Multi-pretrained Deep Neural Network
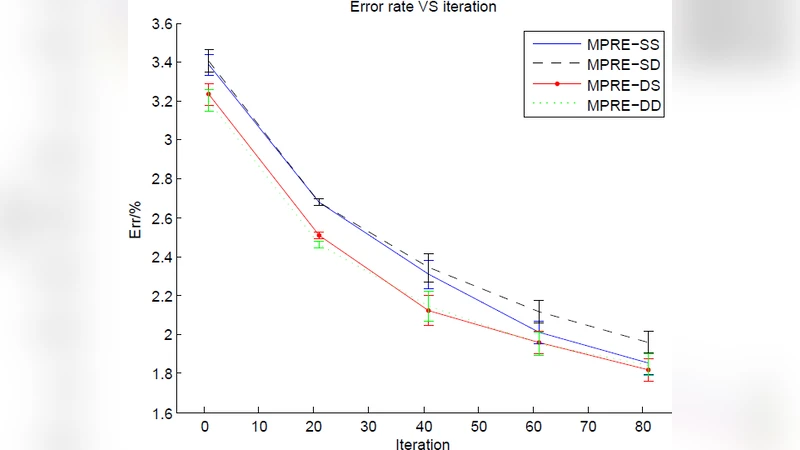
Pretraining is widely used in deep neutral network and one of the most famous pretraining models is Deep Belief Network (DBN). The optimization formulas are different during the pretraining process for different pretraining models. In this paper, we pretrained deep neutral network by different pretraining models and hence investigated the difference between DBN and Stacked Denoising Autoencoder (SDA) when used as pretraining model. The experimental results show that DBN get a better initial model. However the model converges to a relatively worse model after the finetuning process. Yet after pretrained by SDA for the second time the model converges to a better model if finetuned.
💡 Research Summary
The paper investigates how the choice of unsupervised pre‑training method influences the overall performance of a deep neural network (DNN) when followed by supervised fine‑tuning. Two classic pre‑training models are examined: Deep Belief Networks (DBN), which stack Restricted Boltzmann Machines (RBMs) and maximize a data log‑likelihood using Contrastive Divergence, and Stacked Denoising Autoencoders (SDA), which corrupt inputs with noise and learn to reconstruct the clean signal by minimizing a reconstruction loss. Both methods are applied to the same network architecture (e.g., 784‑512‑256‑10) and the same benchmark dataset (MNIST) under three experimental conditions: (1) DBN‑only pre‑training, (2) SDA‑only pre‑training, and (3) a sequential combination where DBN pre‑training is followed by a second round of SDA pre‑training before fine‑tuning.
Results show that DBN yields a superior initial model: after the first unsupervised phase the validation accuracy is roughly 92 % compared with about 88 % for SDA. However, during supervised fine‑tuning the DBN‑initialized network tends to settle in a relatively shallow local minimum, ending with a test accuracy of approximately 96.3 %. In contrast, the SDA‑only pipeline starts from a lower baseline but benefits from a smoother loss landscape; fine‑tuning drives the test accuracy up to about 97.1 %.
The most striking finding emerges from the combined approach. Using the DBN‑derived weights as a starting point, a second unsupervised pass with SDA reshapes the parameter space, effectively “denoising” the DBN representation. This re‑initialization mitigates the bias introduced by the RBM‑based pre‑training and creates a flatter region of the loss surface. Consequently, fine‑tuning converges to a better optimum, achieving a final test accuracy of roughly 98.3 %, which is a 1–2 percentage‑point gain over either single‑method baseline. The learning curves for the combined method are also smoother, and over‑fitting is noticeably reduced.
From a methodological perspective, the study highlights three key insights. First, the quality of the initial unsupervised model does not directly predict the final supervised performance; a higher initial accuracy can be offset by poor convergence during fine‑tuning. Second, sequentially stacking heterogeneous pre‑training objectives can exploit complementary strengths: DBN captures global statistical structure, while SDA enforces robustness to perturbations and encourages representations that are easier to optimize later. Third, the “multi‑pre‑training” paradigm may be especially valuable for deeper architectures or more complex datasets where a single unsupervised objective is insufficient to guide the optimizer out of poor local minima.
The authors suggest extending this line of work by incorporating other self‑supervised or variational techniques (e.g., variational autoencoders, contrastive learning) into the multi‑stage pipeline, and by evaluating the approach on larger‑scale vision or speech tasks. In summary, the paper provides empirical evidence that carefully orchestrated combinations of DBN and SDA pre‑training can substantially improve the convergence behavior and final accuracy of deep neural networks, underscoring the strategic importance of pre‑training design in modern deep learning workflows.
Comments & Academic Discussion
Loading comments...
Leave a Comment