CNN based texture synthesize with Semantic segment
Deep learning algorithm display powerful ability in Computer Vision area, in recent year, the CNN has been applied to solve problems in the subarea of Image-generating, which has been widely applied in areas such as photo editing, image design, computer animation, real-time rendering for large scale of scenes and for visual effects in movies. However in the texture synthesize procedure. The state-of-art CNN can not capture the spatial location of texture in image, lead to significant distortion after texture synthesize, we propose a new way to generating-image by adding the semantic segment step with deep learning algorithm as Pre-Processing and analyze the outcome.
💡 Research Summary
**
The paper addresses a critical shortcoming of contemporary convolutional neural network (CNN)–based texture synthesis: the loss of spatial coherence and object shape when a single texture is applied uniformly across an entire image. To mitigate this, the authors propose inserting a semantic segmentation step before the synthesis stage, thereby separating foreground objects from background and treating each region independently.
The authors first review traditional texture synthesis approaches, distinguishing between procedural methods (e.g., reaction‑diffusion, cell‑division models) and sample‑based statistical methods (e.g., Markov Random Fields, wavelet‑based models, Efros‑Freeman quilting). They note that recent deep‑learning techniques, particularly those using Gram‑matrix representations of VGG‑based feature maps (Gatys et al., 2015), have achieved impressive style transfer results but still suffer from severe distortion when applied to complex scenes because they ignore region‑specific spatial information.
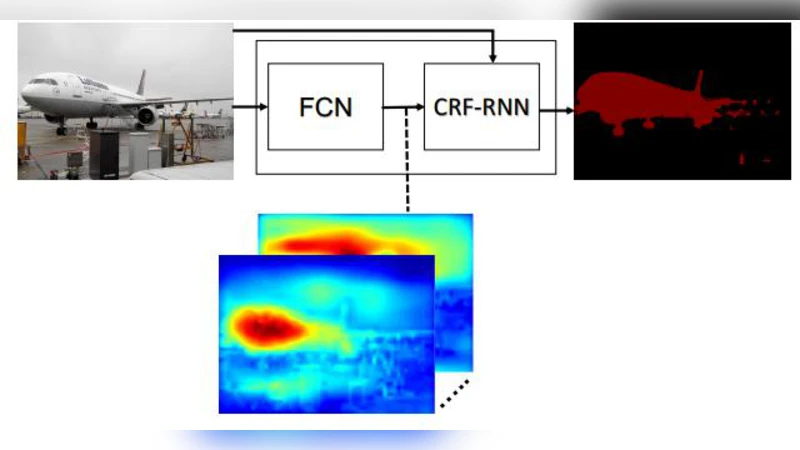
For semantic segmentation, the paper evaluates four state‑of‑the‑art models on the PASCAL VOC 2012 validation set: FCN‑8s (62.2 % mean IU), DeepLab (71.6 %), DeconvNet (72.5 %), and CRF‑RNN (74.7 %). The CRF‑RNN architecture, which couples a fully convolutional network (providing unary potentials) with a recurrent conditional random field (providing pairwise potentials), yields the highest accuracy and sharp boundary delineation. Consequently, the authors adopt CRF‑RNN as their segmentation engine.
The proposed pipeline proceeds as follows:
- Segmentation – The input image is processed by the CRF‑RNN model, producing a pixel‑wise label map that separates foreground entities (people, animals, etc.) from background.
- Region Extraction – Foreground and background are extracted as separate images.
- Feature Extraction – Each region is fed through a VGG‑19 network. For each convolutional layer (l), the activations are reshaped into a matrix (F^l). The Gram matrix (G^l = F^l (F^l)^T) captures the pairwise correlations of feature maps, discarding explicit spatial layout while preserving texture statistics.
- Texture Synthesis – Instead of initializing with white noise, the authors initialize the optimization with the original region image to preserve coarse structure. Using gradient descent, they minimize a loss that is the weighted sum of squared differences between the Gram matrices of the target style image and the generated image across selected layers. The gradient of this loss with respect to the pixel values is computed via standard back‑propagation.
The authors conduct experiments using a Picasso painting as the style source. When the entire image is stylized without segmentation, fine details of the foreground objects are heavily blurred, and the overall composition suffers from spatial inconsistency. By contrast, applying the style separately to the foreground and background preserves object contours and yields a more faithful artistic rendition. The paper also compares network architectures for style transfer, concluding that VGG‑19 outperforms AlexNet and GoogLeNet because its uniform 3 × 3 kernels retain more fine‑grained information.
In the conclusion, the authors claim three primary contributions: (1) introducing semantic segmentation as a pre‑processing step to reduce spatial distortion in CNN‑based texture synthesis; (2) demonstrating that CRF‑RNN segmentation improves boundary preservation during style transfer; and (3) validating that VGG‑19’s deeper, finer‑scale feature hierarchy yields superior texture fidelity. They acknowledge current limitations, such as the modest size of experimental datasets and the absence of an automated texture‑matching database. Future work is outlined to include building a large, annotated texture repository, developing intelligent matching algorithms, and integrating the entire pipeline into a real‑time AI‑driven painting system.
Comments & Academic Discussion
Loading comments...
Leave a Comment