LLFR: A Lanczos-Based Latent Factor Recommender for Big Data Scenarios
The purpose if this master's thesis is to study and develop a new algorithmic framework for Collaborative Filtering to produce recommendations in the top-N recommendation problem. Thus, we propose Lanczos Latent Factor Recommender (LLFR); a novel "bi…
Authors: Maria Kalantzi
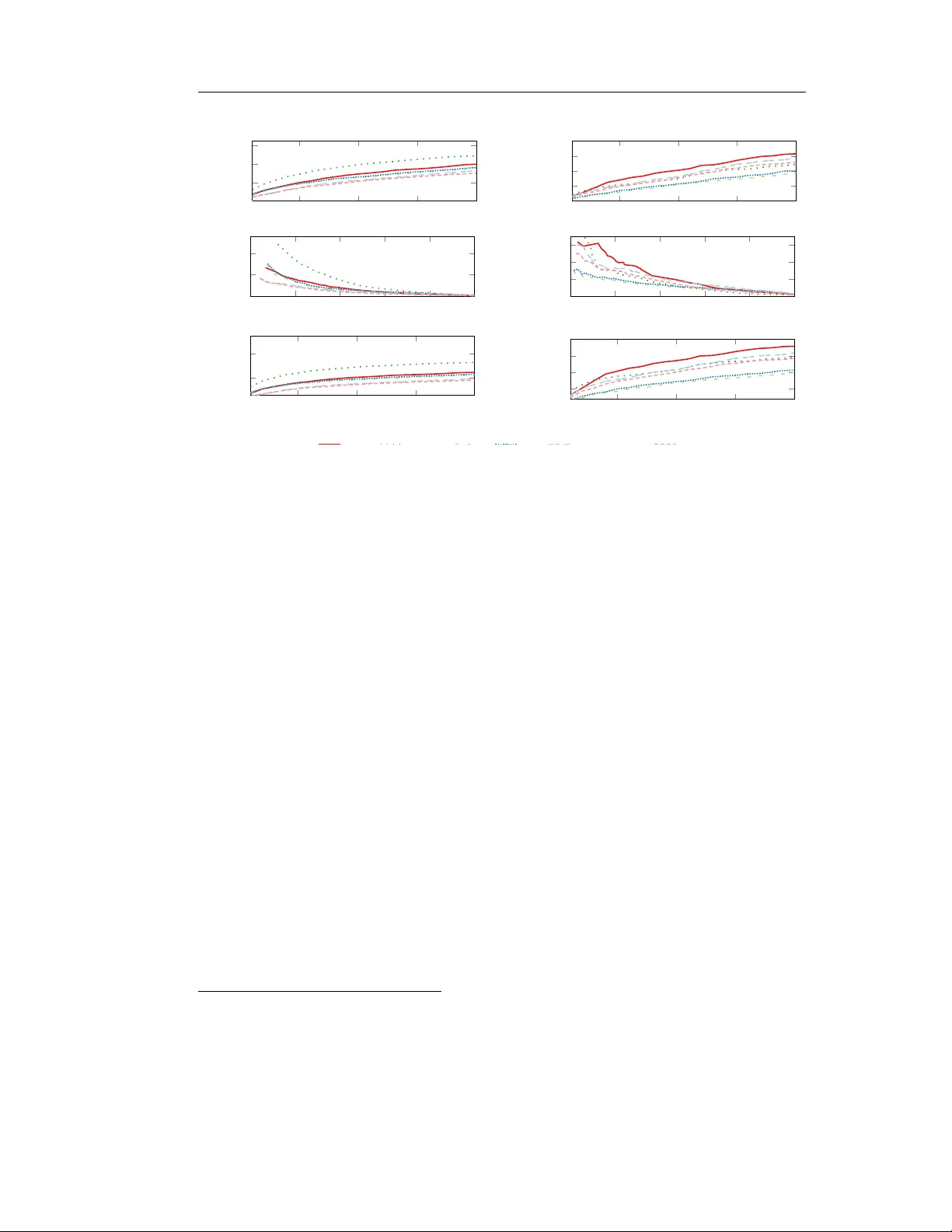
Τ Μ Η/Υ Π Μ Δ Ε «Α νάπτυξ η αποδοτικ ού αλγορίθμου συνεργατικής διήθησης με χρήση των διανυσμάτων Lanczos για το πρόβλημα των top-N συστάσεων σε συστήματα μεγάλου όγκ ου δεδομένων» της Μαρίας Κ αλαντζ ή Επιβλέπων: Κ αθ. Γ ιάννης Γαροφαλάκης 14 Ιουνίου 2016 Π Π Τ Μ Η/Υ Π Μ Δ Ε «Α νάπτυξη αποδοτικού αλγορίθμου συνεργατικής διήθησης με χρήση των διανυσμάτων Lanczos για το πρόβλημα των top-N συστάσεων σε συστήματα μεγάλου όγκ ου δεδομένων» Μαρία Κ αλαντζ ή, A.M. 824 Κ αθηγητής Γ ιάννης Γαροφαλάκης ……………………… ……………………… ……………………… Κ αθηγητής Αθανάσιος Τ σακαλίδης ……………………… ……………………… ……………………… Α ναπληρωτής Κ αθηγητής Ιωάννης Χατζ ηλυγ ερούδης ……………………… ……………………… ……………………… 14 Ιουνίου 2016 Copyright © 2016 Μαρίας Κ αλαντζή Με επιφύλαξη παντός δικαιώματος. All rights reserved. Απαγορεύεται η αντιγραφή, αποθήκευση και διανομή της παρούσας εργασίας, εξ’ ολοκλήρου ή τμήματος αυτής, για εμπορικό σκοπό. Επιτρέπεται η ανατύπωση, αποθήκευση και διανομή για σκοπό µη κερδο- σκοπικ ό, εκπαιδευτικής ή ερευνητικής φύσης, υπό την προϋπόθεση να αναφέρεται η πηγή προέλευσης και να διατηρείται το παρόν μήνυμα. Ερωτήματα που αφορούν τη χρήση της εργασίας για κερδοσκοπικό σκοπό πρέπει να απευθύνονται προς τους συγγραφείς. Οι απόψεις και τα συμπεράσματα που περιέχ ονται σε αυτό το έγγραφο εκφράζ ουν τους συγγραφείς και δεν πρέπει να ερμηνευτεί ότι αντιπροσωπεύουν τις επίσημες θέσεις του Πανεπιστημίου Πατρών. Σ το Θάνο … v Περίληψη Σκοπός της παρούσας διπλωματικής εργασίας είναι η μελέτη και ανάπτυξη ενός νέου αλγοριθ- μικού πλαισίου Συνεργατικής Διήθησης ( C ollaborative F iltering) για την παραγωγή συστάσεων, και ειδικ ότερα για το πρόβλημα των top-N συστάσεων. Προτείνουμε λοιπόν τον Lanczos Latent Factor Recommender (LLFR), έναν νέο CF αλγόριθμο, φιλικ ό στη διαχείριση μεγάλου όγκου δεδομένων για το πρόβλημα των top-N συστάσεων. Χρη- σιμοποιώντας μία προσέγγιση υπολογιστικά αποδοτική η οποία βασίζεται στη μέθοδο Lanczos, ο LLFR μειώνει τη διάσταση του προβλήματος κατασκευάζ οντας ένα latent factor μοντέλο, το οποίο μπορεί άμεσα να αξιοποιηθεί για την παραγωγή προσωποποιημένων διανυσμάτων κατά- ταξης στο χώρο αντικειμένων. Μια σειρά πειραμάτων σε πραγματικά σύνολα δεδομένων ( MovieLens10M, Yahoo!Music ) διαφορετικών επιπέδων πυκνότητας υποδεικνύουν ότι ο LLFR αποδίδει καλύτερα συγκριτικά με άλλες γνωστές μεθόδους top-N συστάσεων, τόσο από υπολογιστική όσο και ποιοτική σκοπιά. Επιπλέον, τα πειραματικά μας αποτελέσματα δείχνουν ότι αυτό το προβάδισμα στην απόδοση, συγκρινόμενο με ανταγωνιστικές μεθόδους, αυξ άνεται καθώς τα δεδομένα γίνονται αραιότερα, δηλαδή στις περιπτώσεις όπου δεν υπάρχουν αρκετά διαθέσιμα δεδομένα προκειμένου να ανα- γνωριστούν ομοιότητες και εντέλει να παραχθούν αξιόπιστες συστάσεις. Πιο συγκεκριμένα, ο LLFR αποδίδει καλύτερα τόσο στην περίπτωση όπου η αραιότητα είναι γενικευμένη – όπως στο New Community Pr oblem , το οποίο συναντάται στα πραγματικά συ- στήματα κατά τα αρχικά τους στάδια όπου δεν υπάρχουν αρκετά δεδομένα ακ όμα στο σύστημα – όσο και στην ιδιαίτερα ενδιαφέρουσα περίπτωση όπου η αραιότητα εντοπίζεται τοπικά σε ένα μικρό κομμάτι των δεδομένων – όπως στο New Users Problem , το οποίο συναντάται κατά την εισαγωγή νέων χρηστών σε ένα υπάρχον σύστημα, όπου ακριβώς επειδή αυτοί οι χρήστες είναι νέοι δεν έχουν προλάβει να βαθμολογήσουν αντικείμενα. Λέξεις Κλειδιά Συστήματα Συστάσεων, Συνεργατική Διήθηση, Αραιότητα, T op-N, Recommender Systems, Collaborative Filtering, Sparsity , Lanczos Method, Dimensionality Reduction Abstract The purpose if this master ’ s thesis is to study and develop a new algorithmic framework for C ollaboartive F iltering to produce recommendations in the top-N recommendation problem. Thus, we propose Lanczos Latent Factor Recommender (LLFR); a novel “big data friendly” collaborative filtering algorithm for top-N recommendation. Using a computationally efficient Lanczos-based procedure, LLFR builds a low dimensional item similarity model, that can be readily exploited to produce personalized ranking vectors over the item space. A number of experiments on real datasets ( MovieLens10M, Yahoo!Music ) at dif ferent density levels indicate that LLFR outperforms other state-of-the-art top-N recommendation methods from a computational as well as a qualitative perspective. Our experimental results also show that its relative performance gains, compared to competing methods, increase as the data get sparser , where there is not enough data for the system to uncover similarities and generate reliable recommendations. More specifically , this is true both when the sparsity is generalized – as in the New Community Pr oblem , a very common problem faced by real recommender systems in their beginning stages, when there is not sufficient number of ratings for the collaborative filtering algorithms to uncover similarities between items or users – and in the very interesting case where the sparsity is localized in a small fraction of the dataset – as in the New Users Problem , where new users are introduced to the system, they have not rated many items and thus, the CF algorithm can not make reliable personalized recommendations yet. Keywords Recommender Systems, Collaborative Filtering, T op-N, Sparsity , Lanczos Method, Dimensionality Reduction Ευχ αριστίες Σε αυτό το σημείο, θα ήθελα να απευθύνω τις ιδιαίτερες ευχαριστίες μου σε όλους όσους συνέβαλλαν στην εκπόνηση της μεταπτυχιακής διπλωματικής μου εργασίας. Αρχικά, θα ήθελα να ευχαριστήσω τον καθηγητή μου και επιβλέποντα, κ. Γ ιάννη Γαροφα- λάκη για την πολύτιμη καθοδήγηση και βοήθεια. Επίσης, ευχ αριστώ τους καθηγητές κ. Αθανά- σιο Τ σακαλίδη και κ. Ιωάννη Χατζηλ υγερούδη που με τίμησαν και δέχτηκαν να συμμετάσχουν στην τριμελή επιτροπή αξιολόγησης της διπλωματικής μου. Ιδιαίτερα, θα ήθελα να ευχ αριστήσω το διδάκτορα Αθανάσιο Ν.Νικολακ όπουλο για την πο- λύτιμη συμβολή και καθοδήγησή του σε όλη την πορεία των μεταπτυχιακών μου σπουδών. Τ ον ευχαριστώ ολόψυχα που με εμπιστεύτηκε και δέχτηκε να συνεργαστούμε για τη συγγραφή της κοινής μας δημοσίευσης. Η αστείρευτη βοήθεια, η επιστημονική του κατάρτιση και εμπειρία που μου προσέφερε απλόχερα συντέλεσαν στη δημιουργία της παρούσας διπλωματικής εργασίας. Τ έλος, οφείλω ένα μεγάλο ευχαριστώ στην οικογένειά μου και την αδελφική μου φίλη Δή- μητρα, για την υποστήριξη, τη συμπαράσταση και την κατανόησή τους σε όλη τη διάρκεια των μεταπτυχιακών μου σπουδών. Μα πάνω απ’ όλα, θα ήθελα να ευχαριστήσω μέσα απ’ την καρ- διά μου το σύζυγό μου Θάνο, που είναι πάντα δίπλα μου και με στηρίζει σε κάθε μου βήμα. Σ’ ευχαριστώ ζωή μου …. xi Περιεχ όμενα Περίληψη vii Ευχ αριστίες xi Περιεχ όμενα xii Κατάλογος σχημάτων xv Κατάλογος πινάκ ων xvii 1 Εισαγωγή 1 1.1 Συστήματα Συστάσεων . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1.2 Συνεισφορά της Εργασίας . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.3 Οργάνωση της Διπλωματικής . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 2 Συστήματα Συστάσεων Συνεργατικής Διήθησης 7 2.1 Συνεργατική Διήθηση - Collaborative Filtering . . . . . . . . . . . . . . . . . 7 2.1.1 Matrix Factorization Models . . . . . . . . . . . . . . . . . . . . . . . 10 2.1.2 Μοντέλα Γειτνίασης - Neighborhood Models . . . . . . . . . . . . . . 1 1 2.1.2.1 Πλεονεκτήματα των Μοντέλων Γειτνίασης . . . . . . . . . . 12 2.1.2.2 Μειονεκτήματα των Μοντέλων Γειτνίασης . . . . . . . . . . 14 2.2 Latent Factor Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 2.2.1 Διάσπαση του μητρώου βαθμολογιών . . . . . . . . . . . . . . . . . . 15 2.2.2 Διάσπαση του μητρώου ομοιοτήτων . . . . . . . . . . . . . . . . . . . 17 2.3 Graph-Based Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 2.3.1 Path-based ομοιότητα . . . . . . . . . . . . . . . . . . . . . . . . . . 19 2.3.2 Random walk ομοιότητα . . . . . . . . . . . . . . . . . . . . . . . . . 20 2.4 Συμπεράσματα . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 3 Lanczos Latent Factor Recommender 25 3.1 Latent Factor Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 3.1.1 PureSVD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 3.2 Τ ο μοντέλο LLFR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 3.3 Ο Αλγόριθμος LLFR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 3.3.1 Υπολογιστικά Θέματα . . . . . . . . . . . . . . . . . . . . . . . . . . 28 4 Πειραματική Αξιολόγηση 31 xiii Περιεχόμενα xiv 4.1 Datasets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 4.2 Μεθοδολογία και διαδικασία πειραμάτων . . . . . . . . . . . . . . . . . . . . 32 4.3 Μετρικές απόδοσης . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 4.4 Ποιότητα Συστάσεων . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36 4.5 Τ ο Πρόβλημα της Κρύας Εκκίνησης . . . . . . . . . . . . . . . . . . . . . . . 38 4.5.1 New Community Problem . . . . . . . . . . . . . . . . . . . . . . . . 38 4.5.2 New Users Problem . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 5 Συμπεράσματα 41 Βιβλιογραφία 43 Κ ατάλογος σχημάτων 2.1 Παράδειγμα ενός Συστήματος Συστάσεων [40]. . . . . . . . . . . . . . . . . . 8 2.2 Διαδικασία παραγωγής συστάσεων μέσω συνεργατικής διήθησης [47]. . . . . . 9 2.3 Διμερής γράφος ο οποίος παρουσιάζει τις βαθμολογίες των χρηστών από τον Πίνακα 2.1. Οι βαθμολογίες αντιστοιχ ούν σε βάρη των ακμών. [32]. . . . . . . 19 3.1 Υπολογιστικοί έλεγχοι . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 4.1 Αξιολόγηση της απόδοσης top-N συστάσεων. . . . . . . . . . . . . . . . . . . 37 4.2 Αξιολόγηση της απόδοσης top-N συστάσεων για το New Users Πρόβλημα . . . 39 xv Κ ατάλογος πινάκ ων 2.1 Παράδειγμα ενός μητρώου χρήστη-αντικειμένου (μητρώο βαθμολογιών). Τ ο σύ- στημα πρέπει να κάνει συστάσεις για τον Αλέξη. Κ άποιοι χρήστες δεν έχουν δώσει βαθμολογία σε κάποιες ταινίες, διότι δεν τις έχουν δει ακόμα. . . . . . . 9 3.1 Σύνολα Δεδομένων . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 4.1 Αποτελέσματα απόδοσης για το New Community Πρόβλημα. . . . . . . . . . . 39 xvii Κεφάλαιο 1 Εισαγωγή 1.1 Συστήματα Συστάσεων Ο ολοένα αυξανόμενος όγκος online πληροφοριών που προκύπτει από τις ραγδαία εξελισσό- μενες ηλεκτρονικές εφαρμογές και υπηρεσίες, έχει καταστήσει σαφή την ανάγκη ύπαρξης προ- σεγγίσεων οι οποίες είναι σε θέση να βοηθούν και να κατευθύνουν το χρήστη προς την άμεση και αποδοτική εξυπηρέτησή του, σχετικά με τις αποφάσεις που καλείται να πάρει. Τ α Συστήματα Συστάσεων (ΣΣ) είναι εργαλεία λογισμικού τα οποία παρέχουν αυτόματες και προσωποποιημένες συστάσεις στους χρήστες για αντικείμενα που πρόκειται να χρησιμο- ποιήσουν [ 45 ]. Οι συστάσεις έχουν να κάνουν με αποφάσεις των χρηστών σχετικά με το ποια αντικείμενα να αγοράσουν, ποια άρθρα να διαβάσουν, ποια ταινία να δουν, κλπ. Ως αντικείμενο θεωρείται κάτι που προτείνει το σύστημα στους χρήστες. Συνήθως ένα ΣΣ επικεντρώνεται σε ένα είδος αντικειμένων (π.χ. ταινίες) και ολόκληρος ο σχεδιασμός του, από τη διεπαφή χρήστη μέχρι και την τεχνική συστάσεων που χρησιμοποιεί, έχει πραγματοποιηθεί με μόνο στόχο να παρέχει χρήσιμες και αποτελεσματικές συστάσεις για αυτό το συγκεκριμένο είδος αντικειμένων. Προκειμένου ένα ΣΣ να πετύχει το σκ οπό του κ αι να αναγνωρίσει ενδιαφέροντα αντικείμενα για τον εκάστοτε χρήστη, θα πρέπει να προβλέψει ότι κάποιο αντικείμενο αξίζει να του το συστή- σει. Για να το κάνει αυτό, το ΣΣ πρέπει να είναι ικανό να προβλέψει τη χρησιμότητα κάποιων αντικειμένων ή τουλάχιστον να συγκρίνει τη χρησιμότητα τους και μετά να αποφασίσει ποια από αυτά θα προτείνει με βάση αυτή τη σύγκριση. Τ ο πρόβλημα των συστάσεων μπορεί να ορισθεί ως η εκτίμηση της απόκρισης του χρήστη για τα νέα αντικείμενα, με βάση παλαιότερες πλ ηροφορίες που διαθέτει το σύστημα, και η πρό- ταση σε αυτόν το χρήστη καινούριων αντικειμένων για τα οποία η προβλεπόμενη απόκριση 1 Κεφάλαιο 1. Εισαγωγή 2 είναι υψηλή. Τ ο είδος των αποκρίσεων χρηστών ποικίλει από εφαρμογή σε εφαρμογή. Για πα- ράδειγμα, η απόκριση του χρήστη μπορεί να είναι αρέσει/δεν αρέσει, ενδιαφέρομαι/δεν ενδια- φέρομαι, ή βαθμολογία από 1 έως 5 για το πόσο του άρεσε κάτι με άριστα το 5. Από ’δω και πέρα, θα αναφερόμαστε στην απόκριση του χρήστη ως βαθμολογία . Τ α συστήματα συστάσεων βασίζονται σε διάφορα είδη εισόδου. Τ ο πιο βολικό είναι η υψη- λής ποιότητας άμεση ανατροφοδότηση (feedback), όπου οι χρήστες αναφέρουν απευθείας το ενδιαφέρον τους για αντικείμενα. Για παράδειγμα, το Netflix συλλέγει αστέρια ως βαθμολογία για ταινίες και οι χρήστες του T iV o εκφράζ ουν την προτίμησή τους για τηλεοπτικά σόου επιλέ- γοντας “thumbs up” και “thumbs down” για να δηλώσουν ότι τους αρέσει κάτι ή όχι αντίστοιχα. Ωστόσο, η άμεση ανατροφοδότηση δεν είναι πάντα διαθέσιμη, κι έτσι διάφορα συστήματα συ- μπεραίνουν τις προτιμήσεις των χρηστών από τις πιο εύκολα διαθέσιμες έμμεσες αποκρίσεις τους, οι οποίες αντικατοπτρίζ ουν γνώμες που έχουν προκύψει από τη μελέτη της συμπεριφοράς των χρηστών. Κάποια παραδείγματα έμμεσης ανατροφοδότησης είναι το ιστορικό αγορών, το ιστορικό περιήγησης, οι κινήσεις του ποντικιού, κ.λπ.. Δύο βασικά είδη ΣΣ είναι τα Συνεργατικής Διήθησης (Collaborative Filtering, CF) και τα Διήθησης με Βάση το Περιεχόμενο (Content-based Filtering) . Οι CF τεχνικές θεωρούνται ως οι πιο διάσημες και ευρέως χρησιμοποιούμενες [ 45 ]. Σύμ- φωνα με την πιο απλή υλοποίηση αυτής της προσέγγισης, τα αντικείμενα που προτείνονται στο χρήστη είναι αυτά που άρεσαν κατά το παρελθόν σε άλλους χρήστες με παρόμοιες προτιμήσεις. Η ομοιότητα στις προτιμήσεις δύο χρηστών υπολογίζεται με βάση την ομοιότητα που υπάρχει στις βαθμολογίες που έχουν δώσει οι χρήστες. Α ναφερόμαστε πιο αναλ υτικά στο συγκεκριμένο είδος ΣΣ στο επόμενο κεφάλαιο της παρούσας εργασίας, καθώς ο αλγόριθμος που προτείνουμε ανήκει σε αυτήν την οικογένεια. Στις τεχνικές διήθησης με βάση το περιεχόμενο, το ΣΣ μαθαίνει να προτείνει στους χρήστες αντικείμενα τα οποία είναι παρόμοια με αυτά που άρεσαν στο χρήστη κατά το παρελθόν. Τ έτοιες μέθοδοι έχουν ως βασικό τους στόχο να αναγνωρίσουν τα κοινά χαρακτηριστικά εκείνων των αντικειμένων τα οποία έχουν βαθμολογηθεί θετικά από ένα χρήστη, και έπειτα να συστήσουν στον ίδιο χρήστη νέα αντικείμενα με τα ίδια χαρακτηριστικ ά. Γ ια παράδειγμα, αν ένας χρήστης έχει βαθμολογήσει θετικά μία κωμωδία, τότε το σύστημα θα του προτείνει κι άλλες κωμωδίες. Με λίγα λόγια, η βασική διαδικασία που πραγματοποιείται από ένα σύστημα που βασίζεται στο περιεχόμενο είναι να ταιριάξει τις ιδιότητες ενός προφίλ χρήστη, οι οποίες φανερώνουν τις προτιμήσεις και τα ενδιαφέροντά του, με τις ιδιότητες ενός αντικειμένου, ώστε εντέλει να προτείνει στο χρήστη αντικείμενα που θα τον ενδιαφέρουν [ 34 ]. Συστήματα συστάσεων τα οποία βασίζονται αποκλειστικά στο περιεχόμενο αντιμετωπίζ ουν συνήθως προβλήματα όπως η περιορισμένη ανάλυση του περιεχομένου και η υπερ-εξειδίκευση Κεφάλαιο 1. Εισαγωγή 3 [ 50 ]. Περιορισμένη ανάλυση του περιεχομένου προκύπτει από το γεγονός ότι το σύστημα μπο- ρεί να έχει μόνο λίγες πληροφορίες για τους χρήστες του ή για το περιεχόμενο των αντικειμένων του. Αυτή η έλλειψη πληροφορίας μπορεί να οφείλεται σε διάφορες αιτίες. Για παράδειγμα, ζ η- τήματα προσωπικών δεδομένων ενδεχομένως να προβληματίζ ουν ένα χρήστη με αποτέλεσμα να μην παρέχει προσωπικές του πληροφορίες, ή το ακριβές περιεχόμενο αντικειμένων μπορεί να είναι δύσκ ολο είτε κ οστοβόρο να αποκτηθεί για κάποια είδη αντικειμένων όπως η μουσική ή οι φωτογραφίες. Επίσης, το περιεχ όμενο ενός αντικειμένου είναι συχνά ανεπαρκές για να καθορι- στεί η ποιότητά του. Παραδείγματος χάριν, ίσως είναι αδύνατο να γίνει διαχωρισμός ανάμεσα σε ένα καλώς γραμμένο και ένα κακώς γραμμένο άρθρο αν και τα δύο χρησιμοποιούν τους ίδιους όρους. Η υπερ-εξειδίκευση από την άλλη μεριά, είναι παρενέργεια του τρόπου με τον οποίο τα συστήματα με βάση το περιεχόμενο συστήνουν νέα αντικείμενα, όπου η προβλεπόμενη βαθμο- λογία ενός χρήστη για ένα αντικείμενο είναι υψηλή εάν αυτό το αντικείμενο είναι παρόμοιο με όσα άρεσαν στο χρήστη. Για παράδειγμα, σε μία εφαρμογή που συστήνει ταινίες, το σύστημα μπορεί να προτείνει σε ένα χρήστη μία ταινία της ίδιας κατηγορίας ή μία ταινία με τους ίδιους ηθοποιούς με ταινίες που έχει ήδη παρακολουθήσει αυτός ο χρήστης. Εξαιτίας αυτής της συ- μπεριφοράς, το σύστημα είναι πιθανό να μην μπορεί να συστήσει αντικείμενα τα οποία είναι διαφορετικά αλλά ταυτόχρονα ενδιαφέροντα στο χρήστη. Λύσεις που έχουν προταθεί για αυτό το πρόβλημα περιλαμβάνουν την προσθήκη τυχαιότητας [ 51 ] ή το φιλτράρισμα αντικειμένων τα οποία είναι ιδιαίτερα όμοια [ 6 , 54 ]. Αξίζει να αναφέρουμε ένα ακόμα είδος ΣΣ, τα Υβριδικά . Αυτά τα συστήματα βασίζονται στο συνδυασμό τεχνικών. Ένα υβριδικ ό σύστημα που συνδυάζει δύο διαφορετικές τεχνικές, προσπαθεί να χρησιμοποιήσει τα πλεονεκτήματα της μιας για να επιλύσει τα μειονεκτήματα της άλλης. Γ ια παράδειγμα, οι CF μέθοδοι δυσκολεύονται να διαχειριστούν τα προβλήματα που έχουν να κάνουν με τα νέα αντικείμενα, καθώς δεν μπορούν να πραγματοποιήσουν συστάσεις αντικειμένων τα οποία δεν έχουν καμία βαθμολογία από τους χρήστες. Κ άτι τέτοιο ωστόσο, δεν αποτελεί περιορισμό για τα content-based συστήματα, αφού η πρόβλεψη για αυτά τα νέα αντικείμενα βασίζεται στην περιγραφή τους η οποία ενδεχομένως να είναι πιο εύκολα διαθέσιμη. Έχουν προταθεί διάφοροι τρόποι συνδυασμού δύο ή περισσότερων τεχνικών για τη δημιουργία ενός υβριδικού συστήματος. 1.2 Συνεισφορά της Εργασίας Ο σκοπός της παρούσας διπλωματικής εργασίας είναι η μελέτη και ανάπτυξη μίας εναλλακτι- κής μεθόδου για το πρόβλημα των top-N συστάσεων σε συστήματα μεγάλου όγκου δεδομένων, η οποία να είναι υπολογιστικά αποδοτική και ταυτόχρονα να διατηρεί την ποιότητα συστάσεων, ακόμα και στις ιδιαίτερα δύσκολες συνθήκες όπου τα δεδομένα του συστήματος δεν επαρκούν για να πραγματοποιήσουν προσωποποιημένες συστάσεις (αραιότητα - sparsity). Κεφάλαιο 1. Εισαγωγή 4 Η κύρια συνεισφορά λοιπόν της συγκεκριμένης εργασίας είναι η πρόταση του Lanczos Latent Factor Recommender (LLFR), ενός νέου αλγόριθμου συνεργατικής διήθησης ο οποίος: • Κ ατασκευάζει ένα μικρότερης διάστασης latent factor μοντέλο στο χώρο αντικειμένων, το οποίο ανακαλύπτει τις εγγενείς ομοιότητες ανάμεσα στα αντικείμενα, χρησιμοποιώντας μία προσέγγιση υπολογιστικά αποδοτική η οποία βασίζεται στη μέθοδο Lanczos. Κ άτι τέ- τοιο, τον καθιστά μία οικονομική και επεκτάσιμη εναλλακτική, συγκριτικά με αντίστοι- χους κοστοβόρους αλγόριθμους. • Πετυχαίνει πολύ καλή ποιότητα συστάσεων σε ευρέως χρησιμοποιούμενες μετρικές, ξε- περνώντας διάφορες άλλες γνωστές και κ οινά αποδεκτές τεχνικές. • Παρουσιάζει μικρή ευαισθησία σε προβλήματα που προκαλούνται από την αραιότητα των δεδομένων, τα οποία αποτελούν μεγάλη πρόκληση για τις σύγχρονες και απαιτητικές εφαρμογές. Πιο συγκεκριμένα, ο LLFR αποδίδει καλύτερα τόσο στην περίπτωση όπου η αραιότητα είναι γ ενικευμένη, όπως στο New Community Problem , όσο και στην ιδιαίτερα ενδιαφέρουσα περίπτωση όπου η αραιότητα εντοπίζεται τοπικά σε ένα μικρό κομμάτι των δεδομένων, όπως στο New Users Pr oblem . Τ α παραπάνω αποτελέσματα της παρούσας εργασίας έχουν δημοσιευτεί στο 4th International Conference on W eb Intelligence Mining and Semantics, WIMS 2014, ACM, New Y ork, USA, με τίτλο On the Use of Lanczos V ectors for Efficient Latent Factor-Based T op-N Recommendation [ 41 ]. Η παρουσίαση της εργασίας πραγματοποιήθηκε στο παραπάνω συνέδριο που έλαβε χώρα τον Ιούνιο του 2014 στη Θεσσαλονίκη. 1.3 Οργάνωση της Διπλωματικής Η παρούσα διπλωματική εργασία οργανώνεται ως ακολούθως: Στο Κεφάλαιο 2 γίνεται επισκ όπηση της βιβλιογραφίας αναφορικά με τα Συστήματα Συστά- σεων Συνεργατικής Διήθησης. Πιο συγκεκριμένα, αρχικά περιγράφουμε αναλ υτικά τα χαρα- κτηριστικά αυτής της οικογένειας ΣΣ, ποια είναι τα βασικά είδη μεθόδων που ανήκουν σε αυ- τήν την κατηγορία και ποια προβλήματα αντιμετωπίζουν. Έπειτα, στην προσπάθεια να βρούμε έναν αποδοτικ ότερο τρόπο χειρισμού της αραιότητας των δεδομένων, μίας από τις μεγαλύτερες προκλήσεις που καλούνται να αντιμετωπίσουν σήμερα τέτοια συστήματα, παρουσιάζουμε οι- κογένειες μεθόδων οι οποίες θεωρείται ότι τα πηγαίνουν καλά σε τέτοιες περιπτώσεις όπου τα δεδομένα του συστήματος είναι αραιά: τα Latent Factor και Graph-Based μοντέλα. Στο Κεφάλαιο 3 παρουσιάζουμε αναλυτικά τον LLFR Αλγόριθμο. Αρχικά, αναφερόμαστε στα latent factor μοντέλα και στον PureSVD, ο οποίος αποτελεί ένα από τα πιο πετυχημένα πα- ραδείγματα για τις top-N συστάσεις. Στη συνέχεια, ξεκινώντας με μία σύντομη αναφορά στη Κεφάλαιο 1. Εισαγωγή 5 μέθοδο Lanczos, περιγράφουμε λεπτομερώς το μοντέλο μας. Τ έλος, παρουσιάζουμε τον ολο- κληρωμένο αλγόριθμο καθώς και τα υπολογιστικά του χαρακτηριστικά. Στο Κεφάλαιο 4 περιγράφουμε πλήρως την πειραματική διαδικασία που ακολουθήσαμε, τη μεθοδολογία αξιολόγησης της ποιότητας των συστάσεων που παράγονται και παρουσιάζουμε τα αποτελέσματα που προκύπτουν. Τ έλος, εξετάζ ουμε το Πρόβλημα της Κρύας Εκκίνησης (Cold Start Problem) και ελέγχουμε την απόδοση του αλγορίθμου μας σε συνθήκες προσομοίωσης του συγκεκριμένου προβλήματος. Στο Κεφάλαιο 5 συνοψίζ ουμε αναφέροντας τη συνεισφορά του LLFR και παρουσιάζουμε τα συμπεράσματά μας. Τ έλος, στο Παράρτημα Α παραθέτουμε τον κώδικα που χρησιμοποιήθηκε στη διπλωματική εργασία. Κεφάλαιο 2 Συστήματα Συστάσεων Συνεργατικής Διήθησης 2.1 Συνεργατική Διήθηση - Collaborative Filtering Α ντίθετα με τις προσεγγίσεις με βάση το περιεχόμενο, οι οποίες για να παράξουν συστάσεις χρησιμοποιούν το περιεχόμενο των αντικειμένων εκείνων που έχουν βαθμολογηθεί στο παρελ- θόν από ένα συγκεκριμένο χρήστη, οι προσεγγίσεις συνεργατικής διήθησης βασίζ ονται μεν στις βαθμολογίες του συγκεκριμένου χρήστη αλλά βασίζ ονται και σε αυτές από άλλους χρήστες. Η βασική ιδέα είναι ότι η βαθμολογία ενός χρήστη u για ένα νέο αντικείμενο i είναι πιθανό να είναι παρόμοια με αυτή ενός άλλου χρήστη v , αν οι u και v έχουν βαθμολογήσει άλλα αντικεί- μενα με παρόμοιο τρόπο. Παρόμοια, ο u είναι πιθανό να βαθμολογήσει δύο αντικείμενα i και j με παρόμοιο τρόπο, αν άλλοι χρήστες έχουν δώσει παρόμοιες βαθμολογίες σε αυτά τα δύο αντικείμενα. Οι τεχνικές συνεργατικής διήθησης καταφέρνουν να ξεπερνούν κάποιους από τους περιορι- σμούς που αντιμετωπίζ ουν εκείνες που βασίζονται στο περιεχόμενο. Γ ια παράδειγμα, αντικεί- μενα για τα οποία το σύστημα δεν έχει διαθέσιμο περιεχόμενο ή είναι δύσκολο να αποκτήσει, μπορούν και πάλι να προταθούν σε χρήστες μέσω απαντήσεων από άλλους χρήστες. Επιπλέον, οι συνεργατικές συστάσεις βγάζ ουν συμπεράσματα για την ποιότητα των αντικειμένων με βάση την αξιολόγηση που προκύπτει από τους χρήστες, αντί να βασίζ ονται στο περιεχ όμενο το οποίο μπορεί να είναι κακός δείκτης ποιότητας. Τ έλος, οι συνεργατικές μέθοδοι, σε αντίθεση με τα συστήματα που βασίζ ονται στο περιεχόμενο, μπορούν να προτείνουν αντικείμενα με πολύ δια- φορετικό περιεχόμενο, αρκεί άλλοι χρήστες να έχουν δείξει ενδιαφέρον για αυτά τα διαφορετικά αντικείμενα. 7 Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 8 . . RECOMMENDER SYSTEM . USERS . ITEMS . RA TINGS . . . . . Recommendation List . Rating Predictions . . . . . Σ 2.1: Παράδειγμα ενός Συστήματος Συστάσεων [ 40 ]. Δοθέντος ενός συνόλου χρηστών, ενός συνόλου αντικειμένων και βαθμολογιών - οι οποίες έχουν τεθεί ρητά ή υπονοούνται – σχετικά με το πόσο αρέσουν ή όχι σε ένα χρήστη τα αντι- κείμενα που έχει ήδη δει (βλ. Σχήμα 2.1 ), οι παραδοσιακές CF τεχνικές προσπαθούν να δη- μιουργήσουν “γειτονιές”, με βάση τις ομοιότητες ανάμεσα στους χρήστες ( user-oriented CF) ή τα αντικείμενα ( item-oriented CF) όπως αυτές προκύπτουν από τα δεδομένα. Ο στόχος τους είναι είτε να προβλέψουν τα σκορ προτίμησης για τα άγνωστα ζευγάρια χρήστη-αντικειμένου ( pr ediction-based recommendation), είτε να δημιουργήσουν μία λίστα με αντικείμενα τα οποία είναι πιθανό να ενδιαφέρουν το χρήστη ( ranking-based or top-N recommendation). Συνοψί- ζ οντας, η διαδικασία που ακ ολουθούν οι μέθοδοι συνεργατικής διήθησης για την παραγωγή συστάσεων παρουσιάζεται στο Σχήμα 2.2 . Προκειμένου να διατυπώσουν συστάσεις, τα συστήματα CF χρειάζεται να συσχετίσουν δύο ριζ ικά διαφορετικές οντότητες: αντικείμενα και χρήστες. Υπάρχουν δυο βασικές προσεγγίσεις για την πραγματοποίηση αυτής της σύγκρισης, οι οποίες αποτελούν και τις δύο βασικές τεχνι- κές του CF: η neighborhood προσέγγιση (ή memory-based) και οι model-based προσεγγίσεις. Οι neighborhood μέθοδοι επικεντρώνονται στις σχέσεις ανάμεσα στα αντικείμενα ή, εναλλα- κτικά, ανάμεσα στους χρήστες. Οι model-based προσεγγίσεις (ή latent factor μοντέλα), όπως η παραγοντοποίηση μητρώου, περιλαμβάνουν μία εναλλακτική προσέγγιση προβάλλοντας και τα αντικείμενα και τους χρήστες στον ίδιο λανθάνοντα χώρο. Ο χώρος αυτός προσπαθεί να εξηγή- σει τις βαθμολογίες χαρακτηρίζ οντας και τα αντικείμενα και τους χρήστες με βάση “ παράγοντες ” που προκύπτουν αυτόματα από την αλληλεπίδραση του χρήστη. Στις neighborhood-based CF μεθόδους, οι βαθμολογίες των χρηστών για τα αντικείμενα που διαθέτει το σύστημα χρησιμοποιούνται απευθείας για την πρόβλεψη βαθμολογιών για νέα αντικείμενα. Αυτό μπορεί να γίνει με δύο τρόπους οι οποίοι είναι γνωστοί ως user -based ή item- based συστάσεις. Η αρχική μορφή των μεθόδων που ανήκουν σε αυτήν την οικογένεια, την οποία είχαν υιοθετήσει όλα τα αρχικά CF συστήματα, βασίζεται στη user-based προσέγγιση. Τ έτοιες μέθοδοι υπολογίζουν τις άγνωστες βαθμολογίες με βάση τις καταχωρημένες βαθμολογίες χρη- στών με παρόμοια γούστα. Αργότερα, έγινε διάσημη μία ανάλογη item-based προσέγγιση. Σε αυτές τις μεθόδους, μία βαθμολογία εκτιμάται χρησιμοποιώντας γνωστές βαθμολογίες από τον ίδιο χρήστη αλλά σε παρόμοια αντικείμενα. Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 9 Σ 2.2: Διαδικασία παραγωγής συστάσεων μέσω συνεργατικής διήθησης [ 47 ]. Γ ια παράδειγμα, μπορούμε να δούμε τον Πίνακα 2.1 , στον οποίο παρουσιάζονται οι βαθμο- λογίες πέντε χρηστών σε πέντε ταινίες. Ο Αλέξης πρέπει να αποφασίσει αν θα νοικιάσει την ταινία “Εκδικητές” την οποία δεν έχει δει. Π 2.1: Παράδειγμα ενός μητρώου χρήστη-αντικειμένου (μητρώο βαθμολογιών). Τ ο σύ- στημα πρέπει να κάνει συστάσεις για τον Αλέξη. Κ άποιοι χρήστες δεν έχουν δώσει βαθμολογία σε κάποιες ταινίες, διότι δεν τις έχουν δει ακόμα. Ροζ Πάνθηρας Εκδικητές Μπάτμαν Τ ιτανικός Μονομάχος Μαρία 2 3 5 2 Γ ιάννης 1 5 3 2 Αλέξης 5 ? 3 3 1 Ά ννα 3 2 4 2 Γ ιώργος 2 4 3 Σε αντίθεση με τα neighborhood-based συστήματα, τα οποία χρησιμοποιούν απευθείας τις βαθμολογίες στην πρόβλεψη, οι model-based προσεγγίσεις τις χρησιμοποιούν για να μάθουν ένα μοντέλο προβλέψεων. Η γ ενική ιδέα είναι η μοντελοποίηση των αλληλεπιδράσεων χρήστη- αντικειμένου με παράγοντες οι οποίοι εκπροσωπούν λανθάνοντα χαρακτηριστικά των χρηστών και των αντικειμένων στο σύστημα, όπως η κλάση προτιμήσεων των χρηστών και η κλάση κα- τηγοριών των αντικειμένων. Αυτό το μοντέλο στη συνέχεια εκπαιδεύεται χρησιμοποιώντας τα διαθέσιμα δεδομένα, και στη συνέχεια χρησιμοποιείται για την πρόβλεψη βαθμολογιών χρηστών για νέα αντικείμενα. Για το πρόβλημα της σύστασης αντικειμένων, υπάρχουν πολλές προσεγγί- σεις αυτής της οικογένειας κ αι κάποιες από αυτές είναι οι Latent Semantic Analysis, Maximum Entropy , και Singular V alue Decomposition. Οι παραδοσιακές τεχνικές συνεργατικής διήθησης μπορούν να ομαδοποιηθούν στις ακόλου- θες δύο κατηγορίες ανάλογα με τα αποτελέσματα που παράγουν: Prediction-based Recommendation. Οι μέθοδοι αυτές προσπαθούν να μαντέψουν τη βαθ- μολογία προτίμησης του χρήστη για κάποιο συγκεκριμένο αντικείμενο, και με βάση αυτή να προχωρήσουν στη σύσταση αντικειμένων. Η επιτυχία των αποτελεσμάτων που παράγουν υπο- λογίζεται από μετρικές οι οποίες ελέγχουν την απόσταση ανάμεσα στις πραγματικές βαθμολο- γίες και στις προβλεπόμενες. Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 10 Ranking-based Recommendation. Ο στόχ ος των τεχνικών αυτών είναι η παραγωγή μίας λί- στας με N αντικείμενα τα οποία αναμένεται να ενδιαφέρουν το χρήστη (ranking-based ή top-N συστάσεις). Η λίστα αυτή κατατάσσει τα αντικείμενα με φθίνουσα σειρά προτίμησης του χρή- στη. Με άλλα λόγια, σε αυτές τις περιπτώσεις η μέθοδος δε χρειάζεται να μαντέψει την ακριβή βαθμολογία που θα έδινε ο χρήστης αν χαρακτήριζε κάποιο αντικείμενο, αλλά αρκεί να το συ- μπεριλάβει στη λίστα και να το τοποθετήσει στη σωστή θέση μέσα σε αυτή, συγκριτικά με τα άλλα αντικείμενα που εμπεριέχονται. Αυτές οι μέθοδοι βρίσκουν ολοένα και μεγαλύτερη εφαρ- μογή στα σύγχρονα εμπορικά συστήματα, καθώς αυτά αρκούνται στο να εμφανίσουν στο χρήστη μερικά συγκεκριμένα αντικείμενα τα οποία προβλέπεται να τον ενδιαφέρουν περισσότερο, ενώ δε χρειάζεται να εμφανίσουν τις βαθμολογίες αξιολόγησης. 2.1.1 Matrix Factorization Models Τ α Latent factor models προσεγγίζ ουν τη συνεργατική διήθηση με στόχο να αποκαλύψουν τα λανθάνοντα χαρακτηριστικ ά που δικαιολογούν τις παρατηρούμενες βαθμολογίες. Παραδείγ- ματα αποτελούν τα νευρωνικά δίκτυα και μοντέλα τα οποία προκύπτουν από την παραγοντοποί- ηση του μητρώου βαθμολογιών χρήστη-αντικειμένου (είναι επίσης γνωστά και ως μοντέλα που βασίζ ονται στον SVD). Τ ελευταία, τα μοντέλα παραγοντοποίησης μητρώου έχουν γίνει γνωστά, χάρη στα ελκυστικά χαρακτηριστικά ακρίβειας και επεκτασιμότητας. Στην ανάκτηση πληροφορίας, ο SVD είναι καθιερωμένος για την αναγνώριση λανθάνοντων σημασιολογικών παραγόντων [ 15 ]. Ωστόσο, στο CF η εφαρμογή του SVD στις άμεσες βαθμο- λογίες δημιουργ εί δυσκολίες εξ αιτίας του μεγάλου ποσοστού τιμών που λείπουν. Ο συμβατικ ός SVD δεν ορίζεται όταν λείπουν τιμές από το μητρώο. Επιπλέον, ο μη προσεκτικός χειρισμός των σχετικά ελάχιστων γνωστών εισόδων τον καθιστά ιδιαίτερα επιρρεπή στο overfitting . Σ την προσπάθειά του να “ταιριάξει” όσο καλ ύτερα μπορεί τα πραγματικά δεδομένα, καταλ ήγει να το “παρακάνει” (over-fit) και να κινδυνεύει να συμπεριλάβει και το θόρυβο (στην περίπτωση που εξετάζ ουμε πρόκειται για σκουπίδια/ψεύτικη πληροφορία στα πραγματικά δεδομένα) μέσα στα πραγματικά δεδομένα. Τ ο αποτέλεσμα φυσικά είναι να παράγονται λανθασμένες προβλέψεις, εφόσον ο θόρυβος έχει παραμορφώσει τα δεδομένα. Προηγούμενες εργασίες βασίστηκαν στο imputation [ 47 ], κατά το οποίο συμπληρώνονται οι βαθμολογίες που λείπουν με κάποια τιμή και το μητρώο βαθμολογιών πυκνώνει. Ωστόσο, το imputation μπορεί να γίνει πολύ ακριβό καθώς αυξ άνει πολύ την ποσότητα των δεδομένων. Επιπρόσθετα, τα δεδομένα μπορεί να παραμορφωθούν σημαντικά λόγω της προσέγγισης με μη ακριβείς τιμές. Έτσι, πιο πρόσφατες εργασίες [ 4 , 10 , 29 , 52 ] πρότειναν τη μοντελοποίηση απευθείας μόνο των παρατηρούμενων βαθμολογιών, ενώ ταυτόχρονα αποφεύγουν το overfitting μέσα από ένα επαρκώς regularized μοντέλο. Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 1 1 Στη βασική της μορφή, η παραγοντοποίηση μητρώου χαρακτηρίζει και τα αντικείμενα και τους χρήστες με διανύσματα παραγόντων που προκύπτουν από μοτίβα μέσα από τις βαθμολο- γίες των αντικειμένων. Υψηλή αντιστοιχία ανάμεσα στους παράγοντες αντικειμένου και χρήστη οδηγεί στη σύσταση ενός αντικειμένου σε ένα χρήστη. Αυτές οι μέθοδοι καταφέρνουν ακρί- βεια πρόβλεψης μεγαλύτερη από άλλες δημοσιευμένες τεχνικές συνεργατικής διήθησης. Τ αυτό- χρονα, προσφέρουν ένα αποδοτικό από άποψη μνήμης μοντέλο, το οποίο μπορεί σχετικά εύκολα να εκπαιδευτεί. Αυτό που κάνει αυτές τις τεχνικές ακόμα πιο βολικές είναι η ικανότητά τους να διαχειρίζ ονται διάφορα κρίσιμα θέματα που έχουν να κάνουν με τα δεδομένα. Αρχικά, έχ ουν τη δυνατότητα να μπορούν να ανταπεξέρχονται σε πολλαπλά είδη ανατροφοδότησης του χρήστη (συγκεκριμένη βαθμολογία, χαρακτηρισμός “μου αρέσει/δε μου αρέσει”, κλπ.). Έπειτα, μπο- ρούν να προβλέψουν καλύτερα τις βαθμολογίες χρήστη παρατηρώντας επίσης άλλες σχετικές ενέργειες του ίδιου χρήστη, όπως το ιστορικ ό αγορών και πλοήγησης [ 30 ]. 2.1.2 Μοντέλα Γειτνίασης - Neighborhood Models Η πιο συχνή προσέγγιση στη συνεργατική διήθηση βασίζεται στα μοντέλα γειτνίασης. Οι αλ- γόριθμοι αυτής της οικογένειας για να παράξ ουν μία πρόβλεψη χρησιμοποιούν ολόκληρη ή ένα μέρος της πληροφορίας από το μητρώο βαθμολογιών. Ο στόχος τους είναι να εντοπίσουν τους “γείτονες” ενός νέου χρήστη. Πιο συγκεκριμένα, για να πραγματοποιήσουν μία σύσταση υπο- λογίζ ουν την ομοιότητα ή το βάρος μεταξύ δύο χρηστών ή δύο αντικειμένων, και υπολογίζουν το σταθμισμένο μέσο όρο όλων των βαθμολογιών που έχει δώσει ένας συγκεκριμένος χρήστης ή που έχει πάρει ένα συγκεκριμένο αντικείμενο [ 47 ]. Η παραπάνω διαδικασία υφίσταται για την παραγωγή προτεινόμενων βαθμολογιών (prediction-based recommendation). Για την περί- πτωση όπου παράγεται μία λίστα top-N συστάσεων, τότε οι παραπάνω αλγόριθμοι μέσα από τον υπολογισμό των ομοιοτήτων εντοπίζουν τους k πιο όμοιους χρήστες ή αντικείμενα ( k nearest neighbors), και τους συγκεντρώνουν ώστε να πάρουν τα N πιο συχνά αντικείμενα τα οποία αποτελούν και τη σύσταση. User -based συστάσεις Οι user-based μέθοδοι συστάσεων προβλέπουν μία βαθμολογία r ui ενός χρήστη u για ένα αντικείμενο i χρησιμοποιώντας τις βαθμολογίες που έχουν δοθεί στο i από χρήστες περισσότερο όμοιους (παρουσιάζουν ομοιότητες στις βαθμολογίες) στον u , οι οποίοι ονομάζονται κοντινότεροι γείτονες . Οι γείτονες του χρήστη u είναι ουσιαστικά οι χρήστες v των οποίων οι βαθμολογίες στα αντικείμενα που έχουν βαθμολογηθεί και από τον u και από τους v ταιριάζ ουν πιο πολύ σε αυτές του u . Αξίζει να αναφέρουμε ότι διάφοροι παράμετροι πρέπει να λαμβάνονται υπόψη σε προσεγγίσεις αυτής της οικογένειας, όπως το ότι οι χρήστες δε βαθμολογούν με τον ίδιο τρόπο αντικείμενα που τους αρέσουν (άλλοι είναι πιο αυστηροί στη βαθμολογία τους), ή το ότι ανάμεσα στους γείτονες ενός χρήστη κάποιοι μπορεί να είναι πιο κοντά του σε σχέση με κάποιους άλλους (δίνονται βάρη στη συνεισφορά του κάθε γείτονα, Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 12 ανάλογα με το βαθμό ομοιότητάς του με το χρήστη). Παραδείγματα user-based συστημάτων είναι τα GroupLens [ 27 ] και Ringo[ 50 ]. Item-based συστάσεις Από την άλλη μεριά, ενώ οι user-based μέθοδοι βασίζονται στην άποψη χρηστών με παρόμοια γούστα, οι item-based προσεγγίσεις [ 16 , 33 ] εξετάζουν τις βαθμολογίες που έχουν δοθεί σε όμοια αντικείμενα. Πιο συγκεκριμένα, η βαθμολογία r ui ενός χρήστη u για ένα αντικείμενο i προβλέπεται με βάση τις βαθμολογίες που έχει δώσει ο χρήστης σε άλλα παρόμοια αντικείμενα. Σε τέτοιες προσεγγίσεις, δύο αντικείμενα είναι παρόμοια αν τα έχουν βαθμολογήσει με παρόμοιο τρόπο αρκετοί χρήστες του συστήματος. Και σε αυτήν την οικογέ- νεια προσεγγίσεων απαιτείται κανονικ οποίηση των βαθμολογιών, προκειμένου για παράδειγμα και εδώ να ληφθούν υπόψη οι διαφορετικές βαθμολογικές κλίμακες των χρηστών. Οι item-based προσεγγίσεις κέρδισαν αμέσως έδαφος σε πολλές περιπτώσεις χάρη στην καλύτερη επεκτασι- μότητα και τη βελτιωμένη ακρίβειά τους συγκριτικά με τις user-based μεθόδους. Επιπλέον, οι item-based μέθοδοι δίνουν μια πιο κατανοητή εξήγηση για τις προβλέψεις τους. Αυτό ισχύει διότι οι χρήστες είναι εξ οικειωμένοι με αντικείμενα τα οποία είχαν προτιμήσει στο παρελθόν, αλλά δε γνωρίζ ουν εκείνα τα οποία υποτίθεται ότι συστήνονται λόγω άλλων χρηστών με παρό- μοια γούστα. 2.1.2.1 Πλεονεκτήματα των Μοντέλων Γειτνίασης Ενώ πρόσφατες έρευνες δείχνουν ότι μοντέρνες model-based προσεγγίσεις είναι ανώτερες από τις neighborhood για την πρόβλεψη βαθμολογιών [ 29 , 52 ], γίνεται αντιληπτό ότι η καλή ακρίβεια πρόβλεψης από μόνη της δεν εγγυάται στους χρήστες μία αποτελεσματική και ικανο- ποιητική εμπειρία [ 22 ]. Προς αυτήν την κατεύθυνση, ένας άλλος παράγοντας ο οποίος φαίνεται να παίζει σημαντικό ρόλο στο κατά πόσο οι χρήστες εκτιμούν το σύστημα συστάσεων είναι το ser endipity (απρόσμενα ευχάριστη έκπληξη) [ 22 ]. Πρόκειται για κάτι καινούριο το οποίο βρί- σκει ενδιαφέρον ο χρήστης και που διαφορετικά μπορεί να μην ανακάλ υπτε. Γ ια παράδειγμα, η σύσταση σε ένα χρήστη μιας ταινίας που έχει σκηνοθετήσει ο αγαπημένος του σκηνοθέτης, απο- τελεί μια νέα σύσταση αν ο χρήστης δε γνώριζε την ύπαρξη αυτής της ταινίας, αλλά πιθανότατα θα την ανακάλυπτε μόνος του. Κάτι τέτοιο δεν αποτελεί serendipity . Οι model-based προσεγγίσεις το παρακάνουν στο να χαρακτηρίζ ουν τις προτιμήσεις ενός χρήστη με latent factors. Για παράδειγμα, σε ένα σύστημα που συστήνει ταινίες, τέτοιες μέθο- δοι μπορεί να προσδιορίσουν ότι σε ένα χρήστη αρέσουν ταινίες οι οποίες είναι και αστείες και ρομαντικές, χωρίς να χρειάζεται να ορίσουν τις έννοιες “αστείο” και “ρομαντικό”. Ένα τέτοιο σύστημα είναι σε θέση να συστήσει σε ένα χρήστη μία ρομαντική κωμωδία που δε γνώριζε ο χρήστης. Ωστόσο, ενδεχομένως να είναι δύσκολο για αυτό το σύστημα να συστήσει μία ται- νία η οποία δεν ταιριάζει ακριβώς με αυτήν την υψηλού επιπέδου κατηγορία. Οι neighborhood Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 13 προσεγγίσεις από την άλλη μεριά, συλλαμβάνουν τοπικές συσχετίσεις στα δεδομένα. Συνεπώς, είναι πιθανό για ένα σύστημα συστάσεων ταινιών που χρησιμοποιεί μια τέτοια τεχνική να συ- στήσει στο χρήστη μία ταινία διαφορετική από τα συνηθισμένα γούστα του ή μία ταινία η οποία δεν είναι ιδιαίτερα γνωστή, αν κάποιος από τους στενούς γείτονές του της έχει δώσει υψηλή βαθμολογία. Μία τέτοια σύσταση μπορεί να μην είναι εγγυημένα επιτυχής, όπως θα ήταν μία ρομαντική κομεντί, αλλά ίσως βοηθήσει το χρήστη να ανακαλύψει μία τελείως νέα κατηγορία ή έναν νέο αγαπημένο ηθοποιό/σκηνοθέτη. Γενικά, οι model-based τεχνικές καταφέρνουν να εκφράσουν ιδιαίτερα καλά τις διάφορες εκδοχές των δεδομένων. Έτσι, τείνουν να παρέχουν πιο ακριβή αποτελέσματα από τα μοντέλα γειτνίασης. Ωστόσο, τα περισσότερα εμπορικά συστήματα (για παράδειγμα, τα Amazon [ 33 ] και T iV o [ 2 ]) βασίζονται στα μοντέλα γειτνίασης. Αυτή τους η κυριαρχία οφείλεται εν μέρη στην απλότητά τους. Ωστόσο, υπάρχουν πιο σημαντικοί λόγοι, όπως θα δούμε αμέσως παρακάτω, για να παραμένουν πιστά σε αυτά τα μοντέλα αρκετά πραγματικά συστήματα. Τ α κύρια πλεονεκτήματα των neighborhood-based μεθόδων είναι [ 17 ]: Απλότητα. Τ έτοιες μέθοδοι είναι διαισθητικές και σχετικά απλές στην εφαρμογή τους. Στην πιο απλή τους μορφή, μόνο μία παράμετρος (ο αριθμός των γειτόνων που θα χρησιμοποιηθούν στην πρόβλεψη) χρειάζεται να ρυθμιστεί. Δυνατότητα αιτιολόγησης. Οι neighborhood-based μέθοδοι προσφέρουν επίσης μία σύντομη και διαισθητική αιτιολόγηση για τις συστάσεις που πραγματοποιούνται. Για παράδειγμα, στις item-based συστάσεις, η λίστα με τα γειτονικά αντικείμενα, καθώς και οι βαθμολογίες που έχουν δοθεί από το χρήστη για αυτά τα αντικείμενα, μπορούν να παρουσιαστούν στο χρήστη ως αιτιολόγηση για τη σύσταση που του έχει γίνει. Κ άτι τέτοιο μπορεί να βοηθήσει το χρήστη να κατανοήσει καλύτερα τις συστάσεις και τη συνάφειά τους, και θα μπορούσε να λειτουργήσει ως βάση για ένα αλληλεπιδραστικό σύστημα στο οποίο οι χρήστες μπορούν να επιλέξ ουν τους γείτονες για τους οποίους θα δοθεί μεγαλύτερη σημασία στη σύσταση [ 4 ]. Αποτελεσματικ ότητα. Ένα από τα πιο δυνατά σημεία των neighborhood-based συστημάτων είναι η αποτελεσματικότητά τους. Σε αντίθεση με τα model-based συστήματα, δεν απαι- τούν εκπαίδευση, μία απαίτηση η οποία πρέπει να πραγματοποιείται σε τακτά χρονικά διαστήματα σε μεγάλες εμπορικές εφαρμογές. Ενώ η διαδικασία των συστάσεων είναι συνήθως πιο ακριβή όταν πρόκειται για model-based μεθόδους, οι nearest-neighbors μπο- ρούν να υπολογισθούν από πριν σε ένα off-line βήμα, προσφέροντας σχεδόν στιγμιαίες συστάσεις. Επιπλέον, η αποθήκευση αυτών των nearest-neighbors έχει μικρές απαιτήσεις σε μνήμη, καθιστώντας τέτοιες προσεγγίσεις επεκτάσιμες σε εφαρμογές με εκατομμύρια χρηστών και αντικειμένων. Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 14 Σ ταθερότητα. Μια ακόμα χρήσιμη ιδιότητα των συστημάτων συστάσεων που βασίζ ονται σε αυτήν την προσέγγιση είναι ότι επηρεάζ ονται ελάχιστα από τη διαρκή προσθήκη χρη- στών, αντικειμένων και βαθμολογιών, κάτι το οποίο παρατηρείται κατά κανόνα σε με- γάλες εμπορικές εφαρμογές. Για παράδειγμα, ένα item-based σύστημα είναι σε θέση να κάνει συστάσεις σε νέους χρήστες αμέσως μόλις υπολογιστούν οι ομοιότητες ανάμεσα στα αντικείμενα, χωρίς να χρειάζεται να ξανά-εκπαιδεύσει το σύστημα. Επιπλέον, μόλις εισαχθούν κάποιες βαθμολογίες για ένα νέο αντικείμενο, το μόνο που απαιτείται να υπο- λογιστεί είναι οι ομοιότητες ανάμεσα σε αυτό το αντικείμενο και σε αυτά που υπάρχουν ήδη στο σύστημα. 2.1.2.2 Μειονεκτήματα των Μοντέλων Γειτνίασης Οι προσεγγίσεις γειτνίασης που βασίζονται στις συσχετίσεις ανάμεσα στις βαθμολογίες πα- ρουσιάζ ουν δύο σημαντικά μειονεκτήματα: Περιορισμένη κάλ υψη (limited coverage). Η κάλ υψη αφορά στο εύρος αντικειμένων που μπορεί να συστήσει ένα ΣΣ. Επειδή οι συσχετίσεις μεταξύ βαθμολογιών μετρούν την ομοιότητα ανάμεσα σε δύο χρήστες συγκρίνοντας τις βαθμολογίες τους στα ίδια αντικείμενα, οι χρήστες μπορούν να είναι γείτονες μόνο εάν έχουν βαθμολογήσει κοινά αντικείμενα. Αυτή η υπόθεση είναι πολύ περιοριστική, καθώς χρήστες οι οποίοι έχουν βαθμολογήσει λίγα ή και καθόλου κοινά αντικείμενα μπορεί και πάλι να έχ ουν παρόμοιες προτιμήσεις. Επιπλέον, αφού μπορούν να προ- ταθούν μόνο αντικείμενα τα οποία έχουν βαθμολογηθεί από γείτονες, η κάλυψη τέτοιων μεθό- δων μπορεί επίσης να είναι περιορισμένη. Ευαισθησία στα αραιά δεδομένα. Οι μέθοδοι συστάσεων που βασίζονται στη γειτονικ ότητα υποφέρουν επίσης από την έλλειψη διαθέσιμων βαθμολογιών. Η αραιότητα είναι ένα κοινό πρό- βλημα για τα περισσότερα συστήματα συστάσεων [ 8 , 38 , 40 , 43 , 44 ] λόγω του ότι οι χρήστες συνήθως βαθμολογούν μόνο ένα μικρό μέρος των διαθέσιμων αντικειμένων [ 5 , 22 , 46 ]. Στο με- ταξύ, αυτό ενισχύεται και από το γεγονός ότι οι νέοι χρήστες ή τα νέα αντικείμενα που έχουν προστεθεί σε ένα σύστημα είναι πιθανό να μην έχ ουν καθόλου βαθμολογίες. Αυτό το πρόβλημα είναι γνωστό ως Τ ο Πρόβλημα της Κρύας Εκκίνησης [ 48 ]. Όταν τα δεδομένα είναι αραιά, δύο χρήστες ή αντικείμενα είναι απίθανο να έχουν κοινές βαθμολογίες, και κατά συνέπεια, οι προ- σεγγίσεις που βασίζονται στη γειτονικότητα θα προβλέψουν βαθμολογίες χρησιμοποιώντας έναν πολύ περιορισμένο αριθμό από γ είτονες. Επιπλέον, οι βαθμοί ομοιότητας μπορεί να υπολογίζ ο- νται χρησιμοποιώντας μόνο ένα μικρό αριθμό βαθμολογιών, οδηγώντας έτσι σε “προκατειλ ημ- μένες” συστάσεις. Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 15 Μία κοινή λύση για όλα αυτά τα προβλήματα είναι η συμπλήρωση των βαθμολογιών που λεί- πουν με κάποιες προκαθορισμένες τιμές [ 16 ], όπως η μέση τιμή του εύρους βαθμολογιών, και η μέση βαθμολογία. Μια πιο αξιόπιστη προσέγγιση είναι να χρησιμοποιηθεί πληροφορία από το περιεχόμενο για τη συμπλήρωση των βαθμολογιών που λείπουν [ 22 , 27 ]. Γ ια παράδειγμα, τα δε- δομένα που λείπουν μπορούν να παραχθούν από αυτόνομους πράκτορες, γνωστούς ως filterbots [ 22 , 27 ], οι οποίοι ενεργούν ως συνηθισμένοι χρήστες του συστήματος και βαθμολογούν αντι- κείμενα με βάση κάποια συγκεκριμένα χαρακτηριστικά του περιεχομένου τους. Από την άλλη μεριά, τα δεδομένα που λείπουν μπορούν να προβλεφθούν και από μία προσέγγιση με βάση το περιεχόμενο [ 36 ]. Ωστόσο, και αυτές οι λύσεις έχουν τα μειονεκτήματά τους. Για παράδειγμα, το να δώσει κανείς μία προκαθορισμένη τιμή στις βαθμολογίες που λείπουν μπορεί να προκαλέσει προκατάληψη στις συστάσεις. Επίσης, μπορεί να μην είναι διαθέσιμο περιεχόμενο σχετικά με τα αντικείμενα για τον υπολογισμό βαθμολογιών ή ομοιοτήτων. Στις επόμενες ενότητες παρουσιάζ ονται δύο από τις βασικότερες προσεγγίσεις για την αντι- μετώπιση των προβλημάτων της περιορισμένης κάλυψης και της αραιότητας: οι dimensionality reduction και οι graph-based μέθοδοι. 2.2 Latent Factor Models Οι dimensionality reduction μέθοδοι [ 4 , 5 , 29 , 42 , 46 , 53 ] αντιμετωπίζ ουν τα προβλήματα μειωμένης κάλυψης και αραιότητας προβάλλοντας χρήστες και αντικείμενα σε ένα μειωμένης διάστασης λανθάνοντα χώρο ο οποίος συλλαμβάνει τα πιο βασικά τους χαρακτηριστικά. Λόγω του ότι χρήστες και αντικείμενα συγκρίνονται σε αυτόν τον πυκνό υποχώρο με υψηλού επιπέδου χαρακτηριστικ ά αντί για τον χώρο βαθμολογιών, μπορούν να ανακαλυφθούν σχέσεις με μεγα- λύτερο νόημα. Πιο συγκεκριμένα, μπορεί να βρεθεί μία σχέση ανάμεσα σε δύο χρήστες, ακόμα και αν αυτοί οι χρήστες έχ ουν βαθμολογήσει διαφορετικά αντικείμενα. Ως αποτέλεσμα, τέτοιες μέθοδοι είναι γενικά λιγότερο ευαίσθητες στα αραιά δεδομένα [ 4 , 5 , 46 ]. Κ ατά κύριο λόγο, υπάρχουν δύο τρόποι τους οποίους μπορούν να χρησιμοποιήσουν οι μέθο- δοι αυτής της κατηγορίας: η διάσπαση του μητρώου βαθμολογιών, και η διάσπαση ενός αραιού μητρώου ομοιοτήτων. 2.2.1 Διάσπαση του μητρώου βαθμολογιών Μια διάσημη dimensionality reduction προσέγγιση για τη σύσταση αντικειμένων είναι η Latent Semantic Indexing (LSI) [ 15 ]. Σε αυτήν την προσέγγιση, το | U | × | I | χρήστη-αντικείμενο μητρώο βαθμολογιών R τάξης n προσεγγίζεται από ένα μητρώο ˆ R = PQ ⊤ τάξης k < n , όπου P είναι ένα | U | × k μητρώο από παράγοντες σχετικούς με χρήστες και Q ένα | I | × k μητρώο Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 16 από παράγοντες αντικειμένων. Διαισθητικά, η u -οστή γραμμή του P , p u ∈ R k , αναπαριστά τις συντεταγμένες του χρήστη u μετά την προβολή τους στο λανθάνοντα χώρο k διάστασης. Α ντίστοιχα, η i -οστή γραμμή του Q , q i ∈ R k , μπορεί να θεωρηθεί ως οι συντεταγμένες του αντικειμένου i σε αυτόν το λανθάνοντα χ ώρο. Τ α μητρώα P και Q συνήθως υπολογίζ ονται ελα- χιστοποιώντας το reconstruction error που ορίζεται με τη squared Frobenius norm: err ( P , Q ) = || R − PQ ⊤ || 2 F = u,i ( r ui − p u q i ⊤ ) 2 . Η ελαχιστοποίηση αυτού του σφάλματος είναι ισοδύναμη με τη διάσπαση σε ιδιοτιμές ( Singular V alue Decomposition , SVD) του μητρώου R [ 20 ]: R = U Σ V ⊤ , όπου U είναι το | U | × n μητρώο που περιέχει τα αριστερά ιδιοδιανύσματα, V είναι το | I | × n μητρώο που περιέχει τα δεξιά ιδιοδιανύσματα, και Σ είναι το n × n διαγώνιο μητρώο με τις ιδιοτιμές. Συμβολίζουμε με Σ k , U k και V k τα μητρώα τα οποία προκύπτουν επιλέγοντας ένα υποσύνολο με τις k μεγαλύτερες ιδιοτιμές και τα αντίστοιχα ιδιοδιανύσματα, το παραγοντο- ποιημένο μητρώο χρηστών και το παραγοντοποιημένο μητρώο αντικειμένων αντιστοιχούν σε P = U k Σ 1/2 k και Q = V k Σ 1/2 k αντίστοιχα. Μόλις υπολογιστούν τα P και Q , η κλασική model-based πρόβλεψη μιας βαθμολογίας r ui είναι: r ui = p u q i ⊤ Ωστόσο, υπάρχει ένα σημαντικό πρόβλημα στην εφαρμογή του SVD στο μητρώο με τις βαθ- μολογίες R : οι περισσότερες τιμές r ui του R δεν έχουν οριστεί, καθώς είναι πολύ πιθανό να μην έχει δοθεί κάποια βαθμολογία στο i από τον u . Α ν και είναι δυνατό να τεθεί μία καθορι- σμένη τιμή στο r ui , όπως αναφέρθηκε και παραπάνω, κάτι τέτοιο θα εισήγαγε κάποιου είδους προκατάληψη στα δεδομένα. Ακόμα πιο σημαντικ ό πρόβλημα είναι ότι κάτι τέτοιο θα οδηγούσε στο να κάνει πυκνό το μεγάλο μητρώο R , και κατ’ επέκταση να καταστήσει μη πρακτική την SVD διάσπαση του R . Κοινή λύση σε αυτό το πρόβλημα αποτελεί το να μάθουν τα P και Q να χρησιμοποιούν μόνο τις γνωστές βαθμολογίες [ 4 , 29 , 52 , 53 ]: err ( P , Q ) = r ui ∈ R ( r ui − p u q i ⊤ ) 2 + λ ( || p u || 2 + || q i || 2 ) , όπου λ είναι μία παράμετρος η οποία ελέγχει το επίπεδο της κανονικοποίησης. Στις συστάσεις που βασίζ ονται στη γειτνίαση, μπορεί να χρησιμοποιηθεί η ίδια αρχή για τον υπολογισμό της ομοιότητας ανάμεσα σε χρήστες ή αντικείμενα στο λανθάνοντα χ ώρο [ 5 ]. Αυτό Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 17 μπορεί να συμβεί λύνοντας το ακ όλουθο πρόβλημα: err ( P , Q ) = r ui ∈ R ( z ui − p u q i ⊤ ) 2 υπό τους περιορισμούς: || p u || = 1 , ∀ u ∈ U , || q i || = 1 , ∀ i ∈ I , όπου z ui είναι η βαθμολογία r ui κανονικ οποιημένη στο διάστημα [ − 1 , 1] . Γ ια παράδειγμα, αν r min και r max είναι η ελάχιστη και μέγιστη τιμή αντίστοιχα στο αρχικό σύνολο βαθμολογιών, z ui = r ui − ¯ r u r max − r min . Αυτό το πρόβλημα αντιστοιχεί στην εύρεση, για κάθε χρήστη u και αντικείμενο i , συντεταγμέ- νων στην επιφάνεια της k -διάστασης μοναδιαίας σφαίρας έτσι ώστε ο u να δώσει μία υψηλή βαθμολογία στο i αν οι συντεταγμένες τους είναι κοντά μεταξύ τους στην επιφάνεια. Α ν δύο χρήστες u και v είναι γειτονικοί στην επιφάνεια, τότε θα δώσουν παρόμοιες βαθμολογίες στα ίδια αντικείμενα, και έτσι, η ομοιότητα ανάμεσα σε αυτούς τους χρήστες μπορεί να υπολογιστεί ως w uv = p u p v ⊤ . Α ντίστοιχα, η ομοιότητα ανάμεσα σε δύο αντικείμενα i και j μπορεί να υπολογιστεί ως w ij = q i q j ⊤ . 2.2.2 Διάσπαση του μητρώου ομοιοτήτων Η βασική αρχή αυτής της δεύτερης dimensionality reduction προσέγγισης είναι η ίδια με της προηγούμενης: διάσπαση του μητρώου στους πρωταρχικούς του παράγοντες οι οποίοι αποτε- λούν την προβολή των χρηστών ή των αντικειμένων στον λανθάνοντα χώρο. Ωστόσο, αντί να διασπαστεί το μητρώο βαθμολογιών, διασπάται ένα αραιό μητρώο ομοιοτήτων. Έστω W ένα συμμετρικό μητρώο διάστασης n το οποίο αποτελείται από ομοιότητες είτε χρηστών είτε αντικειμένων. Θα υποθέσουμε την προηγούμενη περίπτωση. Γ ια ακόμα μία φορά, θέλουμε να προσεγγίσουμε το W με ένα μητρώο Ŵ = PP ⊤ μικρότερης διάστασης k < n ελαχιστοποιώντας την ακόλουθη ποσότητα: err ( P ) = || R − PP ⊤ || 2 F = u,v ( w uv − p u p v ⊤ ) 2 . Τ ο μητρώο Ŵ είναι μία “συμπιεσμένη” έκδοση του W η οποία είναι λιγότερη αραιή σε σχέση με το W . Όπως και προηγουμένως, η εύρεση του μητρώου παραγόντων P είναι ισοδύναμη με Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 18 τον υπολογισμό των ιδιοτιμών του W : W = V Λ V ⊤ όπου Λ είναι ένα διαγώνιο μητρώο που περιέχει τις | U | ιδιοτιμές του W , και V είναι ένα | U | × | U | ορθογώνιο μητρώο που περιέχει τα αντίστοιχα ιδιοδιανύσματα. Έστω V k ένα μητρώο που σχη- ματίζεται από τα k κύρια (κανονικοποιημένα) ιδιοδιανύσματα του W , που αντιστοιχούν στους άξ ονες του λανθάνοντα υποχώρου διάστασης k . Οι συντεταγμένες p u ∈ R k ενός χρήστη u σε αυτόν τον υποχώρο δίνεται από την u -οστή γραμμή του μητρώου P = V k Λ 1/2 k . Επιπλέον, οι ομοιότητες χρηστών που υπολογίζονται σε αυτόν το λανθάνοντα υποχώρο δίνονται από το μη- τρώο W ′ = PP ⊤ = V k Λ k V k ⊤ 2.3 Graph-Based Models Στις graph-based προσεγγίσεις, τα δεδομένα αναπαρίστανται από ένα γράφο όπου οι κόμ- βοι είναι χρήστες, αντικείμενα ή και τα δύο, και οι ακμές αναπαριστούν τις αλληλεπιδράσεις ή ομοιότητες ανάμεσα στους χρήστες και τα αντικείμενα. Για παράδειγμα, στο Σχήμα 2.3 , τα δε- δομένα μοντελοποιούνται ως ένα διμερές γράφημα όπου τα δύο σύνολα ακμών αναπαριστούν χρήστες και αντικείμενα, και μία ακμή συνδέει το χρήστη u με το αντικείμενο i αν υπάρχει βαθ- μολογία στο σύστημα που έχει δοθεί στο i από τον u . Σ την ακμή μπορεί επίσης να αποδοθεί ένα βάρος, όπως η τιμή της αντίστοιχης βαθμολογίας. Σε ένα άλλο μοντέλο, οι κόμβοι μπορεί να αναπαριστούν είτε χρήστες είτε αντικείμενα, και μία ακμή συνδέει δύο κόμβους αν οι βαθμολο- γίες που αντιστοιχούν στους δύο αυτούς κόμβους είναι επαρκώς σχετιζόμενες. Τ ο βάρος αυτής της ακμής μπορεί να είναι η αντίστοιχη τιμή συσχέτισης [ 17 ]. Σε αυτά τα μοντέλα, οι στάνταρ προσεγγίσεις που βασίζονται στις συσχετίσεις προβλέπουν τη βαθμολογία ενός χρήστη u για ένα αντικείμενο i χρησιμοποιώντας μόνο τους κόμβους οι οποίοι συνδέονται απευθείας με τον u ή το i . Από την άλλη μεριά, οι graph-based προσεγγίσεις επιτρέπουν σε κόμβους οι οποίοι δε συνδέονται απευθείας να επηρεάζουν ο ένας τον άλλο δια- δίδοντας πληροφορίες κατά μήκος των ακμών του γραφήματος. Όσο μεγαλύτερο είναι το βάρος μιας ακμής, τόσο περισσότερες πληροφορίες επιτρέπεται να περάσουν δια μέσω αυτής. Επίσης, η επιρροή ενός κόμβου σε έναν άλλο πρέπει να είναι μικρότερη αν οι δύο κόμβοι είναι πολύ μακριά στο γράφημα. Αυτές οι δύο ιδιότητες, γνωστές ως propagation και attenuation [ 23 , 24 ], παρατηρούνται συχνά σε graph-based μέτρα ομοιότητας. Οι μεταβατικές συσχετίσεις που συλλαμβάνονται από τις graph-based μεθόδους μπορούν να χρησιμοποιηθούν για τη σύσταση αντικειμένων με δύο διαφορετικούς τρόπους. Στην πρώτη Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 19 Σ 2.3: Διμερής γράφος ο οποίος παρουσιάζει τις βαθμολογίες των χρηστών από τον Πί- νακα 2.1 . Οι βαθμολογίες αντιστοιχούν σε βάρη των ακμών. [ 32 ]. προσέγγιση, η εγγύτητα ενός χρήστη u σε ένα αντικείμενο i στο γράφημα χρησιμοποιείται απευ- θείας για την αξιολόγηση της βαθμολογίας του u στο i [ 18 , 23 , 24 ]. Ακολουθώντας αυτήν την ιδέα, τα αντικείμενα που συστήνονται από το σύστημα στον u είναι εκείνα τα οποία είναι τα πιο “κοντινά” στον u στο γράφημα. Από την άλλη μεριά, η δεύτερη προσέγγιση θεωρεί την εγγύτητα δύο κόμβων χρηστών ή αντικειμένων στο γράφο ως μέτρο ομοιότητας, και χρησιμοποιεί αυτήν την ομοιότητα ως τα βάρη μια μεθόδου συστάσεων που βασίζεται στη γειτονικ ότητα [ 18 , 35 ]. 2.3.1 Path-based ομοιότητα Σε αυτές τις μεθόδους, η απόσταση ανάμεσα σε δύο κόμβους του γράφου εκτιμάται ως συ- νάρτηση του πλήθους των μονοπατιών που συνδέουν τους δύο κόμβους, καθώς και το μήκος αυτών των μονοπατιών. Συντομότερο μονοπάτι. Στο [ 1 ] περιγράφεται μία μέθοδος συστάσεων η οποία υπολογίζει την ομοιότητα ανάμεσα σε δύο χρήστες με βάση τη μικρότερη απόσταση μεταξύ τους σε ένα γράφο. Σε αυτήν τη μέθοδο, τα δεδομένα μοντελοποιούνται ως ένας κατευθυνόμενος γράφος του οποίου οι κόμβοι είναι χρήστες και οι ακμές καθορίζ ονται με βάση τις έννοιες horting και pr edictability . Με την έννοια horting εννοούμε μία σχέση ανάμεσα σε δύο χρήστες η οποία ικανοποιείται αν αυτοί οι χρήστες έχουν βαθμολογήσει παρόμοια αντικείμενα. Από την άλλη μεριά, με την έννοια predictability αναφερόμαστε σε μία πιο ισχυρή ιδιότητα η οποία απαιτεί επιπλέον οι βαθμολογίες του ενός χρήστη να είναι παρόμοιες με αυτές του άλλου. Σύνολο μονοπατιών. Εναλλακτικά, για να εκτιμηθεί η συμβατότητα ενός χρήστη και ενός αντικειμένου σε ένα διμερή γράφο, μπορεί να χρησιμοποιηθεί ο αριθμός των μονοπατιών ανά- μεσά τους [ 24 ]. Έστω R το | U | × | I | μητρώο βαθμολογιών όπου r ui ισούται με 1 αν ο χρήστης u Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 20 έχει βαθμολογήσει το αντικείμενο i , και 0 αλλιώς. Τ ο μητρώο γειτνίασης A του διμερούς γράφου μπορεί να οριστεί από το R ως A = 0 R ⊤ R 0 . Σε αυτήν την προσέγγιση, η σχέση ανάμεσα σε ένα χρήστη u και ένα αντικείμενο i ορίζεται ως το άθροισμα των βαρών όλων των διακριτών μονοπατιών που συνδέουν τον u με τον v , όπου v ένας δεύτερος χρήστης (επιτρέποντας στους κόμβους να εμφανίζ ονται περισσότερες από μία φορές στο μονοπάτι), των οποίων το μήκος δεν είναι μεγαλύτερο από ένα μέγιστο μήκος K . Να σημειωθεί ότι από τη στιγμή που ο γράφος είναι διμερής, το K πρέπει να είναι περιττός αριθμός. Προκειμένου να ελαττωθεί η συμβολή των μεγαλύτερων μονοπατιών, το βάρος που δίνεται σε ένα μονοπάτι μήκους k ορίζεται ως α k , όπου α ∈ [0 , 1] . Με βάση το γεγονός ότι ο αριθμός των μονοπατιών μήκους k μεταξύ ζευγαριών από κόμβους δίνεται από το A k , το μητρώο συσχετίσεων χρηστών-αντικειμένων S k είναι S K = K k =1 α k A k = ( I − α A ) − 1 ( α A − α K A K ) . Αυτή η μέθοδος υπολογισμού αποστάσεων ανάμεσα σε κόμβους ενός γράφου είναι γνωστή ως μέτρο Katz [ 26 ]. Στα συστήματα συστάσεων τα οποία έχουν μεγάλο αριθμό χρηστών και αντικειμένων, ο υπο- λογισμός της παραπάνω τιμής συσχέτισης, αλλά και άλλων αντίστοιχων τιμών, ίσως απαιτεί εκτεταμένους υπολογιστικούς πόρους. Για την αντιμετώπιση αυτών των περιορισμών, στο [ 24 ] χρησιμοποιήθηκαν τεχνικές διάδοσης ενεργοποίησης (spreading activation techniques) [ 14 ]. Ου- σιαστικά, τέτοιες τεχνικές λειτουργούν ως εξής: αρχικά ενεργοποιούν ένα επιλεγμένο υποσύ- νολο κόμβων ως κόμβους εκκίνησης, και στη συνέχεια επαναληπτικά ενεργοποιούν τους κόμ- βους που προσπελάζ ονται απευθείας από τους κόμβους που είναι ήδη ενεργοί, μέχρι να υπάρξει κάποιο κριτήριο σύγκλισης. 2.3.2 Random walk ομοιότητα Μία δεύτερη μέθοδος υπολογισμού της ομοιότητας είναι η random walk ομοιότητα, όπου οι μεταβατικές σχέσεις ορίζονται μέσα σε ένα πιθανοτικό πλαίσιο. Σε αυτό το πλαίσιο, η ομοιότητα ή συνάφεια ανάμεσα σε χρήστες ή αντικείμενα εκτιμάται ως η πιθανότητα προσπέλασης αυτών των κ όμβων σε έναν τυχαίο περίπατο. Τυπικά, αυτό μπορεί να περιγραφεί με μία πρώτης τάξης Μαρκοβιανή διαδικασία με μητρώο πιθανοτήτων μετάβασης P ∈ R n × n [ 17 ]. Η πιθανότητα μετάβασης από την κατάσταση i στη j σε οποιοδήποτε χρονικό βήμα t είναι p ij = Pr ( s ( t + 1) = j | s ( t ) = i ) . Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 21 Έστω π ( t ) το διάνυσμα το οποίο περιέχει την κατανομή καταστάσεων για το βήμα t , έτσι ώστε π i ( t ) = Pr ( s ( t ) = i ) . Η εξέλιξη της Μαρκοβιανής αλ υσίδας χαρακτηρίζεται από π ( t + 1) = P ⊤ π ( t ) . Επιπλέον, υπό την προϋπόθεση ότι το P είναι στοχαστικό κατά γραμμές, δηλαδή j p ij για όλα τα i , η διαδικασία συγκλίνει σε ένα διάνυσμα σταθερής κατανομής π ( ∞ ) που αντιστοιχεί στο θετικό ιδιοδιάνυσμα του P ⊤ με ιδιοτιμή 1 . Αυτή η διαδικασία περιγράφεται συχνά με τη μορφή ενός γράφου με βάρη ο οποίος έχει έναν κ όμβο για κάθε κατάσταση, και όπου η πιθανότητα να υπάρξει μετάβαση από έναν κόμβο σε ένα διπλανό κόμβο δίνεται από το βάρος της ακμής που συνδέει αυτούς τους κόμβους. ItemRank. Μία μέθοδος συστάσεων η οποία βασίζεται στον αλγόριθμο PageRank για την τα- ξινόμηση ιστοσελίδων [ 9 ], είναι ο ItemRank [ 23 ]. Αυτή η προσέγγιση ταξινομεί τις προτιμήσεις ενός χρήστη u για νέα αντικείμενα i με βάση την πιθανότητα ο u να επισκεφτεί το i κατά τη διάρκεια ενός τυχαίου περιπάτου σε ένα γράφο όπου οι κόμβοι αντιστοιχούν στα αντικείμενα του συστήματος και οι ακμές συνδέουν αντικείμενα που έχουν βαθμολογηθεί από κοινούς χρήστες. Τ α βάρη των ακμών δίνονται από το | I | × | I | μητρώο πιθανοτήτων μετάβασης P για το οποίο p ij = | U ij | / | U i | είναι η αναμενόμενη δεσμευμένη πιθανότητα ένας χρήστης να βαθμολογήσει ένα αντικείμενο j αν έχει βαθμολογήσει ένα αντικείμενο i . Όπως και στον PageRank, ο τυχαίος περιηγητής μπορεί σε οποιοδήποτε βήμα t , είτε χρησι- μοποιώντας το P να μεταπηδήσει σε ένα γειτονικ ό κόμβο με πιθανότητα α , είτε να “τηλεμετα- φερθεί” σε οποιοδήποτε κόμβο με πιθανότητα (1 − α ) . Έστω r u η u -οστή γραμμή του μητρώου με τις βαθμολογίες R . Τ ότε η κατανομή πιθανότητας του χρήστη u να τηλεμεταφερθεί σε άλλους κόμβους δίνεται από το διάνυσμα d u = r u / || r u || . Με βάση αυτούς τους ορισμούς, το διάνυσμα σταθερής κατανομής του χρήστη u κατά το βήμα t + 1 μπορεί να εκφραστεί αναδρομικά ως π u ( t + 1) = α P ⊤ π u ( t ) + (1 − α ) d u . (2.1) Γ ια πρακτικούς λόγους, το π u ( ∞ ) συνήθως υπολογίζεται από μία διαδικασία η οποία πρώτα αρχικοποιεί την κατανομή ως ομοιόμορφη, δηλαδή π u (0) = 1 n 1 n , και στη συνέχεια επαναλη- πτικά ενημερώνει το π u , χρησιμοποιώντας την 2.1 , έως ότου συγκλίνει. Μόλις το π u ( ∞ ) έχει υπολογιστεί, το σύστημα συστήνει στον u το αντικείμενο i το οποίο έχει το υψηλότερο π ui . 2.4 Συμπεράσματα Παρότι εφαρμόζ ονται με επιτυχία σε πολλές εφαρμογές, οι στάνταρ CF τεχνικές αντιμετω- πίζ ουν πολλές προκλήσεις οι οποίες δεν έχουν επιλυθεί ακόμα. Μία από τις σημαντικότερες, Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 22 όπως αναφέρθηκε και παραπάνω, είναι η αραιότητα , ένα πολύ σύνηθες πρόβλημα το οποίο προ- κύπτει όταν τα διαθέσιμα δεδομένα δεν επαρκούν για την αναγνώριση παρόμοιων στοιχείων [ 8 , 38 , 40 , 43 , 44 ]. Η αραιότητα είναι ένα εγγενές χαρακτηριστικ ό των συστημάτων συστά- σεων διότι στη μεγαλύτερη πλειοψηφία των πραγματικών εφαρμογών οι χρήστες αλληλεπιδρούν μόνο με ένα μικρό ποσοστό των διαθέσιμων αντικειμένων, και την ίδια στιγμή νέοι χρήστες και νέα αντικείμενα προστίθενται τακτικά στο σύστημα. Οι παραδοσιακές CF τεχνικές, όπως τα neighborhood models, παρουσιάζ ουν ευπάθεια στην αραιότητα, ένα γεγονός το οποίο περιορί- ζει την ποιότητα των συστάσεων που παράγουν [ 17 ]. Α νάμεσα στις πιο υποσχόμενες προσεγγίσεις για την αντιμετώπιση των προβλημάτων που σχετίζ ονται με αυτό το χαρακτηριστικ ό είναι τα Latent Factor και Graph-Based μοντέλα. Ωστόσο, παρότι οι τεχνικές αυτές είναι πολλά υποσχ όμενες όσον αφορά στο χειρισμό των προβλημάτων που σχετίζ ονται με την αραιότητα, αντιμετωπίζουν σοβαρά υπολογιστικά θέματα και περιορι- σμούς επεκτασιμότητας, καθώς ο αριθμός των χρηστών και των αντικειμένων αυξάνεται ρα- γδαία στις σύγχρονες εφαρμογές ηλεκτρονικού εμπορίου. Οι Nikolakopoulos et al. [ 38 , 40 , 43 , 44 ] για την αντιμετώπιση της αραιότητας και των προ- βλημάτων που προκαλεί η ύπαρξή της, εκμεταλλεύονται την ιεραρχική δομή του χώρου αντι- κειμένων [ 37 ] και τα μεταδεδομένα από τα datasets, και προτείνουν προσεγγίσεις οι οποίες τα πηγαίνουν ιδιαίτερα καλά, ενώ ταυτόχρονα παραμένουν υπολογιστικά αποδοτικές και επεκτάσι- μες. Πιο συγκεκριμένα, οι συγγραφείς στο [ 44 ] πρότειναν τον αλγόριθμο Hierar chical Itemspace Rank (HIR), ο οποίος ανακαλύπτει σχέσεις ανάμεσα στα αντικείμενα μέσα από τη διάσπαση του χώρου αντικειμένων. Ορίζει μπλοκ από στενά σχετιζ όμενα στοιχεία και χρησιμοποιώντας αυτή τη νέα σύνθεση εκμεταλλεύεται τις ιδιότητες που είναι κρυμμένες στη δομή του χώρου αντικει- μένων. Επιπρόσθετα, οι συγγραφείς προτείνουν [ 38 , 40 ] ένα γ ενικό τρόπο αντιμετώπισης της αραιό- τητας και των συνεπειών της μέσω της μεθόδου NCDREC . Πρόκειται για μία αποτελεσματική και επεκτάσιμη προσέγγιση η οποία συνδυάζει την αποτελεσματικότητα των latent factor μοντέ- λων με την ικανότητα των graph-based μοντέλων να διατηρούν τις “τοπικές” σχέσεις ανάμεσα στα στοιχεία. Κ αι πάλι βασιζόμενοι στην ιδέα της Decomposability [ 37 ], μέσα από τη διάσπαση του χώρου αντικειμένων ορίζ ουν μπλοκ από στενά σχετιζόμενα στοιχεία και εισάγουν τα αντί- στοιχα έμμεσα συστατικά εγγύτητας τα οποία έχουν ως στόχο να γεμίσουν τα κενά στα δεδομένα που προκαλεί η αραιότητα. Τ έλος, μελετούν τις θεωρητικές ιδιότητες αυτής της διάσπασης και παρουσιάζ ουν τις επαρκείς συνθήκες που εγγυώνται πλήρη κάλυψη του χώρου αντικειμένων ακόμα και σε καταστάσεις έντονης αραιότητας. Ο στόχος μας σε αυτήν την εργασία είναι να βρεθεί μία εναλλακτική μέθοδος συστάσεων η οποία να συνδυάζει υπολογιστική αποδοτικότητα και να μην παρουσιάζει ευαισθησία στην αραιότητα, χωρίς ταυτόχρονα να θυσιάζει την top-N ποιότητα. Ακολουθώντας την προσέγγιση του PureSVD, επικεντρωνόμαστε κι εμείς στη μείωση της διάστασης του προβλήματος, αλλά Κεφάλαιο 2. Συστήματα Συστάσεων Συνεργατικής Διήθησης 23 με πιο συμφέρων τρόπο. Έτσι, προτείνουμε τη δημιουργία ενός latent factor μοντέλου εκμε- ταλλευόμενοι μία υπολογιστικά αποδοτική διαδικασία Krylov υποχώρου, η οποία ονομάζεται Lanczos method . Κεφάλαιο 3 Lanczos Latent Factor Recommender 3.1 Latent Factor Models Η βασική υπόθεση πίσω από τη χρήση των latent factor μοντέλων για τη δημιουργία συστη- μάτων συστάσεων είναι ότι οι προτιμήσεις των χρηστών επηρεάζ ονται από ένα σύνολο “κρυμ- μένων παραγόντων προτίμησης” οι οποίοι είναι συνήθως πολύ συγκεκριμένοι στον τομέα των συστάσεων [ 30 ]. Αυτοί οι παράγοντες είναι γενικά μη εμφανείς και μπορεί να μην είναι απαραί- τητα διαισθητικά κατανοητοί. Ωστόσο, οι Latent Factor αλγόριθμοι μπορούν να συμπεράνουν αυτούς τους παράγοντες από την ανατροφοδότηση του χρήστη όπως αυτή αντικατοπτρίζεται στις βαθμολογίες. 3.1.1 PureSVD Ένα από τα πιο επιτυχημένα παραδείγματα latent factor αλγορίθμων για top-N συστάσεις, είναι ο PureSVD. Ο αλγόριθμος PureSVD θεωρεί μηδενικές όλες τις τιμές που λείπουν από το μητρώο με τις βαθμολογίες, και παράγ ει συστάσεις προσεγγίζ οντας το user-item rating μητρώο R με την παρακάτω παραγοντοποίηση: ˆ R = U Σ Q ⊤ όπου, U είναι ένα n × f ορθοκανονικό μητρώο, Q είναι ένα m × f ορθοκανονικ ό μητρώο, και Σ είναι ένα f × f διαγώνιο μητρώο που περιέχει τις πρώτες f ιδιάζουσες τιμές. Οι γραμμές του μητρώου ˆ R περιλαμβάνουν τα διανύσματα συστάσεων για κάθε χρήστη στο σύστημα. Να σημειωθεί ότι παρότι οι πραγματικές τιμές του μητρώου ˆ R δεν έχουν νόημα ως βαθμολογίες, εισάγουν μία διάταξη στα αντικείμενα η οποία είναι αρκετή για τη σύσταση top-N λιστών. 25 Κεφάλαιο 3. Lanczos Latent Factor Recommender 26 Οι συγγραφείς στο [ 13 ], μετά την αξιολόγηση της απόδοσης διαφόρων latent factor-based αλγορίθμων και neighborhood μοντέλων, βρήκαν ότι ο PureSVD ήταν ικανός να παράγει κα- λύτερες top-N συστάσεις συγκριτικά με εξελιγμένες matrix factorization μεθόδους [ 29 , 31 ] και άλλες διάσημες CF τεχνικές. Ωστόσο, παρά τα πολ ύ καλά του αποτελέσματα, ο PureSVD περι- λαμβάνει τον υπολογισμό του truncated singular value decomposition του μητρώου με τις βαθ- μολογίες, ο οποίος, λόγω του αυξ ανόμενου αριθμού χρηστών και αντικειμένων στις μοντέρνες εφαρμογές ηλεκτρονικού εμπορίου, θα μπορούσε να επιφέρει απαγορευτικά μεγάλο υπολογι- στικό βάρος. 3.2 Τ ο μοντέλο LLFR Μέθοδος Lanczos. Η μέθοδος Lanczos χρησιμοποιήθηκε αρχικά σε εφαρμογές γραμμικής άλγεβρας για τον υπολογισμό των ιδιοδιανυσμάτων ή/και των ιδιαζ ουσών τριπλετών μεγάλων αραιών μητρώων [ 21 ]. Από ποιοτική άποψη, οι Blom και Ruhe [ 7 ] πρότειναν τη χρήση ενός αλγορίθμου στενά συνδεδεμένου με τη μέθοδο Latent Semantic Indexing ο οποίος χρησιμοποιεί τη Lanczos τεχνική διδιαγωνοποίησης για να παράξει δύο σύνολα διανυσμάτων τα οποία ουσια- στικά αντικ αθιστούν τα αριστερά και δεξιά ιδιάζ οντα διανύσματα, μειώνοντας το υπολογιστικό κόστος. Οι Chen and Saad [ 12 ] εξέτασαν πρόσφατα τη χρήση των Lanczos διανυσμάτων σε εφαρμο- γές όπου το κύριο ζ ήτημα μετατίθεται στον υπολογισμό ενός γινομένου μητρώου-διανύσματος στις κύριες ιδιάζουσες κατευθύνσεις του μητρώου δεδομένων. Έδειξαν την αποτελεσματικότητα αυτής της προσέγγισης σε δύο διαφορετικά προβλήματα από το χ ώρο της ανάκτησης πληροφο- ρίας και αναγνώρισης προσώπου. Απ’ όσο είμαστε σε θέση να γνωρίζουμε, πρόκειται για την πρώτη εργασία η οποία προτεί- νει τη χρήση των Lanczos διανυσμάτων για το πρόβλημα των top-N συστάσεων. Επιπλέον, ο στόχος μας ήταν διαφορετικός από τους παραπάνω, υπό την έννοια ότι εμείς εφαρμόζουμε τη μέθοδο Lanczos απευθείας σε ένα μητρώο ομοιότητας αντικειμένων χωρίς να προσπαθήσουμε να ακολουθήσουμε την προσέγγιση του PureSVD. Ορισμοί. Έστω U = { u 1 , u 2 , . . . , u n } ένα σύνολο από χρήστες και V = { v 1 , v 2 , . . . , v m } ένα σύνολο από αντικείμενα . Έστω R ένα σύνολο από πλειάδες t ij = ( u i , v j , r ij ) , όπου r ij είναι ένας μη αρνητικός αριθμός στον οποίο θα αναφερόμαστε ως η βαθμολογία που δίνεται από το χρήστη u i για το αντικείμενο v j , και έστω R ∈ R n × m ένα μητρώο του οποίου το ij th στοιχείο περιέχει τη βαθμολογία r ij αν η πλειάδα t ij ανήκει στο R , και μηδέν αλλιώς. Αυτές οι βαθμολογίες μπορούν να προέρχονται είτε από την ξεκάθαρη απόκριση του χρήστη είτε να συμπεραίνονται από τη συμπεριφορά και αλληλεπίδραση του χρήστη με το σύστημα. Επίσης, Κεφάλαιο 3. Lanczos Latent Factor Recommender 27 θεωρούμε μια διαμέριση {L , T } των βαθμολογιών σε ένα σύνολο εκπαίδευσης - training set L και ένα σύνολο ελέγχου - test set T . Για κάθε χρήστη u i , δηλώνουμε ως L i το σύνολο των αντικειμένων που έχουν βαθμολογηθεί από τον u i στο L . Πιο συγκεκριμένα: L i ≜ { v k : t ik ∈ L} Μητρώο Συσχετίσεων μεταξύ Α ντικειμένων (Inter -item Correlation Matrix) A . Αρχικά εί- ναι απαραίτητο να ορίσουμε ένα μητρώο το οποίο να συλλαμβάνει τις ομοιότητες ανάμεσα στα στοιχεία του χώρου αντικειμένων. Έτσι, ορίζ ουμε ένα συμμετρικό μητρώο A ∈ R m × m του οποίου το στοιχείο ij th δίνεται από: A kℓ ≜ ∥ r k ∥∥ r ℓ ∥|U kℓ | , (3.1) όπου ∥ r j ∥ είναι η ευκλείδεια νόρμα της στήλης που αντιστοιχεί στο αντικείμενο v j του μητρώου βαθμολογιών, και το U kℓ ⊆ U υποδηλώνει το σύνολο των χρηστών που έχουν βαθμολογήσει και τα δύο αντικείμενα v k και v ℓ , δηλαδή: U kℓ ≜ { u s : ( v k ∈ L s ) ∧ ( v ℓ ∈ L s ) } για k = ℓ ∅ αλλιώς (3.2) Ο στόχος μας είναι να διασπάσουμε το μητρώο στους κύριους παράγοντές του οι οποίοι ανα- παριστούν προβολές των διανυσμάτων συσχέτισης μεταξύ των αντικειμένων στο λανθάνοντα χώρο. Κατασκευάζ οντας το Λανθάνον Μοντέλο. Δοθέντος ενός μητρώου X και ενός αρχικού μο- ναδιαίου διανύσματος q , ο αντίστοιχος Krylov υποχ ώρος δίνεται από K f ( X , q ) = range { q , Xq , X 2 q , . . . , X f − 1 q } (3.3) Οι μέθοδοι υποχώρου Krylov σχηματίζ οντας μία ορθογώνια βάση για τον K f , μπορούν να χρη- σιμοποιηθούν για την επίλυση διαφόρων ειδών αριθμητικών προβλημάτων [ 21 ]. Η γενική λ ύση για την εύρεση των ιδιοτιμών/ιδιοδιανυσμάτων που χρησιμοποιεί τον K f ονομάζεται μέθοδος Arnoldi και χρησιμοποιεί αναδρομικά όλες τις διαστάσεις του K f σε κάθε επανάληψη. Η συμμε- τρική εκ δοχή της Arnoldi ονομάζεται μέθοδος Lanczos και το βασικό της χαρακτηριστικ ό είναι ότι εκμεταλλεύεται τη συμμετρία του αρχικού μητρώου και χρησιμοποιεί αναδρομή τριών όρων. Κ άτι τέτοιο καθιστά τη Lanczos ιδιαίτερα αρμοστή για εφαρμογές σε μεγάλα σύνολα δεδομένων (για περαιτέρω πληροφορίες βλ. [ 21 ]). Κεφάλαιο 3. Lanczos Latent Factor Recommender 28 3.3 Ο Αλγόριθμος LLFR Οι συγκεκριμένες ιδιότητες του μοντέλου μας (συμμετρία και αραιότητα), και το γεγονός ότι ενδιαφερόμαστε για συστάσεις που βασίζονται στην κατάταξη, η οποία μας δίνει την ευε- λιξία να μη νοιαζόμαστε για τις ακριβείς βαθμολογίες κατάταξης (είναι αρκετή η σωστή σειρά αντικειμένων), καθιστά την προσέγγιση Lanczos έναν ιδανικό υποψήφιο για την κατασκευή του λανθάνοντα χώρου και την αποδοτική παραγωγή λιστών συστάσεων. Επίσημα, για κάθε χρήστη u i ορίζ ουμε ένα προσωποποιημένο διάνυσμα συστάσεων το οποίο δίνεται από: π ⊤ i ≜ r ⊤ i QQ ⊤ (3.4) όπου r ⊤ i οι βαθμολογίες του χρήστη u i και Q ∈ R m × f είναι το μητρώο το οποίο περιλαμβάνει τα Lanczos διανύσματα που σχηματίζουν τη βάση του Krylov υποχώρου K f που αντιστοιχεί στο μητρώο συσχετίσεων μεταξύ αντικειμένων A . Ο πλήρης αλγόριθμος για τον υπολογισμό του μητρώου Q και το τελικό μητρώο συστάσεων Π για όλο το σύνολο των χρηστών δίνεται παρακάτω: Algorithm 1 Lanczos Latent Factor Recommender (LLFR) Είσοδος: Τ ο Μητρώο Συσχετίσεων μεταξύ αντικειμένων A ∈ R m × m , το Μητρώο Βαθμολο- γιών R ∈ R n × m , ένα τυχαίο μοναδιαίο διάνυσμα q 1 ∈ R m , και ο αριθμός των latent factors f . Έξ οδος: Τ ο μητρώο Π ∈ R n × m του οποίου οι γραμμές είναι τα διανύσματα συστάσεων για κάθε χρήστη. 1: q 0 ← 0 2: β 1 ← 0 3: for i ← 1 , ..., f do 4: w ← Aq i − β i q i − 1 5: α i ← w ⊤ q i 6: w ← w − α i q i 7: β i +1 ← ∥ w ∥ 2 8: q i + 1 ← w / β i +1 9: end for 10: return Π ← RQQ ⊤ 3.3.1 Υπολογιστικ ά Θέματα Ο αλγόριθμος LLFR είναι κατά πολύ πιο οικονομικός και σε χρήση μνήμης και σε κατανά- λωση χρόνου συγκριτικά με τον PureSVD. Πιο συγκεκριμένα, ο LLFR χρειάζεται O (( nnz + m ) f ) χρόνο για αραιά μητρώα (όπου nnz είναι ο αριθμός των μη μηδενικών στοιχείων του A ), ο οποίος είναι ο χρόνος για τον υπολογισμό των Lanczos διανυσμάτων [ 12 , 21 ]. Να σημειωθεί ότι σε πραγματικές εφαρμογές, δε χρειάζεται ο εκ των προτέρων υπολογισμός και η αποθήκευση του μητρώου Π . Οι αντίστοιχες γραμμές του μπορούν να ανακατασκευαστούν στη στιγμή, όποτε χρειάζεται, από το μικρής διάστασης μητρώο Q . Κεφάλαιο 3. Lanczos Latent Factor Recommender 29 0 100 200 300 400 500 600 0 500 1 , 000 Latent F actors Time (sec) LLFR PureSVD Σ 3.1: Υπολογιστικοί έλεγχοι Τ ο Σχήμα 3.1 παρουσιάζει το χρόνο υπολογισμού ως συνάρτηση του αριθμού των latent factors για τους αλγόριθμους LLFR και PureSVD όταν εφαρμόστηκαν στο MovieLens10M σύνολο δεδομένων 1 . Για τον υπολογισμό του PureSVD χρησιμοποιήθηκε η βελτιστοποιημένη sparse svd συνάρτηση svds της Matlab . Η διαδικασία LLFR υλοποιήθηκε επίσης σε Matlab για να υπάρχει δικαιοσύνη στις συγκρίσεις. Όλα τα πειράματα εκτελέστηκαν σε Linux σύστημα με 64bit μηχανή και 20GB RAM. Τ ο σχήμα 3.1 κάνει φανερό ότι το υπολογιστικό βάρος του LLFR είναι σημαντικά μικρότερο από αυτό του PureSVD. Επιπρόσθετα, όπως θα δούμε στο επόμενο κεφάλαιο, αυτό το πλεονέκτημα υφίσταται χωρίς να θυσιαστεί η ποιότητα των αποτε- λεσμάτων. Π 3.1: Σύνολα Δεδομένων Σύνολο Δεδομένων #Χρήστες #Α ντικείμενα #Βαθμολογίες MovieLens10M 2 71,567 10,681 10,000,054 Yahoo!Music 3 1,823,179 136,736 717,872,016 1 Περισσότερες πληροφορίες για τα σύνολα δεδομένων που χρησιμοποιήθηκαν σε αυτήν την εργασία παρουσιά- ζ ονται στον Πίνακα 3.1 . 2 http://grouplens.org/ 3 http://webscope.sandbox.yahoo.com Κεφάλαιο 4 Πειραματική Αξιολόγηση 4.1 Datasets Τ α σύνολα δεδομένων τα οποία χρησιμοποιήσαμε για τη διεξ αγωγή των πειραμάτων μας είναι τα MovieLens10M και Yahoo!Music . Η ερευνητική ομάδα GroupLens συγκέντρωσε και διαθέτει δεδομένα από το διαδικτυακό τόπο MovieLens 1 , μία online υπηρεσία συστάσεων ταινιών. Τ ο MovieLens10M που χρησιμο- ποιήσαμε, όπως φαίνεται και στον Πίνακα 3.1 , περιέχει 71 , 567 χρήστες, 10 , 681 αντικείμενα και συνολικά 10 , 000 , 054 βαθμολογίες. Οι χρήστες που συμπεριλήφθηκαν επιλέχθηκαν με τυχαίο τρόπο, και όλοι έχουν βαθμολογήσει τουλάχιστον 20 ταινίες. Στο συγκεκριμένο MovieLens σύ- νολο δεδομένων δεν περιλαμβάνεται οποιαδήποτε δημογραφική πληροφορία. Τ έλος, κάθε χρή- στης αναπαρίσταται από ένα id, και δεν παρέχεται καμία περεταίρω πληροφορία. Α ντίστοιχα, το R2 - Yahoo! Music αποτελείται από 717 , 872 , 016 βαθμολογίες για 136 , 736 αντικείμενα που δόθηκαν από 1 , 823 , 179 χρήστες των υπηρεσιών Y ahoo! Music. Τ ο Y ahoo! Music αποτελεί ένα στιγμιότυπο των προτιμήσεων της κοινότητας Y ahoo! Music για διάφορα τραγούδια. Τ α δεδομένα συλλέχθηκαν ανάμεσα στο 2002 και 2006. Κάθε τραγούδι του συνόλου συνοδεύεται από τα εξής χαρακτηριστικά: καλλιτέχνη, άλμπουμ, και κατηγορία. Οι χρήστες, τα τραγούδια, οι καλλιτέχνες και τα άλμπουμ αναπαρίστανται από τυχαία αριθμητικά αναγνωρι- στικά που τους έχ ουν αποδοθεί ώστε να μην αποκ αλύπτεται κ αμία αναγνωριστική πληροφορία. Τ α παραπάνω σύνολα δεδομένων χρειάστηκε να τα επεξεργαστούμε κατάλληλα προκειμένου να χρησιμοποιηθούν αποδοτικά στα πειράματά μας. 1 http://movielens.org 31 Κεφάλαιο 4. Πειραματική Αξιολόγηση 32 4.2 Μεθοδολογία κ αι διαδικ ασία πειραμάτων Προκειμένου να αξιολογήσουμε την απόδοση του LLFR στη σύσταση top-N αντικειμένων στους χρήστες, πραγματοποιούμε μια σειρά από πειράματα χρησιμοποιώντας το Yahoo!Music σύνολο δεδομένων. Συγκρίνουμε τον LLFR απέναντι στον PureSVD και σε ακόμα τέσσερις διάσημους graph- based top-N αλγόριθμους συστάσεων: τον average Commute T ime (CT) [ 18 ], τον Pseudo-Inverse of the user-item graph Laplacian (L † ) [ 19 ], τον Matrix For est Algorithm (MF A) [ 1 1 ], και τον ItemRank (IR) [ 23 ]. Ακολουθεί μία σύντομη περιγραφή για τον καθένα από τους παραπάνω. A verage Commute Time (CT). Ως average commute time n ( i, j ) ορίζεται ο μέσος αριθμός βημάτων τα οποία θα χρειαστεί ένας τυχαίος περιηγητής, ξεκινώντας από την κατάσταση i = j για να φτάσει στην κατάσταση j για πρώτη φορά και πίσω στην i . Ο average Commute T ime (CT) χρησιμοποιεί το average commute time n ( i, j ) για να ταξινομήσει τα στοιχεία του συνόλου που εξετάζεται, όπου i, j είναι στοιχεία της βάσης δεδομένων. Για παράδειγμα, εάν πρόκειται για σύσταση ταινιών σε ανθρώπους, τότε ο αλγόριθμος υπολογίζει το average commute time ανάμεσα σε ανθρώπους στοιχεία και ταινίες στοιχεία. Όσο πιο μικρό είναι το αποτέλεσμα τόσο πιο όμοια είναι τα δύο στοιχεία [ 18 ]. Α ν μετρήσουμε την απόσταση ανάμεσα στους κόμβους που αναπαριστούν ανθρώπους και ταινίες στο δοθέντα διμερή γράφο, μπορούμε να χρησιμοποι- ήσουμε αυτό το σκορ για την ταξινόμηση των ταινιών [ 23 ]. Pseudo-Inverse of the user-item graph Laplacian ( L † ). Τ ο μητρώο αυτό περιέχει τα εσω- τερικά γινόμενα των διανυσμάτων που αντιστοιχούν στους κόμβους σε έναν Ευκλείδειο χώρο όπου οι κόμβοι είναι διαχ ωρισμένοι με βάση το commute time [ 18 , 19 ]. Matrix Forest Algorithm (MF A). Τ ο MF A μητρώο περιέχει στοιχεία τα οποία παρέχ ουν επι- πλέον μέτρα ομοιότητας ανάμεσα στους κόμβους του γράφου ενσωματώνοντας μη κατευθυνό- μενα μονοπάτια, με βάση το matrix-forest θεώρημα [ 1 1 ]. ItemRank (IR). Πρόκειται για μία μέθοδο συστάσεων που βασίζεται στον αλγόριθμο PageRank, η οποία παράγει ένα εξατομικευμένο διάνυσμα βαθμολογιών για το σύνολο των αντικειμένων, χρησιμοποιώντας έναν τυχαίο περίπατο με επανεκκινήσεις σε ένα γράφο συσχετίσεων μεταξύ αντικειμένων. Πιο συγκεκριμένα, ταξινομεί τις προτιμήσεις ενός χρήστη u για νέα αντικείμενα i ως την πιθανότητα ο u να επισκεφτεί το i κατά τη διάρκεια ενός τυχαίου περιπάτου σε ένα Κεφάλαιο 4. Πειραματική Αξιολόγηση 33 γράφημα του οποίου οι κόμβοι αντιστοιχούν στα αντικείμενα του συστήματος και οι ακμές συν- δέουν αντικείμενα τα οποία έχουν βαθμολογηθεί από κοινούς χρήστες [ 17 ]. Η ιδέα στην οποία στηρίζεται ο αλγόριθμος ItemRank είναι ότι μπορεί να χρησιμοποιηθεί το μοντέλο που προκύ- πτει από το Γράφο Συσχετίσεων (Correlation Graph) για την πρόβλεψη των προτιμήσεων του χρήστη [ 23 ]. Στην περίπτωση των latent factor μεθόδων, δοκιμάσαμε τους αλγόριθμους για κάθε σύνολο δεδομένων χρησιμοποιώντας 20-800 latent factors και αναφέρουμε τα καλ ύτερα αποτελέσματα που επιτεύχθηκαν. Γ ια να αξιολογήσουμε την ποιότητα των συστάσεων, υιοθετήσαμε τη μεθοδολογία που προ- τάθηκε από τους συγγραφείς του [ 13 ]. Πιο συγκεκριμένα, οι βαθμολογίες χωρίζ ονται σε δύο υποσύνολα: στο σύνολο εκπαίδευσης M και στο σύνολο ελέγχου T . Τ ο T περιλαμβάνει μόνο βαθμολογίες με 5 αστέρια (άριστα), το οποίο μπορούμε με ασφάλεια να ισχυριστούμε ότι πε- ριέχει αντικείμενα σχετικά με τους αντίστοιχους χρήστες. Στην περίπτωση που εξετάζουμε, το σύνολο εκπαίδευσης M είναι το αρχικό πλήρες σύνολο δεδομένων. Συγκεκριμένα, πρώτα συλλέγουμε τυχαία το 1.4% των βαθμολογιών στο σύνολο δεδομέ- νων προκειμένου να δημιουργήσουμε το σύνολο αξιολόγησης P . Στη συνέχεια, χρησιμοποιούμε κάθε αντικείμενο v j , το οποίο έχει βαθμολογηθεί με 5 αστέρια από το χρήστη u i στο P , για να σχηματίσουμε το σύνολο ελέγχου T . Τ έλος, για κάθε αντικείμενο στο T που έχει βαθμολογηθεί με 5 αστέρια, επιλέγουμε τυχαία άλλα 1000 μη βαθμολογημένα αντικείμενα του ίδιου χρήστη (υποθέτουμε ότι πρόκειται για αντικείμενα που δεν ενδιαφέρουν άμεσα το χρήστη) και σχηματί- ζ ουμε λίστες κατάταξης ταξινομώντας και τα 1001 αντικείμενα σύμφωνα με τα σκορ συστάσεων που παράγονται από κάθε μέθοδο. Έστω p η θέση κατάταξης στη λίστα του αντικειμένου v j που εξετάζεται κάθε φορά. Τ ο βέλτιστο αποτέλεσμα αντιστοιχεί στην περίπτωση όπου το v j βρίσκεται πιο πάνω στην κατάταξη από όλα τα τυχαία αντικείμενα ( p = 1 ). Σχηματίζ ουμε την top-N λίστα συστάσεων επιλέγοντας τα πρώτα N αντικείμενα από τη λίστα (βρίσκονται πιο ψηλά στην κατάταξη). Α ν p ≤ N έχουμε επιτυχία (hit), δηλαδή το αντικείμενο συστάθηκε στο χρήστη. Διαφορετικά, έχουμε αποτυχία (miss). Οι πιθανότητες επιτυχίας αυξάνονται όσο μεγαλώνει το N. Όταν N = 1001 έχουμε πάντα επιτυχία. 4.3 Μετρικές απόδοσης Σε πολλές εφαρμογές το ΣΣ δεν προβλέπει τις προτιμήσεις του χρήστη για κάποια αντικεί- μενα, όπως οι βαθμολογίες ταινιών, αλλά προσπαθεί να συστήσει στους χρήστες αντικείμενα τα οποία είναι πιθανό να τους φανούν χρήσιμα. Γ ια παράδειγμα, όταν ο χρήστης επιλέγει κάποιες ταινίες, το Netflix του προτείνει και άλλες ταινίες που μπορεί να τον ενδιαφέρουν με βάση αυτές Κεφάλαιο 4. Πειραματική Αξιολόγηση 34 που επέλεξε. Σε αυτήν την περίπτωση, δεν μας ενδιαφέρει αν το σύστημα πρόβλεψε σωστά ή όχι τις βαθμολογίες για αυτές τις ταινίες αλλά εάν το σύστημα πρόβλεψε σωστά ότι αυτές οι ταινίες θα ενδιαφέρουν τον χρήστη ώστε να τις επιλέξει. Έτσι και στο top-N πρόβλημα. Δεν μας ενδιαφέρει η πρόβλεψη της βαθμολογίας που θα έδινε ο χρήστης σε ένα αντικείμενο, αλλά ενδιαφερόμαστε στο να παρουσιάσουμε στο χρήστη τα N αντικείμενα που θα ήθελε να χρησιμοποιήσει περισσότερο. Έτσι, επιλέξαμε και τις κατάλλ ηλες μετρικές για την αξιολόγηση των αποτελεσμάτων μας, οι οποίες εστιάζ ουν στη μέτρηση της χρησιμότητας μιας ταξινομημένης λίστας αντικειμένων που παράγει το σύστημα συστάσεων στο χρήστη. Γ ια να ελέγξ ουμε λοιπόν την ποιότητα των συστάσεων, μεταξύ άλλων, χρησιμοποιούμε και τις καθιερωμένες μετρικές ακρίβειας Recall και Precision , όπως αυτές ορίστηκαν στο [ 13 ]. Όπως αναφέραμε και παραπάνω, για κάθε μία περίπτωση που εξετάζουμε (αποτελείται από 1001 αντικείμενα), έχουμε ένα και μοναδικό σχετικό αντικείμενο (το αντικείμενο εκείνο που ανήκει στο T ). Έτσι, η recall για μία συγκεκριμένη περίπτωση μπορεί να υποθέσει είτε την τιμή 0 (στην περίπτωση αποτυχίας) είτε την τιμή 1 (στην περίπτωση επιτυχίας). Ομοίως, η precision μπορεί να υποθέσει είτε την τιμή 0 είτε 1/ N . Τ α συνολ ικά recall κ αι precision ορίζ ονται λοιπόν από το μέσο όρο όλων των περιπτώσεων: recall ( N ) = #hits |T | precision ( N ) = #hits N · |T | όπου |T | το πλήθος των βαθμολογιών ελέγχου. Αξίζει να σημειώσουμε σε αυτό το σημείο, ότι έχουμε υποθέσει πως όλα τα 1000 τυχαία αντι- κείμενα είναι άσχετα στο χρήστη και κατά συνέπεια, αυτή η υπόθεση οδηγεί στην υποβάθμιση των τιμών recall και precision που υπολογίζ ουμε σε σχέση με τις πραγματικές τιμές. Γ ια την αξιολόγηση των αποτελεσμάτων μας, χρησιμοποιούμε επίσης και άλλους γνωστούς δείκτες κατάταξης με βάση τη χρησιμότητα, οι οποίοι υποβαθμίζουν τη χρησιμότητα ενός αντι- κειμένου που συστήνεται κατά ένα παράγοντα που εξ αρτάται από τη θέση του στη λίστα συστά- σεων [ 49 ]. Με άλλα λόγια, τα αντικείμενα τα οποία δε βρίσκονται ψηλά στη λίστα τιμωρούνται πιο αυστηρά καθώς είναι πιο πιθανό ο χρήστης να μην τα παρατηρήσει. Η χρησιμότητα κάθε σύστασης είναι η χρησιμότητα του αντικειμένου που συστήνεται μειω- μένη κατά ένα παράγοντα που εξ αρτάται από τη θέση του στη λίστα με τις συστάσεις. Ένα παράδειγμα τέτοιας χρησιμότητας είναι η πιθανότητα ο χρήστης να παρατηρήσει μία σύσταση στη θέση i της λίστας. Υποτίθεται συνήθως ότι οι χρήστες παρατηρούν τις λίστες συστάσεων από την αρχή ως το τέλος, με τη χρησιμότητα των συστάσεων να φθίνει πιο έντονα καθώς κινού- μαστε προς το τέλος της λίστας. Αυτή η μείωση μπορεί επίσης να ερμηνευτεί ως η πιθανότητα Κεφάλαιο 4. Πειραματική Αξιολόγηση 35 ότι ένας χρήστης θα παρατηρούσε μία σύσταση σε μία συγκεκριμένη θέση στη λίστα, με τη χρη- σιμότητα της σύστασης, δεδομένου ότι παρατηρήθηκε, να εξαρτάται μόνο από το αντικείμενο που συστήθηκε. Υπό αυτήν την έννοια, η πιθανότητα ότι μία συγκεκριμένη θέση στη λίστα συ- στάσεων παρατηρήθηκε, υποτίθεται ότι εξαρτάται μόνο από τη θέση και όχι από τα αντικείμενα που συστήνονται [ 49 ]. Σε πολλές εφαρμογές, ο χρήστης μπορεί να χρησιμοποιήσει είτε μόνο ένα είτε ένα μικρό αριθμό αντικειμένων από αυτά που συστήνονται. Σε τέτοιες περιπτώσεις, αναμένεται οι χρή- στες να παρατηρήσουν μόνο λίγα αντικείμενα τα οποία βρίσκονται στην κορυφή της λίστας συστάσεων. Τ έτοιες εφαρμογές μπορούν να μοντελοποιηθούν χρησιμοποιώντας σημαντική μεί- ωση σε σχέση με τη θέση καθώς κινούμαστε προς τα κάτω στη λίστα. Μία υποψήφια μετρική για αυτές τις περιπτώσεις είναι το R-Score . Σε άλλες εφαρμογές ο χρήστης αναμένεται να διαβάσει ένα σχετικά μεγάλο μέρος της λίστας. Σε κάποια είδη αναζήτησης, όπως η αναζ ήτηση νομικών εγγράφων, οι χρήστες ίσως να ψάχνουν για όλα τα σχετικά αντικείμενα, και να ήταν πρόθυμοι να διαβάσουν μεγάλο μέρος της λίστας συστάσεων [ 49 ]. Αυτές οι μετρικές παρουσιάζ ονται παρακάτω: Έστω π q ο δείκτης του q th αντικειμένου στη λίστα κατάταξης με συστάσεις π , και y ένα διάνυσμα με τιμές σχετικότητας για μια ακ ολουθία αντικειμένων. • R-Score. Η μετρική R-Score υποθέτει ότι η αξία των συστάσεων φθίνει εκθετικά στη λίστα κατάταξης και δίνει για κάθε χρήστη την ακόλουθη βαθμολογία: R-Score ( α ) = q max ( y π q − d, 0) 2 q − 1 α − 1 όπου d είναι μία “δεν ενδιαφέρομαι” βαθμολογία που εξ αρτάται από το πρόβλημα, και α είναι μία half-life παράμετρος, η οποία ελέγχει την εκθετική πτώση της αξίας των θέσεων στη λίστα κατάταξης [ 49 ]. • NDCG@ k . Τ ο Cumulative Discounted Gain αποτελεί ένα μέτρο κατά το οποίο οι θέσεις κατάταξης φθίνουν λογαριθμικά και ορίζεται ως: DCG@ k ( y , π ) = k q =1 2 y π q − 1 log 2 (2 + q ) Τ ο κανονικοποιημένο Discounted Cumulative Gain μπορεί συνεπώς να οριστεί ως ο λό- γος του DCG@ k ( y , π ) ως προς το DCG της καλύτερης δυνατής κατάταξης (βλ. [ 3 ] για λεπτομέρειες). Κεφάλαιο 4. Πειραματική Αξιολόγηση 36 • Mean Reciprocal Rank. MRR είναι ο μέσος όρος του reciprocal rank score κάθε χρήστη, και ορίζεται ως ακ ολούθως: RR = 1 min q { q : y π q > 0 } 4.4 Ποιότητα Συστάσεων Ακολουθώντας τη διαδικασία ελέγχου των Karypis et al. [ 25 ], παίρνουμε τα Yahoo!Music δεδομένα και δημιουργούμε δύο σύνολα δεδομένων με διαφορετική πυκνότητα (η πυκνότητα προκύπτει από το πλήθος των βαθμολογιών δια το γινόμενο του πλήθους χρηστών και αντι- κειμένων). Αυτό συνέβη ώστε να αξιολογηθεί συγκεκριμένα η απόδοση των αλγορίθμων σε δεδομένα χαμηλ ής πυκνότητας, τα οποία συναντώνται αρκετά συχνά σε ρεαλιστικά σενάρια. Πιο συγκεκριμένα, επιλέγουμε τυχαία ένα υποσύνολο από χρήστες και αντικείμενα από τα συνολικά. Στη συνέχεια, διατηρώντας το ίδιο πλήθος χρηστών και αντικειμένων, δημιουργούμε το πρώτο πιο αραιό σύνολο δεδομένων διαγράφοντας τυχαία τιμές από το μητρώο με τις βαθ- μολογίες. Όμοια, δημιουργείται και το δεύτερο ακόμα πιο αραιό σύνολο δεδομένων. Συγκεκρι- μένα, αφαιρούμε με τυχαίο τρόπο τιμές από το μητρώο βαθμολογιών του αραιότερου συνόλου δεδομένων. Τ α σύνολα δεδομένων που προκύπτουν σημειώνονται ως Yahoo1 και Yahoo2 και οι πυκνότητές τους είναι 1 . 63 % και 0 . 55 % αντίστοιχα. Στην πρώτη γραμμή του Σχήματος 4.1 , αναφέρουμε το Recall ως συνάρτηση του N (δηλαδή τον αριθμό των αντικειμένων που συστήνονται) και στη δεύτερη γραμμή το Precision ως συνάρ- τηση του Recall, για το Yahoo1 (πρώτη στήλη) και Yahoo2 (δεύτερη στήλη). Σε ό,τι αφορά το Recall( N ), έχουμε εστιάσει σε τιμές του N στο εύρος [1 . . . 20] . Μεγαλ ύτερες τιμές του N μπο- ρούν να αγνοηθούν για ένα τυπικό top-N πρόβλημα [ 13 ]. Σ την τελευταία γραμμή του σχήματος, αναφέρουμε το Normalized Discounted Cumulative Gain για top-N λίστες κατάταξης, και πάλι για τιμές του N στο εύρος [1 . . . 20] . Όπως μπορούμε να δούμε, ο LLFR έχει πολύ καλή απόδοση φτάνοντας τη δεύτερη θέση στο πυκνό Yahoo1 και την πρώτη θέση στο Yahoo2 σύνολο δεδομένων. Πιο συγκεκριμένα, βλέπουμε ότι ο LLFR καταφέρνει να διατηρήσει την απόδοσή του στην πιο αραιή περίπτωση φτάνοντας για παράδειγμα, για N = 15, τιμή Recall περίπου 0.32, ενώ ο PureSVD πέφτει στο 0.25. Αυτό πρακτικά σημαίνει ότι περίπου 32% των 5-άστερων αντικειμένων παρουσιάζονται από τον LLFR στις top-15 λίστες κατάταξης για τους αντίστοιχους χρήστες, ένα αποτέλεσμα ικανοποιητικ ό δεδομένης της αραιότητας των δεδομένων. Τ α ίδια αποτελέσματα ισχύουν και για τις μετρικές Precision και NDCG. Επίσης, αξίζει να σημειωθεί ότι οι μέθοδοι τυχαίων περιπάτων, ItemRank και Commute T ime, τα πάνε ιδιαίτερα καλά, ειδικά στα πιο αραιά δεδομένα όπου έχουν καλύτερη απόδοση από τον PureSVD σε όλες τις μετρικές. Κεφάλαιο 4. Πειραματική Αξιολόγηση 37 5 10 15 20 0 0 . 2 0 . 4 0 . 6 N Recall(N) Yahoo1 (densit y = 1.63%) 5 10 15 20 0 0 . 1 0 . 2 0 . 3 0 . 4 N Recall(N) Yahoo2 (densit y = 0.55%) 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 05 0 . 1 Recall Precision 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 01 . 02 . 03 Recall Precision 5 10 15 20 0 . 2 0 . 4 N NDCG 5 10 15 20 . 05 0 . 1 0 . 15 0 . 2 N NDCG LLFR PureSVD L † MF A Commute Time ItemRank Σ 4.1: Αξιολόγηση της απόδοσης top-N συστάσεων. Παρατηρούμε ότι ο LLFR παράγει πολύ καλά αποτελέσματα, και ταυτόχρονα είναι κατά πολύ ο πιο συμφέρων υπολογιστικά σε σχέση με όλες τις μεθόδους που εξετάστηκαν. Να ση- μειώσουμε σε αυτό το σημείο ότι ο αλγόριθμος Commute T ime απαιτείται να χειριστεί ένα γράφημα με n + m ακμές (όπου n είναι ο αριθμός των χρηστών και m ο αριθμός των αντικει- μένων) και να υπολογίσει 2 nm βαθμολογίες κατά το πρώτο πέρασμα. Ομοίως, οι L † και MF A, απαιτούν τον άμεσο υπολογισμό του ψευδο-αντίστροφου του Laplacian, ενός γραφήματος με n + m ακμές, και την αντιστροφή ενός ( n + m ) -διάστατου τετραγωνικού μητρώου, αντίστοιχα (βλέπε [ 18 ] για περισσότερες λεπτομέρειες). Πρόκειται για προβλήματα τα οποία γίνονται εύ- κολα μη διαχειρίσιμα καθώς ο αριθμός των χρηστών στο σύστημα μεγαλώνει. Πράγματι, μόνο οι LLFR και ItemRank περιλαμβάνουν μητρώα των οποίων οι διαστάσεις εξ αρτώνται μόνο από τη διάσταση του χ ώρου αντικειμένων, η οποία στις περισσότερες πραγματικές εφαρμογές αυξά- νει αργά. Ωστόσο, στα πειράματά μας, παρατηρούμε ότι ο LLFR τρέχει 10 φορές πιο γρήγορα από τον ItemRank 2 . Αυτό ισχύει για κάθε σύνολο δεδομένων που δοκιμάσαμε. Τ έλος, το γεγονός ότι η μέθοδός μας ξεπερνά σε απόδοση όλες τις άλλες μεθόδους στο πιο αραιό σύνολο δεδομένων υποδεικνύει ότι ο LLFR θα μπορούσε να είναι πολ ύ χρήσιμος για την αντιμετώπιση ενός πολύ βασικού προβλήματος, το οποίο είναι γνωστό ότι ευθύνεται για τη σημαντική υποβάθμιση της ποιότητας σε πραγματικά συστήματα συστάσεων, το Cold Start Pr oblem . 2 επιλέγοντας convergence tolerance 10 − 5 , damping factor 0.85 (όπως προτείνεται από τους συγγραφείς στο [ 23 ]), και υπολογίζ οντας τα διανύσματα συστάσεων για όλους τους χρήστες με τη μία, ώστε να εκμεταλλευτούμε τα βελ- τιστοποιημένα BLAS3 kernels. Κεφάλαιο 4. Πειραματική Αξιολόγηση 38 4.5 Τ ο Πρόβλημα της Κρύας Εκκίνησης Τ ο cold start πρόβλημα έχει να κάνει με τη δυσκολία πραγματοποίησης αξιόπιστων συστά- σεων εξαιτίας μιας αρχικής έλλειψης βαθμολογιών [ 8 ]. Πρόκειται για ένα πρόβλημα που συ- ναντάται συχνά σε πραγματικά συστήματα συστάσεων κατά τα πρώτα τους στάδια, όπου δεν υπάρχουν αρκετές βαθμολογίες προκειμένου οι αλγόριθμοι συνεργατικής διήθησης να ανακα- λύψουν ομοιότητες ανάμεσα σε αντικείμενα και χρήστες ( New Community Pr oblem ). Ωστόσο, το πρόβλ ημα μπορεί να προκύψει κ αι κατά την εισαγωγή νέων χρηστών σε ένα ήδη υπάρχον σύστημα ( New Users Pr oblem ). Όπως είναι αναμενόμενο, επειδή αυτοί οι χρήστες είναι νέοι, δεν έχουν βαθμολογήσει ακόμα πολλά αντικείμενα και έτσι, ο CF αλγόριθμος δεν μπορεί ακόμα να κάνει αξιόπιστες προσωποποιημένες συστάσεις. Κ άτι τέτοιο μπορεί να θεωρηθεί ως ένα είδος προβλήματος τοπικής αραιότητας και αποτελεί μία από τις διαρκείς προκλήσεις που αντιμετωπίζ ουν τα συστήματα συστάσεων σε λειτουργία [ 28 ]. Τ έλος, συχνά παρουσιάζεται και το πρόβλημα λόγω νέων αντικειμένων ( New Items Pr oblem ) [ 8 ], όπου τα νέα αντικείμενα που μπαίνουν στο σύστημα συνήθως δεν έχουν αρχικά βαθμολο- γίες, και έτσι δεν είναι πιθανό να συσταθούν σε κάποιο χρήστη. Κατά συνέπεια, ένα αντικείμενο το οποίο δεν περιλαμβάνεται σε συστάσεις, περνάει απαρατήρητο από μεγάλο μέρος της κοινό- τητας των χρηστών, και καθώς οι χρήστες δε γνωρίζ ουν την ύπαρξή του, δεν το βαθμολογούν. Με αυτόν τον τρόπο, προκύπτει ένας φαύλος κύκλος, όπου αντικείμενα του συστήματος παρα- μερίζ ονται και δεν αποτελούν μέρος της διαδικασίας συστάσεων. Μία κοινή λύση σε αυτό το πρόβλημα είναι να δίνεται κίνητρο σε κάποιους χρήστες ώστε να βαθμολογούν κάθε νέο αντι- κείμενο που εισέρχεται στο σύστημα [ 8 ]. Εμείς στην παρούσα εργασία ασχολούμαστε με τις δύο πρώτες εκδοχές του προβλήματος. Η τρίτη εκδοχή του προβλήματος όπως αυτή αναφέρθηκε παραπάνω (καθώς και το πλήρες πρό- βλημα), μελετάται στο [ 44 ], όπου προσομοιώνεται η κατάσταση και εξετάζεται η απόδοση του προτεινόμενου αλγορίθμου HIR. 4.5.1 New Community Problem Προκειμένου να αξιολογήσουμε την απόδοση του LLFR στην αντιμετώπιση του new community problem, εκτελούμε το ακόλουθο πείραμα: προσομοιώνουμε το φαινόμενο επιλέγοντας τυχαία να συμπεριλάβουμε το 10%, 20% και 30% του Yahoo1 συνόλου δεδομένων σε τρεις νέες τε- χνητά αραιές εκδόσεις, με τέτοιο τρόπο όπου κάθε σύνολο δεδομένων είναι υποσύνολο του επό- μενου. Η ιδέα είναι ότι αυτά τα νέα σύνολα δεδομένων αναπαριστούν στιγμιότυπα των αρχικών σταδίων του συστήματος συστάσεων, όταν η κ οινότητα των χρηστών ήταν νέα και το σύστημα υστερούσε σε βαθμολογίες. Κεφάλαιο 4. Πειραματική Αξιολόγηση 39 Στη συνέχεια, παίρνουμε τα νέα σύνολα δεδομένων και δημιουργούμε σύνολα ελέγχου ακ ο- λουθώντας τη μεθοδολογία που περιγράφεται στο Κεφάλαιο 4.2 . Εκτελούμε όλους τους αλγό- ριθμους και αξιολογούμε την απόδοσή τους χρησιμοποιώντας το Mean Reciprocal Rank και το R-Score με halflife α = 5 . Επιλέξαμε αυτές τις μετρικές λόγω του γεγονότος ότι μπορούν να συνοψίσουν την απόδοση συστάσεων σε έναν μόνο αριθμό, κάτι που κάνει ευκολότερη τη σύ- γκριση της top-N ποιότητας για τα διαφορετικά στάδια κατά την εξέλιξη του συστήματος. Ο Πίνακας 4.1 παρουσιάζει τα αποτελέσματα. Π 4.1: Αποτελέσματα απόδοσης για το New Community Πρόβλημα. LLFR PureSVD L † MF A CT IR 10% MRR 0.1 184 0.1075 0.0106 0.0571 0.0197 0.0870 R-Score 0.1474 0.1296 0.0085 0.0563 0.0089 0.1028 20% MRR 0.0874 0.0722 0.0257 0.0271 0.0459 0.0630 R-Score 0.1238 0.1 180 0.0309 0.0331 0.0728 0.0905 30% MRR 0.0930 0.0924 0.0316 0.0348 0.0646 0.0741 R-Score 0.1352 0.1289 0.0396 0.0454 0.1047 0.1 117 Βλέπουμε ξεκάθαρα ότι ο LLFR έχει καλύτερη απόδοση από κάθε άλλο αλγόριθμο και στα τρία στάδια, με το προβάδισμά του να είναι μεγαλύτερο στις δύο πιο αραιές περιπτώσεις. Να σημειωθεί ότι το σύνολο δεδομένων που χρησιμοποιήθηκε είναι το Yahoo1 , ένα σύνολο δεδομέ- νων στο οποίο ο PureSVD “είχε το πάνω χέρι”, καθώς όπως αποδείχτηκε είχε καλύτερη απόδοση στην πλήρη περίπτωση που παρουσιάστηκε στην προηγούμενη ενότητα. 4.5.2 New Users Problem Γ ια να αξιολογήσουμε την απόδοση του αλγορίθμου μας στην αντιμετώπιση του new users problem, χρησιμοποιούμε ξανά το Yahoo1 σύνολο δεδομένων και εκτελούμε το ακόλουθο πεί- ραμα. Επιλέγουμε τυχαία 50 χρήστες οι οποίοι έχουν βαθμολογήσει 100 αντικείμενα ή περισσό- τερα, και διαγράφουμε τυχαία το 95% των βαθμολογιών τους. Τ ο σκεπτικό είναι ότι τα τροπο- ποιημένα δεδομένα αναπαριστούν μία “προηγούμενη έκδοση” του συνόλου δεδομένων, όταν οι 5 10 15 20 0 0 . 1 0 . 2 0 . 3 N Recall(N) 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 02 . 04 . 06 Recall Precision 5 10 15 20 0 . 1 0 . 2 N NDCG LLFR PureSVD L † MF A Comm ute Time ItemRank Σ 4.2: Αξιολόγηση της απόδοσης top-N συστάσεων για το New Users Πρόβλημα Κεφάλαιο 4. Πειραματική Αξιολόγηση 40 χρήστες ήταν νέοι στο σύστημα και έτσι, είχαν λιγότερες βαθμολογίες. Στη συνέχεια, παίρνουμε το μέρος του συνόλου δεδομένων που αντιστοιχεί σε αυτούς τους νέους χρήστες και δημιουρ- γούμε το σύνολο ελέγχου όπως και προηγουμένως, χρησιμοποιώντας 10% ως cut-off αυτή τη φορά για το σύνολο αξιολόγησης, ώστε να έχουμε αρκετές ταινίες βαθμολογημένες με 5 στο σύ- νολο ελέγχου και να εκτιμήσουμε αξιόπιστα την ποιότητα της απόδοσης. Μία παρόμοια μέθοδος χρησιμοποιήθηκε στο [ 37 ] για την αξιολόγηση της W eb ranking ποιότητας για το πρόβλημα των νέων σελίδων που προστίθενται ( Newly Added Pages Pr oblem ), όπου οι σελίδες αυτές είναι νέες και έτσι έχ ουν λιγότερα εισερχόμενα links κ αι κατά συνέπεια, το link graph είναι αραιό. Στο Σχήμα 4.2 , βλέπουμε ότι ο LLFR έχει τις καλύτερες επιδόσεις συγκριτικά με όλους τους άλλους αλγορίθμους που εξετάστηκαν σε όλες τις μετρικές. Αξίζει να σημειωθεί, ότι παρότι ο PureSVD έχει καλή απόδοση σε αυτό το σύνολο δεδομένων, και η πυκνότητα της τροποποιη- μένης έκδοσης παραμένει κοντά στην αρχική (1.46%), η ποιότητά του για το σύνολο των νέων χρηστών έχει μειωθεί σημαντικά. Επιπλέον, είναι ενδιαφέρον το ότι ο LLFR καταφέρνει να έχει σημαντικά καλύτερη απόδοση από όλες τις graph-based μεθόδους, οι οποίες θεωρούνται στη βιβλιογραφία ανάμεσα στις πιο υποσχόμενες προσεγγίσεις για την αντιμετώπιση των προβλη- μάτων που σχετίζ ονται με την αραιότητα, λόγω της ικανότητάς τους να εκμεταλλεύονται τις μεταβατικές σχέσεις στα δεδομένα [ 17 , 23 ]. Κεφάλαιο 5 Συμπεράσματα Στην παρούσα διπλωματική εργασία παρουσιάσαμε τον αλγόριθμο Lanczos Latent Factor Recommender . Πρόκειται για μία νέα εναλλακτική latent factor-based πρόταση για το πρόβλημα των top-N συστάσεων, υπολογιστικά αποδοτική, και κατάλλ ηλη για εφαρμογές μεγάλου όγκου δεδομένων ( big data ). Τ ο βασικ ό χαρακτηριστικό του LLFR το οποίο του δίνει αυτό το προβά- δισμα κόστους, είναι ότι μειώνει τη διάσταση του προβλήματος κατασκευάζ οντας τη Lanczos βάση του Krylov υποχώρου που ορίζεται από ένα μητρώο συσχετίσεων μεταξύ αντικειμένων. Στη συνέχεια, χρησιμοποιεί το χαμηλής διάστασης μοντέλο για να παράγει λίστες κατάταξης αντικειμένων για τον κάθε χρήστη. Πραγματοποιήσαμε μία σειρά από πειράματα σε πραγματικά σύνολα δεδομένων, και συγκε- κριμένα στα MovieLens10M και Yahoo!Music , και συγκρίναμε τον LLFR με άλλους διάσημους αλγόριθμους, οι οποίοι φημίζ ονται για την ικανότητά τους να τα πηγαίνουν καλά στις διάφορες προκλήσεις που χαρακτηρίζ ουν τις σύγχρονες εφαρμογές. Γ ια την αξιολόγηση των αποτελεσμά- των επιλέξ αμε ευρέως χρησιμοποιούμενες μετρικές, οι οποίες έχουν νόημα για ένα πραγματικ ό σύστημα συστάσεων. Τ α πειράματα έδειξ αν ότι ο LLFR επιτυγχάνει πολύ καλά αποτελέσματα απέναντι στις άλλες μεθόδους συνεργατικής διήθησης με τις οποίες συγκρίθηκε, σε επίπεδο τόσο υπολογιστικ ού κ ό- στους όσο και ποιότητας συστάσεων. Αξίζει δε να τονίσουμε ότι η μέθοδός μας συμπεριφέρεται ιδιαίτερα καλά όταν η αραιότητα των δεδομένων είναι έντονη, όταν δηλαδή δεν υπάρχουν αρ- κετά δεδομένα στο σύστημα ώστε ο αλγόριθμος να ανακαλ ύψει συσχετίσεις μεταξύ χρηστών και αντικειμένων, και να πραγματοποιήσει επιτυχημένες συστάσεις, όπως στο Πρόβλημα Κρύας Εκ- κίνησης ( Cold Start Pr oblem ). Η αραιότητα είναι ένα σύνηθες πρόβλημα στις σύγχρονες πραγ- ματικές εφαρμογές διότι συνήθως οι χρήστες αλληλεπιδρούν μόνο με ένα μικρό ποσοστό των διαθέσιμων αντικειμένων, και την ίδια στιγμή νέοι χρήστες και νέα αντικείμενα προστίθενται τακτικά στο σύστημα. 41 Κεφάλαιο 5. Συμπεράσματα 42 Γ ια να ελέγξ ουμε την απόδοση του αλγόριθμού μας στο πρόβλημα Κρύας Εκκίνησης, πραγ- ματοποιήσαμε πειράματα προσομοιώνοντας την περίπτωση New Community Problem – η οποία συναντάται στα πραγματικά συστήματα κατά τα αρχικά τους στάδια όπου δεν υπάρχουν αρ- κετά δεδομένα ακόμα στο σύστημα – και New Users Pr oblem – η οποία συναντάται κατά την εισαγωγή νέων χρηστών σε ένα υπάρχον σύστημα, όπου ακριβώς επειδή αυτοί οι χρήστες είναι νέοι δεν έχουν προλάβει να βαθμολογήσουν αντικείμενα. Τ α αποτελέσματα έδειξ αν ότι ο LLFR τα πάει καλύτερα σε σχέση με όλες τις άλλες μεθόδους που εξετάστηκαν, συμπεριλαμβανομέ- νων και των graph-based τεχνικών οι οποίες είναι πολλά υποσχόμενες στην αντιμετώπιση της αραιότητας. Η απλοϊκότητα του LLFR φαίνεται να είναι πιο αποδοτική στην περίπτωση αραιών δεδομέ- νων, σε σχέση με άλλους πιο ακριβείς ή έξυπνους ή πολύπλοκ ους αλγόριθμους, όπως ο PureSVD, οι οποίοι πολλές φορές αποτυγχάνουν στην απόδοσή τους λόγω του overfitting που παρουσιά- ζ ουν σε συνθήκες αραιότητας. Συνοψίζ οντας, τα αποτελέσματά μας υποδεικνύουν ότι τόσο το υπολογιστικ ό προφίλ του LLFR όσο και η απόδοσή του στο top-N πρόβλημα συστάσεων τον καθιστούν ως έναν πολύ καλό υποψήφιο για ευρείας κλίμακας εφαρμογές συστάσεων. Βιβλιογραφία [1] Charu C Aggarwal, Joel L W olf, Kun-Lung W u, and Philip S Y u. Horting hatches an egg: A new graph-theoretic approach to collaborative filtering. In Pr oceedings of the fifth ACM SIGKDD international conference on Knowledge discovery and data mining , pages 201– 212. ACM, 1999. [2] Kamal Ali and Wijnand V an Stam. Tivo: making show recommendations using a distributed collaborative filtering architecture. In Pr oceedings of the tenth ACM SIGKDD international confer ence on Knowledge discovery and data mining , pages 394–401. ACM, 2004. [3] Suhrid Balakrishnan and Sumit Chopra. Collaborative ranking. In Pr oceedings of the fifth ACM international conference on W eb sear ch and data mining , WSDM ’12, pages 143– 152, New Y ork, NY , USA, 2012. ACM. [4] Robert Bell, Y ehuda Koren, and Chris V olinsky . Modeling relationships at multiple scales to improve accuracy of large recommender systems. In Proceedings of the 13th ACM SIGKDD international confer ence on Knowledge discovery and data mining , pages 95– 104. ACM, 2007. [5] Daniel Billsus and Michael J Pazzani. Learning collaborative information filters. In ICML , volume 98, pages 46–54, 1998. [6] Daniel Billsus and Michael J Pazzani. User modeling for adaptive news access. User modeling and user-adapted interaction , 10(2-3):147–180, 2000. [7] Katarina Blom and Axel Ruhe. A krylov subspace method for information retrieval. SIAM Journal on Matrix Analysis and Applications , 26(2):566–582, 2004. [8] J. Bobadilla, F . Ortega, A. Hernando, and A. Gutiérrez. Recommender systems survey . Know .-Based Syst. , 46:109–132, July 2013. [9] Sergey Brin and Lawrence Page. Reprint of: The anatomy of a large-scale hypertextual web search engine. Computer networks , 56(18):3825–3833, 2012. 43 Bibliography 44 [10] John Canny . Collaborative filtering with privacy via factor analysis. In Pr oceedings of the 25th annual international ACM SIGIR confer ence on Resear ch and development in information r etrieval , SIGIR ’02, pages 238–245, New Y ork, NY , USA, 2002. ACM. [1 1] Pavel Chebotarev and Elena Shamis. The matrix-forest theorem and measuring relations in small social groups. arXiv pr eprint math/0602070 , 2006. [12] Jie Chen and Y ousef Saad. Lanczos vectors versus singular vectors for effective dimension reduction. Knowledge and Data Engineering, IEEE T ransactions on , 21(8):1091–1103, 2009. [13] Paolo Cremonesi, Y ehuda Koren, and Roberto T urrin. Performance of recommender algorithms on top-n recommendation tasks. In Pr oceedings of the fourth ACM conference on Recommender systems , RecSys ’10, pages 39–46. ACM, 2010. [14] Fabio Crestani and Puay Leng Lee. Searching the web by constrained spreading activation. Information Pr ocessing & Management , 36(4):585–605, 2000. [15] Scott Deerwester , Susan T Dumais, George W Furnas, Thomas K Landauer , and Richard Harshman. Indexing by latent semantic analysis. Journal of the American society for information science , 41(6):391, 1990. [16] Mukund Deshpande and George Karypis. Item-based top-n recommendation algorithms. ACM T ransactions on Information Systems (TOIS) , 22(1):143–177, 2004. [17] Christian Desrosiers and George Karypis. A comprehensive survey of neighborhood-based recommendation methods. In Francesco Ricci, Lior Rokach, Bracha Shapira, and Paul B. Kantor , editors, Recommender Systems Handbook , pages 107–144. Springer US, 201 1. [18] F . Fouss, A. Pirotte, J.M. Renders, and M. Saerens. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. Knowledge and Data Engineering, IEEE T ransactions on , 19(3):355–369, 2007. [19] François Fouss, Kevin Francoisse, Luh Y en, Alain Pirotte, and Marco Saerens. An experimental investigation of kernels on graphs for collaborative recommendation and semisupervised classification. Neural Networks , 31:53–72, 2012. [20] Gene H Golub and Charles F V an Loan. Matrix computations. johns hopkins studies in the mathematical sciences, 1996. [21] Gene H Golub and Charles F V an Loan. Matrix computations , volume 3. JHU Press, 2012. [22] Nathaniel Good, J Ben Schafer , Joseph A Konstan, Al Borchers, Badrul Sarwar , Jon Herlocker , and John Riedl. Combining collaborative filtering with personal agents for better recommendations. In AAAI/IAAI , pages 439–446, 1999. Bibliography 45 [23] Marco Gori and Augusto Pucci. ItemRank: a random-walk based scoring algorithm for recommender engines. In Proceedings of the 20th international joint conference on Artifical intelligence , IJCAI’07, pages 2766–2771, 2007. [24] Zan Huang, Hsinchun Chen, and Daniel Zeng. Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering. ACM T ransactions on Information Systems (TOIS) , 22(1):1 16–142, 2004. [25] Santosh Kabbur, Xia Ning, and George Karypis. Fism: Factored item similarity models for top-n recommender systems. In Pr oceedings of the 19th ACM SIGKDD International Confer ence on Knowledge Discovery and Data Mining , KDD ’13, pages 659–667, New Y ork, NY , USA, 2013. ACM. [26] Leo Katz. A new status index derived from sociometric analysis. Psychometrika , 18(1):39– 43, 1953. [27] Joseph A Konstan, Bradley N Miller , David Maltz, Jonathan L Herlocker , Lee R Gordon, and John Riedl. Grouplens: applying collaborative filtering to usenet news. Communications of the ACM , 40(3):77–87, 1997. [28] JosephA. Konstan and John Riedl. Recommender systems: from algorithms to user experience. User Modeling and User-Adapted Interaction , 22(1-2):101–123, 2012. [29] Y ehuda Koren. Factorization meets the neighborhood: a multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD international confer ence on Knowledge discovery and data mining , pages 426–434. ACM, 2008. [30] Y ehuda Koren and Robert Bell. Advances in collaborative filtering. In Francesco Ricci, Lior Rokach, Bracha Shapira, and Paul B. Kantor , editors, Recommender Systems Handbook , pages 145–186. Springer US, 201 1. [31] Y ehuda Koren, Robert Bell, and Chris V olinsky . Matrix factorization techniques for recommender systems. Computer , 42(8):30–37, 2009. [32] Marianna Kouneli. Exploiting hierarchy for ranking-based recommendation. arXiv pr eprint arXiv:1512.07444 , 2015. [33] Greg Linden, Brent Smith, and Jeremy Y ork. Amazon. com recommendations: Item-to- item collaborative filtering. Internet Computing, IEEE , 7(1):76–80, 2003. [34] Pasquale Lops, Marco De Gemmis, and Giovanni Semeraro. Content-based recommender systems: State of the art and trends. In Recommender systems handbook , pages 73–105. Springer , 201 1. Bibliography 46 [35] H. Luo, C. Niu, R. Shen, and C. Ullrich. A collaborative filtering framework based on both local user similarity and global user similarity . Machine Learning , 72(3):231–245, 2008. [36] Prem Melville, Raymond J Mooney , and Ramadass Nagarajan. Content-boosted collaborative filtering for improved recommendations. In AAAI/IAAI , pages 187–192, 2002. [37] Athanasios N. Nikolakopoulos and John D. Garofalakis. NCDawareRank: a novel ranking method that exploits the decomposable structure of the web. In Proceedings of the sixth ACM international conference on W eb sear ch and data mining , WSDM ’13, pages 143– 152, New Y ork, NY , USA, 2013. ACM. [38] Athanasios N Nikolakopoulos and John D Garofalakis. Ncdrec: A decomposability inspired framework for top-n recommendation. In W eb Intelligence (WI) and Intelligent Agent T echnologies (IAT), 2014 IEEE/WIC/ACM International Joint Confer ences on , volume 1, pages 183–190. IEEE, 2014. [39] Athanasios N Nikolakopoulos and John D Garofalakis. Random surfing without teleportation. In Algorithms, Probability , Networks, and Games , pages 344–357. Springer International Publishing, 2015. [40] Athanasios N Nikolakopoulos and John D Garofalakis. T op-n recommendations in the presence of sparsity: An ncd-based approach. In W eb Intelligence , volume 13, pages 247– 265. IOS Press, 2015. [41] Athanasios N Nikolakopoulos, Maria Kalantzi, and John D Garofalakis. On the use of lanczos vectors for efficient latent factor-based top-n recommendation. In Proceedings of the 4th International Confer ence on W eb Intelligence, Mining and Semantics (WIMS14) , page 28. ACM, 2014. [42] Athanasios N Nikolakopoulos, V assilis Kalantzis, and John D Garofalakis. Eigenrec: An efficient and scalable latent factor family for top-n recommendation. arXiv preprint arXiv:151 1.06033 , 2015. [43] Athanasios N. Nikolakopoulos, Marianna Kouneli, and John Garofalakis. A novel hierarchical approach to ranking-based collaborative filtering. In Lazaros Iliadis, Harris Papadopoulos, and Chrisina Jayne, editors, Engineering Applications of Neural Networks , volume 384 of Communications in Computer and Information Science , pages 50–59. Springer Berlin Heidelberg, 2013. [44] Athanasios N Nikolakopoulos, Marianna A Kouneli, and John D Garofalakis. Hierarchical itemspace rank: Exploiting hierarchy to alleviate sparsity in ranking-based recommendation. Neur ocomputing , 163:126–136, 2015. Bibliography 47 [45] Francesco Ricci, Lior Rokach, and Bracha Shapira. Intr oduction to recommender systems handbook . Springer , 201 1. [46] B. Sarwar , G. Karypis, J. Konstan, and J. Riedl. Application of dimensionality reduction in recommender system-a case study . T echnical report, DTIC Document, 2000. [47] Badrul Sarwar , George Karypis, Joseph Konstan, and John Riedl. Item-based collaborative filtering recommendation algorithms. In Pr oceedings of the 10th international confer ence on W orld W ide W eb , WWW ’01, pages 285–295, New Y ork, NY , USA, 2001. ACM. [48] Andrew I Schein, Alexandrin Popescul, L yle H Ungar, and David M Pennock. Methods and metrics for cold-start recommendations. In Pr oceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval , pages 253– 260. ACM, 2002. [49] Guy Shani and Asela Gunawardana. Evaluating recommendation systems. In Francesco Ricci, Lior Rokach, Bracha Shapira, and Paul B. Kantor , editors, Recommender Systems Handbook , pages 257–297. Springer US, 201 1. [50] Upendra Shardanand and Pattie Maes. Social information filtering: algorithms for automating “word of mouth”. In Proceedings of the SIGCHI confer ence on Human factors in computing systems , pages 210–217. ACM Press/Addison-W esley Publishing Co., 1995. [51] Beerud Sheth and Pattie Maes. Evolving agents for personalized information filtering. In Artificial Intelligence for Applications, 1993. Proceedings., Ninth Confer ence on , pages 345–352. IEEE, 1993. [52] Gábor T akács, István Pilászy , Bottyán Németh, and Domonkos T ikk. Major components of the gravity recommendation system. ACM SIGKDD Explorations Newsletter , 9(2):80–83, 2007. [53] Gábor T akács, István Pilászy , Bottyán Németh, and Domonkos T ikk. Scalable collaborative filtering approaches for large recommender systems. The Journal of Machine Learning Resear ch , 10:623–656, 2009. [54] Y i Zhang, Jamie Callan, and Thomas Minka. Novelty and redundancy detection in adaptive filtering. In Proceedings of the 25th annual international ACM SIGIR conference on Resear ch and development in information r etrieval , pages 81–88. ACM, 2002.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment