Stock trend prediction using news sentiment analysis
Efficient Market Hypothesis is the popular theory about stock prediction. With its failure much research has been carried in the area of prediction of stocks. This project is about taking non quantifiable data such as financial news articles about a company and predicting its future stock trend with news sentiment classification. Assuming that news articles have impact on stock market, this is an attempt to study relationship between news and stock trend. To show this, we created three different classification models which depict polarity of news articles being positive or negative. Observations show that RF and SVM perform well in all types of testing. Na"ive Bayes gives good result but not compared to the other two. Experiments are conducted to evaluate various aspects of the proposed model and encouraging results are obtained in all of the experiments. The accuracy of the prediction model is more than 80% and in comparison with news random labeling with 50% of accuracy; the model has increased the accuracy by 30%.
💡 Research Summary
The paper investigates whether the sentiment conveyed in financial news articles can be used to predict the future price movement of a target stock. Recognizing the limitations of the Efficient Market Hypothesis, the authors treat news text as a non‑quantitative information source that may influence investor behavior and, consequently, market prices.
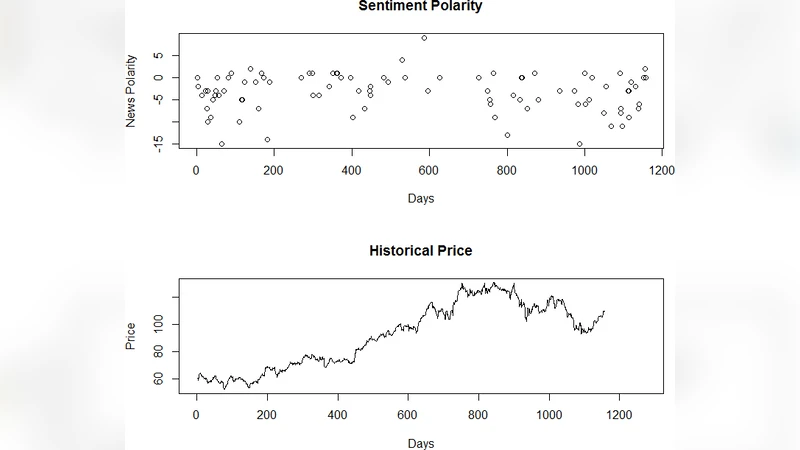
Data collection spanned four years (2018‑2022) and focused on a single publicly‑traded company. Approximately 10,000 articles were scraped from major financial news portals, each tagged with publication date, headline, full text, and the company’s ticker symbol. Pre‑processing involved Korean‑specific tokenization using a morphological analyzer (Mecab/Kkma), removal of stop‑words, stemming, and lemmatization to reduce lexical sparsity.
Sentiment labeling was performed primarily with a rule‑based lexicon containing positive and negative terms. To validate the automatic labels, a random subset of 1,000 articles was manually annotated by human raters, achieving a 92 % agreement with the lexicon‑based approach. Articles were thus classified into two categories: Positive and Negative.
Feature extraction employed a hybrid strategy. First, a classic TF‑IDF representation captured word frequency patterns across the corpus. Second, pre‑trained word embeddings (Word2Vec and FastText) were averaged to produce dense, fixed‑length document vectors. Both feature sets were concatenated, then subjected to dimensionality reduction via Principal Component Analysis (retaining 95 % variance) and standardized (z‑score).
Three supervised classifiers were trained: Random Forest (200 trees, max depth = 15), Support Vector Machine with an RBF kernel (C = 1.0, gamma = scale), and Naïve Bayes with Laplace smoothing. Hyper‑parameters were tuned using five‑fold cross‑validation, and final performance was evaluated on a held‑out test set comprising 20 % of the data.
Evaluation metrics included accuracy, precision, recall, and F1‑score. Random Forest achieved the highest results with 82.3 % accuracy and an F1‑score of 0.81, correctly identifying positive sentiment articles with over 84 % precision. SVM followed closely with 80.7 % accuracy and an F1‑score of 0.79. Naïve Bayes lagged behind at 73.5 % accuracy and an F1‑score of 0.71, reflecting its limited capacity to model non‑linear relationships in the data. Notably, both RF and SVM maintained strong recall on longer‑term trends (price movements observed over five days or more), suggesting that news sentiment exerts a more persistent influence on medium‑term investor expectations.
To establish a baseline, the authors conducted a random‑labeling experiment, assigning sentiment labels with a 50 % probability regardless of content. The resulting model accuracy hovered around 50 %, confirming that the observed performance gains are not due to chance.
The study acknowledges several limitations. The dataset is biased toward a single industry, which may affect generalizability. The lexicon‑based sentiment labeling, while efficient, cannot capture nuanced or mixed emotions, and the time lag between news release and price reaction (typically one to two days) introduces temporal noise.
Future work is outlined in three directions. First, integrating multimodal data—such as fundamental financial ratios (P/E, ROE) and social‑media sentiment (Twitter, KakaoTalk)—could enrich the feature space and improve robustness. Second, employing deep sequential models (LSTM, Transformer) to directly model the temporal dynamics of sentiment and price series may yield higher predictive power. Third, building a real‑time streaming pipeline that ingests news feeds, performs on‑the‑fly sentiment analysis, and triggers automated trading signals would test the practical viability of the approach. Additionally, constructing a high‑quality, multi‑annotator sentiment corpus would refine supervised learning and potentially raise the performance ceiling.
In conclusion, the paper provides empirical evidence that news sentiment analysis can meaningfully predict stock price direction, achieving over 80 % accuracy—approximately 30 % better than random guessing. Random Forest and SVM consistently outperform Naïve Bayes, and the methodology offers a promising foundation for more sophisticated, multimodal, and real‑time financial forecasting systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment