Left/Right Hand Segmentation in Egocentric Videos
Wearable cameras allow people to record their daily activities from a user-centered (First Person Vision) perspective. Due to their favorable location, wearable cameras frequently capture the hands of the user, and may thus represent a promising user-machine interaction tool for different applications. Existent First Person Vision methods handle hand segmentation as a background-foreground problem, ignoring two important facts: i) hands are not a single “skin-like” moving element, but a pair of interacting cooperative entities, ii) close hand interactions may lead to hand-to-hand occlusions and, as a consequence, create a single hand-like segment. These facts complicate a proper understanding of hand movements and interactions. Our approach extends traditional background-foreground strategies, by including a hand-identification step (left-right) based on a Maxwell distribution of angle and position. Hand-to-hand occlusions are addressed by exploiting temporal superpixels. The experimental results show that, in addition to a reliable left/right hand-segmentation, our approach considerably improves the traditional background-foreground hand-segmentation.
💡 Research Summary
The paper addresses a fundamental limitation in first‑person vision (FPV) research: most existing methods treat the user’s hands as a single foreground object, ignoring the fact that a person typically has two interacting hands that may occlude each other. To overcome this, the authors propose a three‑stage pipeline that produces a left/right (L/R) hand segmentation robust to hand‑hand occlusions, asymmetric hand positions, and objects near the frame borders.
Stage 1 – Binary hand segmentation.
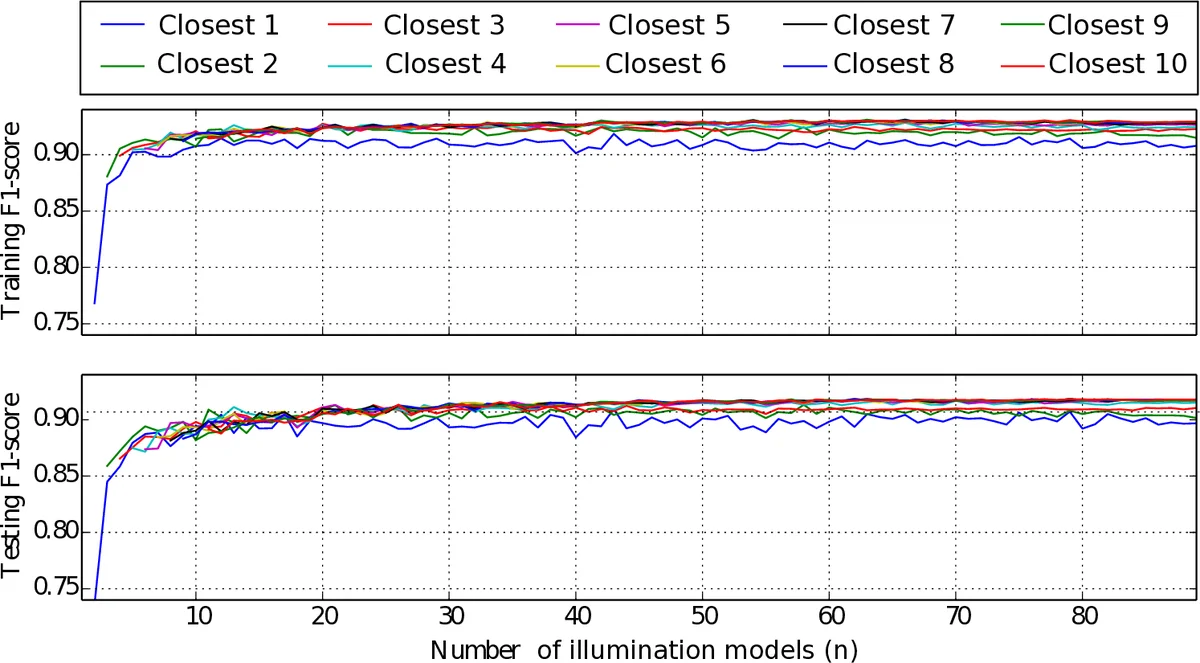
A multi‑model approach builds a pool of illumination‑specific Random Forest classifiers. For each training frame a Random Forest (RF) is trained on pixel‑wise LAB values, and the frame’s HSV histogram is stored as a global feature (GF). At test time the HSV histogram of the current frame is compared to all stored GFs using a K‑Nearest‑Neighbour (KRF) structure; the K most similar illumination models are retrieved. Each of the K RFs produces a binary mask, and the masks are fused by a decaying weight λ = 0.9 (λⁱ = 0.9ⁱ). This weighted averaging yields a segmentation that adapts to lighting changes and improves the F1 score by roughly 10 % over a single‑model baseline.
Stage 2 – Occlusion detection and splitting.
Temporal superpixels are computed across consecutive frames. By tracking the movement of superpixel clusters, the algorithm detects when two clusters merge into a single skin‑like region, indicating a hand‑hand occlusion. A simple set‑algebra test decides whether an occlusion is present (99 % detection accuracy). When occlusion is detected, the superpixel boundaries are used to split the merged mask into two separate hand masks, preserving the spatial detail of each hand.
Stage 3 – Left/right hand identification.
For each hand mask the centroid position (r) and the orientation angle (θ) of the principal axis are extracted. The authors model the joint distribution of (θ, r) for left and right hands using Maxwell distributions, whose parameters are learned from annotated data. Given a new mask, the likelihood under both distributions is computed and a maximum‑likelihood‑ratio test assigns the mask to “left” or “right”. This probabilistic model is robust to asymmetries and to hands appearing near image borders, achieving 99 % identification accuracy on the Kitchen dataset.
Experiments.
The pipeline is evaluated on the publicly available Kitchen dataset and on a self‑collected egocentric video set. Metrics include F1 score for segmentation, occlusion detection rate, hand‑identification accuracy, and processing speed. Results show: (i) an average F1 improvement of about 10 points compared with the state‑of‑the‑art binary segmenter; (ii) 99 % occlusion detection and correct splitting; (iii) 99 % left/right identification; (iv) real‑time performance of 30 FPS when images are resized to a width of 600 px and the Random Forest and superpixel computations are GPU‑accelerated.
Discussion and limitations.
A key strength is the modularity of the three stages: the occlusion detector can be applied to masks generated by any RGB‑D or depth‑aware segmenter, and the identification module can be swapped with a faster detector if occlusions are irrelevant for a specific application. The approach assumes at most one left and one right hand in the field of view and requires an initial frame without occlusion, which limits applicability in multi‑person or crowded scenarios.
Conclusion and future work.
The authors present the first comprehensive L/R hand‑segmentation system for egocentric video that simultaneously improves binary segmentation, resolves hand‑hand occlusions, and reliably labels each hand. Future directions include extending the model to handle multiple interacting people, integrating depth information for more precise occlusion handling, and incorporating temporal motion models to predict hand trajectories for downstream tasks such as activity recognition or rehabilitation monitoring.
Comments & Academic Discussion
Loading comments...
Leave a Comment