Spectral decomposition method of dialog state tracking via collective matrix factorization
The task of dialog management is commonly decomposed into two sequential subtasks: dialog state tracking and dialog policy learning. In an end-to-end dialog system, the aim of dialog state tracking is to accurately estimate the true dialog state from…
Authors: Julien Perez
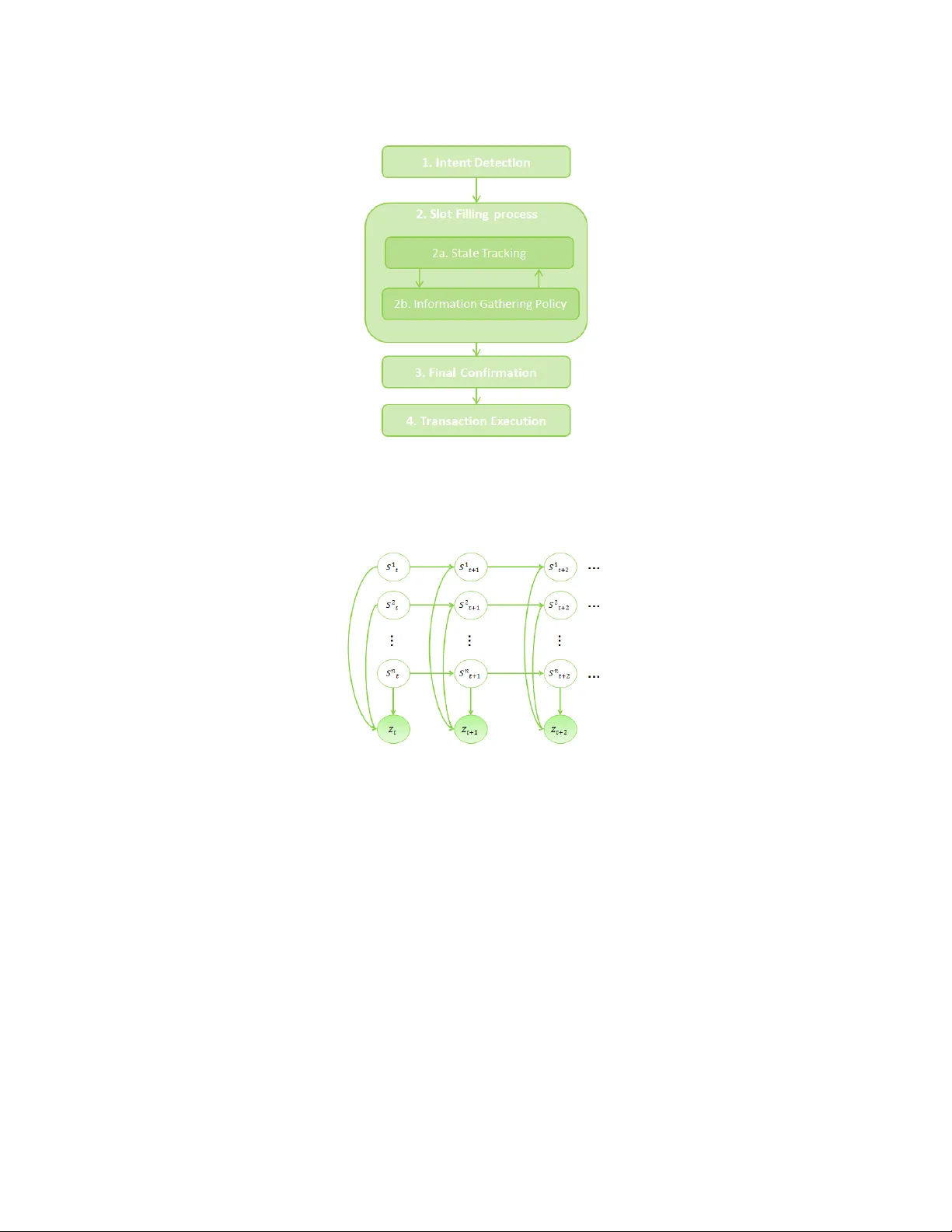
Dialogue & Discourse 7(3) (2016) 34 –46 doi: 10.5087/dad.2016.304 Spectral decomposition method of dialog state tracking via collectiv e matrix factorization Julien P er ez J U L I E N . P E R E Z @ X R C E . X E RO X . C O M Xer ox Resear c h Center Eur ope Gr enoble, 38000, F rance Editor: Jason D. W illiams, Antoine Raux, and Matthew Henderson Submitted 04/15; Accepted 02/16; Published online 04/16 Abstract The task of dialog management is commonly decomposed into two sequential subtasks: dia- log state tracking and dialog policy learning. In an end-to-end dialog system, the aim of dialog state tracking is to accurately estimate the true dialog state from noisy observ ations produced by the speech recognition and the natural language understanding modules. The state tracking task is primarily meant to support a dialog policy . From a probabilistic perspective, this is achiev ed by maintaining a posterior distrib ution ov er hidden dialog states composed of a set of context de- pendent variables. Once a dialog policy is learned, it striv es to select an optimal dialog act given the estimated dialog state and a defined rew ard function. This paper introduces a novel method of dialog state tracking based on a bilinear algebric decomposition model that provides an efficient in- ference schema through collecti ve matrix factorization. W e ev aluate the proposed approach on the second Dialog State Tracking Challenge (DSTC-2) dataset and we sho w that the proposed tracker giv es encouraging results compared to the state-of-the-art trackers that participated in this standard benchmark. Finally , we show that the prediction schema is computationally efficient in comparison to the previous approaches. 1. Introduction The field of autonomous dialog systems is rapidly gro wing with the spread of smart mobile de vices but it still faces many challenges to become the primary user interface for natural interaction through con versations. Indeed, when dialogs are conducted in noisy en vironments or when utterances them- selves are noisy , correctly recognizing and understanding user utterances presents a real challenge. In the context of call-centers, efficient automation has the potential to boost productivity through increasing the probability of a call’ s success while reducing the ov erall cost of handling the call. One of the core components of a state-of-the-art dialog system is a dialog state tracker . Its purpose is to monitor the progress of a dialog and provide a compact representation of past user inputs and system outputs represented as a dialog state. The dialog state encapsulates the information needed to successfully finish the dialog, such as users’ goals or requests. Indeed, the term “dialog state” loosely denotes an encapsulation of user needs at an y point in a dialog. Obviously , the precise defi- nition of the state depends on the associated dialog task. An effecti ve dialog system must include a tracking mechanism which is able to accurately accumulate e vidence ov er the sequence of turns of a dialog, and it must adjust the dialog state according to its observations. In that sense, it is an essen- c 2016 Julien Perez This is an open-access article distributed under the terms of a Creati ve Commons Attribution License ( http : // creativecommons . org / licenses / by / 3 . 0 / ). tial componant of a dialog systems. Ho we ver , actual user utterances and corresponding intentions are not directly observable due to errors from Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU), making it difficult to infer the true dialog state at any time of a dialog. A common method of modeling a dialog state is through the use of a slot-filling schema, as re vie wed in W illiams and Y oung (2007). In slot-filling, the state is composed of a predefined set of v ariables with a predefined domain of e xpression for each of them. The goal of the dialog system is to ef ficiently instantiate each of these v ariables thereby performing an associated task and satisfying the corresponding intent of the user . V arious approaches hav e been proposed to define dialog state trackers. The traditional methods used in most commercial implementations use hand-crafted rules that typically rely on the most likely result from an NLU module as described in Y eh et al. (2014). Ho wever , these rule-based sys- tems are prone to frequent errors as the most likely result is not always the correct one. Moreover , these systems often force the human customer to respond using simple keyw ords and to explic- itly confirm ev erything they say , creating an experience that div erges considerably from the natural con versational interaction one might hope to achieve as recalled in W illiams (2014). More recent methods employ statistical approaches to estimate the posterior distribution ov er the dialog states allo wing them to represent the uncertainty of the results of the NLU module. Statistical dialog state trackers are commonly cate gorized into one of two approaches according to ho w the posterior prob- ability distribution over the state calculation is defined. In the first type, the generativ e approach uses a generativ e model of the dialog dynamic that describes how the sequence of utterances are generated by using the hidden dialog state and using Bayes’ rule to calculate the posterior distribu- tion of the state. It has been a popular approach for statistical dialog state tracking, since it naturally fits into the P artially Observ able Marko v Decision Process (POMDP) models as described in Y oung et al. (2013), which is an integrated model for dialog state tracking and dialog strate gy optimization. Using this generic formalism of sequential decision processes, the task of dialog state tracking is to calculate the posterior distribution ov er an hidden state gi ven an history of observations. In the second type, the discriminati ve approach models the posterior distrib ution directly through a closed algebraic formulation as a loss minimization problem. Statistical dialog systems, in maintaining a distribution o ver multiple hypotheses of the true dialog state, are able to beha ve rob ustly e ven in the face of noisy conditions and ambiguity . In this paper , a statistical type of approach of state tracking is proposed by lev eraging the recent progress of spectral decomposition methods formalized as bi- linear algebraic decomposition and associated inference procedures. The proposed model estimates each state transition with respect to a set of observations and is able to compute the state transition through an inference procedure with a linear comple xity with respect to the number of v ariables and observ ations. Roadmap: This paper is structured as follo ws, Section 2 formally defines transactional dialogs and describes the associated problem of statistical dialog state tracking with both the generati ve and discriminati ve approaches. Section 3 depicts the proposed decompositional model for coupled and temporal hidden v ariable models and the associated inference procedure based on Collecti ve Matrix Factorization (CMF). Finally , Section 4 illustrates the approach with experimental results obtained using a state of the art benchmark for dialog state tracking. 2. T ransactional dialog state tracking The dialog state tracking task we consider in this paper is formalized as follows: at each turn of a task-oriented dialog between a dialog system and a user , the dialog system chooses a dialog act d to express and the user answers with an utterance u . The dialog state at each turn of a giv en dialog is defined as a distribution o ver a set of predefined variables, which define the structure of the state as mentioned in Williams et al. (2005). This classic state structure is commonly called slot filling and the associated dialogs are commonly referred to as transactional . Indeed, in this context, the state tracking task consists of estimating the v alue of a set of predefined variables in order to perform a procedure or transaction which is, in fact, the purpose of the dialog. T ypically , the NLU module processes the user utterance and generates an N-best list o = { < d 1 , f 1 >, . . . , < d n , f n > } , where d i is the hypothesized user dialog act and f i is its confidence score. In the simplest case where no ASR and NLU modules are employed, as in a text based dialog system as proposed in Henderson et al. (2013) the utterance is taken as the observ ation using a so-called bag of words representation. If an NLU module is av ailable, standardized dialog act schemas can be considered as observations as in Bunt et al. (2010). Furthermore, if prosodic information is av ailable by the ASR component of the dialog system as in Milone and Rubio (2003), it can also be considered as part of the observation definition. A statistical dialog state tracker maintains, at each discrete time step t , the probability distribution ov er states, b ( s t ) , which is the system’ s belief ov er the state. The general process of slot-filling, transactional dialog management is summarized in Figure 1. First, intent detection is typically an NLU problem consisting of identifying the task the user w ants the system to accomplish. This first step determines the set of v ariables to instantiate during the second step, which is the slot- filling process. This type of dialog management assumes that a set of v ariables are required for each predefined intention. The slot filling process is a classic task of dialog management and is composed of the cyclic tasks of information gathering and integration, in other words – dialog state trac king . Finally , once all the v ariables ha ve been correctly instantiated, a common practice in dialog systems is to perform a last general confirmation of the task desired by the user before finally executing the requested task. As an example used as illutration of the proposed method in this paper , in the case of the DSTC-2 challenge, presented in Henderson et al. (2014b), the context was taken from the restaurant information domain and the considered v ariables to instanciate as part of the state are { Area (5 possible v alues) ; FOOD (91 possible v alues) ; Name (113 possible v alues) ; Pricerange (3 possible values) } . In such framew ork, the purpose is to estimate as early as possible in the course of a given dialog the correct instantiation of each variable. In the following, we will assume the state is represented as a concatenation of zero-one encoding of the v alues for each v ariable defining the state. Furthermore, in the context of this paper , only the bag of words has been considered as an observ ation at a giv en turn but dialog acts or detected named entity provided by an SLU module could hav e also been incorporated as evidence. T wo statistical approaches ha ve been considered for maintaining the distribution ov er a state gi ven sequential NLU output. First, the discriminativ e approach aims to model the posterior prob- ability distribution of the state at time t + 1 with regard to state at time t and observ ations z 1: t . Second, the generative approach attempts to model the transition probability and the observation probability in order to exploit possible interdependencies between hidden variables that comprise the dialog state. Figure 1: Prototypical transactional dialog management process, also called slot-filling dialog man- agement Figure 2: Generati ve Dialog State T racking using a factorial HMM 2.1 Generativ e Dialog State T racking A generativ e approach to dialog state tracking computes the belief over the state using Bayes’ rule, using the belief from the last turn b ( s t − 1 ) as a prior and the likelihood giv en the user utterance hypotheses p ( z t | s t ) , with z t the observation gathered at time t . In the prior work W illiams et al. (2005), the likelihood is factored and some independence assumptions are made: b t ∝ X s t − 1 ,z t p ( s t | z t , d t − 1 , s t − 1 ) p ( z t | s t ) b ( s t − 1 ) (1) Figure 2 depicts a typical generativ e model of a dialog state tracking process using a factorial hidden Markov model proposed by Ghahramani and Jordan (1997). The shaded variables are the observed dialog turns and each unshaded variable represents a single variable describing the task dependent variables. In this family of approaches, scalability is considered as one of the main issues. One way to reduce the amount of computation is to group the states into partitions, as proposed in the Hidden Information State (HIS) model of Gasic and Y oung (2011). Other approaches to cope with the scalability problem in dialog state tracking is to adopt a factored dynamic Bayesian network by making conditional independence assumptions among dialog state components, and then using approximate inference algorithms such as loopy belief propagation as proposed in Thomson and Y oung (2010) or a blocked Gibbs sampling as in Raux and Ma (2011). T o cope with such limitations, discriminati ve methods of state tracking presented in the next part of this section aim at directly model the posterior distribution of the track ed state using a choosen parametric form. 2.2 Discriminativ e Dialog State T racking The discriminative approach of dialog state tracking computes the belief over a state via a trained parametric model that directly represents the belief b ( s t +1 ) = p ( s s +1 | s t , z t ) . Maximum Entropy has been widely used in the discriminativ e approach as described in Metallinou et al. (2013). It formulates the belief as follo ws: b ( s ) = P ( s | x ) = η .e w T φ ( x,s ) (2) where η is the normalizing constant, x = ( d u 1 , d m 1 , s 1 , . . . , d u t , d m t , s t ) is the history of user dialog acts, d u i , i ∈ { 1 , . . . , t } , the system dialog acts, d m i , i ∈ { 1 , . . . , t } , and the sequence of states leading to the current dialog turn at time t . Then, φ ( . ) is a vector of feature functions on x and s , and finally , w is the set of model parameters to be learned from annotated dialog data. According to the formulation, the posterior computation has to be carried out for all possible state realizations in order to obtain the normalizing constant η . This is not feasible for real dialog domains, which can have a large number of variables and possible variable instantiations. So, it is vital to the discriminativ e approach to reduce the size of the state space. For example, Metallinou et al. (2013) proposes to restrict the set of possible state v ariables to those that appeared in NLU results. More recently , Lee et al. (2013) assumes conditional independence between dialog state v ariables to address scalability issues and uses a conditional random field to track each variable separately . Finally , deep neural models, performing on a sliding window of features extracted from previous user turns, hav e also been proposed in Henderson et al. (2014c). Of the current literature, this f amily of approaches ha ve prov en to be the most efficient for publicly av ailable state tracking datasets. In the next section, we present a decompositional approach of dialog state tracking that aims at reconciling the two main approaches of the state of the art while le veraging on the current advances of low-rank bilinear decomposition models, as recalled in Ma et al. (2014), that seems particularly adapted to the sparse nature of dialog state tracking tasks. 3. Spectral decomposition model for state tracking in slot-filling dialogs In this section, the proposed model is presented and the learning and prediction procedures are detailed. The general idea consists in the decomposition of a matrix M , composed of a set of turn’ s transition as ro ws and sparse encoding of the corresponding feature variables as columns. More precisely , a ro w of M is composed with the concatenation of the sparse representation of (1) s t , a state at time t (2) s t +1 , a state at time t + 1 (3) z t , a set of feature representating the observ ation. In the considered context, the bag of words composing the current turn is chosen as the observation. The parameter learning procedure is formalized as a matrix decomposition task solved through Alternating Least Square Ridge regression. The ridge regression task allows for an asymmetric penalization of the targeted variables of the state tracking task to perform. Figure 3 illustrates the collectiv e matrix factorization task that constitutes the learning procedure of the state tracking model. The model introduces the component of the decomposed matrix to the form of latent v ariables { A, B , C } , also called embeddings. In the next section, the learning procedure from dialog state transition data and the proper tracking algorithm are described. In other terms, each ro w of the matrix corresponds to the concatenation of a ”one-hot” representation of a state description at time t and a dialog turn at time t and each column of the ov erall matrix M corresponds to a consider feature respectiv ely of the state and dialog turn. Such type of modelization of the state tracking problem presents se veral adv antages. First, the model is particularly fle xible, the definition of the state and observation spaces are independent of the learning and prediction models and can be adapted to the context of tracking. Second, a bias by data can be applied in order to condition the transition model w .r .t separated matrices to decompose jointly as often proposed in multi-task learning as described in Caruana (1996) and collective matrix f actorization as detailed in kumar Bokde et al. (2015). Finally , the decomposition method is fast and parallelizable because it mainly le verages on core methods of linear algebra. From our kno wledge, this proposition is the first attend to formalize and solve the state tracking task using a matrix decomposition approach. Figure 3: Spectral State T racking, Collective Matrix F actorization model as inference procedure 3.1 Lear ning method For the sake of simplicity , the { B , C } matrices are concatenated to E , and M is the concatenation of the matrices { S t , S t +1 , Z t } depicted in Figure 3. Equation 3 defines the optimization task, i.e. the loss function, associated with the learning problem of latent v ariable search { A, E } . min A,E || ( M − AE ) W || 2 2 + λ a || A || 2 2 + λ b || E || 2 2 , (3) where { λ a , λ b } ∈ R 2 are regularization hyper-parameters and W is a diagonal matrix that increases the weight of the state variables, s t +1 in order bias the resulting parameters { A, E } toward better predictiv e accurac y on these specific variables. This type of weighting approach has been sho wn to be as efficient in comparable generati ve discriminative trade-off tasks as mentioned in Ulusoy and Bishop (2006) and Lasserre and Bishop (2007). An Alternating Least Squar es method that is a sequence of two con ve x optimization problems is used in order to perform the minimization task. First, for kno wn E , compute: A ∗ = arg min A || ( M − AE ) W || 2 2 + λ a || A || 2 2 , (4) then for a gi ven A , E ∗ = arg min E || ( M − AE ) W || 2 2 + λ b || E || 2 2 (5) By iterativ ely solving these two optimization problems, we obtain the follo wing fixed-point regularized and weighted alternating least square algorithms where t correspond to the current step of the ov erall iterative process: A t +1 ← ( E T t W E t + λ a I ) − 1 E T t W M (6) E t +1 ← ( A T t A t + λ b I ) − 1 A T t M (7) As presented in Equation 6, the W matrix is only in volved for the updating of A because only the subset of the columns of E , representing the features of the state to predict, are weighted dif ferently in order to increase the importancd of the corresponding columns in the loss function. For the optimization of the latent representation composing E , presented in Equation 7, each call session’ s embeddings stored in A hold the same weight, so in this second step of the algorithm, W is actually an identity matrix and so does not appear . 3.2 Pr ediction method The prediction process consists of (1) computing the embedding of a current transition by solving the corresponding least square problem based on the two variables { s t , z t } that correspond to our current knowledge of the state at time t and the set of observations extracted from the last turn that is composed with the system and user utterances, (2) estimating the missing values of interest, i.e. the likelihood of each v alue of each variable that constitutes the state at time ( t + 1) , s t +1 , by com- puting the cross-product between the transition embedding calculated in (1) and the corresponding column embeddings of E , and of the value of each variable of s t +1 . More precisely , we write this decomposition as M = A.E T (8) where M is the matrix of data to decompose and . the matrix-matrix product operator . As in the pre vious section, A has a ro w for each transition embedding, and E has a column for each v ariable- v alue embedding in the form of a zero-one encoding. When a new ro w of observ ations m i for a ne w set of variables state s i and observations z i and E is fixed, the purpose of the prediction task is to find the ro w a i of A such that: a i .E T ≈ m T i (9) Even if it is generally dif ficult to require these to be equal, we can require that these last elements hav e the same projection into the latent space: a T i .E T .E = m T i .E (10) Then, the classic closed form solution of a linear regression task can be deri ved: a T i = m T i .E . ( E T .E ) − 1 (11) a i = ( E T .E ) − 1 .E T .m i (12) In f act, Equation 11 is the optimal value of the embedding of the transition m i , assuming a quadratic loss is used. Otherwise it is an approximation, in the case of a matrix decomposition of M using a logistic loss for example. Note that, in equation 11, ( E T .E ) − 1 requires a matrix in version, but for a low dimensional matrix (the size of the latent space). Sev eral advantages can be identified in this approach. First, at learning time, alternati ve ridge re gression is computationally ef ficient because a closed form solution exists at each step of the optimization process employed to infer the parameters, i.e the low rank matrices, of the model. Second, at decision time, the state tracking procedure consists of (1) computing the embedding a of the current transition using the current state estimation s t and the current observ ation set z t and (2) computing the distrib ution ov er the state defined as a vector -matrix product between a and the latent matrix E . Finally , this inference method can be partially associated to the general technique of matrix completion. But, a proper matrix completion task would have required a matrix M with missing v alue corresponding to the exhausi ve list of the possible triples s t , s t +1 , z t , which is obviously intractable to represent and decompose. 4. Experimental settings and Evaluation In a first section, the dialog domain used for the ev aluation of our dialog tracker is described and the different probability models used for the domain. In a second section, we present a first set of experimental results obtained through the proposed approach and its comparison to se veral reported results of approaches of the state of the art. 4.1 Restaurant inf ormation domain W e used the DSTC-2 dialog domain as described in W illiams et al. (2013) in which the user queries a database of local restaurants by interacting with a dialog system. The dataset for the restaurant information domain were originally collected using Amazon Mechanical T urk. A usual dialog proceeds as follo ws: first, the user specifies his personal set of constraints concerning the restaurant he looks for . Then, the system of fers the name of a restaurant that satisfies the constraints. User then accepts the of fer , and requests for additional information about accepted restaurant. The dialog ends when all the information requested by the user are provided. In this context, the dialog state tracker should be able to track se veral types of information that composes the state like the geographic area, T racker Joint goal Baseline 0.69 Focus 0.74 HWU 0.75 HWU+ 0.72 Rule-based 0.73 MaxEnt 0.72 RNN 0.75 CMF-350 0 . 79 ± 0 . 03 T able 1: Accuracy of the proposed model on the DSTC-2 test-set the food type, the name and the price range slots. In this paper , we restrict ourselves to tracking these v ariables, but our tracker can be easily setup to track others as well if they are properly specified. The dialog state tracker updates its belief turn by turn, receiving evidence from the NLU module with the actual utterance produced by the user . In this experiment, it has been chosen to restrict the output of the NLU module to the bag of word of the user utterances in order to be comparable the most recent approaches of state tracking like proposed in Henderson et al. (2013) that only use such information as e vidence. One important interest in such approach is to dramatically simplify the process of state tracking by suppressing the NLU task. In fact, NLU is mainly formalized in current approaches as a supervised learning approach. The task of the dialog state tracker is to generate a set of possible states and their confidence scores for each slot, with the confidence score corresponding to the posterior probability of each v ariable state w .r .t the current estimation of the state and the current e vidence. Finally , the dialog state tracker also maintains a special v ariable state, called None , which represents that a gi ven v ariable composing the state has not been observed yet. For the rest of this section, we present experimental results of state tracking obtained in this dataset and we compare with state of the art generati ve and discriminati ve approaches. 4.2 Experimental r esults As a comparison to the state of the art methods, T able 1 presents accurac y results of the best Collec- ti ve Matrix Factorization model, with a latent space dimension of 350 , which has been determined by cross-validation on a dev elopment set, where the value of each slot is instantiated as the most probable w .r .t the inference procedure presented in Section 3. In our e xperiments, the v ariance is estimated using standard dataset reshuffling. The same results are obtained for sev eral state of the art methods of generativ e and discriminativ e state tracking on this dataset using the publicly av ailable results as reported in Sun et al. (2014). More precisely , as provided by the state-of-the-art approaches, the accurac y scores computes p ( s ∗ t +1 | s t , z t ) commonly name the joint goal. Our propo- sition is compared to the 4 baseline trackers pro vided by the DSTC or ganisers. They are the baseline tracker (Baseline), the focus tracker (Focus), the HWU tracker (HWU) and the HWU tracker with original flag set to (HWU+) respecti vely . Then a comparison to a maximum entropy (MaxEnt) pro- posed in Lee and Eskenazi (2013) type of discriminati ve model and finally a deep neural network (DNN) architecture proposed in Sun (2014) as reported also in Sun et al. (2014) is presented. 5. Related work As depicted in Section 2, the litterature of the domain can mainly decomposed into three family of approaches, rule-based, generativ e and discriminative. In previous works on this topics, W illiams (2007) formally used particle filters to perform inference in a Bayesian network modeling of the dialog state, W illiams (2008) presented a generati ve track er and sho wed ho w to train an observ ation model from transcribed data, W illiams (2010) grouped indistinguishable dialog states into partitions and consequently performed dialog state tracking on these partitions instead of the indi vidual states, Thomson and Y oung (2010) used a dynamic Bayesian network to represent the dialog model in an approximate form. So, most attention in the dialog state belief tracking literature has been giv en to generativ e Bayesian network models until recently as proposed in Paek and Horvitz (2000) and Thomson and Y oung (2010). On the other hand, the successful use of discriminativ e models for belief tracking has recently been reported by W illiams (2012) and Henderson et al. (2013) and was a major theme in the results of the recent edition of the Dialog State Tracking Challenge. In this paper , a latent decomposition type of approach is proposed in order to address this general problem of dialog system. Our method gi ves encouraging results in comparison to the state of the art dataset and also does not required complex inference at test time because, as detailed in Section 3, the tracking algorithm hold a linear complexity w .r .t the sum of realization of each considered v ariables defining the state to track which is what we believ e is one of the main advantage of this method. Secondly collecti ve matrix factorization paradigm also for data fusion and bias by data type of modeling as successfully performed in matrix factorization based recommender systems K oren et al. (2009). 6. Conclusion In this paper , a methodology and algorithm for ef ficient state tracking in the context of slot-filling dialogs has been presented. The proposed probabilistic model and inference algorithm allows ef- ficient handling of dialog management in the context of classic dialog schemes that constitute a large part of task-oriented dialog tasks. More precisely , such a system allows efficient tracking of hidden variables defining the user goal using any kind of av ailable evidence, from utterance bag- of-words to the output of a Natural Language Understanding module. Our current in vestigation on this subject are the beneficiary of distributional word representation as proposed in Mikolo v et al. (2013) to cope with the question of unkno wn words and unkno wn slots as suggested in Hender- son et al. (2014a). In summary , the proposed approach differentiates itself by the follo wing points from the prior art: (1) by producing a joint probability model of the hidden variable transition in a gi ven dialog state and the observations that allow tracking the current beliefs about the user goals while explicitly considering potential interdependencies between state variables (2) by proposing the necessary computational frame work, based on collecti ve matrix factorization, to ef ficiently infer the distribution over the state v ariables in order to deriv e an adequate dialog policy of information seeking in this context. Finally , while transactional dialog tracking is mainly useful in the context of autonomous dialog management, the technology can also be used in dialog machine reading and kno wledge e xtraction from human-to-human dialog corpora as proposed in the fourth edition of the Dialog State T racking Challenge. References The SJTU system for dialog state tracking challenge 2. In Pr oceedings of the 15th Annual Meeting of the Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) . Association for Computa- tional Linguistics, 2014. Harry Bunt, Jan Alexandersson, Jean Carletta, Jae-W oong Choe, Ale x Chengyu Fang, K oiti Hasida, Kiyong Lee, V olha Petukhov a, Andrei Popescu-Belis, Laurent Romary , Claudia Soria, and David T raum. T o wards an ISO standard for dialogue act annotation. In Pr oceedings of the Seventh In- ternational Confer ence on Languag e Resour ces and Evaluation (LREC’10) . European Language Resources Association (ELRA), may 2010. Rich Caruana. Algorithms and applications for multitask learning. In Pr oc. 13th International Confer ence on Machine Learning , pages 87–95. Morg an Kaufmann, 1996. Milica Gasic and Steve Y oung. Ef fecti ve handling of dialogue state in the hidden information state POMDP-based dialogue manager . TSLP , 7(3):4, 2011. Zoubin Ghahramani and Michael I. Jordan. F actorial hidden Markov models. Mac hine Learning , 29(2-3):245–273, 1997. M. Henderson, B. Thomson, and S. J. Y oung. Rob ust dialog state tracking using delexicalised re- current neural networks and unsupervised adaptation. In Pr oceedings of IEEE Spoken Language T echnology , 2014a. Matthe w Henderson, Blaise Thomson, and Stev e Y oung. Pr oceedings of the SIGDIAL 2013 Con- fer ence , chapter Deep Neural Network Approach for the Dialog State T racking Challenge, pages 467–471. Association for Computational Linguistics, 2013. Matthe w Henderson, Blaise Thomson, and Jason D. W illiams. The second dialog state tracking challenge. In Pr oceedings of SIGDIAL . ACL Association for Computational Linguistics, June 2014b. Matthe w Henderson, Blaise Thomson, and Ste ve Y oung. W ord-based dialog state tracking with recurrent neural networks. In in Pr oceedings of SIGdial , 2014c. Y ehuda K oren, Robert M. Bell, and Chris V olinsky . Matrix factorization techniques for recom- mender systems. IEEE Computer , 42(8):30–37, 2009. Dheeraj kumar Bokde, Sheetal Girase, and Debajyoti Mukhopadhyay . Role of matrix factorization model in collaborati ve filtering algorithm: A survey . CoRR , abs/1503.07475, 2015. Julia Lasserre and Christopher M. Bishop. Generativ e or discriminativ e? getting the best of both worlds. BA YESIAN ST A TISTICS , 8:3–24, 2007. Donghyeon Lee, Minwoo Jeong, Kyungduk Kim, Seonghan Ryu, and Gary Geunbae Lee. Unsu- pervised spoken language understanding for a multi-domain dialog system. IEEE T ransactions on Audio, Speec h & Language Pr ocessing , 21(11):2451–2464, 2013. Sungjin Lee and Maxine Eskenazi. Recipe for building robust spoken dialog state trackers: Dialog state tracking challenge system description. In Pr oceedings of the SIGDIAL 2013 Confer ence , pages 414–422, Metz, France, August 2013. Association for Computational Linguistics. Rick Ma, Nafise Barzigar , Aminmohammad Roozgard, and Samuel Cheng. Decomposition ap- proach for low-rank matrix completion and its applications. IEEE T ransactions on Signal Pr o- cessing , 62(7):1671–1683, 2014. Angeliki Metallinou, Dan Bohus, and Jason W illiams. Discriminati ve state tracking for spoken dialog systems. In Association for Computer Linguistics , pages 466–475. The Association for Computer Linguistics, 2013. T omas Mikolo v , W en tau Y ih, and Geof frey Zweig. Linguistic re gularities in continuous space word representations. In Lucy V anderwende, Hal Daum ´ e III, and Katrin Kirchhof f, editors, HLT - N AA CL , pages 746–751. The Association for Computational Linguistics, 2013. Diego H. Milone and Antonio J. Rubio. Prosodic and accentual information for automatic speech recognition. IEEE T ransactions on Speec h and Audio Pr ocessing , 11(4):321–333, 2003. T im Paek and Eric Horvitz. Con versation as action under uncertainty . In UAI ’00: Pr oceedings of the 16th Confer ence in Uncertainty in Artificial Intelligence, Stanfor d University , Stanford, California, USA , pages 455–464. Morg an Kaufmann, 2000. Antoine Raux and Y i Ma. Efficient probabilistic tracking of user goal and dialog history for spoken dialog systems. In INTERSPEECH , pages 801–804. ISCA, 2011. Kai Sun, Lu Chen, Su Zhu, and Kai Y u. A generalized rule based tracker for dialogue state tracking. In SLT , pages 330–335. IEEE, 2014. Blaise Thomson and Stev e Y oung. Bayesian update of dialogue state: A POMDP framework for spoken dialogue systems. Computer Speech & Language , 24(4):562–588, 2010. I. Ulusoy and C. M. Bishop. Comparison of generative and discriminativ e techniques for object detection and classification. In T owar d Category-Le vel Object Recognition , pages 173–195, 2006. Jason Williams, Antoine Raux, Deepak Ramachandran, and Alan Black. The dialog state tracking challenge. In Pr oceedings of the SIGDIAL 2013 Confer ence , pages 404–413, Metz, France, August 2013. Association for Computational Linguistics. Jason D. W illiams. Using particle filters to track dialogue state. In IEEE W orkshop on Automatic Speech Recognition & Understanding , ASR U 2007, K yoto, J apan, December 9-13, 2007 , pages 502–507, 2007. Jason D. W illiams. Exploiting the ASR n-best by tracking multiple dialog state hypotheses. In INTERSPEECH , pages 191–194. ISCA, 2008. Jason D. W illiams. Incremental partition recombination for efficient tracking of multiple dialog states. In ICASSP , pages 5382–5385, 2010. Jason D. W illiams. Challenges and opportunities for state tracking in statistical spoken dialog systems: Results from two public deployments. J . Sel. T opics Signal Pr ocessing , 6(8):959–970, 2012. Jason D. W illiams. W eb-style ranking and slu combination for dialog state tracking. In Pr oceedings of SIGDIAL . A CL Association for Computational Linguistics, June 2014. Jason D. W illiams and Stev e Y oung. Partially observable Markov decision processes for spoken dialog systems. Computer Speec h & Language , 21(2):393–422, 2007. Jason D. W illiams, Pascal Poupart, and Stev e Y oung. Factored partially observable markov deci- sion processes for dialogue management. In In 4th W orkshop on Knowledge and Reasoning in Practical Dialo g Systems , pages 76–82, 2005. Peter Z. Y eh, Benjamin Douglas, W illiam Jarrold, Adwait Ratnaparkhi, Deepak Ramachandran, Peter F . Patel-Schneider , Stephen La verty , Nirvana T ikku, Sean Brown, and Jeremy Mendel. A speech-dri ven second screen application for TV program discovery . In Carla E. Brodley and Peter Stone, editors, Pr oceedings of the T wenty-Eighth AAAI Confer ence on Artificial Intellig ence, J uly 27 -31, 2014, Qu ´ ebec City , Qu ´ ebec, Canada , pages 3010–3016. AAAI Press, 2014. ISBN 978- 1-57735-661-5. Ste ve Y oung, Milica Gasic, Blaise Thomson, and Jason D. W illiams. POMDP-based statistical spoken dialog systems: A revie w . Pr oceedings of the IEEE , 101(5):1160–1179, 2013.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment