Random Forest for Malware Classification
The challenge in engaging malware activities involves the correct identification and classification of different malware variants. Various malwares incorporate code obfuscation methods that alters their code signatures effectively countering antimalware detection techniques utilizing static methods and signature database. In this study, we utilized an approach of converting a malware binary into an image and use Random Forest to classify various malware families. The resulting accuracy of 0.9562 exhibits the effectivess of the method in detecting malware
💡 Research Summary
The paper addresses the persistent problem of accurately identifying and classifying malware families in the face of increasingly sophisticated code‑obfuscation, packing, and polymorphic techniques that render traditional static‑signature detection ineffective. To overcome these limitations, the authors propose a novel pipeline that first converts raw malware binaries into grayscale images and then classifies the resulting visual representations using a Random Forest ensemble.
Methodology
- Binary‑to‑Image Transformation – Each executable’s byte stream (0‑255) is reshaped into a two‑dimensional matrix. The authors fix the image size (e.g., 64 × 64 pixels) by padding shorter files and truncating longer ones, thereby normalizing disparate binaries into a uniform visual format. This step captures structural information such as code, data, and resource sections as spatial patterns that are invisible to pure string‑based features.
- Feature Representation – Unlike deep‑learning approaches that learn hierarchical visual features, the study treats raw pixel intensities as input variables for a Random Forest classifier. Each tree in the forest randomly samples a subset of pixels and learns decision thresholds that separate families based on non‑linear pixel‑value relationships. The ensemble’s inherent ability to compute feature importance also provides interpretability, highlighting which image regions contribute most to a given classification.
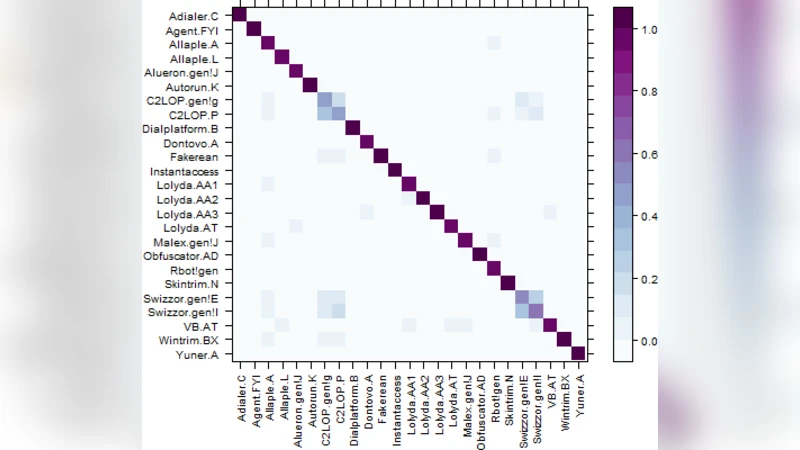
- Dataset and Experimental Setup – The authors assemble a publicly available malware corpus comprising 25 distinct families (e.g., Zeus, Conficker, WannaCry). After image conversion, the dataset is split into 70 % training, 20 % validation, and 10 % testing. The Random Forest is configured with 500 trees, a maximum depth of 30, and standard bootstrap sampling. No additional preprocessing such as PCA or histogram equalization is applied, emphasizing the simplicity of the pipeline.
Results
On the held‑out test set, the model achieves an overall accuracy of 0.9562 (95.62 %). Per‑family precision and recall both exceed 0.94, indicating robust discrimination even for families heavily employing obfuscation and packing. Feature‑importance analysis reveals that central and boundary regions of the images—areas that often correspond to executable headers and section delimiters—carry the highest discriminative power. These findings corroborate prior observations that malware families embed characteristic byte‑level signatures in predictable structural locations.
Discussion of Limitations
The authors acknowledge several constraints:
- Resolution Sensitivity – The choice of image size directly influences classification performance; overly coarse images may discard subtle patterns, while excessively fine resolutions increase computational load.
- Runtime Overhead – Converting binaries to images and traversing 500‑tree ensembles can be prohibitive for real‑time endpoint protection, suggesting a need for optimization or lightweight alternatives (e.g., LightGBM, CatBoost).
- Generalization to Unseen Families – The model is trained on a closed set of 25 families; its ability to detect novel or hybrid malware remains untested.
Future Directions
Potential extensions include:
- Dimensionality Reduction – Applying PCA or auto‑encoders before the Random Forest to lower inference latency while preserving salient visual cues.
- Hybrid Feature Fusion – Combining image‑based pixel features with traditional static attributes (header metadata, imported API calls, strings) to build a multimodal classifier that leverages complementary information sources.
- Dynamic‑Analysis Integration – Augmenting the static image pipeline with behavioral traces (e.g., system call sequences) to capture runtime characteristics that static binaries alone cannot reveal.
- Scalable Deployment – Investigating GPU‑accelerated image preprocessing and parallel tree evaluation to meet the throughput demands of large‑scale security operations.
Conclusion
The study demonstrates that a straightforward transformation of malware binaries into visual form, followed by a Random Forest classifier, can achieve high‑accuracy family‑level discrimination without the complexity of deep neural networks. The approach not only mitigates the weaknesses of signature‑based detection but also offers interpretability through feature‑importance metrics. While further work is required to address scalability and generalization, the proposed method constitutes a promising addition to the arsenal of static‑analysis techniques for modern malware defense.
Comments & Academic Discussion
Loading comments...
Leave a Comment