Memory shapes time perception and intertemporal choices
There is a consensus that human and non-human subjects experience temporal distortions in many stages of their perceptual and decision-making systems. Similarly, intertemporal choice research has shown that decision-makers undervalue future outcomes …
Authors: Pedro A. Ortega, Naftali Tishby
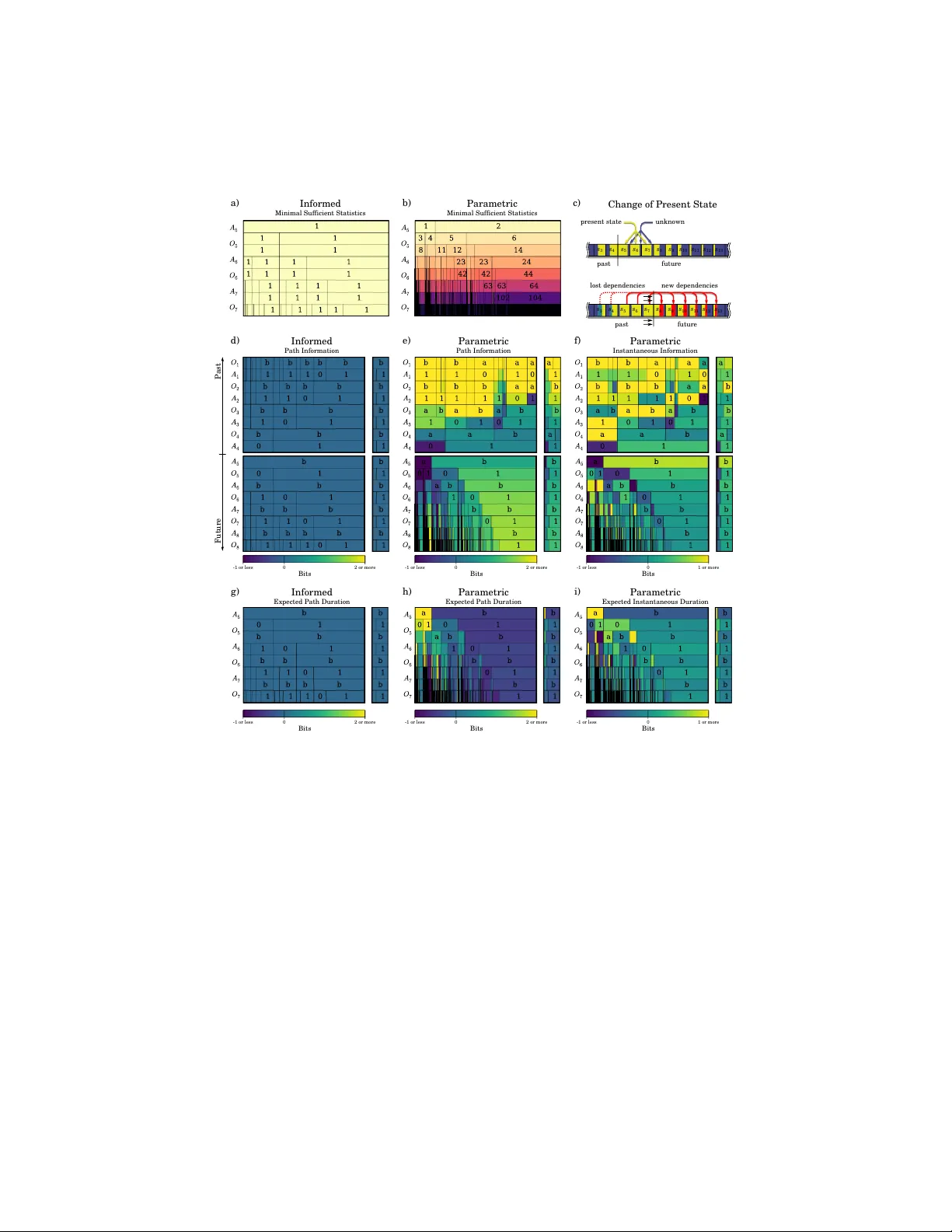
Memory shap es time p erception and in tertemp oral c hoices P edro A. Ortega Naftali Tish b y Univ ersity of Pennsylv ania The Hebrew Universit y in Jerusalem op e@seas.upenn.edu tish by@cs.h uji.ac.il There is a consensus that h uman and non-human sub jects exp erience temp oral distortions in man y stages of their p erceptual and decision- making systems. Similarly , in tertemp oral c hoice research has shown that decision-makers underv alue future outcomes relativ e to immedi- ate ones. Here we com bine techniques from information theory and artificial intelligence to sho w ho w b oth temp oral distortions and in- tertemp oral choice preferences can b e explained as a consequence of the co ding efficiency of sensorimotor represen tation. In particular, the mo del implies that in teractions that constrain future b ehavior are p erceived as b eing b oth longer in duration and more v aluable. F urthermore, using sim ulations of artificial agents, we inv estigate ho w memory constrain ts enforce a renormalization of the perceived timescales. Our results show that qualitatively different discoun t functions, such as exp onen tial and h yp erb olic discoun ting, arise as a consequence of an agent’s probabilistic mo del of the w orld. Keywor ds: Bay esian learning, time p erception, intertemporal c hoice, predictiv e information, free energy . Signific anc e Statement: W e prop ose that p erceiv ed durations can b e quantified in terms of an agen t’s memory changes due to the enco ding of past-future sensorimotor dep endencies. Consisten t with findings in psychoph ysics, we sho w that even ts that are predicted to b e unlikely yet rewarding are p erceived as b eing longer in duration. F urthermore, through the simulation of artificial agen ts, w e sho w that the asymptotic b ehavior of intertemporal preferences can b e explained as a consequence of the mo del class emplo yed by an agent to predict its future. 1 In tro duction Our aim is to propose a mo del of sub jective time based on information theory and to in vestigate its implications relative to tw o phenomena: 1 Time p erception. Wh y does time app ear to slo w down when y ou visit a new place, and sp eed up once y ou get familiar with it? Recen t findings in psychology , neuroscience, and ethology suggest that perceived duration do es not coincide with physical duration, but rather dep end on the statistical prop erties of stim uli. Exp erimen ts in psychoph ysics exp erimen ts ha ve sho wn that, if presented with a train of rep eated stim uli at constant time in terv als (e.g., a letter, word, ob ject, or face), sub jects w ould perceive them as decreasing in duration [70, 44]. On the other hand, the opp osite effect is rep orted whenever the prop erties of a train of stim uli are suddenly changed: brigh ter [10, 66], bigger [41, 73], dynamic [11, 31], or more complex stimuli [54, 49] app ear to last longer. Measurements of brain activit y hav e found that longer durations correlate with increased neuronal firing rates, fMRI, or EEG signals [2, 20, 16, 35, 45, 40]. When combined with ideas from information theory , these observ ations ha ve led to the hypothesis that the sub jective duration of a stim ulus is prop ortional to the amount of neural energy required to represent said stimulus, and that this energy is a signature of the co ding efficiency [21]. In tertemp oral choice. Wh y do $ 100 to da y feel more than $ 100 tomor- ro w? In tertemp oral c hoices lie at the heart of economic decision-making. The economic literature has prop osed early on [52] that rational decision-makers prefer immediate rewards o ver similar rew ards in the future b ecause they dis- c ount time —that is, future moments in time weigh t less in their assessmen t of utilit y . Historically , the first and most commonly used mathematical mo del of temp oral discounting, namely exp onential disc ounting 1 , prop oses that decision- mak ers discoun t future utilities using a single, constant discoun t rate which compresses distinct psyc hological motives [52, 24]. The second most influential t yp e of mo del is hyp erb olic disc ounting , which postulates that discount rates de cline o ver longer time horizons, i.e. future v alues decrease less rapidly than exp onen tial. Structurally , hyperb olic discoun ting do es not p ossess many of the elegan t prop erties of exp onential discounting (such as e.g. dynamical consis- tency); ho wev er, it has significan tly more empirical supp ort [8, 34, 4, 59]. T emporal discounting w as originally conceived as a prop ert y of the decision- mak er’s preferences (e.g. the utility function’s curv ature). Ho w ever, relatively recen t studies hav e in vestigated the role of sub jective time as the underlying cause of in tertemp oral preferences. F or instance, prior work prop osed that h y- p erbolic discoun ting arises due to a sub-additiv e perception of duration [46]; and recen t exp erimen tal findings [65, 74, 8] ha v e suggested that intertemporal c hoice patterns are well captured by treating time as a perceptual modality sub ject to classical psyc hophysical laws (e.g. W eber-F echner law). Similar to prior prop osals [60], the question we address here is: ho w do es an agen t’s memory affect time p erception and intertemporal preferences? Here w e prop ose a model of time p erception in terms of an agen t’s memory requiremen ts to enco de (temporal) sensorimotor dep endencies. This approach does not touc h 1 Also known as ge ometric disc ounting in the artificial intelligence literature. 2 a 1 a 2 a 3 a 4 a 5 a 6 a 7 a 8 o 1 o 2 o 3 o 4 o 5 o 6 o 7 o 8 Experience P o 3 a 3 o 2 a 2 o 1 a 1 Encoding 1000 100 1011 01 0110 110 1001 0101 ... a) b) c) actions observations Figure 1: The interactions b et ween an agen t and its environmen t can b e ana- lyzed using information theory [1]. (b) If we discretize time and the contin uum of sensorimotor even ts, then the in teractions can b e thought of as a sequence of sym b ols b eing written on a tap e, generated b y a sto c hastic process P . The sym b ols a t and o t are the action and the observ ation in turn t respectively , and s t is the corresp onding memory state of the pro cess. (c) As is t ypical in informa- tion theory , w e translate these symbols into binary co dew ords to emphasize the complexit y of generating them sp on taneously using fair coin flips. Sp ecifically , a co dew ord of length l corresponds to a interaction occurring with probability 2 − l (panel c). The adv antage of this view is that it enables a quan titative analysis of the limitations on the pro cess, such as the constrain ts on the dep endencies linking in teractions at different p oin ts in time. up on the cognitive pro cesses that implement the sense of time (such as internal clo ck and attentional c ounter mo dels [27, 39, 17, 38]), nor do es it attempt to pro vide a phenomenological account [63, 72, 15, 18]. Instead, by restricting our atten tion to the purely statistical prop erties of b eha vior, we obtain a mo del of time p erception that is agnostic to the implementation details and the sub- strate. In this abstraction, a range of to ols b ecome a v ailable that enable the quan titative inv estigation of representational limitations. Our main finding is that a system’s memory simultaneously shap es its p erception of time and its in tertemp oral preferences, consisten t with previous exp erimen tal findings. 2 Predictiv e Information and F ree Energy W e consider adaptive agents that in teract with an environmen t, e.g. a mouse c hasing fo od in a lab oratory maze, a v acuum-cleaning rob ot, or a rib osomal complex synth esizing proteins in the citoplasm (see Fig. 1). In artificial in telli- gence, suc h agent-en vironmen t systems are often appro ximated using discrete- time sto c hastic pro cesses in which the agen t and the environmen t take turns to exc hange actions and observ ations drawn from appropriately defined finite sets A and O resp ectively [51]. In eac h time step, the agent acts following a p olicy 3 P ( a | s ) which sp ecifies the probabilit y of generating the action a ∈ A when it is in state s ∈ S . Similarly , the environmen t replies with an observ ation o ∈ O follo wing the sto c hastic dynamics P ( o | s, a ). The agent generates actions so as to bring ab out its goals, such as optimizing a feedbac k signal or maintaining a homeostatic equilibrium. W e cen ter our analysis on the sto c hastic pro cess describing the interaction dynamics as seen from the p erspective of the agent. An adaptiv e agen t has to sim ultaneously solve tw o learning tasks: predicting the environmen t and learn- ing to act optimally . In Bay esian reinforcement learning [19], the standard approac h is to mo del this as an agent that uses past data to learn a parameter θ ∈ Θ that encapsulates b oth the prop erties of the en vironment and its cor- resp onding optimal policy . As the agent gains kno wledge about θ , it improv es its predictions about the environmen t and sim ultaneously its ability to choose b etter actions (see Section 3 for concrete examples). Accordingly , the sto c has- tic pro cess P represents the agent’s b eliefs ab out the interaction dynamics, and the state s ∈ S is given by the agent’s information state or memory state 2 . W e will assume that the state s it is the minimal sufficient statistic, i.e. the min- imal information shared b et ween the past exp erience and the parameter θ , as an y redundan t information contained in the past do es not improv e the agent’s prediction abilities and thus can b e discarded. In order to establish a link b et ween the agent’s memory state, reward func- tion, and temp oral p erception prop erties, we first need to clarify what w e mean b y memory and reward, and how to infer these from the sto c hastic process P . 2.1 Predictiv e Information W e first fo cus on the memory of the sto chastic pro cess. As is customary in in- formation theory , the information conten t of a given finite sequence is assessed in terms of its binary co deword length [14]. The binary length is a standardized pro xy for the complexit y of a sequence, as it c haracterizes both the amount of t wo-state storage units required for remembering it and the difficulty of gen- erating it from fair coin flips [37] (Fig. 1b). Shannon prov ed that the optimal exp ected codeword length is giv en by the en tropy , implying that a minimal co de- w ord has length − log p , w here p is the probability of the sequence [57]. Man y tec hniques exist to construct near-optimal lossless codewords for data streams; a particularly elegan t one is arithmetic c o ding [48, 61]. What is memory? F ollowing Bialek et al. [6], imagine that we hav e measured the first few interactions, and call this past x p . Given x p , we w ant to predict a finite num b er of future interactions x f . Ev en b efore lo oking at the data, w e know that some futures are more likely than others, and this knowledge is summarized by a prior distribution P ( x f ). If in addition we take in to account the 2 Notice that the agent’s memory is not lo calized within its b ody: rather, it is distributed between the bo dy and the surroundings. F or instance, a v acuum-cleaning rob ot with a handful internal states can use the ob jects in its en vironment as an external memory device—op ening the p ossibilit y to T uring-complete behavior. Hence, a comprehensive analysis of the agent’s behavior must be based on the memory of the combined agent-en vironment system. 4 information contained in the past, then w e obtain a more tightly concen trated p osterior distribution o ver futures, P ( x f | x p ). The num b er of bits in the past x p that are used to improv e the prediction of a future x f is quan tified as the difference betw een the prior and p osterior co dew ord lengths: − log P ( x f ) − − log P ( x f | x p ) = log P ( x f | x p ) P ( x f ) . (1) 1 measures the minimal memory that a system must p ossess to enable this prediction 3 . If we av erage o ver all realizations, w e obtain the mutual information b et w een the past and the future: I ( X p ; X f ) = E P log P ( X f | X p ) P ( X p ) . (2) In the literature, this quantit y is known as the pr e dictive information [5, 6]. In tuitively , the predictive information can b e thought of as quan tifying the amoun t of memory that is preserved by the patterns, rules, or correlations that relate the past with the future. An imp ortan t prop erty of the predictive information is that it is subextensive if the sto chastic pro cess is stationary . In other words, the predictive information has a sublinear asymptotic gro wth in the length of a realization. This is in stark contrast to the entrop y of the pro cess, whic h gro ws linearly with the length of a realization. Consequen tly , only a v anishing fraction of the dynamics of the pro cess is go verned by patterns; most of it is driven b y pure noise. 2.2 F ree Energy Our second step is to establish a firm link b et w een the statistics of stochastic pro cesses and their implicit rew ards. T he evolution of the sto c hastic process can b e analyzed using decision-theoretic to ols b y adopting a complementary view to the previous one. In this interpretation, conditioning amounts to imp osing con- strain ts on an otherwise free ev olution of the stochastic process. The assumption is that, if uncon trolled, the future interactions x f w ould follo w the sto c hastic dynamics describ ed by the prior distribution P ( x f ). Ho wev er, when the agent exp eriences the past interactions x p , it acquires knowledge that leads it to steer the pro cess in to a more desir e d direction, resulting in the dynamics giv en by the p osterior distribution P ( x f | x p ) [69]. This transformation can b e character- ized as the result of maximizing expected rew ards sub ject to constrain ts on the memory capacity of the pro cess [68, 42]. The asso ciated ob jective function is the free energy functional 3 This difference can be negative. In this case, it can b e interpreted as the amount of information contained in the past x p that is inconsistent with the future x f . 5 F ( x p )[ ˜ P ] : = X x f ˜ P ( x f | x p ) h R ( x f | x p ) + F ( x p , x f ) i (Exp ected Rewards) − 1 β X x f ˜ P ( x f | x p ) log ˜ P ( x f | x p ) P ( x f ) (KL-Div ergence) (3) whic h is to b e maximized w.r.t. to the distribution ˜ P o ver futures x f conditioned on the past x p . In the first exp ectation, R ( x f | x p ) is the r e al r ewar d 4 of the future sequence x f conditioned on the past x p and F ( x p , x f ) is the terminal rew ard of the sequence x p x f . The second term is a p enalization that measures the memory cost of changing the probability of x f . The parameter β > 0 is the inverse temp er atur e, and it encapsulates the trade-off b et ween rewards and information costs: larger v alues corresp ond to cheaper memory costs and therefore more con trol. The posterior distribution o ver the future is then defined as the maximizer of (3) giv en by the Gibbs distribution P ( x f | x p ) := 1 Z P ( x f ) exp n β [ R ( x f | x p ) + F ( x p , x f )] o (4) where Z is a normalizing constant. Since (3) and (4) must hold for any past-future windo w, tw o consequences follo w. The first is that the free energy functional has a recursiv e structure given b y the equality b et ween optimal free energies 5 and terminal rew ards: F ( x p ) = max ˜ P F ( x p )[ ˜ P ] . (5) In particular, the terminal rewards F ( x p , x f ) that app ear in equation (3) are themselv es the result of optimizing free energy functionals ov er the distant fu- tures that occur after x p x f . If we av erage o ver the pasts, we get E F ( X p ) = E R ( X f | X p ) + F ( X p , X f ) − 1 β I ( X p ; X f ) , (6) whic h reveals that the KL-p enalization term is a constrain t on the predictive information, imp osing a limit on the memory of the sto chastic pro cess during the maximization of the exp ected rewards. The second consequence is that rew ards and log-likelihoo ds are related via an affine transformation log P ( x p | x f ) = β h R ( x f | x p ) + F ( x p , x f ) i + C , (7) where C is a constant. Intuitiv ely , this means that “the future x f has more rew ard giv en the past x p ” and “the future x f is more likely given the past x p ” 4 W e assume that rewards are additive: R ( v , w | u ) = R ( v | u ) + R ( w | u, v ). 5 F rom an economic point of view, the optimal free energy (5) turns out to be the c ertainty- e quivalent value of knowing x p ; in other words, it is the net worth the agent attributes to the future when it has exp erienced the past x p . 6 are t wo equiv alent statements 6 . In addition, (7) provides a simple formula for estimating the rew ards from the realizations of a giv en sto c hastic pro cess. 3 Results W e hav e conducted simulations of agent-en vironmen t systems to achiev e tw o goals: first, to measure the agen ts’ sub jective time frame (made precise later in this section); and second, to calculate their implicit discoun t functions. The sim ulation results (samples from the sto chastic pro cesses) provided us with the necessary data to subsequently estimate (using the to ols reviewed in the previous section) the implicit memory constraints and rewards contained in the agent- en vironment interactions. F or simplicit y , our sim ulations are based on the standard framework of m ulti- armed bandit problems [33]. In these problems, an agen t gam bles a slot-mac hine with multiple arms. When play ed, an arm provides the agen t with a Bernoulli- distributed nominal reward, where the bias is initially unknown to the agent. The ob jective of the game is to play a sequence of arms in order to maximize the sum of rew ards. Although simple, bandit problems p ose many of the core c hallenges of sequen tial decision-making. F or instance, an agen t has to balance greedy choices versus c hoices intended to acquire new knowledge—a trade-off kno wn as the exploration-exploitation dilemma [64]. Throughout all our sim ulations we used tw o-armed bandits with arms la- b eled as “a” and “b” (Fig. 2e). T o in vestigate how the learning ability impacts time p erception, we sim ulated agents with probabilistic mo dels of increasing complexit y (Materials & Metho ds). T o do so, w e used four different types of parameter spaces Θ: a singleton set Θ, representing an informed agent that already knows the dynamics of the environmen t and the optimal p olicy; a finite set Θ; a finite-dimensional parameter space Θ giving rise to a parametric prob- abilistic mo del; and an infinite-dimensional parameter space Θ. W e call these agen ts informe d , finite , p ar ametric , and nonp ar ametric [26] resp ectiv ely . Note that only the last three are adaptiv e. F urthermore, the agents use a probability matc hing strategy kno wn as Thompson sampling to pic k their actions. Accord- ingly , in each turn the agent samples one bias for each arm from the p osterior distribution o ver Θ and then plays the arm with the largest bias [67]. Fig. 2 compares the predictions made by the four probabilistic mo dels. The nominal rew ards issued by the bandits should not b e confused with the real rewards defined in the previous section. Although nominal rew ards feature in the description of the problem setup of multi-armed bandits, finding a p olicy that maximizes rewards is in general intractable. Therefore, the resulting p olicies will not b e optimal with resp ect to those nominal rewards. Ho wev er, 6 Similar points regarding the equiv alence betw een rewards and likelihoo ds were made pre- viously , see e.g. [25, 55]. It is also worth clarifying that w e treat rew ards as internal, subje ctive quantities. This is consistent with exp ected utility theory [71, 53], but unlike the more re- cent interpretation in reinforcement learning where rewards are treated as externally supplied, ob jective quan tities. 7 1 0 b a 1 a) 1 0 b a 1 2 0 b a 1 3 Informed Finite Parametric Nonparametric Bandit Sequ ence Two-Armed Ban dit b) c) d) e) f) Figure 2: Predicted futures for agen ts with increasing mo del complexit y . Agen ts pla y a tw o-armed bandit with Bernoulli-distributed rewards. (a–d) show their predictions for the next three in teractions after having exp erienced four initial in teractions x p = (a1,a0,b1,b1), i.e. where the agen t switc hed to action “b” after observing a loss in the second trial of arm “a”. The diagrams show the predicted probabilit y (cell width) of eac h path of interactions, and sidebars con tain the marginal probabilities. In spite of pla ying the same bandit depicted in (e), their predictions v ary due to their probabilistic mo dels, ranging from an informed (a) to a nonparametric mo del (d). The informed agen t kno ws the Bernoulli biases of eac h arm and therefore alwa ys mak es p erfect predictions and pla ys optimal actions. The finite and parametric agents learn the transition probabilities of a single t wo-armed bandit (e), whereas the nonparametric agent attempts to fit a more complex model that is based on a sequence of bandits (f ). w e can use the free energy functional to infer the real rewards optimized by the sto c hastic pro cess defined b y the in teractions b et ween the constructed agents and the bandits. 3.1 Presen t Scop e and Perceiv ed Durations W e measure the passage of time using clo c ks, e.g. hourglasses, wrist watc hes, planetary mov emen ts and atomic clo c ks, all of whic h register c hanges in the ph ysical state of the w orld [47]. Analogously , an agent tracks the passage of time through the c hanges in its memory state triggered by the interactions. Main taining a memory state induces temp oral correlations betw een the past and the future that are a signature of the underlying adaptive mec hanisms [5, 56, 62]. Con versely , the lack of temp oral correlations is indicative of the absence of memory . A t an y giv en p oin t during the realization of the stochastic pro cess, it is natu- ral to define the “present” as the minimal information contained in the memory 8 state that can b e confirmed empirically , i.e. the minimal sufficien t statistic of the past (Fig. 3a,b). Imagine that the agent exp eriences the past x p and enters state s . In this state, the amount of information the agent p ossesses ab out any particular future x f is equal to Presen t( x f ) = log P ( x f | x p ) P ( x f ) = log P ( x f | s ) P ( x f ) (8) bits. Similarly , only log P ( x p | s ) /P ( x p ) bits ab out the past are remembered. Both of these quantities are upp er b ounded by − log P ( x p ), the total infor- mation contained in the past. The scop e of the agent’s presen t is the part of the past/future that is remembered/predicted by the agent’s memory state (Fig. 3d–f ). In the sp ecial case of the informed agent, the present state has zero span (Fig. 3d) b ecause it does not need to maintain an y memory in order to b eha ve optimally . In contrast, the parametric agent possesse s an extensive scop e (Fig. 3e,f ) that grows with more exp erience. In particular, the agen t can only remember its past up to a p erm utation of the interactions b ecause the distribution ov er observ ations is exchangeable. F urthermore, it predicts futures that are consisten t with the past exp erience; for instance, in the illustrated case the agent’s most likely future rep eatedly pulls arm “b” and observes “1” in ac- cordance with the past x p = (a1,a0,b1,b1). Deviations from the past, such as those caused by o ddballs, contradict the memory state (i.e. they share a nega- tiv e n umber of bits). Note that the p ossession of a presen t scope is a prop ert y shared b y all adaptive agents. Giv en this definition of the present scop e, we prop ose to mo del the passage of time relative to the sto c hastic pro cess as the num b er of bits in the memory that c hange during the exp erience of an in teraction (Fig. 3c). This definition rests up on the assumption that the sto c hastic pro cess is implemen ted on a compu- tation mo del ha ving fixed bandwidth p er operation—such as a (probabilistic) T uring machine, which can only mo dify a limited num b er of bits p er cycle 7 [58, 43]. W e argue that this provides a more plausible time metric than the time index or ev en the entrop y of the sto c hastic pro cess, for using the index of the stochastic pro cess would yield a non-homogeneous complexity per time unit 8 . F ormally , giv en a finite past x p and future x n x f , consider a transition that increases the past from x p to x p x n and reduces the future from x n x f to x f as depicted in Fig. 3c. The p erceiv ed duration of x n relativ e to this limited windo w is equal to the difference Duration( x n ) = log P ( x f | x n , x p ) P ( x f ) − log P ( x f , x n | x p ) P ( x f , x n ) = log P ( x n | x f ) P ( x n | x p ) . (9) 7 In the case of a probabilistic T uring machine, the only bits that can change within a cycle are those needed to represen t the state of the T uring machine, the mov emen t the header, and the conten t the current cell in the tape. 8 Since an individual interaction can b e arbitrarily complex, forcing it to b e computed in one time unit would require a machine that can operate at an un b ounded sp eed. 9 Future Past Informed Parametric Parametric -1 or less 2 or more Bits 0 -1 or less 2 or more Bits 0 -1 or less 1 or more Bits 0 Path Information Path Information Instantaneous Information d) f) e) Informed Parametric Minimal Sufficient Statistics Minimal Sufficient Statistics a) b) Parametric Parametric Expected Path Duration Expected Instantaneous Duration i) h) s 8 s 9 s 6 s 5 s 10 s 4 s 7 s 11 s 12 s 13 s 3 past future unknown present state past future new dependencies lost dependencies s 8 s 9 s 6 s 5 s 10 s 4 s 7 s 11 s 12 s 13 s 3 Change of Present State c) Informed Expected Path Duration g) -1 or less 2 or more Bits 0 -1 or less 2 or more Bits 0 -1 or less 1 or more Bits 0 Figure 3: (a,b) Comparison of the minimal sufficient statistic (i.e. the memory state) of t wo probabilistic mo dels. In the diagrams, the states are sequentially n umbered and color-co ded to highlight rep etitions. The probabilistic mo del of the informed agen t has only a single memory state, whereas the parametric class p ossesses man y . (c) The duration of a sequence of interactions is defined b y taking the difference in information b et ween t wo different memory states. The exp erience of new interactions causes the agen t to acquire new predictive information about the future while forgetting details ab out the past. (d–f ) Illus- tration of the agent’s presen t scope measured in terms of the information shared b et w een the memory state and the past/future paths. In (d) & (e), the cell color enco des the cumulativ e information for the path starting from the past-future divide and then leading up to the cell. Diagram (f ) is obtained from (e) by taking the difference b etw een t wo consecutiv e paths. (g,h) Exp ected duration of in teraction paths. The cell color encodes the total duration of the path tak en. (i) Exp ected duration of individual interactions, obtained as the difference b e- t ween the duration of tw o consecutiv e paths. In all diagrams, we conditioned the models on the past x p = (a1,a0,b1,b1) as in Fig. 2. 10 These durations are illustrated in Fig. 3g–i. The informed agent op erates in the equilibrium regime and thus do es not exp erience time (Fig. 3g). In contrast, the parametric agent p erceiv es durations that v ary with the current kno wledge. F or instance, Fig. 3h–i show that predictable interactions decrease in duration (e.g. “b1,b1,b1”), whereas a mistake (e.g. accidentally playing “a” instead of “b”) and some of rew ards result in longer durations. Oddballs, such as the deviations from “b1,b1,b1”, do not necessarily entail longer durations. 3.2 T emp oral Discounting When an agent has a limited capacity to predict the future, it can only exploit a fraction of the rewards that lie ahead. The precise amount can b e inferred b y insp ecting how muc h they affect the b eha vior of the sto c hastic pro cess. If the probabilit y P ( x f | x p ) of c ho osing a future x f giv en a past x p is the result of optimizing the free energy functional (3), then the change in log-probabilit y can b e written as (Materials & Metho ds) log P ( x f | x p ) P ( x f ) = β R ( x f | x p ) + F ( x p , x f ) − F ( x p ) . (10) Using (8), we iden tify the l.h.s. with the information ab out the future x f pre- dicted by the present. The r.h.s. is prop ortional to the difference b et ween tw o terms: R ( x f | x p ) + F ( x p , x f ), the cumulativ e and terminal rew ards of x f ; and F ( x p ), the certaint y-equiv alen t v alue of all the p otential futures. This result states that the change of a choice’s probability dep ends exclusively on how m uch it improv es upon the summarized v alue of the c hoice set. In accordance to decision theory , we refer to this excess as the r ejoic e (i.e. negative regret, see Materials & Metho ds) [7]. The rejoice scales prop ortionally with the agent’s memory and is therefore determined by the learning mo del. In the economic literature, an agent that reacts only to a fraction of the rew ard is explained through a discoun t function. T ypically , a discoun t function giv es smaller weigh ts to rew ards that lie farther in the future [24]. F ollowing the same rationale, we next sho w ho w to derive discount functions that re-weigh t the rew ards in order to equate them with the rejoices. W e conducted Mon te-Carlo simulations of the four agents to study the evo- lution of their predictive p erformance (Materials & Metho ds). T o isolate the effects of the adaptive policy from the effects of learning the environmen t, we also ran each agen t a second time but using a (non-adaptive) uniform random p olicy . All estimates w ere obtained from av eraging simulated tra jectories of ev en length that w ere split in the middle to get a past x p and a future x f . The results are shown in Fig. 4. The first panel (Fig. 4a) sho ws that the conditional en tropies of the past given the future H ( X p | X f ), which were obtained b y av- eraging ov er the negativ e log-lik eliho o ds − log P ( x p | x f ), grow linearly with the size of the window. As discussed in Sec. 2.2, log-likelihoo ds are affine transfor- mations of the real rew ards. In contrast, the mutual information betw een the past and the future grows sublinearly , and the growth rate increases with mo del 11 a) b) c) d) e) f) Figure 4: Monte-Carlo a verages of agent-en vironmen t systems. The color-co des are the same throughout the plots. Agen ts used either a random policy (solid curv es) or Thompson sampling (dashed c urv es). (a) Conditional entrop y of the past given the future H ( X p | X f ). This curve represen ts the a verage ov er the negativ e, real rewards of equation (7). (b,c) Mutual information b et ween the past and future. The log-scale in (c) was chosen so as to emphasize the logarithmic growth of the parametric case. (d) Exp ected nominal rewards of the future as a function of the length of the past-future windo w. (e) Av eraged nominal rewards as a function of the mutual information, where the latter is in terpreted as a measure of perceived duration. The plot shows the empirical data together with the fitted curves for agents using a uniformly random p olicy . (f ) Discoun t functions derived from the curves in (e). They provide low er b ounds for the discoun t functions used by the agents using an adaptiv e p olicy . 12 T able 1: Least-Square Fits of PR and MI. Mo del f ( z ) a b MSE NR, Finite bz — 0.5013 0.3421 NR, P arametric bz — 0.5001 0.5309 NR, Nonparametric bz — 0.4721 0.0893 MI, Finite a (1 − exp( − bz )) 2.0107 0.0567 0.0018 MI, P arametric a log (1 + bz ) 1.5283 0.0884 0.0036 MI, Nonparametric az b 0.3291 0.6327 0.0779 complexit y (Fig. 4b–c). The mutual information curves for non-adaptiv e p oli- cies provide a low er b ound for their adaptiv e coun terparts. How ev er, adaptive p olicies conv erge to the optimal p olicies in the limit, and so we exp ect their m utual information curv es to con verge to the low er b ound. The simulations confirm this in the finite and parametric agen ts. Fig. 4c also shows that the parametric mo del has a logarithmic growth in mutual information. In compar- ison, the nonparametric mo del is seen to be supe r-logarithmic and the finite mo del upper-b ounded. Finally , we ha ve also insp ected the sum of the nominal rew ards con tained in the futures. Fig. 4d shows that all the agen ts predict nomi- nal rew ards that gro w prop ortionally with the length of the past-future window. The slop es of these curv es v ary , and agen ts with adaptive policies predict b etter rew ards. W e computed linear fits of the nominal rew ard curves (NR) of Fig. 4d and nonlinear fits for the mutual information (MI) curves of Fig. 4b for the agents with uniform p olicies, which will serv e as lo wer b ounds for the ones based on adaptiv e p olicies. Sp ecifically , the nonlinear models ha ve the follo wing asymp- totic b eha vior in the length z of the interv al of past interactions: exp onential deca y O ( e − bz ) for the finite agen t; logarithmic growth O (log bz ) for the paramet- ric agent; and p o wer-la w growth O ( z b ), 0 < b < 1, for the nonparametric agent. The last tw o hav e b een justified analytically in previous work: Bialek et al. [5] hav e sho wn that the predictiv e information of mo dels based on finite- and infinite-dimensional parameter vectors has logarithmic and p o wer-la w growth re- sp ectiv ely . Notice that since nominal and real rew ards are b oth asymptotically linear, choosing one or the other for our fits would lead to the same asymptotic conclusions. The results of this fit are listed T able 1. Combining these fits, w e calculated the predicted rewards relativ e to the agent’s perceived duration (Fig. 4e). The plots show that agen ts predict a superlinear gro wth relative to their perceived duration. Given that the rejoice is prop ortional to the dura- tion, agents m ust assign decaying w eights to the predicted rew ards, and these w eights are given b y the discount functions listed in T able 2, sho wn in Fig. 4f (Materials & Metho ds). The discoun t functions can b e classified according to their asymptotic decay , resulting in: infinite, linear, exp onen tial, and hyper- b olic discoun ting for the informed, finite, parametric, and nonparametric agen t resp ectiv ely . These functions provide lo wer b ounds for the discoun t functions 13 T able 2: Discount F unctions δ ( τ ) Gro wth T yp e Informed 0 0 Infinite Finite max(0 , 0 . 2274 − 0 . 1131 τ ) O (1) Linear P arametric 0 . 2701 e − 0 . 6543 τ O ( e − cτ ) Exp onen tial Nonparametric 0 . 2314 τ − 0 . 5805 O ( τ − c ) Hyp erbolic of the agen ts using an adaptive p olicy . 4 Discussion Our theoretical mo del relates the change of an agen t’s memory state to the p erceiv ed duration of interactions and to the rejoice. Concisely stated, this relationship is giv en by ∆Memory = Duration = ∆Rejoice. (11) Sp ecifically , we hav e tak en the memory to b e synon ymous with the minimal suf- ficien t statistics (i.e. encoding all past-future dep endencies and only those) of the agent’s probabilistic mo del. As suggested b y the agent-en vironmen t setup, w e exp ect the memory substrate in animals to encompass every mo dulator of b eha vior, ranging from the synaptic weigh ts in the brain to the immediate sur- roundings. F urthermore, an increase of the information-pro cessing capacit y p er in teraction can be related to ph ysiological factors suc h a decrease in b ody size or an increase in metab olic rate [28]. Our agent-en vironmen t simulations illustrate that while complex reactiv e b ehavior can emerge from limited to no memory (as in the informed agent), adaptiv e b eha vior dep ends on the a v ailability of sufficien t memory resources. Consisten t with previous findings in the field of time p erception [21], the mo del links the shortening durations of repeated stimuli to their increased pre- dictabilit y . More sp ecifically how ev er, it distinguishes b et ween three cases. In- teractions that are (a) well-predicted or (b) nov el but irrelev ant for future be - ha vior imply fewer c hanges to the agent’s memory when exp erienced. Therefore, their p erceiv ed duration is shorter. In contrast, (c) o ddballs that are r elevant for future b eha vior (i.e. eliciting larger rejoice) induce adaptation and are th us p erceiv ed as b eing longer in duration. This connection b et ween the p ercep- tion of time and rewards is supp orted by empirical findings in the literature on atten tion [12]. F or instance, in a recent study where participan ts p erformed a prosp ectiv e timing task, it w as found that only o ddballs signaling relativ ely high reward compared to the standards were p erceiv ed to last longer, whereas o ddballs with no or little rew ard remained unaffected [22]. 14 Within this con text, it is instructiv e to examine t wo limit cases. Consider an agen t with a clo c k that tic ks once p er interaction. If the agent has little to no memory (like the informed agent in our exp erimen ts), then the temp oral resolution v anishes and the clock spins infinitely fast from the agent’s point of view. In con trast, if the agent p ossesses no capacity constraints, as is assumed in the perfect rationalit y paradigm [50], then the clo c k slows do wn to a p oint where it app ears frozen. In this sense, memory capacity acts a form of temp oral inertia that quan tifies the amount of information required to mov e the agent one clock tic k in time. The memory constraints limit the agen t’s ability to react to distan t rewards, giving rise to the phenomenon of temp oral discounting. The simulation results ha ve sho wn how model complexity qualitativ ely affects the asymptotic b eha vior of discount rates; in particular, exp onen tial and hyperb olic discoun ting w ere sho wn to arise from parametric and nonparametric mo del classes resp ectiv ely . Giv en that humans hav e b een shown to display h yp erb olic discounting [34], our results suggest that human in tertemp oral v alue judgmen t ma y arise from a memory formation rate comparable to that of nonparametric mo dels. The model of time p erception can also account for some effects of general memory manipulation. F or instance, an increase of memory plasticit y will cor- relate p ositively with p erceiv ed durations. This phenomenon is consistent with exp erimen tal findings, e.g. in which the administration of dopamine has led to the ov erestimation of durations and the atten uation of impulsivity (steep dis- coun ting) [32, 30]. Finally , is worth remarking that the relation betw een memory changes, du- ration and rejoice that we hav e laid out here is not sp ecific to said v ariables, but rather a general prop erty of quantities that are extensive/additiv e in the in teractions. In other words, the limitations imp osed by the memory gro wth rate app ear to b e a general prop ert y of p erception. V erifying this property for other p erceptual modalities (other than time and reward) is a task to b e further explored in the future. Materials and Metho ds Multi-Armed Bandit Pro cesses. W e considered simple agents and en vi- ronmen ts where the set of actions and observ ations w ere chosen as A = { a , b } and O = { 0 , 1 } resp ectiv ely . F or the actions, the symbols “a” and “b” encode the left and the right arm resp ectiv ely; for the observ ations, 0 and 1 corresp ond to a nominal loss and reward resp onses. The environmen t is a t wo-armed bandit c haracterized b y a bias vector θ = [ θ a , θ b ] T , where θ a ∈ [0 , 1] for a ∈ { a, b } . When the agent pulls arm a , the bandit replies with a rew ard drawn from a Bernoulli distribution with bias θ a . When the biases are known, as is the case in the informe d agent, then the optimal strategy consists in alwa ys playing the arm with the highest bias, a ∗ = arg max a { θ a } . In our simulations of the in- formed agent, we c hose a bias vector equal to θ = [ 1 4 , 3 4 ] . Hence, the optimal strategy w as to pick a = b in every turn. 15 When the biases are unkno wn, the agent’s uncertain t y is mo deled b y placing a prior distribution o ver the bias vector [19, 29]. In the case of the finite agen t, the hypothesis class is given by the set of four bias vectors Θ = { 1 4 , 3 4 } × { 1 4 , 3 4 } , and it places the prior pmf f ( z ; α, β ) := z α − 1 (1 − z ) β − 1 P ξ = 1 4 , 3 4 ξ α − 1 (1 − ξ ) β − 1 o ver each arm’s bias. The terms α > 0 and β > 0 are hyperparameters that keep trac k of the total num b er of times that the bandit responded with rew ards and a losses respectively [9, 13]. The resulting prior pmf is a pro duct distribution P ( θ ) = f ( θ a ; α a , β a ) f ( θ b ; α b , β b ) . The p ar ametric agent enriches the finite case by extending the h yp othesis class to all the bias vectors in the unit square Θ = [0 , 1] × [0 , 1], placing an indep enden t Beta pdf B ( z ; α, β ) := z α − 1 (1 − z ) β − 1 ´ 1 0 ξ α − 1 (1 − ξ ) β − 1 dξ o ver each v ector component. Because b oth agen ts hav e priors that are conjugate to the Bernoulli distribution, their posteriors are obtained by just up dating the four hyperparameters α a , β a , α a , and β b . F or example, if the agent plays arm “a” and the environmen t replies with a reward, then the h yp erparameter α a is incremen ted in one count and the others are k ept equal. The nonp ar ametric agent is based on a more flexible model. Rather than as- suming a single bandit, the model considers a sequence of tw o-armed bandits la- b eled as N = 1 , 2 , 3 , . . . , each one ha ving its own v ector of biases [ θ a ( N ) , θ b ( N )]. Starting at bandit N = 1, the agen t mov es to the next bandit N → N + 1 whenev er it receives a reward, and returns to the first bandit ( N = 1) when it receives a loss. In eac h interaction, only the hyperparameters of the curren t bandit are up dated. The resulting hypothesis class is giv en b y the set Θ of all maps θ : N → [0 , 1] × [0 , 1]. T o generate actions, all the agents employ either a uniform strategy or Thompson sampling [67]. In the latter case, an agent generates Monte-Carlo samples of the biases of the current bandit from its p osterior distribution. Sub- sequen tly , it plays the arm asso ciated to the largest bias. A t the b eginning of each sim ulation, all the hyperparameters of an agen t’s probabilistic mo del where initialized to one, i.e. α = 1, β = 1 for the finite and parametric agen ts, and α ( N ) = 1, β ( N ) = 1 for all N ∈ N in the case of the nonparametric agent. This corresp onds to a uniform distribution ov er ev ery bias. F urthermore, the true (unknown) biases were sampled uniformly in accordance to the agents’ priors. Sufficien t Statistics. The sufficient statistics for the four agents follow di- rectly from their probabilistic mo dels. The informed agent’s stochastic pro cess is memoryless; therefore, its sufficient statistic can b e modeled as a constant 16 function of the past. The predictions made b y the finite, parametric, and non- parametric agents depend up on the total counts of rewards and losses (i.e. the h yp erparameters) observ ed so far, the n umber N of the bandit, and the action issued during the current in teraction if av ailable. Rejoice. The main difference b et w een exp ected utility theory [71, 53] and regret theory [23, 3, 36] is that in the former decision-makers maximize the exp ected utility , whereas in the latter decision-makers minimize r e gr et , i.e. they c ho ose an action a that minimizes a function Q{ U ( a ) , U ( a ref ) } , where a ref is a reference action and U is a utility function. The regret function quan tifies how m uch the utility U ( a ) of a is affected b y what would hav e happ ened had a ref b een chosen instead of a [7]. Arguably , the simplest regret function is given by the difference Q{ U ( a ) , U ( a ref ) } = U ( a ref ) − U ( a ). Decision-making based on the free energy functional can b e related to regret theory . The solution to the av erage free energy functional is giv en by Gibbs distribution P ( x f | x p ) = 1 Z P ( x f ) exp β h R ( x f | x p ) + F ( x p , x f ) i , (12) where the normalizing constan t Z is the partition function. It is well-kno wn that the optimal free energy is equal to F ( x p ) := max ˜ P F ( x p )[ ˜ P ] = 1 β log Z. In the economic literature, this quan tity is known as the certaint y-equiv alent, and it is a function of the set of future rewards { R ( y f | x p ) + F ( x p , y f ) } y f that measures the agent’s sub jectiv e w orth of the cumulativ e rewards that lie in the future. The v alue is b ounded as E R ( X f | X p ) + F ( X p , X f ) x p ≤ F ( x p ) ≤ max x f R ( x f | x p ) + F ( x p , x f ) , where the low er and upp er b ounds are attained when β → 0 and β → ∞ resp ectiv ely . Rearranging (12) as log P ( x f | x p ) P ( x f ) = β h R ( x f | x p ) + F ( x p , x f ) − F ( x f ) i , rev eals that the changes in c hoice probabilities are gov erned by a rejoice (neg- ativ e regret) function that con trasts the rew ards of future realizations against the certain ty-equiv alent: log P ( x f | x p ) P ( x f ) = − β Q n R ( x f | x p ) + F ( x p , x f ) , F ( x f ) o . 17 Mon te-Carlo Sim ulations. The curv es for the conditional entrop y (Fig. 4a), the m utual information (Fig. 4b & c), and the predicted rewards (Fig. 4d) w ere obtained from Monte-Carlo av erages made at equally spaced lo cations ( t = 1 , 11 , 21 , . . . , 201). T o calculate an estimate at lo cation t , we av eraged the log-probabilities and rewards of in teraction sequences of length 2 t generated from the agent’s sto c hastic pro cess describ ed in the previous section. Given the n -th simulated interaction sequence, let x ( n ) p and x ( n ) f b e its first and second half resp ectiv ely . F urthermore, let R nom ( x ( n ) f | x ( n ) p ) denote the nominal rewards o ver the second half, calculated as the sum of the observ ations in x ( n ) f . The en tropies H ( X p , X p ), H ( X f | X p ), H ( X f ), and the exp ected nominal rewards E R nom ( X f | X p ) w ere estimated as H ( X p , X f ) ≈ − 1 N N X n =1 log P ( x ( n ) p , x ( n ) f ) , (13) H ( X f | X p ) ≈ − 1 N N X n =1 log P ( x ( n ) p , x ( n ) f ) P ( x ( n ) p ) , (14) H ( X f ) ≈ − 1 N N X n =1 log 1 M M X m =1 P ( x ( m ) p , x ( n ) f ) P ( x ( m ) p ) , (15) E R nom ( X f | X p ) ≈ 1 N N X n =1 R nom ( x f | x p ) ( n ) . (16) W e used the difference betw een (15) and (13) as an estimate for the mutual information I ( X p ; X f ) = H ( X f ) − H ( X f | X p ). In particular, note that the es- timate of the marginal entrop y H ( X f ) was obtained using a doubly-sto c hastic Mon te-Carlo av erage ov er N M samples in whic h the second half was k ept fixed during blo c ks of size M . The conditional entrop y of the past given the fu- ture, which stands for a pro xy of the real rewards, was estimated using the form ula H ( X p | X f ) = H ( X p , X f ) − H ( X f ). The num ber of samples were chosen as N = 1000 and M = 3000. In the cases of the parametric and nonparametric agen ts, w e made additional appro ximations to the Thompson sampling strategy . Sp ecifically , we used the normal appro ximation to the Beta distribution: B ( z ; α, β ) ≈ N z ; µ = α α + β , σ 2 = αβ ( α + β ) 2 (1 + α + β ) . The approximation holds well for large v alues of α and β , and it has the adv an- tage of keeping b oth the generation and ev aluation of action samples computa- tionally tractable. The probabilit y of c ho osing arm “a” then b ecomes equal to 1 − F ( c ) , where F is the cdf of the normal distribution with zero mean and unit v ariance, and c = 1 2 ( µ a − µ b ) q σ − 2 a + σ − 2 b . 18 T emporal discounting. The discount functions were deriv ed using the fol- lo wing pro cedure. The choice of the functional forms of the mo del classes listed in T able 1 were motiv ated b y prior studies of the long-term b eha vior of the en- trop y and the predictiv e information [5]. The exception is the functional form of the finite mo del’s mutual information, which w as chosen through insp ection of the curve. The parameters were fit (least-square regression) to the data obtained in the Monte-Carlo simulations. This yielded tw o functions p er agen t: the ex- p ected nominal reward function R ( z ) and the mutual information I ( z ), both as a function of the num b er of interactions z ∈ (0 , ∞ ) of the past and the future windo w. F or analytical con venience, w e extended the num b er of in teractions form the discrete to the contin uous domain. The tw o functions R ( z ) and I ( z ) w ere then connected via z . Fig. 4e is obtained b y plotting R ( τ ) := R ( I − 1 ( τ )), where the inv erse I − 1 ( τ ) is the num b er of in teractions as a function of the mu- tual information τ ∈ (0 , ∞ ), no w interpreted as a temp oral co ordinate. These in verses were equal to: z = 1 b log( a a − τ ) for the finite mo del; z = 1 b ( e τ /a − 1) for the parametric mo del; and z = ( τ a ) 1 /b for the nonparametric mo del. The resp ectiv e nominal reward functions R ( τ ) are just rescaled v ersions of I − 1 ( τ ). T o obtain the discount functions, we m ust make sure that the discoun ted future gro ws prop ortionally in τ , that is ˆ t = τ t =0 δ ( t ) ∂ R ∂ t ( t ) dt = ατ , b ecause the rejoice ατ is prop ortional to the mutual information. Assuming w.l.g. that α = 1, this is achiev ed when δ ( t ) = ∂ R ∂ t − 1 ( t ) . Th us, the resulting discount functions ha ve the shap es: δ ( τ ) = d − cτ for the finite case; δ ( τ ) = de − cτ , for the parametric case; and δ ( τ ) = dτ − c for the nonparametric case. Note that the constan ts c and d are p ositiv e in eac h case. Comp eting In terests The authors declare that the research was conducted in the absence of any commercial or financial relationships that could b e construed as a p oten tial conflict of in terest. Ac kno wledgements P .A. Ortega would like to thank D. Balduzzi, D.A. Braun, J.R. Donoso, K.- E. Kim and D. Polani for helpful commen ts and suggestions. This study was funded by the Israeli Science F oundation center of excellence, the D ARP A MSEE pro ject and the Intel Collab orativ e Researc h Institute for Computational Intel- ligence (ICRI-CI). 19 References [1] W.R. Ashb y . An intr o duction to cybernetics . Chapman and Hall Ltd., 1956. [2] R. B. Barlow, D. M. Sno dderly , and H. A. Swadlo w. Intensit y co ding in primate visual system. Exp erimental Br ain R ese ar ch , 31(2):163–77, 1978. [3] D.E. Bell. Regret in decision making under uncertaint y. Op erations R ese ar ch , 33:961– 981, 1982. [4] G.S. Berns, D. Laibson, and G. Loewenstein. In tertemp oral c hoice–tow ard an integrativ e framework. T r ends in Co gnitive Scienc e (R e gul. Ed.) , 11(11):482–8, 2007. [5] W. Bialek, I. Nemenman, and N. Tishb y . Predictability , Complexit y , and Learning. Neur al Computation , 13:2409–2463, 2001. [6] W. Bialek, I. Nemenman, and N. Tishb y . Complexity through nonextensivity. Physica A: Statistic al Me chanics and its Applications , 302(1-4):89–99, December 2001. [7] H. Bleichrodt and P . P . W akker. Regret theory: A b old alternative to the alternatives. The Ec onomic Journal , 125(583):493–532, 2015. [8] W.D. Bradford, P . Dolan, and M.M. Galizzi. Lo oking Ahead: Sub jective Time P erception and Individual Time Discoun ting. T ec hnical Rep ort CEP Discussion P apers 1255, Centre for Economic Performance, LSE, 2014. [9] D.A. Braun and P .A. Ortega. A minimum relative entrop y principle for adaptive con- trol in linear quadratic regulators. In The 7th c onfer enc e on informatics in c ontr ol, automation and r ob otics , volume 3, pages 103–108, 2010. [10] W L Brigner. Effect of p erceiv ed brightness on p erceiv ed time. Per c ept Mot Skil ls , 63(2 Pt 1):427–30, Octob er 1986. [11] J. F. Brown. Motion expands perceived time. Psycholo gische F orschung , (14):233–248, 1931. [12] S. W. Bro wn. Timing, resources, and interference: A ttentional mo dulation of time p er- ception. Attention and time , pages 107–121, 2010. [13] O. Chapelle and L. Li. An Empirical Ev aluation of Thompson Sampling. In A dvanc es in Neur al Information Pr o c essing Systems 24 , pages 2249–2257, 2011. [14] T.M. Cov er and J.A. Thomas. Elements of information the ory . Wiley New Y ork, 1991. [15] Arnaud D’Argembeau and Martial V an der Linden. Individual differences in the phe- nomenology of mental time travel: The effect of vivid visual imagery and emotion regu- lation strategies. Conscious Cognition , 15(2):342–50, 2006. [16] B. M. de Jong, S. Shipp, B. Skidmore, R. S. F rack owiak, and S. Zeki. The cerebral activity related to the visual p erception of forward motion in depth. Brain , 117 (Pt 5): 1039–54, 1994. [17] V. Dragoi, J. E. R. Staddon, R. G. Palmer, and C. V. Buhusi. Interv al Timing as an Emergent Learning Prop ert y. Psycholo gic al R eview , 110:126–144, 2003. [18] S. Droit-V olet and S. Gil. The Time-Emotion Parado x. Philosophic al T r ansactions of the R oyal So ciety B: Biolo gical Scienc es , 364:1943–1953, 2009. [19] M.O. Duff. Optimal le arning: c omputational pr oc e dur es for b ayes-adaptive markov de- cision pr o c esses . PhD thesis, 2002. Director-Andrew Barto. 20 [20] P . Dupont, G. A. Orban, B. De Bruyn, A. V erbruggen, and L. Mortelmans. Many areas in the h uman brain respond to visual motion. Journal of Neur ophysiolo gy , 72(3):1420–1424, 1994. [21] D.M. Eagleman and V. P ariyadath. Is sub jectiv e duration a signature of co ding efficiency? Philosophic al tr ansactions of the Royal Society of L ondon. Series B, Biolo gic al sciences , 364(1525):1841–1851, July 2009. [22] M. F ailing and J. Theeuw es. Reward alters the perception of time. Co gnition , 148:19–26, 2016. [23] P .C. Fishburn. The F oundations of Exp e cte d Utility . D. Reidel Publishing, Dordrec ht, 1982. [24] S. F rederick, G. Lo ew enstein, and T. O’Donogh ue. Time Discoun ting and Time Prefer- ence: A Critical Review. Journal of Ec onomic Liter ature , 40(2):351–401, June 2002. [25] K. F riston, R. Adams, and R. Montague. What is v alue-accum ulated reward or evidence? F r ontiers in Neuror ob otics , 6:11, 2012. [26] Z. Ghahramani. Bay esian non-parametrics and the probabilistic approach to mo delling. Philosophic al T r ansactions of the R oyal So ciety A , 371(20110553), 2013. [27] J. Gibb on, R. M. Churc h, and W. H. Meck. Scalar timing in memory . Annals of the New Y ork Ac ademy of Sciences , 423:52–77, 1984. [28] K. Healy , L. McNally , G.D. Ruxton, N. Co oper, and A.L. Jac kson. Metab olic rate and bo dy size are linked with p erception of temp oral information. Animal Behaviour , 86(4): 685–696, 2013. [29] M. Hutter. Universal Artificial Intel ligenc e: Se quential De cisions b ase d on Algorithmic Pr ob ability . Springer, Berlin, 2004. [30] J. V oon V. Johansson J. Niemel¨ a S. Bergman J. Kaasinen V. Joutsa. Dopaminergic function and intertemporal choice. T r anslational psychiatry , 5(1), 2015. [31] R. Kanai, C. L. P affen, H. Hogendo orn, and F. A. V erstraten. Time dilation in dynamic visual display . Journal of vision , 6(12):1421–1430, 2006. [32] A. S. Allen D. C. Nav arro-Cebrian A. Mitc hell J. M. Fields H. L. Kayser. Dopamine, corticostriatal connectivity , and intertemporal choice. The Journal of Neur oscienc e , 32 (27):9402–9409, 2012. [33] T.L. Lai and H. Robbins. Asymptotically efficient adaptive allo cation rules. A dvanc es in applie d mathematics , 6:4–22, 1995. [34] D. Laibson. Golden Eggs and Hyp erbolic Discoun ting. Quarterly Journal of Ec onomics , 112(2):443–477, 1997. [35] D. E. Linden, D. Prvulovic, E. F ormisano, M. V ollinger, F. E. Zanella, R. Go ebel, and T. Dierks. The functional neuroanatomy of target detection: An fMRI study of visual and auditory o ddball tasks. Cerebr al Cortex , 9:815–823, 1999. [36] G. Lo omes and R. Sugden. Regret theory: An alternative approach to rational c hoice under uncertaint y. Ec onomic Journal , 92:805–824, 1982. [37] D.J.C. MacKay . Information The ory, Infer enc e, and L earning Algorithms . Cambridge Universit y Press, 2003. [38] M. Maniadakis and P . T rahanias. Time models and cognitive pro cesses: a review. F ron- tiers in Neur or ob otics , 8:7, 2014. 21 [39] M. S. Matell and W. H. Meck. Neuropsychological mechanisms of in terv al timing b eha v- ior. Bio essays , 22(1):94–103, 2000. [40] S. O. Murray , H. Bo yaci, and D. Kersten. The representation of p erceiv ed angular size in human primary visual cortex. Natur e Neur oscienc e , 9(3):429–34, 2006. [41] F. Ono and J. Kaw ahara. The sub jective size of visual stimuli affects the p erceiv ed duration of their presentation. Per c eption & psychophysics , 69(6):952–957, August 2007. [42] P .A. Ortega and D.A. Braun. Thermodynamics as a theory of decision-making with information-processing costs. Pr o c e e dings of the R oyal So ciety A: Mathematical, Physic al and Engine ering Scienc e , 469(2153), 2013. [43] C. M. Papadimitriou. Computational Complexity . Addison-W esley , 1994. ISBN 0201530821. [44] V. Pariy adath and D. M. Eagleman. Brief sub jective durations contract with rep etition. Journal of vision , 8(16), 2008. ISSN 1534-7362. [45] C. Ranganath and G. Rainer. Neural mechanisms for detecting and remembering nov el even ts. Natur e R eviews Neur oscienc e , 4:193–202, 2003. [46] D. Read. Is time-discounting hyperbolic or subadditive? Journal of R isk and Unc er- tainty , 23(1):5–32, 2001. [47] P . J. Riggs. Contemporary Concepts of Time in W estern Science and Philosophy. In L ong History, De ep Time: De epening Histories of Plac e , pages 47–66. ANU Press, 2015. [48] J. Rissanen. Generalized Kraft Inequality and Arithmetic Co ding. IBM Journal of R ese ar ch and Development , 20(3):198–203, 1976. [49] C. O. Z. Roelofs and W. P . C. Zeeman. Influence of different sequences of optical stimuli on the estimation of duration of a given in terv al of time. Acta Psycholo gic a , 8:89–128, 1951. [50] A. Rubinstein. Mo deling b ounde d r ationality . MIT Press, 1998. [51] S. Russell and P . Norvig. Artificial Intel ligenc e: A Mo dern Appr o ach . Prentice-Hall, Englewood Cliffs, NJ, 3rd edition edition, 2009. [52] P .A. Samuelson. A Note on Measurement of Utility. R eview of Ec onomic Studies , 4(2): 155–161, F ebruary 1937. [53] L.J. Sav age. The F oundations of Statistics . John Wiley and Sons, New Y ork, 1954. [54] H. R. Schiffman and D. J. Bobko. Effects of stimulus complexity on the p erception of brief temp oral interv als. Journal of Experimental Psycholo gy , 103(1):156–9, 1974. [55] P . Sch warten beck, T. H. B. FitzGerald, C. Math ys, R. Dolan, M. Kron bichler, and K. F ris- ton. Evidence for surprise minimization ov er v alue maximization in choice behavior. Scientific R ep orts , 5(16575), 2015. [56] C.R. Shalizi and J.P . Crutchfield. Computational Mec hanics: Pattern and Prediction, Structure and Simplicity. Journal of Statistic al Physics 104 (2001): 816–879 , 2000. [57] C.E. Shannon. A mathematical theory of comm unication. Bel l System T e chnic al Journal , 27:379–423 and 623–656, Jul and Oct 1948. [58] M. Sipser. Intr o duction to the The ory of Computation . PWS Pub Co, 1996. 22 [59] D. Soman, G. Ainslie, S. F rederick, X. Li, J. Lynch, P . Moreau, A. Mitc hell, D. Read, A. Sawy er, Y. T rope, K. W ertenbroch, and G. Zauberman. The psyc hology of in tertemp o- ral discounting : Why are distan t ev en ts v alued differen tly from pro ximal ones? Marketing L etters , 16(3–4):347–360, 2005. [60] J. E. R. Staddon. Interv al timing: memory , not a clo c k. T rends in Co gnitive Scienc es (R e gul. Ed.) , 9(7):312–4, 2005. [61] C. Steinrueck en. Compr essing structure d obje cts . PhD thesis, Universit y of Cam bridge, 2014. [62] S. Still, D.A. Siv ak, A.J. Bell, and G.E. Cro oks. Thermo dynamics of Prediction. Phys. R ev. L ett. , 109(12):120604, September 2012. [63] T. Suddendorf and M. C. Corballis. Mental time travel and the evolution of the human mind. Genetic, So cial, and General Psycholo gy Mono gr aphs , 123(2):133–67, 1997. [64] R.S. Sutton and A.G. Barto. Reinfor c ement L e arning: A n Intro duction . MIT Press, Cambridge, MA, 1998. [65] T. T ak ahashi, H. Oono, and M. H. B. Radford. Psychoph ysics of time p erception and intertemporal c hoice mo dels. Physic a A: Statistic al Me chanics and its Applic ations , 387 (8):2066–2074, 2008. [66] M. T erao, J. W atanab e, A. Y agi, and S. Nishida. Reduction of stimulus visibility com- presses apparent time interv als. Nat. Neur osci. , 11:541–542, 2008. [67] W.R. Thompson. On the Likelihoo d that One Unknown Probability Exceeds Another in View of the Evidence of Tw o Samples. Biometrika , 25(3/4):pp. 285–294, 1933. [68] N. Tish by and D. Polani. Information Theory of Decisions and Actions. In Hussain T ay- lor V assilis, editor, Per c eption-r e ason-action cycle: Mo dels, algorithms and systems . Springer, Berlin, 2011. [69] E. T o doro v. Efficient computation of optimal actions. Pr o c e e dings of the National A c ademy of Scienc es U.S.A. , 106:11478–11483, 2009. [70] Peter Ulric U. Tse, James Intriligator, Jos´ ee Riv est, and Patric k Cav anagh. Atten tion and the sub jective expansion of time. Per c eption & psychophysics , 66(7):1171–1189, October 2004. ISSN 0031-5117. [71] J. V on Neumann and O. Morgenstern. The ory of Games and Economic Behavior . Prince- ton Universit y Press, Princeton, 1944. [72] M.A. Wheeler, D.T. Stuss, and E. T ulving. T ow ard a theory of episodic memory: The frontal lob es and autonoetic consciousness. Psycholo gic al Bul letin , 121:331–354, 1997. [73] B. Xuan, D. Zhang, S. He, and X. Chen. Larger stimuli are judged to last longer. Journal of Vision , 7:1–5, 2007. [74] G. Zaub erman, B. K. Kim, S. A. Malkoc, and J. R. Bettman. Discounting time and time discounting: Sub jective time p erception and intertemporal preferences. Journal of Marketing R ese ar ch , 46(4):543–556, 2009. 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment