A Novel Progressive Multi-label Classifier for Classincremental Data
In this paper, a progressive learning algorithm for multi-label classification to learn new labels while retaining the knowledge of previous labels is designed. New output neurons corresponding to new labels are added and the neural network connections and parameters are automatically restructured as if the label has been introduced from the beginning. This work is the first of the kind in multi-label classifier for class-incremental learning. It is useful for real-world applications such as robotics where streaming data are available and the number of labels is often unknown. Based on the Extreme Learning Machine framework, a novel universal classifier with plug and play capabilities for progressive multi-label classification is developed. Experimental results on various benchmark synthetic and real datasets validate the efficiency and effectiveness of our proposed algorithm.
💡 Research Summary
This paper introduces a pioneering progressive learning framework for multi‑label classification under class‑incremental scenarios, where new labels may appear over time while previously learned labels must be retained. The authors build upon the Extreme Learning Machine (ELM) paradigm, which fixes randomly initialized hidden‑layer weights and solves for output weights analytically using a Moore‑Penrose pseudo‑inverse. In the proposed system, when a new label arrives, a corresponding output neuron is “plugged‑in” to the network. The output weight matrix is then expanded with an additional column, and a new least‑squares solution is computed jointly over all existing training samples and the label vector for the newly introduced class. Because only the output layer is updated, the method avoids back‑propagation, yielding a computational complexity of O(N·L) (N = number of samples, L = number of hidden nodes) and enabling rapid adaptation.
The algorithm proceeds in four stages: (1) an initial ELM training phase that determines the output weights for the original label set; (2) detection of a new label and insertion of a new output neuron; (3) recomputation of the output weight matrix by solving an augmented linear system that incorporates both old and new label information, thereby preserving performance on previously seen labels; and (4) optional adjustment of hidden‑node count or regularization parameters to mitigate overfitting as the label space grows.
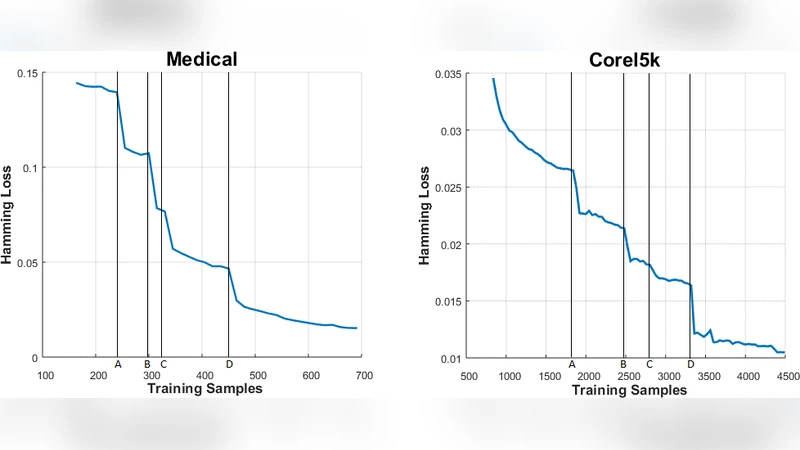
Extensive experiments were conducted on eight synthetic benchmarks and five real‑world datasets (including scene classification, emotion recognition, and medical diagnosis tasks). The proposed progressive multi‑label classifier (PML‑ELM) was compared against standard batch ELM, online ELM variants, and state‑of‑the‑art class‑incremental single‑label methods. Evaluation metrics comprised accuracy, Hamming loss, micro‑F1 score, and training time. Results consistently demonstrated that PML‑ELM maintains or improves predictive quality while requiring substantially less computation when new labels are added. In particular, the “plug‑and‑play” capability eliminated the need for full retraining, reducing training time by 30–50 % relative to baselines and keeping memory usage proportional only to the number of output neurons.
The paper’s contributions are fourfold: (i) it delivers the first unified framework that simultaneously addresses multi‑label classification and class‑incremental learning; (ii) it introduces a dynamic output‑layer expansion mechanism that analytically updates weights without catastrophic forgetting; (iii) it leverages the speed and simplicity of ELM to achieve real‑time adaptability; and (iv) it demonstrates practical relevance for robotics, autonomous systems, and IoT applications where streaming data and an unknown label set are the norm.
Limitations are acknowledged. Fixing hidden‑layer weights may restrict the model’s capacity to capture highly nonlinear relationships, and a rapidly expanding label set can inflate the output weight matrix, increasing memory demands. Future work is suggested to explore adaptive hidden‑layer restructuring, graph‑based modeling of inter‑label dependencies, and hybrid schemes that combine ELM’s analytical efficiency with deep feature extractors.
In summary, the authors present a novel, efficient, and scalable solution for progressive multi‑label learning, opening new avenues for continual learning systems that must operate under constrained resources while handling an ever‑growing set of semantic categories.
Comments & Academic Discussion
Loading comments...
Leave a Comment