Alternating optimization method based on nonnegative matrix factorizations for deep neural networks
The backpropagation algorithm for calculating gradients has been widely used in computation of weights for deep neural networks (DNNs). This method requires derivatives of objective functions and has some difficulties finding appropriate parameters s…
Authors: Tetsuya Sakurai, Akira Imakura, Yuto Inoue
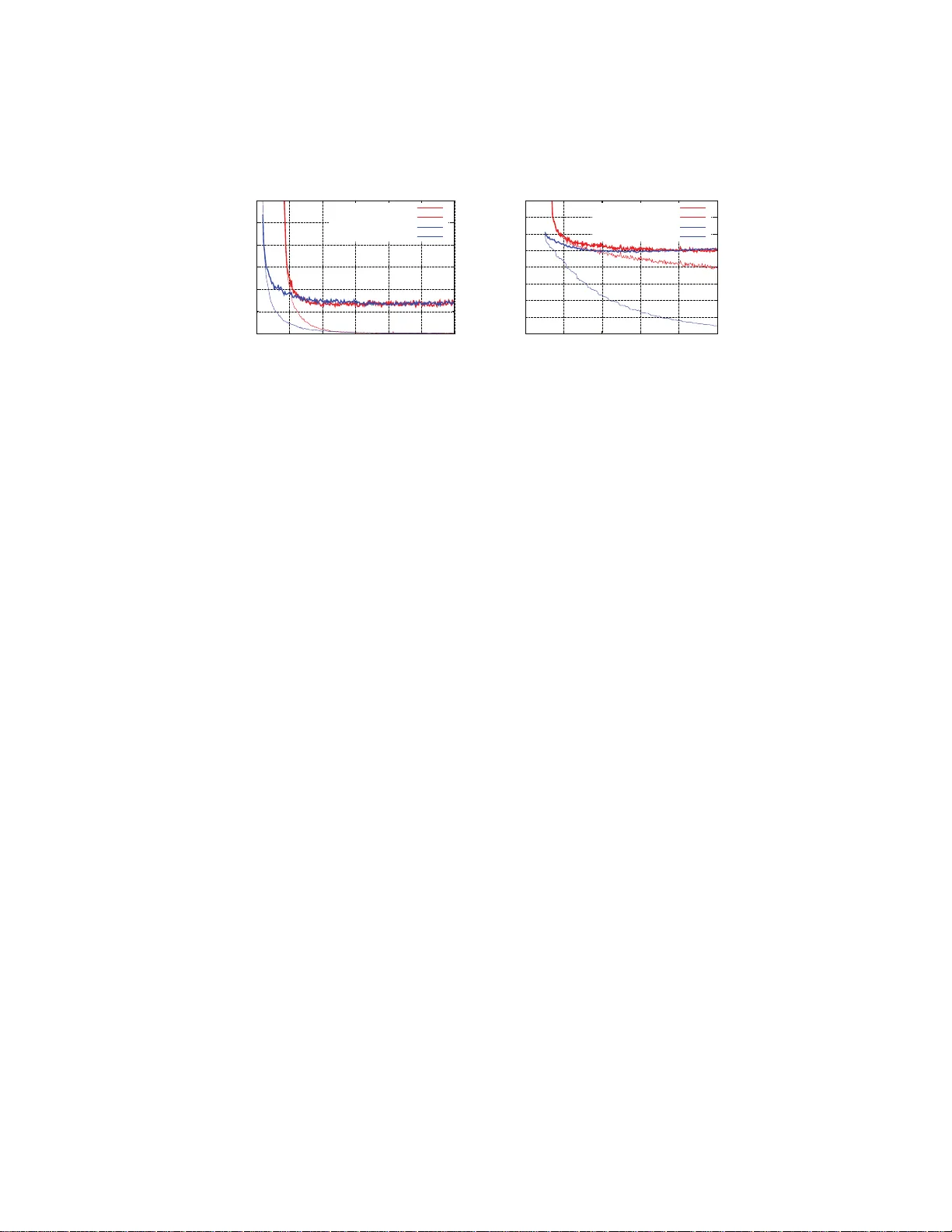
Alternating optimization metho d based on nonnegativ e matrix factorizations for deep neural net w orks T etsuya Sakurai 1 , 2 , Akira Imakura 1 , Y uto Inoue 1 , and Y asunori F utamura 1 1 Department o f Computer Science, Universit y of Tsukuba 2 JST/CREST Abstract. The backpropagati on algorithm for calculating gradients has b een widely used in computation of w eigh ts for d eep neural netw orks (DNNs). This method req u ires deriv atives of ob jective functions and has some difficulties finding appropriate parameters such as learning rate. In this pap er, we propose a no vel approac h for computing w eigh t matrices of fully-connected D NNs by using t wo types of semi-nonnegativ e matrix factorizatio ns (semi-NMFs). In this metho d, optimization pro cesses are p erf ormed by calculating wei ght m atrices alternately , and bac k p ropag a- tion (BP) is not u sed. W e also present a method to calculate stac ked autoen coder using a N MF. The output results of the auto encoder are used as pre-training data for DN N s. The experimental results sh o w that our method using three types of NMFs attains simil ar error rates to the conv entional DNNs with BP . 1 In t roduction Deep neur al netw o rks (DNNs) attr acted a great dea l of a tten tion for their high efficiency in v ar ious fields, such as sp eec h recognition, imag e reco gnition, ob- ject detection, ma terials discovery . By using a backpropagation (BP) technique prop osed by Rumelhart, et al. [15], computational per fo rmance is improv ed for training m ultilayer neural net works. Ho wever, learning often tak e s a long time to conv e rge, and it may fall in to a lo cal minim um. Bengio, et al. [1] prop osed a metho d to improv e gener al p erformance by pre-training with a n autoenco der. Moreov er, selection o f appro priate learning rates [12] and restr iction of weigh ts as drop out [16] have also used to minimize the e x pected er ror. Hinton, et al. discussed initia lization of w e ig h ts in [6]. Neural netw orks have v ar iations suc h as fully- connected netw or ks, c on volu- tional net works and r ecurren t netw orks. LeCun, et al. [12] show ed that c on vo- lutional neura l netw orks attain high efficie nc y for image reco gnition. In DNNs, activ ation functions are used to attain nonlinear pr operties. Rece ntly , the recti- fied linear function (ReLU) [5, 13] has often b een used. F eedforward neural net works a r e computed by mult iplying weigh t matr ices and input matrices. Thus, the ma in computatio ns a r e matrix–matrix multip li- cations (GEMM), and acceler ators suc h as GPUs are employed to obtain high 2 per formance [2]. Ho wev er, a lar g e computational cos t of neural netw o rks is s till a pro blem. In this pa per, w e prop ose a nov el computing metho d for fully-connected DNNs that uses t wo types of semi-nonnega tiv e matrix factorizatio ns (semi- NMFs). In this metho d, optimization pro cesses are p erformed by calculating weigh t matrices alternately , and BP is not used. W e also present a metho d to calculate a stack ed autoe nco der using a NMF [11, 14]. The output res ults of the auto encoder are used as pre-training data for DNNs. In the pre s en ted method, co mputations are represented by matrix– matrix computations, and accelera tors suc h as GP Us and MICs can b e employed like in B P computations . In B P computations, mini-batches are used to av o id s ta g- nations o f the optimizatio n precess. The use of small mini-batch sizes decreases matrix siz es a nd gains reductions in computations. The present ed metho d also uses partitione d matrices; howev er, the matr ix size is la rger than that of c on- ven tional BP , and we expe c t high perfo rmance. This paper is organized a s follows. I n Sectio n 2, we review the co n ven tio nal metho d of computing DNNs. In Section 3, w e prese nt a metho d for computing weigh ts in DNNs using tw o types of s emi-NMFs. W e also present a method to calculate a stack ed auto enco der using NMF. In Section 4, w e show some exper- imen tal results of our pro posed approach. Sectio n 5 pr esen ts our co nclusions. W e use MA TLAB colon notations throughout. Moreover, let A = { a ij } ∈ R m × n , then A ≥ 0 denotes that all en tr ies are nonnegative: a ij ≥ 0. 2 Computation of deep neural net works Let n in , n out , m b e sizes of input and output units and the training da ta, resp ec- tively . Moreov er , let X ∈ R n in × m and Y ∈ R n out × m be input and output data. Using a weigh t matrix W ∈ R n out × n in and a bias vector b ∈ R n out , the ob jective function o f one layer of neural net works can b e wr itt en as E ( W, b , X , Y ) = D Y , f ( W X + be T ) + h ( W , b ) , where D ( · , · ) is a divergence function, e = [1 , 1 , . . . , 1] T ∈ R m , f ( U ) is an a c tiv a- tion function and h ( W, b ) is a r egularization ter m. There a re several activ a tion functions such as sigmoid functions like the log istic function and the hyperb olic tangent function. Recently , r ectified linear unit (ReLU) has b een wide ly used. The o b jectiv e function of DNNs with d − 1 hidden units of siz e n i , i = 1 , 2 , . . . , d − 1 is written as E ( W 1 , . . . , W d , b 1 , . . . , b d , X , Y ) = D Y , W d f ( W d − 1 · · · f ( W 1 X + b 1 e T ) · · · + b d − 1 e T ) + b d e T + h ( W 1 , . . . , W d , b 1 , . . . , b d ) . (1) Here, W i ∈ R n i × n i − 1 , b i ∈ R n i − 1 , n 0 = n in , n d = n out . BP algor ithms, whic h are based on the gradient desce n t method using deriv atives, are one of the most standard algorithms used to minimize the ob jective function. 3 Algorithm 1 T he basic concept of the propo sed method 1: S et initial guesses W (0) 1 , W (0) 2 , . . . , W (0) d 2: for k = 1 , 2 , . . . do: 3: for i = d, d − 1 , . . . , 1 do: 4: Minimize (approx.) E ( k ) i ( W i , X, Y ) for W i with an initial guess W ( k − 1) i , and get W ( k ) i 5: end for 6: e nd for 3 An alternating optimization metho d based on nonnegativ e matrix factorization In this pap er, we consider solving the following minimization pr oblem min W 1 ,...,W d E ( W 1 , . . . , W d , X , Y ) , (2) where the ob jective function simplifies the ob jective function (1) us ing the sq ua re error of DNNs and is defined by E ( W 1 , . . . , W d , X , Y ) := 1 2 k Y − W d f ( W d − 1 · · · f ( W 1 X ) · · · ) k 2 F , (3) where k · k F is the F rob enius norm. Her e, the activ ation function f ( U ) is se t as ReLU. The basic co ncept of our algo rithm to so lv e (2) is an alternating optimization that (approximately) optimizes ea c h weigh t matrix W i for i = d, d − 1 , . . . , 1, one by one. Let W (0) 1 , W (0) 2 , . . . , W (0) d be initial guesses of W 1 , . . . , W d , resp ectiv ely . An a utoenco der to set the initial guesses will be discussed in Sectio n 4. In each iteration k , we also define ob jective functions E ( k ) i ( W i , X , Y ) := E ( W ( k − 1) 1 , . . . , W ( k − 1) i − 1 , W i , W ( k ) i +1 , . . . , W ( k ) d , X , Y ) , as for the i -th weigh t matrix W i . Then, we (a ppro x ima tely) solve the minimiza- tion problems W ( k ) i = ar g min W i E ( k ) i ( W i , X , Y ) for i = d, d − 1 , . . . , 1 . The basic concept o f our prop osed method is shown in Algorithm 1 . Let matrice s Z ( k ) i ∈ R n i × m be defined as Z ( k ) 0 := X , Z ( k ) i := f ( W ( k ) i f ( W ( k ) i − 1 · · · f ( W ( k ) 1 X ) · · · )) , i = 1 , 2 , . . . , d − 1 . Then, in what follows, w e derive our alternating optimization algo rithm using semi-NMF [3] and nonlinear semi-NMF. 4 3.1 Optimization for W d using semi-NM F Using the matrix Z ( k − 1) d − 1 , the ob jective function for the w eight matrix W d is rewritten a s E ( k ) d ( W d , X , Y ) = 1 2 k Y − W d Z ( k − 1) d − 1 k 2 F . Here, we note that Z ( k − 1) d − 1 ≥ 0 fr o m the definition of Z ( k − 1) i . Ther e fo re, w e can o btain W ( k ) d and b Z ( k ) d − 1 by (approximately) solving nonnegative constraint minimization problem of the form [ W ( k ) d , b Z ( k ) d − 1 ] = a r g min W d ,Z d − 1 k Y − W d Z d − 1 k F , s.t. Z d − 1 ≥ 0 , (4) using initia l guesses W ( k − 1) d , Z ( k − 1) d − 1 . This minimization problem is k nown a s semi-NMF. 3.2 Optimization for W i , i = d − 1 , . . . , 1 using nonlin ear s emi-NMF F rom the definition of Z ( k − 1) i , w e expec t b Z ( k ) d − 1 ≈ f ( W d − 1 Z d − 2 ) (5) to minimize the ob jective function (3). Then, w e consider (approximately) s olv- ing the minimization problem [ W ( k ) i , b Z ( k ) i − 1 ] = a r g min W i ,Z i − 1 k b Z ( k ) i − f ( W i Z i − 1 ) k F , s.t. Z i − 1 ≥ 0 (6) for W i with i = d − 1 , d − 2 , . . . , 1. This minimization proble m (6 ) is a nonnegative constraint minimization pro blem like (4). How ever, (6) has a nonlinear a ctiv ation function. In this pape r , w e call this pr oblem nonlinear semi-NMF. In order to so lv e this nonlinear semi-NMF, w e in tro duce an alternating min- imization a lgorithm that minimizes no nlinea r least squar es problems min W i k b Z ( k ) i − f ( W i Z ( k − 1) i − 1 ) k F (7) and min Z i − 1 ≥ 0 k b Z ( k ) i − f ( W ( k ) i Z i − 1 ) k F , (8) one by one. Here, we note that (8) has a nonnega tiv e constr ain t on Z i . W e also note that, fo r i = 1 , w e do not requir e a s olution of (8), because Z 0 = X . The nonlinear least squares pr oblems (7) and (8) are solved b y stationa ry iteration- like methods as shown in Algorithms 2 and 3, wher e A † is a pseudo-inv er se of A . I n practice, the pseudo-inv er se of A is approximated using a lo w-rank approximation of A . 5 Algorithm 2 An iter ation metho d for solving nonlinear least s quares min X k B − f ( X A ) k F 1: S et initial guess X 0 and parameter ω 2: for s = 0 , 1 , . . . do: 3: R s = B − f ( X s A ) 4: X s +1 = X s + ω R s A † 5: e nd for Algorithm 3 An iteration method for solving no nneg ativ e c o nstrain nonlinear least s q uares min X ≥ 0 k B − f ( AX ) k F 1: S et initial guess X 0 and parameter ω 2: for s = 0 , 1 , . . . do: 3: R s = B − f ( AX s ) 4: X s +1 = f ( X s + ω A † R s ) 5: e nd for 3.3 An alternating opti mization metho d Using semi-NMF (4) and nonlinear semi-NMF (5 ), the algo rithm o f the pro- po sed metho d is summarize d in Alg orithm 4. In pr actice, the input data X is approximated using a low-rank approximation based on the s ingular v alue decomp osition: X = [ U 1 , U 2 ] Σ 1 Σ 2 V T 1 V T 2 ≈ U 1 Σ 1 V T 1 . Here, we assume that all hidden units have almost the same size: n ≈ n i , then the c o mputational cost of the prop osed method is O ( mn 2 + dn 3 ). The prop osed metho d can also use the mini-batch technique. Let X ℓ := X (: , J ℓ ) b e a submatr ix of the input data X co rrespo nding to each mini-batch, where J ℓ is the index set in the mini-batch. Then, in order to use the mini-batch techn ique for the pr oposed method, we need to compute the low-rank a ppro x - imation o f X ℓ ≈ U ℓ, 1 Σ ℓ, 1 V T ℓ, 1 , in each iteration. W e can reduce the re q uired computational cost b y reusing the results of the lo w- rank approximation of X as follows: X (: , J ℓ ) ≈ U ℓ, 1 Σ ℓ, 1 V T ℓ, 1 ≈ U 1 Σ 1 V 1 ( J ℓ , :) T . Other impro vemen t techniques used for BP are also exp ected to improve the per formance of the prop osed metho d. 4 An alternating optimization-based stac ked auto enco de r using NMF In this section, we prop ose an alternating optimization- based stacked auto en- co der using NMF for computing initial g uesses W (0) i of the prop osed metho d 6 Algorithm 4 A prop osed metho d 1: S et initial guess W (0) 1 , W (0) 2 , . . . , W (0) d 2: for k = 1 , 2 , . . . do: 3: Solve (approx.) semi-N MF (4 ) with initial guesses W ( k − 1) d , Z ( k − 1) d − 1 and get W ( k ) d , b Z ( k ) d − 1 4: for i = d − 1 , . . . , 2 do: 5: Solve (approx.) n onlinea r LSQ (7) by A lg orithm 2 with an initial guess W ( k − 1) i , and get W ( k ) i 6: Solve (approx.) n onnegativ e constrain nonlinear LS Q (8) by A lg orithm 3 with an initial guess Z ( k − 1) i − 1 , and get b Z ( k ) i − 1 7: end for 8: Solve (approx.) n onlinea r LSQ (7) for i = 1 by A lg orithm 2 with an initial guess W ( k − 1) 1 , and get W ( k ) 1 9: Set Z ( k ) i for i = 1 , 2 , . . . , d − 1 10: end for Algorithm 5 A prop osed sta cked a utoenco der 1: for i = 1 , 2 , . . . , d − 1 do: 2: Set initial guess f W (0) i , Z (0) i 3: for k = 1 , 2 , . . . , iter max do: 4: Solve (approx.) NMF (9) with initial guesses f W ( k − 1) i , Z ( k − 1) i , and get f W ( k ) i , b Z ( k ) i 5: Solve (approx.) n onlinea r LSQ min W i k b Z ( k ) i − f ( W i Z i − 1 ) k F by Algorithm 2 with initial guess W ( k − 1) i , and get W ( k ) i 6: Set Z ( k ) i = f ( W ( k ) i Z i − 1 ) 7: end for 8: e nd for (Algorithm 4). Let b Z 0 = X . Then, for the stack ed auto encoder, w e compute the initial guesses W (0) i by (approximately) minimizing min W i , f W i k b Z i − 1 − f W i f ( W i Z i − 1 ) k F for i = 1 , 2 , . . . , d − 1 lik e as for the DNNs. Each minimization problem is solved by NMF a s shown below [ f W i , b Z i ] = a r g min f W i ,Z i ≥ 0 k b Z i − 1 − f W i Z i k F (9) and Algo rithm 2 is used to solve the nonlinear leas t squares problem as W i = min W i k b Z i − f ( W i Z i − 1 ) k F . (10) By so lv ing (9 ) and (10) alter natily , the algorithm for the propo s ed sta c ked au- to encoder is s umm arized b y Algorithm 5 . 7 0 1 2 3 4 5 6 0 100 200 300 400 500 600 Error rate Wall clock time[sec.] BP train BP test Proposed train Proposed test (a) MNIST. 0 10 20 30 40 50 60 70 80 0 300 600 900 1200 1500 Error rate Wall clock time[sec.] BP train BP test Proposed train Proposed test (b) CIF AR10. Fig. 1: Conv e r gence histo ry of the prop osed metho d a nd BP with [1000 - 500] hidden units for MNIST and CIF AR10. 5 P er forma nce ev aluations In this section, we ev aluate the p erformance of the prop osed metho d (Algo - rithm 4) using the stac ked auto enco der (Algorithm 5) for fully-connected DNNs for MNIST [10] and CIF AR10 [8 ]. There ar e se veral techniques for improving the per formance of BP such as a ffine/elastic distortions and denoising auto encoder . These techniques ar e a lso exp ected to improve the pe r formance of our algo rithm. Therefore, in this section, we just make a co mparison with a simple BP . F or the prop osed metho d, the n umber of itera tio ns of the auto encoder and the LSQs and the thresho ld of the low-rank approximation of the input data X were set as (5 , 10 , 4 . 0 × 1 0 − 2 ) for MNIST and (20 , 25 , 5 . 0 × 10 − 3 ) for CIF AR10, resp ectiv ely . The size of the mini-batches was set as 5000 and the auto encoder was co mput ed using only 5 000 r a ndom sa mples. F or o ptimizing parameters of BP , we used AD AM o ptimizer [7 ]. F or AD AM optimizer, initial learning rates for the stack e d autoe ncoder and for the fine tuning w er e set as (10 − 3 , 10 − 3 ) for MNIST and (5 . 0 × 10 − 4 , 10 − 3 ) for CIF AR10, respectively . O ther par ameters β 1 , β 2 and ε of ADAM w ere s et as the default parameter s of T ensor Flo w. W e used the nor malized initialization [4 ] for initial g uesses of the stack e d autoenco der. The size of the mini-batches w as set as 100 and the autoe ncoder was co mputed using o nly 5000 r andom samples. The p erformance ev a luations were carried out using double precision arith- metic on Intel(R) Xeon(R) CPU E5-2667 v3 (3.20GHz). The prop osed method was implemented in MA TLAB and the BP was implemented using T ensor - Flow [17]. Fig. 1 shows the co n vergence history o f the pro posed method and BP with [1000- 500] hidden units for MNIST and CIF AR10. T a ble 1 shows the 95% con- fidence in terv a l of the error r ate and the computation time of 10 ep och of b oth metho ds with sev eral hidden units for MNIST. 8 T able 1: The 95% co nfidence interv al of the erro r rate a nd the computation time of 10 ep och o f the pr oposed metho d (MA TLAB) and BP (T ensor Flow) with several hidden units for MNIST. BP Proposed hidden units Error rate [%] time Error rate [%] time train data test data [sec.] train data test data [sec.] 500 0.30 ± 0.0 14 1.77 ± 0.03 15 3 3.68 ± 0.04 3 3.73 ± 0.0 9 99 1000-500 0.06 ± 0.0 07 1.39 ± 0.08 33 0 0.04 ± 0.00 4 1.50 ± 0.0 6 310 1500-1000 -500 0.32 ± 0.0 86 1.90 ± 0.15 73 9 0.01 ± 0.00 4 1.35 ± 0.0 3 737 2000-1500 -1000-500 0.48 ± 0.132 1.84 ± 0.18 1589 0.00 ± 0.001 1.29 ± 0.04 1581 These ex p erimental results show that our metho d a tt ains a similar error rate, for several hidden units, as conv entional DNNs with BP . Sp ecifically , the pro - po sed metho d achiev es b etter err or r a tes with deep er hidden units. Moreover, the prop osed metho d needs a smaller computation time for the stack ed a utoenco der and almo st the sa me computation time for the fine tuning. 6 Conclusions In this pap er, w e prop osed an alternating optimization algorithm for computing weigh t matrice s of fully-connected DNNs by using the semi-NMF and the nonlin- ear semi-NMF. W e also presented a method to calculate a stacked autoe nc o der by using NMF. The exper imen tal results show ed that our metho d using NMF attains a similar e r ror rate and a s imila r computation time to co n ven tiona l DNNs with BP . Almost the all computations o f the prop osed method are represented by matrix–matrix computations, and accelerato rs such as GPUs and MICs ar e employ ed like in BP co mputations. The prop osed metho d also uses mini-batc h techn ique; how ever, the matrix size is larger than that of conv entional BP . Ther e- fore, w e exp ect that the pr oposed metho d achiev es high per formance o n rec en t computational en vir onmen ts. F or future work, we will consider a bias vector, sparse re gularizations and other a ctiv ation functions. Mor eo ver, w e will extend our algorithm to conv olu- tional neur al netw or ks. W e will also consider parallel computation implementa- tion and ev aluate the p erformance in recent para llel e n vironments. References 1. Bengio,Y., Lamblin, P ., Popovici, D., and Larochelle, H.: Greedy la yer-wisetraining of deep netw orks. In Pr o c. A dvanc es in Neur al Inf ormat ion Pr o c essing Systems 19 153–160 (2006). 2. Ciresan, D.C., Meier, U., Masci, J., Gam b ard ella, L.M., and Schmidh u ber, J.: Flexible, high p erformance conv olutional neu ral net works for image classification, 9 Pr o c. 22nd International Joint Confer enc e on Artificial Intel ligenc e , 1237–124 2 (2011). 3. Ding, D., Li, T., and Jordan, M. I.: Conv ex and semi-nonnegative matrix factoriza - tions. IEEE T r ansactions on Patter n Analysis and Machine Intel ligenc e 32 , 45–55 (2010). 4. Glorot, X. and Bengio, Y.: Und ersta nding the difficulty of training deep feedfor- w ard neural netw orks, in International c onfer enc e on artificial intel ligenc e and statistics , 249–256 (2010). 5. Glorot, X., Bordes, A., and Bengio ., Y.: Deep sp a rse rectifier neural netw orks. I n Pr o c.14th International Confer enc e on Artificial Intel li genc e and Statistics 315–323 (2011). 6. Hinton, G.E., D eng, L., Y u, D., Dahl, G.E., Mohamed, A., Jaitly , N., Senior, A., and V anhoucke, V.: Deep neural netw orks for acoustic mod eling in speech recognition, IEEE Signal Pr o c essing Magazine 29 ,82–97 (2012). 7. Kingma, D. P . and Ba, J.: ADAM: A Metho d for Sto chastic Optimization , The International Conference on Learning Representations (ICLR), San Diego, 2015 8. Krizhevsky , A., Hinton, G.: Learning multiple lay ers of features from tin y images. Computer Scienc e Dep artment, University of T or onto, T e ch. R ep , 1 7 (2009). 9. LeCun, Y., Boser, B., Denker, J.S., Hen derson, D., How ard, R .E ., Hubbard, W., and Jac kel, L.D.: Backpropaga tion applied to hand w ritten zip cod e recog nition, Neur al Computation 1 , 541–551 (1989). 10. LeCun, Y.: T he MNIST database of handwritten d ig its, http://y ann.lecun.com/exdb/mn ist. 11. Lee, D.D., and S eung, H.S.: Learning t h e parts of ob jects by non-negativ e matrix factorizatio n. Natur e 401 , 788– 791 (1999). 12. LeCun, Y., Bottou, L., Bengio, Y., Huffier, P .: Gradient-based learning applied to docu men t recognition, In Pr o c. IEEE 86 , 2278–2324 (1998). 13. N ai r, V., and Hin ton, G.E.: Rectified linear u nits improv e restricted Boltzmann mac hines, In Proc. I C ML (2010). 14. Paatero, P ., and T app er, U.: Positiv e matrix factorization: A non-negative factor mod el with optimal utilization of error estimates of data val ues. Envir onmetrics 5 111–126 (1994). 15. R umelhart, D. E., H in ton, G. E., and Willia ms, R . J.: Learning representations by back-propagating errors. Natur e 323 , 533–536 (1986). 16. S riv astav a, N., Hinton, G.E. Krizhevsky , A., Sutskev er, I., and Salakhutdino v, R .: Drop out: A simple wa y to p rev ent neural net works from o verfitting, J. Machine L e arning R ese ar ch 15 , 1929–1958 (2014 ). 17. T ensorFlo w, https://www.tensor flow.org/ .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment