Calibrated Fair Measures of Measure: Indices to Quantify an Individuals Scientific Research Output
Are existing ways of measuring scientific quality reflecting disadvantages of not being part of giant collaborations? How could possible discrimination be avoided? We propose indices defined for each discipline (subfield) and which count the plausible contributions added up by collaborators maintaining the spirit of interdependency. Based on the growing debate about defining potential biases and detecting unethical behavior, a standardized method to measure contributions of the astronomical number of coauthors is introduced.
💡 Research Summary
The paper addresses a long‑standing concern in scientometrics: the distortion of individual performance metrics caused by participation in very large research collaborations. Traditional indicators such as total number of publications, citations per paper, and the Hirsch h‑index treat every author on a multi‑thousand‑person paper as if they contributed equally. As a result, scientists who belong to collaborations like the CMS, ATLAS, or ALICE experiments at the Large Hadron Collider accrue dramatically higher metric values than researchers who work in smaller groups or independently, even when the actual personal contribution is modest.
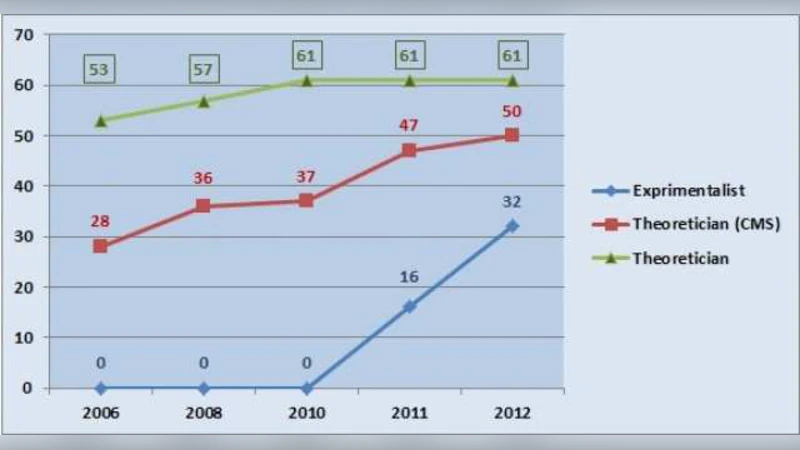
To illustrate the problem, the author examines three physicists over a five‑year period: an experimentalist who joined CMS in 2011, a theorist who has been a CMS member since 2008, and a non‑collaborating theorist. The CMS members show a steep rise in papers (from a few to hundreds), citations (from a few hundred to over ten thousand), and h‑index (reaching the 30‑40 range), whereas the independent theorist’s metrics increase only modestly. The author interprets this disparity as “unfair discrimination” against scientists outside giant collaborations.
The proposed solution consists of two complementary calibrations. First, a discipline‑specific normalization is introduced. For each subfield (identified by PACS numbers or an equivalent classification), the minimum and maximum values of the chosen metric (papers per year, citations per paper, or h‑index) are periodically determined from a comprehensive database (e.g., INSPIRE‑HEP). These extrema define a 0‑100 scale, allowing a fair comparison of researchers within the same subfield regardless of overall citation culture.
Second, a collaboration‑size correction factor is applied. Let N be the total number of members of a collaboration and n the number of individuals who actually contributed to a given paper. The correction factor
C = 1 – (N – n)/N
is multiplied by the raw metric to obtain a “calibrated measure.” When all authors truly contribute (N = n) the factor equals 1, leaving the metric unchanged; when only a small subset contributes, C approaches zero, dramatically reducing the inflated score. The author acknowledges that n is not directly observable in most publications, but suggests that author‑lists longer than ten names could be truncated with “et al.” and that internal collaboration records could be used to estimate effective contributor counts.
The paper also discusses the social‑scientific notion of interdependence: in a truly interdependent team every member’s work relies on the others, justifying equal weighting; in large, loosely coupled collaborations this condition fails, supporting the need for differential weighting. The author critiques the unrealistic expectation that any individual could produce the hundreds of papers per year that large collaborations generate, emphasizing that the time required for problem formulation, literature review, analysis, writing, and peer review cannot be compressed arbitrarily.
Finally, the author argues that the calibrated indices would be valuable for hiring committees, funding agencies, and institutional rankings, because they would reflect both the scientific impact and the genuine personal contribution of researchers. The framework is presented as extensible to other disciplines, provided that each field adopts a comparable hierarchical classification system and maintains up‑to‑date statistical baselines. In summary, the paper offers a quantitative critique of existing bibliometric practices in the era of mega‑collaborations and proposes a two‑step normalization and collaboration‑size correction that aims to restore fairness to individual scientific evaluation.
Comments & Academic Discussion
Loading comments...
Leave a Comment