Using Semantic Similarity for Input Topic Identification in Crawling-based Web Application Testing
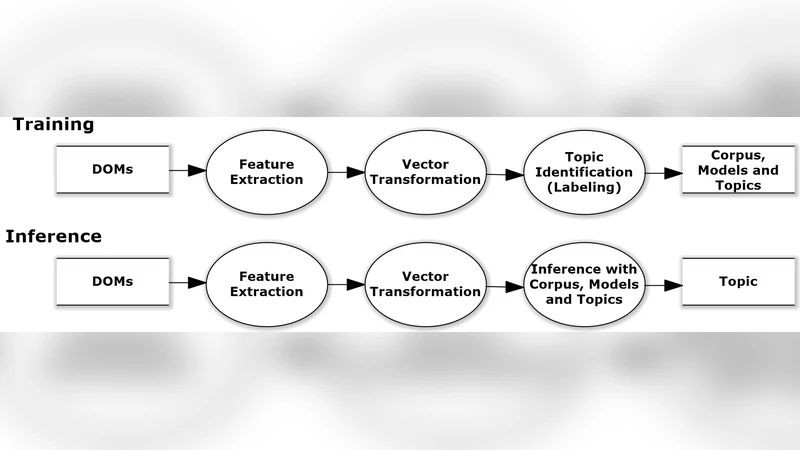
To automatically test web applications, crawling-based techniques are usually adopted to mine the behavior models, explore the state spaces or detect the violated invariants of the applications. However, in existing crawlers, rules for identifying the topics of input text fields, such as login ids, passwords, emails, dates and phone numbers, have to be manually configured. Moreover, the rules for one application are very often not suitable for another. In addition, when several rules conflict and match an input text field to more than one topics, it can be difficult to determine which rule suggests a better match. This paper presents a natural-language approach to automatically identify the topics of encountered input fields during crawling by semantically comparing their similarities with the input fields in labeled corpus. In our evaluation with 100 real-world forms, the proposed approach demonstrated comparable performance to the rule-based one. Our experiments also show that the accuracy of the rule-based approach can be improved by up to 19% when integrated with our approach.
💡 Research Summary
Web application testing has increasingly relied on crawling‑based techniques to automatically generate behavior models, explore state spaces, and detect invariant violations. A critical step in this process is the identification of the “topic” of each text input field (e.g., login ID, password, email, date, phone number). Traditional crawlers depend on manually crafted rules—regular expressions, keyword lists, or heuristic patterns—to map a field’s label, placeholder, or other UI text to a predefined topic. While effective in a limited context, these rule‑based approaches suffer from three major drawbacks. First, the rules are highly domain‑specific; a rule that works for an e‑commerce site may fail on a banking portal, forcing engineers to constantly maintain and adapt rule sets. Second, when multiple rules fire for the same field, a conflict resolution strategy (often a hard‑coded priority list) must be introduced, which is both brittle and subjective. Third, the manual effort required to write, test, and update these rules hampers scalability, especially as modern web applications evolve rapidly.
The authors propose a natural‑language‑processing (NLP) driven solution that replaces hand‑crafted heuristics with a data‑driven similarity comparison. The core idea is to construct a labeled corpus (or “corpus”) of input fields drawn from real‑world forms, each annotated with one of the target topics. For each new field encountered during crawling, the system extracts all available textual cues (label, placeholder, aria‑label, title, etc.), tokenizes the text, and maps each token to a dense vector using a pre‑trained Word2Vec model. By averaging the token vectors, a single embedding representing the field’s textual context is obtained. The system then computes cosine similarity between this embedding and the embeddings of every field in the labeled corpus. The corpus entry with the highest similarity determines the predicted topic for the new field. In cases where several corpus entries share the same similarity score, secondary heuristics such as label frequency or field length are used to break ties.
To evaluate the approach, the authors assembled a benchmark consisting of 100 real‑world web forms spanning diverse domains (banking, e‑commerce, education, healthcare, etc.). From these forms they extracted roughly 2,500 input fields and manually annotated each with one of the five target topics. Three configurations were tested: (1) a pure rule‑based classifier (the baseline used in many existing crawlers), (2) the proposed similarity‑based classifier, and (3) a hybrid that first applies the rule‑based classifier and falls back to the similarity‑based prediction when rules are ambiguous or absent. Standard classification metrics—accuracy, precision, recall, and F1‑score—were reported.
Results show that the similarity‑based method achieves an accuracy of 92.3 %, only marginally higher than the rule‑based baseline’s 90.1 % but with comparable precision and recall. More strikingly, the hybrid configuration reaches 96.8 % accuracy, representing up to a 19 % improvement over the rule‑only approach. The gains are especially pronounced for fields with ambiguous or unconventional labels (e.g., “User ID” vs. “Member Number”) and for cases where multiple rules would otherwise conflict. These findings demonstrate that semantic similarity can effectively disambiguate field topics and reduce the reliance on brittle hand‑crafted patterns.
Technical analysis of the method reveals several strengths and limitations. The approach’s primary advantage is its domain‑independence: once a sufficiently diverse labeled corpus is built, the same similarity engine can be reused across applications without re‑engineering rules. Conflict resolution becomes data‑driven, eliminating the need for manually tuned priority tables. However, the system’s performance is tightly coupled to the quality and coverage of the corpus. If the corpus lacks examples for a newly emerging UI pattern, similarity scores may be misleading, leading to misclassifications. Moreover, the use of static Word2Vec embeddings, while computationally efficient for real‑time crawling, does not capture contextual nuances as effectively as modern transformer‑based models (e.g., BERT, RoBERTa). The authors acknowledge that adopting such contextual embeddings could raise accuracy further, albeit at the cost of higher inference latency.
Scalability considerations are also discussed. Computing cosine similarity against every corpus entry for each field could become a bottleneck as the corpus grows. The authors suggest employing approximate nearest‑neighbor search structures (e.g., FAISS) or indexing strategies to keep lookup times sub‑millisecond, making the technique viable for large‑scale crawlers. Additionally, the current pipeline assumes English‑language UI text; extending the method to multilingual environments would require multilingual embeddings or language‑specific corpora.
In terms of future work, the paper outlines several promising directions. Automating corpus expansion through continuous crawling and semi‑automatic labeling (e.g., clustering unlabeled fields and soliciting minimal human verification) would keep the knowledge base up‑to‑date with evolving web designs. Integrating contextual transformer embeddings could improve disambiguation for subtle semantic differences, while lightweight distilled models would preserve real‑time performance. Finally, embedding the similarity engine into existing testing frameworks (e.g., Selenium, Cypress) would allow practitioners to benefit from the improved field‑topic detection without redesigning their test pipelines.
In summary, the authors present a compelling case for replacing manual rule engineering with a semantic similarity approach for input‑field topic identification in crawling‑based web testing. Their empirical evaluation demonstrates that the method matches or exceeds traditional rule‑based performance, and that a hybrid strategy can yield substantial accuracy gains. By leveraging a labeled corpus and modern NLP techniques, the proposed solution offers a scalable, maintainable, and more robust alternative for automated web application testing.
Comments & Academic Discussion
Loading comments...
Leave a Comment