System Combination for Short Utterance Speaker Recognition
For text-independent short-utterance speaker recognition (SUSR), the performance often degrades dramatically. This paper presents a combination approach to the SUSR tasks with two phonetic-aware systems: one is the DNN-based i-vector system and the other is our recently proposed subregion-based GMM-UBM system. The former employs phone posteriors to construct an i-vector model in which the shared statistics offers stronger robustness against limited test data, while the latter establishes a phone-dependent GMM-UBM system which represents speaker characteristics with more details. A score-level fusion is implemented to integrate the respective advantages from the two systems. Experimental results show that for the text-independent SUSR task, both the DNN-based i-vector system and the subregion-based GMM-UBM system outperform their respective baselines, and the score-level system combination delivers performance improvement.
💡 Research Summary
This paper tackles the severe performance degradation that occurs in text‑independent short‑utterance speaker recognition (SUSR) when the test utterance length drops to a few seconds or less. The authors argue that the core difficulty stems from a mismatch between the long enrollment data used to train speaker models and the limited test data, which leads to unreliable Baum‑Welch statistics for both GMM‑UBM and i‑vector frameworks. To mitigate this, they propose a “phonetic‑aware” strategy that leverages phone‑level information obtained from an automatic speech recognition (ASR) system. Two distinct phonetic‑aware systems are built and later combined at the score level.
The first system is a DNN‑based i‑vector model. A large‑scale DNN trained for ASR provides senone (phone‑state) posterior probabilities, which replace the traditional GMM posteriors when computing sufficient statistics and the total‑variability matrix (T‑matrix). Consequently, each Gaussian component of the underlying UBM is effectively tied to a specific phone, and the resulting low‑dimensional i‑vectors encode phone‑conditioned speaker characteristics. This shared‑latent‑variable approach improves robustness to short test segments because the i‑vector aggregates information across all phones.
The second system is a sub‑region (SBM‑DD) GMM‑UBM model. Here the acoustic space is partitioned into phonetic sub‑regions based on Chinese “Final” units. The authors first cluster the many finals into six classes using K‑means, then train a separate GMM‑UBM for each class (sub‑region). During scoring, each test frame is assigned to a sub‑region via ASR alignments, and a phone‑dependent speaker GMM is evaluated against the corresponding sub‑region UBM. The log‑likelihood ratios from all sub‑regions are averaged to produce a single score. This approach captures fine‑grained phonetic detail, which is especially valuable when only a few frames are available.
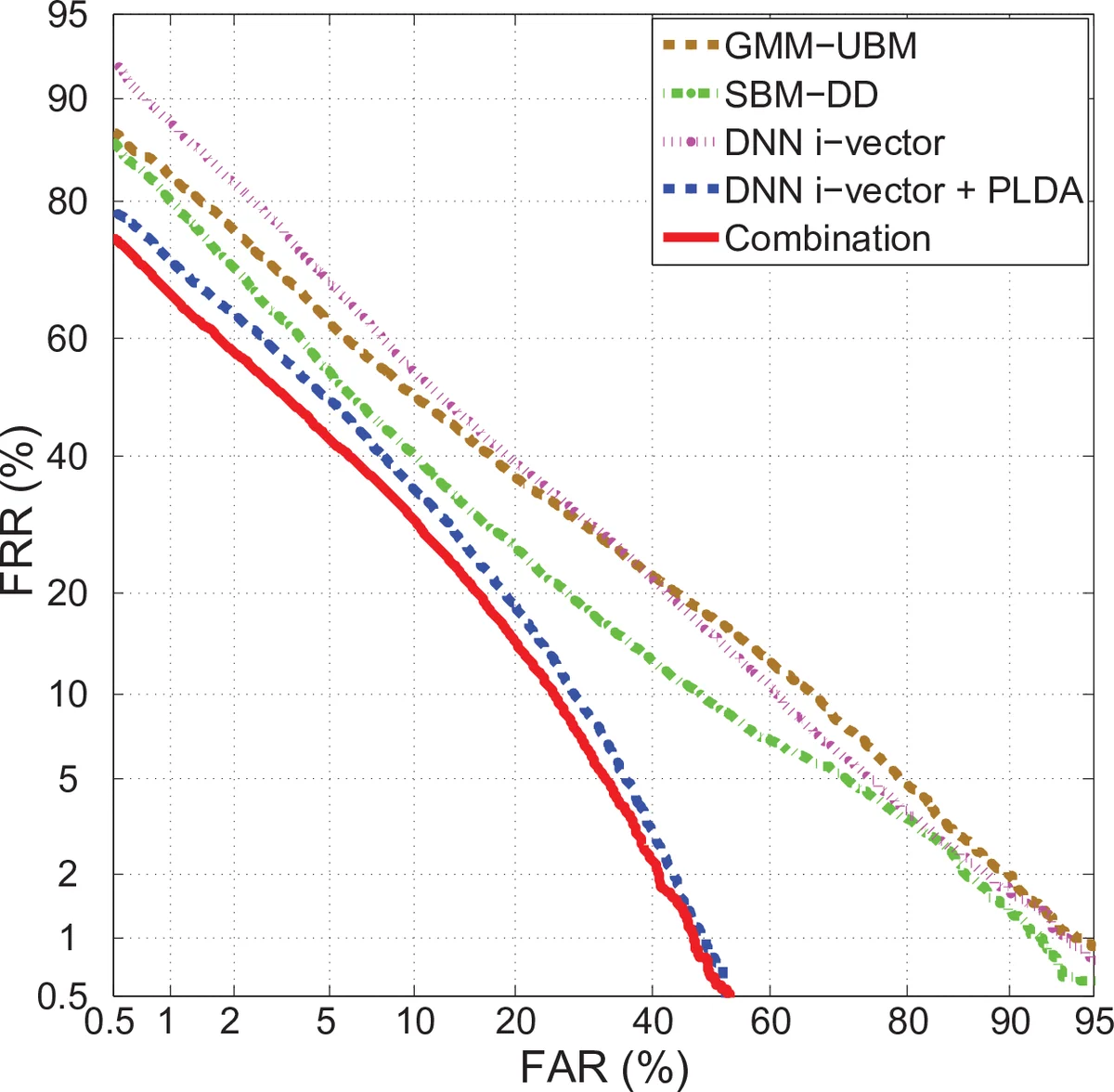
Both systems are evaluated on a newly created Chinese SUSR corpus (SUD12) containing 56 speakers and 0.5‑2 s utterances, as well as on a larger 17‑hour Chinese speech set (863DB) used for training UBMs and the T‑matrix. Baselines include a conventional 1,024‑component GMM‑UBM and a standard GMM‑i‑vector system (400‑dimensional). The DNN‑i‑vector system, after PLDA scoring, achieves 19.16 % equal error rate (EER), while the sub‑region system achieves 22.74 % EER. When the two scores are linearly fused (α = 0.94 weighting the DNN‑i‑vector score), the combined system reaches an EER of 17.43 %, a substantial improvement over any single method.
Key insights from the study are: (1) phonetic‑aware modeling substantially mitigates the data‑scarcity problem inherent in short utterances; (2) the DNN‑i‑vector and sub‑region models provide complementary strengths—global robustness via shared latent variables versus detailed phonetic discrimination via independent sub‑region GMMs; (3) simple linear score fusion is sufficient to harvest these complementary benefits, with the DNN‑i‑vector score dominating the combination but the sub‑region contribution still yielding a measurable gain.
The paper’s contributions are threefold: (i) introduction of two distinct phonetic‑aware architectures tailored for SUSR; (ii) a systematic evaluation showing that each outperforms its non‑phonetic baseline; (iii) demonstration that score‑level combination yields state‑of‑the‑art performance on a challenging short‑utterance benchmark. The authors suggest future work on more sophisticated phone clustering, multilingual extensions, and end‑to‑end deep learning fusion strategies, which could further enhance real‑world applications such as mobile authentication, voice‑controlled assistants, and forensic speaker verification where only brief speech samples are available.
Comments & Academic Discussion
Loading comments...
Leave a Comment