Parallelizing Word2Vec in Shared and Distributed Memory
Word2Vec is a widely used algorithm for extracting low-dimensional vector representations of words. It generated considerable excitement in the machine learning and natural language processing (NLP) communities recently due to its exceptional perform…
Authors: Shihao Ji, Nadathur Satish, Sheng Li
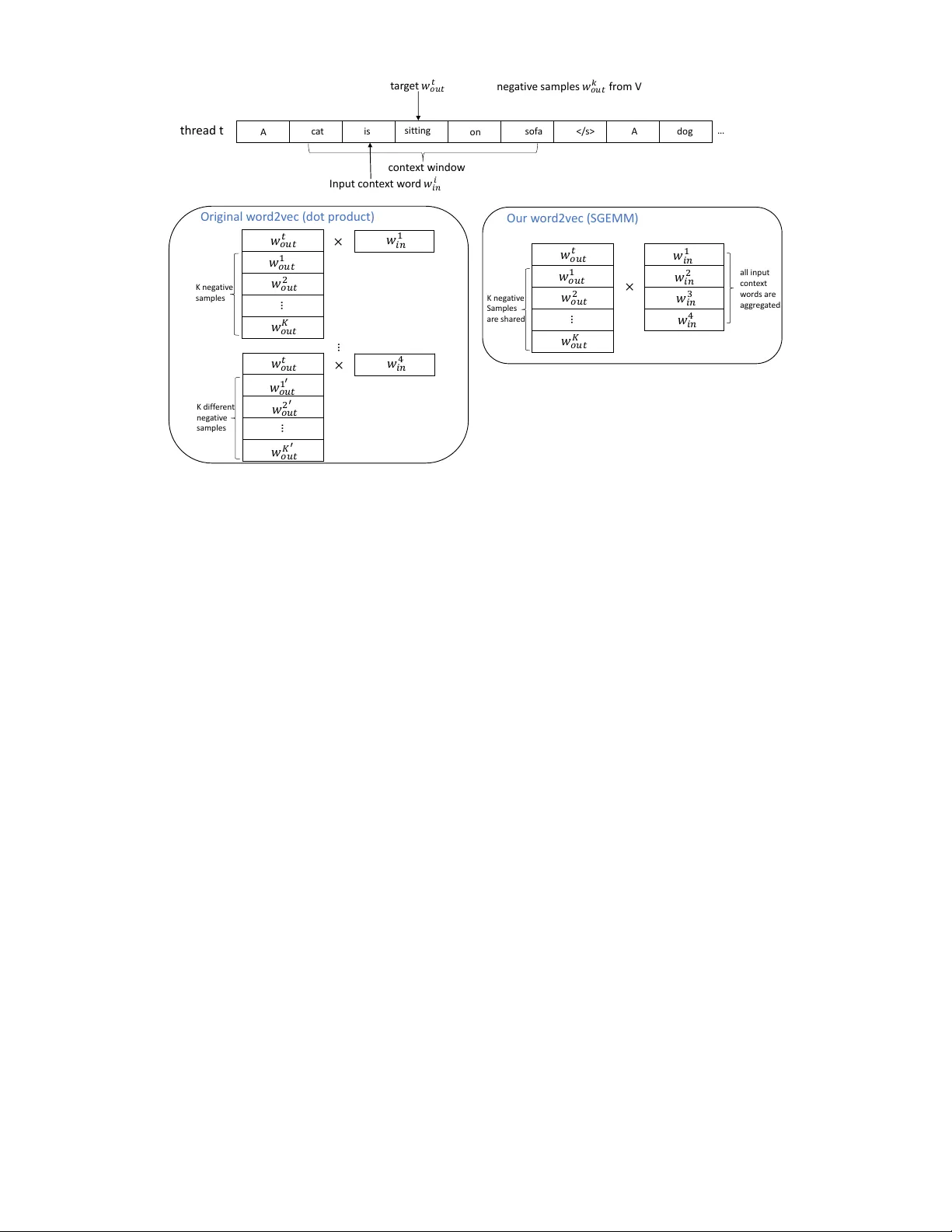
P arallelizing W ord2V ec in Shared and Distrib uted Memory Shihao Ji, Nadathur Satish, Sheng Li, Pradeep Dubey Parallel Computing Lab, Intel Labs, USA Emails: { shihao.ji, nadathur .rajagopalan.satish, sheng.r .li, pradeep.dubey } @intel.com Abstract —W ord2V ec is a widely used algorithm for extracting low-dimensional vector repr esentations of words. It generated considerable excitement in the machine learning and natural language processing (NLP) communities r ecently due to its exceptional performance in many NLP applications such as named entity recognition, sentiment analysis, machine translation and question answering. State-of-the-art algorithms including those by Mikolov et al. ha ve been parallelized for multi-core CPU architectures but are based on vector-v ector operations that are memory-bandwidth intensive and do not efficiently use computational resources. In this paper , we improv e reuse of various data structures in the algorithm through the use of minibatching, hence allowing us to express the problem using matrix multiply operations. W e also explore differ ent techniques to distribute word2v ec computation across nodes in a compute cluster , and demonstrate good strong scalability up to 32 nodes. In combination, these techniques allow us to scale up the computation near linearly across cores and nodes, and process hundreds of millions of words per second, which is the fastest word2vec implementation to the best of our knowledge. I . I N T RO D U C T I O N Natural language processing (NLP) aims to process text efficiently and enable understanding of human languages; it is one of the most critical tasks to ward artificial intelligence [1]. One of the fundamental issues of NLP concerns ho w machines can represent words of a language, upon which more complex learning and inference tasks can be built efficiently . Instead of the traditional bag of words (or one-hot) representation, distributed word embedding represents each word as a dense vector in a low-dimensional embedding space such that se- mantically and syntactically similar w ords are close to each other . This idea has been applied to a wide range of NLP tasks with considerable success [2], [3], [4]. Recently , Mikolov et al. [5] generated considerable ex- citement in the machine learning and NLP communities by introducing a neural network based model to learn distributed word representations, which they call word2vec. It was sho wn that word2vec produces state-of-the-art performance on word similarity , word analogy tasks as well as many do wnstream NLP applications such as named entity recognition, machine translation and question answering [6], [7]. The word similar - ity task is to retrie ve w ords that are similar to a gi ven word. On the other hand, word analogy requires answering queries of the form a:b;c:? , where a, b , and c are words from the vocabulary , and the answer to the query must be semantically related to c in the same way as b is related to a . This is best illustrated with a concrete example: Gi ven the query king:queen;man:? we expect the model to output woman . The goal behind word2vec is to find word representations that are useful for predicting the surrounding words in a sentence. A common approach is to use the Skip-gram model architecture with negati ve sampling [5]. This method in volv es judging similarity between two words as the dot product of their word representations, and the goal is to minimize the distance of each word with its surrounding w ords while maximizing the distances to randomly chosen set of words (a.k.a “negati ve samples”) that are not expected to be close to the target. The formulation of word2v ec uses Stochastic Gradient De- scent (SGD) to solv e this optimization problem. SGD solv es optimization problems iterativ ely; at each step, it picks a pair of words: an input word and another word either from its neighborhood or a random ne gati ve sample. It then computes the gradients of the objective function with respect to the two chosen words, and updates the word representations of the two words based on the gradient values. The algorithm then proceeds to the next iteration with a different word pair being chosen. The formulation abo ve has two main issues: (1) SGD is inherently sequential: since there is a dependence between the update from one iteration and the computation in the next iteration (they may happen to touch the same word representations), each iteration must potentially wait for the update from the previous iteration to complete. This does not allow us to use the parallel resources of the hardware. (2) Even if the above problem is solved, the computation performed in each iteration is a single dot product of two word vectors. This is a level-1 BLAS [8] operation and is limited by memory bandwidth, thus not utilizing the increasing computational power of modern multi-core and many-core processors. T o solve (1), word2v ec uses Hogwild [9], a scheme where different threads process different word pairs in parallel and ignore any conflicts that may arise in the model update phases. In cache-coherent architectures, ho wev er , Hogwild tends to hav e true and false sharing of the model data structure between threads, and is heavily limited by inter-thread communication. In this work, we propose a simple yet efficient parallel algorithm to speed up the word2vec computation in shared memory and distrib uted memory systems. • W e present a scheme based on minibatching and shared negati ve samples to conv ert the lev el-1 BLAS operations of word2vec into the lev el-3 BLAS [8] matrix multiply operations, hence ef ficiently lev eraging the v ector units and multiply-add instructions of modern architectures. This is described in Section III. • W e parallelize this approach across batches of inputs, thereby reducing the total number of model updates to the shared model and hence limiting inter-thread com- munication. This allows our scheme to scale better than Hogwild. • W e perform experiments to scale out our technique to a cluster of 32 compute nodes. Nodes across the cluster perform synchronous model updates, and we follo w the technique proposed in [10] to reduce network traffic. W e adjust the frequency of propagating model updates across the network to achie ve balance between computation and communication. T o maintain a good con ver gence rate in the presence of a limited number of updates (as number of compute nodes increases), we explore a simple learning rate adjustment trick without the computation and memory overheads of other learning rate scheduling techniques, such as AdaGrad [11] and RMSProp [12]. In combination, these techniques allow us to scale the com- putation near linearly across cores and nodes, and process hundreds of millions of words per second, which is the fastest word2vec implementation to the best of our kno wledge. The remainder of the paper is organized as follows. In Sec. II we describe the basic word2vec model and the original parallelization scheme proposed by Mikolov et al. [5]. A ne w parallelization scheme is then presented in Sec. III, along with a distributed implementation cross nodes in a compute cluster . Example results on the One Billion W ords Benchmark [13] are presented in Sec. IV , with comparisons to the best known performance reported currently in the literature. Conclusions and future w ork are discussed in Sec. V . I I . T H E W O R D 2 V E C M O D E L W ord2vec represents each word w in a vocab ulary V as a lo w-dimensional dense vector v w in an embedding space R D , and attempts to learn the continuous w ord vectors v w , ∀ w ∈ V , from a training corpus such that the spatial distance between words then describes the similarity between words, e.g., the closer two w ords are in the embedding space, the more similar they are semantically and syntactically . These word representations are learned based on the distributional hypothesis [14], which assumes that words with similar con- text tend to have a similar meaning. Under this hypothesis, two distinct model architectures: Contextual Bag-Of-W ords (CBO W) and Skip-Gram with Negati ve Sampling (SGNS) are proposed in word2v ec to predict a target word from surrounding context [15], [5]. W e focus here on the SGNS model since it produces state-of-the-art performance and is widely used in the NLP community . The training objecti ve of the Skip-gram is to find word representations that are useful for predicting the surrounding 𝑀 𝑖𝑛 𝑤 𝑡 𝑤 𝑡 − 2 𝑤 𝑡 + 1 𝑤 𝑡 + 2 𝑤 𝑡 − 1 𝑀 𝑜𝑢𝑡 𝑀 𝑜𝑢𝑡 𝑀 𝑜𝑢𝑡 𝑀 𝑜𝑢𝑡 out p u t h idd en inp u t outp u t outp u t outp u t Fig. 1: The Skip-gram model architecture based on a simplified one hidden layer neural network model. words in a sentence from a large textual corpus. Giv en a sequence of training w ords { w 1 , w 2 , · · · , w T } , the objective of the Skip-gram model is to maximize the a verage log probability J (Ω) = 1 T T X t =1 X − c ≤ j ≤ c,j 6 =0 log p ( w t + j | w t ) , (1) where Ω is the model parameters to be optimized (and will be defined soon), c is the size of the training context (a sliding window around the center word w t ), and p ( w t + j | w t ) is the probability of seeing w ord w t + j giv en the center w ord w t . This probability function is formulated as a simplified one hidden layer neural network model, depicted in Fig. 1. The network has an input layer , a hidden layer without nonlinear transformation (also called projection layer), and a few soft- max output layers, each of which corresponds to an output word within the context window . T ypically , the network is fed as input w t ∈ R V , where V denotes the v ocabulary size, and it produces a hidden state h ∈ R D , where D is the size of the hidden layer or the dimension of the embedding space, which is in turn transformed to the output w t + j ∈ R V . Different layers are fully connected, with the weight matrix M out at output layers shared among all output words. Collecting all the weight matrices from this architecture, we denote the model parameter by Ω = { M V × D in , M V × D out } . In the Skip-gram model above, the input w t is a sparse vector of a 1-of- V (or one-hot) encoding with the element corresponding to the input w ord w t being 1 and the rest of components set to 0. Therefore, the basic Skip-gram formula- tion defines p ( w t + j | w t ) as the softmax function: p ( w O | w I ) = exp( h v w I in , v w O out i ) P V w =1 exp( h v w I in , v w out i ) (2) where h· , ·i denote the inner product between two vectors, v w in and v w out are the “input” and “output” vector representations of w , corresponding to the respectiv e rows of model parameter matrices M in and M out . The computation of this formulation is prohibiti vely e xpensiv e since its cost is proportional to V , which is the size of the vocab ulary and is often very large (e.g., around 10 6 ). T o improve performance of word2v ec, Mik olov et al. [5] introduced negati ve sampling that approximates the log of softmax (2) as log p ( w O | w I ) ≈ log σ ( h v w I in , v w O out i ) + K X k =1 E w k ∼ P n ( w ) [log σ ( − h v w I in , v w k out i )] , (3) where σ ( x ) = 1 1+exp( − x ) is the sigmoid (logistic) function, and the e xpectations are computed by dra wing random words from a sampling distribution P n ( w ) , ∀ w ∈ V . T ypically the number of negativ e samples K is much smaller than V (e.g., k ∈ [5 , 20] ), and hence roughly a V /K times of speed-up. Even though negati v e sampling is an effecti v e approxima- tion technique, as the size of the corpus is typically at the order of billions of words and v ocabulary size is at the order of millions (e.g., T = 10 9 , and V = 10 6 ), training word2vec model often takes tens of hours or e ven days for some Internet scale applications. I I I . W O R D 2 V E C A L G O R I T H M A N D I M P RO V E M E N T S In order to solve the optimization problem described in the previous section, Stochastic Gradient Descent (SGD) is commonly used. SGD is an iterati ve algorithm; at each itera- tion, a single ( w I , w O ) pair is picked, where w I is an input context word and w O is a target word or a negati v e sample. The gradient of the objectiv e function is then calculated w .r .t. the word vectors for w I and w O ; and a small change/update is made to these vectors. One of the problems of SGD is that it is inherently challenging to parallelize, i.e., SGD only updates the w ord v ectors of a pair of words at a time, and parallel model updates on multiple threads can result in conflicts if the threads try to update the vectors of the same word. The original implementation of word2vec by Mikolov et al. 1 uses Hogwild [9] to parallelize SGD. Hogwild is a parallel SGD algorithm that seeks to ignore conflicts between model updates on dif ferent threads and allows updates to proceed ev en in the presence of conflicts. The psuedocode of Hogwild SGD update is shown in Algorithm 1. The algorithm takes in a matrix M V × D in that contains the word representations for each input word, and a matrix M V × D out for the word representations of each output word. Each word is represented as an array of D floating point numbers, corresponding to one row of the two matrices. These matrices are updated during the computation. W e also take in a specific target word, and a set of N input context words around the tar get as depicted in Fig. 2. The algorithm iterates over the N input words in Lines 2-3. The psuedocode only shows a single thread; in Hogwild, the loop in Line 2 is parallelized ov er threads without any additional change in the code. In the loop at Line 6, we pick either the positiv e example (the target word in Line 8) or a negati ve example at random (Line 10). Lines 13-15 compute the gradient of the objecti ve function with respect to the choice of input word and positiv e/negati ve example. Lines 17–20 1 https://code.google.com/archiv e/p/word2vec/ Algorithm 1: Hogwild SGD implementation of word2vec in one thread. 1 Given model parameter Ω = { M in , M out } , learning rate α , 1 target word w t out , and N input words { w 0 in , w 1 in , · · · , w N − 1 in } 2 for (i = 0; i < N; i++) { 3 input_word = w i in ; 4 for (j = 0; j < D; j++) temp[j] = 0; 5 // negative sampling 6 for (k = 0; k < negative + 1; k++) { 7 if (k = 0) { 8 target_word = w t out ; label = 1; 9 } else { 10 target_word = sample one word from V; label = 0; 11 } 12 inn = 0; 13 for (j = 0; j < D; j++) inn += M in [input_word][j] * M out [target_word][j]; 14 err = label - σ (inn); 15 for (j = 0; j < D; j++) temp[j] += err * M out [target_word][j]; 16 // update output matrix 17 for (j = 0; j < D; j++) M out [target_word][j] += α * err * M in [input_word][j]; 18 } 19 // update input matrix 20 for (j = 0; j < D; j++) M in [input_word][j] += α * temp[j] ; 21 } perform the update to the entries M out [ pos/neg example ] and M in [ input context ] . Algorithm 1 reads and updates entries corresponding to the input context and positiv e/negati ve words at each iteration of the loop at Line 6. This means that there is a potential dependence between successiv e iterations. Hogwild ignores such dependencies and proceeds with updates regardless of conflicts. In theory , this can reduce the rate of conv ergence of the algorithm as compared to a sequential run. Howe ver , the Hogwild approach has been shown to work well in case the updates across threads are unlikely to be to the same word; and indeed for large v ocabulary sizes, conflicts are relati vely rare and con vergence is not typically af fected. A. Advantages and Drawbacks of Algorithm 1 Algorithm 1 has a few main advantages: threads do not need to synchronize between updates and can hence proceed independently with minimal instruction ov erheads. Further , the computation of the gradient is based off the current state of the model visible to the thread at that time. Since all threads update the same shared model, the values read are only as stale as the communication latency between threads, and in practice this does not cause much con ver gence problems for word2vec. Howe ver , the algorithm suf fers from two main drawbacks that significantly affect runtimes. First, since multiple threads can update the same cache line containing a specific model entry , there can be significant ping-ponging of cache lines across cores. This leads to high access latencies and significant drop in scalability . Second and perhaps e ven more importantly , there is a significant amount of locality in the model updates that is not exploited in the Hogwild algorithm. As an example, we can easily see that the same tar get word is used in the t ar g e t 𝑤 𝑜𝑢𝑡 𝑡 I npu t c on t e x t w or d 𝑤 𝑖𝑛 𝑖 c on t e x t win do w n eg a ti v e samples 𝑤 𝑜𝑢𝑡 𝑘 fr om V thr ead t 𝑤 𝑜𝑢𝑡 𝐾 … A c a t on so f a A is sit tin g … d og 𝑤 𝑜𝑢𝑡 𝑡 𝑤 𝑜𝑢𝑡 1 𝑤 𝑜𝑢𝑡 2 𝑤 𝑖𝑛 1 𝑤 𝑜𝑢𝑡 𝐾 … 𝑤 𝑜𝑢𝑡 𝑡 𝑤 𝑜𝑢𝑡 1 𝑤 𝑜𝑢𝑡 2 × × … 𝑤 𝑜𝑢𝑡 𝑡 𝑤 𝑜𝑢𝑡 1 ′ 𝑤 𝑜𝑢𝑡 2 ′ 𝑤 𝑖𝑛 4 × 𝑤 𝑖𝑛 1 𝑤 𝑖𝑛 4 𝑤 𝑖𝑛 3 𝑤 𝑖𝑛 2 𝑤 𝑜𝑢𝑡 𝐾 ′ … K n eg a t iv e samp les K d if f er en t n eg a t iv e samp les K n eg a t iv e Sam p les ar e sh ar ed a ll in p u t c ont e x t w or d s ar e ag gr eg a t ed Or i ginal w or d2v ec ( dot pr oduct ) Our w or d2v ec ( SGEMM ) Fig. 2: The parallelization schemes of the original word2vec (left) and our optimization (right). model updates for several input words. By performing a single update at a time, this locality information is lost, and the algorithm performs a series of dot-products that are level-1 BLAS operations and limited by memory bandwidth. It is indeed, as we show next, possible to batch these operations into a level-3 BLAS call which can more ef ficiently utilize the compute capabilities and the instruction sets of modern multi-core and man y-core architectures. B. New P arallelization Scheme in Shared Memory W e first discuss ho w we can exploit the av ailable locality in Algorithm 1. This can be done e ven on a single compute thread. W e then describe the impact of this step on paralleliza- tion and inter -thread communication. W e exploit locality in tw o steps. As a motiv ation, consider Fig. 2. The figure to the left shows the parallelization scheme of the original word2vec. Note that we compute dot products of the word vectors for a given input word w i in with both the tar get word w t out as well as a set of K negati ve samples { w 1 out , · · · , w K out } . Rather than doing these one at a time, it is rather simple to batch these dot products into a matrix vector multiply , a le vel-2 BLAS operation, as sho wn in the left side of Fig. 2. Howe ver , this alone does not buy significant performance improvement. Indeed, most likely the shared input word vector may come from cache. In order to conv ert this to a le vel-3 BLAS operation, we also need to batch the input context words. Doing this is non-trivial since the negativ e samples for each input word could be dif ferent in the original word2v ec implementation. W e hence propose “neg ativ e sample sharing” as a strategy , where we share neg ativ e samples across a small batch of input words. Doing so allows us to con vert the original dot-product based multiply into a matrix-matrix multiply call (GEMM) as shown on the right side of Fig. 2. At the end of the GEMM, the model updates for all the word vectors of all input words and tar get/sample w ords that are computed need to be written back. Performing matrix-matrix multiplies (GEMMs) rather than dot-products allows us to leverage all the compute capabilities of modern architectures including instruction set features such as multiply-add instructions in the Intel A VX2 instruction set. It also allo ws us to le verage heavily optimized linear algebra libraries. Note that typical matrix dimensions are not very large. For instance, the number of negativ e samples is only 5–20, and the batch size for the input batches are limited to about 10–20 for conv ergence reasons. Ne vertheless, we find that we get considerable speedups e ven with this le vel of reuse ov er the original word2vec. C. Consequence of the new parallelization scheme While the original word2v ec performs model updates (and potentially the inter-thread communication that comes with it) after each dot product, our ne w parallelization scheme abo ve performs a number of dot products as a GEMM call (corre- sponding to multiple input words and multiple samples) before performing model updates. W e follow a simple “Hogwild”- style philosophy for multi-threading across the GEMM calls - we allow for threads to potentially conflict when updating the models at the end of the GEMM operation. It is important to note that the locality optimization has a secondary but important benefit - we cut down on the total number of updates to the model. This happens since the GEMM operation performs a reduction (in registers/local cache) to an update to a single entry in the output matrix; while in the original word2v ec scheme such updates to the same entry (same input word representation, for instance) happen at distinct periods of time with potential ping-pong traffic happening in between. As we will see in Sec. IV when we present results, this leads to a much better scaling of our approach than the original word2vec. Howe ver , we need to pay careful emphasis to the rate of con ver gence while doing these transformations. In contrast to the original word2vec that does small partial model updates frequently , our new GEMM based scheme batches many model updates together and performs less frequent updates. This can result in different multi-threading behavior . Specifi- cally , it is possible that threads read a more up-to-date model in the original w ord2vec as opposed to the GEMM based scheme. The extent to which this occurs is, of course, dependent on the batch size we use for the inputs. In our experiments, with a batch size of about 10-20, we have not found any significant impact on con ver gence. One reason for this is that many of the intermediate model updates in the original word2vec are to parts of the model that will be updated again in the very near future – for example, updates to the same input word due to multiple same input words occur close by in time. Even if relativ ely updated models are seen in the original word2vec, they are still not the final result and could be partially updated due to model update conflicts from multiple threads. D. Comparison to BIDMac h The word2v ec implementation in BIDMach [10] also uses the previously described idea of shared negati ve samples. Howe ver , the computation in BIDMach is organized in a different way . First, BIDMach separates the handling of the positiv e e xamples and neg ativ e samples into tw o steps. For handling positiv e examples, BIDMach iterates over each word and performs dot products of word v ectors considering that word as the target and surrounding words as input context. W e can think of these operations as a sequence of matrix v ector products, each time with a single target and corresponding input context words. There is some reuse of context words across matrix vector calls due to the ov erlap in context between successiv e target w ords. Howe ver , since computation is not batched into higher le v el BLAS calls, BIDMach cannot fully exploit this reuse through standard techniques such as register and cache blocking – register and cache state may not be maintained across loop iterations. In a similar w ay , BIDMach also processes negati ve samples as a sequence of dot products, and suffers from similar limitations. In contrast, we directly exploit reuse of input context words across the positive and negati ve samples using a GEMM call. The underlying opti- mized libraries can then exploit reuse across all levels of the register and cache hierarchy . W e demonstrate the performance impact of both designs when we present results in Sec. IV . E. Distributed Memory P arallelization Scalability on multi-node distrib uted system is as important as, if not more important than, that on single node system. This is because typical large scale machine learning applications are compute intensi ve and require days, weeks even months of training time. In the case of word2vec, even with the techniques we proposed abov e, it still takes tens of hours or ev en days to train on some of the largest data sets in the industry , such as the 100 billion word news articles from Google. Thus, scaling out word2vec on multi-node distributed system is critical in practice. T o scale out word2vec, we e xplore different techniques to distribute its computation across nodes in a compute cluster . Since the indi vidual matrix multiplies are not very lar ge, there is not too much performance that can be gained from distribut- ing these across multiple nodes (a.k.a. model parallelism). Therefore, data parallelism is considered for distributed im- plementation. In data parallelism with N computing nodes, the training corpus is equally partitioned into N shards and the model parameters Ω = { M in , M out } are replicated on each computing node; each node then independently processes the data partition it o wns and updates its local model, and periodically synchronizes the local model with all the other N − 1 nodes. There are two common issues to be addressed in data parallelism: (1) ef ficient model synchronization ov er the com- munication network, and (2) improving the statistical effi- ciency of lar ge mini-batch SGD. The first issue arises because typical network bandwidths are an order of magnitude lo wer than CPU memory bandwidths. For e xample, in commonality cloud computing infrastructures such as A WS the network bandwidths are around 1GB/sec; even in HPC system with FDR infiniband, the network bandwidths are still of the order of 10GB/sec. As the typical size of the model Ω is about 2.5GB in our experiments, full model synchronization ov er 4 computing nodes connected via FDR Infiniband takes about 0.5 seconds, which is too slow to keep up with local model updates. In the case of word2v ec, ho we ver , not all word v ectors are updated at the same frequency as those are proportional to the word unigram frequencies, e.g., the v ectors in the model associated with popular words are updated more frequently than those of rare words. W e therefore strive to match model update frequency to word frequency , and a sub-model (instead of full-model) synchronization scheme, similar to the one exploited in BIDMach [10], is used. The second issue arises because as the number of nodes N increases, conceptually a N times larger mini-batch is used in SGD update, which af fects the statistical ef ficiency and slows down the rate of con ver gence. Fortunately , this issue has been studied recently and v arious techniques are proposed to mitigate the loss of con ver gence rate. W e follow the m -weighted sample scheme studied in Splash [16] and increase the starting learning rate as the number of nodes increases while exploring different learning rate scheduling techniques, such as AdaGrad [11] and RMSProp [12], to improv e con vergence rate. From our experiments, we found that while AdaGrad and RMSProp are ef fecti ve techniques to speed up con vergence, they incur large memory consumption since the y dedicate a learning rate to each model parameter and need a separate matrices of the same size as Ω to store the per- parameter learning rates. In addition, accessing lar ge memory arrays mak es the algorithm memory-bandwidth intensi ve and slows down the throughput considerably . Instead, we found that a simple learning rate update schedule based on a single learning rate is quite satisfactory , and empirically we note that we just need to reduce the learning rate more aggressiv ely as number of nodes increases. W e demonstrate the ef fectiv eness of these techniques in our experiments next. I V . E X P E R I M E N T S W e optimize word2vec with the techniques discussed above both in single node shared memory system and in multi-node distributed system. W e report the system-performance mea- sured as throughput, i.e., million words/sec, and the pr edictive- performance measured as accurac y on standard w ord similarity and word analogy test sets. The performances of our optimiza- tion are compared with the original word2vec on CPUs, and with the state-of-the-art results reported in literature on Nvidia GPUs. Our code will be made a vailable for general usage. A. Experimental Setup Hardwar e : The majority of our e xperiments are performed on two Intel architectures for shared memory and distributed memory computation: (1) dual-socket Intel Xeon E5-2697 v4 Broadwell CPUs, and (2) the latest Intel Xeon Phi Knights Landing (KNL) processors. The Broadwell proces- sor has 36 cores (72 threads including Simultaneous Multi- Threading/SMT) running at 2.3 GHz, and the KNL processor has 68 cores and each core has 4 hardware threads (or 272 threads in total) running at 1.4 GHz. Each machine has 128 GB RAM and runs Red Hat Enterprise Linux Server release 6.5. In the distributed setting, all the Broadwell nodes are connected through FDR infiniband, and all the KNL nodes are connected through Intel Omni-P ath (OP A) Fabric. Software : W e use custom end-to-end code written in C++ with OpenMP , and compiled with the Intel C++ Compiler version 16.0.2. W e use Intel MKL version 11.3.2 and Intel MPI library version 5.1.3 for SGEMM calls and multi-node massage passing. T raining corpora : W e train our word2vec models on three different corpora: (1) a small (text8) dataset 2 of 17 million words from wikipedia that is widely used for word embedding demos, (2) the recently released One Billion W ords bench- mark [13], and (3) a large collection of 7.2 billion words that we gathered from a variety of data sources: the 2015 W ikipedia dump with 1.6 billion words, the WMT14 Ne ws Crawl 3 with 1.7 billion words, the aforementioned one billion word benchmark, and UMBC webbase corpus 4 with around 3 billion words. Different corpora are used in order to verify the generalization performance of our algorithm under dif ferent training data statistics. The one billion word benchmark [13] is our main dataset for throughput and predictive accuracy study since this is the benchmark on which the best known GPU performances were reported. 2 http://mattmahoney .net/dc/text8.zip 3 http://www .statmt.org/wmt14/translation- task.html 4 http://ebiquity .umbc.edu/resource/html/id/351 T est sets : The quality of trained models are ev aluated on wor d similarity and word analogy tasks. F or word similarity , we use WS-353 [17] which is one of the most popular test datasets used for this purpose. It contains word pairs together with human-assigned similarity judgments. The word representations are ev aluated by ranking the pairs according to their cosine similarities, and measuring the Spearmans rank correlation coefficient with the human judgments. For word analogy , we use the Google analogy dataset [15], which contains 19544 word analogy questions, partitioned into 8869 semantic and 10675 syntactic questions. The semantic ques- tions contain fi ve types of semantic analogies, such as capital cities (Paris:France;T ok yo:?), currency (USA:dollar;India:?) or people (king:queen;man:?). The syntactic questions contain nine types of analogies, such as plural nouns, opposite, or comparativ e, for example good:better;smart:?. A question is correctly answered only if the algorithm selects the word that is exactly the same as the correct word in the question. Code : W e compare the performances of three different implementations of word2v ec: (1) the original implementation from Google that is based on Hogwild SGD on shared mem- ory systems (https://code.google.com/archiv e/p/word2v ec/), (2) BIDMach (https://github .com/BIDData/BIDMach) which achiev es the best known performance of word2vec on Nvida GPUs, and (3) our optimized implementation on Intel archi- tectures. W ord2vec parameters : In the experiments on the one billion word benchmark, we follow the parameter settings of BIDMatch (dim=300, negati ve samples=5, window=5, sample=1e-4, vocab ulary of 1,115,011 words). In this case, the size of the model Ω = { M in , M out } is about 2.5GB. Similar parameter settings are used for the small text8 dataset and the 7.2 billion w ord collection discussed abov e. B. Single Node Shar ed Memory Systems T o achiev e high performance on modern multi-socket multi- core shared memory systems, parallel algorithms need to have strong scalability across cores and sockets. Scaling across cores is challenging for word2vec because more threads cre- ates more inter-core traf fic due to cache line conflicts (in- cluding false sharing), which prev ents it from achie ving good scalability . Scaling across sockets is e ven more challenging since the same traf fic caused by cache line conflicts and false sharing needs to trav el across sockets. The high inter-socket communication overhead imposes a major hurdle to achieve good scalability across sockets. System-Perf ormance (Throughput) : Fig. 3 shows the system-performance measured as million words/sec of our algorithm and the original word2vec, scaling across all cores/threads and sockets of a 36-core dual-socket Intel Broad- well CPU. W e use the one billion word benchmark [13] in the e xperiment. When using only one thread, our optimiza- tion achiev es 2.6X speedup over the original word2vec. The superior performance of our optimization is due to the new parallelization scheme which is more hardware-friendly after con verting lev el-1 BLAS dot-products to le vel-3 BLAS matrix multiplies as described in Sec. III. 1 2 4 8 18 36 72 0 1 2 3 4 5 6 Number of Threads (from a single BDW node) (Million) Words/Sec Original Our Fig. 3: Scalabilities of the original word2vec and our opti- mization on all threads of an Intel Broadwell CPU; ev aluated on the one billion word benchmark [13]. When scaling to multiple threads, our algorithm achiev es linear speedup as sho wn in Fig. 3. This linear scalability is near perfect within a single socket (when number of threads ≤ 36 ), and the scalability becomes sub-linear when two sockets are in volv ed (when number of threads = 72) in which case cross- socket memory access penalizes the potential linear scaling. In contract, the original word2v ec scales linearly only until 8 threads and slo ws do wn significantly after that. In the end, the original word2v ec deliv ers about 1.6 million w ords/sec, while our code deli vers 5.8 million words/sec or a 3.6X speedup over the original word2v ec. The superior performance highlights the effecti veness of our optimization, as compared to the original word2v ec, in reducing unnecessary inter -thread communications and utilizing computation resource of modern multi-core architecture. Predicti ve-Perf ormance (Accuracy) : Deliv ering higher throughput is only meaningful when the trained model reaches similar or better predictiv e accuracy . W e therefore ev aluate the models trained from the original word2v ec and our im- plementation, and report their predictiv e performances on the word similarity and word analysis tasks in T able I. In order to verify the generalization performance of our techniques, we run the respecti ve codes on three dif ferent training corpora as described above. As can be seen from T able I, our code achieves very similar (most of time higher) predicti ve accuracy , compared to the original word2vec, cross three different corpora. It demonstrates that our optimization generalizes very well to different corpora that hav e a variety of sizes under different vocab ulary settings. T o examine the robustness of our word2vec further, we study its predicti ve accuracy under v arying data statistics. W e T ABLE I: Predictive performances of the models trained from the original word2vec and our optimization on three different training corpora. All the experiments are performed on an Intel Broadwell CPU. V ocabulary W ord Similarity W ord Analogy Corpus Size Original Our Original Our 17M-word (text8) 71,291 63.4 66.5 17.2 18.1 1B-word benchmark 1,115,011 64.0 64.1 32.4 32.1 7.2B-word collection 1,115,011 70.0 69.8 73.5 74.0 T ABLE II: Predicti ve performances of trained models on one billion word benchmark with vocab ularies of dif ferent sizes. V ocabulary W ord Similarity W ord Analogy Size Original Our Original Our 1,115,011 64.2 64.1 32.4 32.1 500,000 63.0 62.4 32.2 33.0 250,000 63.1 61.8 32.2 33.0 100,000 55.6 55.8 32.2 31.9 50,000 49.7 49.7 30.1 29.9 again run the original word2vec and our optimization on the one billion word benchmark but with vocabularies of dif ferent sizes. For the v ocabulary of size N , we keep the top N most popular words occurred in the corpus in the vocabulary . These popular w ords ha ve the most of occurrences in the training corpus, and therefore their updates (and also the conflicts in the “Hogwild”-style SGD) are more frequent than those on rare words. It can been seen from T able II that both the original word2vec and our optimization achie ve very similar accuracies for all vocabulary sizes, including the most challenging one with a small vocab ulary of 50K words. Overall, these experiments demonstrate that the paralliza- tion scheme and the optimization techniques we proposed in Sec. III deliv ers 3X-4X speedup ov er the original word2vec without loss of predicti ve accuracy . Comparison to state-of-the-arts : After demonstrating the superior performances of our optimization, we now perform detailed comparison to the state-of-the-arts, including the original word2vec from Google and BIDMach. Since all the implementations achie ve similar accuracy , we focus on the throughput in the comparison. Improving throughput (while maintaining accuracy) is always important since it democ- ratizes the large word2v ec models by lowering the training costs. Thus, extensi ve studies ha ve been focused on improving throughput. The best known performance reported currently in the literature is from BIDMach on the one billion word benchmark using Nvidia GPUs [10]. W e therefore run our experiments on the same benchmark using the same param- eter setting as that of BIDMach. Moreov er , to ev aluate the generalization of our techniques, we also run our experiments on three different Intel architectures including the latest Intel Xeon Phi Knight Landing processor . T able III sho ws the detailed comparisons. On Intel Haswell and Broadwell architectures, BIDMach and our optimization outperform the original word2vec: typically BIDMach delivers T ABLE III: Performance comparison of the state-of-the-art implementations of word2vec on different architectures, in- cluding dual-socket 28-core Intel Haswell E5-2680 v3, dual- socket 36-core Intel Broadwell E5-2697 v4, single-socket 68- core Intel Knights Landing, Nvidia K40 GPU, and Nvidia GeForce T itan-X GPU. Results on CPU-platforms are obtained from our e xperiments, while results on the GPU systems are obtained from published literature [10]. Results are ev aluated on the one billion word benchmark [13]. Processor Code W ords/Sec Intel HSW (Xeon E5-2680 v3) Original 1.5M Intel HSW (Xeon E5-2680 v3) BIDMach 2.4M Intel HSW (Xeon E5-2680 v3) Our 4.2M Intel BD W (Xeon E5-2697 v4) Original 1.6M Intel BD W (Xeon E5-2697 v4) BIDMach 2.5M Nvdia K40 BIDMach 4.2M 1 Intel BD W (Xeon E5-2697 v4) Our 5.8M Nvdia GeForce T itan-X BIDMach 8.5M 1 Intel KNL (Xeon Phi) Our 8.9M 1 Data from [10]. 1.6X speedup over the original w ord2vec while our optimiza- tion deli vers 2.8X-3.6X speedup. In addition, our performance on Intel Broadwell (5.8 million w ords/sec) outperforms BID- Mach’ s performance on Nvidia K40 (4.2 million words/sec). The best kno wn performance on shared memory system was reported by BIDMach [10] on Nvidia GeForce T itan-X (8.5 million words/sec) which is 1.5X faster than our performance on Intel Broadwell. Ho we ver , in terms of compute ef ficiency , BIDMach on Nvidia T itan-X is much lo wer than our code on Intel Broadwell since the former has 3X peak flops of the latter , indicating that BIDMach’ s efficienc y on Nvidia Titan- X is only half of ours on Intel Broadwell. This is likely due to the parallelization scheme of BIDMach, which cannot efficiently use all computational resources, as we discussed in Sec. III-D. Finally , our optimization on Intel KNL processor deliv ers 8.9 million words/sec, a ne w record on the one billion word benchmark achie ved on a single node shared memory system. C. Distributed Multi-node Systems Next we demonstrate the scalability and predictiv e perfor- mance of our distributed w ord2vec on multi-node distributed systems. The experiments with our distributed word2vec are performed on two CPU clusters: (1) Intel Broadwell nodes connected via FDR Infiniband, and (2) Intel KNL nodes con- nected via Intel OP A Fabric. Fig. 4 sho ws the scalability of our distributed word2v ec on both distrib uted systems as number of nodes increases, while T able IV reports the corresponding pre- dictiv e performances on the word similarity and word analogy benchmarks. F or the purpose of comparison, we also include in Fig. 4 BIDMach’ s performances on N = 1 , 4 NV idia T itan- X GPUs provided by [10], which reports the state-of-the-art performance achieved on multi-GPU systems. Again, good scalability is only meaningful when similar or better accurac y is achie ved. W e therefore provide the predicti v e performance of the original word2v ec as the baseline in T able IV . 1 2 4 8 16 32 0 20 40 60 80 100 120 140 160 Number of Nodes (Million) Words/Sec Our distributed w2v on Intel BDW Our distributed w2v on Intel KNL BIDMach on NVidia Titan−X Fig. 4: Scalabilities of our distributed word2vec on multiple Intel Broadwell and Knight Landing nodes, and BIDMach on N = 1 , 4 NV idia T itan-X nodes as reported in [10]. . T ABLE IV: Predicti ve performances of our distributed word2vec trained on the one billion word benchmark [13] ev aluated on the word similarity and word analogy tasks. The performance of the original word2v ec is provided as baseline. #Nodes W ord Similarity W ord Analogy Original ( N = 1 ) 64.0 32.4 Distributed w2v BDW KNL BDW KNL N = 1 64.1 63.7 32.1 32.1 N = 2 64.1 65.2 32.3 32.5 N = 4 63.0 63.4 32.0 32.2 N = 8 63.8 64.9 32.1 31.3 N = 16 62.8 62.3 31.6 31.0 N = 32 63.2 61.2 31.1 30.1 As can been seen from Fig. 4 and T able IV , our distrib uted word2vec achiev es near linear scaling until 16 Broadwell nodes or 8 KNL nodes while maintaining a comparable accu- racy to that of the original word2vec. As the number of nodes increases, to achiev e the linear scaling while maintaining a comparable accuracy , we need to increase the learning rate and the model synchronization frequency slightly to mitigate the loss of con vergence rate. When number of Broadwell nodes increases to 32 (or KNL for 16), we need to further increase model synchronization frequency to maintain a good predicti ve accuracy . Ho we ver , the increment of model synchronization frequency takes a toll on the scalability , and leads to a sub- linear scaling at 32 Broadwell nodes or 16 KNL nodes. Despite of this, our distributed word2vec deliv ers ov er 100 million words/sec with a small 1% accurac y loss. T o the best of our knowledge, this is the best performance reported so far on this benchmark. As a comparison, BIDMach only deli v ers 2.4X speedup on 4 GPU cards vs. 1 GPU card or a 60% ef ficiency . T ABLE V: Performance comparison of state-of-the-art dis- tributed word2vec trained on the one billion word bench- mark [13] with multi-node CPU and GPU systems Systems Node Count Code W ords/Sec Nvidia T itan-X GPU 4 nodes BIDMach 20M 1 Intel Broadwell CPU 4 nodes Our 20M Intel Knights Landing 4 nodes Our 29.4M Intel Broadwell CPU 32 nodes Our 110M Intel Knights Landing 16 nodes Our 94.7M 1 Data from [10]. Last, we collect the best kno wn performance of distributed word2vec from the literature [10], and compare it with our performance on Intel Broadwell and KNL nodes and report them in T able V . W e only consider the meaningful throughputs that maintain a comparable accuracy . Therefore, only the performances of 32 Broadwell nodes and 16 KNL nodes are included. As can be seen, our 4 Broadwell nodes matches BIDMach’ s performance on 4 Nvidia T itan-X cards, and we deliv er about 110 million words/sec on a cluster of 32 Intel Broadwell nodes, the best performance reported so far on this benchmark. W ith 16 Intel KNL nodes, we deliver close to 100 million words/sec meaningful throughput. V . C O N C L U S I O N A high performance parallel word2vec algorithm in shared and distributed memory systems is proposed. It combines the idea of Hogwild, minibatching and shared negati ve sam- pling to con vert the lev el-1 BLAS vector -vector operations to the lev el-3 BLAS matrix multiply operations. As a re- sult, the proposed algorithm is more hardware-friendly and can efficiently leverage the vector units and multiply-add instruction of modern multi-core and many-core architectures. W e also explore different techniques, such as sub-model synchronization and learning rate scheduling, to parallelize the word2vec computation across multiple computing nodes. These techniques dramatically reduce network communication and keep the model synchronized ef fectiv ely when number of nodes increases. W e demonstrate the throughput and predicti ve accuracy of our algorithm comparing to the state-of-the-arts implementations, such the original word2vec and BIDMach, on both single node shared memory systems and multi-node distributed systems. W e achie ve near linear scalability across cores and nodes, and process hundreds of mullions of words per second, the best performance reported so far on the one billion word benchmark. As for future work, our plans include asynchronous model update similar to parameter se ver [18], more efficient sub- model synchronization strategy as well as improving the rate of conv ergence of the distributed word2vec implementation. R E F E R E N C E S [1] C. D. Manning and H. Sch ¨ utze, F oundations of Statistical Natur al Language Pr ocessing . Cambridge, MA, USA: MIT Press, 1999. [2] R. Collobert and J. W eston, “ A unified architecture for natural language processing: deep neural networks with multitask learning, ” in Pr oceed- ings of the 25th international conference on Machine learning , 2008, pp. 160–167. [3] X. Glorot, A. Bordes, and Y . Bengio, “ A unified architecture for natural language processing: deep neural networks with multitask learning, ” in Pr oceedings of the 25th international conference on Machine learning , 2011, pp. 513–520. [4] P . D. Turne y , “Distrib utional semantics beyond words: Supervised learn- ing of analogy and paraphrase, ” in T ransactions of the Association for Computational Linguistics (T ACL) , 2013, pp. 353–366. [5] T . Mikolov , I. Sutskever , K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their composi- tionality , ” i n Advances in Neur al Information Pr ocessing Systems 26 , 2013, pp. 3111–3119. [6] K. Cho, B. v an Merrienboer , C. Gulcehre, D. Bahdanau, F . Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using rnn encoder-decoder for statistical machine translation, ” in Pr oceedings of the 2002 Confer ence on Empirical Methods in Natural Language Pr ocessing (EMNLP) , 2014. [7] J. W eston, S. Chopra, and A. Bordes, “Memory networks, ” in Interna- tional Confer ence on Learning Repr esentations (ICLR) , 2015. [8] L. S. Blackford, J. Demmel, J. Dongarra, I. Duff, S. Hammarling, G. Henry , M. Heroux, L. Kaufman, A. Lumsdaine, A. Petitet, R. Pozo, K. Remington, and R. C. Whaley , “ An updated set of basic linear algebra subprograms (blas), ” ACM T rans. Mathematical Softwar e , vol. 28, no. 2, pp. 135–151, 2002. [9] F . Niu, B. Recht, C. Re, and S. J. Wright, “Hogwild: A lock-free approach to parallelizing stochastic gradient descent, ” in Advances in Neural Information Pr ocessing Systems , 2011, pp. 693–701. [10] J. Canny , H. Zhao, Y . Chen, B. Jaros, and J. Mao, “Machine learning at the limit, ” in IEEE International Conference on Big Data , 2015. [11] J. Duchi, E. Hazan, and Y . Singer , “ Adapti ve subgradient methods for online learning and stochastic optimization, ” Journal of Machine Learning Resear ch , vol. 12, pp. 2121–2159, 2011. [12] G. Hinton, “Lecture 6.5-rmsprop: Divide the gradient by a running av erage of its recent magnitude, ” 2012, cOURSERA: Neural Networks for Machine Learning. [13] C. Chelba, T . Mikolov , M. Schuster , Q. Ge, T . Brants, P . K oehn, and T . Robinson, “One billion word benchmark for measuring progress in statistical language modeling, ” in INTERSPEECH , 2014, pp. 2635–2639. [14] G. A. Miller and W . G. Charles, “Contextual correlates of semantic similarity , ” in Language and cognitive pr ocesses , 1991. [15] T . Mikolo v , K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space, ” Pr oceedings of W orkshop at ICLR , 2013. [16] Y . Zhang and M. I. Jordan, “Splash: User-friendly programming interface for parallelizing stochastic algorithms, ” arXiv pr eprint arXiv:1506.07552 , 2015. [17] L. Finkelstein, E. Gabrilovich, Y . Matias, E. Ri vlin, Z. Solan, G. W olf- man, and E. Ruppin, “Placing search in context: The concept revisited, ” ACM T ransactions on Information Systems , vol. 20, pp. 116–131, 2002. [18] M. Li, D. Andersen, A. Smola, J. Park, A. Ahmed, V . Josifovski, J. Long, E. Shekita, and B.-Y . Su, “Scaling distributed machine learning with the parameter server , ” in Operating Systems Design and Implementation (OSDI) , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment