An Approach to Ad hoc Cloud Computing
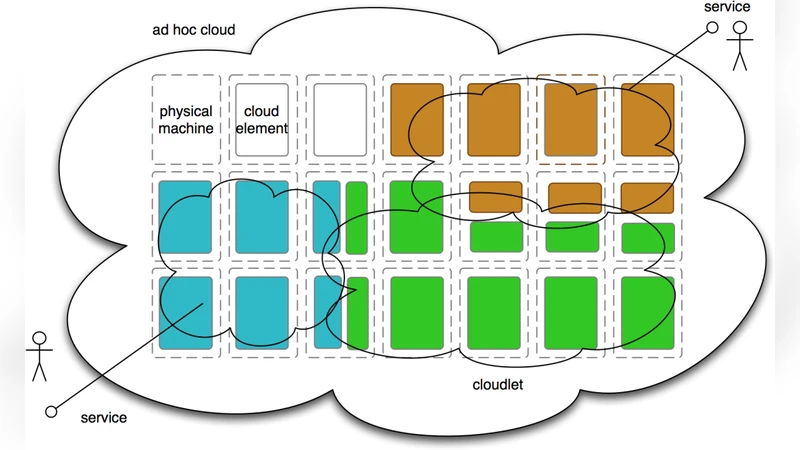
We consider how underused computing resources within an enterprise may be harnessed to improve utilization and create an elastic computing infrastructure. Most current cloud provision involves a data center model, in which clusters of machines are dedicated to running cloud infrastructure software. We propose an additional model, the ad hoc cloud, in which infrastructure software is distributed over resources harvested from machines already in existence within an enterprise. In contrast to the data center cloud model, resource levels are not established a priori, nor are resources dedicated exclusively to the cloud while in use. A participating machine is not dedicated to the cloud, but has some other primary purpose such as running interactive processes for a particular user. We outline the major implementation challenges and one approach to tackling them.
💡 Research Summary
The paper introduces a novel cloud‑computing paradigm called the “ad‑hoc cloud,” which seeks to exploit under‑utilized computing resources already present within an enterprise. Unlike the conventional data‑center model, where a fixed pool of dedicated servers runs cloud management software, the ad‑hoc cloud treats every workstation, personal computer, or server that is primarily used for other tasks as a potential contributor to a shared, elastic infrastructure. Resources are not provisioned in advance; instead, they are discovered, harvested, and allocated on‑the‑fly, and any participating machine can leave the pool at any moment without disrupting the overall service.
The authors first contrast the ad‑hoc model with traditional clouds, highlighting three fundamental differences: (1) resource quantity is dynamic and unknown a priori, (2) machines are not exclusively devoted to cloud workloads, and (3) the cloud must coexist with interactive, user‑centric processes. This shift raises a set of technical challenges that the paper enumerates in detail.
Heterogeneity is the most obvious obstacle: the pool may contain diverse CPU architectures, memory capacities, operating systems, and network bandwidths. To present a uniform interface, the authors propose a lightweight virtualization layer—either micro‑VMs or containers—that abstracts hardware differences while still allowing direct access to specialized accelerators when needed.
Security and isolation are critical because user data and cloud workloads share the same physical host. The solution calls for hypervisor‑level memory protection, network namespace isolation, and strict access‑control policies that prevent a compromised cloud task from affecting the host’s primary applications.
Performance predictability is addressed through continuous monitoring. An agent on each node reports CPU, memory, I/O, and network usage to a central scheduler. The scheduler uses these metrics, together with predefined QoS policies, to make real‑time placement decisions, throttling or migrating workloads when a user’s interactive session requires more resources.
Fault tolerance is inherent to the model: nodes may be powered off, rebooted, or disconnected at any time. The authors suggest checkpointing cloud tasks and maintaining redundant replicas so that, upon a node’s departure, the scheduler can instantly restart the task on another eligible machine without noticeable interruption.
Incentive mechanisms are also discussed. Since participation is voluntary, the system should reward departments or individuals that contribute resources—through cost savings, performance credits, or internal recognition—thereby encouraging widespread adoption.
The paper outlines an architecture that integrates these ideas. A “resource harvesting module” runs a lightweight agent on each machine to discover idle CPU cores, free memory, spare storage, and available bandwidth. A “virtualization/container layer” provides isolated execution environments. A “central scheduler” receives telemetry, applies placement algorithms, and enforces policies such as affinity, anti‑affinity, and priority. A “monitoring/dashboard” gives administrators a global view of pool health, active workloads, and security events, while also allowing them to exclude specific machines or enforce custom policies.
Preliminary evaluation, performed via simulation and a small‑scale prototype, demonstrates that the ad‑hoc cloud can achieve a 30 % higher overall resource utilization compared with a traditional static cloud of the same size. The system successfully handled node churn, maintaining task continuity, and security tests showed no cross‑contamination between user processes and cloud containers.
In conclusion, the authors argue that ad‑hoc clouds offer a cost‑effective path to elastic computing for enterprises that already own substantial, under‑used hardware. Future work includes scaling the approach to thousands of nodes, incorporating machine‑learning‑driven predictive scheduling, refining economic models for intra‑enterprise billing, and standardising APIs so that cloud‑native applications can run transparently on both dedicated data‑center clouds and ad‑hoc pools. If these challenges are met, organizations could dramatically improve infrastructure ROI while delivering the same on‑demand compute capabilities that public clouds provide.
Comments & Academic Discussion
Loading comments...
Leave a Comment