Very Deep Convolutional Neural Networks for Robust Speech Recognition
This paper describes the extension and optimization of our previous work on very deep convolutional neural networks (CNNs) for effective recognition of noisy speech in the Aurora 4 task. The appropriate number of convolutional layers, the sizes of the filters, pooling operations and input feature maps are all modified: the filter and pooling sizes are reduced and dimensions of input feature maps are extended to allow adding more convolutional layers. Furthermore appropriate input padding and input feature map selection strategies are developed. In addition, an adaptation framework using joint training of very deep CNN with auxiliary features i-vector and fMLLR features is developed. These modifications give substantial word error rate reductions over the standard CNN used as baseline. Finally the very deep CNN is combined with an LSTM-RNN acoustic model and it is shown that state-level weighted log likelihood score combination in a joint acoustic model decoding scheme is very effective. On the Aurora 4 task, the very deep CNN achieves a WER of 8.81%, further 7.99% with auxiliary feature joint training, and 7.09% with LSTM-RNN joint decoding.
💡 Research Summary
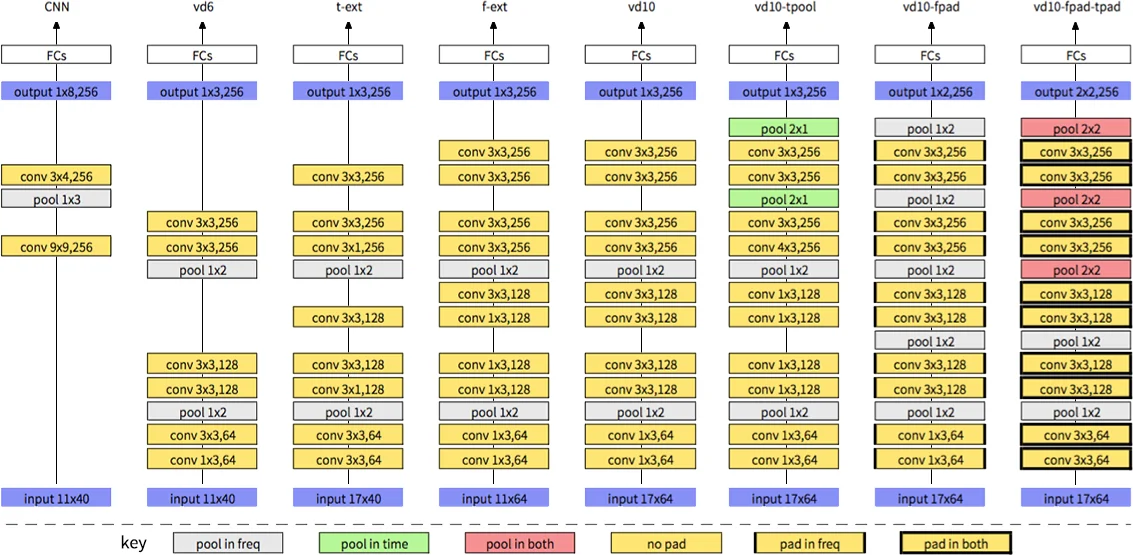
This paper investigates how to substantially improve noise‑robust automatic speech recognition (ASR) by designing and optimizing a very deep convolutional neural network (VDCNN) for the Aurora 4 benchmark. The authors start from the conventional ASR‑oriented CNN architecture (two convolutional layers with 9×9 and 3×4 filters, followed by four fully‑connected layers) and systematically modify every architectural component to enable many more convolutional layers while preserving or even enhancing performance in noisy conditions.
Key architectural changes
- Filter and pooling size reduction – The authors replace the large 9×9 and 3×4 filters with 3×3 (or 1×3/3×1) filters and limit pooling to non‑overlapping 1×2 or 2×2 windows. This mirrors the design philosophy that has driven breakthroughs in computer‑vision deep nets and allows the network depth to increase without exploding the receptive field.
- Input feature‑map enlargement – Typical speech CNNs use an 11‑frame temporal context and 40‑dimensional filter‑bank (FBANK) features. The paper expands the temporal context to 17 frames and the frequency dimension to 64, thereby providing enough spatial resolution for stacking up to ten convolutional layers (model “vd10”). Two intermediate variants, “t‑ext” (time‑extended) and “f‑ext” (frequency‑extended), demonstrate that each dimension independently contributes to error‑rate reduction.
- Padding strategies – While most speech CNN work performs “valid” convolutions (no padding), the authors experiment with zero‑padding on the frequency axis only (vd10‑fpad) and on both frequency and time axes (vd10‑fpad‑tpad). Padding preserves feature‑map size, enables additional pooling stages, and yields a clear WER improvement (from 4.13 % to 3.27 % on the overall Aurora 4 test set).
- Pooling in time – Adding temporal pooling (vd10‑tpool) does not help and even slightly degrades performance, confirming earlier observations that time‑axis down‑sampling harms ASR accuracy.
Input channel selection – Contrary to the common practice of feeding static FBANK together with Δ and ΔΔ (three channels), the experiments show that a single static FBANK channel works better for very deep networks. The authors argue that deep convolutions can learn temporal dynamics directly from the raw static spectra, making the explicit delta features redundant.
Auxiliary‑feature joint training – To further increase robustness, the VDCNN is jointly trained with i‑vector and fMLLR features. The auxiliary features are processed by a small feed‑forward sub‑network and merged with the VDCNN activations before the fully‑connected layers. This adaptation scheme reduces the overall WER to 7.99 %, a 0.8 % absolute gain over the plain VDCNN.
Combination with LSTM‑RNN – The authors also train a complementary long‑short‑term memory recurrent neural network (LSTM‑RNN) on the same data. During decoding, they perform state‑level weighted log‑likelihood combination of the VDCNN and LSTM‑RNN scores (joint decoding). Because the VDCNN excels at local spectral pattern modeling while the LSTM‑RNN captures long‑range temporal dependencies, the combined system achieves the best reported result of 7.09 % WER on Aurora 4, outperforming the individual models by a sizable margin.
Experimental results – Table 1 shows that the baseline CNN already beats a comparable DNN (4.11 % vs 4.17 % on clean speech). The progressive VDCNN variants (vd6, t‑ext, f‑ext, vd10) steadily lower WER, especially on the noisy subsets B, C, and D. Adding frequency padding (vd10‑fpad) and both‑axis padding (vd10‑fpad‑tpad) yields the largest single‑model gain (overall 8.81 %). Joint training with auxiliary features pushes the result to 7.99 %, and the final VDCNN + LSTM‑RNN joint decoding reaches 7.09 %.
Conclusions and impact – The paper demonstrates that, by carefully adapting deep‑vision design principles—small filters, extensive padding, and deeper stacks—to the speech domain, one can build a CNN that is both much deeper than traditional ASR CNNs and substantially more robust to additive noise and channel mismatch. The auxiliary‑feature joint training and model‑combination strategies further illustrate how complementary information sources can be fused effectively. The work sets a new benchmark for noise‑robust ASR on Aurora 4 and provides a clear recipe (filter size, pooling, padding, input dimension, auxiliary features) for researchers aiming to deploy very deep CNNs in real‑world, low‑SNR speech applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment