Discovery and Visualization of Nonstationary Causal Models
It is commonplace to encounter nonstationary data, of which the underlying generating process may change over time or across domains. The nonstationarity presents both challenges and opportunities for causal discovery. In this paper we propose a prin…
Authors: Kun Zhang, Biwei Huang, Jiji Zhang
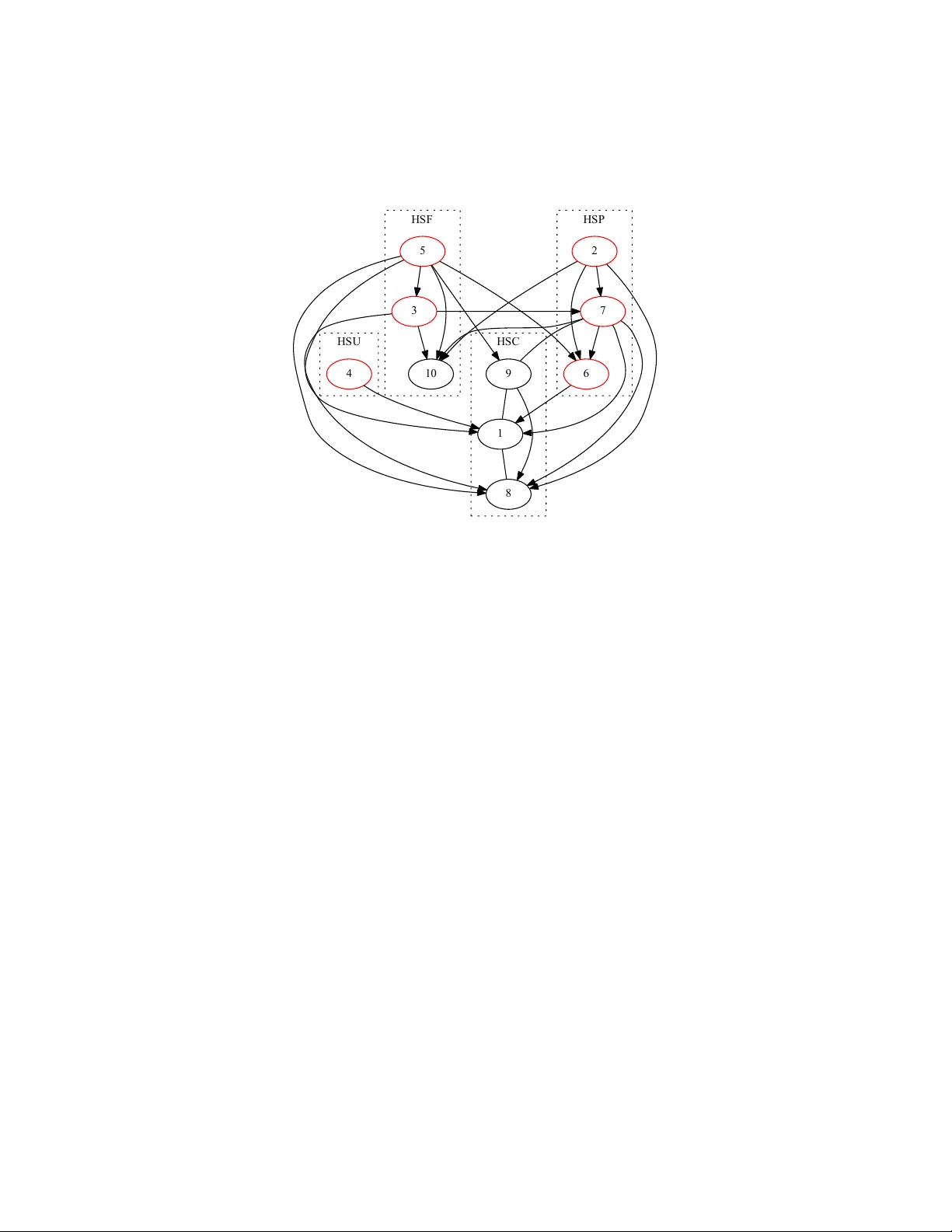
Disco v ery and Visualization of Nonstationary Causal Mo dels Kun Zhang ∗ 1,2 , Biw ei Huang † 1,2 , Jiji Zhang ‡ 3 , Bernhard Sc h¨ olk opf § 2 and Clark Glymour ¶ 1 1 Carnegie Mellon Univ ersity 2 MPI for In telligent Systems, T¨ ubingen, German y 3 Lingnan Univ ersity , Hong Kong Abstract It is commonplace to encoun ter nonstationary data, of which the un- derlying generating pro cess ma y change o ver time or across domains. The nonstationarit y presen ts b oth challenges and opportunities for causal dis- co very . In this pap er we prop ose a principled framework to handle non- stationarit y , and develop metho ds to address three imp ortan t questions. First, w e propose an enhanced constraint-based method to detect v ari- ables whose local mechanisms are nonstationary and reco ver the skeleton of the causal structure ov er observ ed v ariables. Second, w e present a w ay to determine some causal directions b y taking adv antage of information carried by changing distributions. Third, we develop a metho d for visu- alizing the nonstationarity of lo cal mechanisms. Exp erimen tal results on v arious synthetic and real-world datasets are presented to demonstrate the efficacy of our metho ds. 1 In tro duction In man y fields of empirical sciences and engineering, w e would like to obtain causal knowledge for many purp oses. As it is often difficult if not imp ossible to carry out randomized exp eriments, inferring causal relations from purely obser- v ational data, known as the task of causal disco very , has drawn muc h attention in sev eral fields including computer science, statistics, philosophy , economics, and neuroscience. With the rapid accumulation of h uge v olumes of data of v ar- ious types, causal discov ery is facing exciting opp ortunities but also great chal- lenges. One phenomenon such data often feature is that of distribution shift. Distribution shift ma y o ccur across domains or o ver time. F or an example of the ∗ kunz1@andrew.cmu.edu † biwei.h uang@tuebingen.mpg.de ‡ jijizhang@ln.edu.hk § bs@tuebingen.mpg.de ¶ cg09@andrew.cmu.edu 1 former kind, consider the problem of remote sensing image classification, whic h aims to derive land use and land cov er information through the pro cess of inter- preting and classifying remote sensing imagery . The data collected in different areas and at different times usually hav e different distributions due to different ph ysical factors related to ground, v egetation, illumination conditions, etc. As an example of the latter kind, the fMRI recordings are usually nonstationary: the causal connections in the brain may change with stimuli, tasks, states, the atten tion of the sub ject, etc. More sp ecifically , it is b elieved that one of the basic prop erties of the neural connections in the brain is its time-dep endence [1]. T o these situations many existing approac hes to causal disco very fail to apply , as they assume a fixed causal mo del and hence a fixed joint distribution underlying the observed data. In this pap er w e assume that the underlying causal structure is a directed acyclic graph (D AG), but the mechanisms or parameters asso ciated with the causal structure, or in other w ords the causal model, may c hange across domains or o ver time (we allow mechanisms to change in such a wa y that some causal links in the structure b ecome v acuous or v anish ov er some time p eriods or domains). W e aim to develop a principled framework to mo del such situations as well as practical metho ds to address these questions: • How to efficiently identify the v ariables whose lo cal causal mec hanisms are nonstationary and recov er the skeleton of the causal structure o ver the observed v ariables? • How to tak e adv antage of the information carried by distribution shifts for the purp ose of identifying causal directions? • How to visualize the nonstationarit y of those causal mec hanisms that c hange o ver time or across domain? This pap er is organized as follo ws. In Section 2 we define and motiv ate the problem in more detail and review related w ork. Section 3 prop oses an enhanced constrain t-based metho d for recov ering the skeleton of the causal structure ov er the observed v ariables and iden tify those v ariables whose generating pro cesses are nonstationary . Section 4 develops a metho d for determining some causal directions by exploiting nonstationarity . Section 5 proposes a wa y to visualize nonstationarit y . Section 6 reports sim ulations results to test the p erformance of the prop osed causal discov ery approac h when the ground truth is known. Finally , w e apply the metho d to some real-w orld datasets, including financial date and fMRI data, in Section 7. 2 Problem Definition and Related W ork 2.1 Causal Disco v ery of Fixed Causal Mo dels Most causal discov ery metho ds assume that there is a fixed causal mo del un- derlying the observed data and aim to estimate it from the data. Classic ap- 2 proac hes to causal disco v ery divide roughly in to tw o types. In late 1980’s and early 1990’s, it w as noted that under appropriate assumptions, one could reco v er a Marko v equiv alence class of the underlying causal structure based on condi- tional independence relationships among the v ariables [2, 3]. This giv es rise to the constrain t-based approach to causal disco very , and the resulting equiv- alence class ma y contain multiple D AGs (or other related graphical ob jects to represen t causal structures), which en tail the same conditional indep endence re- lationships. The required assumptions include the causal Marko v condition and the faithfulness assumption, which entail a corresp ondence b et ween separation prop erties in the underlying causal structure and statistical indep endence prop- erties in the data. The so-called score-based approach (see, e.g., [4, 5]) searches for the equiv alence class which gives the highest score under some scoring crite- rion, such as the Bay esian Information Criterion (BIC) or the p osterior of the graph given the data. Another set of approaches is based on restricted functional causal mo dels, whic h represent the effect as a function of the direct causes together with an in- dep enden t noise term [3]. Under appropriate assumptions, these approaches are able to identify the whole causal mo del. More sp ecifically , the causal direction implied b y the restricted functional causal model is generically identifiable, in that the model assumptions, such as the indep endence betw een the noise and cause, hold only for the true causal direction and are violated for the wrong di- rection. Examples of suc h restricted functional causal mo dels include the Linear, Non-Gaussian, Acyclic Mo del (LiNGAM [6]), the additive noise mo del [7, 8], and the p ost-nonlinear causal mo del [9]. The method presen ted in [10] makes use of a certain type of smo othness of the function in the correct causal direction to distinguish cause from effect, though it do es not giv e explicit identifiabilit y conditions. 2.2 With Nonstationary Causal Mo dels Supp ose we are working with a set of observ ed v ariables V = { V i } n i =1 and the underlying causal structure ov er V is represented b y a DA G G . F or each V i , let P A i denote the set of parents of V i in G . Supp ose at eac h p oin t in time or in eac h domain, the joint probability distribution of V factorizes according to G : P ( V ) = n Y i =1 P ( V i | P A i ) . (1) W e call each P ( V i | P A i ) a causal module. If there are distribution shifts (i.e., P ( V ) changes ov er time or across domains), at least some causal modules P ( V k | P A k ), k ∈ N must change. W e call those causal mo dules nonstationary c ausal mo dules . Their changes ma y b e due to changes of the in volv ed functional mo dels, causal strengths, noise levels, etc. W e assume that those quan tities that change ov er time or cross domains can b e written as functions of a time or domain index, and denote by C suc h an index. 3 V 1 V 2 V 3 V 4 g ( C ) V 1 V 2 V 3 V 4 (a) (b) Figure 1: An illustration on how ignoring changes in the causal mo del may lead to spurious connections by the constraint-based method. (a) The true causal graph (including confounder g ( C )). (b) The estimated conditional indep endence graph on the observ ed data in the asymptotic case. If the changes in some mo dules are related, one can treat the situation as if there exists some unobserved quantit y (confounder) whic h influences those mo dules and, as a consequence, the conditional indep endence relationships in the distribution-shifted data will be differen t from those implied by the true causal structure. Therefore, standard constrain t-based algorithms suc h as PC [2, 3] may not be able to rev eal the true causal structure. As an illustration, suppose that the observ ed data were generated according to Fig. 1(a), where g ( C ), a function of C , is in volv ed in the generating pro cesses for both V 2 and V 4 ; the conditional indep endence graph for the observed data then contains spurious connections V 1 − V 4 and V 2 − V 4 , as shown in Fig. 1(b), b ecause there is only one conditional indep endence relationship, V 3 ⊥ ⊥ V 1 | V 2 . −2 0 2 −2 −1 0 1 2 X 1 X 2 (b) on data set 2 −2 0 2 −2 −1 0 1 2 X 1 X 2 (c) on both data sets −2 0 2 −2 −1 0 1 2 X 1 X 2 (a) on data set 1 −2 0 2 −1 −0.5 0 0.5 1 X 1 ˆ E (d) on both data sets Figure 2: An illustration of a failure of using the approach based on functional causal mo dels for causal direction determination when the causal mo del changes. (a) Scatter plot of V 1 and V 2 on dataset 1. (b) That on dataset 2. (c) That on merged data (both datasets). (d) The scatter plot of V 1 and the estimated regression residual on merged data. Moreo ver, when one fits a fixed functional causal mo del (e.g., a linear, non- Gaussian mo del [6]) to distribution-shifted data, the estimated noise may not b e indep enden t from the cause any more. Consequen tly , the approac h based on restricted functional causal mo dels in general cannot infer the correct causal structure either. Fig. 2 gives an illustration of this point. Suppose w e ha ve t wo datasets for v ariables V 1 and V 2 : V 2 is generated from V 1 according to V 2 = 0 . 3 V 1 + E in the first and according to V 2 = 0 . 7 V 1 + E in the second, and in b oth datasets V 1 and E are m utually indep enden t and follow a uniform distribution. Fig. 2(a - c) show the scatter plots of V 1 and V 2 on dataset 1, on dataset 2, and on merged data, resp ectively . (d) then shows the scatter plot of V 1 , the cause, and the estimated regression residual on b oth datasets; they are not indep enden t any more, although on either dataset the regression residual is 4 indep enden t from V 1 . T o tackle the issue of c hanging causal mo dels, one ma y try to find causal mo dels on sliding windo ws [11] (for nonstationary data) or for differen t do- mains (for data from multiple domains) separately, and then compare them. Impro ved versions include the online changepoint detection metho d [12], the online undirected graph learning [13], the lo cally stationary structure track er algorithm [14]. Such metho ds may suffer from high estimation v ariance due to sample scarcity , large type I I errors, and a large n um b er of statistical tests. Some metho ds aim to estimate the time-v arying causal mo del by making use of certain types of smo othness of the change [15], but they do not explicitly lo cate the nonstationary causal mo dules. Several metho ds aim to mo del time-v arying time-dela yed causal relations [16, 17], whic h can b e reduced to online parameter learning because the direction of the causal relations is giv en (i.e., the past influ- ences the future). Compared to them, learning c hanging instan taneous causal relations, with which we are concerned in this pap er, is generally more difficult. Moreo ver, most of these metho ds assume linear causal models, limiting their applicabilit y to complex problems with nonlinear causal relations. In con trast, w e will dev elop a nonparametric and computationally efficient metho d that can identify nonstationary causal mo dules and recov er the causal sk eleton. W e will also sho w that distribution shifts actually contain useful infor- mation for the purp ose of determining causal directions and dev elop practical algorithms accordingly . 3 Enhanced Constrain t-Based Pro cedure 3.1 Assumptions As already mentioned, we allow changes in some causal mo dules to b e related, whic h ma y b e explained by p ositing unobserved confounders. Intuitiv ely , such confounders may refer to some high-level bac kground v ariables. F or instance, for fMRI data, they may b e the sub ject’s atten tion or unmeasured background stim uli impinging on a sub ject–scanner noise, random thoughts, physical sensa- tions, etc.; for the stock market, they may b e related to economic p olicies and c hanges in the ownership among the companies, etc. Thus we do not assume causal sufficiency for the set of observ ed v ariables. Ho wev er, we assume that the confounders, if an y , can be written as smo oth functions of time or domain index. It follows that at each time or in each domain, the v alues of these confounders are fixed. W e call this a we ak c ausal sufficiency assumption. Denote by { g l ( C ) } L l =1 the set of suc h confounders (whic h ma y b e empty). W e further assume that for eac h V i the local causal pro cess for V i can be represen ted b y the following structural equation mo del (SEM): V i = f i P A i , g i ( C ) , θ i ( C ) , i , (2) where g i ( C ) ⊆ { g l ( C ) } L l =1 denotes the set of confounders that influence V i , θ i ( C ) denotes the effective parameters in the mo del that are also assumed to b e 5 functions of C , and i is a disturbance term that is indep enden t of C and has a non-zero v ariance (i.e., the mo del is not deterministic). W e also assume that the ’s are m utually indep enden t. Note that { g l ( C ) } L l =1 are in tro duced to accoun t for changes in differen t causal mo dules that are not indep enden t. As a result, although θ i ( C ) may also con- tribute to a change in the causal mo dule for V i , c hanges to the mo dule for V i due to θ i ( C ) are indep endent of changes to the mo dule for V j due to θ j ( C ), i 6 = j . In other w ords, θ i ( C ) is specific to V i and is indep enden t of θ j ( C ) for i 6 = j . Note that g i ( C ) and θ i ( C ) can b e constant, corresp onding to stationary causal mo dules. In this pap er w e treat C as a random v ariable, and so there is a joint dis- tribution ov er V ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 . W e assume that this distribution is Marko v and faithful to the graph resulting from the following additions to G (whic h, recall, is the causal structure o ver V ): add { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 to G , and for each i , add an arro w from each v ariable in g i ( C ) to V i and add an arrow from θ i ( C ) to V i . W e will refer to this augmented graph as G aug . Ob viously G is simply the induced subgraph of G aug o ver V . 3.2 Detecting Changing Mo dules and Reco vering Causal Sk eleton In this section we prop ose a metho d to detect v ariables whose mo dules change and infer the skeleton of G . The basic idea is simple: we use the (observed) v ariable C as a surrogate for the unobserved V ∪ { g l ( C ) } L l =1 , or in other words, w e tak e C to capture C-sp e cific information. 1 W e now sho w that given the assumptions in 3.1, we can apply a constrain t-based algorithm to V ∪ { C } to detect v ariables with changing mo dules and recov er the sk eleton of G . Algorithm 1 Detection of Changing Mo dules and Reco very of Causal Skeleton 1. Build a complete undirected graph U C on the v ariable set V ∪ { C } . 2. ( Dete ction of changing mo dules ) F or ev ery i , test for the marginal and conditional indep endence betw een V i and C . If they are indep endent giv en a subset of { V k | k 6 = i } , remov e the edge b et ween V i and C in U C . 3. ( R e overy of c ausal skeleton ) F or every i 6 = j , test for the marginal and conditional indep endence b et ween V i and V j . If they are indep enden t giv en a subset of { V k | k 6 = i, k 6 = j } ∪ { C } , remov e the edge betw een V i and V j in U C . 1 Recall that C may simply be time. Thus in this paper we take time to be a sp ecial random v ariable which follows a uniform distribution ov er the considered time p eriod, with the corresp onding data points evenly sampled at a certain sampling frequency . W e realize that this view of time will invite philosophical questions, but for the purp ose of this pap er, we will set those questions aside. One can regard this stipulation as purely a formal device without substan tial implications on time p er se . 6 The pro cedure is briefly describ ed in Algorithm 1. It outputs an undirected graph, U C , that contains C as well as V . In Step 2, whether a v ariable V i has a c hanging module is decided by whether V i and C are independent conditional on some subset of other v ariables. The justification for one side of this decision is trivial. If V i ’s mo dule do es not change, that means P ( V i | P A i ) remains the same for ev ery v alue of C , and so V i ⊥ ⊥ C | P A i . Th us, if V i and C are not indep enden t conditional on any subset of other v ariables, V i ’s mo dule c hanges with C , which is represented by an edge betw een V i and C . Con versely , we assume that if V i ’s mo dule c hanges, which entails that V i and C are not indep enden t given P A i , then V i and C are not indep enden t giv en any other subset of V \{ V i } . If this assumption do es not hold, then w e only claim to detect some (but not necessarily all) v ariables with changing mo dules. Step 3 aims to disco ver the skeleton of the causal structure o ver V . Its (asymptotic) correctness is justified by the following theorem: Theorem 1. Given the assumptions made in Se ction 3.1, for every V i , V j ∈ V , V i and V j ar e not adjac ent in G if and only if they ar e indep endent c onditional on some subset of { V k | k 6 = i, k 6 = j } ∪ { C } . Pr o of. Before getting to the main argument, let us establish some implications of the SEMs Eq. 2 and the assumptions in Section 3.1. Since the structure is assumed to b e acyclic or recursive, according to Eq. 2, all v ariables V i can be written as a function of { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 and { m } n m =1 . As a conse- quence, the probabilit y distribution of V at eac h v alue of C is determined b y the distribution of 1 , ..., n , and the v alues of { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 . In other w ords, p ( V | C ) is determined by Q n i =1 p ( i ) (for 1 , ..., n are m utually in- dep enden t), and { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 , where p ( · ) denotes the probability densit y or mass function. F or any V i , V j , and V ij ⊆ { V k | k 6 = i, k 6 = j } , b ecause p ( V i , V j | V ij , C ) is determined b y p ( V | C ), it is also determined b y Q n i =1 p ( i ) and { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 . Since Q n i =1 p ( i ) do es not c hange with C , w e ha ve p ( V i , V j | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 ∪ { C } ) = p ( V i , V j | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 ) . (3) That is, C ⊥ ⊥ ( V i , V j ) | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 . (4) By the weak union prop ert y of conditional indep endence, it follows that C ⊥ ⊥ V j | { V i } ∪ V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 . (5) W e are now ready to prov e the theorem. Let V i , V j b e any t wo v ariables in V . First, supp ose that V i and V j are not adjacent in G . Then they are not adjacent in G aug , which recall is the graph that incorp orates { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 . It follows that there is a set V ij ⊆ { V k | k 6 = i, k 6 = j } such that V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 d-separates V i from V j . Since the joint 7 distribution ov er V ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 is assumed to b e Marko v to G aug , we hav e V i ⊥ ⊥ V j | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 . (6) Because all g l ( c ) and θ m ( C ) are deterministic functions of C , we hav e p ( V i , V j | V ij ∪ { C } ) = p ( V i , V j | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 ∪ { C } ). According to [18] , Eqs. 6 and 4 imply V i ⊥ ⊥ ( C , V j ) | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 . By the w eak union property of conditional independence, it fol- lo ws that V i ⊥ ⊥ V j | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 ∪ { C } . As all g l ( C ) and θ m ( C ) are deterministic functions of C , it follows that V i ⊥ ⊥ V j | V ij ∪ { C } . In other words, V i and V j are conditionally indep enden t given a subset of { V k | k 6 = i, k 6 = j } ∪ { C } . Con versely , supp ose V i and V j are conditionally indep enden t given a subset S of { V k | k 6 = i, k 6 = j } ∪ { C } . W e show that V i and V j are not adjacent in G , or equiv alen tly , that they are not adjacent in G aug . There are tw o p ossible cases to consider: • Supp ose S does not contain C . Then since the join t distribution ov er V ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 is assumed to b e F aithful to G aug , V i and V j are not adjacent in G aug , and hence not adjacent in G . • Otherwise, S = V ij ∪ { C } for some V ij ⊆ { V k | k 6 = i, k 6 = j } . That is, V i ⊥ ⊥ V j | V ij ∪ { C } , or (7) p ( V i , V j | V ij ∪ { C } ) = p ( V i | V ij ∪ { C } ) p ( V j | V ij ∪ { C } ) . According to Eq. 3, and also noting that { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 is a deterministic function of C , we hav e p ( V i , V j | V ij ∪ { C } ) = p ( V i , V j | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 ) , (8) whic h also implies p ( V i | V ij ∪ { C } ) = p ( V i | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 ) , (9) p ( V j | V ij ∪ { C } ) = p ( V j | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 ) . (10) Substituting Eqs. 8 - 10 into Eq. 7 gives p ( V i , V j | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 ) (11) = p ( V i | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 ) p ( V j | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 ) . That is, V i ⊥ ⊥ V j | V ij ∪ { g l ( C ) } L l =1 ∪ { θ m ( C ) } n m =1 . Again, by the F aithfulness assumption on G aug , this implies that V i and V j are not adjacent in G aug and hence are not adjacent in G . 8 Therefore, V i are V j are not adjacen t in G if and only if they are conditionally indep enden t given some subset of { V k | k 6 = i, k 6 = j } ∪ { C } . In the ab ov e pro cedure, it is crucial to use a general, nonparametric condi- tional indep endence test, for how v ariables dep end on C is unk own and usually v ery nonlinear. In this work, we use the kernel-based conditional indep endence test (KCI-test [19]) to capture the dep endence on C in a nonparametric wa y . By contrast, if we use, for example, tests of v anishing partial correlations, as is widely used in the neuroscience communit y , the prop osed metho d will not work w ell. 4 An Adv an tage of Nonstationarit y in Determi- nation of Causal Direction W e no w show that using the additional v ariable C as a surrogate not only allo ws us to infer the sk eleton of the causal structure, but also facilitates the determination of some causal directions. Let us call those v ariables that are adjacen t to C in the output of Algorithm 1 “ C -specific v ariables”, which are actually the effects of nonstationary causal mo dules. F or each C -sp ecific v ariable V k , it is p ossible to determine the direction of every edge inciden t to V k , or in other words, it is p ossible to infer P A k . Let V l b e any v ariable adjacent to V k in the output of Algorithm 1. There are tw o p ossible cases to consider: 1. V l is not adjacen t to C . Then C − V k − V l forms an unshielded triple in the skeleton. F or practical purp oses, we can take the direction b et ween C and V k as C → V k (though we do not claim C to b e a cause in any substan tial sense). Then w e can use the standard orientation rules for unshielded triples to orient the edge b et ween V k and V l [2, 3]: if V l and C are indep enden t given a set of v ariables excluding V k , then the triple is a V-structure, and we hav e V k ← V l . Otherwise, if V l and C are independent giv en a set of v ariables including V k , then the triple is not a V-structure, and we hav e V k → V l . 2. V l is also adjacent to C . This case is more complex than Case 1, but it is still p ossible to iden tify the causal direction b et ween V k and V l , based on the principle that P ( cause ) and P ( effect | cause ) change independently; a heuristic metho d is given in Section 4.1. The procedure in Case 1 contains the metho ds proposed in [20, 21] for causal disco very from changes as special cases, whic h ma y also be in terpreted as sp ecial cases of the principle underlying the metho d for Case 2: if one of P ( cause ) and P ( effect | cause ) changes while the other remains inv ariant, they are clearly indep enden t. 9 4.1 Inference of the Causal Direction b etw een V ariables with Changing Mo dules W e no w develop a heuristic metho d to deal with Case 2 ab o ve. F or simplicity , let us start with the tw o v ariable case: suppose V 1 and V 2 are adjacent and are b oth adjacen t to C (and not adjacent to an y other v ariable). W e aim to identify the causal direction b et ween them, whic h, without loss of generalit y , we supp ose to b e V 1 → V 2 . The guiding idea is that nonstationarity may carry information that confirms “independence” of causal modules, whic h, in the simple case w e are considering, is the “indep endence” b et ween P ( V 1 ) and P ( V 2 | V 1 ). If P ( V 1 ) and P ( V 2 | V 1 ) are “indep enden t” but P ( V 2 ) and P ( V 1 | V 2 ) are not, then the causal direction is inferred to be from V 1 to V 2 . The idea that causal modules are “indep enden t” is not new, but in a stationary situation where each mo dule is fixed, such independence is very difficult, if not imp ossible, to test. By contrast, in the situation w e are considering presently , both P ( V 1 ) and P ( V 2 | V 1 ) are nonstationary , and w e can try to measure the extent to which v ariation in P ( V 1 ) and v ariation in P ( V 2 ) are dependent (and similarly for P ( V 2 ) and P ( V 1 | V 2 )). This is the sense in which nonstationarit y actually helps in the inference of causal directions, and as far as we kno w, this is the first time that suc h an adv an tage is exploited in the case where b oth P ( cause ) and P ( effect | cause ) c hange. W e now derive a metho d along this line. Note that although b oth of V 1 and V 2 are adjacen t to C , there do es not necessarily exist a confounder. Fig. 3(a) sho ws the case where the inv olv ed c hanging parameters, θ 1 ( C ) and θ 2 ( C ) are in- dep enden t, i.e., P ( V 1; θ 1 ) and P ( V 2 | V 1 ; θ 2 ) change indep enden tly . (W e dropp ed the argument C in θ 1 and θ 2 to simplify notations.) V 1 V 2 θ 1 ( C ) θ 2 ( C ) V 1 V 2 θ 1 ( C ) θ 2 ( C ) g 1 ( C ) (a) (b) Figure 3: Two p ossible situations where V 1 → V 2 and b oth V 1 and V 2 are adjacen t to C . (a) θ 1 ( C ) ⊥ ⊥ θ 2 ( C ). (b) In addition to the changing parameters, there is a confounder g 1 ( C ) underlying V 1 and V 2 . F or the rev erse direction, one can decompose the join t distribution of ( V 1 , V 2 ) according to P ( V 1 , V 2 ; θ 0 1 , θ 0 2 ) = P ( V 2 ; θ 0 2 ) P ( V 1 | V 2 ; θ 0 1 ) , (12) where θ 0 1 and θ 0 2 are assumed to b e sufficient for the corresp onding distribution terms. Generally sp eaking, θ 0 1 and θ 0 2 are not indep enden t, b ecause they are determined jointly by b oth θ 1 and θ 2 . W e assume that this is the case, and iden tify the direction b et ween V 1 and V 2 based on this assumption. 10 No w we face tw o problems. First, how can we compare the dep endence b et w een θ 1 and θ 2 and that b et ween b etw een θ 0 1 and θ 0 2 ? Second, in our non- parametric setting, we do not really ha ve such parameters. How can w e compare the dep endence bas ed on the given data? F or the first problem, we make use of the follo wing measures of contributions from the parameters. The total contribution (in a wa y analogous to causal effect; see [22]) from θ 0 1 and θ 0 2 to ( V 1 , V 2 ) can b e measured with mutual information: S ( θ 0 1 ,θ 0 2 ) → ( V 1 ,V 2 ) = I ( θ 0 1 , θ 0 2 ); ( V 1 , V 2 ) = I ( θ 0 2 ; V 2 ) + I ( θ 0 1 ; V 1 | V 2 ) + I ( θ 0 2 ; V 1 | θ 0 1 , V 2 ) = I ( θ 0 2 ; V 2 ) + I ( θ 0 1 ; V 1 | V 2 ) , (13) where the second equalit y holds b ecause of the c hain rule, and the last one b ecause the sufficiency of θ 0 1 for P ( V 1 | V 2 ; θ 0 1 ) implies θ 0 2 ⊥ ⊥ V 1 | θ 0 1 , V 2 . Eq. 13 in volv es the regular mutual information and conditional mutual information. Since θ 0 1 and θ 0 2 are dep enden t, their individual contributions to ( V 1 , V 2 ) are redundan t. Belo w w e calculate the individual con tributions. The con tribution from θ 0 2 to V 2 is S θ 0 2 → V 2 = I ( θ 0 2 ; V 2 ) . The contribution from θ 0 1 to V 1 has been deriv ed in [22]: S θ 0 1 → V 1 = E h log P ( V 1 | V 2 ,θ 0 1 ) R P ( V 1 | V 2 , ˜ θ 0 1 ) P ( ˜ θ 0 1 )d ˜ θ 0 1 i , where ˜ θ 0 1 is an indepen- den t copy of θ 0 1 . As a consequence, the redundancy in the contributions from θ 0 1 and θ 0 2 is ∆ V 2 → V 1 = S θ 0 2 → V 2 + S θ 0 1 → V 1 − S ( θ 0 1 ,θ 0 2 ) → ( V 1 ,V 2 ) = E h log P ( V 1 | V 2 ) R P ( V 1 | V 2 , ˜ θ 0 1 ) P ( ˜ θ 0 1 )d ˜ θ 0 1 i = E h log P ( V 1 | V 2 ) E ˜ θ 0 1 P ( V 1 | V 2 , ˜ θ 0 1 ) i . ∆ V 2 → V 1 is alw ays non-negativ e b ecause it is a Kullbac k-Leibler divergence. One can verify that if θ 0 1 ⊥ ⊥ θ 0 2 , which implies θ 0 1 ⊥ ⊥ V 2 , we hav e R P ( V 1 | V 2 , ˜ θ 0 1 ) P ( ˜ θ 0 1 )d ˜ θ 0 1 = R P ( V 1 | V 2 , ˜ θ 0 1 ) P ( ˜ θ 0 1 | V 2 )d ˜ θ 0 1 = P ( V 1 | V 2 ), leading to ∆ V 2 → V 1 = 0. ∆ V 2 → V 1 pro vides a wa y to measure the dep endence b et ween θ 0 1 and θ 0 2 . Re- garding the second problem mentioned ab o ve, since we do not hav e parametric mo dels, we prop ose to estimate ∆ V 2 → V 1 from the data b y: ˆ ∆ V 2 → V 1 = D log ¯ P ( V 1 | V 2 ) h ˆ P ( V 1 | V 2 ) i E , (14) where h·i denotes the sample a verage, ¯ P ( V 1 | V 2 ) is the empirical estimate of P ( V 1 | V 2 ) on all data p oin ts, and h ˆ P ( V 1 | V 2 ) i denotes the sample av erage of ˆ P ( V 1 | V 2 ), the estimate of P ( V 1 | V 2 ) at each time (or in eac h domain). In our implemen tation, we used kernel density estimation (KDE) on all data p oin ts to estimate ¯ P ( V 1 | V 2 ), and used KDE on sliding windows (or in each domain) to estimate ˆ P ( V 1 | V 2 ). W e tak e the direction for whic h ˆ ∆ is smaller to be the causal direction. If there is a confounder g 1 ( C ) underlying V 1 and V 2 , as shown in Fig. 3(b), w e conjecture that the ab o ve approac h still works if the influences from g 1 ( C ) is 11 not very strong, for the following reason: for the correct direction, ˆ ∆ measures the influence from the confounder; for the wrong direction, it measures the influence from the confounder and the dep endence in the “parameters” caused b y the wrong causal direction. A future line of research is to seek a more rigorous theoretical justification of this metho d. When there are more than t wo v ariables which are connected to C and inter-connected, we try all p ossible causal structures and choose the one that minimizes the total ˆ ∆ v alue, i.e., P i : P A i 6 = ∅ ˆ ∆ P A i → V i . 5 Kernel Nonstationarit y Visualization of Causal Mo dules It is informative to determine for which v ariable the causal mo del (data-generating pro cess), or P ( V i | P A i ), c hanges. But usually it is not enough – one often wan ts to interpret the pattern of the changes, find what causes the changes, and un- derstand the causal pro cess in more detail. T o achiev e so, it is necessary to disco ver how the causal model changes, i.e., where the c hanges o ccur and how fast it c hanges, and visualize the c hanges. Although the changes occur in the conditional distribution P ( V i | P A i ), usually it is not straightforw ard to see the prop erties of the changes by directly lo oking at the distribution itself. A low- dimensional representation of the changes is needed. In the parametric case, if we know which parameters of the causal mo del P A i → V i are changing, whic h could be the mean of a ro ot cause, the co efficien ts in a linear SEM, etc., then we can estimate such parameters for different v alues of C and see how they change. Ho wev er, such knowledge is usually not av ailable, and more imp ortan tly , for the sake of flexibilit y we often mo del the causal pro cesses nonparametrically . Therefore, it is desirable to develop a general nonparametric procedure for nonstationarit y visualization of c hanging causal mo dules. Note that c hanges in P ( V i | P A i ) are irrelev an t to changes in P ( P A i ), and accordingly , they are not necessarily the same as c hanges in the joint distribution P ( V i , P A i ). (If V i is a ro ot cause, P A i is an empty set, and P ( V i | P A i ) reduces to the marginal distribution P ( V i ).) W e aim to find a mapping of P ( V i | P A i ) whic h captures its nonstationarity: λ i ( C ) = h i ( P ( V i | P A i , C )) . (15) W e call λ i ( C ) the nonstationarit y encapsulator for P ( V i | P A i , C ). This for- m ulation is rather general: any identifiable parameters in P ( V i | P A i , C ) can b e expressed this w ay , and in the nonparametric case, λ i ( C ) can b e seen as a statistic to summarize c hanges in P ( V i | P A i , C ) along with C . If P ( V i | P A i , C ) do es not change along with C , then λ i ( C ) remains constant. Otherwise, λ i ( C ) is intended to capture the v ariabilit y of P ( V i | P A i , C ) across differen t v alues of C . No w there are t wo problems to solv e. One is giv en only observed data, not the conditional distribution, how to represent λ i ( C ) in Eq. 15 conv eniently . 12 The other is what criterion and metho d to use to enable λ i ( C ) to capture the v ariabilit y in the conditional distribution along with C . W e tackle the ab o ve t wo problems by making use of kernels [23], and accordingly prop ose a metho d called kernel nonstationarity visualization (KNV) of causal mo dules. 5.1 Using Kernel Embedding of Conditional Probabilities W e use the kernel embedding of conditional distributions [24] instead of the original conditional distributions. Suppose we hav e kernels k (1) X and k (1) Y for v ariables X and Y , with the corresp onding Repro ducing Kernel Hilb ert Spaces (RKHS) H (1) X and H (1) Y , resp ectiv ely . Given conditional distribution P ( Y | X ), its kernel em b edding can b e seen as an op erator mapping from H (1) X to H (1) Y , defined as U Y | X = C Y X C − 1 X X , where C Y X and C X X denote the (uncentered) cross- co v ariance and cov ariance operators, resp ectiv ely [25]. The empirical estimate of U Y | X is ˆ U Y | X = Ψ Y ( K X + β I ) − 1 Ψ | X , where β is a regularization parameter (set to 0.05 in our exp erimen ts), and Ψ Y , Ψ X , and K X are the feature matrix on Y , feature matrix on X , and the k ernel matrix on X , resp ectiv ely [24]. W e use the Gaussian kernel for k (1) X and k (1) Y with kernel width σ 1 , and ˆ U Y | X enco des the information of P ( Y | X ) on the given data. In our problem, we need consider the kernel conditional distribution embed- ding of P ( V i | P A i ) for e ach value of C . If C is a domain index, for each v alue of C we hav e a dataset of ( V i | P A i ). If C is a time index, we use a sliding window to find the data corresponding to C = c , by using the data of ( V i , P A i ) in the windo w of length L centered at c . As w e shall see later, It is possible to av oid directly calculating the empirical estimate of the em b edding, but w e need the follo wing (“cross”) kernel (or Gram) matrices: K V i ( c, c 0 ) is the “cross” kernel matrix b et w een the v alues of V i corresp onding to C = c and those corresp onding to C = c 0 , and similarly for K P A i ( c, c 0 ). 5.2 Nonstationary Encapsulator Extraction by Eigen v alue Decomp osition Next, in principle, we use the estimated kernel embedding of conditional distri- butions, ˆ U V i | P A i ,C = c , as input, and aim to find ˆ λ i ( c ) as a (nonlinear) mapping of ˆ U V i | P A i ,C = c , to capture its v ariabilit y across differen t c . This can be read- ily achiev ed by exploiting some nonlinear principle comp onen t analysis (PCA) tec hniques, and here we adopted k ernel principal comp onen t analysis problem (KPCA) [26], for its nice form ulation and computational efficiency . KPCA computes principal comp onen ts in high-dimensional feature spaces of the in- put. In our case, for each c the input, ˆ U V i | P A i ,C = c , is a matrix. W e can stac k it into a long vector, and then represent ˆ λ i ( c ) by making use of a sec- ond kernel, k (2) (whic h is usually differen t from k (1) ), as required b y KPCA. Denote by the corresp onding Gram matrix by M , whose ( c, c 0 )th entry is, M ( c, c 0 ) , k (2) ˆ U V i | P A i ,C = c , ˆ U V i | P A i ,C = c 0 . Calculating ˆ U V i | P A i ,C = c in volv es 13 the empirical k ernel maps of V i and P A i ; below we show that w e can directly find M without explicitly making use of empirical kernel maps. If we use a linear kernel for k (2) , the ( c, c 0 )th entry of M is 2 M l ( c, c 0 ) = T r ˆ U | V i | P A i ,C = c ˆ U V i | P A i ,C = c 0 =T r Ψ P A i ( c ) K P A i ( c, c ) + β I − 1 Ψ | V i ( c ) Ψ V i ( c 0 ) K P A i ( c 0 , c 0 ) + β I − 1 Ψ P A i ( c 0 ) =T r K V i ( c 0 , c ) K P A i ( c, c ) + β I − 1 K P A i ( c, c 0 ) K P A i ( c 0 , c 0 ) + β I − 1 . (16) If k (2) is a Gaussian k ernel with kernel width σ 2 , we hav e M G ( c, c 0 ) = exp − || ˆ U V i | P A i ( c ) − ˆ U V i | P A i ( c 0 ) || 2 F 2 σ 2 2 = exp − M l ( c, c ) + M l ( c 0 , c 0 ) − 2 M l ( c 0 , c ) 2 σ 2 2 , (17) where || · || F denotes the F rob enius norm. Finally , ˆ λ i ( C ) can b e found by p erforming eigenv alue decomp osition on the ab o v e Gram matrix, M l or M g ; for details please see [26]. Algorithm 2 summa- rizes the prop osed KNR metho d. There are several hyperparameters to set. In our exp erimen ts, w e set the kernel width σ 2 1 (for k (1) ) and σ 2 2 (for k (2) ) to the median distance b et ween p oin ts in the sample, as in [27]. W e kept the window length L = 100. Algorithm 2 KNV of Causal Mo dels 1. F or p ossible v alues c and c 0 , calculate K V i ( c, c 0 ) and K P A i ( c, c 0 ) with kernel k (1) . If C is a time index, they can b e obtained by extracting corresp onding en tries of the kernel matrices K V i and K P A i on the whole data. 2. Calculate Gram matrix M with kernel k (2) (see Eq. 16 for linear k ernels and Eq. 17 for Gaussian kernels). 3. Find ˆ λ i ( C ) by directly feeding Gram matrix M to KPCA. That is, p erform eigen v alue decomp osition on M to find the nonlinear principal comp onen ts ˆ λ i ( C ), as in Section 4.1 of [26]. 2 When P A i is an empty set, P ( V i | P A i ) reduces to P ( V i ). In this case we use the em- bedding of P ( V i ), µ V i , E P ( V i ) [ ψ ( V i )], whose empirical estimate is the sample mean of ψ ( V i ) on the sample. Here ψ ( · ) denotes the feature map. Accordingly , M l ( c, c 0 ) reduces to 1 n c n c 0 1 | n c 0 K V i ( c 0 , c ) 1 n c , where n c and n c 0 are the sizes of the data corresp onding to C = c and C = c 0 , respectively , and 1 n c is the vector of 1’s of length n c . 14 6 Exp erimen tal Results on Sim ulated Data 6.1 A T oy Example W e generated syn thetic data according to the SEMs sp ecified in Fig. 4. More sp ecifically , the exogenous input to V 1 , the causal strength from V 3 to V 5 (the co efficien t f 3 in the structural equation for V 5 ), and the noise v ariance in the equation for V 4 are time v arying; the changing parameters w ere represented b y sin usoid or cosine functions of T . W e used different p eriodic lev els ( w = 5 , 10 , 20 , 30) of the v arying comp onents, as well as different sample sizes ( N = 600 , 1000). In eac h setting, w e run 10 replications, with b oth our enhanced constrain t-based metho d (Algorithm 1, with the time index for C ) and the original constrain t-based metho d; we used the SGS searc h pro cedure [28] and k ernel-based conditional indep endence test [19]. V 1 = f 1 · E 0 + E 1 , V 2 = sin( V 2 1 ) − 0 . 2 V 1 + E 2 , V 3 = 0 . 5cos( V 1 ) + E 3 , V 4 = sin( V 2 + V 3 ) + 0 . 2 V 2 + f 2 · E 4 , V 5 = f 3 · tanh( V 3 ) + 0 . 2 V 3 + E 5 , V 6 = 0 . 5( V 2 + V 5 ) + E 6 . f 1 = sin( w · t N ) f 2 = 0 . 8sin( w · ( t N + 1 2 )) , f 3 = 1 . 5cos( w · ( t N + 1 2 )) , with t = 1 , · · · , N . e 0 ∼ U [0 , 1] , e i ∼ U [ − 0 . 3 , 0 . 3] , with i = 1 , · · · , 6 . Figure 4: The SEMs according to whic h we generated the simulated data. The input to V 1 , the noise v ariance to V 4 , and the causal strength from V 3 to V 5 are time v arying, represen ted b y f 1 , f 2 and f 3 , respectively . W e tried different w , and different sample sizes N . w 5 10 20 30 FP rate 0 0.1 0.2 0.3 0.4 0.5 5 10 20 30 FN rate 0 0.1 0.2 0.3 0.4 0.5 Enhanced, 600 Original, 600 Enhanced, 1000 Original, 1000 Figure 5: The estimated FP rate and FN rate with w = 5 , 10 , 20 , 30 and N = 600 , 1000 b y both our enhanced constraint-based metho d and the orig- inal constraint-based metho d. Fig. 5 shows the F alse Positiv e (FP) rate and the F alse Negative (FN) rate 15 of the discov ered adjacencies b et ween the V ’s at significance level 0 . 05. It is ob vious that compared to the original metho d, our method effectiv ely reduces the num b er of spurious connections, i.e., edges ( V 1 , V 4 ), ( V 1 , V 5 ) and ( V 4 , V 5 ), in all the settings. The FN rate only very slightly increases. As w increases, the FP rate stays stable, and the FN rate sligh tly increases for both metho ds; as N increases, the FN rate is greatly reduced. In addition, from the augmented causal graph, we can identify causal directions by the pro cedure in Section 4. In this simulation, the whole causal DA G is correctly identified. How ev er, with the original SGS metho d, we can only identify tw o causal directions: 5 → 6 and 2 → 6, and there are spurious edges ( V 1 , V 4 ), ( V 1 , V 5 ) and ( V 4 , V 5 ). F urthermore, we visualized the nonstationarit y of causal modules, P ( V 1 ), ( V 2 , V 3) → V 4 , and V 3 → V 5 , by KNV (Algorithm 2). W e tried b oth the linear kernel and Gaussian kernel for k (2) . Figure 6 shows the first component of the extracted nonstationarity encapsulators ˆ λ i , i = 1 , 4 , 5, corresp onding to the three nonstationary causal mo dels; see the blue solid lines. Panels (a) and (b) corresp ond to the setting w = 5 , N = 600 and w = 30 , N = 600, resp ectiv ely . The red dashed lines show the changing parameters f 1 , f 2 , and f 3 in the resp ectiv e causal mo dels. Note that they ha v e b een rescaled to match with the nonstationarity encapsulators ˆ λ i . W e can see that KNV successfully recov ers the v ariability in the causal mo dels (as represented by changing parameters f 1 , f 2 , f 3 , corresp onding to c hanges in the causal strength or noise v ariance). In addition, the Gaussian kernel gives better results esp ecially in the case where w = 30. f 1 -2 0 2 Linear Kernel -2 0 2 Gaussian Kernel f 2 -2 0 2 -2 0 2 0 200 400 600 f 3 -2 0 2 0 200 400 600 -2 0 2 (a) f 1 -1 0 1 Linear Kernel -1 0 1 Gaussian Kernel f 2 -4 0 4 0 200 400 600 f 3 -2 0 2 0 200 400 600 -2 0 2 -2 0 2 (b) Figure 6: The estimated nonstationarity encapsulators giv en by KNV and the corresp onding changing parameters f 1 , f 2 , and f 3 in causal mo dels P ( V 1 ), ( V 2 , V 3) → V 4 , and V 3 → V 5 , tested on b oth linear kernel and Gaussian k ernel for k 2 in KNV. The blue solid line represents the recov ered signal, while the red dashed line represents the true signal. (a) F or the setting w = 5 and N = 600. (b) w = 30 and N = 600. T o summarize, we found that when there is only one changing parameter in the causal mo del P ( V i | P A i ), whic h may b e the linear co efficien t, the mean of the noise, or its v ariance, with the Gaussian k ernel for k (2) , one component of λ i ( C ) is usually enough to capture the changes – this comp onen t is close to a nonlinear transformation of the changing parameter, and its corresp onding 16 eigen v alue is at least five times bigger than the remaining ones. How ever, if the functional form of the causal model changes, say , if the SEM changes from a linear one to a quadratic one, more than one comp onen t of λ i ( C ) has relatively large eigenv alues, and they join tly capture the change in P ( V i | P A i ) (results are not included here). 6.2 Exp erimen tal Results on Sim ulated fMRI In recent years the brain effectiv e connectivit y study from fMRI has received m uch attention. The fMRI exp eriments ma y last for a relatively long time p eriod, during which the causal influences are likely to change along with certain unmeasured states (e.g., the attention) of the sub ject and ignoring the time- dep endence may lead to spurious connections. Likewise, the causal influences ma y also v ary as a function of the exp erimental condition (e.g., health, disease, and b eha vior) [11]. Curren tly little is known for the causal connectivity in our brain, so firstly w e applied our approach on simulated fMRI data which enables us to ev aluate the robustness of our approac h with known ground truth. W e generated the sim ulated fMRI signal according to the DCM forward mo del [29]. Fig. 7 sho ws a basic setting of the netw ork top ologies, where w e mo deled the external input u 1 to the no des as random square w a ve [30], and the exter- nal input to the connections with different kinds of functions, e.g., exp onen tial deca y , square w av e, and log functions. Since the study on ho w causal connec- tions b et ween brain regions are c hanging is v ery limited, w e tried to represent them with different functions to mo del different p ossible scenarios. In addition, in practice we may analyze the fMRI signal concatenated from differen t scans (differen t sub jects or different instruments), so in order to mo del this situation, w e concatenated tw o generated BOLD signals to derive the final signal. V 1 V 2 V 3 V 4 V 5 u 1 u 2 u 3 u 4 u 5 Figure 7: The basic setting of the netw ork top ologies. W e tested our enhanced constraint-based metho d on 50 realizations, where the time information T is included in to the system to capture smooth v arying causal relations and the influences from smo oth v arying laten t confounders. Fig. 8(a) gives the F alse Positiv e (FP) rate and F alse Negative (FN) rate at signif- icance level 0.03. W e compared our enhanced constrain t-based metho d with the original one (b oth with SGS search and KCI test), and we also compared with partial correlation test since it is widely used in fMRI analysis [30]. It is ob vious that our approach greatly reduces the FP rate, that is, it effectiv ely re- duces spurious connections which are induced by the time-v arying connections, while at the same time increases the FN rate in a reasonable range. The partial correlation test giv es the worst results, with the FP rate 1 and the FN rate 0.1016 in a small-sample-size case. Since there is a certain amount of v ariation across realizations, w e give a causal connection if it exists in more than 80% 17 of all the realizations. Fig. 8(b-c) show the causal structures estimated by our approac h and the original constraint-based metho d with KCI-test. The partial correlation test pro duces fully connected graph. N=600 N=1000 FP rate 0 0.2 1 0.6 0.8 1 N=600 N=1000 FN rate 0 0.05 0.1 0.15 Enhanced Original Parial Corr. (a) Estimation error. V 1 V 2 V 3 V 4 V 5 (b) Estimated causal graph by the enhanced metho d V 1 V 2 V 3 V 4 V 5 (c) Estimated graph b y the original metho d Figure 8: (a) The estimation error, FP rate and FN rate, deriv ed from our enhanced constraint-based metho d, the original constraint-based metho d with K CI and the partial correlation test. (b,c) The estimated causal graph by the our approach and the original constraint-based one. 7 Exp erimen ts on Real Data 7.1 On Sto c k Returns W e applied our metho d to daily returns of 10 ma jor sto c ks in Hong Kong. The dataset is from the Y aho o finance database, containing daily dividend/split ad- justed closing prices from 10/09/2006 to 08/09/2010. F or the few days when the sto c k price is not av ailable, a simple linear in terp olation is used to estimate the price. Denoting the closing price of the i th sto c k on day t by P i,t , the corresp onding return is calculated by V i,t = P i,t − P i,t − 1 P i,t − 1 . The 10 sto c ks are Che- ung Kong Holdings (1), Wharf (Holdings) Limited (2), HSBC Holdings plc (3), Hong Kong Electric Holdings Limited (4), Hang Seng Bank Ltd (5), Hender- son Land Developmen t Co. Limited (6), Sun Hung Kai Prop erties Limited (7), Swire Group (8), Cathay Pacific Airw a ys Ltd (9) and Bank of China Hong Kong (Holdings) Ltd (10). 3 , 5 and 10 belong to Hang Seng Finance Sub-index (HSF), 1 , 8 and 9 b elong to Hang Seng Commerce & Industry Sub-index (HSC), 2 , 6 and 7 b elong to Hang Seng Prop erties Sub-index (HSP) and 4 b elongs to Hang 18 H S C H S U H S P H S F 3 1 0 7 8 5 6 1 9 2 4 Figure 9: The estimated causal structure among the 10 sto c k returns. Red cycles indicate that the corresponding sto c k returns are time-dep enden t. Our enhanced constraint-based metho d eliminated the edges for pairs (2,3), (5,7), (3,6) and (6,8), compared to the results by original SGS. Seng Utilities Sub-index (HSU). It is b eliev ed that during the financial crisis around 2008, the causal relations in Hong Kong sto c k mark et hav e changed. Fig. 9 sho ws the estimated causal structure b y our method, where 2 , 3 , 4 , 5 , 6 and 7 are found to b e time-dep endent as indicated by red cycles. In contrast, the original constrain t-based metho d produces four more edges, which are (2,3), (3,6), (5,7) and (6,8). W e found that all time-dep endent returns are in HSF, HSP , and HSU, which are directly affected by some unconsidered factors, e.g. p olicy c hanges. F urthermore, we inferred the causal directions b y the pro cedure giv en in Section 4, and we found that all the inferred directions are reasonable. In particular, the within sub-index causal directions tend to satisfy the owner- mem b er relationship. F or example, 4 → 1 b ecause 1 partially o wns 4, and similarly for 5 → 3 and 9 → 8. Those sto c ks in HSF are the ma jor causes to those in HSC and in HSP , and the sto cks in HSP and HSU impact those in HSC. These causal relations match with the fact that financial institutions are in the leading p osition to impact other fields, and industries are usually affected by financial institutions, companies in prop erties, and companies in utilities. One exception is that, 10, Bank of China Hong Kong in HSF, is affected by 2 in HSP; it is p erhaps b ecause of Bank of China Hong Kong’s close relation with Bank of China in mainland China. Figure 10 (bottom panels) visualizes the nonstationarit y of (c hanging) causal mo dules, for sto c ks 2 , 3 , 4 , 5 , 6, and 7. W e can see that the nonstationary en- 19 10/09/06 08/09/10 2 -5 0 5 3 -2 0 2 4 -5 0 5 7 -2 -1 0 1 10/09/06 T 1 T 2 T 3 08/09/10 5 -5 0 5 10/09/06 T 1 T 2 T 3 08/09/10 6 -1 0 1 Figure 10: The visualized nonstationarit y of causal mo dules of time-dep enden t sto c k returns as w ell as the curve of the TED spread ov er the same p eriod. T op: Curv e of the TED spread shown for comparison. Bottom: Visualized nonstationarit y of causal mo dules for stocks 2 , 3 , 4 , 5 , 6, and 7, where T 1 , T 2 , and T 3 stand for 07 / 16 / 2007, 06 / 30 / 2008, and 02 / 11 / 2009, resp ectiv ely . W e can see that the nonstationary comp onen ts of ro ot causes, 2 , 4, and 5, share the similar v ariability with c hange p oin ts around T 1 , T 2 , and T 3 . The nonstationary comp onen ts of 3, 6, and 7 ha ve change p oin ts only around T 2 and T 3 . capsulators of ro ot causes, 2 , 4, and 5, share a similar v ariability; the change p oin ts are around T 1 (07/16/2007), T 2 (06/30/2008), and T 3 (02/11/2009). The nonstationary encapsulators of 3, 6, and 7 ha ve change points around T 2 (06/30/2008) and T 3 (02/11/2009), but without T 1 , whic h means that at the b e- ginning of financial crisis, these sto c ks were not directly affected b y the change of external factors. These findings match with the critical time points of fi- nancial crisis around the y ear of 2008. The activ e phase of the crisis, which manifested as a liquidity crisis, could b e dated from August, 2007, 3 around T 1 . The nonstationarity encapsulators, esp ecially those of 2, 4, 5, and 3, seem to b e consistent with the change of the TED spread, 4 whic h is an indicator of p erceiv ed credit risk in the general economy and sho wn in Figure 10 (top panel) for comparison; 7 and 6 seem to b e directly influenced by the change in the underlying unmeasured factor, which may b e related to the credit risk, mainly from 2008. 3 See more information at https://en.m.wikipedia.org/wiki/Financial_crisis_of_ 2007- 08 . 4 See https://en.m.wikipedia.org/wiki/TED_spread . 20 7.2 On fMRI Hipp o campus This fMRI Hipp ocampus dataset [31] w as recorded from six separate brain regions: p erirhinal cortex (PRC), parahipp ocampal cortex (PHC), entorhinal cortex (ERC), subiculum (Sub), CA1, and CA3/Dentate Gyrus (CA3) in the resting states on the same p erson in 64 successive da ys. W e are interested in in vestigating causal connections b et ween these six regions in the resting states. The anatomical connections b et w een them rep orted in the literature are shown in Fig. 11. W e used the anatomical connections as a reference, b ecause in the- ory a direct causal connection b et ween tw o areas should not exist if there is no anatomical connection b et ween them. P H C E R C C A 3 C A 1 P R C S u b Figure 11: The anatom- ical connections b et ween the six separate brain regions. W e applied our enhanced constraint-based method on 10 successiv e days separately , with time information T as an additional v ariable in the system. W e assumed that the underlying causal graph is acyclic, although the anatomical structure giv es cycles. W e found that our metho d effectively reduces the FP rate, from 62 . 86% to 17 . 14%, compared to the original constraint-based method with SGS searc h and KCI-test. Here we regard those connections that do not exist in the anatomical structure as spurious; ho wev er, with the lack of ground truth, w e are not able to compare the FN rate. W e found that the causal structure v aries across days, but the connections b etw een CA1 and CA3, and b etw een CA1 and SUB are robust, whic h coincides with the current findings in neuroscience [32]. In addition, on most datasets the causal graphs w e derived are acyclic, which v alidates the use of constrain t-based metho d. F urthermore, we applied the pro cedure in Section 4 to infer the causal directions. W e successfully recov ered the following causal directions: CA3 → CA1, CA1 → Sub, Sub → ER C, ERC → CA1 and PRC → ERC, and the accuracy of direction determination is 85.71% (w e consider the anatomical connections, shown in Fig. 11, as ground truth for the directions). 7.3 On WiFi Dataset The WiFi dataset has been seen as a benchmark dataset to test the p erformance of domain adaptation algorithms. The indo or WiFi lo calization data can be easily outdated since the WiFi signal strength (features) ma y v ary with time p eriods, devices, space and usage of the WiFi [33]. Therefore, it is imp ortant to detect the domain-v arying features in domain adaptation. In this dataset, the data were collected from three different time p eriods in the same lo cations. 21 W e added the domain information ( D = 1 , 2 , 3) as an additional v ariable in the causal system to capture the domain-v arying features. Here we set the significance lev el as 0.05 and we found that only a small subsets of features (8/67) v ary across domains, with feature index = { 1, 2, 3, 4, 5, 6, 12, 44 } , whic h provides b enefits for further analysis in domain adaptation. W e also found that compared to the original constraint-based metho d, our metho d gives muc h sparser connections b et ween the features (the n umber of connections b etw een the features is reduced from 52 to 26). 8 Conclusion This pap er is concerned with discov ery and visualization of nonstationary mo d- els, where causal mo dules may change ov er time or across datasets. W e assume a weak causal sufficiency condition, whic h states that all confounders can be written as smo oth functions of time or the domain index. W e prop osed (1) an enhanced constraint-based metho d for lo cating v ariables whose causal mo dules are nonstationary and estimating the skeleton of the causal structure ov er the observ ed v ariables, (2) a method for causal direction determination that takes adv an tage of the nonstationarit y , and (3) a technique for visualizing nonstation- ary causal mo dules. In this paper w e only considered instan taneous or contemporaneous causal relations, as indicated by the assumption that the observ ed data are indep en- den tly but not identically distributed; the strength (or model, or ev en existence) of the causal relations is allow ed to c hange ov er time. W e did not explicitly con- sider time-delay ed causal relations and in particular did not engage autoregres- siv e mo dels. Ho wev er, we note that it is natural to generalize our framework to incorp orate time-delay ed causal relations, just in the wa y that constrain t-based causal discov ery was adapted to handle time-series data (see, e.g., [34]). There are several op en questions w e aim to answer in future work. First, in this paper we assumed that causal directions do not flip despite of nonstationar- it y . But what if some causal directions also change o v er time or across domains? Can we develop a general approach to detect causal direction changes? Second, to fully determine the causal structure, one migh t need to com bine the p rop osed framew ork with other approaches, such as those based on restricted functional causal models. How can this b e efficiently accomplished? Third, the issue of dis- tribution shift may decrease the p ow er of statistical (conditional) indep endence tests. Is it p ossible to mitigate this problem? References [1] M. Havlicek, K.J. F riston, J. Jan, M. Brazdil, and V.D. Calhoun. Dynamic mo deling of neuronal resp onses in fMRI using cubature k alman filtering. Neur oimage , 56:2109–2128, 2011. 22 [2] P . Spirtes, C. Glymour, and R. Sc heines. Causation, Pr e diction, and Se ar ch . MIT Press, Cam bridge, MA, 2nd edition, 2001. [3] J. Pearl. Causality: Mo dels, R e asoning, and Infer enc e . Cambridge Univer- sit y Press, Cambridge, 2000. [4] D. M. Chick ering. Optimal structure iden tification with greedy search. Journal of Machine L e arning R ese ar ch , 3:507–554, 2003. [5] D. Hec kerman, D. Geiger, and D. M. Chick ering. Learning ba yesian net- w orks: The com bination of kno wledge and statistical data. Machine L e arn- ing , 20:197–243, 1995. [6] S. Shimizu, P .O. Ho yer, A. Hyv¨ arinen, and A.J. Kerminen. A linear non- Gaussian acyclic mo del for causal discov ery . Journal of Machine L e arning R ese ar ch , 7:2003–2030, 2006. [7] P .O. Ho yer, D. Janzing, J. Moo ji, J. Peters, and B. Sch¨ olk opf. Nonlin- ear causal discov ery with additive noise models. In A dvanc es in Neur al Information Pr o c essing Systems 21 , V ancouver, B.C., Canada, 2009. [8] K. Zhang and A. Hyv¨ arinen. Acyclic causality discov ery with additiv e noise: An information-theoretical persp ectiv e. In Pr o c. Eur op e an Confer enc e on Machine L e arning and Principles and Pr actic e of Know le dge Disc overy in Datab ases (ECML PKDD) 2009 , Bled, Slov enia, 2009. [9] K. Zhang and A. Hyv¨ arinen. On the identifiabilit y of the p ost-nonlinear causal mo del. In Pr o c e e dings of the 25th Confer enc e on Unc ertainty in A rtificial Intel ligenc e , Montreal, Canada, 2009. [10] J. Mo oij, O. Stegle, D. Janzing, K. Zhang, and B. Sch¨ olk opf. Probabilistic laten t v ariable mo dels for distinguishing b etw een cause and effect. In A d- vanc es in Neur al Information Pr o c essing Systems 23 (NIPS 2010) , Curran, NY, USA, 2010. [11] V. D. Calhoun, R. Miller, G. P earlson, and T. Adal. The chronnectome: Time-v arying connectivity netw orks as the next frontier in fMRI data dis- co very . Neur on , 84(2):262–274, 2014. [12] R. P . Adams and D. J. C. Mack ay . Bayesian online change p oint dete ction , 2007. T echnical report, Universit y of Cam bridge, Cambridge, UK. Preprin t at [13] M. T alih and N. Hengartner. Structural learning with time-v arying com- p onen ts: T racking the cross-section of financial time series. Journal of the R oyal Statistic al So ciety - Series B , 67 (3):321–341, 2005. [14] E. Kummerfeld and D. Danks. T racking time-v arying graphical structure. In A dvanc es in neur al information pr o c essing systems 26 , La Jolla, CA, 2013. [15] B. Huang, K. Zhang, and B. Sc h¨ olk opf. Identification of time-dep enden t causal mo del: A gaussian pro cess treatment. In the 24th International 23 Joint Confer enc e on Artificial Intel ligenc e, Machine L e arning T r ack , pages 3561–3568, Buenos, Argentina, 2015. [16] E. P . Xing, W. F u, and L. Song. A state-space mixed mem b ership blo c k- mo del for dynamic net work tomography . A nnals of Applie d Statistics , 4 (2):535–566, 2010. [17] L. Song, M. Kolar, and E. Xing. Time-v arying dynamic Ba y esian netw orks. In A dvanc es in neur al information pr o c essing systems 23 , 2009. [18] M. Madiman. On the en tropy of sums. In Pr o c e e dings of IEEE Information The ory Workshop (ITW’08) , pages 303–307, 2008. [19] K. Zhang, J. Peters, D. Janzing, and B. Sch¨ olk opf. Kernel-based conditional indep endence test and application in causal discov ery . In Pr o c e e dings of the 27th Confer enc e on Unc ertainty in A rtificial Intel ligenc e (UAI 2011) , Barcelona, Spain, 2011. [20] K. Hoov er. The logic of causal inference. Ec onomics and Philosophy , 6:207– 234, 1990. [21] J. Tian and J. P earl. Causal disco very from changes: a bay esian approach. In Pr o c e e dings of the 17th Confer enc e on Unc ertainty in A rtificial Intel li- genc e (UAI2001) , pages 512–521, 2001. [22] D. Janzing, D. Balduzzi, M. Grosse-W entrup, and B. Sc h¨ olk opf. Quantify- ing causal influences. A nn. Statist. , 41:2324–2358, 2013. [23] B. Sch¨ olkopf and A. Smola. L e arning with kernels . MIT Press, Cambridge, MA, 2002. [24] L. Song, J. Huang, A. Smola, and K. F ukumizu. Hilb ert space embeddings of conditional distributions with applications to dynamical systems. In International Confer enc e on Machine L e arning (ICML 2009) , June 2009. [25] K. F ukumizu, F. R. Bach, M. I. Jordan, and C. Williams. Dimensionalit y reduction for sup ervised learning with repro ducing k ernel Hilb ert spaces. Journal of Machine L e arning R ese ar ch , 5:73–99, 2004. [26] B. Sc h¨ olkopf, A. Smola, and K. Muller. Nonlinear comp onen t analysis as a kernel eigenv alue problem. Neur al Computation , 10:1299–1319, 1998. [27] A. Gretton, K. Borgwardt, M. Rasch, B. Sch¨ olk opf, and A. Smola. A k ernel metho d for the t wo-sample-problem. In NIPS 19 , pages 513–520, Cam bridge, MA, 2007. MIT Press . [28] P . Spirtes, C. Glymour, and R. Sc heines. Causation, Pr e diction, and Se ar ch . Spring-V erlag Lectures in Statistics, 1993. [29] K. J. F riston, L. Harrison, and W. P enny . Dynamic causal mo delling. Neur oimage , 19(4):1273–1302, 2003. [30] S. M. Smith, K. L. Miller, G. Salimi-Khorshidi, M. W ebster, C. F. Beck- mann, T. E. Nichols, and M. W. W o olric h. Netw ork mo delling metho ds for fMRI. Neur oimage , 54(2):875–891, 2011. 24 [31] R. Poldrac k. http://myconnectome.org/wp/ . [32] D. Song, MC. Hsiao, I. Opris, RE. Hampson, VZ. Marmarelis, GA. Ger- hardt, SA. Deadwyler, and TW. Berger. Hipp ocampal micro circuits, func- tional connectivity , and prostheses. R e c ent A dvanc es On the Mo dular Or- ganization of the Cortex , pages 385–405, 2015. [33] Qiang Y ang, Sinno Jialin Pan, and Vincent W enc hen Zheng. Estimating lo cation using wi-fi. 23(1):8–13, 2008. [34] T. Ch u and C. Glymour. Searc h for additive nonlinear time series causal mo dels. Journal of Machine L e arning R ese ar ch , 9:967–991, 2008. 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment