Wide & Deep Learning for Recommender Systems
Generalized linear models with nonlinear feature transformations are widely used for large-scale regression and classification problems with sparse inputs. Memorization of feature interactions through a wide set of cross-product feature transformatio…
Authors: Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen
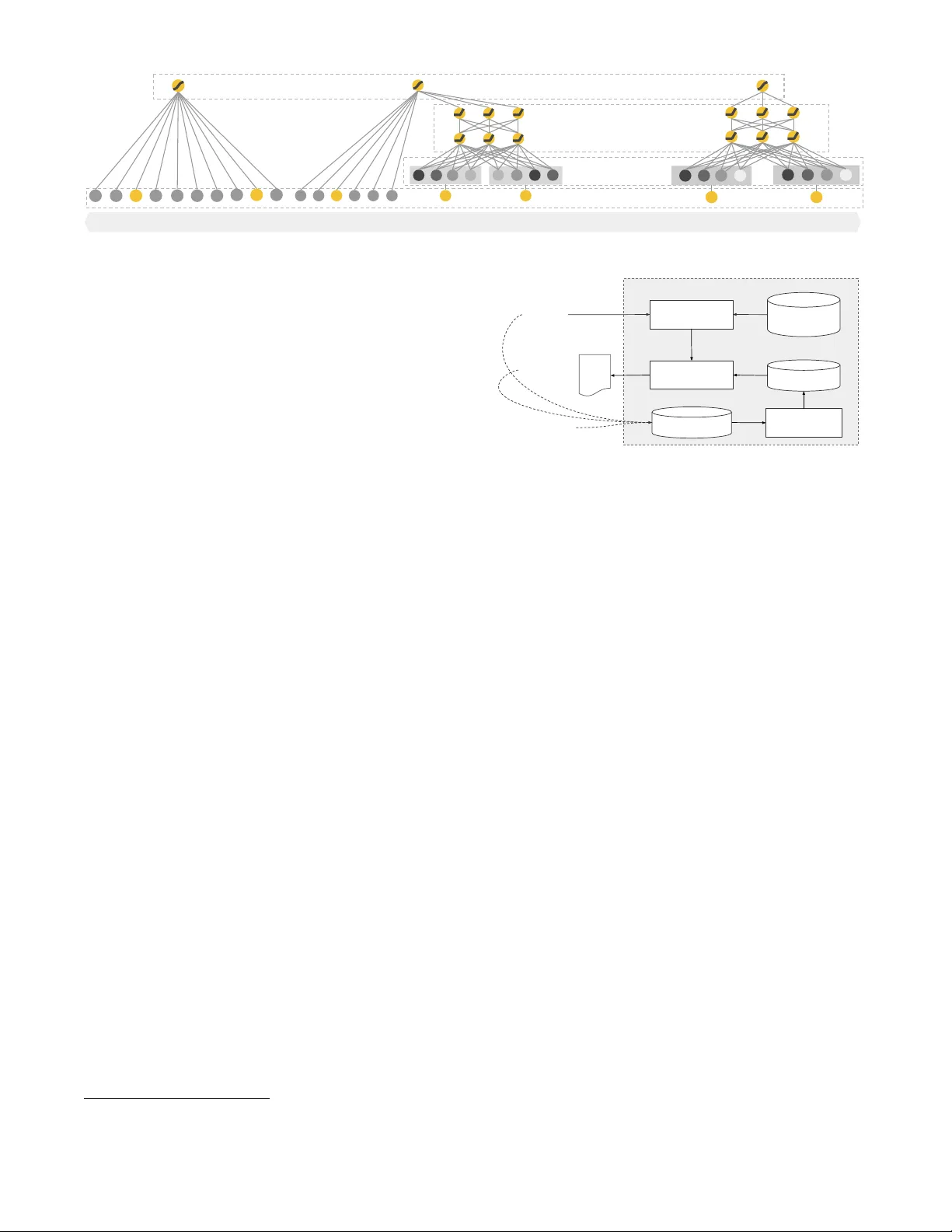
Wide & Deep Learning f or Recommender Systems Heng-Tze Cheng, Lev ent K oc, Jeremiah Har msen, T al Shaked, T ushar Chandra, Hrishi Aradh y e, Glen Anderson, Greg Corrado , Wei Chai, Mustafa Ispir , Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, Hemal Shah Google Inc. ∗ ABSTRA CT Generalized linear mo dels with nonlinear feature transfor- mations are widely used for large-scale regression and clas- sification problems with sparse inpu ts. Memorization of fea- ture in teractions through a wide set of cross-product feature transformations are effective and interpretable, while gener- alization requires more feature engineering effort. With less feature engineering, de ep neural net works can generalize bet- ter to unseen feature combinations through lo w-dimensional dense embeddings learned for the sparse features. Ho wev er, deep neural net w orks with em b eddings can ov er-generalize and recommend less relev ant items when t he user-item in ter- actions are sparse and high-rank. In this pap er, we present Wide & Deep learning—join tly trained wide linear mo dels and deep neural netw orks—to com bine the b enefits of mem- orization and generalization for recommender systems. W e productionized and ev aluated the system on Go ogle Play , a commercial mobile app store with o ver one billion activ e users and ov er one million apps. Online exp erimen t results sho w that Wide & Deep significan tly increased app acquisi- tions compared with wide-only and deep-only mo dels. W e ha ve also op en-sourced our implement ation in T ensorFlow. CCS Concepts • Computing metho dologies → Mac hine learning; Neu- r al networks; Sup ervise d le arning; • Information systems → R e c ommender systems; K eywords Wide & Deep Learning, Recommender Systems. 1. INTR ODUCTION A recommender system can b e view ed as a search ranking system, where the input query is a set of user and con textual information, and the output is a ranked list of items. Given a query , the recommendation task is to find the relev ant items in a database and then rank the items based on certain ob jectives, such as clic ks or purc hases. One c hallenge in recommender systems, similar to the gen- eral searc h ranking problem, is to ac hieve both memorization and gener alization . Memorization can be loosely defined as learning the frequent co-o ccurrence of items or features and exploiting the correlation av ailable in the historical data. Generalization, on the other hand, is based on transitivit y of correlation and explores new feature combinations that ∗ Corresponding author: hengtze@google.com ha ve never or rarely o ccurred in the past. Recommenda- tions based on memorization are usually more topical and directly relev ant to the items on which users ha ve already performed actions. Compared with memorization, general- ization tends to improv e the diversit y of the recommended items. In this pap er, we fo cus on the apps recommendation problem for the Go ogle Play store, but the approach should apply to generic recommender systems. F or massiv e-scale online recommendation and ranking sys- tems in an industrial setting, generalized linear mo dels such as logistic regression are widely used b ecause they are sim- ple, scalable and interpretable. The mo dels are often trained on binarized sparse features with one-hot encoding. E.g., the binary feature “ user _installed_app=netflix ” has v alue 1 if the user installed Netflix. Memorization can b e achiev ed effectiv ely using cross-product transformations ov er sparse features, such as AND ( user_installed_app=netfli x , imp res- sion_app=pandora ” ), whose v alue is 1 if the user installed Netflix and then is later shown Pandora. This explains how the co-occurrence of a feature pair correlates with the target label. Generalization can b e added by using features that are less granular, such as AND ( user_installed_catego ry=video , impression_category=music ), but manual feature engineer- ing is often required. One limitation of cross-pro duct trans- formations is that they do not generalize to query-item fea- ture pairs that hav e not appeared in the training data. Em b edding-based mo dels, suc h as factorization machines [5] or deep neural netw orks, can generalize to previously un- seen query-item feature pairs b y learning a low-dimensional dense embedding vector for each query and item feature, with less burden of feature engineering. How ever, it is dif- ficult to learn effectiv e lo w-dimensional representa tions for queries and items when the underlying query-item matrix is sparse and high-rank, such as users with sp ecific preferences or niche items with a narrow app eal. In such cases, there should be no interactions b et w een most query-item pairs, but dense embeddings will lead to nonzero prediction s for all query-item pairs, and th us can o ver-generalize and mak e less relev ant recommendations. On the other hand, linear mo d- els with cross-product feature transformations can memorize these “exception rules” with muc h fewer parameters. In this pap er, w e presen t the Wide & Deep learning frame- w ork to achiev e both memorizati on and generalization in one model, by jointly training a linear mo del comp onen t and a neural net w ork component as shown in Figure 1. The main contributions of the paper include: • The Wide & Deep learning framework for join tly train- ing feed-forward neural net works with em b eddings and Wide Models Deep Models Wide & Deep Models Hidden Layers Sparse Features Output Units Dense Embeddings Figure 1: The sp ectrum of Wide & Deep mo dels. linear mo del with feature transformations for generic recommender systems with sparse inputs. • The implemen tation and ev aluation of the Wide & Deep recommender system pro ductionized on Go ogle Pla y , a mobile app store with ov er one billion active users and ov er one million apps. • W e hav e open-sourced our implementation along with a high-lev el API in T ensorFlow 1 . While the idea is simple, we show that the Wide & Deep framew ork significantly improv es the app acquisition rate on the mobile app store, while satisfying the training and serving speed requirement s. 2. RECOMMENDER SYSTEM O VER VIEW An o verview of the app recommender system is shown in Figure 2. A query , whic h can include v arious user and con textual features, is generated when a user visits the app store. The recommender system returns a list of apps (also referred to as impressions) on whic h users can p erform cer- tain actions such as clicks or purchases. These user actions, along with the queries and impressions, are recorded in the logs as the training data for the learner. Since there are ov er a million apps in the database, it is in tractable to exhaustively score ev ery app for every query within the serving latency requirements (often O (10) mil- liseconds). Therefore, the first step up on receiving a query is r etrieval . The retriev al system retu rns a short list of items that b est match the query using v arious signals, usually a com bination of machine-learned mo dels and human-defined rules. After reducing the candidate po ol, the r anking sys- tem ranks all items by their scores. The scores are usually P ( y | x ), the probabilit y of a user action lab el y giv en the features x , including user features (e.g., coun try , language, demographics), contextual features (e.g., device, hour of the da y , day of the w eek), and impression features (e.g., app age, historical statistics of an app). In this pap er, w e focus on the ranking model using the Wide & Deep learning framework. 3. WIDE & DEEP LEARNING 3.1 The Wide Component The wide comp onent is a generalized linear mo del of the form y = w T x + b , as illustrated in Figure 1 (left). y is the prediction, x = [ x 1 , x 2 , ..., x d ] is a v ector of d features, w = [ w 1 , w 2 , ..., w d ] are the model parameters and b is the bias. The feature set includes raw input features and transformed 1 See Wide & Deep T utorial on http://tensorflow.org . Item 1 Item 2 Item 3 ... Database Query Items Learner Model Ranked O(10) items Logs User Actions Retrieval O(100) items Ranking Recommendation System All items Figure 2: Over view of the recommender system. features. One of the most important transformations is the cr oss-pr o duct tr ansformation , which is defined as: φ k ( x ) = d Y i =1 x c ki i c ki ∈ { 0 , 1 } (1) where c ki is a bo olean v ariable that is 1 if the i -th fea- ture is part of the k -th transformation φ k , and 0 otherwise. F or binary features, a cross-product transformation (e.g., “ AND ( gender=female , language=en )” ) is 1 if and only if the constituen t features ( “ gender=female ” and “ language=en ” ) are all 1, and 0 otherwise. This captures the interacti ons betw een the binary features, and adds nonlinearity to the generalized linear mo del. 3.2 The Deep Component The deep comp onent is a feed-forw ard neural net work, as sho wn in Figure 1 (right). F or categorical features, the orig- inal inputs are feature strings (e.g., “ language=en ” ). Eac h of these sparse, high-dimensional categorical features are first conv erted into a low-dimensional and dense real-v alued v ector, often referred to as an embedding vector. The di- mensionalit y of the embeddings are usually on the order of O (10) to O (100). The embedding v ectors are initialized ran- domly and then the v alues are trained to minimize the final loss function during model training. These low-di mensional dense embedding vectors are then fed into the hidden lay ers of a neural net w ork in the forw ard pass. Specifically , each hidden la y er performs the following computation: a ( l +1) = f ( W ( l ) a ( l ) + b ( l ) ) (2) where l is the lay er num b er and f is the activ ation function, often rectified linear units (ReLUs). a ( l ) , b ( l ) , and W ( l ) are the activ ations, bias, and mo del weigh ts at l -th lay er. 3.3 Joint T raining of Wide & Deep Model The wide component and deep comp onen t are combined using a w eighted sum of their output log o dds as the pre- User Data App Impression Data Training Data Generation Vocabulary Generator Model Trainer Model Verifier Model Servers Model Serving Apps Recommendation Engine Previous Models Data Generation Model Training Figure 3: Apps recommendation pip eline ov erview. diction, whic h is then fed to one common logistic loss func- tion for join t training. Note that there is a distinction b e- t ween joint tr aining and ensemble . In an ensem ble, indi- vidual mo dels are trained separately without knowing eac h other, and their predictions are com bined only at inference time but not at training time. In con trast, joint training optimizes all parameters simultaneously by taking both the wide and deep part as well as the w eigh ts of their sum in to accoun t at training time. There are implications on mo del size too: F or an ensemble, since the training is disjoin t, each individual model size usually needs to b e larger (e.g., with more features and transformations) to achiev e reasonable accuracy for an ensem ble to w ork. In comparison, for joint training the wide part only needs to complement the weak- nesses of the deep part with a small n um b er of cross-product feature transformations, rather than a full-size wide model. Join t training of a Wide & Deep Mo del is done b y back- propagating the gradients from the output to b oth the wide and deep part of the mo del sim ultaneously using mini-batch stochastic optimization. In the exp erimen ts, w e used F ollow- the-regularized-leader (FTRL) algorithm [3] with L 1 regu- larization as the optimizer for the wide part of the mo del, and AdaGrad [1] for the deep part. The combined model is illustrated in Figure 1 (cen ter). F or a logistic regression problem, the model’s prediction is: P ( Y = 1 | x ) = σ ( w T wide [ x , φ ( x )] + w T deep a ( l f ) + b ) (3) where Y is the binary class lab el, σ ( · ) is the sigmoid func- tion, φ ( x ) are the cross pro duct transformations of the orig- inal features x , and b is the bias term. w wide is the v ector of all wide mo del weigh ts, and w deep are the weigh ts applied on the final activ ations a ( l f ) . 4. SYSTEM IMPLEMENT A TION The implemen tation of the ap ps recommendation pipeline consists of three stages: data generation, model training, and model serving as shown in Figure 3. 4.1 Data Generation In this stage, user and app impression data within a p eriod of time are used to generate training data. Each example corresponds to one impression. The lab el is app ac quisition : 1 if the impressed app w as installed, and 0 otherwise. V o cabularies, which are tables mapping categorical fea- ture strings to in teger IDs, are also generated in this stage. The system computes th e ID space for all the string features that o ccurred more than a minimum n umber of times. Con- tin uous real-v alued features are normalized to [0 , 1] by map- ping a feature v alue x to its cum ulative distribution function P ( X ≤ x ), divided into n q quan tiles. The normalized v alue is i − 1 n q − 1 for v alues in the i -th quantiles. Quantile boundaries ReLU (1024) Logistic Loss Embeddings ReLU (512) ReLU (256) User Installed App Impression App User Demographics Device Class ... Age #App Installs #Engagement sessions ... Cross Product Transformation Embeddings Embeddings Embeddings Concatenated Embeddings (~1200 dimensions) Continuous Features Categorical Features Figure 4: Wide & Deep mo del structure for apps recommendation. are computed during data generation. 4.2 Model T raining The model struct ure we used in the exp erimen t is shown in Figure 4. During training, our input lay er tak es in training data and vocabularies and generate sparse and dense fea- tures together with a lab el. The wide comp onen t consists of the cross-pro duct transformation of user installed apps and impression apps. F or the deep part of the mo del, A 32- dimensional embedding v ector is learned for eac h categorical feature. W e concatenate all the embeddings together with the dense features, resulting in a dense vect or of approxi- mately 1200 dimensions. The concatenated v ector is then fed in to 3 ReLU lay ers, and finally the logistic output unit. The Wide & Deep models are trained on ov er 500 billion examples. Ev ery time a new set of training data arrives, the model needs to be re-trained. How ever, retraining from scratc h every time is computationally exp ensive and delays the time from data arriv al to serving an updated model. T o tackle this c hallenge, we implemented a wa rm-starting system whic h initializes a new model with the embeddings and the linear mo del weigh ts from the previous model. Before loading the mo dels in to the mo del servers, a dry run of the mo del is done to make sure that it do es not cause problems in serving liv e traffic. W e empirically v alidate the model qualit y against the previous model as a sanity chec k. 4.3 Model Serving Once the mo del is trained and verified, w e load it into the model serv ers. F or each request, the servers receiv e a set of app candidates from the app retriev al system and user features to score eac h app. Then, the apps are rank ed from the highest scores to the lo w est, and w e show the apps to the users in this order. The scores are calculated b y running a forw ard inference pass ov er the Wide & Deep mo del. In order to serve each request on the order of 10 ms, we optimized the p erformance using m ultithreading parallelism b y running smaller batches in parallel, instead of scoring all candidate apps in a single batch inference step. 5. EXPERIMENT RESUL TS T o ev aluate the effectiveness of Wide & Deep learning in a real-w orld recommender system, w e ran live exp erimen ts and ev aluated the system in a couple of asp ects: app acqui- sitions and serving p erformance. 5.1 A pp Acquisitions W e conducted live online exp erimen ts in an A/B test- ing framework for 3 w eeks. F or the control group, 1% of T able 1: Offline & onl ine metrics o f different models. Online Acquisition Gain is relativ e to the control. Model Offline A UC Online Acquisition Gain Wide (con trol) 0.726 0% Deep 0.722 +2.9% Wide & Deep 0.728 +3.9% users were randomly selected and presen ted with recom- mendations generated by the previous version of ranking model, which is a highly-optimized wide-only logistic regres- sion mo del with rich cross-pro duct feature transformations. F or the exp erimen t group, 1% of users were presented with recommendations generated by the Wide & Deep model, trained with the same set of features. As shown in T able 1, Wide & Deep model improv ed the app acquisition rate on the main landing page of the app store by +3.9% relative to the con trol group (statistically significant). The results w ere also compared with another 1% group using only the deep part of the model with the same features and neural net work structure, and the Wide & Deep mode had +1% gain on top of the deep-only mo del (statistically significan t). Besides online exp erimen ts, we also sho w the Area Under Receiv er Operator Characteristic Curv e (A UC) on a holdout set offline. While Wide & Deep has a slightly higher offline A UC, the impact is more significant on online traffic. One possible reason is that the impressions and labels in offline data sets are fixed, whereas the online system can generate new exploratory recommendations by blending generaliza- tion with memorization, and learn from new user resp onses. 5.2 Serving Perf ormance Serving with high throughput and lo w latency is challeng- ing with the high level of traffic faced by our commercial mobile app store. At p eak traffic, our recommender servers score o ver 10 million apps p er second. With single threading, scoring all candidates in a single batch takes 31 ms. W e im- plemen ted multith reading and split eac h batc h into smaller sizes, whic h significantly reduced the clien t-side latency to 14 ms (including serving o verhead ) as sho wn in T able 2. 6. RELA TED WORK The idea of com bining wide linear mo dels with cross- product feature transformations and deep neural net w orks with dense em beddings is inspired by previous work, suc h as factorization mac hines [5] whic h add generalization to linear models by factorizing the interactions betw een tw o v ariables as a dot pro duct betw een t wo low-dimensional embedding v ectors. In this pap er, we expanded the mo del capacity b y learning highly nonlinear in teractions b et ween em b eddings via neural netw orks instead of dot products. In language models, joint training of recurren t neural net- w orks (RNNs) and maxim um en trop y mo dels with n -gram features has been proposed to significantly reduce the RNN complexit y (e.g., hidden la yer sizes) b y learning direct weigh ts betw een inputs and outputs [4]. In computer vision, deep residual learning [2] has b een used to reduce the difficulty of training deep er mo dels and improv e accuracy with shortcut connections which skip one or more lay ers. Join t training of neural net works with graphical models has also been applied to h uman p ose estimation from images [6]. In this work we explored the joint training of feed-forwa rd neural net works T able 2: Serving latency vs. batc h size and threads. Batc h size Num b er of Threads Serving Latency (ms) 200 1 31 100 2 17 50 4 14 and linear mo dels, with direct connections b etw een sparse features and the output unit, for generic recommendation and ranking problems with sparse input data. In the recommender syst ems literature, collaborativ e deep learning has been explored b y coupling deep learning for con tent information and collaborative filtering (CF) for the ratings matrix [7]. There has also b een previous work on mobile app recommender systems, such as AppJo y which used CF on users’ app usage records [8]. Different from the CF-based or conten t-based approaches in the previous work, w e join tly train Wide & Deep models on user and impression data for app recommender systems. 7. CONCLUSION Memorization and generalization are both imp ortan t for recommender systems. Wide linear mo dels can effectiv ely memorize sparse feature interac tions using cross-pro duct fea- ture transformations, while deep neural netw orks can gener- alize to previously unseen feature interactions through lo w- dimensional em beddings. W e presented the Wide & Deep learning framework to combine the strengths of both types of mo del. W e productionized and ev aluated the framework on the recommender system of Go ogle Play , a massive-scale commercial app store. Online exp erimen t results show ed that the Wide & Deep mo del led to significant impro v ement on app acquisitions ov er wide-only and deep-only mo dels. 8. REFERENCES [1] J. Duchi, E. Hazan, and Y. Singer. Adaptiv e subgradien t methods for online learning and sto c hastic optimization. Journal of Machine L e arning R ese ar ch , 12:2121–2159, July 2011. [2] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. Pr o c. IEEE Confer enc e on Computer Vision and Pattern Re co gnition , 2016. [3] H. B. McMahan. F ollow-the-reg ularized-leader and mirror descen t: Equiv alence theorems and l1 regularization. In Pr o c. AIST A TS , 2011. [4] T. Mikolo v, A. Deoras, D. P ov ey , L. Burget, and J. H. Cernocky . Strategies for training large scale neural net work language models. In IEEE Automatic Sp e e ch R e c o gnition & Understanding Workshop , 2011. [5] S. Rendle. F actorization mach ines with libFM. ACM T r ans. Intel l. Syst. T e chnol. , 3(3):57:1–57:22, May 2012. [6] J. J. T ompson, A. Jain, Y. LeCun, and C. Bregler. Joint training of a conv olutional netw ork and a graphical model for human p ose estimation. In Z. Ghahramani, M. W elling, C. Cortes, N. D. La wrence, and K. Q. W einberger, editors, NIPS , pages 1799–1807. 2014. [7] H. W ang, N. W ang, and D.-Y. Y eung. Collaborative deep learning for recommender systems. In Pr o c. KDD , pages 1235–1244, 2015. [8] B. Y an and G. Chen. AppJo y: P ersonalized mobile application discov ery . In MobiSys , pages 113–126, 2011.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment