Deep Feature Fusion Network for Answer Quality Prediction in Community Question Answering
Community Question Answering (cQA) forums have become a popular medium for soliciting direct answers to specific questions of users from experts or other experienced users on a given topic. However, for a given question, users sometimes have to sift through a large number of low-quality or irrelevant answers to find out the answer which satisfies their information need. To alleviate this, the problem of Answer Quality Prediction (AQP) aims to predict the quality of an answer posted in response to a forum question. Current AQP systems either learn models using - a) various hand-crafted features (HCF) or b) use deep learning (DL) techniques which automatically learn the required feature representations. In this paper, we propose a novel approach for AQP known as - “Deep Feature Fusion Network (DFFN)” which leverages the advantages of both hand-crafted features and deep learning based systems. Given a question-answer pair along with its metadata, DFFN independently - a) learns deep features using a Convolutional Neural Network (CNN) and b) computes hand-crafted features using various external resources and then combines them using a deep neural network trained to predict the final answer quality. DFFN achieves state-of-the-art performance on the standard SemEval-2015 and SemEval-2016 benchmark datasets and outperforms baseline approaches which individually employ either HCF or DL based techniques alone.
💡 Research Summary
The paper addresses the problem of Answer Quality Prediction (AQP) in community Question‑Answering (cQA) platforms, where users must often sift through many low‑quality or irrelevant answers to find the one that satisfies their information need. Existing AQP approaches fall into two broad categories: (a) hand‑crafted feature (HCF) methods that rely on extensive feature engineering and external resources, and (b) deep learning (DL) methods that automatically learn representations from large corpora but typically ignore external knowledge. While HCF methods are interpretable and can exploit domain‑specific cues, they require costly manual design; DL methods are data‑driven and language‑agnostic but may miss semantic signals that are not easily captured from raw text alone.
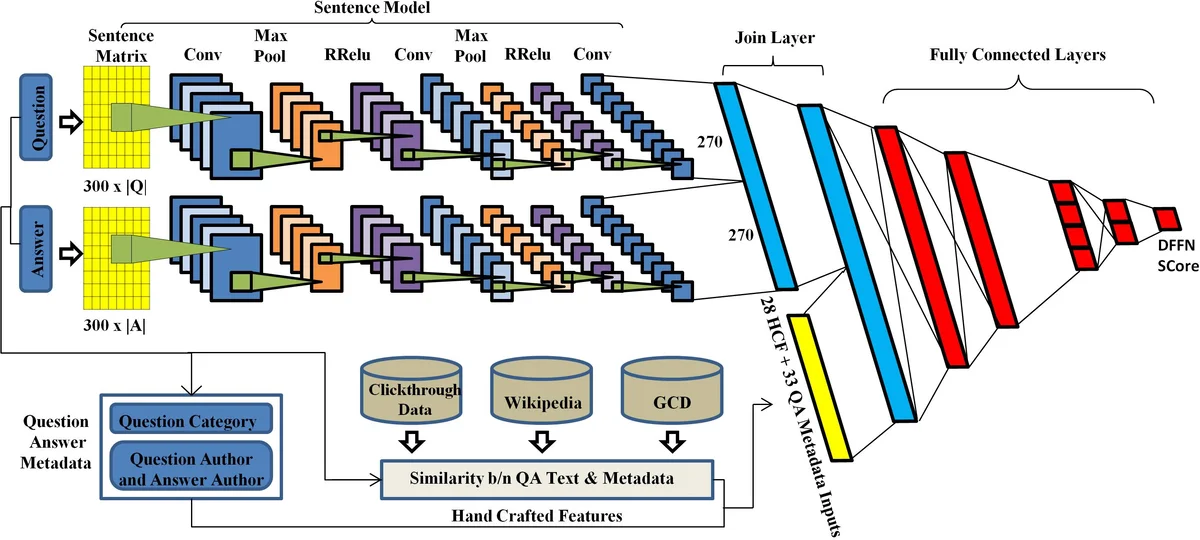
To combine the strengths of both paradigms, the authors propose the Deep Feature Fusion Network (DFFN). DFFN takes as input a question‑answer pair together with associated metadata (question category, author identifiers, etc.) and processes them through two parallel pipelines. The first pipeline is a Convolutional Neural Network (CNN) that maps each word to a 300‑dimensional GloVe embedding, applies 2‑D convolutions with multiple filter sizes, uses Randomized Leaky ReLU (RReLU) activations, and max‑pools the results. This yields a 270‑dimensional representation for the question and another 270‑dimensional representation for the answer; concatenating them produces a 540‑dimensional “deep feature” vector (CNNFR).
The second pipeline extracts a set of 28 hand‑crafted features (HCFR) that capture semantic similarity and contextual cues unavailable to the CNN alone. These features are grouped into three categories:
-
Wikipedia‑based features – TagMe is used to link substrings in the question and answer to Wikipedia page titles. Similarity between TagMe concepts is computed with Wikipedia Miner, which measures overlap of in‑links and out‑links. Google Cross‑Lingual Dictionary (GCD) is queried for common and proper nouns; the top ten concepts per text are retrieved and their similarity is also measured with Wikipedia Miner. Named Entity similarity is derived by counting co‑occurrences of entities in the top‑k GCD‑retrieved documents.
-
Sentence‑vector features – Paragraph2Vec is trained on the training data (good QA pairs only) to obtain dense vectors for arbitrary‑length texts; cosine similarity between question and answer vectors is used. Sent2Vec (both DSSM and CDSSM variants) is trained on click‑through data; cosine similarity between the resulting vectors provides additional semantic matching scores.
-
Metadata‑based features – Author reputation scores (good vs. bad), a Boolean flag indicating whether the answer author is the same as the question asker, patterns of the question author’s comments, statistical counts per question category, answer position, presence of URLs, email addresses, punctuation, and emoticons are all encoded as numeric or binary features.
These hand‑crafted vectors are concatenated with the deep CNN vector and fed into a second‑stage fully‑connected neural network. The final layer uses either a softmax (for the three‑class SemEval‑2015 task) or a sigmoid (for the binary SemEval‑2016 task) to output a quality score. Training minimizes cross‑entropy loss with dropout and L2 regularization to mitigate over‑fitting.
Experiments are conducted on the standard SemEval‑2015 (Task A, three classes: good, potentially useful, bad) and SemEval‑2016 (Task A, two classes: good, bad) datasets. Baselines include previously published HCF‑based SVM/Random Forest models and pure DL models such as CNN, LSTM, and CNN‑LSTM. DFFN achieves state‑of‑the‑art performance, improving mean average precision (MAP) from 0.78 (best baseline) to 0.84 on SemEval‑2015 and F1 from 0.84 to 0.89 on SemEval‑2016. Ablation studies show that using only the CNN features drops performance to 0.78 MAP, while using only hand‑crafted features yields 0.73 MAP, confirming that the two feature streams are complementary. Feature importance analysis indicates that GCD/TagMe similarity scores and author reputation contribute most to the final decision, highlighting the value of external knowledge and social signals.
The authors acknowledge several limitations. Dependence on external resources such as Wikipedia and GCD may hinder applicability to niche domains lacking rich knowledge bases (e.g., specialized medical forums). The CNN architecture is relatively shallow, potentially limiting its ability to capture long‑range dependencies or complex logical structures present in longer answers. Future work is suggested to replace or augment the CNN with Transformer‑based encoders, integrate knowledge‑graph embeddings, and develop domain‑adaptation techniques to improve generalization across diverse cQA platforms.
In summary, DFFN demonstrates that a principled fusion of deep learned representations and carefully engineered semantic and metadata features can substantially advance answer quality prediction, achieving superior results on benchmark datasets while retaining interpretability through its hand‑crafted component.
Comments & Academic Discussion
Loading comments...
Leave a Comment