Gaus sian pr iors and informative priors a re b eing explored to e s timate the sp eaker no rmalization para meters. Additiona lly , the p os sibilit y of using hig her o rder sp eaker norma liz ation mo dels in the pro po sed Bay esian para meter estimation framework is also be ing in v estigated. App endix .1. Derivation of Posterior Distribution of κ given in Equation (17): W e hav e f y ( Y i | κ, α i , σ ) given in Equation (16) and the pr ior of κ is Gaussia n i.e. f 1 ( κ | a, b ) = 1 √ 2 π b e − ( κ − a ) 2 b 2 . Let Y = ( Y 1 , Y 2 . . . , Y n ) a nd α = ( α 1 , α 2 , . . . , α n ). The joint distribution of ( Y , κ | α , σ ) is giv en by , f (1) y ( Y , κ | α , σ ) = n Y i =1 f y ( Y i | κ, α i , σ ) f 1 ( κ ) = 1 (2 π σ 2 ) nr / 2 e − P n i =1 ( Y i − µ i ) T ( Y i − µ i ) 2 σ 2 1 √ 2 π b e − ( κ − a ) 2 b 2 = 1 (2 π ) nr +1 2 bσ nr e − ( κ 2 A κ − 2 κB κ + C κ ) = 1 (2 π ) nr +1 2 bσ nr e − A κ ( κ − B κ A κ ) 2 +( B 2 κ A κ − C κ ) (.1) where, A κ = 1 r 2 σ 2 P n i =1 ( α i − 1) 2 + 1 2 b 2 B κ = a 2 b 2 + 1 2 σ 2 P n i =1 ( α i − 1 ) { ( Y i − α i X ) T . 1 } C κ = a 2 2 b 2 + 1 2 σ 2 P n i =1 { ( Y i − α i X ) T ( Y i − α i X ) } Now the joint distributio n o f ( Y | α, σ ) can b e obtained by int egrating Equation (.1) over κ as follows, 19 f (2) y ( Y | α , σ ) = Z ∞ −∞ f (1) y ( Y , κ | α , σ ) dκ = 1 (2 π ) nr +1 2 bσ nr Z ∞ −∞ e − A κ ( κ − B κ A κ ) 2 +( B 2 κ A κ − C κ ) dκ = 1 (2 π ) nr +1 2 bσ nr r π A κ e ( B 2 κ A κ − C κ ) (.2) Finally , p oster ior distribution o f κ can b e obtained by dividing E quation (.1) by Eq uation (.2) f κ ( κ | Y , α , σ ) = f (1) y ( Y , κ | α , σ ) f (2) y ( Y | α , σ ) = r A κ π ! e − A κ ( κ − B κ A κ ) 2 = 1 q 2 π σ 2 post e − ( κ − µ post ) 2 2 σ 2 post (.3) where, σ 2 κ = 1 2 A κ and µ κ = B κ A κ App endix .2. Derivation of Posterior Distribution of α i given in Equation (18): The prio r distribution of α i is a ssumed to b e Gaus s ian i.e. f 1 ( α i | c, d ) = 1 √ 2 π d e − ( α i − c ) 2 d 2 . So, the joint distribution o f Y i and α i can b e obta ine d by multiplying f 1 ( α i ) with f y ( Y i | κ, α i , σ ) as follows, f (1) α ( Y i , α i | κ, σ ) = f y ( Y i | κ, α i , σ ) f 1 ( α i ) = 1 (2 π σ 2 ) r / 2 e − ( Y i − µ i ) T ( Y i − µ i ) 2 σ 2 1 √ 2 π d e − ( α i − c ) 2 d 2 = 1 (2 π ) r +1 2 dσ r e − ( A α i α 2 i − 2 B α i α i + C α i ) = 1 (2 π ) r +1 2 dσ r e − A α i ( α i − B α i A α i ) 2 +( B 2 α i A α i − C α i ) (.4) where, A α i = 1 2 d 2 + X T X +2 κ ( X T 1 )+ r κ 2 2 σ 2 B α i = X T Y i + κ ( X + Y i ) T 1 + r κ 2 2 σ 2 + c 2 d 2 C α i = Y T i Y i +2 κ ( Y T i 1 )+ r κ 2 2 σ 2 + c 2 2 d 2 Now the distributio n o f ( Y i | κ, σ ) can b e obta ined by integrating Equa tion (.4) ov er α i as follows, f (2) α ( Y i | κ, σ ) = Z ∞ −∞ f (1) α ( Y i , α i | κ, σ ) dα i = 1 (2 π ) r +1 2 dσ r Z ∞ −∞ e − A α i ( α i − B α i A α i ) 2 +( B 2 α i A α i − C α i ) dα i = 1 (2 π ) r +1 2 dσ r r π A α i e ( B 2 α i A α i − C α i ) (.5) Finally , p oster ior distribution o f α i can b e obta ine d by dividing Equatio n (.4) by Equation (.5 ) 20 f α ( α i | κ, σ , Y i ) = f (1) α ( Y i , α i | κ, σ ) f (2) α ( Y i | κ, σ ) = r A α i π ! e − A α i ( κ − B α i A α i ) 2 = 1 q 2 π σ 2 post e − ( α i − µ post ) 2 2 σ 2 post (.6) where, σ 2 α i = 1 2 A α i and µ α i = B α i A α i App endix .3. Derivation of Posterior Distribution of σ given in Equation (19): The prior distr ibution of σ is assumed to b e uniform i.e. f 2 ( σ | θ 1 , θ 2 ) = 1 θ 2 − θ 1 . So, the joint distr ibutio n of Y i and σ can be obtained by multiplying f 2 ( σ | θ 1 , θ 2 ) with f y ( Y i | κ, α i , σ ) as follows, f (1) σ ( Y , σ | α , κ ) = n Y i =1 f y ( Y i | κ, α i , σ ) f 2 ( σ ) = 1 (2 π σ 2 ) nr / 2 e − P n i =1 ( Y i − µ i ) T ( Y i − µ i ) 2 σ 2 1 θ 2 − θ 1 = 1 (2 π ) nr 2 ( θ 2 − θ 1 ) σ nr e − P n i =1 ( Y i − µ i ) T ( Y i − µ i ) 2 σ 2 (.7) Now the distributio n o f ( Y | α , κ ) can b e obtained by int egrating Equation (.7) ov er σ as follows, f (2) σ ( Y | α , κ ) = Z ∞ −∞ f (1) σ ( Y , σ | α , κ ) dσ = Z ∞ −∞ 1 (2 π ) nr 2 ( θ 2 − θ 1 ) σ nr e − P n i =1 ( Y i − µ i ) T ( Y i − µ i ) 2 σ 2 dσ (.8) Finally , p oster ior distribution o f α i can b e obta ine d by dividing Equatio n (.7) by Equation (.8 ) f σ ( σ | κ, α , Y ) = f (1) σ ( Y , σ | α , κ ) f (2) σ ( Y | α , κ ) = e − 1 2 σ 2 P n i =1 ( Y i − µ i ) T ( Y i − µ i ) σ nr R θ 2 θ 1 e − 1 2 σ 2 P n i =1 ( Y i − µ i ) T ( Y i − µ i ) σ nr dσ (.9) Assuming β = 1 2 P n i =1 ( Y i − µ i ) T ( Y i − µ i ) the deno minator in the ab ov e Equation can b e written as, Z θ 2 θ 1 e − β σ 2 σ nr dσ = 1 2 β 1 − nr 2 Z β θ 2 1 β θ 2 1 z nr − 1 2 − 1 e − z dz = 1 2 β 1 − nr 2 ( γ − γ l − γ u ) (.10) where, γ = Γ nr − 1 2 , γ l = Γ low er β θ 2 2 , nr − 1 2 and γ u = Γ upper β θ 1 2 , nr − 1 2 App endix .4. Derivation of Inte gr ate d Likeliho o d F unction given in Equation (28): The likelihoo d function o f Θ given in Eq uation (27) can b e written as follows, 21 L (Θ | Ω , Y ) = f 1 ( κ | Θ κ ) f 2 ( σ | Θ σ ) n Y i =1 f y ( Y i | κ, α i , σ ) f 1 ( α i | Θ α ) = 1 √ 2 π b e − ( κ − a ) 2 b 2 1 θ 2 − θ 1 n Y i =1 1 (2 π σ 2 ) r / 2 e − ( Y i − µ i ) T ( Y i − µ i ) 2 σ 2 1 √ 2 π d e − ( α i − c ) 2 d 2 ! (.11) Equation (.11) is int egrated ov er α , κ and σ to obtain an integrated likelihoo d function s o lely dep endent on hyper parameters as given b elow, I L (Θ) = Z θ 2 θ 1 1 θ 2 − θ 1 Z ∞ −∞ 1 √ 2 π b e − ( κ − a ) 2 b 2 n Y i =1 Z ∞ −∞ e − ( Y i − µ i ) T ( Y i − µ i ) 2 σ 2 + − ( α i − c ) 2 2 d 2 (2 π σ 2 ) r / 2 √ 2 π d dα i dκ dσ = Z θ 2 θ 1 1 θ 2 − θ 1 Z ∞ −∞ f ( κ, σ, c, d ) √ 2 π b e − ( κ − a ) 2 2 b 2 dκ dσ (.12) The function, f ( κ, σ, c, d ) in Equa tion (.12) is calculated as follows, f ( κ, σ, c, d ) = n Y i =1 Z ∞ −∞ e − ( Y i − µ i ) T ( Y i − µ i ) 2 σ 2 + − ( α i − c ) 2 2 d 2 (2 π σ 2 ) r / 2 √ 2 π d dα i = n Y i =1 1 (2 π ) r +1 2 dσ r r π A α i e ( B 2 α i A α i − C α i ) = A − n 2 α i 2 n ( r +1) 2 π nr 2 d n σ nr e P n i =1 B 2 α i A α i − C α i ! (.13) [1] D. O ’Shaughnessy , In teracting wi th computers by voice: automatic sp eech recognition and synthesis, Pro ceedings of the IEEE 91 (9) (2003) 1272–1305. [2] J. Cohen, T. Kamm, A. Andreou, An experi men t in systematic sp eake r v ariability , in: Final Day Review., DoD Speech W orkshop on Robust Sp eech Recognition, Baltimor e, 1994. [3] L. Lee, R. C. Rose, Sp eak er normali zation usi ng efficient frequency warping pr ocedures, i n: Acoust ics, Sp eec h, and Signal Pro cessing, 1996. ICASSP-96. Conference Pro ceedings., 1996 IEEE In ternational Conference on, V ol. 1, IEEE, 1996, pp. 353–356. [4] S. Umesh, S. Bharath Kumar, M . Vi na y , R. Sharma, R. Si nha, A simple approach to non-unifor m vo w el normalization, in: Acoustics, Speech, and Si gnal Pr ocessing (ICASSP), 2002 IEEE In ternational Conference on, V ol. 1, IEEE, 2002, pp. I–517. [5] P . E. Nordstrom, B. Lindblom, A normali zation pro cedure for vo w el formant data, Int . Cong. Phonetic Sci., Leeds, England. [6] G. F an t, Non-unifor m vo wel nor m alization, Speech T rans. Lab. Q. Prog. Stat. Rep (1975) 2–3. [7] J. D. Mi ller, Audi tory- p erceptual interpretation of the vo w el, The journal of the A coustical so ciety of A merica 85 (1989) 2114. [8] N. Flynn, Comparing vo wel formant normalisation pro cedures, Y ork Pap. Linguist., Ser 2 (11) (2011) 1–28. [9] L. Lee, R. Rose, A fr equency warping approac h to sp eak er normalization, Speech and audio pro cessing, ieee transactions on 6 (1) (1998) 49–60. [10] S. W egmann, D . M cAl laster, J. Orloff, B. Peskin, Sp eaker norm alization on conv er s ational telephone sp eec h, in: Acoustics, Speech, and Si gnal Pr ocessing, 1996. ICASSP-96. Conference Pro ceedings., 1996 IEEE In ternational Conference on, V ol. 1, IEEE, 1996, pp. 339–341. [11] R . Sinha, S. Umesh, Non-uniform scaling based sp eake r normalization, in: A coustics, Sp eec h, and Signal Pro cessing (ICASSP), 2002 IEEE Internationa l Conference on, V ol. 1, IEEE, 2002, pp. I–589. [12] S. Umesh, L. Cohen, D. Nelson, Fitting the mel scale, in: Acoustics, Sp eech, and Signal Pro cessing, 1999. Pro ceedings., 1999 IEEE Internat ional Conference on, V ol. 1, IEEE, 1999, pp. 217–220. [13] E. Ei de, H. Gish, A parametric approach to vocal tract l ength nor m alization, in: Acoustics, Speech, and Signal Pro cessing, 1996. ICASSP-96. Confer ence P r oceedings., 1996 IEEE Inte rnational Conference on, V ol. 1, IEEE, 1996, pp. 346–348. [14] S. S. Stevens, J. V olkmann, The rel ation of pitch of frequency: A revised scale, Am. J. Psyc hol. [15] A . Acero, R. M . Stern, Robust speech r ecognition b y normali zation of the acoustic space, in: Acoustics, Sp eec h, and 22 Signal Pro cessing, 1991. ICASSP-91., 1991 Inte rnational Conf er ence on, IEEE, 1991, pp. 893–896. [16] S. Cox, Speaker normalization in the mfcc domain, in: Proc. In t. Conf. on Sp ok en Language Pro cessing, V ol. 2, 2000, pp. 853–856. [17] D . Sanand, D. D. Kumar, S. Umesh, Linear transfor mation approac h to vtln using dynamic frequency warping, i n: Eigh th Ann ual Conference of the Internation al Sp eec h Communica tion Asso ciation, 2007. [18] S. B. Kumar, S. U mesh, Non unif orm sp eak er normalization using affine transformation, The Journal of the Acoustical Society of Amer i ca 124 (2008) 1727. [19] J. A. Nelder, R. Mead, A simplex method for function mini mization, Computer journal 7 (4) (1965) 308–313. [20] R . C. Snell, F. M ilinazzo, F orman t l ocation f rom lp c analysis data, Sp eech and Audio Pro cessing, IEEE T ransactions on 1 (2) (1993) 129–134. [21] G. Casella, E. I. George, Explaining the gibbs sampler, The American Statistician 46 (3) (1992) 167–174. [22] R . V. Hogg, A. T. Craig, Introduction to mathematical statistics. 1978. [23] S. G. W. Paul Damien, Sampling truncated normal, b eta, and gamma densities, Journal of Computational and Graphical Statistics 10 (2) (2001) 206–215. doi:10.1198/106 186001526279 06 . [24] N . Karm ark ar, A new pol ynomial-time algorithm for linear programming, in: Proceedings of the sixteen th ann ual ACM symposi um on Theory of computing, ACM, 1984, pp. 302–311. [25] P . C. Mahalanobis, On the generalised distance in statistics, Proceedings of the National Institute of Sciences of Ind ia (1936) 49–55. [26] G. E. Peterson, H. L. Barney , Con trol methods used i n a study of the vo w els, The Journal of the Acoustical Society of America 24 (1952) 175. [27] J. Hi l lenb rand, L. A. Gett y , M. J. Clark, K. Wheeler, Acoustic characteristics of american english vo wels, The Journal of the Acoustical society of A m erica 97 (1995) 3099. [28] Peterson and barney database, http://www.c s.cmu.ed u/afs/cs/project/ai- repository/ai/areas/speech/database/pb/0.html . [29] H illenbrand database , http://homepage s.wmich.edu/ ~ hillenbr /voweldat a.html . [30] L. R. Rabiner, A tutorial on hidden marko v mo dels and selected applications i n sp eec h r ecognition, Pro ceedings of the IEEE 77 (2) (1989) 257–286. [31] J. Mariani, Recen t adv ances in sp eec h pro cessing, in: Acoustics, Sp eec h, and Signal Pr ocessing, 1989. ICASSP-89., 1989 In ternational Conference on, IEEE, 1989, pp. 429–440. [32] S. Da vis, P . Mermelstein, Compari son of parametric represen tations for monosyllabic w ord recognition in contin uously spoken sent ences, Acoustics, Sp eech and Si gnal Pr ocessing, IEEE T ransactions on 28 (4) (1980) 357–366. [33] P . Zhan, M. W estphal, Sp eak er normali zation based on fr equency warping, in: Acoustics, Sp eec h, and Signal Pro cessing, 1997. ICASSP-97., 1997 IEEE Internationa l Conference on, V ol. 2, IEEE, 1997, pp. 1039–1042. [34] P . Zhan, A. W aibel, V o cal tract length normalization for large vocabulary cont inuo us speech recognition, T ech. rep., DTIC Document (1997). [35] H . G. Hi rsch, D. Pearce, The aurora exp eriment al framewo rk for the perf ormance ev aluation of sp eech recognition systems under noisy conditions, in: ASR2000-Automatic Sp eec h Recognition: Challenges for the new Mil lenium ISCA T utorial and Research W or kshop (ITR W), 2000. 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment