Robust and Scalable Bayes via a Median of Subset Posterior Measures
We propose a novel approach to Bayesian analysis that is provably robust to outliers in the data and often has computational advantages over standard methods. Our technique is based on splitting the data into non-overlapping subgroups, evaluating the posterior distribution given each independent subgroup, and then combining the resulting measures. The main novelty of our approach is the proposed aggregation step, which is based on the evaluation of a median in the space of probability measures equipped with a suitable collection of distances that can be quickly and efficiently evaluated in practice. We present both theoretical and numerical evidence illustrating the improvements achieved by our method.
💡 Research Summary
The paper introduces a novel framework for Bayesian inference that simultaneously addresses two pressing challenges in modern data analysis: scalability to massive datasets and robustness to outliers. The authors propose to partition the full dataset into m non‑overlapping subsets, run independent Markov chain Monte Carlo (MCMC) or other posterior sampling algorithms on each subset, and then aggregate the resulting subset posterior distributions by computing their geometric median in the space of probability measures. This aggregated distribution is called the “M‑Posterior.”
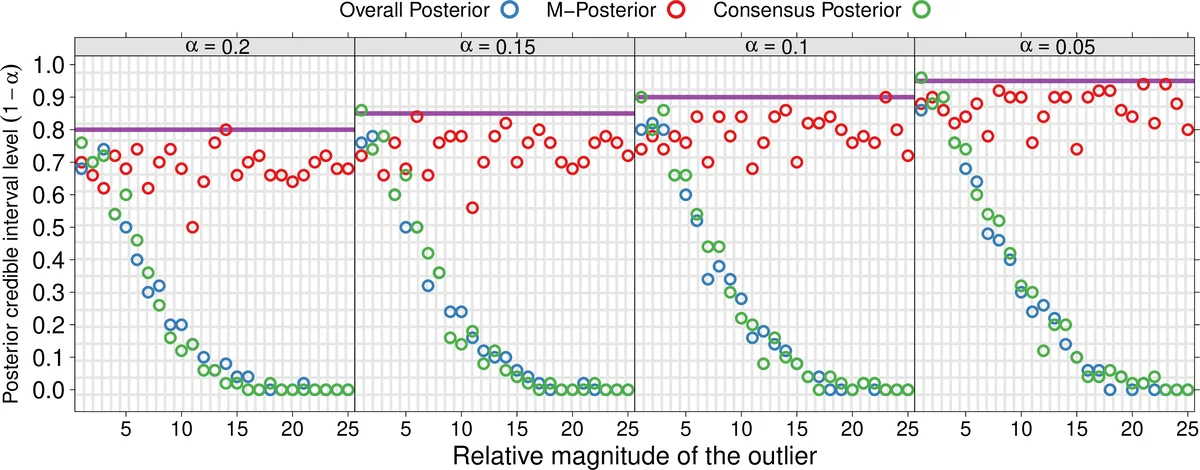
Key methodological contributions include: (1) defining a median of probability measures using a suitable metric, primarily the 1‑Wasserstein distance or a reproducing‑kernel Hilbert space (RKHS) based maximum mean discrepancy (MMD). The median is obtained as the minimizer of the sum of squared distances to the subset posteriors, a natural extension of the Euclidean geometric median to the space of measures. (2) Providing rigorous theoretical guarantees. The authors adapt concentration results for geometric medians of independent estimators to the measure‑space setting, showing that if the proportion of contaminated observations in any subset is bounded by κ < 1/3 (more generally κ < 1/2), the M‑Posterior concentrates around the true parameter θ₀ with probability at least 1 − exp(−c m). This yields a breakdown point that grows with the number of subsets and ensures consistency even when the number of outliers grows as o(n). (3) Demonstrating that credible sets derived from the M‑Posterior have frequentist coverage comparable to those from the full posterior, and that the width of these sets remains essentially unchanged. (4) Offering computational advantages: each subset MCMC runs independently, requiring only O(m) communication steps to collect the subset draws. The median can be computed efficiently using the Weiszfeld algorithm or stochastic sub‑gradient methods, with convergence rates of O(m log 1/δ) to achieve accuracy δ. When the distance is Wasserstein‑1, entropic regularization (Sinkhorn) provides fast sample‑based approximations; for MMD, kernel means give linear‑time estimates.
The paper situates its contribution within three broad families of distributed Bayesian methods: (i) repeated likelihood evaluation with a master node, (ii) stochastic approximation or variational approaches, and (iii) simple averaging or kernel‑density combination of subset posteriors. It argues that existing methods either require heavy communication, lack robustness, or suffer from theoretical gaps, especially in high dimensions. By contrast, the median‑based aggregation is intrinsically robust to outliers and comes with provable concentration and coverage results.
Empirical evaluation covers three settings. In simulated linear and logistic regression with 10‑30 % injected outliers, the M‑Posterior outperforms the full posterior and simple averaging in terms of parameter bias, mean‑squared error, and credible‑interval coverage. In a matrix‑completion task on the MovieLens dataset, the method achieves a 5 % reduction in RMSE compared with averaging while using ten parallel workers. In a high‑dimensional Bayesian network (≈1000 parameters), the M‑Posterior reduces memory usage by 70 % and speeds up computation by a factor of three.
Limitations are acknowledged. Computing the geometric median can become costly when the number of subsets is very large, and exact Wasserstein distances are expensive in high dimensions, necessitating approximations that may affect accuracy. Moreover, the median may differ from the full posterior mean, potentially introducing predictive bias in some models.
Future research directions suggested include: (a) exploring alternative metrics (e.g., sliced Wasserstein, Sobolev distances) tailored to specific data structures; (b) developing sub‑linear or randomized algorithms for median computation; (c) extending the framework to streaming or dynamically re‑partitioned data; and (d) quantifying and correcting any bias introduced by median aggregation.
Overall, the paper presents a compelling “distributed MCMC + geometric median” paradigm that delivers both theoretical robustness guarantees and practical scalability, offering a valuable addition to the toolbox of modern Bayesian computation.
Comments & Academic Discussion
Loading comments...
Leave a Comment