Bayesian Poisson Tucker Decomposition for Learning the Structure of International Relations
We introduce Bayesian Poisson Tucker decomposition (BPTD) for modeling country--country interaction event data. These data consist of interaction events of the form "country $i$ took action $a$ toward country $j$ at time $t$." BPTD discovers overlapp…
Authors: Aaron Schein, Mingyuan Zhou, David M. Blei
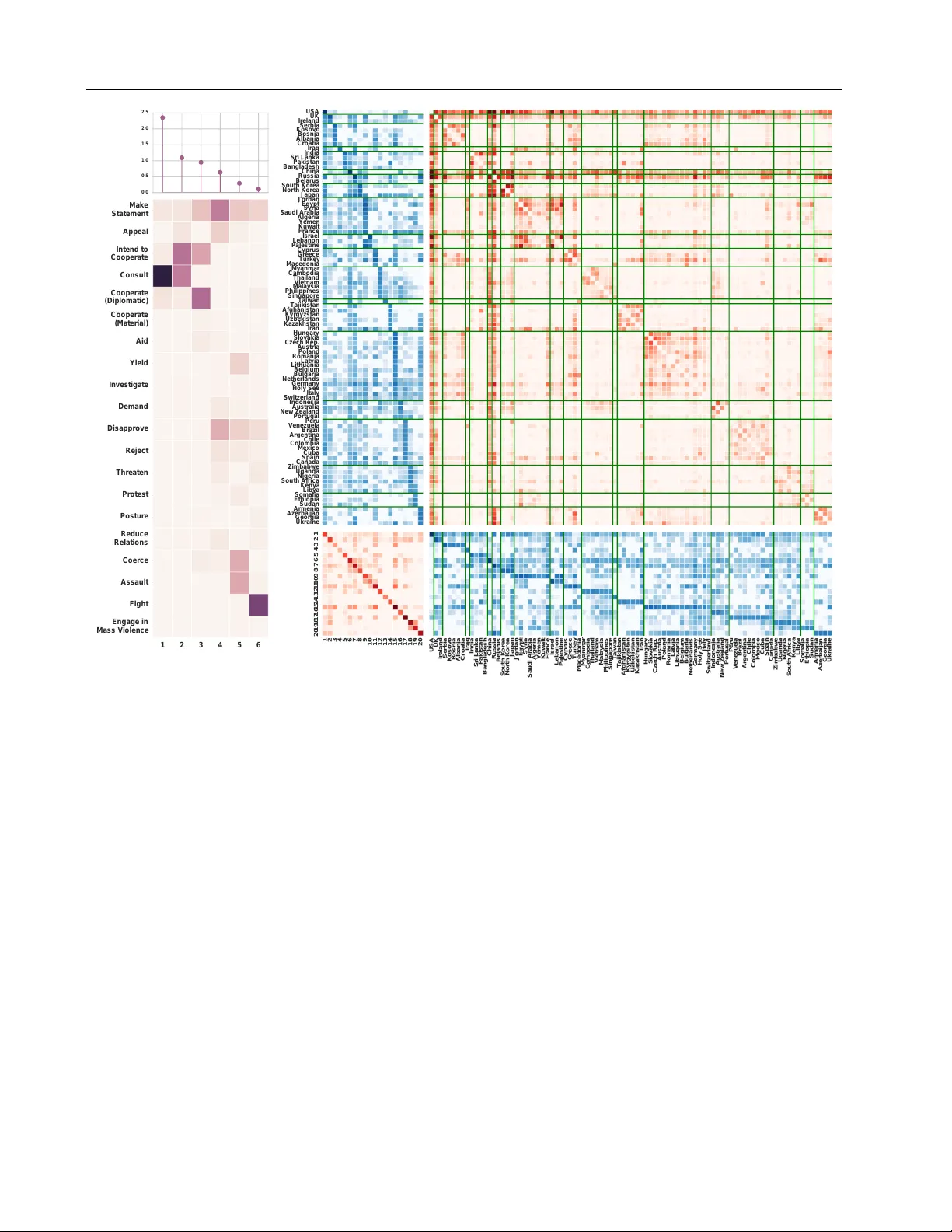
Bayesian P oisson T ucker Decomposition f or Learning the Structur e of International Relations Aaron Schein A S C H E I N @ C S . U M A S S . E D U Univ ersity of Massachusetts Amherst Mingyuan Zhou M I N G Y UA N . Z H O U @ M C C O M B S . U T E X A S . E D U Univ ersity of T e xas at Austin David M. Blei DA V I D . B L E I @ C O L U M B I A . E D U Columbia Univ ersity Hanna W allach W A L L AC H @ M I C R O S O F T . C O M Microsoft Research New Y ork City Abstract W e introduce Bayesian Poisson T ucker de- composition (BPTD) for modeling country– country interaction ev ent data. These data con- sist of interaction ev ents of the form “coun- try i took action a tow ard country j at time t . ” BPTD discovers overlapping country– community memberships, including the number of latent communities. In addition, it discovers directed community–community interaction net- works that are specific to “topics” of action types and temporal “regimes. ” W e show that BPTD yields an efficient MCMC inference algorithm and achie ves better predictiv e performance than related models. W e also demonstrate that it dis- cov ers interpretable latent structure that agrees with our knowledge of international relations. 1. Introduction Like their inhabitants, countries interact with one another: they consult, negotiate, trade, threaten, and fight. These interactions are seldom uncoordinated. Rather , they are connected by a fabric of ov erlapping communities, such as security coalitions, treaties, trade cartels, and military al- liances. For e xample, OPEC coordinates the petroleum e x- port policies of its thirteen member countries, LAIA fosters trade among Latin American countries, and N A T O guaran- tees collectiv e defense against attacks by external parties. Pr oceedings of the 33 rd International Conference on Machine Learning , New Y ork, NY , USA, 2016. JMLR: W&CP volume 48. Copyright 2016 by the author(s). A single country can belong to multiple communities, re- flecting its dif ferent identities. For example, V enezuela— an oil-producing country and a Latin American country—is a member of both OPEC and LAIA. When V enezuela inter- acts with other countries, it sometimes does so as an OPEC member and sometimes does so as a LAIA member . Countries engage in both within-community and between- community interactions. For example, when acting as an OPEC member , V enezuela consults with other OPEC countries, b ut trades with non-OPEC, oil-importing coun- tries. Moreover , although V enezuela engages in between- community interactions when trading as an OPEC member, it engages in within-community interactions when trading as a LAIA member . T o understand or predict ho w countries interact, we must account for their community member- ships and how those memberships influence their actions. In this paper , we take a ne w approach to learning ov er- lapping communities from interaction e vents of the form “country i took action a toward country j at time t . ” A data set of such interaction ev ents can be represented as either 1) a set of e vent tok ens, 2) a tensor of e vent type counts, or 3) a series of weighted multinetworks. Models that use the token representation naturally yield ef ficient inference al- gorithms, models that use the tensor representation exhibit good predictive performance, and models that use the net- work representation learn latent structure that aligns with well-known concepts such as communities. Previous mod- els of interaction ev ent data have each used a subset of these representations. Our approach—Bayesian Poisson T ucker decomposition (BPTD)—takes adv antage of all three. Bayesian P oisson T ucker Decomposition for Lear ning the Structure of International Relations 1 2 3 4 5 6 7 8 9 10 11 12 Estonia Denmark Slovenia Finland Sweden Holy See Austria Lithuania Switzerland Latvia Hungary Netherlands Belgium Bulgaria Slovakia Romania Czech Rep. Poland Croatia Italy Germany France Macedonia Cyprus Greece Turkey Montenegro Kosovo Albania Bosnia Serbia 1 2 3 4 5 6 7 8 9 10 11 12 12 11 10 9 8 7 6 5 4 3 2 1 Figure 1. Latent structure learned by BPTD from country– country interaction ev ents between 1995 and 2000. T op right : A community–community interaction network specific to a single topic of action types and temporal regime. The topic places most of its mass on the Intend to Cooperate and Consult actions, so this network represents cooperative community–community in- teractions. The two strongest between-community interactions (circled) are 2 − → 5 and 2 − → 7. Left : Each row depicts the o ver- lapping community memberships for a single country . W e sho w only those countries whose strongest community membership is to either community 2, 5, or 7. W e ordered the countries ac- cordingly . Countries strongly associated with community 7 are at highlighted in red; countries associated with community 5 are highlighted in green; and countries associated with community 2 are highlighted in purple. Bottom right : Each country is col- ored according to its strongest community membership. The la- tent communities hav e a very strong geographic interpretation. BPTD b uilds on the classic T ucker decomposition ( T ucker , 1964 ) to factorize a tensor of event type counts into three factor matrices and a four-dimensional core tensor (sec- tion 2 ). The factor matrices embed countries into com- munities, action types into “topics, ” and time steps into “regimes. ” The core tensor interacts communities, top- ics, and regimes. The country–community factors en- able BPTD to learn ov erlapping community member- ships, while the core tensor enables it to learn directed community–community interaction networks specific to topics of action types and temporal regimes. Figure 1 il- lustrates this structure. BPTD leads to an efficient MCMC inference algorithm (section 4 ) and achie ves better predic- tiv e performance than related models (section 6 ). Finally , BPTD discovers interpretable latent structure that agrees with our knowledge of international relations (section 7 ). 2. Bayesian P oisson T ucker Decomposition W e can represent a data set of interaction events as a set of N e vent tokens, where a single token e n = ( i a − → j, t ) indicates that sender country i ∈ [ V ] took action a ∈ [ A ] tow ard receiv er country j ∈ [ V ] during time step t ∈ [ T ] . Alternativ ely , we can aggregate these e vent tokens into a four-dimensional tensor Y , where element y ( t ) i a − → j is a count of the number of ev ents of type ( i a − → j, t ) . This tensor will be sparse because most ev ent types never actually occur in practice. Finally , we can equiv alently view this count tensor as a series of T weighted multinetwork snapshots, where the weight on edge i a − → j in the t th snapshot is y ( t ) i a − → j . BPTD models each element of count tensor Y as y ( t ) i a − → j ∼ Po C X c =1 θ ic C X d =1 θ j d K X k =1 φ ak R X r =1 ψ tr λ ( r ) c k − → d ! , (1) where θ ic , θ j d , φ ak , ψ tr , and λ ( r ) c k − → d are positive real num- bers. Factors θ ic and θ j d capture the rates at which coun- tries i and j participate in communities c and d , respec- tiv ely; factor φ ak captures the strength of association be- tween action a and topic k ; and ψ tr captures how well regime r explains the events in time step t . W e can col- lectiv ely view the V × C country–community factors as a latent f actor matrix Θ , where the i th row represents country i ’ s community memberships. Similarly , we can view the A × K action–topic factors and the T × R time-step–regime factors as latent factor matrices Φ and Ψ , respectively . Fac- tor λ ( r ) c k − → d captures the rate at which community c takes ac- tions associated with topic k toward community d during regime r . The C × C × K × R such factors form a core tensor Λ that interacts communities, topics, and re gimes. The country–community factors are gamma-distrib uted, θ ic ∼ Γ( α i , β i ) , (2) where the shape and rate parameters α i and β i are specific to country i . W e place an uninformativ e gamma prior over these shape and rate parameters: α i , β i ∼ Γ( 0 , 0 ) . This hierarchical prior enables BPTD to express heterogeneity in the countries’ rates of activity . For example, we expect that the US will engage in more interactions than Burundi. The action–topic and time-step–regime factors are also gamma-distributed; howe ver , we assume that these factors are drawn directly from an uninformati ve gamma prior , φ ak , ψ tr ∼ Γ( 0 , 0 ) . (3) Because BPTD learns a single embedding of countries into communities, it preserves the traditional network-based notion of community membership. Any sender–receiv er asymmetry is captured by the core tensor Λ , which we can Bayesian P oisson T ucker Decomposition for Lear ning the Structure of International Relations view as a compression of count tensor Y . By allo wing on-diagonal elements, which we denote by λ ( r ) c k and of f- diagonal elements to be non-zero, the core tensor can rep- resent both within- and between-community interactions. The elements of the core tensor are gamma-distributed, λ ( r ) c k ∼ Γ η c η ↔ c ν k ρ r , δ (4) λ ( r ) c k − → d ∼ Γ( η ↔ c η ↔ d ν k ρ r , δ ) c 6 = d. (5) Each community c ∈ [ C ] has two positive weights η c and η ↔ c that capture its rates of within- and between- community interaction, respecti vely . Each topic k ∈ [ K ] has a positiv e weight ν k , while each regime r ∈ [ R ] has a positiv e weight ρ r . W e place an uninformati ve prior ov er the within-community interaction rates and gamma shrink- age priors over the other weights: η c ∼ Γ( 0 , 0 ) , η ↔ c ∼ Γ( γ 0 / C , ζ ) , ν k ∼ Γ( γ 0 / K , ζ ) , and ρ r ∼ Γ( γ 0 / R , ζ ) . These priors bias BPTD tow ard learning latent structure that is sparse. Finally , we assume that δ and ζ are drawn from an uninformativ e gamma prior: δ, ζ ∼ Γ( 0 , 0 ) . As K → ∞ , the topic weights and their corresponding action–topic factors constitute a draw G K = P ∞ k =1 ν k 1 φ k from a gamma process ( Ferguson , 1973 ). Similarly , as R → ∞ , the regime weights and their correspond- ing time-step–re gime factors constitute a draw G R = P ∞ r =1 ρ r 1 ψ r from another gamma process. As C → ∞ , the within- and between-community interaction weights and their corresponding country–community factors con- stitute a draw G C = P ∞ c =1 η ↔ c 1 θ c from a marked gamma process ( Kingman , 1972 ). The mark associated with atom θ c = ( θ 1 c , . . . , θ V c ) is η c . W e can vie w the elements of the core tensor and their corresponding factors as a draw G = P ∞ c =1 P ∞ d =1 P ∞ k =1 P ∞ r =1 λ ( r ) c k − → d 1 θ c , θ d , φ k , ψ r from a gamma process, pro vided that the e xpected sum of the core tensor elements is finite. This multirelational gamma pro- cess extends the relational g amma process of Zhou ( 2015 ). Proposition 1: In the limit as C , K , R → ∞ , the expected sum of the cor e tensor elements is finite and equal to E ∞ X c =1 ∞ X k =1 ∞ X r =1 λ ( r ) c k + X d 6 = c λ ( r ) c k − → d = 1 δ γ 3 0 ζ 3 + γ 4 0 ζ 4 . W e prov e this proposition in the supplementary material. 3. Connections to Pre vious W ork Poisson CP decomposition: DuBois & Smyth ( 2010 ) de- veloped a model that assigns each event token (ignoring time steps) to one of Q latent classes, where each class q ∈ [ Q ] is characterized by three categorical distributions— θ → q ov er senders, θ ← q ov er recei vers, and φ q ov er actions—i.e., P ( e n = ( i a − → j, t ) | z n = q ) = θ → iq θ ← j q φ aq . (6) This model is closely related to the Poisson-based model of Schein et al. ( 2015 ), which explicitly uses the canoni- cal polyadic (CP) tensor decomposition ( Harshman , 1970 ) to factorize count tensor Y into four latent factor matrices. These factor matrices jointly embed senders, receivers, ac- tion types, and time steps into a Q -dimensional space, y ( t ) i a − → j ∼ Po Q X q =1 θ → iq θ ← j q φ aq ψ tq ! , (7) where θ → iq , θ ← j q , φ aq , and ψ tq are positiv e real numbers. Schein et al. ’ s model generalizes Bayesian Poisson matrix factorization ( Cemgil , 2009 ; Gopalan et al. , 2014 ; 2015 ; Zhou & Carin , 2015 ) and non-Bayesian Poisson CP de- composition ( Chi & Kolda , 2012 ; W elling & W eber , 2001 ). Although Schein et al. ’ s model is expressed in terms of a tensor of e vent type counts, the relationship between the multinomial and Poisson distributions ( Kingman , 1972 ) means that we can also express it in terms of a set of ev ent tokens. This yields an equation that is similar to equation 6 , P ( e n = ( i a − → j, t ) | z n = q ) ∝ θ → iq θ ← j q φ aq ψ tq . (8) Con versely , DuBois & Smyth ’ s model can be expressed as a CP tensor decomposition. This equiv alence is anal- ogous to the relationship between Poisson matrix factor- ization and latent Dirichlet allocation ( Blei et al. , 2003 ). W e can make Schein et al. ’ s model nonparametric by adding a per-class positi ve weight λ q ∼ Γ( γ 0 Q , ζ ) , i.e., y ( t ) i a − → j ∼ Po Q X q =1 θ → iq θ ← j q φ aq ψ tq λ q ! . (9) As Q → ∞ the per-class weights and their corresponding latent factors constitute a draw from a g amma process. Adding this per-class weight reveals that CP decomposi- tion is a special case of T ucker decomposition where the cardinalities of the latent dimensions are equal and the of f- diagonal elements of the core tensor are zero. DuBois & Smyth ’ s and Schein et al. ’ s models are therefore highly constrained special cases of BPTD that cannot capture dimension-specific structure, such as communities of coun- tries or topics of action types. These models require each latent class to jointly summarize information about senders, receiv ers, action types, and time steps. This requirement conflates communities of countries and topics of action types, thus forcing each class to capture potentially redun- dant information. Moreover , by definition, CP decompo- sition models cannot express between-community interac- tions and cannot express sender–recei ver asymmetry with- out learning completely separate latent factor matrices for Bayesian P oisson T ucker Decomposition for Lear ning the Structure of International Relations senders and receiv ers. These limitations mak e it hard to in- terpret these models as learning community memberships. Infinite relational models: The infinite relational model (IRM) of Kemp et al. ( 2006 ) also learns latent structure specific to each dimension of an M -dimensional tensor; howe ver , unlike BPTD, the elements of this tensor are bi- nary , indicating the presence or absence of the correspond- ing e vent type. The IRM therefore uses a Bernoulli like- lihood. Schmidt & Mørup ( 2013 ) extended the IRM to model a tensor of event counts by replacing the Bernoulli likelihood with a Poisson likelihood (and gamma priors): y ( t ) i a − → j ∼ Po λ ( z t ) z i z a − → z j , (10) where z i , z j ∈ [ C ] are the respectiv e community assign- ments of countries i and j , z a ∈ [ K ] is the topic as- signment of action a , and z t ∈ [ R ] is the regime assign- ment of time step t . This model, which we refer to as the gamma–Poisson IRM (GPIRM), allocates M -dimensional ev ent types to M -dimensional latent classes—e.g., it allo- cates all tokens of type ( i a − → j, t ) to class ( z i z a − → z j , z t ) . The GPIRM is a special case of BPTD where the rows of the latent factor matrices are constrained to be “one-hot” binary vectors—i.e., θ ic = 1 ( z i = c ) , θ j d = 1 ( z j = d ) , φ ak = 1 ( z a = k ) , and ψ tr = 1 ( z t = r ) . With this constraint, the Poisson rates in equations 1 and 10 are equal. Unlik e BPTD, the GPIRM is a single-membership model. In ad- dition, it cannot express heterogeneity in rates of activity of the countries, action types, and time steps. The latter limitation can be remedied by letting θ iz i , θ j z j , φ az a , and ψ tz t be positi ve real numbers. W e refer to this variant of the GPIRM as the degree-corrected GPIRM (DCGPIRM). Stochastic block models: The IRM itself generalizes the stochastic block model (SBM) of No wicki & Sni- jders ( 2001 ), which learns latent structure from binary net- works. Although the SBM was originally specified using a Bernoulli likelihood, Karrer & Ne wman ( 2011 ) introduced an alternativ e specification that uses the Poisson likelihood: y i − → j ∼ Po C X c =1 θ ic C X d =1 θ j d λ c − → d ! , (11) where θ ic = 1 ( z i = c ) , θ j = 1 ( z j = d ) , and λ c − → d is a positiv e real number . Like the IRM and the GPIRM, the SBM is a single-membership model and cannot express heterogeneity in the countries’ rates of activity . Airoldi et al. ( 2008 ) addressed the former limitation by letting θ ic ∈ [0 , 1] such that P C c =1 θ ic = 1 . Meanwhile, Karrer & Ne wman ( 2011 ) addressed the latter limitation by allow- ing both θ iz i and θ j z j to be positi ve real numbers, much like the DCGPIRM. Ball et al. ( 2011 ) simultaneously ad- dressed both limitations by letting θ ic , θ j d ≥ 0 , but con- strained λ c − → d = λ d − → c . Finally , Zhou ( 2015 ) extended Ball et al. ’ s model to be nonparametric and introduced the Poisson–Bernoulli distribution to link binary data to the Poisson likelihood in a principled fashion. In this model, the elements of the core matrix and their corresponding fac- tors constitute a draw from a relational gamma process. Non-Poisson T ucker decomposition: Researchers some- times refer to the Poisson rate in equation 11 as be- ing “bilinear” because it can equiv alently be written as θ j Λ θ > i . Nickel et al. ( 2012 ) introduced RESCAL— a non-probabilistic bilinear model for binary data that achiev es state-of-the-art performance at relation extraction. Nickel et al. ( 2015 ) then introduced sev eral extensions for extracting relations of dif ferent types. Bilinear models, such as RESCAL and its extensions, are all special cases (albeit non-probabilistic ones) of T ucker decomposition. Hoff ( 2015 ) recently dev eloped a Gaussian-based T ucker decomposition model and multilinear tensor regression model ( Hoff , 2014 ) for analyzing interaction e vent data. Finally , there are many other T ucker decomposition meth- ods ( Kolda & Bader , 2009 ). Although these include non- parametric ( Xu et al. , 2012 ) and nonne gativ e v ariants ( Kim & Choi , 20007 ; Mørup et al. , 2008 ; Cichocki et al. , 2009 ), BPTD is the first such model to use a Poisson likelihood. 4. Posterior Infer ence Giv en an observed count tensor Y , inference in BPTD in- volv es “in verting” the generati ve process to obtain the pos- terior distribution over the parameters conditioned on Y and hyperparameters 0 and γ 0 . The posterior distribution is analytically intractable; ho wev er, we can approximate it using a set of posterior samples. W e dra w these sam- ples using Gibbs sampling, repeatedly resampling the v alue of each parameter from its conditional posterior giv en Y , 0 , γ 0 , and the current v alues of the other parameters. W e express each parameter’ s conditional posterior in a closed form using gamma–Poisson conjugacy and the auxiliary variable techniques of Zhou & Carin ( 2012 ). W e provide the conditional posteriors in the supplementary material. The conditional posteriors depend on Y via a set of “la- tent sources” ( Cemgil , 2009 ) or subcounts. Because of the Poisson additivity theorem ( Kingman , 1972 ), each latent source y ( tr ) ic ak − → j d is a Poisson-distributed random v ariable: y ( tr ) ic ak − → j d ∼ Po θ ic θ j d φ ak ψ tr λ ( r ) c k − → d (12) y ( t ) i a − → j = C X c =1 D X d =1 K X k =1 R X r =1 y ( tr ) ic ak − → j d . (13) T ogether , equations 12 and 13 are equiv alent to equation 1 . In practice, we can equiv alently view each latent source in Bayesian P oisson T ucker Decomposition for Lear ning the Structure of International Relations terms of the token representation described in section 2 , y ( tr ) ic ak − → j d = N X n =1 1 ( e n = ( i a − → j, t )) 1 ( z n = ( c k − → d, r )) , (14) where each token’ s class assignment z n is an auxiliary la- tent variable. Using this representation, computing the la- tent sources (given the current values of the model param- eters) simply in volves allocating event tokens to classes, much like the inference algorithm for DuBois & Smyth ’ s model, and aggregating them using equation 14 . The con- ditional posterior for each token’ s class assignment is P ( z n = ( c k − → d, r ) | e n = ( i a − → j, t ) , Y , 0 , γ 0 , . . . ) ∝ θ ic θ j d φ ak ψ tr λ ( r ) c k − → d . (15) Computation is dominated by the normalizing constant Z ( t ) i a − → j = C X c =1 C X d =1 K X k =1 R X r =1 θ ic θ j d φ ak ψ tr λ ( r ) c k − → d . (16) Computing this normalizing constant na ¨ ıvely in volv es O ( C × C × K × R ) operations; howe ver , because each latent class ( c k − → d, r ) is composed of four separate dimen- sions, we can improv e efficienc y . W e instead compute Z ( t ) i a − → j = C X c =1 θ ic C X d =1 θ j d K X k =1 θ ak R X r =1 ψ tr λ ( r ) c k − → d , (17) which in volv es O ( C + C + K + R ) operations. Compositional allocation using equations 15 and 17 im- prov es computational ef ficiency significantly over na ¨ ıve non-compositional allocation using equations 15 and 16 . In practice, we set C , K , and R to lar ge values to approximate the nonparametric interpretation of BPTD. If, for example, C = 50 , K = 10 , and R = 5 , computing the normalizing constant for equation 15 using equation 16 requires 2,753 times the number of operations implied by equation 17 . Proposition 2: F or an M -dimensional core tensor with D 1 × . . . × D M elements, computing the normalizing con- stant using non-compositional allocation r equir es 1 ≤ π < ∞ times the number of operations requir ed to compute it using compositional allocation. When D 1 = . . . = D M = 1 , π = 1 . As D m , D m 0 → ∞ for any m and m 0 6 = m , π → ∞ . W e prov e this proposition in the supplementary material. BPTD and other Poisson-based models yield allocation in- ference algorithms that tak e adv antage of the inherent spar- sity of the data and scale with the number of event to- kens. In contrast, non-Poisson tensor decomposition mod- els (including Hof f ’ s model) lead to algorithms that scale with the size of the count tensor . Allocation-based infer- ence in BPTD is especially ef ficient because it composi- tionally allocates each M -dimensional e vent token to an V V A K C C Figure 2. Compositional allocation. For clarity , we sho w the allo- cation process for a three-dimensional count tensor (ignoring time steps). Observed three-dimensional event tokens (left) are com- positionally allocated to three-dimensional latent classes (right). M -dimensional latent class. Figure 2 illustrates this pro- cess. CP decomposition models, such as those of DuBois & Smyth ( 2010 ) and Schein et al. ( 2015 ), only permit non- compositional allocation. For example, while BPTD allo- cates each token e n = ( i a − → j, t ) to a four-dimensional la- tent class ( c k − → d, r ) , Schein et al. ’ s model allocates e n to a one-dimensional latent class q that cannot be decomposed. Therefore, when Q = C × C × K × R , BPTD yields a faster allocation inference algorithm than Schein et al. ’ s model. 5. Country–Country Interaction Event Data Our data come from the Integrated Crisis Early W arn- ing System (ICEWS) of Boschee et al. and the Global Database of Ev ents, Language, and T one (GDEL T) of Lee- taru & Schrodt ( 2013 ). ICEWS and GDEL T both use the Conflict and Mediation Event Observations (CAMEO) hi- erarchy ( Gerner et al. ) for senders, receiv ers, and actions. The top-lev el CAMEO coding for senders and receiv ers is their country affiliation, while lower lev els in the hier- archy incorporate more specific attributes like their sec- tors (e.g., government or civilian) and their religious or ethnic affiliations. When studying international relations using CAMEO-coded ev ent data, researchers usually con- sider only the senders’ and receivers’ countries. There are 249 countries represented in ICEWS, which include non- univ ersally recognized states, such as Occupied P alestinian T erritory , and former states, such as F ormer Y ugoslav Re- public of Macedonia ; there are 233 countries in GDEL T . The top lev el for actions, which we use in our analyses, consists of twenty action classes, roughly ranked according to their ov erall sentiment. For example, the most neg ative is 20—Use Unconventional Mass V iolence . CAMEO further divides these actions into the QuadClass scheme: V erbal Cooperation (actions 2–5), Material Cooperation (actions 6–7), V erbal Conflict (actions 8–16), and Material Conflict (16–20). The first action ( 1—Make Statement ) is neutral. Bayesian P oisson T ucker Decomposition for Lear ning the Structure of International Relations 6. Predicti ve Analysis Baseline models: W e compared BPTD’ s predictiv e perfor - mance to that of three baseline models, described in sec- tion 3 : 1) GPIRM, 2) DCGPIRM, and 3) the Bayesian Poisson tensor factorization (BPTF) model of Schein et al. ( 2015 ). All three models use a Poisson likelihood and have the same two hyperparameters as BPTD—i.e., 0 and γ 0 . W e set 0 to 0.1, as recommended by Gelman ( 2006 ), and we set γ 0 so that ( γ 0 / C ) 2 ( γ 0 / K ) ( γ 0 / R ) = 0 . 01 . This parameterization encourages the elements of the core ten- sor Λ to be sparse. W e implemented an MCMC inference algorithm for each model. W e pro vide the full generativ e process for all three models in the supplementary material. GPIRM and DCGPIRM are both T ucker decomposition models and thus allocate ev ents to four-dimensional la- tent classes. The cardinalities of these latent dimensions are the same as BPTD’ s—i.e., C , K , and R . In con- trast, BPTF is a CP decomposition model and thus allo- cates ev ents to one-dimensional latent classes. W e set the cardinality of this dimension so that the total number of latent factors in BPTF’ s likelihood was equal to the to- tal number of latent factors in BPTD’ s likelihood—i.e., Q = d ( V × C )+( A × K )+( T × R )+( C 2 × K × R ) V + V + A + T +1 e . W e chose not to let BPTF and BPTD use the same number of latent classes—i.e., to set Q = C 2 × K × R . BPTF does not permit non-compositional allocation, so MCMC inference becomes very slow for ev en moderate values of C , K , and R . CP decomposition models also tend to overfit when Q is large ( Zhao et al. , 2015 ). Throughout our predictiv e ex- periments, we let C = 20 , K = 6 , and R = 3 . These values were well-supported by the data, as we explain in section 7 . Experimental setup: W e constructed twelve different ob- served tensors—six from ICEWS and six from GDEL T . Fiv e of the six tensors for each source (ICEWS or GDEL T) correspond to one-year time spans with monthly time steps, starting with 2004 and ending with 2008; the sixth corre- sponds to a five-year time span with monthly time steps, spanning 1995–2000. W e divided each tensor Y into a training tensor Y train = Y (1) , . . . , Y ( T − 3) and a test ten- sor Y test = Y ( T − 2) , . . . , Y ( T ) . W e further divided each test tensor into a held-out portion and an observed por- tion via a binary mask. W e experimented with two dif- ferent masks: one that treats the elements in volving the most acti ve fifteen countries as the held-out portion and the remaining elements as the observed portion, and one that does the opposite. The first mask enabled us to e valuate the models’ reconstructions of the densest (and arguably most interesting) portion of each test tensor, while the sec- ond mask enabled us to ev aluate their reconstructions of its complement. Across the entire GDEL T database, for example, the elements in volving the most activ e fifteen countries—i.e., 6% of all 233 countries—account for 30% of the ev ent tokens. Moreover , 40% of these elements are non-zero. These non-zero elements are highly dispersed, with a variance-to-mean ratio of 220. In contrast, only 0.7% of the elements inv olving the other countries are non- zero. These elements have a v ariance-to-mean ratio of 26. For each combination of the four models, twelve tensors, and two masks, we ran 5,000 iterations of MCMC inference on the training tensor . W e clamped the country–community factors, the action–topic factors, and the core tensor and then inferred the time-step–regime factors for the test ten- sor using its observed portion by running 1,000 iterations of MCMC inference. W e sa ved e very tenth sample after the first 500. W e used each sample, along with the country– community factors, the action–topic factors, and the core tensor , to compute the Poisson rate for each element in the held-out portion of the test tensor . Finally , we averaged these rates across samples and used each element’ s av er- age rate to compute its probability . W e combined the held- out elements’ probabilities by taking their geometric mean or , equiv alently , by computing their inv erse perplexity . W e chose this combination strategy to ensure that the models were penalized heavily for making poor predictions on the non-zero elements and were not re warded excessi vely for making good predictions on the zero elements. By clamp- ing the country–community factors, the action–topic fac- tors, and the core tensor after training, our experimental setup is analogous to that used to assess collaborativ e fil- tering models’ strong generalization ability ( Marlin , 2004 ). Results: Figure 3 illustrates the results for each combi- nation of the four models, twelv e tensors, and two masks. The top ro w contains the results from the twelve experi- ments inv olving the first mask, where the elements in volv- ing the most activ e fifteen countries were treated as the held-out portion. BPTD outperformed the baselines signif- icantly . BPTF—itself a state-of-the-art model—performed better than BPTD in only one e xperiment. In general, the T ucker decomposition allows BPTD to learn richer latent structure that generalizes better to held-out data. The bot- tom row contains the results from the experiments inv olv- ing the second mask. The models’ performance was closer in these experiments, probably because of the large pro- portion of easy-to-predict zero elements. BPTD and BPTF performed indistinguishably in these e xperiments, and both models outperformed the GPIRM and the DCGPIRM. The single-membership nature of the GPIRM and the DCG- PIRM prev ents them from expressing high le vels of hetero- geneity in the countries’ rates of activity . When the held- out elements were highly dispersed, these models some- times made extremely inaccurate predictions. In contrast, the mixed-membership nature of BPTD and BPTF allo ws them to better express heterogeneous rates of acti vity . Bayesian P oisson T ucker Decomposition for Lear ning the Structure of International Relations 0.0 0.5 1.0 3.9e-03 3.9e-03 3.9e-03 3.9e-03 GDELT 1995-2000 3.3e-02 3.3e-02 3.3e-02 3.3e-02 ICEWS 1995-2000 6.4e-04 6.4e-04 6.4e-04 6.4e-04 GDELT 2004 4.9e-02 4.9e-02 4.9e-02 4.9e-02 ICEWS 2004 1.1e-02 1.1e-02 1.1e-02 1.1e-02 GDELT 2005 2.6e-02 2.6e-02 2.6e-02 2.6e-02 ICEWS 2005 1.2e-04 1.2e-04 1.2e-04 1.2e-04 GDELT 2006 gpirm dcgpirm bptf bptd 1.7e-02 1.7e-02 1.7e-02 1.7e-02 ICEWS 2006 1.4e-06 1.4e-06 1.4e-06 1.4e-06 GDELT 2007 1.2e-02 1.2e-02 1.2e-02 1.2e-02 ICEWS 2007 7.7e-07 7.7e-07 7.7e-07 7.7e-07 GDELT 2008 3.1e-02 3.1e-02 3.1e-02 3.1e-02 ICEWS 2008 0.0 0.5 1.0 9.1e-01 9.1e-01 9.1e-01 9.1e-01 9.8e-01 9.8e-01 9.8e-01 9.8e-01 8.4e-01 8.4e-01 8.4e-01 8.4e-01 9.5e-01 9.5e-01 9.5e-01 9.5e-01 8.8e-01 8.8e-01 8.8e-01 8.8e-01 9.5e-01 9.5e-01 9.5e-01 9.5e-01 8.6e-01 8.6e-01 8.6e-01 8.6e-01 9.4e-01 9.4e-01 9.4e-01 9.4e-01 8.0e-01 8.0e-01 8.0e-01 8.0e-01 9.4e-01 9.4e-01 9.4e-01 9.4e-01 7.1e-01 7.1e-01 7.1e-01 7.1e-01 9.3e-01 9.3e-01 9.3e-01 9.3e-01 Figure 3. Predictive performance. Each plot sho ws the in verse perplexity (higher is better) for the four models: the GPIRM (blue), the DCGPIRM (green), BPTF (red), and BPTD (yello w). In the experiments depicted in the top row , we treated the elements inv olving the most acti ve countries as the held-out portion; in the experiments depicted in the bottom ro w , we treated the remaining elements as the held-out portion. For ease of comparison, we scaled the in verse perplexities to lie between zero and one; we giv e the scales in the top-left corners of the plots. BPTD outperformed the baselines significantly when predicting the denser portion of each test tensor (top row). 7. Exploratory Analysis W e used a tensor of ICEWS e vents spanning 1995–2000, with monthly time steps, to explore the latent structure dis- cov ered by BPTD. W e initially let C = 50 , K = 8 , and R = 3 —i.e., C × C × K × R = 60 , 000 latent classes— and used the shrinkage priors to adapti vely learn the most appropriate numbers of communities, topics, and regimes. W e found C = 20 communities and K = 6 topics with weights that were significantly greater than zero. W e pro- vide a plot of the community weights in the supplementary material. Although all three regimes had non-zero weights, one had a much larger weight than the other two. For comparison, Schein et al. ( 2015 ) used fifty latent classes to model the same data, while Hoff ( 2015 ) used C = 4 , K = 4 , and R = 4 to model a similar tensor from GDEL T . T opics of action types: W e show the inferred action–topic factors as a heatmap in the left subplot of figure 4 . W e ordered the topics by their weights ν 1 , . . . , ν K , which are abov e the heatmap. The inferred topics correspond very closely to CAMEO’ s QuadClass scheme. Moving from left to right, the topics place their mass on increasingly nega- tiv e actions. T opics 1 and 2 place most of their mass on V erbal Cooperation actions; topic 3 places most of its mass on Material Cooperation actions and the neutral 1—Make Statement action; topic 4 places most of its mass on V er- bal Conflict actions and the 1—Make Statement action; and topics 5 and 6 place their mass on Material Conflict actions. T opic-partitioned community–community networks: In the right subplot of figure 4 , we visualize the inferred com- munity structure for topic k = 1 and the most activ e regime r . The bottom-left heatmap is the community–community interaction network Λ ( r ) k . The top-left heatmap depicts the rate at which each country i acts as a sender in each com- munity c —i.e., θ ic P V j =1 P C d =1 θ j d λ ( r ) c k − → d . Similarly , the bottom-right heatmap depicts the rate at which each coun- try acts as a receiv er in each community . The top-right heatmap depicts the number of times each country i took an action associated with topic k tow ard each country j during regime r —i.e., P C c =1 P C d =1 P A a =1 P T t =1 y ( tr ) ic ak − → j d . W e grouped the countries by their strongest community memberships and ordered the communities by their within- community interaction weights η 1 , . . . , η C , from smallest to largest; the thin green lines separate the countries that are strongly associated with one community from the countries that are strongly associated with its adjacent communities. Some communities contain only one or two strongly as- sociated countries. For example, community 1 contains only the US, community 6 contains only China, and com- munity 7 contains only Russia and Belarus. These com- munities mostly engage in between-community interac- tion. Other larger communities, such as communities 9 and 15, mostly engage in within-community interaction. Most communities have a strong geographic interpreta- tion. Moving upward from the bottom, there are com- munities that correspond to Eastern Europe, East Africa, South-Central Africa, Latin America, Australasia, Central Europe, Central Asia, etc. The community–community in- teraction network summarizes the patterns in the top-right heatmap. This topic is dominated by the 4–Consult action, so the network is symmetric; the more ne gativ e topics ha ve asymmetric community–community interaction networks. W e therefore hypothesize that cooperation is an inherently reciprocal type of interaction. W e provide visualizations for the other fiv e topics in the supplementary material. 8. Summary W e presented Bayesian Poisson Tuck er decomposition (BPTD) for learning the latent structure of international re- lations from country–country interaction events of the form “country i took action a toward country j at time t . ” Unlike previous models, BPTD takes advantage of all three repre- sentations of an interaction ev ent data set: 1) a set of event tokens, 2) a tensor of event type counts, and 3) a series of weighted multinetwork snapshots. BPTD uses a Poisson Bayesian P oisson T ucker Decomposition for Lear ning the Structure of International Relations 1 2 3 4 5 6 Engage in Mass Violence Fight Assault Coerce Reduce Relations Posture Protest Threaten Reject Disapprove Demand Investigate Yield Aid Cooperate (Material) Cooperate (Diplomatic) Consult Intend to Cooperate Appeal Make Statement 0.0 0.5 1.0 1.5 2.0 2.5 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 Ukraine Georgia Azerbaijan Armenia Sudan Ethiopia Somalia Libya Kenya South Africa Nigeria Uganda Zimbabwe Canada Spain Cuba Mexico Colombia Chile Argentina Brazil Venezuela Peru Portugal New Zealand Australia Indonesia Switzerland Italy Holy See Germany Netherlands Bulgaria Belgium Lithuania Latvia Romania Poland Austria Czech Rep. Slovakia Hungary Iran Kazakhstan Uzbekistan Kyrgyzstan Afghanistan Tajikistan Taiwan Singapore Philippines Malaysia Vietnam Thailand Cambodia Myanmar Macedonia Turkey Greece Cyprus Palestine Lebanon Israel France Kuwait Yemen Algeria Saudi Arabia Syria Egypt Jordan Japan North Korea South Korea Belarus Russia China Bangladesh Pakistan Sri Lanka India Iraq Croatia Albania Bosnia Kosovo Serbia Ireland UK USA USA UK Ireland Serbia Kosovo Bosnia Albania Croatia Iraq India Sri Lanka Pakistan Bangladesh China Russia Belarus South Korea North Korea Japan Jordan Egypt Syria Saudi Arabia Algeria Yemen Kuwait France Israel Lebanon Palestine Cyprus Greece Turkey Macedonia Myanmar Cambodia Thailand Vietnam Malaysia Philippines Singapore Taiwan Tajikistan Afghanistan Kyrgyzstan Uzbekistan Kazakhstan Iran Hungary Slovakia Czech Rep. Austria Poland Romania Latvia Lithuania Belgium Bulgaria Netherlands Germany Holy See Italy Switzerland Indonesia Australia New Zealand Portugal Peru Venezuela Brazil Argentina Chile Colombia Mexico Cuba Spain Canada Zimbabwe Uganda Nigeria South Africa Kenya Libya Somalia Ethiopia Sudan Armenia Azerbaijan Georgia Ukraine Figure 4. Left: Action–topic factors. The topics are ordered by ν 1 , . . . , ν K (abov e the heatmap). Right: Latent structure discovered by BPTD for topic k = 1 and the most activ e regime, including the community–community interaction network (bottom left), the rate at which each country acts as a sender (top left) and a recei ver (bottom right) in each community , and the number of times each country i took an action associated with topic k to ward each country j during regime r (top right). W e show only the most acti ve 100 countries. likelihood, respecting the discrete nature of the data and its inherent sparsity . Moreov er, BPTD yields a compositional allocation inference algorithm that is more efficient than non-compositional allocation algorithms. Because BPTD is a T ucker decomposition model, it shares parameters across latent classes. In contrast, CP decomposition mod- els force each latent class to capture potentially redundant information. BPTD therefore “does more with less. ” This efficienc y is reflected in our predictive analysis: BPTD out- performs BPTF—a CP decomposition model—as well as two other baselines. BPTD learns interpretable latent struc- ture that aligns with well-known concepts from the net- works literature. Specifically , BPTD learns latent country– community memberships, including the number of com- munities, as well as directed community–community inter - action networks that are specific to topics of action types and temporal regimes. This structure captures the complex- ity of country–country interactions, while rev ealing pat- terns that agree with our knowledge of international rela- tions. Finally , although we presented BPTD in the context of interaction e vents, BPTD is well suited to learning latent structure from other types of multidimensional count data. Acknowledgements W e thank Abigail Jacobs and Brandon Stew art for help- ful discussions. This work was supported by NSF #SBE- 0965436, #IIS-1247664, #IIS-1320219; ONR #N00014- 11-1-0651; D ARP A #F A8750-14-2-0009, #N66001-15-C- 4032; Adobe; the John T empleton Foundation; the Sloan Foundation; the UMass Amherst Center for Intelligent In- formation Retriev al. Any opinions, findings, conclusions, or recommendations expressed in this material are the au- thors’ and do not necessarily reflect those of the sponsors. Bayesian P oisson T ucker Decomposition for Lear ning the Structure of International Relations References Airoldi, E. M., Blei, D. M., Feinberg, S. E., and Xing, E. P . Mixed membership stochastic blockmodels. J ournal of Machine Learning Resear ch , 9:1981–2014, 2008. Ball, B., Karrer , B., and Newman, M. E. J. Ef ficient and principled method for detecting communities in net- works. Physical Review E , 84(3), 2011. Blei, D., Ng, A., and Jordan, M. Latent Dirichlet allo- cation. J ournal of Mac hine Learning Researc h , 3:993– 1022, 2003. Boschee, E., Lautenschlager, J., O’Brien, S., Shellman, S., Starz, J., and W ard, M. ICEWS coded e vent data. Har - vard Data verse. V10. Cemgil, A. T . Bayesian inference for nonnegati ve matrix factorisation models. Computational Intelligence and Neur oscience , 2009. Chi, E. C. and K olda, T . G. On tensors, sparsity , and non- negati ve factorizations. SIAM Journal on Matrix Analy- sis and Applications , 33(4):1272–1299, 2012. Cichocki, A., Zdunek, R., Phan, A. H., and i Amari, S. Nonne gative Matrix and T ensor F actorizations: Appli- cations to Exploratory Multi-W ay Data Analysis and Blind Sour ce Separation . John W iley & Sons, 2009. DuBois, C. and Smyth, P . Modeling relational e vents via latent classes. In Proceedings of the Sixteenth A CM SIGKDD International Conference on Knowledge Dis- covery and Data Mining , pp. 803–812, 2010. Ferguson, T . S. A Bayesian analysis of some nonparametric problems. The Annals of Statistics , 1(2):209–230, 1973. Gelman, A. Prior distributions for variance parameters in hierarchical models. Bayesian Analysis , 1(3):515–533, 2006. Gerner , D. J., Schrodt, P . A., Abu-Jabr , R., and Y ilmaz, ¨ O. Conflict and mediation ev ent observ ations (CAMEO): A new e vent data frame work for the analysis of foreign pol- icy interactions. W orking paper . Gopalan, P ., Ruiz, F . J. R., Ranganath, R., and Blei, D. M. Bayesian nonparametric Poisson factorization for recommendation systems. In Pr oceedings of the Sev- enteenth International Confer ence on Artificial Intelli- gence and Statistics , v olume 33, pp. 275–283, 2014. Gopalan, P ., Hofman, J., and Blei, D. Scalable recommen- dation with Poisson factorization. In Pr oceedings of the Thirty-F irst Conference on Uncertainty in Artificial In- telligence , 2015. Harshman, R. Foundations of the P ARAF AC procedure: Models and conditions for an “explanatory” multimodal factor analysis. UCLA W orking P apers in Phonetics , 16: 1–84, 1970. Hoff, P . Multilinear tensor re gression for longitudinal rela- tional data. arXiv:1412.0048, 2014. Hoff, P . Equi variant and scale-free Tucker decomposition models. Bayesian Analysis , 2015. Karrer , B. and Newman, M. E. J. Stochastic blockmodels and community structure in networks. Physical Review E , 83(1), 2011. Kemp, C., T enenbaum, J. B., Grif fiths, T . L., Y amada, T ., and Ueda, N. Learning systems of concepts with an infi- nite relational model. In Pr oceedings of the T wenty-F irst National Confer ence on Artificial Intelligence , 2006. Kim, Y .-D. and Choi, S. Nonneg ative Tucker decomposi- tion. In Pr oceedings of the IEEE Confer ence on Com- puter V ision and P attern Recognition , 20007. Kingman, J. F . C. P oisson Pr ocesses . Oxford Univ ersity Press, 1972. K olda, T . G. and Bader, B. W . T ensor decompositions and applications. SIAM Review , 51(3):455–500, 2009. Leetaru, K. and Schrodt, P . GDEL T: Global data on events, location, and tone, 1979–2012. W orking paper, 2013. Marlin, B. Collaborativ e filtering: A machine learning per- spectiv e. Master’ s thesis, Univ ersity of T oronto, 2004. Mørup, M., Hansen, L. K., and Arnfred, S. M. Algorithms for sparse nonnegati ve Tucker decompositions. Neural Computation , 20(8):2112–2131, 2008. Nickel, M., T resp, V ., and Kriegel, H.-P . Factorizing Y A GO: Scalable machine learning for linked data. In Pr oceedings of the T wenty-F irst International W orld W ide W eb Conference , pp. 271–280, 2012. Nickel, M., Murph y , K., T resp, V ., and Gabrilovich, E. A re vie w of relational machine learning for knowledge graphs: From multi-relational link pre- diction to automated knowledge graph construction. arXiv:1503.00759, 2015. Nowicki, K. and Snijders, T . A. B. Estimation and predic- tion for stochastic blockstructures. Journal of the Amer- ican Statistical Association , 96(455):1077–1087, 2001. Schein, A., Paisley , J., Blei, D. M., and W allach, H. Bayesian Poisson tensor factorization for inferrring mul- tilateral relations from sparse dyadic ev ent counts. In Bayesian P oisson T ucker Decomposition for Lear ning the Structure of International Relations Pr oceedings of the T wenty-F irst ACM SIGKDD Inter- national Confer ence on Knowledge Discovery and Data Mining , pp. 1045–1054, 2015. Schmidt, M. N. and Mørup, M. Nonparametric Bayesian modeling of complex networks: An introduction. IEEE Signal Pr ocessing Magazine , 30(3):110–128, 2013. T ucker , L. R. The extension of factor analysis to three- dimensional matrices. In Frederiksen, N. and Gullik- sen, H. (eds.), Contributions to Mathematical Psyc hol- ogy . Holt, Rinehart and W inston, 1964. W elling, M. and W eber, M. Positiv e tensor factorization. P attern Recognition Letters , 22(12):1255–1261, 2001. Xu, Z., Y an, F ., and Qi, Y . Infinite Tucker decomposition: Nonparametric Bayesian models for multiw ay data anal- ysis. In Pr oceedings of the T wenty-Ninth International Confer ence on Mac hine Learning , pp. 1023–1030, 2012. Zhao, Q., Zhang, L., and Cichocki, A. Bayesian CP fac- torization of incomplete tensors with automatic rank de- termination. IEEE T r ansactions on P attern Analysis and Machine Intelligence , 37(9):1751–1763, 2015. Zhou, M. Infinite edge partition models for overlapping community detection and link prediction. In Pr oceed- ings of the Eighteenth International Confer ence on Arti- ficial Intelligence and Statistics , pp. 1135–1143, 2015. Zhou, M. and Carin, L. Augment-and-conquer neg ativ e binomial processes. In Advances in Neural Information Pr ocessing Systems T wenty-F ive , pp. 2546–2554, 2012. Zhou, M. and Carin, L. Negati ve binomial process count and mixture modeling. IEEE T ransactions on P at- tern Analysis and Machine Intelligence , 37(2):307–320, 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment