Complex Embeddings for Simple Link Prediction
In statistical relational learning, the link prediction problem is key to automatically understand the structure of large knowledge bases. As in previous studies, we propose to solve this problem through latent factorization. However, here we make us…
Authors: Theo Trouillon, Johannes Welbl, Sebastian Riedel
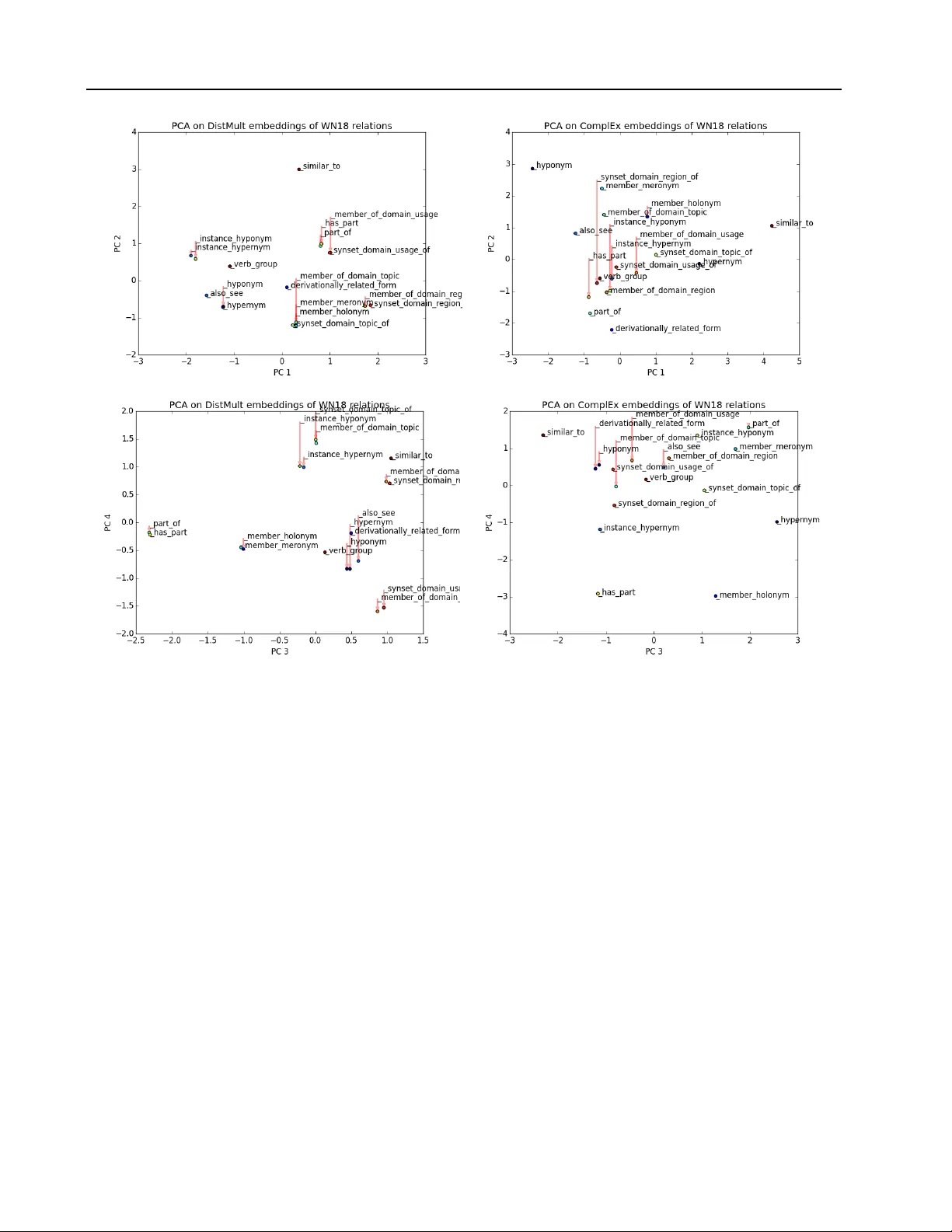
Complex Embeddings f or Simple Link Pr ediction Th ´ eo T rouillon 1 , 2 T H E O . T RO U I L L O N @ X R C E . X E R OX . C O M Johannes W elbl 3 J . W E L B L @ C S . U C L . AC . U K Sebastian Riedel 3 S . R I E D E L @ C S . U C L . AC . U K ´ Eric Gaussier 2 E R I C . G AU S S I E R @ I M AG . F R Guillaume Bouchard 3 G . B O U C H A R D @ C S . U C L . AC . U K 1 Xerox Research Centre Europe, 6 chemin de Maupertuis, 38240 Meylan, FRANCE 2 Univ ersit ´ e Grenoble Alpes, 621 av enue Centrale, 38400 Saint Martin d’H ` eres, FRANCE 3 Univ ersity College London, Go wer St, London WC1E 6BT , UNITED KINGDOM Abstract In statistical relational learning, the link predic- tion problem is k ey to automatically understand the structure of large kno wledge bases. As in pre- vious studies, we propose to solve this problem through latent factorization. Howe ver , here we make use of complex valued embeddings. The composition of complex embeddings can handle a large variety of binary relations, among them symmetric and antisymmetric relations. Com- pared to state-of-the-art models such as Neural T ensor Network and Holographic Embeddings, our approach based on complex embeddings is arguably simpler , as it only uses the Hermitian dot product, the comple x counterpart of the stan- dard dot product between real vectors. Our ap- proach is scalable to large datasets as it remains linear in both space and time, while consistently outperforming alternativ e approaches on stan- dard link prediction benchmarks. 1 1. Introduction W eb-scale knowledge bases (KBs) provide a structured representation of world kno wledge, with projects such as DBPedia ( Auer et al. , 2007 ), Freebase ( Bollacker et al. , 2008 ) or the Google Knowledge V ault ( Dong et al. , 2014 ). They enable a wide range of applications such as recom- mender systems, question answering or automated personal agents. The incompleteness of these KBs has stimulated 1 Code is av ailable at: https://github.com/ ttrouill/complex Pr oceedings of the 33 rd International Confer ence on Machine Learning , New Y ork, NY , USA, 2016. JMLR: W&CP volume 48. Copyright 2016 by the author(s). research into predicting missing entries, a task known as link prediction that is one of the main problems in Statisti- cal Relational Learning (SRL, Getoor & T askar , 2007 ). KBs express data as a directed graph with labeled edges (relations) between nodes (entities). Natural redundan- cies among the recorded relations often make it possi- ble to fill in the missing entries of a KB. As an exam- ple, the relation CountryOfBirth is not recorded for all entities, but it can easily be inferred if the relation CityOfBirth is kno wn. The goal of link prediction is the automatic discovery of such re gularities. How- ev er , many relations are non-deterministic: the combina- tion of the two facts IsBornIn(John,Athens) and IsLocatedIn(Athens,Greece) does not always imply the fact HasNationality(John,Greece) . Hence, it is required to handle other facts in v olving these relations or entities in a probabilistic fashion. T o do so, an increasingly popular method is to state the link prediction task as a 3D binary tensor completion prob- lem, where each slice is the adjacency matrix of one re- lation type in the knowledge graph. Completion based on low-rank factorization or embeddings has been popularized with the Netflix challenge ( Koren et al. , 2009 ). A partially observed matrix or tensor is decomposed into a product of embedding matrices with much smaller rank, resulting in fix ed-dimensional vector representations for each entity and relation in the database. For a giv en fact r(s,o) in which subject s is linked to object o through relation r , the score can then be recov ered as a multi-linear product between the embedding vectors of s , r and o ( Nickel et al. , 2016a ). Binary relations in KBs exhibit various types of pat- terns: hierarchies and compositions like FatherOf , OlderThan or IsPartOf —with partial/total, strict/non-strict orders—and equiv alence relations like IsSimilarTo . As described in Bordes et al. ( 2013a ), a relational model should (a) be able to learn Complex Embeddings for Simple Link Pr ediction all combinations of these properties, namely reflexiv- ity/irreflexi vity , symmetry/antisymmetry and transitivity , and (b) be linear in both time and memory in order to scale to the size of present day KBs, and keep up with their growth. Dot products of embeddings scale well and can naturally handle both symmetry and (ir-)reflexi vity of relations; us- ing an appropriate loss function e ven enables transitiv- ity ( Bouchard et al. , 2015 ). Howe ver , dealing with anti- symmetric relations has so far almost always implied an explosion of the number of parameters ( Nickel et al. , 2011 ; Socher et al. , 2013 ) (see T able 1 ), making models prone to ov erfitting. Finding the best ratio between expressiv e- ness and parameter space size is the keystone of embedding models. In this work we argue that the standard dot product between embeddings can be a very effecti ve composition function, provided that one uses the right r epresentation . Instead of using embeddings containing real numbers we discuss and demonstrate the capabilities of complex embeddings. When using complex v ectors, i.e. vectors with entries in C , the dot product is often called the Hermitian (or sesquilin- ear) dot product, as it in volv es the conjugate-transpose of one of the two vectors. As a consequence, the dot product is not symmetric any more, and facts about antisymmetric relations can receiv e different scores depending on the or- dering of the entities inv olved. Thus complex vectors can effecti vely capture antisymmetric relations while retaining the ef ficiency benefits of the dot product, that is linearity in both space and time complexity . The remainder of the paper is org anized as follows. W e first justify the intuition of using complex embeddings in the square matrix case in which there is only a single rela- tion between entities. The formulation is then extended to a stacked set of square matrices in a third-order tensor to represent multiple relations. W e then describe experiments on large scale public benchmark KBs in which we empiri- cally show that this representation leads not only to simpler and faster algorithms, but also gives a systematic accuracy improv ement over current state-of-the-art alternati ves. T o giv e a clear comparison with respect to e xisting ap- proaches using only real numbers, we also present an equiv alent reformulation of our model that in v olves only real embeddings. This should help practitioners when im- plementing our method, without requiring the use of com- plex numbers in their software implementation. 2. Relations as Real Part of Low-Rank Normal Matrices In this section we discuss the use of complex embed- dings for low-rank matrix factorization and illustrate this by considering a simplified link prediction task with merely a single relation type. Understanding the factorization in complex space leads to a better theoretical understanding of the class of matrices that can actually be approximated by dot products of embed- dings. These are the so-called normal matrices for which the left and right embeddings share the same unitary basis. 2.1. Modelling Relations Let E be a set of entities with |E | = n . A relation between two entities is represented as a binary v alue Y so ∈ {− 1 , 1 } , where s ∈ E is the subject of the relation and o ∈ E its object. Its probability is given by the logistic inv erse link function: P ( Y so = 1) = σ ( X so ) (1) where X ∈ R n × n is a latent matrix of scores, and Y the partially observed sign matrix. Our goal is to find a generic structure for X that leads to a flexible approximation of common relations in real world KBs. Standard matrix factorization approximates X by a matrix product U V T , where U and V are two functionally independent n × K matrices, K being the rank of the ma- trix. W ithin this formulation it is assumed that entities ap- pearing as subjects are different from entities appearing as objects. This means that the same entity will have two dif- ferent embedding vectors, depending on whether it appears as the subject or the object of a relation. This extensi vely studied type of model is closely related to the singular v alue decomposition (SVD) and fits well to the case where the matrix X is rectangular . Ho wev er , in many link prediction problems, the same entity can appear as both subject and object. It then seems natural to learn joint embeddings of the entities, which entails sharing the embeddings of the left and right f actors, as proposed by se veral authors to solve the link prediction problem ( Nick el et al. , 2011 ; Bor - des et al. , 2013b ; Y ang et al. , 2015 ). In order to use the same embedding for subjects and ob- jects, researchers hav e generalised the notion of dot prod- ucts to scoring functions , also known as composition func- tions , that combine embeddings in specific ways. W e briefly recall sev eral examples of scoring functions in T a- ble 1 , as well as the extension proposed in this paper . Using the same embeddings for right and left factors boils down to Eigen value decomposition: X = E W E − 1 . (2) It is often used to approximate real symmetric matrices such as covariance matrices, kernel functions and distance or similarity matrices. In these cases all eigenv alues and eigen vectors live in the real space and E is orthogonal: Complex Embeddings for Simple Link Pr ediction Model Scoring Function Relation parameters O time O space RESCAL ( Nickel et al. , 2011 ) e T s W r e o W r ∈ R K 2 O ( K 2 ) O ( K 2 ) T ransE ( Bordes et al. , 2013b ) || ( e s + w r ) − e o || p w r ∈ R K O ( K ) O ( K ) NTN ( Socher et al. , 2013 ) u T r f ( e s W [1 ..D ] r e o + V r e s e o + b r ) W r ∈ R K 2 D , b r ∈ R K V r ∈ R 2 K D , u r ∈ R K O ( K 2 D ) O ( K 2 D ) DistMult ( Y ang et al. , 2015 ) < w r , e s , e o > w r ∈ R K O ( K ) O ( K ) HolE ( Nickel et al. , 2016b ) w T r ( F − 1 [ F [ e s ] F [ e o ]])) w r ∈ R K O ( K log K ) O ( K ) ComplEx Re( < w r , e s , ¯ e o > ) w r ∈ C K O ( K ) O ( K ) T able 1. Scoring functions of state-of-the-art latent factor models for a given fact r ( s, o ) , along with their relation parameters, time and space (memory) complexity . The embeddings e s and e o of subject s and object o are in R K for each model, except for our model (ComplEx) where e s , e o ∈ C K . D is an additional latent dimension of the NTN model. F and F − 1 denote respectiv ely the Fourier transform and its in verse, and is the element-wise product between two vectors. E T = E − 1 . W e are in this work howe ver explicitly inter- ested in problems where matrices — and thus the relations they represent — can also be antisymmetric. In that case eigen v alue decomposition is not possible in the real space; there only exists a decomposition in the complex space where embeddings x ∈ C K are composed of a real vec- tor component Re( x ) and an imaginary vector component Im( x ) . W ith complex numbers, the dot product, also called the Hermitian product, or sesquilinear form, is defined as: h u, v i := ¯ u T v (3) where u and v are complex-v alued vectors, i.e. u = Re( u ) + i Im( u ) with Re( u ) ∈ R K and Im( u ) ∈ R K cor- responding to the real and imaginary parts of the vector u ∈ C K , and i denoting the square root of − 1 . W e see here that one crucial operation is to take the conjugate of the first vector: ¯ u = Re( u ) − i Im( u ) . A simple way to justify the Hermitian product for composing complex vectors is that it provides a valid topological norm in the induced vectorial space. For example, ¯ x T x = 0 implies x = 0 while this is not the case for the bilinear form x T x as there are many complex v ectors for which x T x = 0 . Even with complex eigen vectors E ∈ C n × n , the in version of E in the eigendecomposition of Equation ( 2 ) leads to computational issues. Fortunately , mathematicians defined an appropriate class of matrices that prevents us from in- verting the eigenv ector matrix: we consider the space of normal matrices , i.e. the complex n × n matrices X , such that X ¯ X T = ¯ X T X . The spectral theorem for normal ma- trices states that a matrix X is normal if and only if it is unitarily diagonalizable: X = E W ¯ E T (4) where W ∈ C n × n is the diagonal matrix of eigen values (with decreasing modulus) and E ∈ C n × n is a unitary ma- trix of eigenv ectors, with ¯ E representing its complex con- jugate. The set of purely real normal matrices includes all sym- metric and antisymmetric sign matrices (useful to model hierarchical relations such as IsOlder ), as well as all orthogonal matrices (including permutation matrices), and many other matrices that are useful to represent binary rela- tions, such as assignment matrices which represent bipar- tite graphs. Ho wev er , far from all matrices expressed as E W ¯ E T are purely real, and equation 1 requires the scores X to be purely real. So we simply keep only the real part of the decomposition: X = Re( E W ¯ E T ) . (5) In fact, performing this projection on the real subspace al- lows the exact decomposition of any real square matrix X and not only normal ones, as shown by Trouillon et al. ( 2016 ). Compared to the singular value decomposition, the eigen- value decomposition has tw o key dif ferences: • The eigenv alues are not necessarily positi ve or real; • The factorization ( 5 ) is useful as the ro ws of E can be used as vectorial representations of the entities corre- sponding to rows and columns of the relation matrix X . Indeed, for a giv en entity , its subject embedding vector is the complex conjugate of its object embed- ding vector . 2.2. Low-Rank Decomposition In a link prediction problem, the relation matrix is unkno wn and the goal is to recover it entirely from noisy observa- tions. T o enable the model to be learnable , i.e. to gener- alize to unobserved links, some regularity assumptions are needed. Since we deal with binary relations, we assume that they hav e low sign-rank . The sign-rank of a sign ma- trix is the smallest rank of a real matrix that has the same sign-pattern as Y : rank ± ( Y ) = min A ∈ R m × n { rank( A ) | sign( A ) = Y } . (6) Complex Embeddings for Simple Link Pr ediction This is theoretically justified by the fact that the sign- rank is a natural complexity measure of sign matrices ( Linial et al. , 2007 ) and is linked to learnability ( Alon et al. , 2015 ), and empirically confirmed by the wide success of factorization models ( Nickel et al. , 2016a ). If the observ ation matrix Y is low-sign-rank, then our model can decompose it with a rank at most the double of the sign-rank of Y . That is, for any Y ∈ {− 1 , 1 } n × n , there always exists a matrix X = Re( E W ¯ E T ) with the same sign pattern sign( X ) = Y , where the rank of E W ¯ E T is at most twice the sign-rank of Y ( T rouillon et al. , 2016 ). Although twice sounds bad, this is actually a good upper bound. Indeed, the sign-rank is often much lower than the rank of Y . For example, the rank of the n × n identity matrix I is n , but rank ± ( I ) = 3 ( Alon et al. , 2015 ). By permutation of the columns 2 j and 2 j + 1 , the I matrix corresponds to the relation marriedTo , a relation known to be hard to factorize ( Nickel et al. , 2014 ). Y et our model can express it in rank 6, for an y n . By imposing a low-rank K n on E W ¯ E T , only the first K values of diag ( W ) are non-zero. So we can directly have E ∈ C n × K and W ∈ C K × K . Individual relation scores X so between entities s and o can be predicted through the following product of their embeddings e s , e o ∈ C K : X so = Re( e T s W ¯ e o ) . (7) W e summarize the abov e discussion in three points: 1. Our factorization encompasses all possible binary re- lations. 2. By construction, it accurately describes both symmet- ric and antisymmetric relations. 3. Learnable relations can be ef ficiently approximated by a simple low-rank factorization, using complex num- bers to represent the latent factors. 3. A pplication to Binary Multi-Relational Data The previous section focused on modeling a single type of relation; we now extend this model to multiple types of relations. W e do so by allocating an embedding w r to each relation r , and by sharing the entity embeddings across all relations. Let R and E be the set of relations and entities present in the KB. W e want to recov er the matrices of scores X r for all the relations r ∈ R . Giv en two entities s and o ∈ E , the log-odd of the probability that the fact r(s,o) is true is: P ( Y rso = 1) = σ ( φ ( r , s, o ; Θ)) (8) where φ is a scoring function that is typically based on a factorization of the observed relations and Θ denotes the parameters of the corresponding model. While X as a whole is unknown, we assume that we observe a set of true and false facts { Y rso } r ( s,o ) ∈ Ω ∈ {− 1 , 1 } | Ω | , corre- sponding to the partially observed adjacency matrices of different relations, where Ω ⊂ R ⊗ E ⊗ E is the set of ob- served triples. The goal is to find the probabilities of entries Y r 0 s 0 o 0 being true or false for a set of targeted unobserved triples r 0 ( s 0 , o 0 ) / ∈ Ω . Depending on the scoring function φ ( s, r , o ; Θ) used to predict the entries of the tensor X , we obtain different mod- els. Examples of scoring functions are given in T able 1 . Our model scoring function is: φ ( r , s, o ; Θ) = Re( < w r , e s , ¯ e o > ) (9) = Re( K X k =1 w rk e sk ¯ e ok ) (10) = h Re( w r ) , Re( e s ) , Re( e o ) i + h Re( w r ) , Im( e s ) , Im( e o ) i + h Im( w r ) , Re( e s ) , Im( e o ) i − h Im( w r ) , Im( e s ) , Re( e o ) i (11) where w r ∈ C K is a complex vector . These equations provide two interesting vie ws of the model: • Changing the repr esentation : Equation ( 10 ) would correspond to DistMult with real embeddings, but handles asymmetry thanks to the complex conjugate of one of the embeddings 2 . • Changing the scoring function : Equation ( 11 ) only in- volv es real vectors corresponding to the real and imag- inary parts of the embeddings and relations. One can easily check that this function is antisymmetric when w r is purely imaginary (i.e. its real part is zero), and symmetric when w r is real. Interestingly , by separating the real and imaginary part of the relation embedding w r , we obtain a decomposition of the relation matrix X r as the sum of a symmetric matrix Re( E diag (Re( w r )) ¯ E T ) and a antisymmetric matrix Im( E diag ( − Im( w r )) ¯ E T ) . Re- lation embeddings naturally act as weights on each la- tent dimension: Re( w r ) over the symmetric, real part of h e o , e s i , and Im( w ) ov er the antisymmetric, imaginary part of h e o , e s i . Indeed, one has h e o , e s i = h e s , e o i , meaning that Re( h e o , e s i ) is symmetric, while Im( h e o , e s i ) is an- tisymmetric. This enables us to accurately describe both 2 Note that in Equation ( 10 ) we used the standard componen- twise multi-linear dot product < a, b, c > := P k a k b k c k . This is not the Hermitian extension as it is not properly defined in the linear algebra literature. Complex Embeddings for Simple Link Pr ediction symmetric and antisymmetric relations between pairs of entities, while still using joint representations of entities, whether they appear as subject or object of relations. Geometrically , each relation embedding w r is an anisotropic scaling of the basis defined by the entity embed- dings E , followed by a projection onto the real subspace. 4. Experiments In order to ev aluate our proposal, we conducted experi- ments on both synthetic and real datasets. The synthetic dataset is based on relations that are either symmetric or antisymmetric, whereas the real datasets comprise differ - ent types of relations found in different, standard KBs. W e refer to our model as ComplEx, for Complex Embeddings. 4.1. Synthetic T ask T o assess the ability of our proposal to accurately model symmetry and antisymmetry , we randomly generated a KB of two relations and 30 entities. One relation is entirely symmetric, while the other is completely antisymmetric. This dataset corresponds to a 2 × 30 × 30 tensor . Figure 2 shows a part of this randomly generated tensor, with a symmetric slice and an antisymmetric slice, decomposed into training, validation and test sets. The diagonal is un- observed as it is not rele v ant in this experiment. The train set contains 1392 observed triples, whereas the validation and test sets contain 174 triples each. Figure 1 shows the best cross-validated A verage Precision (area under Precision-Recall curve) for dif ferent factorization models of ranks ranging up to 50. Models were trained using Stochastic Gradient Descent with mini-batches and AdaGrad for tuning the learning rate ( Duchi et al. , 2011 ), by minimizing the negati ve log-likelihood of the logistic model with L 2 regularization on the parameters Θ of the considered model: min Θ X r ( s,o ) ∈ Ω log(1 + exp( − Y rso φ ( s, r , o ; Θ))) + λ || Θ || 2 2 . (12) In our model, Θ corresponds to the embeddings e s , w r , e o ∈ C K . W e describe the full algorithm in Ap- pendix A . λ is v alidated in { 0 . 1 , 0 . 03 , 0 . 01 , 0 . 003 , 0 . 001 , 0 . 0003 , 0 . 00001 , 0 . 0 } . As expected, DistMult ( Y ang et al. , 2015 ) is not able to model antisymmetry and only predicts the symmetric relations correctly . Although TransE ( Bor - des et al. , 2013b ) is not a symmetric model, it performs poorly in practice, particularly on the antisymmetric rela- tion. RESCAL ( Nickel et al. , 2011 ), with its large number of parameters, quickly overfits as the rank grows. Canon- ical Polyadic (CP) decomposition ( Hitchcock , 1927 ) fails Figure 2. Parts of the training, validation and test sets of the gener- ated experiment with one symmetric and one antisymmetric rela- tion. Red pixels are positiv e triples, blue are ne gativ es, and green missing ones. T op: Plots of the symmetric slice (relation) for the 10 first entities. Bottom: Plots of the antisymmetric slice for the 10 first entities. on both relations as it has to push symmetric and antisym- metric patterns through the entity embeddings. Surpris- ingly , only our model succeeds on such simple data. 4.2. Datasets: FB15K and WN18 Dataset |E | |R| #triples in T rain/V alid/T est WN18 40,943 18 141,442 / 5,000 / 5,000 FB15K 14,951 1,345 483,142 / 50,000 / 59,071 T able 3. Number of entities, relations, and observed triples in each split for the FB15K and WN18 datasets. W e next ev aluate the performance of our model on the FB15K and WN18 datasets. FB15K is a subset of F ree- base , a curated KB of general facts, whereas WN18 is a subset of W or dnet , a database featuring lexical relations be- tween words. W e use original training, validation and test set splits as provided by Bordes et al. ( 2013b ). T able 3 summarizes the metadata of the two datasets. Both datasets contain only positi ve triples. As in Bor- des et al. ( 2013b ), we generated negati ves using the local closed world assumption . That is, for a triple, we randomly change either the subject or the object at random, to form a negati ve example. This negativ e sampling is performed at runtime for each batch of training positiv e examples. For evaluation, we measure the quality of the ranking of each test triple among all possible subject and object sub- stitutions : r ( s 0 , o ) and r ( s, o 0 ) , ∀ s 0 , ∀ o 0 ∈ E . Mean Recip- rocal Rank (MRR) and Hits at m are the standard ev alua- tion measures for these datasets and come in two flavours: raw and filtered ( Bordes et al. , 2013b ). The filtered metrics Complex Embeddings for Simple Link Pr ediction Figure 1. A verage Precision (AP) for each factorization rank ranging from 1 to 50 for dif ferent state of the art models on the combined symmetry and antisymmetry experiment. T op-left: AP for the symmetric relation only . T op-right: AP for the antisymmetric relation only . Bottom: Overall AP . are computed after remo ving all the other positiv e observed triples that appear in either training, validation or test set from the ranking, whereas the raw metrics do not remov e these. Since ranking measures are used, pre vious studies gener- ally preferred a pairwise ranking loss for the task ( Bordes et al. , 2013b ; Nickel et al. , 2016b ). W e chose to use the neg- ativ e log-lik elihood of the logistic model, as it is a continu- ous surrog ate of the sign-rank, and has been sho wn to learn compact representations for several important relations, es- pecially for transitive relations ( Bouchard et al. , 2015 ). In preliminary work, we tried both losses, and indeed the log- likelihood yielded better results than the ranking loss (ex- cept with T ransE), especially on FB15K. W e report both filtered and raw MRR, and filtered Hits at 1, 3 and 10 in T able 2 for the e v aluated models. Furthermore, we chose T ransE, DistMult and HolE as baselines since they are the best performing models on those datasets to the best of our kno wledge ( Nickel et al. , 2016b ; Y ang et al. , 2015 ). W e also compare with the CP model to emphasize empirically the importance of learning unique embeddings for entities. For experimental fairness, we reimplemented these methods within the same frame work as the ComplEx model, using theano ( Bergstra et al. , 2010 ). Ho we ver , due to time constraints and the complexity of an efficient imple- mentation of HolE, we record the original results for HolE as reported in Nickel et al. ( 2016b ). 4.3. Results WN18 describes lexical and semantic hierarchies between concepts and contains many antisymmetric relations such as hypernymy , hyponymy , or being ”part of”. Indeed, the DistMult and T ransE models are outperformed here by ComplEx and HolE, which are on par with respectiv e fil- tered MRR scores of 0.941 and 0.938. T able 4 shows the filtered test set MRR for the models considered and each relation of WN18, confirming the advantage of our model on antisymmetric relations while losing nothing on the oth- ers. 2D projections of the relation embeddings provided in Appendix B visually corroborate the results. On FB15K, the gap is much more pronounced and the ComplEx model largely outperforms HolE, with a filtered MRR of 0.692 and 59.9% of Hits at 1, compared to 0.524 and 40.2% for HolE. W e attribute this to the simplicity of our model and the dif ferent loss function. This is supported by the relativ ely small gap in MRR compared to DistMult (0.654); our model can in fact be interpreted as a complex number version of DistMult. On both datasets, TransE Complex Embeddings for Simple Link Pr ediction WN18 FB15K MRR Hits at MRR Hits at Model Filter Raw 1 3 10 Filter Raw 1 3 10 CP 0.075 0.058 0.049 0.080 0.125 0.326 0.152 0.219 0.376 0.532 T ransE 0.454 0.335 0.089 0.823 0.934 0.380 0.221 0.231 0.472 0.641 DistMult 0.822 0.532 0.728 0.914 0.936 0.654 0.242 0.546 0.733 0.824 HolE* 0.938 0.616 0.93 0.945 0.949 0.524 0.232 0.402 0.613 0.739 ComplEx 0.941 0.587 0.936 0.945 0.947 0.692 0.242 0.599 0.759 0.840 T able 2. Filtered and Raw Mean Reciprocal Rank (MRR) for the models tested on the FB15K and WN18 datasets. Hits@m metrics are filtered. *Results reported from ( Nickel et al. , 2016b ) for HolE model. Relation name ComplEx DistMult T ransE hypernym 0.953 0.791 0.446 hyponym 0.946 0.710 0.361 member meronym 0.921 0.704 0.418 member holonym 0.946 0.740 0.465 instance hypernym 0.965 0.943 0.961 instance hyponym 0.945 0.940 0.745 has part 0.933 0.753 0.426 part of 0.940 0.867 0.455 member of domain topic 0.924 0.914 0.861 synset domain topic of 0.930 0.919 0.917 member of domain usage 0.917 0.917 0.875 synset domain usage of 1.000 1.000 1.000 member of domain region 0.865 0.635 0.865 synset domain region of 0.919 0.888 0.986 deriv ationally related form 0.946 0.940 0.384 similar to 1.000 1.000 0.244 verb group 0.936 0.897 0.323 also see 0.603 0.607 0.279 T able 4. Filtered Mean Reciprocal Rank (MRR) for the models tested on each relation of the W ordnet dataset (WN18). and CP are largely left behind. This illustrates the power of the simple dot product in the first case, and the impor- tance of learning unique entity embeddings in the second. CP performs poorly on WN18 due to the small number of relations, which magnifies this subject/object difference. Reported results are gi ven for the best set of hyper-parameters ev aluated on the v alidation set for each model, after grid search on the fol- lowing values: K ∈ { 10 , 20 , 50 , 100 , 150 , 200 } , λ ∈ { 0 . 1 , 0 . 03 , 0 . 01 , 0 . 003 , 0 . 001 , 0 . 0003 , 0 . 0 } , α 0 ∈ { 1 . 0 , 0 . 5 , 0 . 2 , 0 . 1 , 0 . 05 , 0 . 02 , 0 . 01 } , η ∈ { 1 , 2 , 5 , 10 } with λ the L 2 regularization parameter , α 0 the initial learning rate (then tuned at runtime with AdaGrad), and η the number of negati ves generated per positive training triple. W e also tried varying the batch size but this had no impact and we settled with 100 batches per epoch. Best ranks were generally 150 or 200, in both cases scores were always very close for all models. The number of negati v e samples per positive sample also had a large influence on the filtered MRR on FB15K (up to +0.08 improvement from 1 to 10 negati ves), but not much on WN18. On both datasets regularization was important (up to +0.05 on filtered MRR between λ = 0 and optimal one). W e found the initial learning rate to be very important on FB15K, while not so much on WN18. W e think this may also explain the large gap of improvement our model provides on this dataset compared to pre viously published results – as DistMult results are also better than those pre viously reported ( Y ang et al. , 2015 ) – along with the use of the log-likelihood objectiv e. It seems that in general AdaGrad is relativ ely insensiti ve to the initial learning rate, perhaps causing some overconfidence in its ability to tune the step size online and consequently leading to less efforts when selecting the initial step size. T raining was stopped using early stopping on the valida- tion set filtered MRR, computed ev ery 50 epochs with a maximum of 1000 epochs. 4.4. Influence of Negative Samples W e further in vestigated the influence of the number of neg- ativ es generated per positiv e training sample. In the pre- vious e xperiment, due to computational limitations, the number of negati ves per training sample, η , was validated among the possible numbers { 1 , 2 , 5 , 10 } . W e want to ex- plore here whether increasing these numbers could lead to better results. T o do so, we focused on FB15K, with the best v alidated λ, K, α 0 , obtained from the pre vious e xperi- ment. W e then let η vary in { 1 , 2 , 5 , 10 , 20 , 50 , 100 , 200 } . Figure 3 shows the influence of the number of generated negati ves per positi ve training triple on the performance of our model on FB15K. Generating more negativ es clearly improv es the results, with a filtered MRR of 0.737 with 100 negati ve triples (and 64.8% of Hits@1), before decreas- ing again with 200 negati ves. The model also conv erges with fe wer epochs, which compensates partially for the ad- ditional training time per epoch, up to 50 neg ativ es. It then grows linearly as the number of negati ves increases, mak- ing 50 a good trade-of f between accurac y and training time. Complex Embeddings for Simple Link Pr ediction Figure 3. Influence of the number of negati ve triples generated per positiv e training example on the filtered test MRR and on train- ing time to con vergence on FB15K for the ComplEx model with K = 200 , λ = 0 . 01 and α 0 = 0 . 5 . T imes are giv en relativ e to the training time with one negativ e triple generated per positiv e training sample ( = 1 on time scale). 5. Related W ork In the early age of spectral theory in linear algebra, com- plex numbers were not used for matrix factorization and mathematicians mostly focused on bi-linear forms ( Bel- trami , 1873 ). The eigen-decomposition in the complex do- main as taught today in linear algebra courses came 40 years later ( Autonne , 1915 ). Similarly , most of the exist- ing approaches for tensor factorization were based on de- compositions in the real domain, such as the Canonical Polyadic (CP) decomposition ( Hitchcock , 1927 ). These methods are very effecti ve in many applications that use different modes of the tensor for different types of entities. But in the link prediction problem, antisymmetry of rela- tions was quickly seen as a problem and asymmetric ex- tensions of tensors were studied, mostly by either consider- ing independent embeddings ( Sutskev er , 2009 ) or consider- ing relations as matrices instead of vectors in the RESCAL model ( Nickel et al. , 2011 ). Direct extensions were based on uni-,bi- and trigram latent factors for triple data, as well as a low-rank relation matrix ( Jenatton et al. , 2012 ). Pairwise interaction models were also considered to im- prov e prediction performances. For example, the Uni versal Schema approach ( Riedel et al. , 2013 ) factorizes a 2D un- folding of the tensor (a matrix of entity pairs vs. relations) while W elbl et al. ( 2016 ) extend this also to other pairs. In the Neural T ensor Network (NTN) model, Socher et al. ( 2013 ) combine linear transformations and multiple bilin- ear forms of subject and object embeddings to jointly feed them into a nonlinear neural layer . Its non-linearity and multiple ways of including interactions between embed- dings giv es it an adv antage in expressi veness over models with simpler scoring function like DistMult or RESCAL. As a downside, its v ery large number of parameters can make the NTN model harder to train and overfit more eas- ily . The original multi-linear DistMult model is symmetric in subject and object for e very relation ( Y ang et al. , 2015 ) and achiev es good performance, presumably due to its simplic- ity . The TransE model from Bordes et al. ( 2013b ) also em- beds entities and relations in the same space and imposes a geometrical structural bias into the model: the subject en- tity vector should be close to the object entity vector once translated by the relation vector . A recent no vel way to handle antisymmetry is via the Holographic Embeddings (HolE) model by ( Nickel et al. , 2016b ). In HolE the circular correlation is used for combin- ing entity embeddings, measuring the cov ariance between embeddings at different dimension shifts. This generally suggests that other composition functions than the classi- cal tensor product can be helpful as they allow for a richer interaction of embeddings. Howe ver , the asymmetry in the composition function in HolE stems from the asymmetry of circular correlation, an O ( nlog ( n )) operation, whereas ours is inherited from the complex inner product, in O ( n ) . 6. Conclusion W e described a simple approach to matrix and tensor fac- torization for link prediction data that uses vectors with complex values and retains the mathematical definition of the dot product. The class of normal matrices is a natural fit for binary relations, and using the real part allows for ef- ficient approximation of any learnable relation. Results on standard benchmarks sho w that no more modifications are needed to improv e over the state-of-the-art. There are several directions in which this work can be ex- tended. An ob vious one is to merge our approach with known extensions to tensor factorization in order to fur- ther improv e predictiv e performance. For example, the use of pairwise embeddings together with complex numbers might lead to improved results in many situations that in- volv e non-compositionality . Another direction w ould be to dev elop a more intelligent negativ e sampling procedure, to generate more informativ e negati ves with respect to the positiv e sample from which they have been sampled. It would reduce the number of negati ves required to reach good performance, thus accelerating training time. Also, if we were to use complex embeddings ev ery time a model includes a dot product, e.g. in deep neural networks, would it lead to a similar systematic improv ement? Complex Embeddings for Simple Link Pr ediction Acknowledgements This w ork was supported in part by the P aul Allen Founda- tion through an Allen Distinguished In vestigator grant and in part by a Google Focused Research A ward. References Alon, Noga, Moran, Shay , and Y ehudayof f, Amir . Sign rank versus vc dimension. arXiv pr eprint arXiv:1503.07648 , 2015. Auer , Sren, Bizer, Christian, Kobilaro v , Georgi, Lehmann, Jens, and Ives, Zachary . Dbpedia: A nucleus for a web of open data. In In 6th Intl Semantic W eb Confer ence, Busan, K or ea , pp. 11–15. Springer , 2007. Autonne, L. Sur les matrices hypohermitiennes et sur les matrices unitaires. Ann. Univ . L yons, Nouvelle Srie I , 38: 1–77, 1915. Beltrami, Eugenio. Sulle funzioni bilineari. Giornale di Matematiche ad Uso de gli Studenti Delle Universita , 11 (2):98–106, 1873. Bergstra, James, Breuleux, Oli vier , Bastien, Fr ´ ed ´ eric, Lamblin, Pascal, Pascanu, Razvan, Desjardins, Guil- laume, T urian, Joseph, W arde-Farley , David, and Ben- gio, Y oshua. Theano: a CPU and GPU math expression compiler . In Pr oceedings of the Python for Scientific Computing Confer ence (SciPy) , June 2010. Oral Pre- sentation. Bollacker , Kurt, Ev ans, Colin, Paritosh, Prav een, Sturge, T im, and T aylor , Jamie. Freebase: a collaboratively cre- ated graph database for structuring human knowledge. In SIGMOD 08 Pr oceedings of the 2008 A CM SIGMOD international confer ence on Management of data , pp. 1247–1250, 2008. Bordes, Antoine, Usunier , Nicolas, Garcia-Duran, Alberto, W eston, Jason, and Y akhnenko, Oksana. Irreflexi ve and Hierarchical Relations as T ranslations. In CoRR , 2013a. Bordes, Antoine, Usunier , Nicolas, Garcia-Duran, Alberto, W eston, Jason, and Y akhnenko, Oksana. T ranslating embeddings for modeling multi-relational data. In Ad- vances in Neural Information Pr ocessing Systems , pp. 2787–2795, 2013b. Bouchard, Guillaume, Singh, Sameer , and T rouillon, Th ´ eo. On approximate reasoning capabilities of low-rank vec- tor spaces. In AAAI Spring Syposium on Knowledge Rep- r esentation and Reasoning (KRR): Integr ating Symbolic and Neural Appr oaches , 2015. Dong, Xin, Gabrilovich, Evgeniy , Heitz, Geremy , Horn, W ilko, Lao, Ni, Murphy , K evin, Strohmann, Thomas, Sun, Shaohua, and Zhang, W ei. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th A CM SIGKDD International Confer ence on Knowledge Discovery and Data Mining , KDD ’14, pp. 601–610, 2014. Duchi, John, Hazan, Elad, and Singer , Y oram. Adapti ve subgradient methods for online learning and stochastic optimization. The J ournal of Machine Learning Re- sear ch , 12:2121–2159, 2011. Getoor , Lise and T askar , Ben. Introduction to Statis- tical Relational Learning (Adaptive Computation and Machine Learning) . The MIT Press, 2007. ISBN 0262072882. Hitchcock, F . L. The expression of a tensor or a polyadic as a sum of products. J. Math. Phys , 6(1):164–189, 1927. Jenatton, Rodolphe, Bordes, Antoine, Le Roux, Nicolas, and Obozinski, Guillaume. A Latent Factor Model for Highly Multi-relational Data. In Advances in Neural In- formation Pr ocessing Systems 25 , pp. 3167–3175, 2012. K oren, Y ehuda, Bell, Robert, and V olinsk y , Chris. Ma- trix factorization techniques for recommender systems. Computer , 42(8):30–37, 2009. Linial, Nati, Mendelson, Shahar , Schechtman, Gideon, and Shraibman, Adi. Complexity measures of sign matrices. Combinatorica , 27(4):439–463, 2007. Nickel, Maximilian, Tresp, V olker , and Kriegel, Hans- Peter . A Three-W ay Model for Collective Learning on Multi-Relational Data. In 28th International Confer ence on Machine Learning , pp. 809—-816, 2011. Nickel, Maximilian, Jiang, Xueyan, and Tresp, V olker . Re- ducing the rank in relational factorization models by in- cluding observable patterns. In Advances in Neural In- formation Pr ocessing Systems , pp. 1179–1187, 2014. Nickel, Maximilian, Murphy , Ke vin, T resp, V olk er , and Gabrilovich, Evgeniy . A revie w of relational machine learning for knowledge graphs. Pr oceedings of the IEEE , 104(1):11–33, 2016a. Nickel, Maximilian, Rosasco, Lorenzo, and Poggio, T omaso A. Holographic embeddings of kno wledge graphs. In Proceedings of the Thirtieth AAAI Confer ence on Artificial Intelligence , pp. 1955–1961, 2016b. Riedel, Sebastian, Y ao, Limin, McCallum, Andrew , and Marlin, Benjamin M. Relation extraction with matrix factorization and uni versal schemas. In Human Lan- guage T echnologies: Confer ence of the North American Chapter of the Association of Computational Linguis- tics, Pr oceedings , pp. 74–84, 2013. Complex Embeddings for Simple Link Pr ediction Socher , Richard, Chen, Danqi, Manning, Christopher D, and Ng, Andre w . Reasoning with neural tensor netw orks for knowledge base completion. In Advances in Neural Information Pr ocessing Systems , pp. 926–934, 2013. Sutske ver , Ilya. Modelling Relational Data using Bayesian Clustered T ensor Factorization. In Advances in Neural Information Pr ocessing Systems , v olume 22, pp. 1–8, 2009. T rouillon, Th ´ eo, Dance, Christopher R., Gaussier, ´ Eric, and Bouchard, Guillaume. Decomposing real square ma- trices via unitary diagonalization. , 2016. W elbl, Johannes, Bouchard, Guillaume, and Riedel, Se- bastian. A factorization machine frame work for test- ing bigram embeddings in knowledgebase completion. arXiv:1604.05878 , 2016. Y ang, Bishan, Y ih, W en-tau, He, Xiaodong, Gao, Jianfeng, and Deng, Li. Embedding entities and relations for learn- ing and inference in knowledge bases. In International Confer ence on Learning Repr esentations , 2015. Complex Embeddings for Simple Link Pr ediction A. SGD algorithm W e describe the algorithm to learn the ComplEx model with Stochastic Gradient Descent using only real-v alued vectors. Let us rewrite equation 11 , by denoting the real part of embeddings with primes and the imaginary part with double primes: e 0 i = Re( e i ) , e 00 i = Im( e i ) , w 0 r = Re( w r ) , w 00 r = Im( w r ) . The set of parameters is Θ = { e 0 i , e 00 i , w 0 r , w 00 r ; ∀ i ∈ E , ∀ r ∈ R} , and the scoring function in volv es only real vectors: φ ( r , s, o ; Θ) = h w 0 r , e 0 s , e 0 o i + h w 0 r , e 00 s , e 00 o i + h w 00 r , e 0 s , e 00 o i − h w 00 r , e 00 s , e 0 o i where each entity and each relation has two real embed- dings. Gradients are now easy to write: ∇ e 0 s φ ( r , s, o ; Θ) = ( w 0 r e 0 o ) + ( w 00 r e 00 o ) ∇ e 00 s φ ( r , s, o ; Θ) = ( w 0 r e 00 o ) − ( w 00 r e 0 o ) ∇ e 0 o φ ( r , s, o ; Θ) = ( w 0 r e 0 s ) − ( w 00 r e 00 s ) ∇ e 00 o φ ( r , s, o ; Θ) = ( w 0 r e 00 s ) + ( w 00 r e 0 s ) ∇ w 0 r φ ( r , s, o ; Θ) = ( e 0 s e 0 o ) + ( e 00 s e 00 o ) ∇ w 00 r φ ( r , s, o ; Θ) = ( e 0 s e 00 o ) − ( e 00 s e 0 o ) where is the element-wise (Hadamard) product. As stated in equation 8 we use the sigmoid link function, and minimize the L 2 -regularized ne gativ e log-likelihood: γ (Ω; Θ) = X r ( s,o ) ∈ Ω log(1 + exp( − Y rso φ ( s, r , o ; Θ))) + λ || Θ || 2 2 . T o handle regularization, note that the squared L 2 -norm of a complex vector v = v 0 + iv 00 is the sum of the squared modulus of each entry: || v || 2 2 = X j q v 0 2 j + v 00 2 j 2 = X j v 0 2 j + X j v 00 2 j = || v 0 || 2 2 + || v 00 || 2 2 which is actually the sum of the L 2 -norms of the vectors of the real and imaginary parts. Algorithm 1 SGD for the ComplEx model input Training set Ω , V alidation set Ω v , learning rate α , embedding dim. k , regularization factor λ , neg ativ e ratio η , batch size b , max iter m , early stopping s . e 0 i ← randn( k ) , e 00 i ← randn( k ) for each i ∈ E w 0 i ← randn( k ) , w 00 i ← randn( k ) for each i ∈ R for i = 1 , · · · , m do for j = 1 .. | Ω | /b do Ω b ← sample (Ω , b, η ) Update embeddings w .r .t.: P r ( s,o ) ∈ Ω b ∇ γ ( { r ( s, o ) } ; Θ) Update learning rate α using Adagrad end for if i mo d s = 0 then break if filteredMRR or AP on Ω v decreased end if end for W e can finally write the gradient of γ with respect to a r eal embedding v for one triple r ( s, o ) : ∇ v γ ( { r ( s, o ) } ; Θ) = − Y rso φ ( s, r , o ; Θ) σ ( ∇ v φ ( r , s, o ; Θ)) +2 λv where σ ( x ) = 1 1+e − x is the sigmoid function. Algorithm 1 describes SGD for this formulation of the scor- ing function. When Ω contains only positiv e triples, we generate η negati ves per positi ve train triple, by corrupt- ing either the subject or the object of the positiv e triple, as described in Bordes et al. ( 2013b ). B. WN18 embeddings visualization W e used principal component analysis (PCA) to visual- ize embeddings of the relations of the w ordnet dataset (WN18). W e plotted the four first components of the best DistMult and ComplEx model’ s embeddings in Figure 4 . For the ComplEx model, we simply concatenated the real and imaginary parts of each embedding. Most of WN18 relations describe hierarchies, and are thus antisymmetric. Each of these hierarchic relations has its inv erse relation in the dataset. For example: hypernym / hyponym , part of / has part , synset domain topic of / member of domain topic . Since DistMult is unable to model antisymmetry , it will correctly represent the na- ture of each pair of opposite relations, b ut not the direction of the relations. Loosely speaking, in the hypernym / hyponym pair the nature is sharing semantics, and the direction is that one entity generalizes the semantics of the other . This makes DistMult reprensenting the opposite Complex Embeddings for Simple Link Pr ediction Figure 4. Plots of the first and second (T op), third and fourth (Bottom) components of the WN18 relations embeddings using PCA. Left: DistMult embeddings. Right: ComplEx embeddings. Opposite relations are clustered together by DistMult while correctly separated by ComplEx. relations with very close embeddings, as Figure 4 shows. It is especially striking for the third and fourth principal component (bottom-left). Conv ersely , ComplEx manages to oppose spatially the opposite relations.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment