A Cheap Linear Attention Mechanism with Fast Lookups and Fixed-Size Representations
The softmax content-based attention mechanism has proven to be very beneficial in many applications of recurrent neural networks. Nevertheless it suffers from two major computational limitations. First, its computations for an attention lookup scale …
Authors: Alex, re de Brebisson, Pascal Vincent
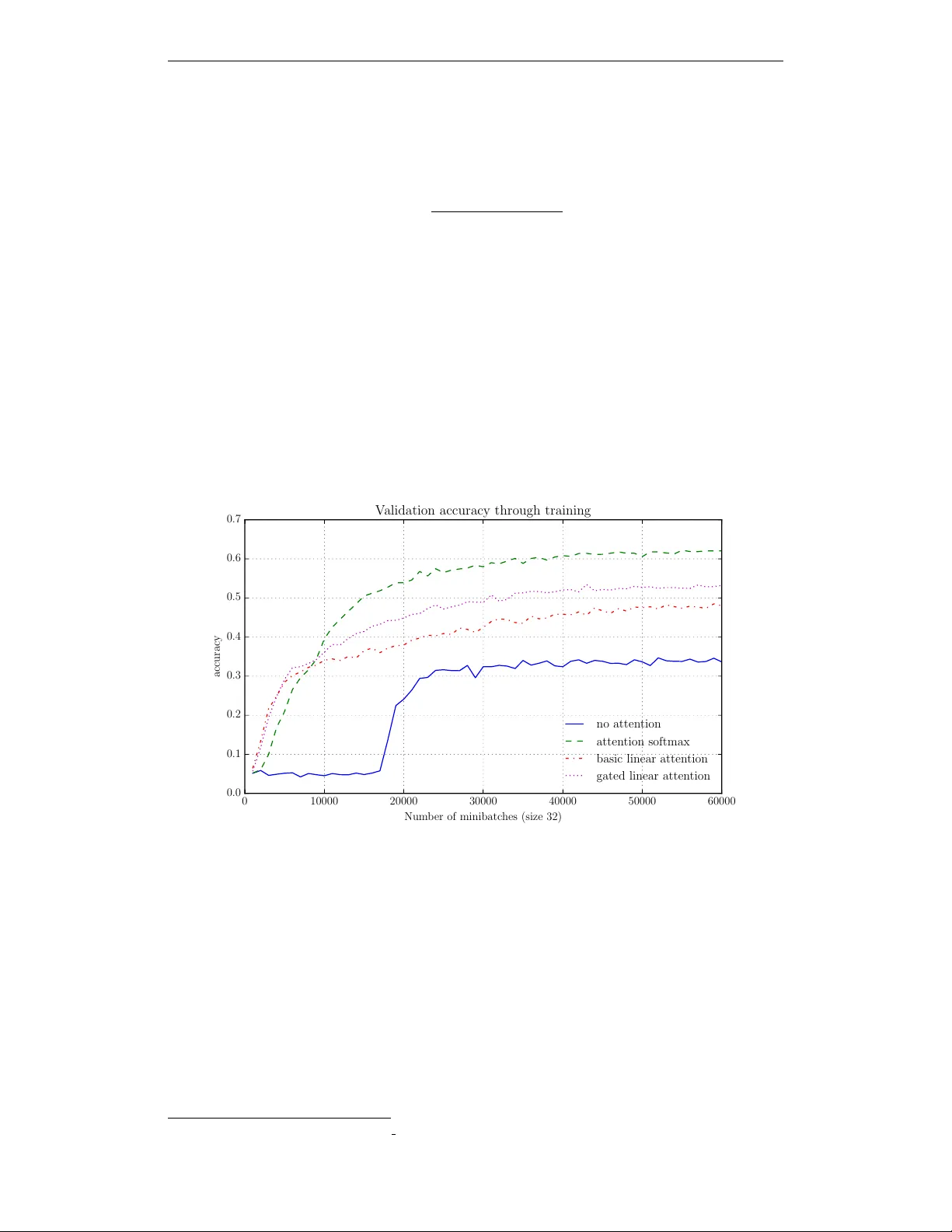
A C H E A P L I N E A R A T T E N T I O N M E C H A N I S M W I T H F A S T L O O K U P S A N D F I X E D - S I Z E R E P R E S E N T A T I O N S Alexandre de Br ´ ebisson MILA, Univ ersity of Montr ´ eal alexandre.de.brebisson@umontreal.ca Pascal V incent MILA, Univ ersity of Montr ´ eal ∗ vincentp@iro.umontreal.ca A B S T R AC T The softmax content-based attention mechanism has prov en to be very benefi- cial in man y applications of recurrent neural networks. Nev ertheless it suffers from two major computational limitations. First, its computations for an attention lookup scale linearly in the size of the attended sequence. Second, it does not encode the sequence into a fixed-size representation but instead requires to mem- orize all the hidden states. These two limitations restrict the use of the softmax attention mechanism to relati vely small-scale applications with short sequences and few lookups per sequence. In this work we introduce a family of linear at- tention mechanisms designed to ov ercome the two limitations listed abov e. W e show that removing the softmax non-linearity from the traditional attention for- mulation yields constant-time attention lookups and fixed-size representations of the attended sequences. These properties make these linear attention mechanisms particularly suitable for large-scale applications with extreme query loads, real- time requirements and memory constraints. Early experiments on a question an- swering task show that these linear mechanisms yield significantly better accuracy results than no attention, but ob viously worse than their softmax alternativ e. 1 I N T RO D U C T I O N Many large-scale applications, in particular among information retriev al tasks, require ef ficient al- gorithms to compress documents and query them. For example, at test time, systems may hav e to process millions of queries simultaneously and in real-time. The content-based attention mecha- nism (Bahdanau et al., 2015) is a recently introduced architecture that allo ws the system to focus on particular parts of the document depending on the query . It has prov en to be very beneficial in many applications of deep learning b ut its expensi ve computations often prev ent it from being used in large-scale applications. In this work we introduce a family of linear attention mechanisms that overcome these limitations and still of fer to some extent the benefits of the traditional attention mechanism. Notations : Let D represent a document sequence of n tokens and let us consider m queries on this document. Let Q represent one of these queries, which is encoded into a column vector representa- tion q (for example the last state of a recurrent neural network). The document D is processed with a recurrent neural network, which, at each timestep t , computes a hidden state h ( t ) of size k . Let H be the n × k matrix composed of all the hidden states of the document D stacked vertically , i.e. whose row H t. = h ( t ) . ∗ and CIF AR 1 2 C L A S S I C S O F T M A X A T T E N T I O N M E C H A N I S M 2 . 1 D E FI N I T I O N A N D C O M P L E X I T Y In this work, we consider the following form of softmax attention mechanism 1 , which computes a representation R ( D , Q ) of the document D conditioned on the question Q : R ( D , Q ) = H T softmax( H q ) , where H q represents the inner products of q with all the hidden states of the document D . The softmax then con verts these inner products into probabilities that are used to compute a weighted sum of the hidden states stacked in H . This mechanism in v olves matrix multiplications which result in an overall O ( nk 2 ) complexity for a single query Q lookup. If, instead of considering a single query , we would like to process m queries, the complexity would be O ( mnk 2 ) . If n or m are very large, this complexity is prohibitiv e and restricts the scale of the potential applications. Furthermore, the classic softmax attention mechanism does not allow to store a fixed-size represen- tation of the document D . Instead, all of the hidden states of the network have to be stored, resulting in a v ariable-size representation that requires O ( nk ) memory space. This can also prohibitiv e when n is large. 2 . 2 A P P L I C A T I O N S O F T H E S O F T M A X A T T E N T I O N M E C H A N I S M S A N D L I M I TA T I O N S In this section, we describe a fe w use cases of the softmax attention mechanism and ho w its compu- tational cost may limit the scale of its applications. • In machine translation (Bahdanau et al., 2015), the document D would be the source sen- tence that has to be translated and which is composed of n words. The translated sentence is generated iterativ ely and at each new timestep, an attention lookup Q is performed. The number of words of the translated sequence is m , which corresponds to the number of re- quired attention lookups. Thus, for each new generated word, a new O ( n ) attention lookup is performed. This may significantly slow down the translation of long sentences (large n and large m ) and pre vent real-time translations. • In question answering (Hermann et al., 2015), the document D is usually a text document of n words. The query Q is a question about the document and there might be m questions per document. In practice, m is undefined. The cost of current softmax attention mechanisms may prev ent real-time question answering from many users. • In information retriev al tasks (such as a search engine), the document D may represent a long sequence (such as a webpage). A query Q could be a single question about a fact im- plicitly contained in one of these documents D . The classic softmax attention mechanism would require scanning all the words of every document D all ov er again for each new searched query . • In network architectures with external memory (Gra ves et al., 2014; Sukhbaatar et al., 2015), D represents the memory to be queried. Current attention mechanism may limit the size of the memory and the number of queries. It seems particularly important to develop more efficient memory mechanisms. One such possibly would be a memory architecture whose memory size does not scale linearly with the number of facts to be stored. Another one would be a linear size memory b ut a sublinear query algorithm. More generally , the softmax attention mechanism is prohibitiv e in large-scale applications which hav e long sequences ( n >> k ), an extremely high amount m of queries (possibly to be processed in 1 Note that this form is found in memory networks (Sukhbaatar et al., 2015) but other forms are common (all with similar complexities and memory requirements), in particular the one introduced by Bahdanau et al. (2015). W e present this particular form because it is the most similar to the cheap mechanism that we introduce in the next section. 2 real-time) and strong memory constraints. There is thus a potential interest for developing cheaper attention mechanisms that would satisfy the follo wing properties: • At test time, a computational complexity independent from the document size n , by op- position to the O ( n ) complexity of current attention mechanisms. Such a cheap attention would hav e very little overhead compared to a recurrent model with no attention (in terms of the sequence size n ). • At test time, a fixed-size representation of the document, by opposition to the O ( n ) memory representations of current attention mechanisms. • At training time, if there are m queries per document, an algorithm which does not scale in O ( nm ) but only in O ( n ) . The linear attention mechanism that we introduce in the next section satisfies these requirements, allowing to potentially tackle problems at a much larger scale. As expected, our early experiments show that these computational gains come at the price of slightly worse accuracy than the softmax attention mechanism, yet definitiv ely better than no attention. 3 C H E A P L I N E A R A T T E N T I O N M E C H A N I S M 3 . 1 D E FI N I T I O N A N D C O M P L E X I T Y In this section, we introduce the simplest version of the linear attention mechanism; more sophisti- cated additions are described in the next section. The linear attention mechanism results from the remov al of the softmax, leading to the following linear attention mechanism: R ( D , Q ) = H T H q = C q , where C = H T H is a square matrix of dimension k × k . C represents a non-centered cov ariance matrix of the hidden states, it is computed in O ( nk 2 ) complexity . Most importantly , it depends only on the document D (not on the query Q ). This implies that if C is computed once, any attention lookup will only cost O ( k 2 ) , i.e. with a comple xity independent from n , the length of the document sequence. For m queries, the resulting attention complexity would be O ( mk 2 ) , i.e. a n speedup compared to the classic softmax attention mechanism ( O ( mnk 2 ) ). Furthermore, each document D can be summarized into the matrix C , i.e a fixed-size representation of size k × k instead of the k × n matrix of hidden states required by the softmax attention. Note that if k > n there is no memory improv ement, in which case it is more suitable to store H rather than the singular matrix C of rank k . Notice that C can be seen as the non-centered covariance matrix of the hidden states. 3 . 2 C O M P U TA T I O N O F C The matrix C is equal to C = H T H . Computing it that way still requires to store all the hidden states h ( t ) and then perform a huge matrix multiplication. T o av oid this O ( n × k ) memory footprint at test time, we can notice that C = H T H = n X t =1 h ( t ) h T ( t ) , which suggests an iterativ e way to compute it: C ( t +1) = C ( t ) + h ( t +1) h T ( t +1) , and C = C ( n ) . This iterativ e process av oids storing all the hidden states and the matrix C can ev entually be computed using only O ( k 2 ) memory space. Although the complexity of computing C is still linear in the size of the sequence n , this compu- tation has to be done only a single time per document, which contrasts with the classic attention mechanism, for which we hav e to scan all over again the document for each ne w query Q . 3 3 . 3 B A C K P RO PAG A T I O N T H RO U G H C Using the iterative procedure to compute C does not require to store all the intermediate C ( t ) during backpropagation. The attention lookup process C q can be written as C q = n X t =1 h ( t ) h T ( t ) q = n X t =1 c ( t ) , where c ( t ) = h ( t ) h T ( t ) q . Naive automatic dif ferentiation tools may sa ve all the states of the matrix C in the forward pass, which is unnecessary gi ven that the corresponding gradient of the loss L with respect to h ( t ) can be written as: ∇ h ( t ) = q h T ( t ) ∇ c ( t ) + ∇ c ( t ) h T ( t ) q , which shows that it is unnecessary to store the intermediate states C ( t ) . 3 . 4 S U M M A RY O F T H E C O M P U TA T I O N A L A D V A N TAG E S T able 1 summarizes the computational and memory benefits of using linear attention mechanisms compared to the original softmax attention. The forward encoding pass is slightly more expensi ve for the linear attention mechanism because it has to perform an outer product at each timestep to update the matrix C . Softmax attention Linear attention a) Query complexity O ( nk ) O ( k 2 ) b) Document compression n × k k × k c) Encoding complexity O ( nk 2 λ ) O ( nk 2 ( λ + 1)) T able 1: Comparison between the traditional softmax mechanism and the linear mechanism of a) the computational cost of an attention lookup, b) the memory requirements to store an encoded document and c) the computational cost of encoding the document ( λ is a constant depending on the type of recurrent unit). 4 G A T E D L I N E A R A T T E N T I O N M E C H A N I S M S W e can generalize the cheap linear attention described pre viously by incorporating non-linear func- tions to update C ( t ) : C ( t +1) = α ( t ) C ( t ) + β ( t ) f ( t ) f T ( t ) , where α ( t ) , β ( t ) and f ( t ) are (non-linear) functions of h ( t +1) and C ( t ) f ( t ) . Their intended functions are described as follows: • The quantity C ( t ) f ( t ) is useful because it measures to some extent how much of f ( t ) is already contained in C ( t ) . Suppose that C ( t ) already contains f ( t ) and only other orthogonal vectors to f ( t ) , then C ( t ) f ( t ) = k f ( t ) k f ( t ) , which giv es information on the presence or not of f ( t ) in the matrix C ( t ) . • α ( t ) and β ( t ) control to what extent the network remembers about the pre vious C ( t ) . • f ( t ) lets the network precisely update certain regions of the matrix C ( t ) . f ( t ) could be the element-wise product of h ( t +1) and a sigmoid whose input is h ( t +1) . Backpropagation requires to know the intermediate values of C ( t ) at each timestep. Instead of storing them in the forward pass, which would be prohibitiv e memory-wise, we can incrementally re- compute each C ( t ) starting from the final matrix C = C ( n ) and in vert the successi ve transformations. 4 If we memorize in the forward pass the values of α ( t ) , β ( t ) , f ( t ) and h ( t ) , we can use them to compute C ( t ) from C ( t +1) : C ( t ) = C ( t +1) − α ( t ) f ( t ) f T ( t ) β ( t ) . Theano implementations of this backward pass and code for the experiments are av ailable on our github repository 2 . In the experiments below , we use a particular instance of the general model abov e, which we call gated linear attention . It is defined by α ( t ) = β ( t ) = 1 and f ( t ) = sigmoid( W h ( t +1) + b ) h ( t +1) , where is the element-wise product. In other words, the network has now the capacity to control the information it adds to the matrix C . The full mechanism can be written as: C ( t +1) = C ( t ) + sigmoid( W h ( t +1) + b ) h ( t +1) sigmoid( W h ( t +1) + b ) h ( t +1) T . 5 E X P E R I M E N T S 0 10000 20000 30000 40000 50000 60000 Num b er of minibatc hes (size 32) 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 accuracy V alidation accuracy through training no atten tion atten tion softmax basic linear atten tion gated linear atten tion Figure 1: Comparison of the validation accuracies obtained with different attention mechanisms on the CNN question-answering dataset. W e observ e a) that as e xpected the softmax attention mechanism yields the best accuracy , b) that the linear mechanisms are significantly better than no attention, c) that the gated linear attention is significantly better than the basic linear attention, d) that models with attention are faster to conv erge, probably due the skip connections introduced by the attention mechanism. The cheap linear attention mechanism is designed for large-scale applications with a v ery lar ge number of queries per document in real-time. Research datasets are not really suitable to highlight their computational efficienc y in practice. Therefore, we focus on comparing their accuracy results. W e ev aluated the basic and gated versions of the linear attention mechanism on a question answering task. W e used the CNN dataset released by Hermann et al. (2015), which is composed of Cloze style questions on documents with n = 750 words on average. There are about m = 4 questions per document. W e did not aim to reach state of the art results but simply to compare the different versions of attention. As such, we used a simple architecture, which only requires a few hours to 2 https://github .com/adbrebs/efficient attention 5 train. W e fixed the architecture for all our experiments and the models only differ by their attention part. More precisely , the common architecture is composed of a single-layer GR U network to encode the query and a separate single-layer GR U network to encode the document 3 . W e used AD AM to train our networks. For the two GRU networks, we chose a small hidden size k = 100 and word embeddings of size 100. At test time, an optimized implementation should yield a speedup of n ∗ k ∗ m m ∗ k 2 = n k ≈ 7 for each attention lookup 4 . Howe ver , at this stage, we are more interested in the accuracy results comparison rather than the speed. The speedup would better be illustrated in applications with a (very) large number of queries per document and relati vely long documents, but such public datasets are still rare. 6 D I S C U S S I O N Our early experiments on question-answering suggest that linear mechanisms and their gated exten- sions significantly improv e models with no attention. As expected, the accuracy results of softmax attention are better but the gap can be reduced when adding non-linear gates to the basic linear mechanism. W e belie ve that more sophisticated e xtensions could further improve the results. In terms of memory , the linear attention mechanisms can be seen as a trade-off between no-attention models and classic softmax models. They compress the document sequence into k × k represen- tations, which can store more information than the k -length vector of the last hidden state of a classic recurrent network, but obviously less than the n × k stored hidden states of a softmax at- tention mechanism. This is probably more suitable for tasks with relativ ely long sequences and an extremely high number of lookups. Nev ertheless, for extremely long sequences, we belie ve that fixed-size representations may not capture enough information and further research should focus on sublinear (maybe O (log ( n )) or adaptative, depending on ho w much information is contained in the sequence) representations. This k × k representation can not only store more information than a k -length vector but it also acts as skip connections from the past hidden states to the output. As a result, we observed that it can capture longer term dependencies and the training optimization is easier because it is less prone to the vanishing gradient problem. A potential extension of this cheap mechanism is to interlea ve the updates of C ( t ) and h ( t ) to create a new flav or of recurrent unit, which uses second order information about the past hidden states ( C ( t ) can be seen as a non-centered cov ariance matrix). The recurrent unit would take as input not only the previous hidden state h ( t − 1) and the current input x ( t ) but also the product C ( t ) h ( t ) which ev aluates to some extent ho w much of h ( t ) is already stored in C ( t ) . 7 C O N C L U S I O N W e introduced a new family of attention mechanisms, called linear attention mechanisms, which, with little computational o verhead, yield better and easier to optimize models compared to standard recurrent networks with no attention. Their constant O ( k 2 ) attention lookup complexity and their O ( k 2 ) memory requirements make them v ery appealing alternati ves to b uild large-scale information retriev al systems, for which the computational costs of traditional softmax attention mechanisms are prohibitiv e. More precisely , we believ e that the linear attention mechanisms would be suitable on large-scale tasks with some of these three properties: • long sequences, long enough so that a recurrent network with no attention is unable to capture long-enough dependencies. 3 Note that for their baseline model without attention, Hermann et al. (2015) concatenated the question and the document. Despite improving a lot the performance, this approach does not allow to compute a represen- tation of the document independent of the query (it requires to know the question in advance). Therefore we encoded the query and the document with two independent networks. 4 These are the complexity gains for the attention lookups only , we do not consider the forward pass neces- sary for both softmax and linear attentions. 6 • many attention lookups, such that traditional softmax attention mechanisms would be too slow . This is particularly important for real-time systems which have to process extremely large loads of queries simultaneously (for e xample millions of queries per hour). • a requirement to store documents into fixed-size representations. R E F E R E N C E S Bahdanau, Dzmitry , Cho, Kyunghyun, and Bengio, Y oshua. Neural machine translation by jointly learning to align and translate. In ICLR’2015, , 2015. Grav es, Alex, W ayne, Greg, and Danihelka, Ivo. Neural turing machines. arXiv preprint arXiv:1410.5401 , 2014. Hermann, Karl Moritz, Ko ˇ cisk ´ y, T om ´ a ˇ s, Grefenstette, Edward, Espeholt, Lasse, Kay , W ill, Suley- man, Mustafa, and Blunsom, Phil. T eaching machines to read and comprehend. In Advances in Neural Information Pr ocessing Systems (NIPS) , 2015. URL 1506.03340 . Sukhbaatar , Sainbayar , szlam, arthur, W eston, Jason, and Fergus, Rob . End-to-end memory net- works. In Cortes, C., La wrence, N. D., Lee, D. D., Sugiyama, M., and Garnett, R. (eds.), Advances in Neural Information Pr ocessing Systems 28 , pp. 2440–2448. Curran Associates, Inc., 2015. URL http://papers.nips.cc/paper/5846- end- to- end- memory- networks. pdf . 7
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment