Local Network Community Detection with Continuous Optimization of Conductance and Weighted Kernel K-Means
Local network community detection is the task of finding a single community of nodes concentrated around few given seed nodes in a localized way. Conductance is a popular objective function used in many algorithms for local community detection. This …
Authors: Twan van Laarhoven, Elena Marchiori
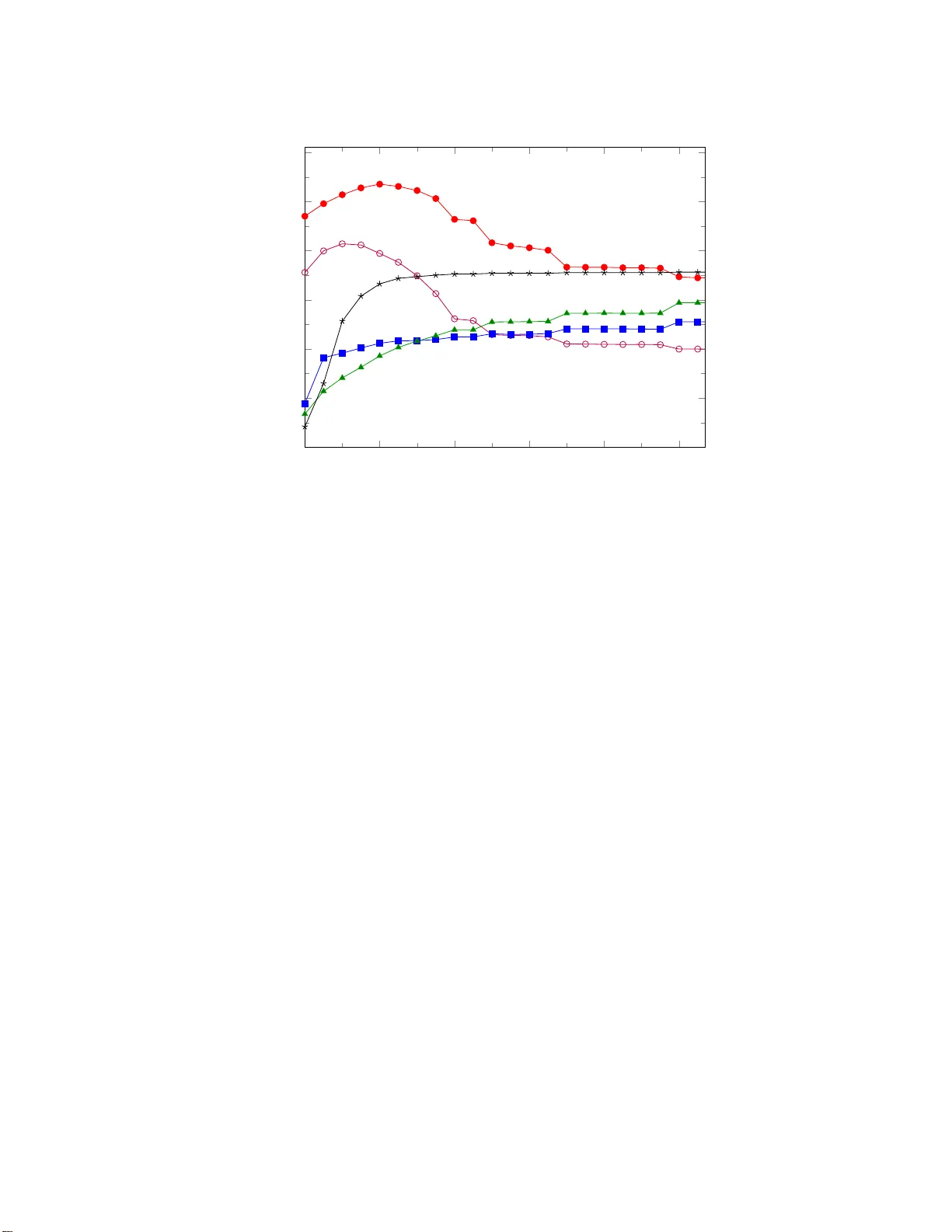
Journal of Mac hine Learning Researc h 17 (2016) 1-28 Submitted 12/15; Revised 6/16; Published 8/16 Lo cal Net w ork Comm un i t y Detection with Con tin uous Optimization of Conductance and W eigh ted Kernel K-Means Tw an v an Laarho v en tv anlaarhoven@cs.r u.nl Elena Marc hiori elenam@cs.ru.nl Institute for Computing and Information Scienc es R adb oud University Nijme gen Postbus 9010 6500 GL Nijme gen, The Netherlands Editor: Jure Lesk ov ec Abstract Lo cal netw ork comm unity detection is the task of finding a single communit y of nodes concentrated a round few given seed no des in a lo calized wa y . Conductance is a p opular ob jective function used in ma n y a lgorithms for lo cal co mmunit y detection. This pap er studies a cont inuous relaxatio n of conductance. W e show that contin uous o pt imization of this o b jectiv e still leads to discrete co mm unities. W e investigate the relatio n o f conduc- tance with weigh ted kernel k-means for a single communit y , which leads to the in tro duction of a new ob jective function, σ -conductance. Conductance is obtained by s e t ting σ to 0. Two algo r ithms, EMc a nd PG Dc , are prop osed to lo cally optimize σ -conductance and automatically tune the par ameter σ . They are ba sed o n e xpectation maximiza tion and pro jected gr adien t desce nt, resp ectiv ely . W e prov e lo calit y and give p erformance guar- antees for EMc and PGDc for a class of dense and well separated commu nities centered around the seeds. Exp eriment s are conducted on netw orks with ground-tr uth comm unities, comparing to state-of-the-art graph diffusion algorithms for conducta nce o ptim ization. O n large graphs, re s ult s indicate that EMc and PGDc sta y localized and pro duce communities most similar to the ground, while g raph diffusion a lgorithms genera te large communities of low er quality . 1 Keyw ords: communit y detection, sto c hastic blo c k mo del, conductance 1. In tro duction Imagine that you are trying to find a comm unit y of n odes in a net w ork around a give n set of n odes. A simple wa y to app roa c h this problem is to consider this set as seed no des, and then k eep addin g no des in a lo cal neigh b orho od of the seeds as long as this mak es the communit y b etter in some sense. In contrast to global clustering, where the o v erall comm unit y structure of a net w ork has to b e found , lo ca l comm unit y detection aims to find only one comm unity around the giv en s e eds by relying on lo cal computations inv olving only no des relativ ely close to the seed. Lo cal comm unit y detection b y seed expansion is 1. Source code of the algorithms used in the paper is a vai lable a t http://cs. ru.nl/ ~ tvanlaarho ven/conducta nce2016 . c 2016 Tw an v an Laarho v en and Elena Marchiori. v an Laarhoven and Marchiori esp ecia lly b eneficial in large net works, and is commonly used in real-l ife large scale netw ork analysis (Gargi et al., 2011; L e sk o v ec et al., 2010; W u et al., 2012). Sev eral algorithms for lo ca l comm unity detection op erate by seed expansion. These metho ds h av e different expansion strategies, but what they ha v e in common is their use of conductance as the ob jectiv e to b e optimized. In tuitiv ely , condu c tance measures ho w strongly a set of no des is connected to the rest of the graph; sets of no des that are isolated from the graph h a ve lo w conductance and mak e go od comm unities. The problem of findin g a set of minimum condu ct ance in a graph is computationally in tractable (Chawla et al., 2005; ˇ S ´ ıma and Schae ffer, 2006 ). As a consequence, many heuris- tic and appr oximati on algorithms for lo ca l comm unit y detection ha v e b een int ro duced (see references in the related work section). In particular, effectiv e algorithms for this task are based on th e lo cal graph diffusion metho d. A graph diffusion vect or f is an infinite series f = P ∞ i =0 α i P i s , w it h diffus ion co effici en ts P ∞ i =0 α i = 1, seed n odes s , and ran- dom walk transition matrix P . Typ es of graph d iffu sio n, suc h as p ersonalized P age Rank (Andersen and Lang , 2006) and Heat Kernel (Chung, 2007), are determined b y the choi ce of th e diffusion coefficients. In the diffusion metho d an appro ximation of f is computed. After dividin g eac h v ector comp onent by th e degree of the corresp onding no de, the n o des are sorted in d esc ending order b y their v alues in this v ector. Next, the cond u ct ance of eac h prefix of the sorted list is computed and either the set of smallest conductance is s e lected, e.g. in (Andersen and Lang, 2006) or a local optima of condu c tance along the prefix length dimension (Y an g and Lesko ve c , 2012) is considered. These algorithms optimize conductance along a single dimension, representing the ord er in whic h no des are add ed by the algorithm. How eve r this orderin g is mainly related to the seed, and not directly to the ob jectiv e that is b eing optimized. Algorithms for the direct optimization of conductance mainly op erate in th e discr ete searc h sp a ce of comm unities, and lo c ally optimize conductance b y addin g and /o r r e mo ving on e no de. Th is amounts to fixin g a sp ecific neigh b orho o d structur e ov er comm unities where the neigh b ors of a comm unit y are only those communities which d iffe r by th e members h ip of a single no de. This is just one p ossible c hoice of comm unity neigh b or. A n at ural w a y to a v oid the problem of c ho osing a sp ecific n e igh b orho od structure is to u se con tin uous r ather than discrete optimizat ion. T o do this, w e need a conti nuous r e laxation of conductance, extending the notion of communities to allo w for fractional mem b ership. This pap er in v estigates suc h a con tin uous relaxation, whic h leads to the follo wing fi ndings. 1.0.1 On Local Optima Although lo cal optima of a con tin uous relaxation of conductance migh t at first glance ha v e no des with fractional memb er s hips, somewhat sur prisingly all strict lo cal optima are d is- crete. T his means that con tin uous optimization can d irect ly b e u sed to fin d comm unities without fractional memb erships. 1.0.2 Rela tion with Weighted Kernel K-Means W e unrav el the relation b et we en conductance and weigh ted kernel k-means ob j e ctiv es using the framew ork by Dhillon et al. (2007). Since the aim is to find only one comm unity , w e consid e r a sligh t v ariation w it h one m e an, that is, with k = 1. Th is relation leads 2 Local Network Com munity Detection with Continuous Optimiza tion to th e intro d uctio n of a n ew ob jectiv e fun c tion f o r lo ca l comm unit y detection, called σ - conductance, whic h is the su m of conductance an d a regularization term w h ose in fluence is con trolled by a parameter σ . Interestingly , the c hoice of σ has a direct effect on the n umber of lo cal optima of the function, where larger v alues of σ lead to more lo cal optima. In particular, we pro v e that for σ > 2 all discrete comm unities are local optima. As a consequence, due to the seed expansion appr o ac h, lo cal optimization of σ -conductance fa v ors smaller communities for larger v alues of σ . 1.0.3 Algorithms Lo ca l optimization of σ -conductance can b e easily p erformed u sing the pro jected gradient descen t metho d. W e dev elop an algorithm based on this metho d, called PGDc . Motiv ated b y the relation b et ween conductance and k-means clustering, we in trod uce an Exp ectation- Maximizatio n (EM) algorithm for σ -conductance optimizatio n, called EMc . W e sho w that for σ = 0, this algorithm is almost identi cal to pro jected gradien t descent with an infinite step size in eac h iteration. W e then prop ose a heuristic pro cedure for c ho o sing σ automat- ically in these algorithms. 1.0.4 Retrieving Communities W e giv e a theoretic c haracterizatio n of a class of comm unities, called dense and isolated comm unities, for whic h PGDc and EMc p erform optimally . F or this class of comm unities the algorithms exactly reco v er a communit y from the seeds. W e in v estigate the relation b e- t w een this class of comm unities and the notion of ( α, β )-cluster prop osed b y (Mishra et al., 2008) f or so cial n e t w orks analysis. And we sho w that, while all maximal cliques in a graph are ( α, β )-clusters, they are not necessarily dense and isolated comm unities. W e give a simple condition on the degree of the no des of a communit y whic h guaran tees that a dense and isolated communit y satisfying su c h condition is also an ( α, β )-cluster. 1.0.5 Experiment a l Per f ormance W e use publicly av ailable artificial and real-life n et wo rk data with lab eled groun d -truth comm unities to assess the p erforman ce of PGDc and EMc . Resu lts of the tw o m e th- o ds are v ery similar, with PGDc p erforming slightly b etter, while EMc is slight ly faster. These results are compared with those obtained b y three state-of-t he-art algorithms for con- ductance optimization based on the lo cal graph diffusion: the p opular Pe rsonalized P age Rank ( PPR ) diffusion algorithm by And er s e n and Lang (2006), a more recen t v ariant by Y ang an d Lesk o v ec (2012) (her e called YL ), and the Heat Kern e l (HK) d iffusion algorithm b y Kloster and Gleic h (2014). On large net wo rks PGDc and EMc stay localized and p r o - duce communities whic h are more faithful to the ground truth than those generated by the considered graph diffus i on algorithms. PPR and HK p rodu c e muc h larger comm unities with a lo w cond ucta nce, while the YL strategy outputs very small comm unities with a higher conductance. 3 v an Laarhoven and Marchiori 1.1 Related W ork The enormous gro wth of n et wo rk data from diverse disciplines such as so cial and infor- mation science and b iology has b o oste d researc h on netw ork communit y detection (see for instance th e ov erviews b y Schaeffe r (2007) and F ortun a to (2010)). Here we confine our sel f to literature w e consider to b e relev ant to the presen t w ork, namely lo cal comm u nit y detec- tion by seed expansion, and review related work on conductance as ob jectiv e fun ct ion and its local optimization. W e also briefly review researc h on other ob jectiv es functions, and on prop erties of comm unities and of seeds. 1.1.1 Conduct an ce and Its Local Optimiza tion Conductance h as b een largely us ed for net w ork comm unity detection. F or in sta nce Lesk o v ec et al. (2008) int ro duced the notion of netw ork comm unit y p rofile p lo t to measure the qualit y of a ‘b est’ comm unit y as a function of communit y size in a netw ork. They used conductance to measure the qualit y of a communit y and analyze a large n um b er of comm unities of different size scales in real-w orld so cial and information net w orks. Direct conductance optimization was sh o wn to fa v or comm unities whic h are qu a si-cliques (Kang and F aloutsos, 2011) or comm unities of large size whic h include ir r el ev ant sub graphs (Andersen and Lang , 2006; Whang et al., 2013). P opular algorithms for lo cal comm unit y detection emplo y the local graph diffusion metho d to find a comm unit y with small conductance. Starting from the seminal work b y S pielman and T eng (2004) v arious algorithms f or lo c al comm unit y detection by seed expansion b ase d on this approac h hav e b een p roposed (Andersen et al. , 2006; Avron and Horesh, 2015; Chung, 2007; Kloster and Gleic h, 2014; Zhu et al., 2013a ). The theoretical analysis in these works is largely based on a mixing result whic h sho ws that a cut with small cond u ct ance can b e found b y simulating a rand o m w alk starting f rom a single no de for sufficient ly man y steps (Lo v´ asz and Simono vits, 1990). This result is used to pro v e that if the seed is near to a set w ith small conductance then the r esult of the pro cedure is a comm unit y with a related conductance, whic h is returned in time pr o p ortional to the volume of the comm unity (up to a logarithmic factor). Mahoney et al. (2012) p erformed lo cal communit y d e tection by mo difying th e sp ectral program u s e d in standard global sp ectral clustering. Sp ecifically the authors incorp orated a bias to w ards a target region of seed no des in the form of a constrain t to force the solution to b e well conn ected with or to lie near the s e eds. The d eg ree of connectedness w as sp ecified by setting a so-called corr elation parameter. Th e authors show ed that the optimal solution of the resulting constrained optimization problem is a generaliza tion of P ersonalized PageRa nk (Andersen and Lang , 2006). 1.1.2 Other Object i ves Conductance is not the only ob jectiv e fu nctio n used in lo cal comm unit y d etection algo- rithms. V arious other ob jectiv e fu nctio ns hav e b een considered in the literature. F or in- stance, C h en et al. (2009) prop osed to use the ratio of the av erage in ternal and external degree of no des in a communit y as ob j ective function. Claus et (2005) prop osed a lo cal v ari- an t of mo dularit y . W u et al. (2015) mo dified the classical den sit y ob jectiv e, equal to the sum of edges in the comm unity divided by its size, by replacing the denominator with th e 4 Local Network Com munity Detection with Continuous Optimiza tion sum of weigh ts of th e comm unity no des, where the w eigh t of a no de quan tifies its p r o ximit y to the seeds and is computed u sing a graph diffusion metho d. A comparative exp eriment al analysis of ob j e ctiv e functions with r espect to their exp er- imen tal and theoretical p roperties was p erformed e.g. in (Y ang and Lesko v ec , 2012) and (W u et al., 2015), resp ectiv ely . 1.1.3 Proper ties of Communities Instead of fo c using on ob jective functions and metho ds for lo cal comm unit y detection, other researc hers inv estigated prop erties of comm unities. Mishra et al. (2008) fo cused on inter- esting classes of communities and algorithms for their exact retriev al. Th ey defined th e so called ( α, β )-communities and dev elop ed algorithms capable of retrieving this t yp e of comm unities starting fr o m a seed connected to a large fraction of the memb e rs of the com- m unit y . Zhu et al. (2013 b ) considered the class of w ell-connected communities, whic h ha v e a b etter int ernal connectivit y than condu ct ance. In ternal connectivit y of a communit y is defined as the inv erse of the mixing time for a random walk on the subgraph indu c ed b y the comm unity . They show ed that for we ll-connected comm unities, it is p ossible to pro vide an improv ed p erformance guaran tee, in terms of conductance of th e output, for lo cal com- m unit y detection algorithms based on the diffus io n metho d. Gleic h and Seshadhr i (2012 ) in v estigate d the utilit y of neighbors of the seed; in particular they show ed emp iric ally that suc h neighbors form a ‘go od’ lo cal comm unit y around the seed. Y ang and Lesko ve c (2012) in v estigate d prop erties of ground truth communities in social, information and tec hnologica l net w orks. Lancic hinetti et al. (2011) addressed the problem of finding a significant lo cal comm u- nit y f rom an initial group of no des. Th ey prop osed a metho d w h ic h locally optimizes the statistica l signifi c ance of a comm unity , defined with resp ect to a global null mo del, by iterativ ely adding external signifi c an t no des and r e mo ving in ternal no des that are not sta- tistically relev ant . Th e resulting comm unit y is not guaran teed to conta in the n odes of the initial communit y . 1.1.4 Proper ties of See ds Prop erties of seeds in relation to the p erformance of algorithms we re inv estiga ted by e.g. Kloumann and Kleinb er g (2014). They considered different t yp es of algorithms, in partic- ular a greedy seed expansion algorithm whic h at eac h step adds the no de that yields the most n eg ativ e c hange in conductance (Mislo ve et al., 2010). Whang et al. (2013) in v esti- gated v arious metho ds for choosing the seeds for a Pag eRank based algorithm for comm u n it y detection. Chen et al. (2013) introd uced the notion of lo c al degree cen tral no de, wh ose de- gree is greater than or equal to the d egree of its neighbor no des. A new lo cal communit y detection metho d is introduced based on the lo cal degree central no de. In this metho d, the lo c al comm unity is n ot disco v ered from the giv en starting n ode, but from the lo cal d eg ree cen tral no de that is asso ciated with the giv en starting no de. 1.2 Notation W e start by in tro ducing the notation used in the rest of th is pap er. W e den ote by V th e set of n odes in a net w ork or graph G . A communit y , also called a cluster, C ⊆ V w il l b e a 5 v an Laarhoven and Marchiori subset of no des, and its complemen t C = V \ C consists of all no des not in C . Note that w e consider an y subset of no des to b e a communit y , and the goal of comm unity d etection is to fi nd a go o d comm unity . Let A b e the adjacency matrix of G , where a ij denotes the weigh t of an edge b et ween no des i and j . In unw eighte d graph s a ij is either 0 or 1, and in undir e cted graphs a ij = a j i . In this pap er we w ork only with unw eigh ted und irect ed graphs. W e can generalize this notation to sets of no des, and write a xy = P i ∈ x P j ∈ y a ij . With this notation in hand we can write condu ctance as φ ( C ) = a C C a C V = 1 − a C C a C V . A common alternativ e definition is φ alt ( C ) = a C C min( a C V , a C V ) , whic h considers the comm unity to b e the smallest of C and C . F or ins tance Kloster and Gleic h (2014) and And ersen and Lang (20 06) u se this alternativ e d efi nitio n, while Y ang and Lesko ve c (2012) use φ . Note that φ has a trivial optim um when all no des b elong to the comm unit y , while φ alt will us uall y ha v e a global optim um with roughly h al f of the no des b elonging to th e comm unit y . Neither of these optima are desirable for finding a sin g le small comm unit y . With a set X w e asso ciate an indicator vec tor [ X ] of length | V | , su c h that [ X ] i = 1 if i ∈ X and [ X ] i = 0 otherwise. W e will u sually call this ve ctor x . 2. Con t in uous Relaxation of Conductance If we wan t to talk ab out directly optimizing condu c tance, then we need to defin e what (lo cal) op tima are. The notion of lo c al optima dep ends on the top olog y of the inpu t space, that is to sa y , on what communities w e consider to b e neigh b ors of other comm unities. W e could, for instance, define the neigh b ors of a communit y to b e all communities that can b e created by adding or remo ving a single no de. But this is an arbitrary c hoice, and we could equally we ll defin e the n e igh b ors to b e all comm u nities reac hed b y ad d ing or r emo ving u p to t w o n odes. An alternativ e is to mov e to the con tin uous w orld, where we can u se our kno wledge of calculus to giv e us a notion of lo cal op tima. T o turn communit y finding in to a con tin u ous p roblem, instead of a set C w e need to see the comm unit y as a vecto r c of real num b ers b et ween 0 and 1, wh er e c i denotes the d eg ree to whic h no de i is a member of th e communit y . Giv en a discrete comm unit y C , w e hav e c = [ C ], but the inv erse is not alw a ys p ossible, so the vecto rial setting is more general. The edge w eigh t b et w een s ets of n odes can b e easily generalized to the edge weig ht of mem b ership v ectors, a xy = x T A y = X i ∈ V X j ∈ V x i a ij y j . No w we can rein terpret the previous defi n iti on of conductance as a function of real v ectors, whic h we could expand as φ ( c ) = 1 − P i,j ∈ V c i a ij c j P i,j ∈ V c i a ij . 6 Local Network Com munity Detection with Continuous Optimiza tion With this definition w e can apply the v ast literature on constrained optimization of differ- en tiable functions. In particular, we can lo ok f o r lo ca l optima of the condu c tance, sub ject to the constraint that 0 ≤ c i ≤ 1. These lo cal optima w ill satisfy the Karush - Kuh n -T uc k er conditions, which in this case amoun ts to, for all i ∈ V , 0 ≤ c i ≤ 1 ∇ φ ( c ) i ≥ 0 if c i = 0 ∇ φ ( c ) i = 0 if 0 < c i < 1 , ∇ φ ( c ) i ≤ 0 if c i = 1 . T o use the ab o v e optimization pr oblem for fin ding communities f rom seeds, we add one additional constraint. Giv en a set S of seeds w e require th at c i ≥ s i ; in other w ords, that the seed no des are member s of the communit y . T his is the only w a y in whic h the seeds are used, and th e only wa y in wh ic h we can use the seeds without making extra assump ti ons. 2.1 A Lo ok at the Lo cal Optima By allo wing comm unit y mem b erships that are real num b ers, uncoun tably many more com- m unities are p ossible. One might exp ec t that it is o v erwhelmingly lik ely that op tima of the con tin uous relaxation of condu c tance are comm unities with fractional mem b erships. But this tur ns out not to b e the case. In fact, the strict lo c al optima will all r epresen t discrete comm unities. T o see why this is the case, consider th e ob jectiv e in terms of the membersh ip coefficien t c i for some no de i . This take s the form of a qu a dratic rational fu nctio n, φ ( c i ) = α 1 + α 2 c i + α 3 c 2 i α 4 + α 5 c i . The co efficien ts in the d en o minator are p ositiv e, w hic h means that th e denominator is also p ositiv e for c i > 0. A t an inte rior lo cal minim um we must ha v e φ ′ ( c i ) = 0, which implies that φ ′′ ( c i ) = 2 α 3 / ( α 4 + α 5 c i ) 3 . But α 3 ≤ 0, sin c e it comes fr o m th e c i a ii c i term in the n umerator of the conductance, so φ ′′ ( c i ) ≤ 0, and hence there are only lo cal maxima or saddle p oin ts, not strict lo ca l min ima . It is still p ossible for there to b e plateaus in the ob jectiv e functions, where φ ( c ) is optimal regardless of the v alue of c i for a certain no de i . 2.2 The Relat ion t o W eigh ted Kernel K-Means Clust ering Another view on conductance is by the connection to w eigh ted kernel k -means clustering. The connection b et ween w eigh ted k ernel k -means and ob jectiv es f or graph partitioning has b een thoroughly in v estigate d in Dhillon et al. (2007 ). Here we extend that connection to the single clus t er case. Start with w eigh ted k -means clustering, wh i c h, giv en a dataset { x i } N i =1 and we igh ts { w i } , minimizes the follo w ing ob jectiv e N X i =1 k X j =1 w i c ij k x i − µ j k 2 2 7 v an Laarhoven and Marchiori with resp ect to µ j and c ij , w h ere c ij indicates if p oint i b elongs to cluster j , sub ject to the constrain t that exactly one c ij is 1 for ev ery i . Since our goal is to fin d a single cluster, a first guess w ould b e to tak e k = 2, and to tr y to separate a foreground cluster from the backg round . But w hen using 2-means, there is n o d isti nction b et w een foreground and b a c kground, and so solutions will naturally ha v e t w o clus t ers of roughly equal s i ze. Instead, w e can consider a one-cluster v arian t that distinguishes b et w een p oin ts in a cluster and bac kground p oin ts, wh i c h we call 1-mean clustering. This can b e f o rmulat ed as the minimization of X i w i c i k x i − µ k 2 2 + (1 − c i ) λ i with resp ect to a single µ and cluster mem b ership ind icators c i (b et ween 0 and 1). Here λ i is a cost for no de i b eing a member of th e b a c kground. W e allo w different λ i for differen t no des, as there is n o r ea son to demand a sin g le v alue. The condition for a no de i to b e p art of th e comm unity is k x i − µ k 2 2 < λ i . S o differen t v alues for λ i migh t b e u seful for tw o reasons. T h e first wo uld b e to allo w incorp orating prior knowledge , the second reason w ould b e if the scale (of the clusters) is different , that is, no des (in different clusters) hav e differen t d ista nces from the mean. By adding a diagonal matrix to the ke rnel, the squared distance fr om all p oints to all other p oin ts is increased b y that same amoun t. It mak es sense to comp ensate f o r this in the cond i tion for comm unit y mem b ership. And since the diagonal terms w e add to the k ernel v ary p er n ode, the amoun t that these no des mov e aw ay from other p oin ts also v aries, which is why we use different λ i p er no de. The minimizer for µ is the cen troid of the p oin ts inside the cluster, µ = P i w i c i x i P i w i c i ; while the min imiz er for c i is 1 if and only if k x i − µ k 2 < λ i , and 0 otherw ise. The k -means and 1-mean ob jectiv es can b e ke rnelized by writing distances in terms of inner p rodu c ts, and using a ke rnel K ( i, j ) = h x i , x j i . The cluster mean is then a linear com bination of p oint s, µ = P i µ i x i , giving k x i − µ k 2 2 = K ( i, i ) − 2 X j µ j K ( i, j ) + X j,k µ j K ( j, k ) µ k . By filling in th e optimal µ giv en ab o ve, the 1-mean ob jectiv e then b ecomes φ W,K,λ ( c ) = X i w i c i ( K ( i, i ) − λ i ) + X i w i λ i − P i,j w i c i w j c j K ( i, j ) P i w i c i . The second term is constan t, s o we can d r op it for the pur poses of optimization. W e p ic k λ i = K ( i, i ). With this c hoice, the condition for a no de i to b e a member of the comm unit y is k x i − µ k 2 2 < k x i − 0 k 2 2 . This can b e seen as a 2-means cluster assignm ent 8 Local Network Com munity Detection with Continuous Optimiza tion where the bac kground cluster has the origin as the fixed mean. With this c hoice the fi r st term also d rops out. By con v erting the graph into a k ernel with K = W − 1 AW − 1 , where W is a diagonal m a trix with the w eigh ts w i on the diagonal, w e can obtain ob jectiv es lik e conductance and asso ci ation ratio. Ho w ev er this K is n o t a legal k ernel, b ecause a k ernel has to b e p ositiv e definite. Without a p ositiv e definite k ernel the distances k x i − µ k from the original optimization problem can b ecome n egativ e. T o mak e the kernel p ositiv e definite, we follo w the same r o ute as Dhillon et al. , and add a diagonal matrix, obtaining K = σ W − 1 + W − 1 AW − 1 . Since we are in terested in conductance, we tak e as w eigh ts w i = a iV , the d e gree of no de i , and we tak e λ i = K ( i, i ). Th is results (up to an additive constan t) in the follo wing ob jectiv e w hic h we call σ -conductance, φ σ ( c ) = 1 − P i,j c i c j a ij P i c i a iV − σ P i c 2 i a iV P i c i a iV . Observe that if c is a discrete communit y , then c 2 i = c i , and the last term is constan t. In that case optimization of this ob jectiv e is exactly equiv alent to optimizing condu ctance. F or the p urp oses of con tin uous optimizatio n h o we v er, in c reasing the σ parameter has the effect of increasing the ob jectiv e v alue of non-discrete comm un iti es. So differen t comm u - nities b ecome more separated, and in the extreme case, every discrete comm unit y b ecomes a lo cal op timum. Theorem 1 When σ > 2 , al l discr ete c ommunities c ar e lo c al minima of φ σ ( c ) c onstr aine d to 0 ≤ c i ≤ 1 . Pro o f Th e gradient of φ σ is ∇ φ σ ( c ) i = a iV a cc a 2 c V − 2 a i c a c V + σ a iV P j c 2 j a j V a 2 c V − 2 c i a iV a c V . When c is d isc rete, then P j c 2 j a j V = a c V , so the gradien t simplifies to ∇ φ σ ( c ) i = a iV a c V a cc a c V + (1 − 2 c i ) σ − 2 a i c a iV . Because a i c ≤ a iV and a cc ≤ a c V w e can b ound this by a iV a c V (1 − 2 c i ) σ − 2 ≤ ∇ φ σ ( c ) i ≤ a iV a c V (1 − 2 c i ) σ + 1 . So if c i = 0, we get that ∇ φ σ ( c ) i > 0 when σ > 2. And if c i = 1, we get that ∇ φ σ ( c ) i < 0 when σ > 1. 9 v an Laarhoven and Marchiori Figure 1: A simple sub net work consisting of a clique with tails connecting it to the r est of the net wo rk. The clique (sh a ded no des) is n ot a lo ca l optim um of condu ct ance, but it is a lo cal op timum of σ -conductance wh en σ > 0 . 131. This means that when σ > 2 all discrete comm unities satisfy the KK T conditions, and from the sign of the gradien t w e can see that they are not local maxima. F urtherm o re, φ σ ( c ) is a conca v e fu n ct ion, so it has no sadd le p oin ts (see the pr o of of Th eorem 2 ). This means that all discrete communities are lo cal m in ima of φ σ . Con v ersely , the result from Section 2.1 generalizes to σ -conductance, Theorem 2 When σ ≥ 0 , al l strict lo c al minima c of φ σ ( c ) c onstr aine d to 0 ≤ c i ≤ 1 ar e discr ete. F urthermor e, if σ > 0 then al l lo c al minima ar e discr ete. Pro o f By the argument from Section 2.1. When σ > 0 it is alw a ys the case that α 3 < 0, so there are no saddle p oints or plateaus, an d all lo cal minima are d iscrete . As an example application of σ -co ndu c tance, consider the net w ork in Figure 1. In this net wo rk, the clique is n o t a lo cal optim um of regular conductance. This is b ecause the gradient for the adjacen t n odes w it h degree 2 is alwa ys n e gativ e, regardless of the conductance of the communit y . How ever, for σ -conductance th is gradien t b ecomes p ositiv e when σ > φ σ ( c ), in this case w hen σ > 0 . 131. In other w ords, with higher σ , adjacen t no des with lo w d eg ree are no longer consid er ed part of otherwise tigh tly connected comm unities suc h as cliques. 3. Algorithms W e now in tro duce tw o simple algorithms for the lo c al optimization of conductance and σ -co ndu c tance, analyze their computational complexit y and p ro vide an exact p erformance guaran tee f o r a class of comm unities. Then we lo ok at a pro cedure for the automatic selection of a v alue for σ . 3.1 Pro jected Gradient Descent P erhaps the simplest p ossible metho d for constrained contin u o us optimization problems is pro jected gradient descent. This is an iterativ e algorithm, where in eac h step the solution is mo v ed in the direction of the negativ e gradient, and then this solution is pr o ject ed so as to satisfy the constrain ts. 10 Local Network Com munity Detection with Continuous Optimiza tion In our case, we start from an initial communit y con taining only the seeds, c (0) = s , where s = [ S ] is a sparse v ector indicating th e seed no de(s). Th e n in eac h subsequent iteration we get c ( t +1) = p ( c ( t ) − γ ( t ) ∇ φ ( c ( t ) )) . This p rocess is iterated until con v ergence. The step size γ ( t ) can b e found with line searc h. The gradien t ∇ φ is giv en by ∇ φ ( c ) i = a iV a cc a 2 c V − 2 a ic a c V . And the pr o jecti on p on to the set of v alid communities is d efi ned by p ( c ) = argmin c ′ , s.t. 0 ≤ c ′ i ≤ 1 ,s i ≤ c ′ i k c − c ′ k 2 2 , whic h simply amounts to p ( c ) = max( s , min(1 , c )) . This fun ct ion clips v alues ab o ve 1 to 1, and v alues b elo w s i to s i . Since s i ≥ 0 this also enforces that c i ≥ 0. The complete algorithm is giv en in Algorithm 1. If a discrete communit y is desired, as a final step, we migh t threshold the vec tor c . But as sho wn in Th e orem 2 the found comm unit y is usually already d iscrete . 3.2 Exp ectation-Maximization The connection to k -means clustering suggests that it might b e p ossible to optimize con- ductance u sing an Exp ectat ion-Maximizatio n algorithm similar to Llo yd’s algorithm for k -mea ns clustering. Intuitiv ely , the algorithm would w ork as follo ws: • E step assign eac h n ode i to the communit y if and only if its squared distance to the mean is less than λ i . • M st e p set th e comm unity mean to the w eigh ted cen troid of all no des in the com- m unit y . These steps are alternated u n til con v ergence. Since b oth these steps do not in c rease the ob jectiv e v alue, the algorithm is guarante ed to con v erge. If the comm unit y after some iterations is C , then , as in the pr e vious section, we can fill in the optimal mean into th e E step, to obtain that a no de i should b e part of the comm unit y if K ( i, i ) + a C C /a C V + σ a C V − 2 a iC /a iV + σ c i a C V < λ i . When λ i = K ( i, i ), this condition is equiv alent to ∇ φ σ ( C ) < 0 . 11 v an Laarhoven and Marchiori Algorithm 1 Pro j e cted Gradient Descen t condu ct ance optimization ( PGDc ) Input: A set S of seeds of seeds, a graph G , a constant σ ≥ 0. 1: s ← [ S ] 2: c (0) ← s 3: t ← 0 4: rep eat 5: γ ( t ) ← LineSearch( c ( t ) ) 6: c ( t +1) = p ( c ( t ) − γ ( t ) ∇ φ σ ( c ( t ) )) 7: t ← t + 1 8: until c ( t − 1) = c ( t ) 9: C ← { i ∈ V | c ( t ) i ≥ 1 / 2 } function LineSearch( c ) 1: γ ∗ ← 0, φ ∗ ← φ σ ( c ) 2: g ← ∇ φ σ ( c ) 3: γ ← 1 / max( | g | ) 4: rep eat 5: c ′ ← p ( c − γ g ) 6: if φ σ ( c ′ ) < φ ∗ then 7: γ ∗ ← γ , φ ∗ ← φ σ ( c ′ ) 8: end if 9: γ ← 2 γ 10: until c ′ i ∈ { 0 , 1 } for all i w it h g i 6 = 0 11: return γ ∗ Algorithm 2 EM conductance optimization ( EMc ) Input: A set S of seeds, a graph G , a constan t σ ≥ 0. 1: C (0) ← S 2: t ← 0 3: rep eat 4: C ( t +1) = { i | ∇ φ σ ( C ( t ) ) i < 0 } ∪ S 5: t ← t + 1 6: w hile C ( t ) < C ( t − 1) 12 Local Network Com munity Detection with Continuous Optimiza tion This leads us to the EM communit y findin g algorithm, Algorithm 2 . By taking σ = 0 w e get that no des are assigned to th e comm unit y exactly if the gradient ∇ φ ( C ) i is negativ e. S o , this EM algorithm is v ery similar to pro jected gradien t descen t with an infi nite step size in eac h iteration. T he only difference is for no des with ∇ φ ( C ) i = 0, whic h in the EMc algorithm are alw a ys assigned to the bac kground, wh ile in PGD their mem b ership of the comm unity is left u nc hanged compared to the p revio us iteration. Of course, w e h a v e p reviously established that σ = 0 do es not lead to a v alid kernel (this do esn’t pr e clude u s from still using the EM algorithm). In th e case that σ > 0 there is an extra b a rrier for adding no des not currently in the comm unit y , and an extra barrier for remo ving no des that are in the comm unit y . This is similar to the effect that in cr easing σ has on the gradien t of φ σ . 3.3 Computational Complexit y Both metho ds require the computation of the gradien t in eac h iteration. This computation can b e d on e efficien tly . The only nod es for whic h the gradien t of the conductance is negativ e are the neigh b ors of no des in the curren t comm u nit y , and the only no des for whic h a p o sitiv e gradien t can hav e an effect are those in the comm unit y . So the gradien t do esn’t need to b e computed for other no des. F or the other n odes the gradien t d epend s on the num b er of edges to the communit y , and on th e no de’s degree. Assuming that the no de degree can b e queried in constan t time, the total time p er iteration is p roportional to the size of the one- step-neigh b orho od of the comm unity , wh i c h is of the order of the volume of the comm unit y . If the no de degrees are not kno wn, then the complexit y increases to b e pr oportional to the v olume of the one-step-neigh b orhoo d of the communit y , though this is a one-time cost, not a p er iteratio n cost. As seen in S ec tion 3.5, for dense an d isolated comm unities, the num b er of iterations is b ounded by the diameter of the communit y . In general we can not guarantee su ch a b ound, but in practice the num b er of iterations is alw a y s on the order of the diameter of the reco v ered comm unit y . F or very large datasets, the computation of the gradien t can s t ill b e exp ensive , eve n though it is a lo c al op eratio n. Therefore, w e restrict the search to a set of 1000 no des near the seed. Th is set N is formed by starting with th e s eed, and rep eatedly adding all neigh b ors of no des in N , until the set wo uld con tain more th an 1000 no des. In th i s last step we only add the no des with th e h ig hest a iN /a iV so th a t the fin al set con tains exactly 1000 no des. 3.4 Cho osing σ In S e ction 2.2 we in tro duced th e σ parameter, and we ha v e sh o wn that larger v alues of σ lead to more lo ca l optima. This lea v es the question of c ho osing the v alue of σ . One ob vious c hoice is σ = 0, whic h means th at φ σ is exactly the classical conductance. Another choic e w ould b e to pic k th e smallest σ that leads to a p ositiv e defi nite kernel. But this is a global p roper ty of th e net w ork, that is furtherm o re v ery exp ensiv e to compute. Instead, w e try sev eral d iffe rent v alues of σ for eac h seed, and then pic k the comm unity with the h ig hest density , that is, the communit y C with the largest a C C / | C | 2 . 13 v an Laarhoven and Marchiori 3.5 Exactly Reco v erable Communities W e no w tak e a brief look at which kinds of communities can b e exactly r ec o v ered with gra- dien t descent and exp e ctation-maximiza tion. Supp ose that we wish to reco ve r a communit y C ∗ from a seeds set S , and assume that this comm unit y is connected. Denote b y d ( i ) the shortest path distance from a no de i ∈ C ∗ to an y seed no de, in the su bnet work ind u ce d by C ∗ . First of all, since b oth algorithms gro w the comm unity from th e seeds, we need to lo ok at sub comm unities C ⊆ C ∗ c enter e d ar ound the se e ds , b y whic h we mean that d ( i ) ≤ d ( j ) for all no des i ∈ C and j ∈ C ∗ \ C . Secondly , w e n eed the comm unity to b e sufficien tly densely connected to b e considered a comm unit y in the fi r st place; but at the s a me time the comm unit y needs to b e separated from the rest of the net w ork. Again, b ecause the comm unities are grown, we require that this holds also f or sub communities that are grown from the seeds, Definition 3 A c ommunity C ∗ is dense and isolated with thr eshold σ i f for al l subsets C ⊆ C ∗ c enter e d ar ound the se e ds S : • 2 a iC /a iV > a C C /a C V − σ for al l no des i ∈ C , and • 2 a iC /a iV ≤ a C C /a C V − σ for al l no des i / ∈ C ∗ . Some examples of comm unities that satisfy this prop ert y are cliques and quasi-cliques that are only connected to no des of high d e gree. No w den ote by D n the set of no des i in C ∗ with d ( i ) ≤ n . Clearly D 0 = S , and b ecause the comm unity is connected there is some n ∗ suc h that D n ∗ = C ∗ . W e first lo ok at the exp ectation-maximiza tion algo rithm. Theorem 4 If C ∗ is dense and isolate d, then the iter ates of the EMc algorithm satisfy C ( t ) = D t . Pro o f The pr oof pro ceeds by induction. F or t = 0, the only no des i with d ( i ) = 0 are the seeds, and C (0) = S by defin it ion. No w supp ose that C ( t ) = D t . Then for any no de i there are th ree p ossibilities. • i ∈ D t +1 ; then b ecause C ∗ is dense and D t is cent ered around the seeds, 2 a iC ( t ) /a iV > 1 − φ σ ( C ( t ) ). This imp lie s that ∇ φ σ ( C ( t ) ) i < 0. • i ∈ C ∗ \ D t +1 ; then there are no edges from D t to i , since otherwise the shortest path d istance from i to a seed w ould b e t + 1. So a i c ( t ) = 0, which implies that ∇ φ σ ( C ( t ) ) i ≥ 0. • i / ∈ C ∗ ; then b ecause C ∗ is isolated, 2 a iC ( t ) /a iV ≤ 1 − φ σ ( C ( t ) ), whic h implies that ∇ φ σ ( c ( t ) ) i ≥ 0. hence ∇ φ σ ( C ( t ) ) i < 0 if i ∈ D t +1 , and ∇ φ σ ( C ( t ) ) i ≥ 0 otherwise. This means that C ( t +1) = D t +1 . F or the pr o jecte d gradien t descent algorithm from Section 3.1 we ha v e an analogous theorem, 14 Local Network Com munity Detection with Continuous Optimiza tion Theorem 5 If C ∗ is dense and i so late d, then the iter ates of PGDc satisfy c ( t ) = [ D t ] . Pro o f The pro of p roceeds b y induction, and is analogous to the p roof of Theorem 4. F or t = 0, the only n odes i with d ( i ) = 0 are the seeds, and c (0) = s = [ S ] by definition. No w su pp o se that c ( t ) = [ D t ]. W e ha v e already sho wn that ∇ φ σ ( C ( t ) ) i < 0 if and only if i ∈ D t +1 . This m e ans that after pro jecting onto the set of v alid comm unities, only th e mem b ership of no des in D t +1 can increase. Sin ce no des in D t already hav e membersh ip 1, and no des not in D t +1 already hav e membersh ip 0, they are not affected. Let γ max = max i ∈ D t +1 − 1 / ∇ φ σ ( c ( t ) ) i . Clearly if γ ( t ) ≥ γ max , then c ( t ) i − γ ( t ) ∇ φ σ ( c ( t ) ) i > 1 for all no des i ∈ D t +1 , and hence p ( c ( t ) − γ ( t ) ∇ φ σ ( c ( t ) )) = [ D t +1 ]. So to complete the pro of, we only need to sh o w that the optimal step size found with lin e search is indeed (at least) γ max . Supp ose that γ ( t ) < γ max leads to the optimal conductance. Then there is a no de i ∈ D t +1 with fractional mem b ership, 0 < c ( t +1) i < 1. By r epeated app lic ation of Theorem 2 w e know that there is a discrete communit y C ′ with φ σ ( C ′ ) = φ σ ( c ( t +1) ), and further m o re φ σ ( C ′ \ { i } ) = φ σ ( C ′ ∪ { i } ). The latter can only b e the case if ∇ φ σ ( C ′ ) i = 0. Because the only no des w hose mem b ership has c hanged compared to c ( t ) are those in D t +1 \ D t , it follo ws that C ′ con tains all no des with distance at most t to the seeds, as well as some no des with distance t + 1 to the seeds. This means that C ′ is centered around the seeds, and so ∇ φ σ ( C ′ ) i > 0. T his is a con tradiction, wh ic h means th at γ ( t ) ≥ γ max m ust b e th e optim um. As a corollary , since D n ∗ +1 = D n ∗ , b oth the EMc and the PGDc algorithm will halt, and exactly r e co v er C ∗ . The notion of dense and isolated communit y is wea kly related to that of ( α, β )-cluster (Mishra et al. , 2008) (without the tec hnical assumption that eac h no de has a self-lo op): C is an ( α, β )-cluster, with 0 ≤ α < β ≤ 1 if a iC ≥ β | C | for i in C , a iC ≤ α | C | for i outside C . The definition of dense and isolated comm unity d epend s on the degree of the no des while that of ( α, β )-cluster do es not. As a consequ en c e, not all maximal cliques of a graph are in general den se and isolated comm unities w h ile they are ( α, β )-clusters. F or instance, a maximal clique link ed to an external isolated no de, that is, a n ode of degree 1, is n ot d ense and isolated. In general one can easily sh o w that if C is den s e and isolated and min i ∈ C a iV > max i 6∈ C,a iC > 0 a iV then C is an ( α, β )-cluster w it h β = 1 − φ ( C ) 2 | C | min i ∈ C a iV and α = 1 − φ ( C ) 2 | C | max i 6∈ C,a iC > 0 a iV . 15 v an Laarhoven and Marchiori Dataset #no de #edge clus.c. #comm | C | φ ( C ) LFR (om=1) 5000 25125 0.039 101 49.5 0.302 LFR (om=2) 5000 25123 0.021 146 51.4 0.534 LFR (om=3) 5000 25126 0.016 191 52.4 0.647 LFR (om=4) 5000 25117 0.015 234 53.4 0.717 Karate 34 78 0.103 2 17.0 0.141 F o otball 115 613 0.186 12 9.6 0.402 P ol.Blog s 1490 16715 0.089 2 745.0 0.094 P ol.Books 105 441 0.151 3 35.0 0.322 Flic kr 35313 30175 30 0.030 171 4336.1 0.682 Amazon 33486 3 92587 2 0.079 15103 7 19.4 0.554 DBLP 31708 0 10498 66 0.128 13477 53.4 0.622 Y outub e 11348 90 2987 624 0.002 8385 13.5 0.916 Liv eJournal 39979 62 34681 189 0.045 28751 2 22.3 0.937 Orkut 30724 41 11718 5083 0.014 6288363 14.2 0.977 CYC/Ga vin 2006 6230 6531 0.121 408 4.7 0.793 CYC/Krogan 2006 6230 7075 0.075 408 4.7 0.733 CYC/Collins 2007 6230 14401 0.083 408 4.7 0.997 CYC/Costanzo 2010 6230 57772 0.022 408 4.7 0.996 CYC/Hoppins 2011 6230 10093 0.030 408 4.7 0.999 CYC/all 6230 80506 0.017 408 4.7 0.905 T able 1: Overview of the d a tasets used in the exp erimen ts. F or eac h d a taset we consider three different sets of comm unities. 4. Exp erim en ts T o test the prop osed algorithms, we assess their p erformance on v arious n et wo rks. W e also p erform exp erimen ts on recen t state-of-the- art algorithms b a sed on the diffusion metho d whic h also optimize conductance. 4.1 Algorithms Sp ecifically , we p erform a comparative empirical analysis of the f o llo wing algorithms. 1. PGDc . The pro jected gradien t descent algorithm for optimizing σ -c onductance giv en in Algorithm 1. W e sh o w the results for t w o v arian ts: PGDc -0 w it h σ = 0 and PGDc - d where σ is c hosen to maximize the comm unit y’s densit y as d e scrib ed in Section 3.4. 2. EMc . Th e Exp ectat ion Maximization algorithm for optimizing σ -conductance de- scrib ed in Section 2. W e consider the v arian ts EMc -0 with σ = 0 and EMc -d w h ere σ is c hosen automatically . 3. YL . T h e algorithm by Y ang and Lesk o v ec (2012) (with conductance as s coring func- tion), based on the diffus ion metho d. It computes an appro ximation of the p erson- alized Pag e Rank graph diffus ion v ector (Andersen et al., 2006). T he v alues in this 16 Local Network Com munity Detection with Continuous Optimiza tion v ector are divided b y the degree of the corresp onding no des, and the no des are sorted in descending ord er b y their v alues. The ranking in duces a one dimen s io nal searc h space of communities C k , called a sweep, d efined by the sequence of prefi xe s of th e sorted list, that is, the k top ranked no des, for k = 1 , . . . , | V | . Th e smallest k w hose C k is a ‘lo c al optimum’ of conductance is computed and C k is extracted. Lo cal op- tima of conductance o v er the one d i mensional space C 1 , C 2 , . . . , C | V | are computed using a heuristic. F or increasing k = 1 , 2 , . . . φ ( C k ) is m easur e d. Wh e n φ ( C k ) stops decreasing at k ∗ this is a ‘candidate p oin t’ for a lo cal minimum. It b ecomes a selected lo c al m inim u m if φ ( C k ) keeps increasing after k ∗ and even tually b ecomes higher than αφ ( C k ), otherwise it is d isc arded. α = 1 . 2 is sho wn to give go o d results and is also used in our exp eriment s. Y ang and Lesk o v ec (2012 ) show that fin ding the lo cal op- tima of the swe ep cur v e instead of the global optimum giv es a large impr o v emen t o v er previous lo cal sp ectral clustering metho ds b y Andersen and Lang (2006) and b y Spielman and T eng (2004). 4. HK . The algorithm b y Kloster and Gleic h (2014), also based on the diffus io n metho d. Here, instead of using the P ersonalized PageRa nk score, no des are ranked based on a Heat Kernel diffusion score (Chung, 200 7). W e us e the implemen tation made a v ailable b y Kloster and Gleic h (2014), wh ic h tries differen t v alues of the algorithm’s param- eters t and ǫ , and pic ks the comm unit y with the highest conductance among them. The details are in section 6.2 of (Kloster and Gleic h, 2014). Cod e is a v ailable at https:// www.cs.purdue.e du /homes/dgleich/codes/hkgrow . 5. PPR . The pprp ush algorithm by Andersen and L an g (2006) based on the p ersonalized P age Rank graph diffu sio n. Compared to YL instead of fi nding a lo ca l op timum of the sweep, the metho d lo oks for a global op timum, and hence often fin ds larger comm unities. W e use th e implementa tion included with the HK metho d. 4.2 Datasets 4.2.1 Ar tificial D a t asets The first set of exp erimen ts we p erformed is on artificially generate d net works with a k n o wn comm unit y stru ctur e . W e use the LFR b enc h mark (Lancic hinetti et al., 2008). W e used the parameter settings N=5000 mu=0.3 k=10 maxk=5 0 t1=2 t2=1 minc=20 maxc=100 on=2500 , whic h means that the graph has 5000 no des, and b et ween 20 and 100 comm unities, eac h with b et w een 10 and 50 no des. Half of the no des, 2500 are a mem b er of m ultiple communi- ties. W e v ary the o v erlap parameter ( om ), wh ic h determines h o w many comm unities these no des are in. More ov erlap make s th e p roblem harder. 4.2.2 Social and Informa tion Network Da t asets with Ground Truth W e use fiv e so cial and inf o rmation n etw ork d a tasets w ith ground-truth from the S NAP collect ion (Lesk o v ec an d Krevl, 2014). These datasets are summarized in T able 1. F or eac h dataset we list the num b er of no des, n um b er of edges and the clustering co efficien t. W e consider all a v ailable ground truth comm unities with at least 3 no des. Y ang an d Lesk o v ec (2012) also defined a set of top 5000 communities for eac h dataset. These are communities with a high combined score for several comm unit y go od ness metrics, 17 v an Laarhoven and Marchiori among w h ic h is condu ct ance. W e therefore b eliev e that comm unities in th is set are b iased to b e more easy to reco v er b y optimizing conductance, and therefore d o not consider them here. Results with these top 5000 ground truth comm unities are av aila ble in tables 1–3 in the sup plemen tary material 2 . In addition to the SNAP datasets we also includ e the Flic kr so cial n et wo rk d at aset (W ang et al., 2012). 4.2.3 Protein Inte ra ction Network D a t aset s W e h av e also ru n exp eriments on protein interac tion netw orks of yea st fr o m th e BioGRID database (Stark et al., 2006). This database cu r at es netw orks from sev eral d iffe rent studies. W e h a v e constru cted net w orks for Ga vin et al. (2006), Krogan et al. (2006), Collins et al. (2007), Costanzo et al. (2010), Hopp i ns et al. (2011), as w ell as a net w ork th a t is the u nion of all interact ion net w orks confir med by ph ysical exp erimen ts. As ground truth communities we tak e the CYC2008 catalog of pr o tein complexes for eac h of the net w orks (Pu et al., 2009). 4.2.4 Other D a t asets Additionally we used some classical datasets with known comm unities: Z a c hary’s k arate club Zac hary (1977); F o otball: A netw ork of American college fo otball games (Girv an and Newman, 2002); P olitical b o oks: A n e t w ork of b ooks ab out US p olitics (Krebs, 2004); and Po liti- cal blogs: Hyp erlinks b et w een weblog s on US p olitics (Adamic and Glance , 2005). These datasets might not b e v ery w ell suited f o r this problem, since th e y h a v e v ery few comm u- nities. 4.3 Results In all our exp erimen ts we use a single seed no de, dr a wn u niformly at rand o m from th e comm unit y . W e hav e also p erformed exp eriments with multiple seeds; the r e sults of those exp erimen ts can b e found in the su p plemen tary m a terial. T o k eep the computation time m a nageable we hav e p erformed all exp erimen ts on a random sample of 1000 groun d-truth communities. F or d at asets with fewe r than 1000 comm unities, we in c lude the same comm unity m ultiple times w ith differen t seeds. Since the datasets h e re considered hav e inf orm a tion ab out ground truth comm unities, a n a tural external v alidation criterion to assess the p erformance of algorithms on these datasets is to compare the comm unit y p rodu c ed by an algorithm with the ground truth one. In general, that is, when ground truth information is not a v ailable, this task is more subtle, b eca use it is not clear what is a go od external v alidati on m e tric to ev aluate a comm unit y (Y an g and Lesk o v ec, 2015). W e measure qu a lit y p erform an ce with the F 1 score, whic h for comm unit y fin ding can b e d efined as F 1 ( C, C ∗ ) = 2 | C ∩ C ∗ | | C | + | C ∗ | , 2. The supplementary material is a v ailable from http: //cs.ru.nl/ ~ tvanlaarho ven/conducta nce2016 18 Local Network Com munity Detection with Continuous Optimiza tion Dataset PGDc -0 PGDc -d EMc -0 EMc -d YL HK PPR LFR (om=1) 0.967 0.185 0.868 0.187 0.203 0.040 0.0 41 LFR (om=2) 0.483 0.095 0.293 0.092 0.122 0.039 0.0 41 LFR (om=3) 0.275 0.085 0.158 0.083 0.110 0.037 0.0 39 LFR (om=4) 0.178 0.074 0.100 0.072 0.092 0.032 0.0 34 Karate 0.831 0.472 0.816 0.467 0.600 0.811 0.914 F o otball 0.792 0.816 0.766 0.805 0.816 0.471 0.2 83 P ol.Blog s 0.646 0.1 41 0.661 0.149 0.017 0.661 0.535 P ol.Books 0.596 0.187 0.622 0.197 0.225 0.641 0.663 Flic kr 0.098 0.027 0.097 0.027 0.013 0.054 0.118 Amazon 0.47 0 0.522 0.42 5 0.522 0.493 0.245 0.1 30 DBLP 0.356 0.369 0.317 0.371 0 .341 0.214 0.210 Y outub e 0.089 0 .251 0.073 0.248 0.228 0.037 0.0 71 Liv eJournal 0.067 0 .262 0.059 0.259 0.183 0.035 0.0 49 Orkut 0.042 0 .231 0.033 0.231 0.171 0.057 0.0 33 CYC/Ga vin 2006 0 .474 0.543 0.455 0.543 0.526 0.336 0.2 94 CYC/Krogan 2006 0.410 0 .513 0.364 0.511 0.504 0.229 0.169 CYC/Collins 2007 0.346 0 .429 0.345 0.429 0.416 0.345 0.345 CYC/Costanzo 2010 0.174 0 .355 0.172 0.351 0.314 0.170 0.17 0 CYC/Hoppins 2011 0.368 0 .405 0.368 0.405 0.424 0.368 0.368 CYC/all 0.044 0.459 0.017 0.459 0.425 0.016 0.002 T able 2: Av erage F 1 score b et w een reco v ered communities and groun d-truth. Th e b est result for eac h d a taset is indicated in b old, as are the results not significantl y w orse according to a paired T -test (at significance lev el 0 . 01). where C is th e r e co v ered communit y and C ∗ is the ground truth one. A higher F 1 score is b etter, with 1 ind icating a p erfect corresp ondence b et we en th e tw o communities. Note that a seed no de migh t b e in multiple ground tru th communities. In this case w e only compare the reco v ered comm unit y to th e true comm unit y that we started with. If a metho d fin ds another ground truth comm unity this is not detected, and so it results in a lo w F 1 score. W e also analyze the outpu t of these algorithms w i th r e sp ect to the condu ct ance of pro duced comm unities and their size. Results on the run time of the algorithms are rep orted in the su pplemen tary material (T able 4). Figure 2 shows the F 1 scores as a function of the p a rameter σ . T able 2 s ho ws th e F 1 scores comparing th e r e sults of the metho ds to the true communities. T able 3 shows the mean size of th e foun d comm unities, and T able 4 their conductance. In general, results of these exp erimen ts indicate that on real-life netw orks, our metho ds based on contin u ou s relaxation of condu ct ance, PPR and HK pro duce comm unities with go o d conductance, bu t all are less faithful to the groun d truth when the net w ork cont ains man y small comm u nities. In PGDc , EMc the automatic c hoice of σ helps to ac hiev e results closer to the ground truth , and the built-in tendency of YL to fa v or sm a ll comm u nities helps 19 v an Laarhoven and Marchiori Dataset PGDc -0 PGDc -d EMc -0 EMc -d YL H K PPR LFR (om=1) 52.3 6.2 71.8 6.3 5.9 2410 .0 236 6.2 LFR (om=2) 93.2 5.6 292.8 6.4 4.9 240 4.4 23 11.6 LFR (om=3) 104.7 5.6 451.5 6.4 5.0 2399 .4 2283 .7 LFR (om=4) 108.9 4.9 530.2 5.7 4.9 2389 .1 2262 .0 Karate 20.0 8.0 24.1 8.0 8.8 16.7 17.1 F o otball 1 4.7 9.5 16.2 9.4 8.8 40.5 56.5 P ol.Blog s 515.6 110.1 538.9 118.1 7.2 49 2.7 10 51.1 P ol.Books 37.8 5.2 43.1 5.7 6.7 49.3 53.4 Flic kr 639 .9 73.0 644.6 73.5 12.9 174.2 1 158.1 Amazon 25. 2 5.6 45.6 5.7 6.4 88.8 2081 9.9 DBLP 61.9 5.4 83.5 6.1 6.0 55.0 24495.0 Y outub e 340.6 1 9.4 474.2 21.3 9.3 147 .9 2095 5.5 Liv eJournal 2 43.7 5.5 309.3 5.9 10.8 153.2 3428.7 Orkut 245.1 1 7.9 344.7 19.1 11.1 212.0 163 4.0 CYC/Ga vin 2006 19.7 3.4 34.3 3.5 3.1 236. 7 621 .9 CYC/Krogan 2006 48.4 7.0 138.8 9.4 3.7 723.8 1756 .3 CYC/Collins 2007 202.9 1 9.5 207.2 19.5 2.6 192 .0 189 .4 CYC/Costanzo 2010 540.2 5 8.1 564.2 66.5 5.9 1058 .8 942.9 CYC/Hoppins 2011 2 29.9 110.1 235.5 110.4 4. 3 29 5.2 295.2 CYC/all 65 7.5 16.0 841.9 17. 0 9.6 2795. 2 5786 .0 T able 3: Averag e size of the reco v ered comm unities. as w ell. On the other h an d , on net w orks with large comm unities our metho ds, PPR and HK w ork b est. On the artificial LFR data con tinuous relaxation of conductance seems to w ork b est. This result indicates that the LFR mo d el of ‘what is a comm unit y’ is someho w in agreemen t with th e notion of lo cal comm u nit y as lo cal optimum of the con tin uous relaxat ion of conductance. Ho w ev er, as observ ed in recen t works like (Jeub et al., 2015), th e LFR mo del d oes not seem to repr e sen t the d iv erse charac teristics of r e al-life communities. W e ha v e included tables of the standard d evi ation in the su pplemen tary m a terial. Ove r- all, the standard deviation in cluster size is of the same order of magnitude as the mean. The standard deviation of the conductance is around 0 . 1 for LFR datasets, 0 . 2 for th e SNAP datasets and 0 . 3 for the CYC datasets. It is not surprisin g that the v ariance is this high, b ecause the comm unities v ary a lot in size and d ensit y . Results on th ese datasets can b e sum mariz ed as follo ws. 4.3.1 Ar tificial LFR D a t asets On these d a tasets, HK and PPR tend to fin d comm unities th a t are muc h to o large, with small conductance b ut also with lo w F 1 scores. This happ ens b ecause the LFR n et wo rks are sm all, and th e m e tho ds are ther efore able to consider a large part of the no des in the net w ork. On the other hand, Y L alw a ys starts its searc h at small comm unities, and it stops early , so the communities it finds are smaller than the groun d tr u th ones on these netw orks. 20 Local Network Com munity Detection with Continuous Optimiza tion Dataset PGDc -0 PGDc -d EMc -0 EMc -d YL HK PPR LFR (om=1) 0.301 0.750 0.304 0.74 9 0.755 0.250 0.27 3 LFR (om=2) 0.532 0.786 0.541 0.78 7 0.780 0.315 0.33 8 LFR (om=3) 0.589 0.793 0.587 0.79 3 0.781 0.333 0.35 4 LFR (om=4) 0.604 0.791 0.595 0.79 2 0.775 0.341 0.35 9 Karate 0.129 0.460 0.081 0.475 0.327 0.222 0.136 F o otball 0.27 7 0.356 0.27 4 0.362 0.385 0.244 0.155 P ol.Blog s 0.228 0.743 0.212 0.73 7 0.867 0.2 29 0.137 P ol.Books 0.140 0.622 0.107 0.611 0.571 0.127 0.06 5 Flic kr 0.777 0.937 0.777 0.937 0.951 0.864 0.762 Amazon 0.181 0.464 0.180 0.463 0.402 0.0 81 0.053 DBLP 0.246 0.571 0.257 0.56 5 0.498 0.133 0.14 7 Y outub e 0.601 0.765 0.711 0.759 0.700 0.201 0.341 Liv eJournal 0.563 0.875 0.589 0.874 0.774 0.336 0.489 Orkut 0.718 0.916 0.731 0.917 0.928 0.750 0.71 1 CYC/Ga vin 2006 0.61 4 0.734 0.611 0.732 0.735 0.532 0.5 00 CYC/Krogan 2006 0.466 0.626 0.469 0.620 0.617 0.325 0.26 5 CYC/Collins 2007 0.716 0.953 0.712 0.953 0.972 0.720 0.730 CYC/Costanzo 2010 0.759 0.931 0.755 0.929 0.934 0.672 0.646 CYC/Hoppins 2011 0.788 0.883 0.785 0.882 0.970 0.763 0.763 CYC/all 0.674 0.872 0.742 0.87 4 0.840 0.3 63 0.026 T able 4: Averag e conductance of th e r e co v ered communities. The b est F 1 results are ac hiev ed by PGDc with σ = 0, that is, when the cont in uous relaxation of conductance is used as the ob jectiv e function. This metho d emplo ys a more p o werful optimizer th an YL, so it is able to find a large comm unity with a b etter condu c- tance, bu t it still stops at the first local optimum. I n the LFR datasets these optima are v ery clear, and corresp ond closely to the ground truth communities. In all cases EMc shows similar or sligh tly wo rse p erformance compared to PGDc , so the gradient d esc end algorithm should b e preferred. The automatic c hoice of σ leads to communities whic h are of relativ ely small size. W e b eliev e that this happ ens b ecause th e no des in LFR d a tasets all hav e exactly the same fraction of w ith in comm unit y edges. Increasing σ sud denly make s the gradien t for most of these no des p ositiv e. In real netw orks there are often hubs that are more cen tral to a comm unit y , with m ore connections to the communit y’s no des and to the seed. These hubs still can b e found at higher v alues of σ . 4.3.2 Small Real-Life Social Networks with Few Communities (Kara te, F ootball , Blogs , Books) Our metho ds based on con tin uous relaxation of conductance yield th e b est F 1 results on the F o otball and Blog n et wo rks, w hile PPR p erforms b est on th e other tw o net w orks and ac hiev es b est o v erall conductance. 21 v an Laarhoven and Marchiori 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 σ F 1 Figure 2: Averag e F 1 score as a function of th e σ parameter on the SNAP datasets with the PGDc metho d. 4.3.3 Large Soc i al N etw ork with Big Communities (Fl i ckr) On th is net w ork, PPR ac h iev es th e b est results b oth in terms of F 1 score as well as con- ductance. Ho w ev er the the pro duced comm unities are ab out four time smaller than the ground truth comm unities, w hic h ha v e more than 4000 n o des. PGDc and EMc with σ = 0 yield comm unities of condu ct ance similar to that of PPR comm u nitie s, bu t their size is s mal ler (ab out 650 n odes). This happ ens b ecause the algorithms are r e stricted to 1000 no des around the seed, without this restriction larger comm unities would b e found. S o me- what surp r isingly HK pro duces communities of relativ ely small size (ab o ut 175 n odes). Th e automatic choic e of σ yields to ev en smaller comm unities (ab out 64 no des). The smallest size comm unities are pro duced b y YL (ab out 13 no des). 4.3.4 Large Real -L ife SNAP Networks w i th Many Small Communities On these net w orks the automatic c hoice of σ giv es b est r esu lt s, consisten tly outp erforming the other algorithms. I n Figure 2, the F 1 score of PGDc and EMc as a f unctio n of σ is plotted. F or some d atasets a small v alue of σ w orks w ell, while for others a larger v alue of σ is b etter. Our pro cedure to c ho ose σ pro duces results that are close to, but sligh tly b elo w, the b est a p osteriori c hoice of σ . So on these net w orks the p roposed pro cedure p ositiv ely affects the p erformance of our algorithms. YL fav ors comm unities of small s iz e less faithfu l to the groun d tru th. PGDc -0, EMc -0, PPR and HK ‘explo de’, and pro duce ve ry large comm unities. F or our metho ds th is ‘explosion’ is limited only b ecause we limit the searc h to 1000 no des near the seed. The groun d-truth comm unities of these datasets ha v e rather high conductance, and the n et wo rks ha v e a v ery lo w clus t ering co efficien t. I n suc h a case, 22 Local Network Com munity Detection with Continuous Optimiza tion comm unities ha v e man y links to no des outside, hence conductance alone is clearly not suited to find i ng these t yp e of lo cal comm unities. 4.3.5 Real-Life Protein Int era ction Networks with Ver y Small Communities (CYC) Also on these net w orks the automatic c hoice of σ giv es b est resu lt s. As exp ected, du e to the v ery small size of the ground truth comm unities, YL also achiev es v ery go o d r esults. The other algorithms tend to p rodu c e less realistic, large comm unities whic h h a v e b etter conductance. 4.3.6 R unning Time The b est p erforming algorithm with r espect to run ning time is HK . PGDc and EMc are ab out four times slo w er with a fi xed v alue of σ , and ten to t w en t y times slo w er w hen auto- matically determining σ . Th e runn ing times are included in T able 4 of the supp lementary material. All exp erimen ts we re r un on a 2.4GHz Intel XEON E7-4870 mac hine. Note that the differen t metho d s are implemented in d i fferent languages (our implemen tation is written in Octa v e, w hile HK and PPR are implemen ted in C+ +), so the ru n ning times only giv e an indication of the o v erall tr en d, and can not b e compared directly . 4.3.7 Top 5000 Communities Results with only the top 5000 groun d truth communities a v ailable at the SNAP dataset collect ion are similar to the r e sults with all comm unities. As exp ect ed, the F 1 score is muc h higher and the condu ctance of the reco v ered comm unit y is b etter. Because these ground truth comm unities hav e a b etter condu ctance, it is b etter to optimize conductance, that is to take σ = 0. As a consequence the p erformance of PGDc -0 and EMc -0 is b etter than that of PGDc -d an d EMc -d f o r these comm unities. T h e f ull results are a v ailable in T ables 1–3 in th e supp le ment ary material. 5. Discussion This pap er inv estiga ted conductance as an ob jectiv e function f o r lo cal communit y detection from a set of seeds. By making a con tin uous relaxation of conductance we show h o w standard tec hniques suc h as p ro jected gradien t descent can b e u sed to optimize it. E v en though this is a con tin uous optimizatio n p roblem, we sho w that the lo cal optima are almost alw a y s discrete comm unities. W e further sh ow ed how linking conductance with kernel w eigh ted k -means clustering leads to the n e w σ -conductance ob jectiv e f u nctio n and to simple y et effectiv e algorithms for lo ca l comm unit y detection b y seed expansion. W e provided a formalization of a class of go od lo cal comm unities around a set of seeds and show ed that the prop osed algorithms can fin d them. W e susp ect that th e se communi- ties can also b e exactly retrieve d using lo cal communit y algorithms based on the diffu sio n metho d, but do not yet h a ve a pro of. The condition that suc h comm unities shou ld b e cen- tered around the seeds raises the question of h o w to find such seeds. Although v arious wo rks ha v e stud ie d seed selection for diffusion based algorithms, suc h as Kloumann and Kleinberg 23 v an Laarhoven and Marchiori (2014), this p roblem remains to b e in v estigat ed in the con text of lo cal comm unit y d et ection b y σ -conductance optimization u sing PGDc and EMc . Our exp erimen tal results indicate the effectiv eness of direct optimization of a con tin uous relaxation of σ -co ndu ctance using gradient descen t and exp ectation maximization. In our algorithms w e used comm unit y density as a criterion to c ho ose σ . This resulted to b e a go od c hoice for the p erformance of our algorithms on the SNAP net w orks. It wo uld b e in teresting to in v estigat e also other criteria to c ho ose σ . C o nv ersely , the fact that maxim um density is a go od criterion for selecting σ imp lie s that it migh t also b e directly optimized as an ob jectiv e f or fin d ing comm unities. On some datasets, when optimizing normal conductance, that is, w it h σ = 0, our meth- o ds sometimes find very large comm unities. These comm unities will ha v e a very go od conductance, b ut they do n o t corresp ond w ell to the groun d truth. In some s e nse th e optimizer is ‘too go o d ’, and conductance is not the b est criterion to describ e these commu- nities. A b etter ob jectiv e w ould p erhaps tak e in to accoun t the s i ze of th e comm unit y more explicitly , bu t this needs to b e inv estigated fu rther. In this pap er w e hav e used gradient descen t, a first order op timization metho d whic h utilizes only the ob jectiv e f unction’s gradient. More adv anced optimization metho ds also use second deriv ativ es or appro ximations of those. W e b eliev e that such metho ds will not brin g a large adv an tage compared to gradient descen t, b ecause during the optimization man y co ordinates are at the b oundary v alue 0 or 1, and second deriv ativ es w ould not help to lo c ate these b oundary p oin ts. O ther constrained optimizers su c h as interior p oin t metho ds ha v e the p r oblem that they need to insp ect a m uc h larger p art of the net wo rk, p oten tially all of it, b ecause intermediate steps h a v e non zero mem b ership for all no des. Ac kno wledgmen t s W e thank the review ers for their u seful commen ts. This w ork has b een partially f unded b y the Netherlands Organization for S ci en tific Researc h (NWO) within the EW TOP Compar- timen t 1 p r o ject 612.001.352 . References Lada Adamic and Natalie Glance. The p olitic al b l ogosphere and the 2004 U.S. election: Divided they b log. In LinkKD D ’05: Pr o c e e dings of the 3r d international worksho p on Link disc overy , pages 36–43, 2005. Reid Anders e n an d Kevin J. Lang. Communities from seed sets. In Pr o c e e dings of the 15th International Confer enc e on World Wide Web , WWW ’06, pages 223–232, New Y ork, NY, USA, 2006. A CM. ISBN 1-59593-3 23-9. Reid Andersen, F an Chung, and Kevin Lang. Lo cal graph p artitioning using pagerank v ectors. I n F oundations of Computer Scienc e, 2006. FOCS’06. 47th Annual IEEE Sym- p osium on , pages 475–486 . IEEE, 2006. Haim Avron and Lior Horesh . C o mmunit y d et ection using time-dep enden t p ersonalized pagerank. In Pr o c e e dings of The 32nd International Confer enc e on Machine L e arning , pages 1795–18 03, 2015 . 24 Local Network Com munity Detection with Continuous Optimiza tion Shuc hi Chawla , Rob ert Krauthgamer, Ra vi Kumar, Y u v al Rabani, and D. Siv akumar. On the hardn ess of appr o ximating m ulticut and s parsest-c ut. In Pr o c e e dings of the 20th Annual IEEE Confer enc e on Computational Complexity , CCC ’05, pages 144–1 53, W ash- ington, DC, US A, 2005. IEEE C o mputer S ociet y . ISBN 0-7695-23 64-1. Jiy ang Chen, Osmar Za ¨ ıane, and Randy Go ebel. L o cal communit y iden tification in so cia l net w orks. In So cial Network A nalysis and Mini n g, 2009 . ASONAM ’09 . International Confer enc e on A dvanc es in , p ages 237–2 42. IEEE , 2009. Qiong Chen, Ting-Ting W u, and Ming F ang. Detecting lo cal communit y structur e s in complex n e t w orks b a sed on lo cal d eg ree cent ral no des. Physic a A: Statistic al M e chanics and its Applic ations , 392(3):529 –537, 2013 . F an Chung. T he h eat kernel as the pagerank of a graph. P r o c e e dings of the Nation al A c ademy of Scienc es , 104(5 0):1973 5–19740, 2007. Aaron Clauset. Find i ng lo cal comm unity structure in net w orks. P h ysic al r eview E , 72(2 ): 02613 2, 2005. Sean Collins, et al. T o w ards a comprehensive atlas of the ph ysical in teracto me of sacc ha- rom yces cerevisiae. Mole cular Cel lular Pr ote omics , p ages 60038 1–6002 00, 2007. Mic hael Costanzo, et al. The genetic land sca p e of a cell. Scienc e , 327(59 64):425 –431, 2010. Inderjit S. Dhillon, Y uqiang Guan, and Brian Ku lis. W eigh ted graph cu ts without eige nv ec- tors a multilev el approac h. IEEE T r ans. Pattern Ana l. Mach. Intel l. , 29(11) :1944–1 957, No v em b er 2007. IS SN 0162-88 28. San to F ortu nato . Comm unit y d et ection in graphs. Physics R ep orts , 486:75–17 4, 2010. Ullas Gargi, W enju n Lu , V ahab S Mirrokni, and Sangho Y o o n. Large-scale comm unity detection on youtub e for topic disco v ery and exploration. In ICWSM , 2011. Anne-Claude Gavi n, et al. Pr oteome surve y revea ls mo dularit y of th e yeast cell m a c hinery . Natur e , 440(7084):6 31–636, 2006. Mic helle Girv an and Mark E. J. Newman. Communit y s tr ucture in so cial and biologic al n et - w orks. Pr o c e e dings of the N a tional A c ademy of Scienc es of the U nite d States of Americ a , 99(12 ):7821–7 826, 2002. Da vid F. Gleic h and C. Seshadh ri. V ertex neighborh oo ds, lo w condu c tance cuts, and goo d seeds for lo cal comm unity metho ds. In Pr o c e e dings of the 18th ACM SIGKDD Interna- tional Confer enc e on Know le dge Disc overy and Data M ining , KDD ’12, pages 597–6 05, New Y ork, NY, US A, 2012. A CM. ISBN 978-1-45 03-146 2-6. Suzanne Hoppins, et al. A mitochondrial-focused genetic interac tion map rev eals a scaffold- lik e complex required for in ner m embrane organization in mito c h o ndria. The J o urnal of Cel l Biolo gy , 195(2):3 23–340 , 2011. 25 v an Laarhoven and Marchiori Lucas GS Jeub, Prak ash Balac handran, Mason A Porter, P eter J Mucha, and Mic hael W Mahoney . Th i nk lo cal ly , act lo c ally: Detection of small, medium-sized, and large com- m unities in large net w orks. PH YSICAL REVIE W E Phys R ev E , 91:0128 21, 2015 . U Kang and Ch ristos F aloutsos. Bey ond “ca v eman communities”: Hubs and sp ok es for graph compression and min in g . In Data Mining (ICDM), 2011 IEEE 11th Internation al Confer enc e on , pages 300–309. IEEE, 2011. Kyle K lo ster and Da vid F. Gleic h. Heat k ernel based comm unit y detection. In Pr o c e e dings of the 20th ACM SIGKDD International Confer enc e on Know le dge D isc overy and Data Mining , KDD ’14, pages 1386–1 395, New Y ork, NY, USA, 2014. A CM. ISBN 978- 1-4503- 2956- 9. Isab el M Kloumann and Jon M Klein b erg. Communit y membersh ip iden tification fr o m small seed sets. In Pr o c e e dings of the 20th ACM SIGKDD international c onfer enc e on Know le dge disc overy and data mining , p ages 1366– 1375. A CM, 2014. V aldis Krebs. New p olitical patterns. Editorial, 2004. Nev an J . Krogan, et al. Global landscap e of pr o tein complexes in th e y east s acc haromyc es cerevisiae. Natur e , 440(7084 ):637–64 3, 2006. Andrea Lancic hinetti, San to F ortunato, and Filipp o Radicc hi. Benc hmark graphs for testing comm unit y detection algorithms. Physic al R eview E , 78:04611 0, 2008. Andrea Lancic hinetti, Filipp o Radicc hi, J o s ´ e J Ramasco, San to F ortunato, et al. Findin g statistica lly significant comm unities in net w orks. PloS one , 6(4):e18 961, 2011. Jure Lesko ve c and Andrej Krevl. SNAP Dataset s: Stanford large net w ork dataset collectio n. http://s nap.stanford.ed u /data , Ju ne 2014. Jure Lesko ve c, Kevin J Lang, Anirban Dasgupta, and Mic hael W Mahoney . Statistical prop erties of comm unit y structur e in large social and inform a tion n e t w orks. In P r o c e e dings of the 17th international c onfer enc e on World Wide Web , p a ges 695–704. A CM, 2008. Jure L e sk o v ec, Kevin J Lang, and Mic hael Mahoney . Em pirical comparison of algorithms for netw ork comm unity detection. In P r o c e e dings of the 19th international c onfer enc e on World wide web , p a ges 631–640 . A CM, 2010. L´ aszl´ o Lo v´ asz and Mikl´ os Simonovits. The mixing rate of Mark o v chains, an isop erimet- ric inequalit y , and computing the v olume. In F oundations of Computer Sc ienc e, 1990. Pr o c e e dings., 31st Annual Symp osium on , pages 346–354. IEEE, 1990. Mic hael W Mahoney , Lorenzo O recc hia, and Nisheeth K Vishnoi. A lo cal sp ectral m e tho d for graphs: With app lic ations to impro ving grap h p a rtitions and exploring data graphs lo c ally . The Journal of Machine L e arning R ese ar ch , 13(1):233 9–2365 , 2012. Nina Mishr a , Rob ert Schreib er, Isab elle S t an ton, and Rob ert Endre T arjan. Finding strongly knit clusters in so cial net w orks. Internet Mathematics , 5(1):155–1 74, 2008. 26 Local Network Com munity Detection with Continuous Optimiza tion Alan Mislo v e, Bimal Viswanat h, Krish na P . Gummadi, and P eter Druschel. Y ou are who y ou kno w: Inferrin g user profiles in online so cial n et wo rks. In Pr o c e e dings of the Thir d A CM International Confer enc e on We b Se ar ch and Data Mining , WSDM ’10, pages 251– 260, New Y ork, NY, US A, 2010. A CM. ISBN 978-1-60 558-88 9-6. Shuy e Pu, Jessica W on g, Brian T ur ner, Emerson Cho, and Shoshana J. W o dak. Up - to-date catalo gues of yeast protein complexes. N ucleic A cids R ese ar ch , 37(3):825– 831, 2009. Satu Elisa Schaeffe r. Graph clustering. Computer Scienc e R eview , 1(1):27–6 4, 2007. ISS N 15740 137. Ji ˇ r ´ ı ˇ S ´ ıma and Satu Elisa Sc haeffer. On the NP-completeness of some graph cluster measures. In SOFSEM 2006: The ory and Pr actic e of Computer Scienc e , pages 530–537. Sprin g er, 2006. Daniel A Sp ie lman and Shang-Hua T eng. Nearly-linear time algorithms for graph parti- tioning, graph sparsifi ca tion, and solving linear systems. In Pr o c e e dings of the thirty-sixth annual ACM symp osium on The ory of c omputing , pages 81–90. A CM, 2004. Chris Stark, Bobby-Joe Breitkreutz, T eresa Reguly , Lorrie Bouc her, Ashton Breitkreutz, and Mik e Ty ers. Biogrid: a general rep ository for in teraction datasets. Nucleic A cids R ese ar ch , 34(Database-Issue):535 –539, 2006. Xufei W ang, Lei T ang, Hu a n Liu, and L e i W ang. Learning w it h m ulti-resolution o v erlapping comm unities. Know le dge and Informat ion Systems (KAIS) , 2012. Jo yce J iyoung Whang, Da vid F Gleic h, and Ind er j it S Dhillon. Ov erlapping comm unit y detection u sing seed set expansion. In P r o c e e dings of the 22nd ACM international c on- fer enc e on Confer enc e on information & k no w le dge management , pages 20 99–210 8. A CM, 2013. Xiao-Ming W u, Zh e nguo Li, Anthon y M So, John W right , and Shih -F u Ch a ng. Learnin g with p a rtially abs o rbing random wal ks. In A dvanc e s in Neur al Informatio n P r o c essing Systems , pages 3077–308 5, 2012. Y ub a o W u , Ruoming Jin, Jin g Li, and Xiang Zh a ng. Robust lo cal comm unit y detection: On fr e e r ider effect and its elimination. Pr o c. VLDB Endow. , 8(7):79 8–809, F ebruary 2015. ISSN 2150-8097 . Jaew on Y ang and Jur e L e sk o v ec. Defining and ev aluating netw ork comm unities based on ground-truth. In P r o c e e dings of the ACM SIGKDD Workshop on Mining Data Semantics , MDS ’12, pages 3:1–3:8. ACM, 2012. I SBN 978-1-45 03-1546-3 . Jaew on Y ang and Jur e L e sk o v ec. Defining and ev aluating netw ork comm unities based on ground-truth. Know le dge and Information System s , 42(1):181 –213, 2015. IS SN 0219- 1377. W a yne W. Zachary . An in fo rmation flo w mo del for conflict and fission in sm a ll groups. Journal of Anthr op olo gic al R ese ar c h , 33:452–47 3, 1977. 27 v an Laarhoven and Marchiori Zeyuan A Zhu, Silvio Lattanzi, and V ahab Mirrokni. A lo ca l algorithm for find ing w ell- connected clusters. In P r o c e e dings of the 30th International Confer enc e on M a chine L e arning (ICML-13) , pages 396–4 04, 2013a. Zeyuan Allen Zhu, Silvio Lattanzi, and V ahab Mirrokni. Lo cal graph clustering b ey ond Cheeger’s inequalit y . arXiv pr eprint arXiv:1304.8132 , 2013b. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment