A Large Scale Corpus of Gulf Arabic
Most Arabic natural language processing tools and resources are developed to serve Modern Standard Arabic (MSA), which is the official written language in the Arab World. Some Dialectal Arabic varieties, notably Egyptian Arabic, have received some attention lately and have a growing collection of resources that include annotated corpora and morphological analyzers and taggers. Gulf Arabic, however, lags behind in that respect. In this paper, we present the Gumar Corpus, a large-scale corpus of Gulf Arabic consisting of 110 million words from 1,200 forum novels. We annotate the corpus for sub-dialect information at the document level. We also present results of a preliminary study in the morphological annotation of Gulf Arabic which includes developing guidelines for a conventional orthography. The text of the corpus is publicly browsable through a web interface we developed for it.
💡 Research Summary
The paper addresses the scarcity of computational resources for Gulf Arabic (GA), a dialect spoken across the six Gulf Cooperation Council (GCC) countries. While Modern Standard Arabic (MSA) enjoys extensive corpora and tools, and Egyptian Arabic has received growing attention, GA has lagged behind. To fill this gap, the authors introduce the Gumar Corpus, a large‑scale collection of 1,200 online “forum novels” amounting to approximately 110 million words, 9.3 million sentences, and over 1,200 documents.
The corpus was assembled by automatically crawling publicly posted, anonymously authored, long‑form conversational novels from a single web portal. Each novel is stored as an MS‑Word file, preserving the original formatting. The authors performed document‑level annotation of sub‑dialect information (Saudi, Emirati, Kuwaiti, etc.), novel title, and author pseudonym. Dialect identification relied on explicit statements, place names, character names, cultural markers (e.g., Hijri dates), and lexical cues characteristic of each regional variety.
A major contribution is the extension of the Conventional Orthography for Dialectal Arabic (CODA) to cover GA. Existing CODA rules were designed for Egyptian Arabic and later adapted to other dialects, but GA exhibits unique phonological phenomena such as /q/ → /g/ or /dz/, interdental /t/ and /d/, and the preservation of pharyngealized fricatives. The authors added a set of GA‑specific normalization rules, enabling consistent spelling across the heterogeneous source material.
For morphological annotation, the authors leveraged the MADAMIRA‑EGY analyzer as a baseline, applying the GA‑adapted CODA preprocessing before feeding text to the analyzer. They reported initial annotation statistics, noting typical GA features: loss of case inflection, cliticized future markers (/ba/ instead of MSA /sa/), gender‑specific plural forms in some varieties, and extensive borrowing from English, Persian, and Hindi. An evaluation comparing automatic output to a small manually annotated sample showed that CODA‑based normalization improves tagging accuracy by roughly 10–15 % relative to raw input.
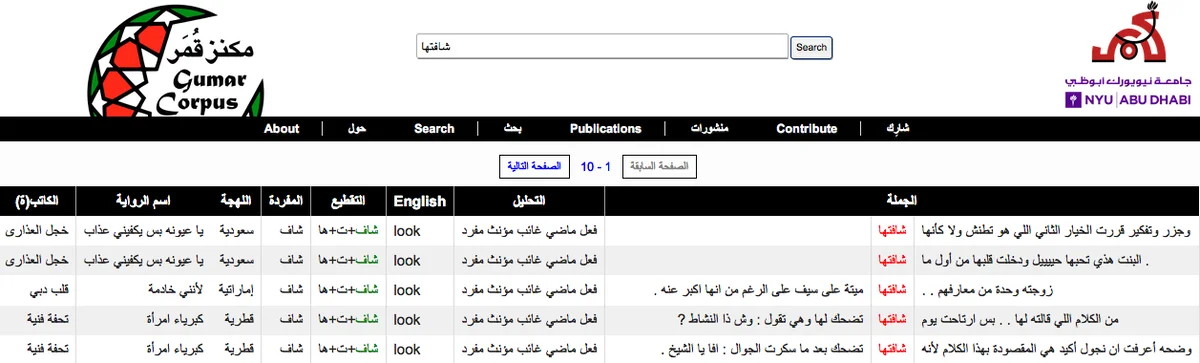
The paper also describes a web‑based interface that allows researchers to browse, filter (by dialect, country, author), and download the corpus in both raw and normalized forms. This public accessibility is intended to stimulate further work on GA, including the creation of dialect‑specific morphological lexicons, syntactic treebanks, machine translation models, and spell‑checking tools.
In the discussion, the authors contrast Gumar with earlier GA resources such as the Emirati Arabic Corpus (2 M words, speech‑oriented) and EMALAC (78 K words, child language). Gumar is distinguished by its focus on adult‑written prose, its multi‑dialect coverage, and its scale. The paper concludes with future directions: expanding manual morphological annotation, building parallel corpora across dialects, training deep neural models for GA, and investigating sociolinguistic patterns evident in the novels (e.g., name selection, gender representation). Overall, the Gumar Corpus represents a significant step toward bringing Gulf Arabic into the mainstream of Arabic NLP research.
Comments & Academic Discussion
Loading comments...
Leave a Comment