Entity Embedding-based Anomaly Detection for Heterogeneous Categorical Events
Anomaly detection plays an important role in modern data-driven security applications, such as detecting suspicious access to a socket from a process. In many cases, such events can be described as a collection of categorical values that are considered as entities of different types, which we call heterogeneous categorical events. Due to the lack of intrinsic distance measures among entities, and the exponentially large event space, most existing work relies heavily on heuristics to calculate abnormal scores for events. Different from previous work, we propose a principled and unified probabilistic model APE (Anomaly detection via Probabilistic pairwise interaction and Entity embedding) that directly models the likelihood of events. In this model, we embed entities into a common latent space using their observed co-occurrence in different events. More specifically, we first model the compatibility of each pair of entities according to their embeddings. Then we utilize the weighted pairwise interactions of different entity types to define the event probability. Using Noise-Contrastive Estimation with “context-dependent” noise distribution, our model can be learned efficiently regardless of the large event space. Experimental results on real enterprise surveillance data show that our methods can accurately detect abnormal events compared to other state-of-the-art abnormal detection techniques.
💡 Research Summary
This paper tackles the problem of detecting anomalous events in domains where each observation consists of a collection of heterogeneous categorical attributes—so‑called heterogeneous categorical events. Typical examples include system logs that record a user, timestamp, source process, destination process, file paths, IP addresses, etc. Existing approaches largely rely on heuristic scoring functions because (1) categorical entities lack intrinsic distance or similarity measures, and (2) the combinatorial event space grows exponentially with the number of attribute types, making probabilistic modeling intractable.
The authors propose a unified probabilistic framework named APE (Anomaly detection via Probabilistic pairwise interaction and Entity embedding). The core ideas are:
-
Entity Embedding – Every distinct entity (e.g., a specific user ID, a particular process name) is represented as a d‑dimensional real‑valued vector v. All entities, regardless of type, share the same latent space, allowing natural similarity computation via dot product or Euclidean distance.
-
Weighted Pairwise Interactions – For an event e = (a₁,…,a_m) the model defines a scoring function
Sθ(e) = Σ_{i<j} w_{ij} (v_{a_i}·v_{a_j})
where w_{ij} ≥ 0 is a learnable weight that reflects the importance of the interaction between attribute types A_i and A_j. This formulation captures the compatibility of each pair of entities while avoiding the combinatorial explosion of higher‑order interactions. -
Probabilistic Model – The event probability is expressed as a softmax over the entire event space Ω:
Pθ(e) = exp(Sθ(e) + c) / Σ_{e’∈Ω} exp(Sθ(e’) + c)
where c is a global log‑partition constant. Direct computation of the denominator is impossible because |Ω| ≈ exp(m). -
Learning via Noise‑Contrastive Estimation (NCE) – To sidestep the normalizing constant, the authors adopt NCE, which turns density estimation into a binary classification problem between real data and artificially generated noise. A novel “context‑dependent” noise distribution is introduced: for each observed event, one attribute type is chosen uniformly, and its value is replaced by a randomly sampled alternative from the same type’s unigram distribution. This yields a negative sample that differs from the original event by only a single entity, keeping the noise distribution close to the data distribution and facilitating efficient learning. Because the exact noise probability is intractable, the authors approximate log k P_n(e’) by log P_{A_i}(a’_i) plus a constant, which can be ignored during optimization.
-
Optimization – The objective combines the log‑sigmoid terms for positive and negative samples, and stochastic gradient descent updates the embeddings v, interaction weights w, and the global constant c. The computational complexity per epoch is O(N k m² d), where N is the number of observed events, k is the number of negative samples per event, m is the number of attribute types, and d is the embedding dimension. Hence the method scales linearly with the dataset size despite the exponential event space.
Experimental Evaluation – Two real‑world enterprise log datasets are used:
- P2P (Process‑to‑Process) – Contains events describing interactions between processes, together with day, hour, user ID, source/destination processes, and folder paths.
- P2I (Process‑to‑Internet) – Records process‑initiated network connections, including day, hour, source IP, destination IP, destination port, process, folder, user ID, and connection type.
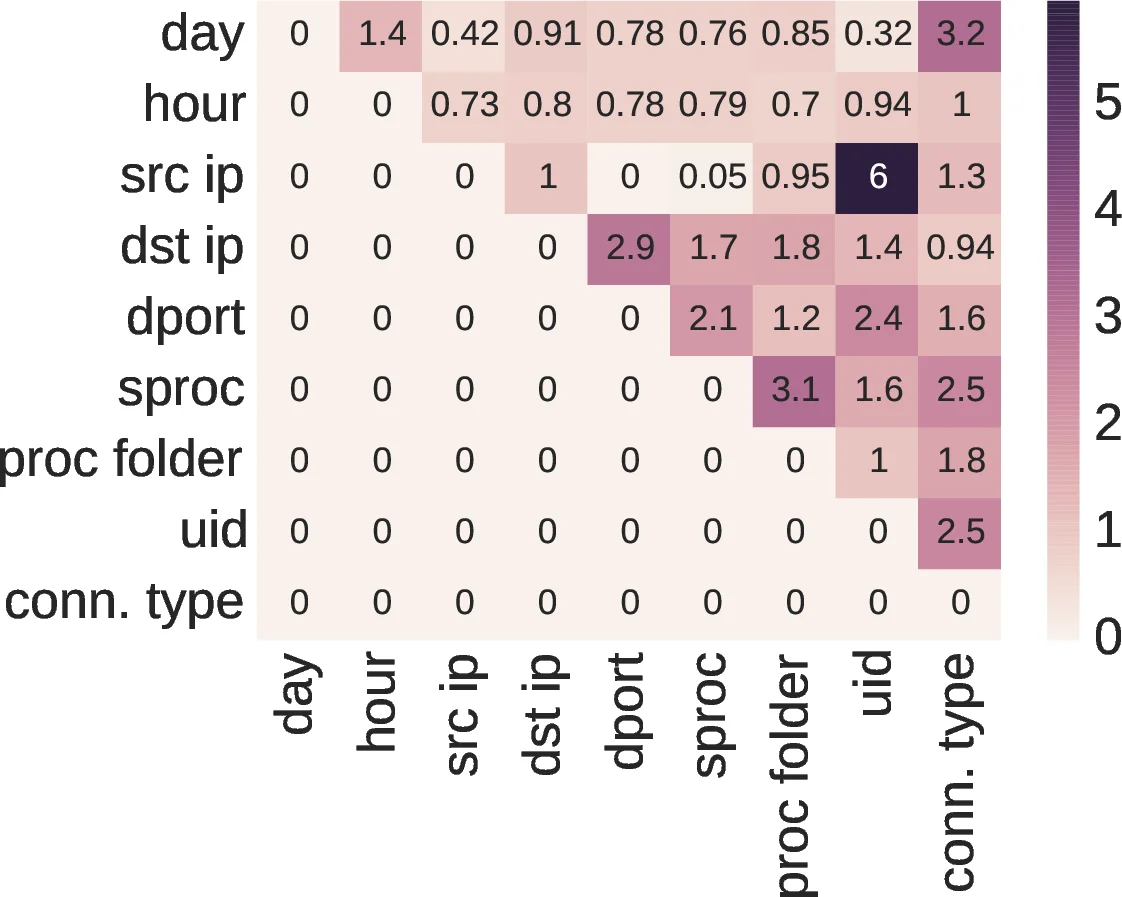
Both datasets have hundreds to thousands of distinct entities per attribute type. Ground‑truth anomaly labels are unavailable; the authors assume the majority of events are normal and treat low‑probability events as anomalies. Baselines include histogram‑based methods, Bayesian networks, and graph‑based anomaly detectors. APE consistently outperforms these baselines in precision, recall, and area‑under‑ROC, demonstrating the benefit of learned embeddings and weighted pairwise interactions. Moreover, inspection of the learned w_{ij} values reveals interpretable patterns: for instance, unusually high weights on “user–high‑privilege process” or “midnight–maintenance process” pairs correspond to known suspicious behaviors.
Contributions – The paper makes three primary contributions:
- A principled way to embed heterogeneous categorical entities into a common latent space, thereby providing a natural similarity measure.
- A weighted pairwise interaction model that balances expressiveness and over‑fitting risk while offering interpretability.
- A context‑dependent NCE training scheme that enables efficient learning despite the astronomically large event space.
Future Directions – The authors suggest extending the model to capture non‑linear interactions (e.g., via neural networks), incorporating temporal dynamics for sequential anomaly detection, and applying the framework to other domains such as financial transactions or social networks.
In summary, the paper presents a solid probabilistic foundation for anomaly detection on heterogeneous categorical data, demonstrates scalable learning through a clever NCE variant, and validates its effectiveness on real enterprise surveillance logs, offering a promising tool for security analysts and data scientists dealing with complex categorical event streams.
Comments & Academic Discussion
Loading comments...
Leave a Comment