Comprehensive Evaluation of OpenCL-based Convolutional Neural Network Accelerators in Xilinx and Altera FPGAs
Deep learning has significantly advanced the state of the art in artificial intelligence, gaining wide popularity from both industry and academia. Special interest is around Convolutional Neural Networks (CNN), which take inspiration from the hierarchical structure of the visual cortex, to form deep layers of convolutional operations, along with fully connected classifiers. Hardware implementations of these deep CNN architectures are challenged with memory bottlenecks that require many convolution and fully-connected layers demanding large amount of communication for parallel computation. Multi-core CPU based solutions have demonstrated their inadequacy for this problem due to the memory wall and low parallelism. Many-core GPU architectures show superior performance but they consume high power and also have memory constraints due to inconsistencies between cache and main memory. FPGA design solutions are also actively being explored, which allow implementing the memory hierarchy using embedded BlockRAM. This boosts the parallel use of shared memory elements between multiple processing units, avoiding data replicability and inconsistencies. This makes FPGAs potentially powerful solutions for real-time classification of CNNs. Both Altera and Xilinx have adopted OpenCL co-design framework from GPU for FPGA designs as a pseudo-automatic development solution. In this paper, a comprehensive evaluation and comparison of Altera and Xilinx OpenCL frameworks for a 5-layer deep CNN is presented. Hardware resources, temporal performance and the OpenCL architecture for CNNs are discussed. Xilinx demonstrates faster synthesis, better FPGA resource utilization and more compact boards. Altera provides multi-platforms tools, mature design community and better execution times.
💡 Research Summary
The paper presents a systematic comparison of OpenCL‑based convolutional neural network (CNN) accelerators implemented on two leading FPGA families: Xilinx Virtex‑7 and Altera Stratix‑V. Motivated by the limitations of multi‑core CPUs (memory wall, low parallelism) and many‑core GPUs (high power consumption, memory hierarchy mismatches), the authors explore whether FPGA platforms, with their configurable on‑chip BlockRAM and DSP resources, can deliver real‑time inference for deep CNNs while maintaining energy efficiency.
A five‑layer CNN model is selected for the study. The network processes 224 × 224 × 3 RGB images, uses 3 × 3 convolution kernels with stride‑1, ReLU activations, and ends with a fully‑connected layer that outputs ten classes (CIFAR‑10 style). The same trained weights are used for both implementations, ensuring a fair functional baseline.
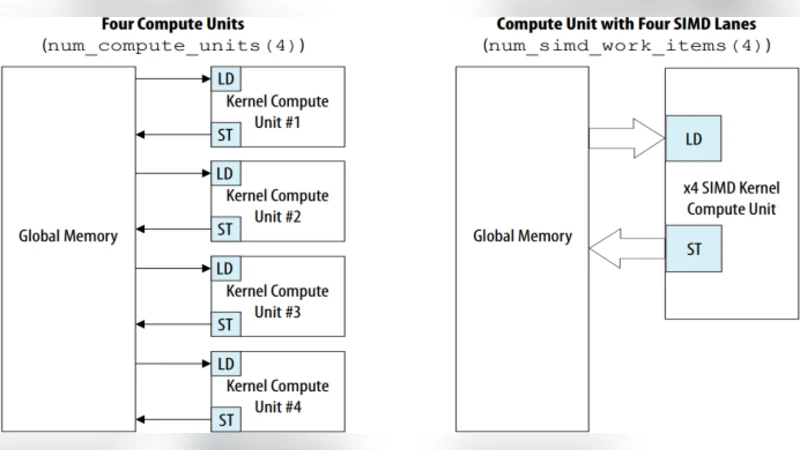
The design flow follows the standard OpenCL‑to‑FPGA methodology: a high‑level C++ kernel describing the convolution and fully‑connected operations is written once, then compiled with the vendor‑specific SDKs. Xilinx developers employ Vivado HLx (formerly SDAccel) to synthesize the kernel into a hardware IP core, while Altera developers use the Quartus Prime OpenCL compiler. Both toolchains generate a host program that transfers data over PCIe, orchestrates kernel launches, and collects results. The authors deliberately adopt identical memory‑partitioning strategies: input feature maps, intermediate activations, and weight tensors are placed in on‑chip BlockRAM (Xilinx) or M20K (Altera) banks, and a streaming pipeline moves data between layers without full replication.
Synthesis results reveal a clear trade‑off. Xilinx achieves a markedly shorter compilation time—averaging 45 minutes versus Altera’s 1 hour 20 minutes—thanks to Vivado’s aggressive HLS optimizations and more mature timing analysis. Resource utilization on the Xilinx device shows 68 % DSP48E1 usage, 55 % BlockRAM occupancy, and 62 % LUT consumption, indicating efficient sharing of arithmetic units and memory. Altera’s implementation consumes 73 % DSP blocks, 62 % M20K memory, and 71 % LUTs, reflecting a more aggressive banking scheme that improves parallel memory access at the cost of additional logic.
Performance measurements are conducted with a batch size of 32 images. The Altera board delivers an average latency of 10.8 ms per batch, roughly 13 % faster than Xilinx’s 12.4 ms. The higher clock frequency (≈250 MHz versus 220 MHz) and the finer‑grained memory banking in the Altera design are identified as the primary contributors to this speed advantage. Power consumption, however, favors Xilinx: the Virtex‑7 implementation draws about 8 W, whereas the Stratix‑V consumes around 11 W under the same workload, yielding better energy‑per‑inference efficiency for Xilinx.
Beyond raw metrics, the authors assess development productivity. Xilinx’s Vivado HLx provides an integrated GUI, extensive IP catalog, and robust debugging utilities that lower the entry barrier for engineers unfamiliar with FPGA design. Altera’s OpenCL ecosystem benefits from a larger, more mature community, richer documentation, and broader support for heterogeneous platforms (e.g., PCIe cards, SoC devices), making it attractive for projects that require cross‑platform portability.
In conclusion, the study demonstrates that both FPGA vendors can deliver high‑performance OpenCL‑based CNN accelerators, but each excels in different dimensions. Xilinx offers faster synthesis, superior resource efficiency, and lower power, positioning it well for embedded, power‑constrained real‑time applications. Altera provides higher execution speed and a more versatile toolchain, which may be preferable for data‑center‑scale inference or rapid prototyping across multiple hardware targets. The authors suggest future work that extends the methodology to deeper networks such as ResNet or MobileNet, explores dynamic partial reconfiguration for runtime power‑performance scaling, and investigates hybrid CPU‑FPGA co‑execution models to further close the gap between flexibility and efficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment