Consider avoiding the .05 significance level
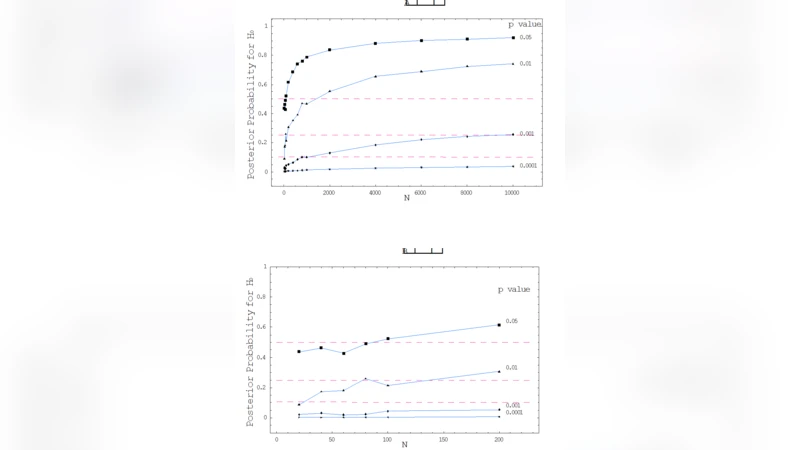
It is suggested that some shortcomings of Null Hypothesis Significance Testing (NHST), viewed from the perspective of Bayesian statistics, turn benign once the traditional threshold p value of .05 is substituted by a sufficiently smaller value. To illustrate, the posterior probability of H0 stating P=.5, given data that just render it rejected by NHST with a p value of .05 (and a uniform prior), is shown here to be not much smaller than .50 for most values of N below 100 (and even exceeds .50 for N>=100); in contrast, with a p value of .001 posterior probability does not exceed .06 for N<=100 (neither .25 for N<9000). Yet more interesting, posterior probability becomes quite independent of N with a p value of .0001, hence practically satisfying the alpha postulate - set by Cornfield (1966) as the condition for p value being a measure of evidence in itself. In view of the low prospect that most researchers will soon convert to use Bayesian statistics in any form, we thus suggest that researchers who elect the conservative option of resorting to NHST be encouraged to avoid as much as possible using a p value of .05 as a threshold for rejecting H0. The analysis presented here may be used to discuss afresh which level of threshold p value seems to be a reasonable, practical substitute.
💡 Research Summary
The paper “Consider avoiding the .05 significance level” revisits the long‑standing practice of using a p‑value threshold of 0.05 in Null Hypothesis Significance Testing (NHST) from a Bayesian perspective. The author argues that the conventional cutoff does not provide a sufficiently low posterior probability for the null hypothesis (H₀) and therefore fails to serve as a reliable measure of evidence. To demonstrate this claim, the analysis assumes a uniform prior (P(H₀)=0.5) and a normal sampling distribution for the test statistic. For each chosen significance level (α = 0.05, 0.001, 0.0001) the posterior probability of H₀ given data that just achieve statistical significance is derived analytically and illustrated across a range of sample sizes (N).
When α = 0.05, the posterior probability of H₀ remains close to 0.5 for most N < 100, and even exceeds 0.5 once N ≥ 100. In practical terms, a result that is “significant” at the 5 % level still leaves the researcher with essentially a coin‑flip chance that H₀ is true. By contrast, with α = 0.001 the posterior probability drops sharply: it stays below 0.06 for N ≤ 100 and does not exceed 0.25 until N approaches 9,000. This demonstrates that a stricter threshold dramatically reduces the chance that a “significant” finding is a false positive. The most striking result occurs at α = 0.0001, where the posterior probability of H₀ becomes almost independent of N and remains well below 0.01 across all examined sample sizes. This behavior satisfies Cornfield’s 1966 “α‑postulate,” which stipulates that a p‑value should itself be a measure of evidence, largely unaffected by sample size.
The author interprets these findings as evidence that the traditional 0.05 cutoff is insufficiently conservative, especially in modern research contexts where large samples are common. Because the Bayesian framework is still not widely adopted, the paper proposes a pragmatic compromise: retain NHST but replace the default α = 0.05 with a much smaller value (e.g., 0.001 or 0.0001). Such a change would preserve the familiar frequentist workflow while substantially improving the evidential quality of published results. The paper also discusses the practical implications for study design, emphasizing that researchers should anticipate the impact of sample size on the posterior probability and choose an α that yields a posterior probability low enough to be scientifically convincing.
In addition to the theoretical derivations, the author provides simulation results that confirm the analytical formulas, visualizing the relationship between α, N, and the posterior probability of H₀. The figures illustrate the non‑linear, sometimes counter‑intuitive, way in which larger N can actually increase the posterior probability under the 0.05 rule, highlighting the danger of relying on a fixed p‑value threshold without considering sample size.
The concluding recommendations are threefold: (1) avoid the default 0.05 significance level whenever possible; (2) adopt a more stringent α (preferably ≤ 0.001) to ensure that “significant” findings correspond to a low posterior probability of H₀; and (3) encourage the statistical community to educate researchers about the Bayesian interpretation of p‑values, even if they continue to use NHST in practice. The author suggests that future work should explore alternative priors, non‑normal data, and the effect of multiple testing to further validate the proposed thresholds.
Comments & Academic Discussion
Loading comments...
Leave a Comment