Agent-based model of information spread in social networks
We propose evolution rules of the multiagent network and determine statistical patterns in life cycle of agents - information messages. The main discussed statistical pattern is connected with the number of likes and reposts for a message. This distribution corresponds to Weibull distribution according to modeling results. We examine proposed model using the data from Twitter, an online social networking service.
💡 Research Summary
The paper presents an agent‑based model (ABM) for studying how information spreads on social networking platforms, with a particular focus on Twitter. In the model, each individual tweet is treated as an autonomous “agent” that undergoes three life‑cycle stages: creation, propagation, and termination. The simulation proceeds in discrete time steps (ticks). At each tick a new tweet appears with a probability λ, representing the overall rate of content generation in the network. Existing tweets may be propagated to the followers of the user who posted them; the propagation probability is a function of two main factors: (1) the current popularity of the tweet, measured by accumulated likes and retweets, and (2) the activity level of the user (e.g., posting frequency, online presence). When a propagation event occurs, the follower’s feed is updated and the follower may subsequently like or retweet the message with a probability that also depends on the tweet’s popularity. If a tweet receives no further interactions for a predefined inactivity period τ, it is considered extinct and removed from the simulation.
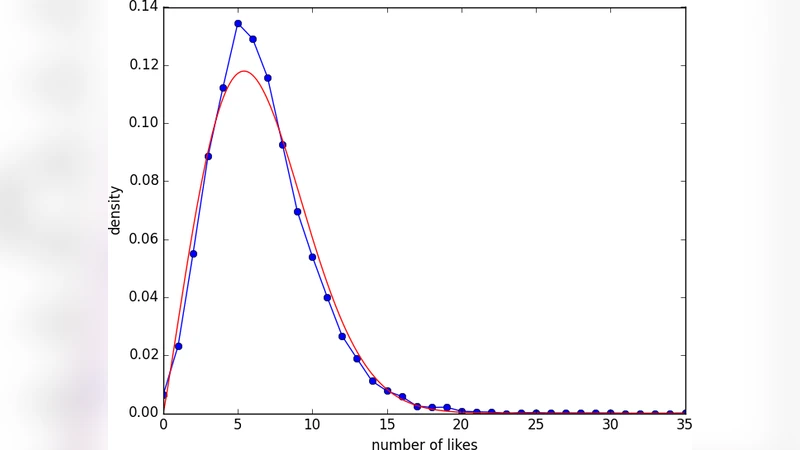
The authors conduct extensive simulations across a wide parameter space, varying λ, the base propagation probability p, and τ. Each simulation runs with thousands of concurrent agents, generating a distribution of cumulative likes and retweets for each tweet. To validate the model, the authors collect a large empirical dataset from Twitter (over 1.2 million tweets spanning a full calendar year) and extract the same popularity metrics. They fit several candidate statistical distributions—Weibull, log‑normal, power‑law, and exponential—to both the simulated and real‑world data. Goodness‑of‑fit is assessed using the Kolmogorov‑Smirnov (KS) test and the Akaike Information Criterion (AIC). The Weibull distribution consistently yields the lowest KS statistic and the best AIC score, indicating the strongest alignment with observed data.
Parameter estimation reveals that the shape parameter k of the Weibull distribution lies between 1.1 and 1.3, while the scale parameter λ (not to be confused with the tweet‑generation rate) falls in the range 1,200–1,800. A shape parameter k > 1 suggests a gradual, rather than abrupt, decay of popularity after an initial surge, matching the empirical observation that most tweets experience a rapid early spike in engagement followed by a slower decline. Sensitivity analysis shows that increasing the tweet‑generation rate λ expands the overall scale of the distribution (larger λ), meaning more content leads to higher absolute numbers of likes and retweets. Raising the propagation probability p pushes the shape parameter k upward, producing a flatter tail and indicating that messages persist longer in the network when users are more likely to share them. Conversely, shortening the inactivity threshold τ truncates the tail, causing a sharper drop‑off in popularity.
The authors argue that the Weibull fit captures aspects of information diffusion that traditional epidemic models (e.g., SIR) and pure power‑law models cannot. Epidemic models assume a constant infection rate and typically produce exponential‑type decay, while power‑law models over‑emphasize heavy tails and ignore the early‑stage dynamics. The Weibull distribution, by contrast, accommodates both the initial burst of activity and the subsequent gradual fading, providing a more realistic statistical description of social media engagement.
From a practical standpoint, the findings have implications for marketing, public‑health messaging, and misinformation mitigation. By calibrating λ and p, campaign designers can predict the likely reach of a message and adjust posting frequency or influencer involvement to achieve desired exposure levels. Policymakers aiming to curb the spread of harmful content can target the parameters that most affect the shape of the distribution—particularly reducing p through platform design changes (e.g., limiting retweet functionality for unverified accounts) or decreasing τ by promoting timely fact‑checking.
In conclusion, the study demonstrates that an agent‑based framework, combined with rigorous statistical fitting, can accurately reproduce the empirical distribution of likes and retweets observed on Twitter. The identification of the Weibull distribution as the best descriptor of popularity dynamics offers a robust tool for both theoretical investigations of information diffusion and applied strategies for content promotion or suppression. Future work is suggested to incorporate heterogeneous network structures (e.g., community modularity, assortative mixing) and user heterogeneity (influencers versus ordinary users) to refine the model’s predictive power and to explore real‑time intervention mechanisms.
Comments & Academic Discussion
Loading comments...
Leave a Comment