Feed-Forward Networks with Attention Can Solve Some Long-Term Memory Problems
We propose a simplified model of attention which is applicable to feed-forward neural networks and demonstrate that the resulting model can solve the synthetic “addition” and “multiplication” long-term memory problems for sequence lengths which are both longer and more widely varying than the best published results for these tasks.
💡 Research Summary
The paper introduces a simplified attention mechanism that can be applied to purely feed‑forward neural networks, enabling them to solve synthetic long‑term memory tasks that traditionally required recurrent architectures. The authors first review the limitations of recurrent neural networks (RNNs), namely vanishing/exploding gradients and the inability to fully parallelize computation across time steps. They then describe the standard attention formulation used in sequence‑to‑sequence models, where a context vector at each time step is a weighted sum of all hidden states.
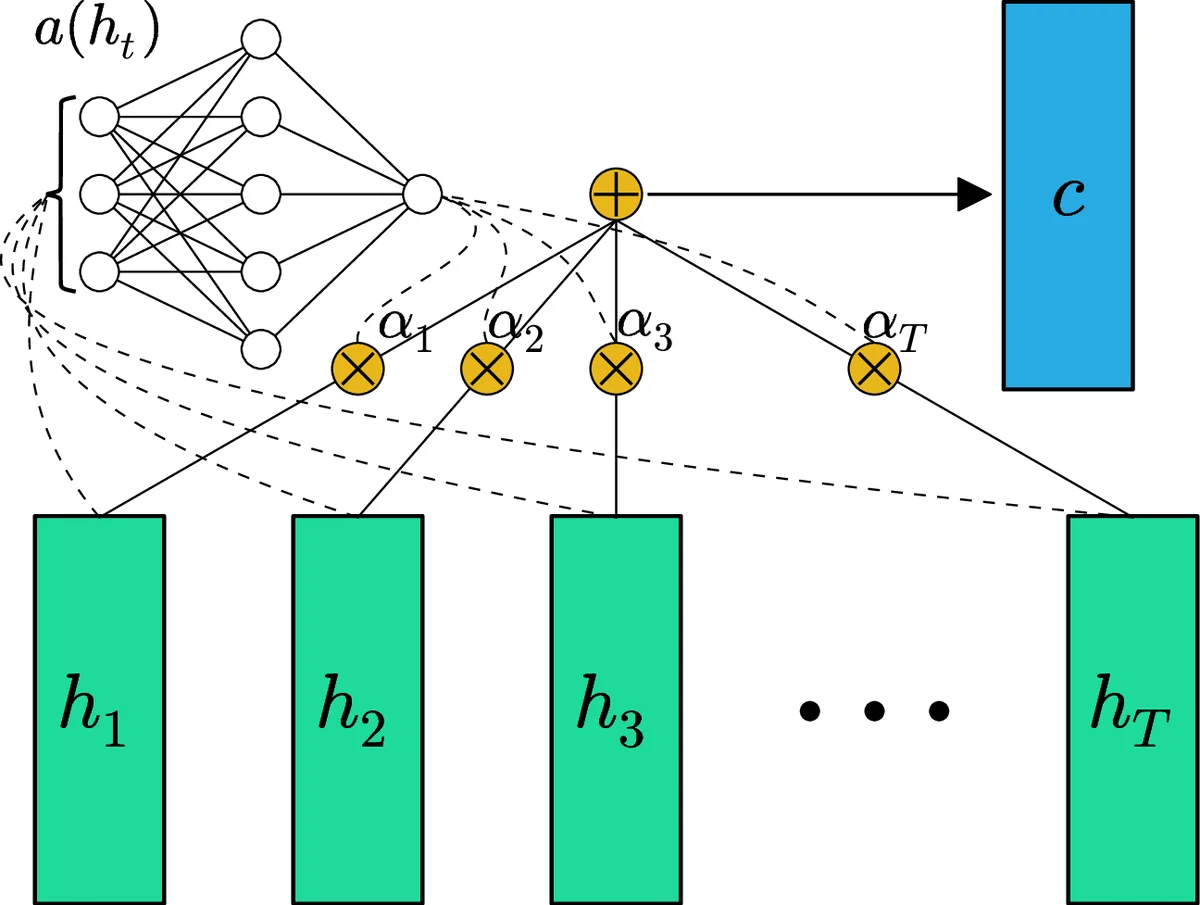
To eliminate recurrence, the authors propose a “feed‑forward attention” where each input token xₜ is transformed independently into a hidden representation hₜ = LReLU(Wₓₕ xₜ + bₓₕ). A learnable scalar score eₜ = a(hₜ) = tanh(Wₕc hₜ + bₕc) is computed for each hₜ, normalized with a softmax to obtain attention weights αₜ = exp(eₜ)/∑ₖexp(eₖ). The entire sequence is then collapsed into a single fixed‑length context vector c = Σₜ αₜ hₜ. This operation is fully parallelizable because it does not depend on previous time steps. The context vector is passed through another linear layer and a Leaky‑ReLU to produce an intermediate vector s, which is finally mapped to a scalar output y via a third linear layer and Leaky‑ReLU. All hidden dimensions are set to D = 100.
Training uses the mean‑squared error between y and the target value, optimized with Adam (β₁ = 0.9, β₂ = 0.999) and learning rates explored in {0.0003, 0.001, 0.003, 0.01}. Weights are initialized with a Gaussian distribution (σ = 1/√N) and biases to zero. Mini‑batches contain 100 sequences; evaluation occurs after each 1,000 parameter updates, and training stops when 100 % test accuracy is reached or after 100 epochs.
The experimental evaluation focuses on the classic “addition” and “multiplication” synthetic tasks introduced by Hochreiter & Schmidhuber (1997). In the fixed‑length setting, sequence lengths T₀ are drawn from {50, 100, 500, 1 000, 5 000, 10 000}, with each sequence length uniformly varied within
Comments & Academic Discussion
Loading comments...
Leave a Comment