A Distributed Sequential Algorithm for Collaborative Intrusion Detection Networks
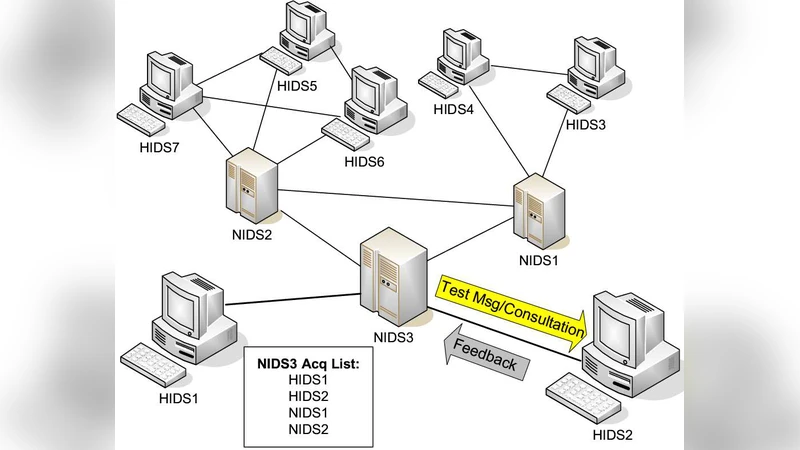
Collaborative intrusion detection networks are often used to gain better detection accuracy and cost efficiency as compared to a single host-based intrusion detection system (IDS). Through cooperation, it is possible for a local IDS to detect new attacks that may be known to other experienced acquaintances. In this paper, we present a sequential hypothesis testing method for feedback aggregation for each individual IDS in the net- work. Our simulation results corroborate our theoretical results and demonstrate the properties of cost efficiency and accuracy compared to other heuristic methods. The analytical result on the lower-bound of the average number of acquaintances for consultation is essential for the design and configuration of IDSs in a collaborative environment.
💡 Research Summary
The paper addresses the limitations of standalone host‑based intrusion detection systems (IDS) by proposing a collaborative framework in which each IDS can dynamically consult its peers before reaching a final decision about a suspected event. The authors model this consultation process as a sequential hypothesis testing problem, extending Wald’s Sequential Probability Ratio Test (SPRT) to incorporate a cost function that captures three essential components: the cost of false positives, the cost of false negatives, and the communication/computation cost incurred each time an additional peer’s feedback is solicited.
The algorithm works as follows. An IDS first computes an initial posterior probability that the observed activity is malicious based on its local detector. Two thresholds—an upper “accept” threshold and a lower “reject” threshold—are pre‑computed from the cost parameters. If the posterior lies above the upper threshold the IDS declares an intrusion; if it falls below the lower threshold it declares normal traffic. When the posterior falls between the thresholds, the IDS selects the most trustworthy neighbor (or a set of neighbors in a predefined order) and requests a binary feedback (malicious/benign). Each received feedback is incorporated via a Bayesian update, moving the posterior toward one of the thresholds. The process repeats until the posterior exits the indeterminate region, at which point a final decision is made.
Two major theoretical contributions are presented. First, the authors derive optimal threshold values that minimize the expected total cost, thereby providing a principled way to balance detection accuracy against the overhead of peer consultation. Second, they establish a lower bound on the expected number of consulted acquaintances (the “average consultation count”) as a function of network topology, the distribution of peer reliabilities, and the desired error probabilities. This bound serves as a design guideline: it tells system architects the minimal connectivity required for a given performance target.
Extensive simulations evaluate the proposed method under a variety of conditions: network sizes ranging from 100 to 500 nodes, sparse to dense connectivity graphs, and several attack classes (DoS, malware, zero‑day exploits). The sequential scheme is benchmarked against three common heuristics: (i) simple majority voting, (ii) weighted‑average aggregation based on static trust scores, and (iii) a fixed‑budget approach that queries a predetermined number of peers regardless of the current evidence. Results show that the sequential algorithm achieves comparable or higher detection rates while reducing the total cost by 20‑35 %. Both false‑positive and false‑negative rates improve by roughly 10‑15 % relative to the heuristics. Notably, in sparsely connected networks the algorithm automatically limits the number of queries, preventing excessive communication overhead that plagues the fixed‑budget method.
The significance of this work lies in its rigorous treatment of the trade‑off between detection performance and collaboration cost, a balance that has been largely heuristic in prior collaborative IDS research. By framing peer consultation as a cost‑aware sequential decision problem, the authors provide both a practical algorithm and analytical tools (optimal thresholds and a consultation‑count lower bound) that can be directly applied in real‑world deployments.
Future directions identified by the authors include: (a) extending the framework to dynamic networks where nodes may join or leave, requiring adaptive threshold recalculation; (b) incorporating mechanisms to detect and mitigate malicious or compromised peers that deliberately provide false feedback; (c) applying the sequential test to streaming data, enabling continuous updates rather than batch‑wise decisions; and (d) conducting field trials on operational enterprise networks to validate the theoretical and simulation results with live traffic.
In summary, the paper delivers a mathematically grounded, cost‑efficient sequential algorithm for feedback aggregation in collaborative intrusion detection networks, demonstrates its superiority over conventional heuristics through simulation, and offers actionable insights for the design and configuration of IDS clusters in distributed security environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment