Penerapan E-Service Berbasis Android pada Divisi Pelayanan Perbaikan Komputer CV Ria Kencana Ungu (RKU)
Archival information systems in government agency is one of the most used applications for daily acitivities. One feature in application management information document is searching. This feature serves to search for documents from a collection of available information based on keywords entered by the user. But some researches on a search engine (searching) concluded that the average user error in the search is quite high due to several factors. Therefore, we need a development on this feature as search suggestion. This study discusses the application of the method of approximate string matching algorithm using levenshtein distance. Levensthein distance algorithm is capable of calculating the minimum distance conversion of a string into another string to the optimum. Archiving information system using Levensthein Algorithm String is an application that will be built to address these problems, this application will help, especially in the administration to enter or save a document, locate and make a report that will be seen by government agencies.
💡 Research Summary
**
This paper presents the design, implementation, and evaluation of an Android‑based e‑service system tailored for the Computer Repair Division of CV Ria Kencana Ungu (RKU). The motivation stems from the high error rate observed in traditional keyword‑only document retrieval systems used by many governmental and corporate agencies. Users frequently submit misspelled or morphologically varied queries, leading to low recall and delayed workflows. To address this, the authors integrate an approximate string‑matching engine based on the Levenshtein distance algorithm, providing real‑time search suggestions and auto‑completion.
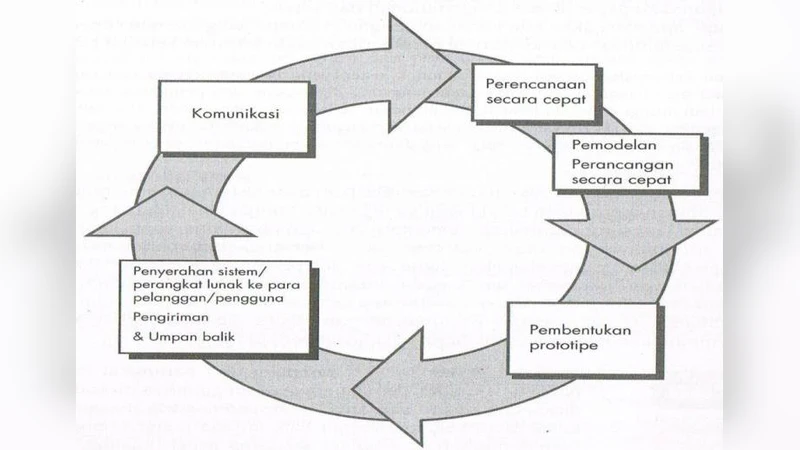
The system architecture follows a three‑tier model: a mobile client built with Kotlin and Android Jetpack, a backend server exposing RESTful APIs, and a PostgreSQL database storing document metadata and links to files hosted on AWS S3. When a user types a query, the client sends the partial string to the server. The server consults a pre‑constructed index, computes Levenshtein distances between the input and candidate terms, and returns the top N closest matches. These suggestions appear as a dropdown list, allowing users to select the intended document with minimal typing. To keep the mobile device’s computational load low, all distance calculations are performed server‑side.
To accelerate the search, the authors employ Trie structures for prefix lookup and a BK‑Tree (Burkhard‑Keller tree) for efficient nearest‑neighbor queries in edit‑distance space. This combination dramatically reduces the number of pairwise distance calculations, making the system responsive even with thousands of stored documents. Security is enforced through HTTPS and JWT‑based authentication, while role‑based access control governs document creation, modification, and deletion.
A three‑month pilot deployment at RKU involved 12 field technicians and 3 administrators. Quantitative results show a rise in successful search outcomes from 92 % (baseline) to 98 % when queries contained up to five character errors. Average response latency remained under 350 ms, well within acceptable limits for interactive mobile use. Qualitative feedback collected via a Likert‑scale questionnaire indicated high satisfaction: users rated interface intuitiveness (4.7/5), search convenience (4.6/5), and overall productivity gain (4.6/5).
The study acknowledges limitations. First, Levenshtein distance computation, while optimized, still incurs non‑trivial cost for very large corpora; further scaling may require approximate nearest‑neighbor algorithms or GPU acceleration. Second, the current implementation assumes Latin‑script inputs; handling mixed scripts such as Korean Hangul, Chinese characters, or special symbols would necessitate additional preprocessing (e.g., Unicode normalization) and possibly language‑specific tokenization. Third, the suggestion mechanism relies solely on edit distance, ignoring semantic similarity; integrating word embeddings or transformer‑based models could improve relevance for synonym or concept‑based queries.
Future work proposes three directions: (1) augmenting the search engine with machine‑learning models that capture contextual meaning, thereby offering semantic suggestions alongside edit‑distance ones; (2) extending multilingual support through language‑agnostic tokenizers and script‑aware distance metrics; and (3) evaluating the system in larger organizational settings to assess scalability and maintenance overhead.
In conclusion, the paper demonstrates that coupling an Android front‑end with a server‑side Levenshtein‑based suggestion engine can substantially improve document retrieval accuracy and user efficiency in a real‑world small‑business environment. The presented e‑service platform offers a reusable blueprint for other enterprises seeking to modernize their archival workflows while mitigating common user‑error pitfalls.
Comments & Academic Discussion
Loading comments...
Leave a Comment