Geometry Aware Mappings for High Dimensional Sparse Factors
While matrix factorisation models are ubiquitous in large scale recommendation and search, real time application of such models requires inner product computations over an intractably large set of item factors. In this manuscript we present a novel f…
Authors: Avradeep Bhowmik, Nathan Liu, Erheng Zhong
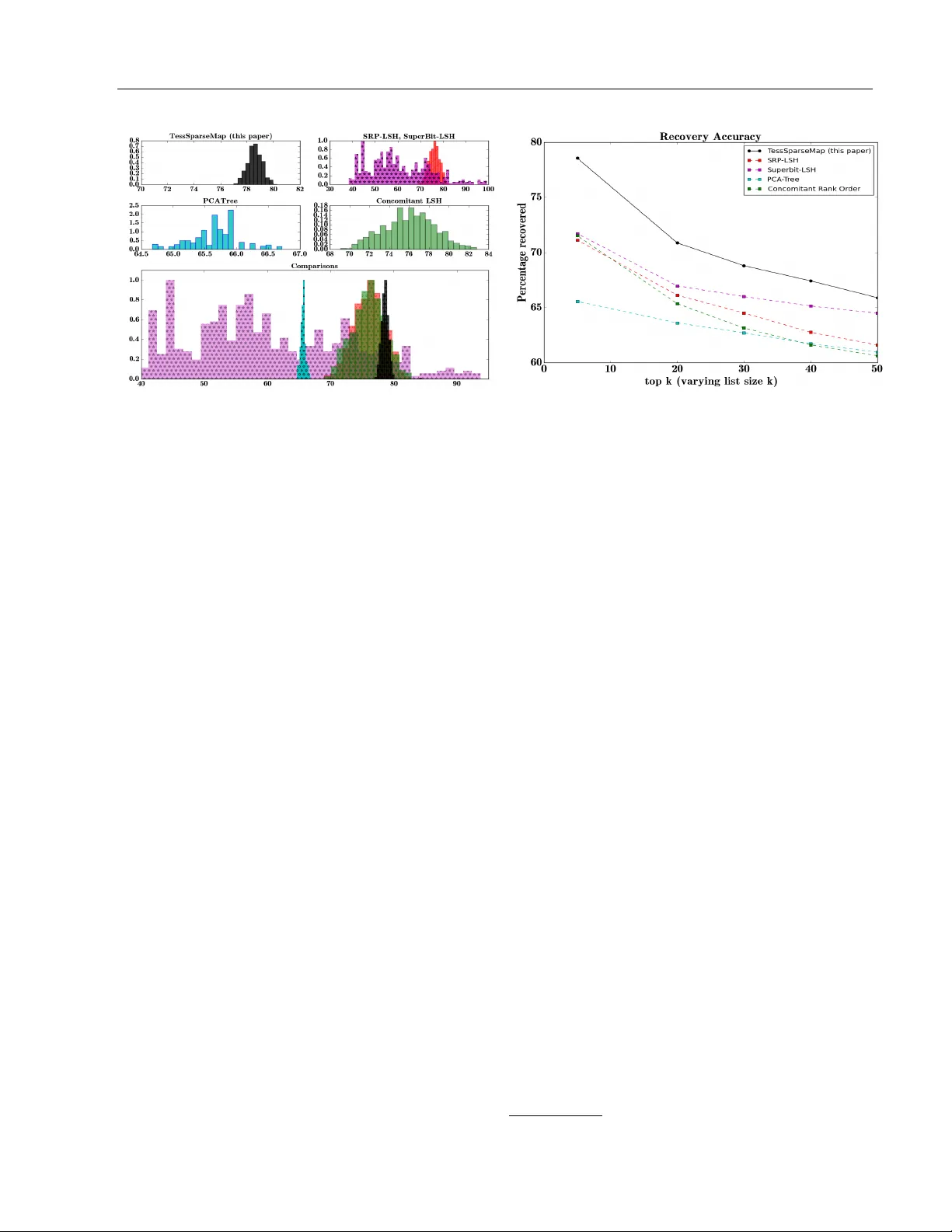
Geometry Aw are Mappings for High Dimensional Sparse F actors Avradeep Bho wmik Nathan Liu Univ ersity of T exas at Austin, Austin, TX Go ogle, Mountain View, CA Erheng Zhong Badri Nara yan Bhask ar Suju Ra jan Y ahoo! Labs, Sunnyv ale, CA Y ahoo! Labs, Sunnyv ale, CA Y ahoo! Labs, Sunnyv ale, CA Abstract While matrix factorisation mo dels are ubiq- uitous in large scale recommendation and searc h, real time application of such mo d- els requires inner product computations ov er an in tractably large set of item factors. In this man uscript w e presen t a nov el frame- w ork that uses the inv e rted index represen ta- tion to exploit structural prop erties of sparse v ectors to significantly reduce the run time computational cost of factorisation mo dels. W e dev elop techniques that use geometry a ware p erm utation maps on a tessellated unit sphere to obtain high dimensional sparse em- b eddings for latent factors with sparsit y pat- terns related to angular closeness of the orig- inal laten t factors. W e also design several efficien t and deterministic realisations within this framew ork and demonstrate with exp er- imen ts that our tec hniques lead to faster run time operation with minimal loss of accuracy . 1 INTR ODUCTION Laten t factor mo dels like matrix [ 17 , 18 ] and tensor [ 23 , 24 ] factorisation are a ubiquitous class of tech- niques with a wide range of applications, mainly in p er- sonalised search and recommendation systems, where eac h user i and eac h item j is assumed to b e associ- ated with laten t factors u i , v j ∈ R k resp ectiv ely and the matrix of in teractions (ratings, clic k/no-click, etc.) R = [ r ij ] for the i th user with the j th item is mo d- elled as the product of their resp ective latent factors as r ij ∼ u > i v j or a monotonic function thereof. While substan tial amoun t of w ork [ 17 , 18 , 25 ] has been App earing in Proceedings of the 19 th In ternational Con- ference on Artificial In telligence and Statistics (AIST A TS) 2016, Cadiz, Spain. JMLR: W&CP volume 51. Copyrigh t 2016 b y the authors. dedicated to learning the latent factors given in terac- tion data in a scalable manner, an often ov erlo ok ed problem is the computational efficiency of deploying the learned factors for real time recommendation. The commonly used brute force retriev al of top- κ rel- ev ant items for any user i requires score computation of the corresponding latent factor u i with ev ery sin- gle item factor v j ∀ j = { 1 , 2 , · · · N } , which is often an intractably large set. Pre-computing scores dur- ing the learning step is often impractical, for instance, in online news recommendation, where user in terests c hange very rapidly and new items keep cropping up all the time. Moreo ver, while changing latent factors can b e learned dynamically , arbitrary c hanges in la- ten t factors would require updates to the entire set of pre-computed scores. A greatly preferable alternative w ould b e to design a tec hnique that automatically discards irrelev ant items p er user, and thereby significantly reduces the searc h space for top- κ recommendations. This manuscript do es exactly this, by exploiting structural prop erties of sparse vectors using the in verted index represen tation. 1.1 Sparse F actors and the Inv erted Index Represen tation Supp ose the factors for users and items w ere v ery sparse, inner pro duct b etw een factors with non- o verlapping sparsity patterns (non-zero’s in differen t indices) w ould compute to 0. In such a case for ev- ery user, relev ant items w ould b e suc h that the cor- resp onding user factor and items factor hav e more or less matching sparsit y pattern. The inv erted index representation [ 11 , 4 ], widely used in information retriev al tasks, is particularly appropri- ate to exploit this prop erty . In our setup, this inv olv es storing the list of items using a data structure where eac h index is asso ciated with all the items whose cor- resp onding latent factors are non-zero in that index. During recommendation, for eac h user, w e extract the set of indices I u in whic h the corresp onding user fac- Geometry Aw are Mappings for High Dimensional Sparse F actors tor u is non-zero, and retrieve using the inv erted index notation, the set of items which are also non-zero in the corresp onding indices in I u . Inner pro duct com- putation is then required only ov er this significantly smaller set, rather than the full item set. 1.2 Conflicting Sparsit y Pattern Clearly , the success of the inv erted index represen ta- tion relies on using factors with significant “conflict” in their sparsity patterns 1 . Lo w dimensional factors are almost alwa ys dense, and to av oid losing to o muc h information, in tro ducing sparsit y w ould need to b e accompanied with an in- crease in dimensionalit y . Unfortunately , most learn- ing algorithms that promote sparsity (like LASSO) cannot necessarily ensure conflicting sparsit y patterns. A more reliable alternativ e is p ost-pro cessing factors (p ossibly dense, and learned using an y appropriate al- gorithm) to obtain high dimensional sparse em b ed- dings such that for original factors that are “close” to each other (high inner pro duct), the corresp onding sparse maps would hav e significan t ov erlap in sparsit y patterns, and vice v ersa. T o our kno wledge, we are the first to explicitly tac kle this exact problem setup, to use the inv erted index represen tation to discard irrelev an t factors with con- flicting sparsity pattern. Our main contributions are as follows: 1. W e introduce a no vel framework consisting of a meta-algorithm that uses geometry a w are permu- tation maps on a tessellated unit sphere to obtain sparse embeddings for latent factors with sparsit y patterns related to angular closeness of the orig- inal factors. 2. W e provide sev eral deterministic realisations for the meta-algorithm that are efficien t with resp ect to time and space complexit y and satisfy desir- able prop erties 3. W e demonstrate the efficacy of our methods with extensiv e experimental ev aluation 1.3 Notation S k refers to the surface of the k -dimensional Euclidean unit sphere. W e use (usually subscripted) blackboard b old font P to denote p erm utations, alwa ys in p - dimensional space unless indicated otherwise, where 1 Tw o sparse v ectors ha ve a conflicting sparsit y pattern if the set of indices of non-zero elements for the tw o v ectors are disjoint or ha ve a v ery small in tersection. F or example [9 , 0 , 8 , 0 , 0] and [0 , 6 , 0 , 7 , 3] hav e non-zero elemen ts in non- o verlapping sets of indices { 0 , 2 } and { 1 , 3 , 4 } resp ectively p > k . Finally , w e use φ : S k 7→ R p to refer to our sparse mapping function that maps factors z on the k -dimensional h yp ersphere to a sparse p -dimensional v ector φ ( z ). Zero padded vectors are denoted by dia- critics as ¨ z . 2 PR OBLEM SETUP Consider the follo wing setup. W e are given a set of N factors [ z 1 ; · · · ; z N ] = Z ∈ Z ⊆ S k , where S k = { x ∈ R k : k x k 2 = 1 } is the unit sphere in k - dimensional Euclidean space R k . F or example, in a recommendation setting the set of factors Z could b e the concatenated set Z = [ U ; V ] of user features U and ob ject features V . The “compatibility” betw een t wo factors z i , z j is mea- sured as r ij = z > i z j . In the context of recommenda- tions, z i = u i is the i th user factor, and z j = v j is the j th item factor, and r ij is the interaction (rating, clic k/no-click). This notion of “compatibility” betw een factors on the unit sphere S k is captured by the angular distance 2 metric d ( · , · ) whic h is defined for an y t wo factors x , y ∈ R k as d ( x , y ) = 1 − x > y k x k 2 k y k 2 F or factors z i , z j ∈ Z , k z k 2 = 1, therefore d ( z i , z j ) = 1 − z > i z j = 1 − r ij . Clearly , factors whic h are more compatible hav e a low angular distance in their Eu- clidean vector represen tations and vice versa. The ob jective is to find a map φ : Z 7→ R p that maps factors in Z to sparse v ectors in a p -dimensional space R p , where p > k . As describ ed earlier, the inv erted index represen tation is useful in extracting vectors whic h hav e o verlapping sparsit y patterns. Hence, the mapping φ should b e suc h that if t wo factors z i and z j ha ve a lo w angu- lar distance b etw een them, their corresp onding map- pings φ ( z i ) and φ ( z j ) should hav e similar sparsity pat- terns. Conv ersely , if z i and z j ha ve a high angular distance betw een them, their corresponding mappings φ ( z i ) and φ ( z j ) should hav e conflicting sparsity pat- terns. 3 A GEOMETR Y A W ARE SCHEMA F OR SP ARSE MAPPING The requirements on φ ( · ) elab orated on in the preced- ing section can b e captured effectively with the fol- lo wing intuitiv e observ ation. Suppose there exists a 2 alternativ ely , one min us standard cosine similarity Bho wmik et al (a) T essellating unit sphere in to regions, and marking each z (b) Padding with zeros, to obtain ¨ z ∼ { z ; 0 } (c) Applying region based p ermu- tation, to get φ ( z ) = P ( ¨ z ) Figure 1: A pictorial representation of the sparse mapping technique- (a) T essellating the unit sphere and asso ciating each factor with its corresp onding tile (b) Padding each factor with zeros to make it p -dimensional (c) Applying to eac h zero-padded vector the p erm utation specific to its tile on the tessellated unit sphere mapping b etw een sparsity patterns and regions on the surface of the unit sphere such that neighbouring re- gions of the unit sphere get similar sparsit y patterns and vice v ersa. Then the requiremen ts on the mapping function can be satisfied b y setting φ to map ev ery fac- tor with the sparsit y pattern that dep ends on whic h region on the unit sphere the factor lies. Our prop osed framew ork uses this intuition to design a mapping function φ ( · ) that maps compatible (an- gularly close) factors to ov erlapping sparsit y patterns and incompatible factors to conflicting sparsit y pat- terns. The steps inv olved are describ ed below (and summarised as the meta-algorithm in Algorithm 1 ). W e show concrete realisations for the meta-algorithm in section 4 . 3.1 Defining a Sc hema First we define a schema consisting of tessellating the unit sphere and a permutation map for each tile or region of the tessellated unit sphere. Step I: T essellating the unit sphere : A natural w ay of defining regions corresp onding to an- gular distance is via tiles on the surface of a tessellated unit sphere. An M -order tessellation for our purp ose is sp ecified completely by a set of M distinct tessellating v ectors Γ = { a i : i = 1 , 2 , · · · M , k a i k = 1 } ⊂ S k . Eac h tile or region γ a asso ciated with a sp ecific tessellating v ector a under this schema is defined simply as the set of p oints which are closest to the said tessellating v ector, that is, γ a = { x ∈ S k : d ( γ a , x ) ≤ d ( γ a 0 , x ) ∀ a 0 ∈ Γ , a 6 = a 0 } Therefore, the b oundary betw een regions under suc h a tessellating scheme consists of p oints on the unit sphere which are equidistant from t wo or more tessel- lating v ectors. Note that this is similar to the concept of a V oronoi tessellation in a metric space. Step I I: Associating ev ery region with a p er- m utation : The next step is to asso ciate a p ermutation P a with eac h a ∈ Γ, w e denote the set of all such p ermuta- tions by P Γ = { P a : a ∈ Γ } . The main requiremen t for this mapping is that nearby tessellating vectors should get mapp ed to similar p ermutations. An informal ex- istence argument can b e made for this using the fact that the set of p ermutations, when represented as the v ertices of a Birkhoff polytop e [ 5 ], can be embedded on the surface of a unit h yp ersphere [ 22 ]. 3.2 Pro cessing F actors based on the Schema Giv en a schema (Γ , P Γ ), defining the map φ ( · ) for a set of factors Z consists of the following steps Step I: Asso ciating ev ery factor to a region : The associated region for a factor z is specified b y the closest (in angular distance) tessellating v ector a z ∈ Γ to the factor, as determined by the following optimi- sation problem a z = arg min a ∈ Γ d ( a , z ) (1) This is, in general, a difficult optimisation problem, with a search space ov er an intractably large discrete domain, but as we shall see in the succeeding sections, man y tessellating sc hemata admit efficient solutions, exact or approximate, to this problem. Step I I: Zero-padding factors : The next step is simply to zero-pad the k -dimensional v ector with p − k zeros to mak e it p -dimensional. De- note the zero-padded factor for z b y ¨ z . Geometry Aw are Mappings for High Dimensional Sparse F actors Step I I I: Applying region sp ecific p ermutation Finally , we apply region sp ecific permutations as de- fined b y P Γ to the zero-padded v ector. Say a z is the tessellating region asso ciated with a factor z , and P a z is the corresp onding p -dimensional p erm utation asso- ciated with a z , then the mapping φ maps z to R p b y using the p ermutation op erator P a z on the zero- padded factor ¨ z as φ ( z ) = P a z ( ¨ z ) (2) A pictorial 3 depiction of the technique has b een sho wn in Figure 1 . With prop er selection of tessellation sc hema and p ermutation map, factors in nearby tiles ha ve similar sparsit y patterns (high ov erlap in non-zero en tries) in their sparse maps and vice v ersa. Algorithm 1 Sparse-mapping meta-algorithm 1: pro cedure Schema (M) 2: Define tessellating set of M v ectors Γ ⊂ S k 3: Define p ermutation map P a for each a ∈ Γ 4: return Γ , P Γ 5: end pro cedure 6: pro cedure ProcessF actors (Γ , P Γ , Z ) 7: for each z ∈ Z do 8: asso ciate region as a z = arg min a ∈ Γ d ( a , z ) 9: zero-pad ˜ z = [ z ; 0] 10: apply p ermutation to get φ ( z ) = P a z ( ˜ z ) 11: end for 12: return φ ( Z ) 13: end pro cedure 3.3 Desiderata for a go o d schema Apart from finding effective tessellation sc hemata and p erm utation maps for each tessellation schema, there are multiple c hallenges that need to be tak en into con- sideration when designing a particular instance for this meta algorithm. Note that for a giv en schema, pro- cessing the factors in volv es tw o p otentially computa- tionally intensiv e steps defined in equations 1 and 2 . Hence, an y schema for tessellation and p ermutation should be such that both 1 and 2 should b e efficien tly computable. Another concern w ould be controlling the storage complexity . The first natural technique that is immediate as a tes- sellation schema is hypersphere p oint picking where random p oints are pick ed uniformly distributed on the surface of the unit h yp ersphere (see for instance [ 19 , 8 , 21 , 13 ]). Owing to [ 20 ], w e hav e a simple metho d of doing this b y generating M indep endent 3 parts of the image adapted from the w eb and identically distributed p oints from the standard k -dimensional multiv ariate Gaussian distribution and normalising them. Since the standard Gaussian distri- bution is spherically symmetric, the resulting p oints are uniformly distributed on the surface of the unit h yp ersphere. Ho wev er, it is immediately apparent that for any ran- domised sc hema for Γ, solving the optimisation prob- lem 1 for any z ∈ Z w ould require an exhaustive search in volving an explicit computation of distance scores with every a ∈ Γ. Since M can b e really large (often sup er exp onential in k , as w e shall see in section 4 ), this is computationally infeasible. Moreov er, b ecause this requires explicit generation and storage of all M tessellating v ectors, the space complexit y required is also prohibitively high. A similar argument holds for the design of the permu- tation map as well. The space of permutations ov er p co ordinates is O (2 plog p ) in p , and assigning p ermuta- tions one by one to each of the M tessellating vectors w ould be infeasible. A one-stop solution to b oth of these problems is to ha ve a deterministic function-based schema for b oth the tessellation and p ermutation map. That is, given a factor z ∈ Z ⊂ S k , finding the tessellating vector closest to it should inv olv e ev aluating a function of z whic h is computationally efficient in terms of k , and for a giv en tessellating vector a ∈ Γ, computing the corresp onding permutation P a should in volv e ev aluat- ing a function of a whic h can b e done efficien tly in terms of p . Therefore, mapping for eac h factor can b e done separately in a tw o-step pro cess without ad- ditional explicit storage or computation of Γ or P Γ . 4 DETERMINISTIC SCHEMA T A In this section, we describ e some concrete realisations for the general sc hema describ ed earlier. In particular, w e specify simple techniques for tessellating the unit sphere, as well as asso ciating a p ermutation map with eac h of these tessellations, and generalise eac h of these tec hniques to define a broader class of realisations for our sc hemata. W e will show that finding φ ( z ) giv en z using each of these techniques only in volv es tw o effi- cien t deterministic function computations, hence they a void all of the pitfalls describ ed in the previous sec- tion. Note that obtaining φ ( z ) for each z can be done separately for each z in parallel. 4.1 T essellating the Unit Sphere The first step in the meta-algorithm is to tessellate the unit sphere. W e start off by describing a simple sc heme in section 4.1.1 and then generalise the idea to sp ecify a larger class of tessellation sc hemes in section Bho wmik et al 4.1.2 . 4.1.1 Directional tessellation Consider the ternary base set B = {− 1 , 0 , 1 } . Sa y A = B k − { 0 } k is the set of all 4 non-zero k -length ternary v ectors formed out of elemen ts of {− 1 , 0 , 1 } . The tessellating v ector set is formed from the nor- malised versions of these vectors, that is Γ = { a = ˜ a k ˜ a k : ˜ a ∈ A} (3) Clearly in this case, M = | Γ | = 3 k − 1. How ever, finding the closest tessellating v ector given any z ∈ Z can b e done efficien tly . 5 Lemma 1. Given a factor z ∈ Z ⊂ S k , solving e qua- tion 1 for Γ as in 3 c an b e p erforme d efficiently in O ( k log k ) time using Algorithm 2 , and r e quir es no ex- plicit stor age of the tessel lating set Γ . The time complexit y of Algorithm 2 is O ( k l og k ) since the limiting op eration is a sorting operation which can b e done in O ( k l og k ) time. Pro of of correctness of this algorithm is presen ted in the supplementary material. 4.1.2 Directional tessellation using D-ary Base set This is exactly the same as the previous case, ex- cept the tessellation is done with a D -ary base set B D = {− 1 , − D − 1 D , · · · , − 1 D , 0 , 1 D , · · · , D − 1 D , 1 } instead of a ternary base set- the corresp onding vector set is A D = B k D − { 0 } k and tessellating set is Γ D = { a = ˜ a k ˜ a k : ˜ a ∈ A D } . Clearly , the ternary base set {− 1 , 0 , 1 } is the same as B D with D = 2. The algorithm 2 for ternary base sets no longer applies directly to the D -ary case. In fact, getting an exact solution is, in general, difficult for this schema. How- ev er, w e can still get an -approximation to the clos- est tessellating vector (the corresp onding algorithm is pro vided in the supplement). Lemma 2. F or any ve ctor z ∈ Z , say a ∗ z is the true solution to e quation 1 with Γ obtaine d the D -ary b ase set. Then, a tessel lating ve ctor ˜ a z c an b e obtaine d such that d ( a ∗ z , ˜ a z ) ≤ , wher e ∼ O ( k /D 2 ) , using an al- gorithm that takes O ( k ) time, and r e quir es no explicit stor age of the tessel lating set Γ D . Therefore, if D √ k , the true tessellating v ector can b e obtained within a v ery small tolerance. The algo- 4 F or example, for k = 2, w e hav e A = { [ − 1 , − 1] , [ − 1 , 0] , [ − 1 , 1] , [0 , 1] , [1 , 1] } . 5 Note that the na ¨ ıv e algorithm that thresholds ev ery index of z on -0.5 or 0.5 to get an element of B do es not giv e an exact solution since we are working with angular distance metrics Algorithm 2 Region Specification on Γ defined on B 1: pro cedure TessVector ( z ) 2: Sort z in desc. order of abs. v alue to get z ↓ 3: Let π be the sorting order, that is, z j ↓ = | z π ( j ) | ≥ z π ( j +1) | = z j +1 ↓ ∀ j 4: Compute scaled cumsum z s from z ↓ as 5: for ι = 1 , 2 , · · · k do 6: Set z ι s = P ι j =1 z j ↓ √ ι 7: end for 8: Let ι ∗ = argmax ι z ι s b e the index of the maxi- m um v alue of z s 9: Define the index set (where z π − 1 ( k ) ↓ = | z k | ∀ k ) I z = { π − 1 (1) , π − 1 (2) , · · · π − 1 ( ι ∗ ) } 10: Compute the tessellating v ector a z as a ι z = ( sig n ( z ι ) √ | I z | if ι ∈ I z 0 otherwise 11: return a z 12: end pro cedure rithm to obtain this and the pro of of this lemma is pro vided in the supplemen tary material. Clearly , this sc hema generates a finer tessellation of the unit sphere with increasing D . 4.2 Sparse Mapping in High Dimensions The next step in the method is to assign a sparsity pattern to ev ery tessellating vector. W e start off b y describing a simple p ermutation map in section 4.2.1 and then generalise the idea to define a larger class of maps in section 4.2.2 . Note that each sparsity pattern can also b e defined as a function (that dep ends on the corresp onding tessellating v ector a z ) that maps a co ordinate of z to a sp ecific co ordinate of φ ( z ). 4.2.1 One Hot Enco ding A simple enco ding scheme is the follo wing. Consider the ternary tessellation scheme as in Section 4.1.1 . Note that for tessellating v ectors obtained from a ternary sc heme, there is a one-one correspondence b e- t ween eac h ˜ a ∈ A and each a ∈ Γ since a j = sig n ( ˜ a j ) (n um of non-zeros in ˜ a ) 1 / 2 ∀ j Therefore, a simple p ermutation scheme for this tes- sellation can be obtained for p = 3 k as follo ws. F or Geometry Aw are Mappings for High Dimensional Sparse F actors ev ery t = 1 , 2 , · · · k and i = 1 , 2 , · · · p set φ ( z ) i = [ P a z ( ¨ z )] i = z t if i = 3 t and ˜ a t z = 1 z t if i = 3 t + 1 and ˜ a t z = 0 z t if i = 3 t + 2 and ˜ a t z = − 1 0 otherwise This basically pads each co ordinate of z with t wo ex- tra zeros and permutes it within eac h 3-index segmen t th us obtained dep ending on the v alue of the corre- sp onding co ordinate of ˜ a z . A similar schema can be obtained for p = D k for the D -ary tessellation. The p ermutation th us obtained is related to the ge- ometry of the tessellation- for any tw o a 1 , a 2 ∈ Γ, the Kendall-T au distance 6 b et ween their corresp ond- ing p erm utations P a 1 , P a 2 is exactly equal to the ` 1 distance b etw een the unnormalised v ectors ˜ a 1 , ˜ a 2 . A b ound for Sp earman’s footrule can also be obtained[ 9 ]. It is easy to see that this mapping also has the desirable prop ert y that for any z ∼ a and z 0 ∼ a 0 , supp ose for a particular index j ∈ { 1 , · · · k } , we ha ve that τ j and τ 0 j are the corresp onding index map for φ ( · ). That is, φ ( z ) τ j = z j and φ ( z 0 ) τ 0 j = z 0 j . Then, τ j = τ 0 j if and only if a j = a 0 j . Moreo ver, the list of possible τ j is unique for an y j and depends only on j , and not on a . This ensures that sparsit y patterns o verlap only for neigh b ouring tessellating regions, uniformly . 4.2.2 P arse T ree Based Enco ding A more general scheme for this can b e obtained in the follo wing manner. Consider the ternary tessella- tion scheme of Section 4.1.1 . Start with a φ ( z ) as a p -length v ector of all zeros. F or constructing a parse- tree of depth δ , initialise b y mapping the first δ − 1 co ordinates of z to sp ecific co ordinates of φ ( z ) using, sa y , the one-hot enco ding scheme. A t eac h subsequent step j = δ, δ + 1 , · · · k , use a sliding windo w of size δ to read the unnormalised tessellating v ector ˜ a , suc h that δ coordinates are read at a time. At step j of the read- ing pro cess, we read the segmen t ˜ a j δ = [ ˜ a j − δ , · · · , ˜ a j ]. Since eac h coordinate of ˜ a can take three p ossible v al- ues {− 1 , 0 , 1 } , we can construct a parse tree of depth δ con taining 3 δ leaf nodes which is trav ersed based on the δ -length segment thus read. Thus, eac h non-leaf no de at depth t ∈ { 0 , 1 , · · · ( δ − 1) } branches out in to three c hild sub-trees corresp onding to ˜ a j − δ + t b eing -1, 0 or 1. Map the remaining co ordinates of φ ( z ) in the following w ay . A t each step j of the reading pro cess, main tain an index counter τ j ∈ { 1 , 2 , · · · p } that defines the current index at time j . Asso ciate each leaf node of the parse 6 minim um num b er of pairwise in versions required to con vert one p ermutation to another, see [ 9 ] tree with a corresponding “action” f ( · ) to perform on the counter to mov e it to the curren t index. That is, giv en the previous index τ j − 1 and the segmen t ˜ a j δ = [ ˜ a j − δ , · · · , ˜ a j ] read at time step j , compute the next p osition for the coun ter as τ j = f ( τ j − 1 ; ˜ a j δ ). Finally , map the j th co ordinate of z to the current index of φ ( z ) as φ ( z ) τ j = z j . Rep eat the same pro cess for eac h step j = δ, δ + 1 , · · · k . F or example, the one-hot enco ding is a sp ecial case of this with δ = 1. Suppose we hav e already mapped z 1 to z j − 1 . At step j , if the leaf no de corresp onding to a j z is 1, the corresp onding action is to set the counter τ j at time j to the co ordinate τ j = 3 j . Similarly , if a j z is a 0, we set the coun ter to the co ordinate τ j = 3 j + 1 and if it is -1, we set τ j = 3 j + 2. The corresp onding co ordinate of φ ( z ) gets mapp ed as φ ( z ) τ j = z j . Other more complicated actions f ( · ) are p ossible. In particular, we describ e some examples in the supple- men t which ha ve the property that for an y a , a 0 at an y step τ j = τ 0 j if and only if [ a j − t , · · · a j ] = [ a 0 j − t , · · · a 0 j ] for some t > δ . Moreov er, list of possible τ j for an y j dep ends uniquely only on j , and not on a itself. The parse-tree pro cedure can b e extended to the case of a D -ary tessellation scheme in a simple manner by con- sidering parse trees where eac h non-leaf no de has D c hild nodes. The mapping procedure is deterministic and time efficien t- supp ose each action f ( · ) in an O (1) op era- tion (most actions lik e shifts, etc. are of this form), the effectiv e time complexity is O ( k δ ). The final space complexit y of storing φ ( z ) for each z is no more than O ( k log p ) using the in verted index representation. 5 DISCUSSION W e w ould like to note that while the preceding discus- sion assumed normalised factors, we do not actually need the factors (or, indeed, even the tessellating v ec- tors) themselves to ha ve unit norm, since w e are any- w ay looking at the angular distance metric. In par- ticular, Algorithm 2 for finding the closest (in terms of angular distance) tessellating v ector a for a given factor z is scale inv arian t in terms of z as well as the set of a . Next, note that our schema is generic and do es not dep end on the sp ecific learning algorithm used for the laten t factors. Moreo ver, b ecause of the geometric na- ture of our framew ork, it can work for all kinds of fac- tors irresp ective of spherical symmetry properties of the factor distribution. F or factors whic h are known to hav e clustered form, a simple extension of our algo- rithm w ould inv olve a non-uniform tessellation scheme with finer granularit y near the cluster centres. Bho wmik et al (a) Histograms of p ercen tage of discarded items ov er users (b) Reco very Accuracy for Syn thetic Data Figure 2: Synthetic Data: our metho d discards more items on a verage with lo w er v ariance across users while ha ving higher recov ery accuracy (histogram y-axes scaled for uniformity) A discussion on non-uniform tessellation is pro vided in the supplementary material. 5.1 Related W ork The closest line of work to our metho d is lo cality sensitiv e hashing [ 14 , 12 ] which lo oks at approximate nearest neighbour extraction. Ho wev er, while hash- ing is mostly concerned with dimensionalit y reduction (faster score computation b y decreasing the effectiv e k ), our problem has more to do with direct reduction of effectiv e search space (faster retriev al by reducing effectiv e N ); in fact, the t wo metho ds are indep endent enough that they can augmen t each other. Hash func- tions ha ve b een developed for differen t distance met- rics lik e Hamming distance [ 12 ], Euclidean distance [ 3 ], Jaccard Similarity [ 7 ], etc. The most p opular hash function for angular similarity is the sign-random- pro jection hash (SRP-LSH) [ 6 ] whic h generates ran- dom hyperplanes and assigns to a factor the sign of the pro jection of that factor on eac h hyperplane. A more recen t alternative to this called Sup erbit-LSH [ 15 ] orthogonalises the random vectors b efore pro jec- tion. Another v ariation uses l concomitant rank order statistics [ 10 ] instead of signed pro jection to compute an l -ary hash co de. Y et another line of work com- putes hash functions b y constructing spatial partition- ing trees, sp ecifically the PCA-tree [ 27 ] which splits eac h factor at the median along principal eigenv ectors. F or standard hashing metho ds, the usual w a y is to ex- tract relev ant items for eac h user b y computing the Hamming distance with the hash functions of corre- sp onding item factors and returning the closest items. In our setup that is not feasible since that w ould defeat the en tire purp ose of not having to compare against ev- ery item. These methods w ould apply to our setup b y computing exact hash matc hes using tree-based data structures. Ho wev er, each instance of LSH divides fac- tors into regions with rigid b oundaries, whic h tends to thro w aw ay to o man y items 7 , esp ecially for factors at the edges. In contrast, since a geometry aw are sc hema is tuned to each factor separately , our metho d by de- sign also captures similarity with ov erlapping regions and soft b oundaries. Uniformly tessellating the unit sphere deterministi- cally is a hard problem. V arious heuristics [ 16 , 2 , 26 ] exist that use, for example, arguments from physics to find minimum energy configurations for c harges on a sphere. Em b edding p erm utations on the unit sphere is ev en more difficult, see for instance [ 22 ]. How ever, un- lik e our metho ds, all of these tec hniques require com- putationally exp ensive exhaustiv e searc h approac hes for finding the correct tessellation for a given factor, or finding the appropriate p ermutation map. 6 EXPERIMENTS W e p erform exp erimental ev aluation of our pro cedure on b oth synthetic data and the MovieLens100k dataset [ 1 ] consisting of ratings compiled from the MovieLens w ebsite. Using recommendation system terminology , one set of factors will be referred to as user factors, the other set as item factors and the inner product b et ween user and item factors will b e referred to as the rating. F or our metho d, w e feed the factors, after some thresh- olding, to a schema that uses the ternary tessellation of Section 4.1.1 and a parse-tree base d permutation map (describ ed in the supplement) to get sparse rep- resen tations. W e use these representations to extract 7 in our experiments, LSH is b o osted by coalescing all items collected by multiple instances of random hashing Geometry Aw are Mappings for High Dimensional Sparse F actors (a) Histograms of p ercen tage of discarded items ov er users (b) Reco very Accuracy for Mo vieLens Data Figure 3: MovieLens Data: for comparable p ercen tage of discarded items, recov ery accuracy is m uch higher for our metho d compared to baselines (histogram y-axes scaled for uniformit y) exactly those items as would b e extracted b y the in- v erted index data structure applied to our sparse fac- tors. The p erformance is compared against the fol- lo wing baselines- sign-random-pro jection hash (SRP- LSH) [ 6 ], Sup erbit-LSH [ 15 ], Concomitant rank order statistics [ 10 ] and PCA-tree [ 27 ]. The comparison is tw o-fold. First, we compute the reco very accuracy- what prop ortion of relev an t items w as actually recov ered b y each of the ab o ve metho ds after discarding certain items. Next, for eac h of the metho ds, we compute for each user the prop ortion of items that are discarded. The p ercentage of items dis- carded show ed a large v ariance for some of the base- lines, hence we display them as histograms. The sup- plemen tary material also con tains a set of figures that plot reco very accuracy against ac hieved sparsity , as w ell as the mean p ercentage of discarded items across metho ds for synthetic and real data. Note that the p ercentage of items discarded has a di- rect relationship with the speed-up achiev ed- eg, if η prop ortion of items are discarded, size of item list for score computation reduces to (1 − η ) whic h results in a 1 1 − η -fold increase in sp eed. 6.1 Syn thetic Data F or syn thetic data, w e randomly generate factors U and V using the standard normal distribution and con- struct the “rating matrix” R = UV > . W e set the factor matrix Z by concatenating the factors U and V as Z = [ U ; V ]. Performance of differen t metho ds on these factors are ev aluated with resp ect the true rating matrix R . Experiments show that our methods ac hieves sup erior p erformance compared to the base- lines, b y obtaining both higher percentage of discarded items (figure 2a ) as w ell as higher accuracy (figure 2b ). With close to 80% of the items discarded on an a ver- age, our metho d ac hieves a nearly five-fold sp eed-up compared to the standard retriev al technique. 6.2 Mo vieLens Data W e use the Mo vieLens100k dataset to learn low dimen- sional factors U and V for users and items resp ectively . The exact same pro cedure as for synthetic data is then rep eated with the learned user and item factors. Ex- p erimen ts show that for comparable p erformance in p ercen tage of discarded items (figure 3a ), our metho d ac hieves m uch higher reco very accuracy (figure 3b ) as compared to the baselines. With around 70% items discarded on a v erage, our metho d w ould result in o ver three-fold sp eed-up in retriev al. 7 CONCLUSION AND FUTURE W ORK In this man uscript we presented a nov el framew ork that exploits structural prop erties of sparse v ectors to significan tly reduce the run time computational cost of factorisation mo dels. W e developed techniques that use geometry aw are permutation maps on a tessellated unit sphere to obtain high dimensional sparse em b ed- dings for factors with sparsity patterns related to angu- lar closeness of the original factors. W e also provided deterministic and efficien t realisations for the frame- w ork. F uture work for this would inv olv e the design of b etter tessellation and sparse mapping schema for this framework and theoretical analyses of the same. Ac knowledgemen ts This work was done while Avradeep Bhowmik and Nathan Liu were at Y aho o! Labs, Sunn yv ale, CA. Bho wmik et al References [1] Mo vielens 100k dataset. Gr oupL ens R ese ar ch . [2] E. L. Altsch uler, T. J. Williams, E. R. Ratner, R. Tipton, R. Stong, F. Dowla, and F. W ooten. P ossible global minimum lattice configurations for thomson’s problem of charges on a sphere. Phys- ic al R eview L etters , 78(14):2681, 1997. [3] A. Andoni and P . Indyk. Near-optimal hash- ing algorithms for approximate nearest neigh- b or in high dimensions. In 47th Annual IEEE Symp osium on F oundations of Computer Scienc e (F OCS) , pages 459–468. IEEE, 2006. [4] V. N. Anh and A. Moffat. Inv erted index com- pression using word-aligned binary co des. Infor- mation R etrieval , 8(1):151–166, 2005. [5] R. B. Bapat and T. E. Ragha v an. Nonne gative matric es and applic ations , v olume 64. Cambridge Univ ersity Press, 1997. [6] M. S. Charik ar. Similarity estimation techniques from rounding algorithms. In Pr o c e e dings of the thiry-fourth annual ACM symp osium on The ory of c omputing , pages 380–388. ACM, 2002. [7] O. Chum, J. Philbin, A. Zisserman, et al. Near duplicate image detection: min-hash and tf-idf w eighting. In BMV C , volume 810, pages 812–815, 2008. [8] J. Co ok. Rational form ulae for the pro duction of a spherically symmetric probabilit y distribution. Mathematics of Computation , 11(58):81–82, 1957. [9] P . Diaconis and R. L. Graham. Sp earman’s fo otrule as a measure of disarray . Journal of the R oyal Statistic al So ciety. Series B (Metho dolo gi- c al) , pages 262–268, 1977. [10] K. Eshghi and S. Ra jaram. Lo calit y sensitive hash functions based on concomitan t rank order statis- tics. In Pr o c e e dings of the 14th ACM SIGKDD international c onfer enc e on Know le dge disc overy and data mining , pages 221–229. ACM, 2008. [11] E. Gabrilo vich and S. Marko vitc h. Computing se- man tic relatedness using wikip edia-based explicit seman tic analysis. In IJCAI , volume 7, pages 1606–1611, 2007. [12] A. Gionis, P . Indyk, R. Mot wani, et al. Similarity searc h in high dimensions via hashing. In VLDB , v olume 99, pages 518–529, 1999. [13] J. Hicks and R. Wheeling. An efficient method for generating uniformly distributed p oints on the surface of an n-dimensional sphere. Communic a- tions of the ACM , 2(4):17–19, 1959. [14] P . Indyk and R. Motw ani. Approximate nearest neigh b ors: tow ards removing the curse of dimen- sionalit y . In Pr o c e e dings of the thirtieth annual A CM symp osium on The ory of c omputing , pages 604–613. ACM, 1998. [15] J. Ji, J. Li, S. Y an, B. Zhang, and Q. Tian. Super- bit locality-sensitiv e hashing. In A dvanc es in Neu- r al Information Pr o c essing Systems , pages 108– 116, 2012. [16] A. Katanforoush and M. Shahshahani. Distribut- ing p oints on the sphere, i. Exp erimental Mathe- matics , 12(2):199–209, 2003. [17] Y. Koren, R. Bell, and C. V olinsky . Matrix fac- torization tec hniques for recommender systems. Computer , (8):30–37, 2009. [18] J. Mairal, F. Bach, J. P once, and G. Sapiro. On- line learning for matrix factorization and sparse co ding. The Journal of Machine L e arning R e- se ar ch , 11:19–60, 2010. [19] G. Marsaglia et al. Choosing a p oint from the surface of a sphere. The Annals of Mathematic al Statistics , 43(2):645–646, 1972. [20] M. E. Muller. A note on a method for generating p oin ts uniformly on n-dimensional spheres. Com- munic ations of the ACM , 2(4):19–20, 1959. [21] J. Newman. V arious techniques used in connec- tion with random digits. NBS Appl. Math. Series , 36:12, 1951. [22] S. M. Plis, T. Lane, and V. D. Calhoun. Direc- tional statistics on p ermutations. arXiv pr eprint arXiv:1007.2450 , 2010. [23] A. Shash ua and T. Hazan. Non-negative tensor factorization with applications to statistics and computer vision. In Pr o c e e dings of the 22nd inter- national c onfer enc e on Machine le arning , pages 792–799. ACM, 2005. [24] K. T ak euchi, R. T omiok a, K. Ishiguro, A. Kim ura, and H. Saw ada. Non-negative multiple tensor fac- torization. In Data Mining (ICDM), 2013 IEEE 13th International Confer enc e on , pages 1199– 1204. IEEE, 2013. [25] C. T eflioudi, F. Mak ari, and R. Gemulla. Dis- tributed matrix completion. In Data Mining (ICDM), 2012 IEEE 12th International Confer- enc e on , pages 655–664. IEEE, 2012. [26] M. T egmark. An icosahedron-based metho d for pixelizing the celestial sphere. The Astr ophysic al Journal , 470:L81, 1996. [27] N. V erma, S. Kp otufe, and S. Dasgupta. Which spatial partition trees are adaptive to intrinsic di- mension? In Pr o c e e dings of the twenty-fifth c on- fer enc e on unc ertainty in artificial intel ligenc e , pages 565–574. AUAI Press, 2009. Geometry Aw are Mappings for High Dimensional Sparse F actors SUPPLEMENT A PR OOFS Pro of of Lemma 1 Pr o of. Using standard Euclidean distance for pro jec- tion of an y factor z on to the tessellating v ectors Γ, recall by definition we ha ve arg min a ∈ Γ d ( a , z ) = arg min a ∈ Γ 1 − a > z k a k 2 k z k 2 = arg max a ∈ Γ a > z ( ∵ k a k 2 = 1) = arg min ˜ a ∈A 1 − ˜ a > z k ˜ a k 2 k z k 2 Supp ose a has t non-zero elements with the corre- sp onding indices I a ⊂ { 1 , 2 , · · · k } with | I a | = t . Clearly , the corresp onding unnormalised ˜ a would also ha ve to hav e had t non-zero elements, eac h of them ± 1, and therefore k ˜ a k 2 = √ t . Therefore, we ha ve a > z = P j ∈ I a sig n ( a j ) z j √ t Clearly , for any fixed t , the maximiser of the numerator is an a such that eac h a j has the same sign as z j and a j is supported (non-zero) at the top t elements (by absolute v alue) of z . Then, we ha ve max a ∈ Γ a > z = max t max a : | I a | = t P j ∈ I a sig n ( a j ) z j √ t = max t z t s where z s is as defined in Algorithm 2 of the main man uscript. This completes the pro of of correctness of the pro jection op erator. Pro of of Lemma 2 The steps to compute the appro ximately closest tessel- lation vector ov er Γ D are given in Algorithm 3 . The pro of given below is not the only one possible, other (p ossibly tigh ter) b ounds can b e obtained by using differen t pro of tec hniques and differen t algebraic ma- nipulations of the quan tities in volv ed. Pr o of. Note that for any scalar s with | s | ≤ 1, there exists a scalar h with | h | ≤ D such that | s − h D | < 1 D . Therefore, since each ˜ a j is a m ultiple of ± 1 D , for any z ∈ S k , there exists ˜ a ∈ A D = B k D \ { 0 } k suc h that k z − ˜ a k = p P i ( z i − ˜ a i ) 2 ≤ √ k D . F or any vector x ∈ S k , denote its pro jection on to A D as A D ( x ) = arg min ˜ a ∈A D k ˜ a − x k 2 Clearly , b y the preceding discussion, k x − A D ( x ) k 2 ≤ √ k D (4) Moreo ver, A D ( x ) can be obtained by follo wing steps 2 to 13 in TessVector - D ( x , D ) as detailed in Algo- rithm 3 . Supp ose for a factor z , the optimal pro jection on Γ D is a ∗ z = arg min a ∈ Γ D d ( a , z ) = arg min a ∈ Γ D 1 2 k a − z k 2 2 = arg min a ∈ Γ D k a − z k 2 Supp ose the pro jection obtained from TessVector - D ( z , D ) is a z . Then w e hav e, k z − a ∗ z k 2 ≤ k z − a z k (5) No w, w e hav e k a z − a ∗ z k ≤ k a z − z k + k z − a ∗ z k [∆ ineq] (6) ≤ 2 k a z − z k [b y 5 ] (7) ≤ 2 ( k a z − A D ( z ) k + kA D ( z ) − z k ) [∆ ineq] (8) Note that a z = A D ( z ) kA D ( z ) k 2 (9) Therefore, k a z − A D ( z ) k = k A D ( z ) kA D ( z ) k 2 − A D ( z ) k = k 1 − 1 kA D ( z ) k 2 A D ( z ) k = |kA D ( z ) k 2 − 1 | F urthermore, b y triangle inequality kA D ( z ) k 2 ≤ kA D ( z ) − z k 2 + k z k = kA D ( z ) − z k 2 + 1 Also, by triangle inequality , kA D ( z ) k 2 ≥ k z k − k z − A D ( z ) k 2 = 1 − kA D ( z ) − z k 2 Therefore, −kA D ( z ) − z k 2 ≤ kA D ( z ) k 2 − 1 ≤ kA D ( z ) − z k 2 Bho wmik et al Hence, |kA D ( z ) k 2 − 1 | ≤ kA D ( z ) − z k 2 (10) Finally , by combining equations 8 and 10 with equa- tion 4 , we get that k a z − a ∗ z k 2 ∼ O ( √ k D ). Since d ( a z , a ∗ z ) ∝ k a z − a ∗ z k 2 2 , we ha ve our result d ( a z , a ∗ z ) ∼ O k D 2 Moreo ver, the time complexity of Algorithm 3 is O ( k ) and eac h step from 4 to 12 can be computed in parallel for each j and each z . Also, algorithm 3 requires no explicit storage of the tessellating set Γ D . This com- pletes the pro of. Algorithm 3 Region Sp ecification on Γ D 1: pro cedure TessVector- D ( z , D ) 2: initialise ˜ a z to all zeros 3: for each z ∈ Z do 4: for each j ∈ { 1 , 2 , 3 , · · · k } do 5: compute a + = | D z j − d D z j e| 6: compute a − = | D z j − b D z j c| 7: if a + ≤ a − then 8: set ˜ a j z = d Dz j e D 9: else 10: set ˜ a j z = b Dz j c D 11: end if 12: end for 13: end for 14: normalise to get a z = ˜ a z k ˜ a z k 2 15: return a z 16: end pro cedure B FUR THER DISCUSSION B.1 Uniform T essellation A k ey consideration while designing a tessellation sc hema on the unit sphere is whether the tessellation needs to b e uniform or non-uniform o v er the surface of the unit sphere. There is no one wa y to capture the notion of “uniformit y” in the con text of a tessella- tion schema. A few example conditions could be that eac h tessellating vector should be equidistant from the closest tessellating v ector, or b y symmetry should hav e the same num b er of closest tessellating vectors, or the diameter of each tile (distance betw een farthest p oints within the same tile) should b e the same for eac h tile. But whichev er wa y “uniformity” is defined, as a gen- eral scheme, a uniform tessellation would make intu- itiv e sense b ecause it captures the relev an t locality prop erties of an y set of factors irresp ective of their distribution. How ev er, in many instances a uniform tessellation may be o verkill, and esp ecially for clus- tered data, a non-uniform tessellation might be more appropriate from efficiency considerations. In partic- ular, a uniform tessellation could be made into a non- uniform tessellation simply b y dropping some of the tessellating vectors. The directional tessellating set A on a ternary base set B do es not uniformly tessellate the unit sphere. This is b ecause for eac h tessellating v ector in Γ, the distance from the nearest tessellating vector dep ends on the num b er of non-zeros in the v ector. In particular, the nearest neighbour to a vector a i is ev ery vector a j suc h that the unnormalised vectors ˜ a i and ˜ a j differ by a Euclidian distance of 1 in the un- normalised space. That is, every nearest neigh b our to a v ector a i can be found b y replacing a single element in the unnormalised version of the v ector ˜ a i in the fol- lo wing wa y . First, obtain ˜ a j b y replacing a single 1 or -1 in ˜ a i b y a 0, or replace a single 0 b y either a 1 or a -1. This is then re-normalised to get the corresp onding a j . The proof of the abov e statemen t is the follo wing. First, clearly the nearest neighbour to ev ery a i m ust b elong to the same orthan t as a i . Supp ose a j b e- longs to the set of nearest neigh b ours. Therefore, sig n ( a ι i ) sig n ( a ι j ) ≥ 0 for every ι = 1 , 2 , · · · k . There- fore, without loss of generalit y , assume that a i lies in the non-negative orthan t, a ι j ≥ 0 ∀ ι . Supp ose a i has t non-zero elemen ts, and a j has t + s non-zero elements, with t > 0 , s 6 = 0. Then, the angular distance b etw een a i and a j is d ( a i , a j ) = 1 − q t t + s if s > 0 1 − q t − s t if s < 0 Clearly , the minimum distance is attained for an y t b y setting s = 1. F ollowing this, we see that the distance b et ween closest neigh b ours a i , a j is d ( a i , a j ) = 1 − q t t +1 . Therefore, the distance betw een closest neigh b ours for a tessellat- ing vector dep ends on the n umber of non-zero elemen ts in the vector. In particular, the set A is more densely pac ked with vectors oriented to wards the “cen tre” of eac h orthant as opp osed to vectors along the axes or along any lo wer dimensional subspaces formed from subsets of the axes. As men tioned in the main manuscript, obtaining uni- form tessellations deterministically is a challenging task and heuristics [ 16 , 2 , 26 ] m ust be resorted to. Geometry Aw are Mappings for High Dimensional Sparse F actors (a) a verage p ercentage of discarded items for Syn thetic Data (b) av erage percentage of discarded items for MovieLens Figure 4: Mean p ercentage of discarded items across users for (a) Syn thetic Data (b) MovieLens Data (a) Reco very Accuracy (b) Reco very Accuracy v ersus Sparsit y Figure 5: Plot for Recov ery Accuracy versus Sparsity Ac hieved (a) Syn thetic Data (b) MovieLens Data B.2 P arse T ree Constructions In this section w e describ e some examples of parse- tree constructions for the p erm utation mapping step, in particular the parse tree used in the exp eriments in the main manuscript. Note that computing the per- m utation map pro ceeds in tw o steps- (i) reading a z at time j as a sequence of δ characters at a time as ˜ a j δ = [ ˜ a j − δ , · · · ˜ a j ], and (ii) marking the next non-zero index via a counter τ t on φ ( · ) as a function of τ j − 1 and ˜ a δ j as τ j = f ( τ j − 1 ; ˜ a j δ ). A k ey desideratum for our mapping sc heme is that for an y tw o a , a 0 at an y step τ j = τ 0 j if and only if [ a j − t , · · · a j ] = [ a 0 j − t , · · · a 0 j ] for some t 0 ≥ δ . This is useful in preven ting “acciden tal” o verlapping sparsity , so that the same sparsit y pattern is not obtained acci- den tally via t wo entirely different set of sliding windo w c haracters read on a and a 0 . It is immediately clear that the one-hot enco ding sat- isfies this prop erty with t 0 = δ = 1. Another simple sc heme (and one that we used in our exp eriments) is the following. Consider a sliding windo w of size δ = 1. Supp ose after j − 1 steps, the coun ter is at position τ j − 1 . Shift the counter to position τ j dep ending on the v alue of curren tly read a j as follows- τ j = k j if a j = 1 τ j − 1 + 1 if a j = 0 k ( k + j ) if a j = − 1 The dimensionalit y increase required is p ∼ O ( k 2 ), ho wev er, with the inv erted index representation, we only require O ( k l og k ) storage space complexity . Man y other parse-tree metho ds are p ossible. In par- ticular, a straightforw ard generalisation of the one-hot sc heme described in the manuscript w ould obtain a class of metho ds that inv olve a one-hot enco ding on Bho wmik et al a D -ary tessellation with a δ -parse-tree which has D δ leaf no des. F or this sc hema, for an y tw o a , a 0 w e shall ha ve the corresp onding counters τ j and τ 0 l at time j and l resp ectively to b e equal τ j = τ 0 l if and only if j = l and ˜ a δ j = ˜ a 0 δ l . C ADDITIONAL PLOTS W e show some additional plots to augmen t the exp er- imen tal results given in the main manuscript. Figure 4a and 4b respectively sho w the av erage sparsit y lev els obtained across all users for differen t metho ds men- tioned in this mansucript. W e also show error bars to giv e an idea of the v ariance. Figure 5a and 5b show a plot of recov ery accuracy plot- ted against a v erage sparsit y achiev ed across all users for our metho d.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment