Sparse matrices for weighted sparse recovery
We derived the first sparse recovery guarantees for weighted $\ell_1$ minimization with sparse random matrices and the class of weighted sparse signals, using a weighted versions of the null space property to derive these guarantees. These sparse mat…
Authors: Bubacarr Bah
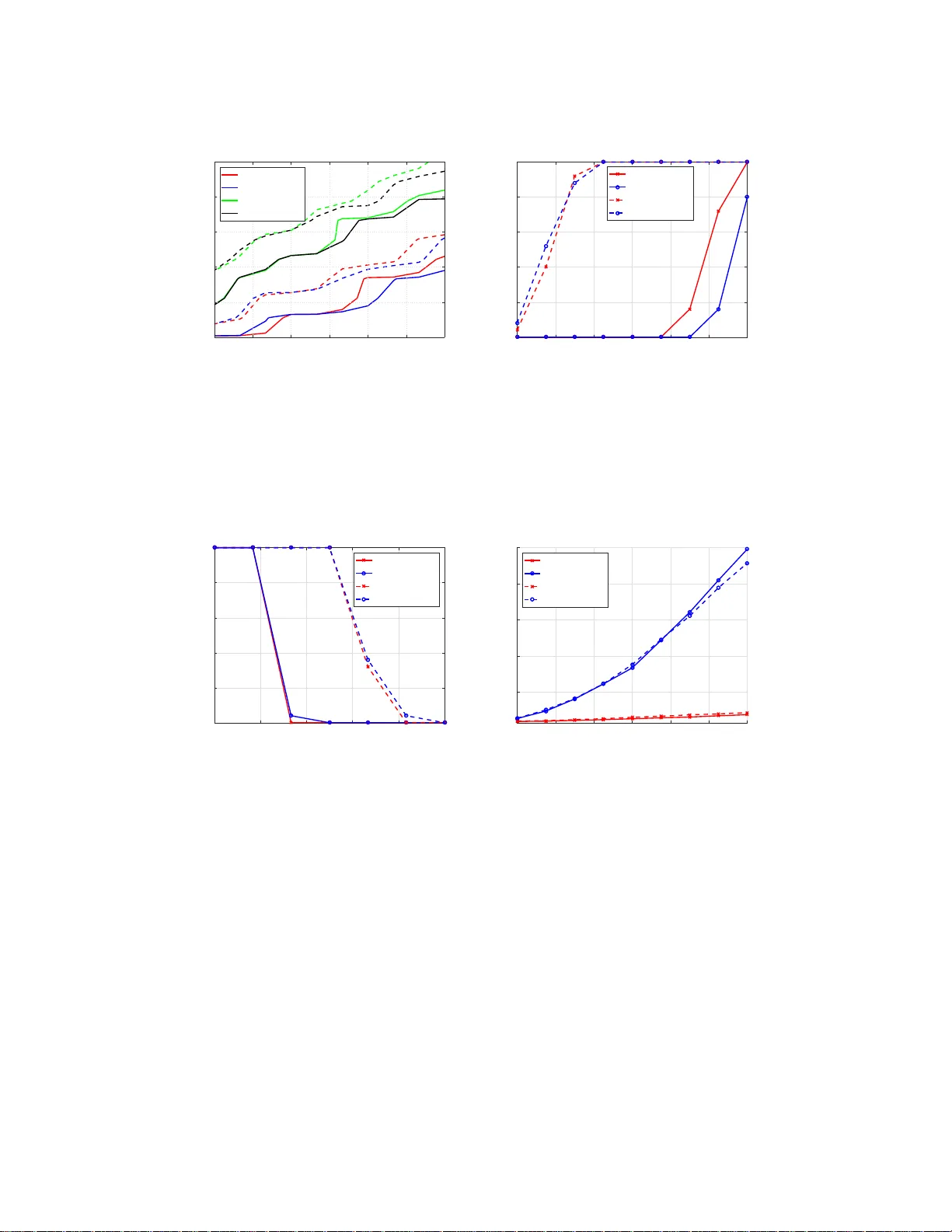
Sparse matrices for w eigh ted sparse reco v ery Bubacarr Bah ∗ August 13, 2018 Abstract W e derived the first sparse recov ery guarantees for w eighted ℓ 1 minimization with sparse random matrices and the clas s of weighted spa rse signals , using a weigh ted versions of the null space pro pe r ty to derive these gua rantees. T he s e s parse matrices from exp ender graphs can b e applied very fast and hav e other b etter computationa l complexities than their dense counterparts. In addition we s how tha t, using such sparse matr ic es, weigh ted s parse recovery with weight ed ℓ 1 minimization leads to sample complexities that are linear in the weigh ted spa r sity o f the signa l and these sampling rates can b e smaller than thos e of standard sparse recovery . Moreover, these results reduce to k nown results in standar d s pa rse recovery and spa rse r ecov ery with prior information and the r esults ar e supp orted b y numerical exp er imen ts. Keyw ords: Compressed sensing, spars e reco v ery , w eigh ted ℓ 1 -minimization, w eigh ted sparsit y , s p arse matrix, expander graph, sample complexit y , nullspace prop ert y 1 In tro duction W eig hted sp arse reco v ery was in tro du ced b y [26] for application to function interp olation but there h as b een a steady gro wth in in terest in the area, [1, 2, 5, 7, 15, 25], since then . In particular [5] sho w ed its equiv alence to standard sp arse r eco v ery using w eigh ted ℓ 1 minimization. The setting consid ered h ere is as follo ws: fo r a signal of interest x ∈ R N whic h is k -sparse and a giv en measurement matrix A ∈ R n × N , w e p erform measurements y = Ax + e for a noise vect or e with k e k 1 ≤ η (this b eing th e main difference w ith the previously mentioned works). Th e we ight ed ℓ 1 -minimization problem is then giv en b y: min z ∈ R N k z k ω , 1 sub ject to k Az − y k 1 ≤ η , (WL1) where k z k ω , 1 = P N i =1 ω i | z i | with wei ght s ω i > 0. If, based on ou r prior kno wledge of the signal, we assign an appropriate weigh t vec tor ω ≥ 1, then any S ⊂ [ N ] suc h th at P i ∈S ω i ≤ s is said to b e weighte d s -sp ar se . When the weigh ted ℓ 1 minimization (WL1) is u sed to reco v er signals supp orted on s ets that are weigh ted s -sp arse, th en the p roblem b ecomes a we igh ted s p arse reco v ery p roblem. ∗ Mathematics Department, Un ivers ity of T exas at Austin ( bah@math.ut exas.edu ). 1 The motiv ation for the use of weigh ted ℓ 1 minimization either for standard sparse reco v ery or weigh ted sparse reco ve ry stems f rom the n umerous app lications in which one naturally is faced with a sparse reco v ery p roblem and a prior distribution o v er th e su pp ort. Consequent ly , th is h as b een the sub ject of seve ral works in the area of compressive sensing, see for example [2, 5, 7, 10, 1 7, 1 9– 21, 24– 26, 28– 30]. Most of these w orks p rop osed v arious strategies for setting w eigh ts (either f rom t w o fixed lev els as in [20, 22], or fr om a con tin uous in terv al as in [10, 26]), in w h ic h smaller w eigh ts are assigned to those indices which are deemed “more lik ely” to b elong to the true underlyin g su pp ort. All of the prior work concerning w eigh ted ℓ 1 minimization considered d ense matrices, either su bgaussian sensing matrices or str uctured random matrices arising from orthonor- mal systems. Here, we instead stu dy the weig hte d ℓ 1 minimization pr oblem using spars e binary matrices for A . In the u n we igh ted setting, binary matrices are kno wn to p ossess what is referr ed to as the squar e-r o ot b ottl ene ck , that is they requir e m = Ω k 2 ro ws in - stead of the optimal O ( k log ( N /k )) rows to b e “go o d” compressed sens ing matrices with resp ect to optimal reco v ery guarant ees in the ℓ 2 norm, see [11, 13]. Y et, in [6], the authors sho w that such sp arse matrices achiev e optimal sample complexit y ( optimal ly few rows of O ( k log ( N /k ))) if one instead considers err or guarantees in the ℓ 1 norm. This pap er aims to dev elop comparable resu lts for sp arse b inary matrices in the setting of w eigh ted ℓ 1 minimization. On th e con trary to b eing second b est in terms of theoretical guarantee s to their dense counte rparts, spars e bin ary matrices ha v e su p erior computational prop er- ties. Their application, storage and generation complexities are muc h smaller th an dense matrices, see T able 1. Moreo v er, these non-mean zero bin ary m atrices are more natural Ensemble Storage Generation Application ( A ∗ y ) Sampling rate Gaussian [9] O ( nN ) O ( nN ) O ( nN ) O ( k log( N /k )) P artial F ourier [18] O ( n ) O ( n ) O ( N log N ) O ( k log 2 ( k ) log( N )) Expander [6] O ( dN ) O ( dN ) O ( dN ) O ( k log( N /k )) T able 1: Computational co mplexities of matr ix ensembles. The num ber of nonze r os pe r column of A is denoted by d , which is typically O (log N ). The r eferences p oint to pap er s that prop osed the sa mpling ra te. The table is a slig h t mo difica tion o f T able I in [23]. to use for some app licatio ns of compressed sensing than the dense mean zero subgaussian matrices, for example the single pixel camera, [14], u s es measurement devices with b inary sensors that inh eren tly corresp ond to binary and sparse inner pro d ucts. The pap er [26] in tro du ced a general set of cond itions on a sampling m atrix and un- derlying signal class wh ic h they use to p ro vide reco v ery guaran tees f or weigh ted ℓ 1 min- imization, n amely , the concepts of weig hte d s p arsit y , weigh ted null space prop ert y , and w eigh ted r estricted isometry pr op ert y . These are generalizations of the by- now classical concepts of sparsit y , n ull space prop ert y , and restricted isometry prop ert y introd uced in [9] for stud ying unw eigh ted ℓ 1 minimization. The pap er [26] fo cused on applying these to ols to m atrices arising from b ounded orthonormal systems, and touc hed briefly on implica- 2 tions for dens e rand om matrices. Here, we sho w that, und er app ropriate mo d ifications, the same to ols can pro vide w eigh ted ℓ 1 minimization guaran tees for sparse b inary sensin g matrices that are adjacency m atrices of expander graphs. Con tributions: The contributions of this wo rk are as follo ws. 1. T he in tro du ction of the we ight ed robust null space prop erty , satisfied b y adjacency matrices of ( k , d, ǫ )-lossless expander graphs, see Definition 3.1 in Section 3.1. 2. T he c haracterization of weigh ted sp arse r eco v ery guaran tees for (WL1) using these matrices, see Th eorem 3.2, in S ection 3.1. 3. T he deriv ation of samplin g rates that are linear in the weig hted sparsity of the signals using suc h matrices, see T heorem 3.3 in Section 3.2. Th ese sampling b ounds reco v er kno wn b ounds for unw eigh ted sparse r eco v ery and sparse reco v ery with partially kno wn supp ort, see Section 3.3. Numerical exp erimen ts su p p ort the theoretical results, see S ection 4. 2 Preliminaries 2.1 Notation & definitions Scalars will b e denoted by lo w ercase letters (e.g. k ), vec tors by lo w ercase b oldface letters (e.g., x ), sets by upp ercase calligraphic letters (e.g., S ) and matrices by upp ercase b oldface letters (e.g. A ). The cardinalit y of a set S is denoted b y |S | and [ N ] := { 1 , . . . , N } . Giv en S ⊆ [ N ], its complement is d enoted by S c := [ N ] \ S and x S is the r estriction of x ∈ R N to S , i.e. ( x S ) i = x i if i ∈ S and 0 otherwise. Γ( S ) denotes the set of neighb or s of S , that is th e righ t no des that are connecte d to the left no des in S in a bipartite graph , and e ij = ( x i , y j ) represents an ed ge connecting no de x i to no de y j . The ℓ p norm of a v ector x ∈ R N is defined as k x k p := P N i =1 x p i 1 /p , while the w eigh ted ℓ p norm is k x k ω ,p := P N i =1 ω 2 − p i | x i | p 1 /p . Th is work fo cuses on th e case w h ere p = 1, i.e k x k ω , 1 := P N i =1 ω i | x i | . A ( k , d, ǫ )-lossless expan d er graph, also called an unb alanc e d expander graph [6], is maximally “well- connected” give n a fixed num b er of edges. More p recisely , it is defin ed as follo ws: Definition 2.1 (Lossless Expander) . L et G = ([ N ] , [ n ] , E ) b e a left-r e gular bip artite gr aph with N left (variable) no des, m right (che c k ) no des, a set of e dges E and left de gr e e d . If, for any ǫ ∈ (0 , 1 / 2) and any S ⊂ [ N ] of size |S | ≤ k , we have that | Γ( S ) | ≥ (1 − ǫ ) d |S | , then G is r eferr e d to as a ( k , d, ǫ )-lossless expander graph . 3 2.2 W eigh ted sparsit y As a mo d el signal class for weigh ted ℓ 1 minimization, we consider the w eigh ted ℓ p spaces considered in [26]. Giv en a v ector of in terest x ∈ R N and a vecto r of wei ght s ω ∈ R N ≥ 1, i.e. ω i ≥ 1 for i ∈ [ N ], the weig hted ℓ p space is defined as ℓ ω ,p := x ∈ R N : k x k ω ,p < ∞ , 0 < p ≤ 2 . (1) The w eigh ted ℓ 0 -“norm” is denoted as k · k ω , 0 ; while the weigh ted cardin alit y of a set S is den oted as ω ( S ) and b oth are resp ectiv ely defined as k x k ω , 0 := X { i : x i 6 =0 } ω 2 i , and ω ( S ) := X i ∈S ω 2 i . (2) Observe that th e w eigh ted cardinalit y upp er b ounds the cardinalit y of a set, i.e. ω ( S ) ≥ |S | since ω i ≥ 1. W e den ote the wei ght ed s -term approxima tion of a vecto r x for s ≥ 1 by σ s ( x ) ω ,p and d efine it as follo ws: σ s ( x ) ω ,p := inf z : k z k ω , 0 ≤ s k z − x k ω ,p . (3) Up to a sm all m ultiplicativ e constan t, this quan tit y can b e computed efficien tly by sorting a weig hted version of the signal x and truncating, see [26] for more details. F or th is work, w e fo cus attenti on to the case p = 1: σ s ( x ) ω , 1 := k x − x S k ω , 1 = k x S c k ω , 1 . (4) 3 Theoretical results The main results of this w ork giv e reco v ery guaran tees f or wei ghte d ℓ 1 minimization (WL1) when th e sampling op erators are adjacency matrices of lossless expan d er graphs for the class of w eigh ted sparse signals. W e charac terize the app ropriate weigh ted robust n ull space prop ert y and expans ion condition that the adjacency m atrix of a ( k , d, ǫ )-lossless expander graph needs to s atisfy to guaran tee robust w eigh ted sparse reco v ery . These results reduce to the s tand ard sp arsit y and unw eigh ted ℓ 1 minimization results when th e w eigh ts are all chosen to b e equal to one. W e derive sample complexities, in terms of the w eigh ted sparsity s , of weig hte d sparse reco v ery using w eigh ted ℓ 1 minimization compared to unw eigh ted ℓ 1 minimization with adj acency matrices of a ( k , d, ǫ )-lo ssless exp an d er graphs. These sample complexities are linear in ω ( S ) and r ed uce to kno wn resu lts of standard sparse r eco ve ry and sparse reco v ery with p rior information. 4 3.1 Robust w eigh ted sparse recov ery guarantees The weighte d nu l l sp ac e pr op erty ( ω -NSP) h as b een used to giv e sparse reco v ery guarante es [20–22, 2 6] w ith t wo sc hemes for c hoice of weig hts. In [20, 26] th e weig hts ω ≥ 1; wh ilst in [21, 22 ] th e weig hts ω ≤ 1. Similar to [26], we consider the weighte d r obust N SP ( ω - RNSP) for the t yp e of matrices w e fo cus on, which is the robu st v ersion of th e NSP in the w eigh ted case and f ollo ws fr om the u n we igh ted RNSP prop osed in [16] for s uc h m atrices. Definition 3.1 ( ω -RNSP) . Given a weight ve ctor ω , a matrix A ∈ R n × N is said to have the r obust ω -RNSP of or der s with c onsta nts ρ < 1 and τ > 0 , if k v S k ω , 1 ≤ ρ k v S c k ω , 1 + τ √ s k Av k 1 , (5) for al l v ∈ R N and al l S ⊂ [ N ] with ω ( S ) ≤ s . W e will deriv e conditions un d er which an expander matrix satisfies the ω -RNSP to deduce error guarante es for weigh ted ℓ 1 minimization (WL1). This is f ormalized in the follo wing theorem. Theorem 3.1. L et A ∈ { 0 , 1 } n × N b e the adjac ency matrix of a ( k , d, ǫ ) -lossless exp ander gr a ph. If ǫ 2 k < 1 / 6 , then A satisfies the ω - RNSP (5) with ρ = 2 ǫ 2 k 1 − 4 ǫ 2 k , and τ = 1 √ d (1 − 4 ǫ 2 k ) . (6) Pr o of. Giv en any z ∈ R N . Let ω ∈ R N b e an asso ciated weig hts ve ctor with ω i ≥ 1, for i ∈ [ N ], and S with |S | ≤ k b e suc h that ω ( S ) ≤ s . W e will p r o v e that if A is the adjacency matrix of a ( k , d, ǫ )-lossless expander , th en A will satisfy the ω -RNSP (5) with the p arameters sp ecified in (6). Giv en S is the ind ex set of the k largest in magnitude en tries of z and let the indexes in S c b e ord ered suc h that ω i | z i | ≥ ω i +1 | z i +1 | for i ∈ S c . (7) Without lost of generalit y (w.l.o.g) w e assume that the set of v aria ble no d es of the b ipartite graph corresp onding to th e ( k , d, ǫ )-lossless exp ander are ordered accordingly . W e d enote the c ol lision set of edges of th e b ipartite graph as E ′ and d efine it as thus E ′ := { e ij | l < i suc h that e lj ∈ E } . (8) W e fi rst state and pro v e the follo wing lemma that will later b e used in the pr o of. Lemma 3.1. L et x ∈ R N b e k -sp arse. Then X e ij ∈ E ′ ω i | x i | ≤ ǫd k x k ω , 1 . (9) 5 Pr o of. Define R i := { e lj ∈ E ′ | l ≤ i } and r i = | R i | . Note that r 0 = r 1 = 0. X e ij ∈ E ′ ω i | x i | = N X i =1 ω i | x i | ( r i − r i − 1 ) (10) ≤ X i ≤ k ω i | x i | ( ǫdi − ǫ d ( i − 1)) (11) = ǫd k x k ω , 1 . (12) Equation (10) comes fr om the defin ition of R . The restriction to k indexes in (11) is due to the f act that x is k -sparse and x i = 0 for all i ∈ [ N ] \ sup p( x ). The b ound in (11) is due to the exp ansion prop ert y of the ( k , d, ǫ )-lossless expander graph, wh ich implies r k ′ ≤ ǫdk ′ for any k ′ ≤ k . 6 Con tin uing with the m ain p ro of, w e split the index set of z into q + 1 subs ets of [ N ] (i.e. S 0 , S 1 , . . . , S q ) of equal cardin alit y k except p ossibly the last subset, S q . W e also assume that ω ( S 0 ) ≤ s . Let E ( S ) denote the set of ed ges connecting to n o des in S . d k z S 0 k ω , 1 = d X i ∈S 0 ω i | z i | = X e ij ∈ E ( S 0 ) ω i | z i | (13) = X ω i | z i | e ij ∈ E ( S 0 ) \ E ′ ( S 0 ) + X e ij ∈ E ′ ( S 0 ) ω i | z i | (14) = X j ∈ Γ( S 0 ) X i ∈S 0 ω i | z i | e ij ∈ E ( S 0 ) \ E ′ ( S 0 ) + X j ∈ Γ( S 0 ) X i ∈S 0 e ij ∈ E ′ ( S 0 ) ω i | z i | . (15 ) Equation 13 comes from the left d -regularit y of the ( k , d, ǫ )-lossless expander graph; w hile (14) is due to the defi n ition of the collision set (8). No w we define γ ( j ) = { i ∈ S 0 | e ij ∈ E ( S 0 ) \ E ′ ( S 0 ) } . (16) Note that | γ ( j ) | = 1 for eac h j ∈ Γ( S 0 ). Using this n otation (15) can b e rewritten as d k z S 0 k ω , 1 = X j ∈ Γ( S 0 ) ω γ ( j ) | z γ ( j ) | + X j ∈ Γ( S 0 ) X i ∈S 0 e ij ∈ E ′ ( S 0 ) ω i | z i | . (17) Next we b ound the fir s t term on the right hand side of (17). The follo wing follo ws from the f act that A is the adjacency matrix of a ( k , d, ǫ )-lossless expander grap h . ( Az ) j = X i ∈ [ N ] a j i z i = X i ∈ [ N ] z i e ij ∈ E = X l ≥ 0 X i ∈S l z i e ij ∈ E = X i ∈S 0 z i e ij ∈ E ( S 0 ) + X l ≥ 1 X i ∈S l z i e ij ∈ E (18) = X i ∈S 0 z i e ij ∈ E ( S 0 ) \ E ′ ( S 0 ) + X i ∈S 0 z i e ij ∈ E ′ ( S 0 ) + X l ≥ 1 X i ∈S l z i e ij ∈ E . (19) In (18) w e app lied the sp litting of th e index set [ N ]; wh ile (19) is due to the d efinition of the collision set (8). With the ordering of the v ariable no des we can use (16), to rewr ite (19) as follo ws. ( Az ) j = z γ ( j ) + X i ∈S 0 z i e ij ∈ E ′ ( S 0 ) + X l ≥ 1 X i ∈S l z i e ij ∈ E . (20) 7 W e multiply (20) b y ω γ ( j ) and then we tak e absolute v alues to get ω γ ( j ) | z γ ( j ) | = | X i ∈S 0 ω γ ( j ) z i e ij ∈ E ′ ( S 0 ) + X l ≥ 1 X i ∈S l ω γ ( j ) z i e ij ∈ E + ω γ ( j ) ( Az ) j | ≤ X i ∈S 0 ω γ ( j ) | z i | e ij ∈ E ′ ( S 0 ) + X l ≥ 1 X i ∈S l ω γ ( j ) | z i | e ij ∈ E + ω γ ( j ) | ( Az ) j | (21) ≤ X i ∈S 0 ω i | z i | e ij ∈ E ′ ( S 0 ) + X l ≥ 1 X i ∈S l ω i | z i | e ij ∈ E + ω γ ( j ) | ( Az ) j | . (22 ) In (21) we used the triangle inequalit y; while in (22) w e used the ord ering of the entries of ω . No w w e can b ound (17) using the b ound in (22) as follo ws. d k z S 0 k ω , 1 ≤ 2 X j ∈ Γ( S 0 ) X i ∈S 0 ω i | z i | e ij ∈ E ′ ( S 0 ) + X j ∈ Γ( S 0 ) X l ≥ 1 X i ∈S l ω i | z i | e ij ∈ E + X j ∈ Γ( S 0 ) ω γ ( j ) | ( Az ) j | (23) = 2 X e ij ∈ E ′ ( S 0 ) ω i | z i | + X l ≥ 1 X j ∈ Γ( S 0 ) X i ∈S l ω i | z i | e ij ∈ E + X j ∈ Γ( S 0 ) ω γ ( j ) | ( Az ) j | . (24 ) In (24) we used the fact that the double sum mation in the fir st term of the right h an d side of (23) is equ iv alen t to a single summation o v er all the edges in E ′ ( S 0 ). Let the set of edges fr om vertex sets S a and S b b e denoted as E ( S a : S b ) . W e upp er b oun d the second term of (24) in the f ollo wing wa y . X l ≥ 1 X j ∈ Γ( S 0 ) X i ∈S l ω i | z i | e ij ∈ E ≤ X l ≥ 1 | E (Γ( S 0 ) : S l ) | max i ∈S l { ω i | z i |} ≤ X l ≥ 1 | E (Γ( S 0 ) : S l ) | 1 k X i ∈S l − 1 ω i | z i | , (25) where (25) is du e to the ord ering assumption (7). But | E (Γ( S 0 ) : S l ) | = | Γ( S 0 ) ∩ Γ( S l ) | and that Γ( S 0 ) ∪ Γ( S l ) = Γ( S 0 ∪ S l ) since S 0 and S l are disjoint . By the inclusion-exclusion principle | Γ( S 0 ) ∩ Γ( S l ) | = | Γ( S 0 ) | + | Γ( S l ) | − | Γ( S 0 ∪ S l ) | and b y the exp ansion prop erty of th e ( k , d, ǫ )-lossless expander graph | Γ( S 0 ∪ S l ) | ≥ (1 − ǫ 2 k ) d |S 0 ∪ S l | . Thus we hav e | E (Γ( S 0 ) : S l ) | = | Γ( S 0 ) | + | Γ( S l ) | − | Γ( S 0 ∪ S l ) | ≤ 2 dk − 2(1 − ǫ 2 k ) dk = 2 ǫ 2 k dk , (26) where we upp er b ound ed eac h of | Γ( S 0 ) | and | Γ( S l ) | by dk since eac h no d e has at most d neigh b ors. 8 Using th is result w e get the follo wing u pp er b ou n d for (25). X l ≥ 1 X j ∈ Γ( S 0 ) X i ∈S l ω i | z i | e ij ∈ E ≤ X l ≥ 1 2 ǫ 2 k dk 1 k k z S l − 1 k ω , 1 = 2 ǫ 2 k d X l ≥ 1 k z S l − 1 k ω , 1 ≤ 2 ǫ 2 k d k z k ω , 1 . (27) F or an u pp er b ound of th e last term of (24) w e pro ceed as follo ws. Note that this term is an inner pr o duct of tw o p ositive ve ctors hence w e can use Cauch y-Sc h w arz inequ alit y . X j ∈ Γ( S 0 ) ω γ ( j ) | ( Az ) j | ≤ s X j ∈ Γ( S 0 ) ω 2 γ ( j ) s X j ∈ Γ( S 0 ) | ( Az ) j | 2 ≤ s X i ∈S 0 dω 2 i k Az k 2 (28) ≤ √ ds k Az k 1 . (29) In (28) we up p er b ounded by u sing the fact that eac h no de has at most d neigh b ors an d that | Γ( S 0 ) | ≤ n to up p er b oun d b y the ℓ 2 norm of Az . W e up p er b oun d the ℓ 2 norm by the ℓ 1 norm in (28) and used the b ound P i ∈S 0 ω 2 i = ω ( S 0 ) ≤ s . Finally , we app ly Lemma 3.1 to u pp er b ound the first term of (24) by 2 ǫ 2 k d k z S 0 k ω , 1 (since ǫ 2 k ≥ ǫ k =: ǫ ). Then we use (27) and (29) to r esp ectiv ely b ound the second and the third terms of (24) to get. d k z S 0 k ω , 1 ≤ 2 ǫ 2 k d k z S 0 k ω , 1 + 2 ǫ 2 k d k z k ω , 1 + √ ds k Az k 1 (30) = 4 ǫ 2 k d k z S 0 k ω , 1 + 2 ǫ 2 k d k z S c 0 k ω , 1 + √ ds k Az k 1 . (31) If we let S 0 = S and the rearrange (31) we ha v e k z S k ω , 1 ≤ 2 ǫ 2 k 1 − 4 ǫ 2 k k z S c k ω , 1 + 1 √ d (1 − 4 ǫ 2 k ) √ s k Az k 1 , (32) whic h is the ω -RNSP (5) with ρ and τ as in (6) , hence concluding the p ro of. Based on Theorem 3.1 we provide reconstruction guaran tees in the follo wing theorem. Theorem 3.2. L et A b e the adjac ency matrix of a ( k , d, ǫ ) -lossless exp and er gr aph with ǫ 2 k < 1 / 6 . Given any x ∈ R N , if y = Ax + e with k e k 1 ≤ η , a solution b x of (WL1) is an appr oximation of x with the fol lowing err or b ounds k b x − x k ω , 1 ≤ C 1 σ s ( x ) ω , 1 + C 2 √ sη , (33) wher e the c onstants C 1 , C 2 > 0 dep end only on d and ǫ . Before we pro v e Theorem 3.2, w e s tate and pr o v e a lemma, wh ic h is k ey to that pro of. 9 Lemma 3.2. If A satisfies ω -RNSP (5) with ρ < 1 and τ > 0 , then given any x , z ∈ R N with k z k ω , 1 ≤ k x k ω , 1 , we have k z − x k ω , 1 ≤ c 1 σ s ( x ) ω , 1 + c 2 √ s k A ( z − x ) k 1 , (34) wher e the c onstants c 1 , c 2 > 0 dep e nd only on d and ǫ . Pr o of. Let S w ith |S | ≤ k such that ω ( S ) ≤ s . Then we hav e k x k ω , 1 ≥ k z k ω , 1 = k z − x + x k ω , 1 = k ( z − x + x ) S k ω , 1 + k ( z − x + x ) S c k ω , 1 ≥ k x S k ω , 1 − k ( z − x ) S k ω , 1 + k ( z − x ) S c k ω , 1 − k x S c k ω , 1 (35) = k x k ω , 1 − 2 k x S c k ω , 1 − 2 k ( z − x ) S k ω , 1 + k z − x k ω , 1 . (36) In (35) we used the tr iangle in equalit y; while in (36) we used the d ecomp osabilit y (sepa- rabilit y) of the ℓ ω , 1 norm, i.e. k ( · ) S k ω , 1 + k ( · ) S c k ω , 1 = k · k ω , 1 . Simplifying and rearranging (36) give s 2 k x S c k ω , 1 ≥ k z − x k ω , 1 − 2 k ( z − x ) S k ω , 1 . (37) No w we are ready to use ω -RNSP1 to upp er b ound the last term of (37) b y r eplacing v in (5) by z − x . Firs tly (5) can b e rewritten as k v S k ω , 1 ≤ ρ 1 + ρ k v k ω , 1 + τ 1 + ρ √ s k Av k 1 . (38 ) Therefore, us in g (38) with v = z − x , (37) b ecomes 2 k x S c k ω , 1 ≥ k z − x k ω , 1 − 2 ρ 1 + ρ k z − x k ω , 1 − 2 τ 1 + ρ √ s k A ( z − x ) k 1 . (39) Simplifying and r earranging (39) yields k z − x k ω , 1 ≤ 2(1 + ρ ) 1 − ρ k x S c k ω , 1 + 4 τ 1 − ρ √ s k A ( z − x ) k 1 . (40) Using th e definition of σ s ( x ) ω , 1 from (4) yields (34) from (40) with c 1 = 2(1 + ρ ) 1 − ρ , and c 2 = 4 τ 1 − ρ . (41) This conclud es the pro of of the lemma. Pr o of. (The or em 3.2) It can b e easily seen that the theorem is a corollary of the Lemma 3.2. The reco v ery err or b oun ds in (33) follo w from the error b oun ds in (34) in Lemma 3.2 b y replacing z with b x and using the triangle inequalit y to b oun d the follo wing: k A ( b x − x ) k 1 ≤ k A b x − y k 1 + k Ax − y k 1 ≤ 2 η . Hence C 1 = c 1 , and C 2 = 2 c 2 . Fi- nally , for A to s atisfy the ω -RNS P with ρ < 1 and τ > 0 we require ǫ 2 k < 1 / 6 . 10 3.2 Sample complexit y Here we deriv e sample complexities in term s of the w eigh ted sparsity , s , of weig hted sp ars e reco v ery using w eigh ted ℓ 1 -minimization with sparse adj acency matrices of ( k , d, ǫ )-lossless expander graphs. These sample complexit y b ounds are linear in th e weigh ted sparsit y of the signal and can b e smaller th an sample complexities of standard spars e reco v ery using unw eigh ted ℓ 1 -minimization with and sparse adjacency matrices of ( k , d, ǫ )-lossless expander graphs. Moreo v er, these results r eco v er kno wn results for the settings of a) uniform weig hts, b) p olynomially growing w eigh ts, c) spars e reco v ery with pr ior sup p ort estimates, and d) known supp ort. In particular, in the setting of sp a rse r e c overy with prior supp o rt estimates , dep ending on mild assumptions on the gro wth of the weig hts and ho w well is the su p p ort estimate aligned w ith the tr ue supp ort will lead to a reduction in samp le complexit y . Th e follo wing deriv atio ns, without loss of generalit y , assume an ordering of the en tries of the signal in order of magnitude suc h that S has the fi rst k largest in magnitude en tries of the signal. Theorem 3.3. Fix weights ω j ≥ 1 . Supp ose that γ > 0 dep e nding on the choic e of weights, and 0 ≤ δ < 1 . Consider an adjac ency matrix of a ( k, d, ǫ ) -lossless exp a nder A ∈ { 0 , 1 } n × N , and a signal x ∈ R N supp orte d on S ⊂ [ N ] with |S | ≤ k and P i ∈S ω 2 i ≤ s . Assume that noisy me a sur ements ar e taken, y = Ax + e with k e k 1 ≤ η and ǫ 2 k < 1 / 6 . Then with pr ob ability at le ast 1 − δ , any solution b x of (WL1) satisfies (33) , if n = O s/ ( ǫ 2 γ ) , and d = O ( ǫn/k ) . (42) Pr o of. Theorem 3.2 guaran tees that any solution b x of (WL1) satisfies (33) if th e sensing matrix is an adjacency matrix of a ( k , d, ǫ )-lossless expander w ith ǫ 2 k < 1 / 6. Therefore, it suffice to prov e the existence of su c h lossless expander grap h s. The pro of follo ws w hat has b ecome a standard pr o cedure f or proving pr ob ab ilistic existence of expand er graphs [3, 6, 16]. Consequen tly , w e will sk ip some of the d etails of the pr o of. Let G = ([ N ] , [ n ] , E ) b e a bipartite graph with N left and n righ t v ertices. L et eac h v ertex in [ N ] ha v e a regular d egree d . W e pr obabilistically construct the graph by pic king eac h no de in [ N ] and connecting it to d n o des in [ n ] c hosen uniformly at random. Then we ask that for an y set S ⊂ [ N ] , |S | ≤ k with ω ( S ) ≤ s , what is the pr obabilit y of failure of the graph to expand on this set? Let this eve nt b e denoted by F k , then F k := | Γ( S ) | < (1 − ǫ ) dk. (43) Therefore, we need to compute Prob {F k } for our fixed S of size k , which w e m a y n ot b e able to do bu t an upp er b ound su ffices. An upp er b ound is giv en by the follo wing lemma pro v en in [8]. Lemma 3.3. Give n a left d -r e gu lar bip art ite gr aph, G = ([ N ] , [ n ] , E ) , with exp a nsion c o efficient ǫ , ther e exist a c onstant µ > 0 such that for any T ⊆ [ N ] with |T | = t , whenever n = O ( dt/ǫ ) , we have Prob {F t } ≤ µ · ǫn dt − ǫdt . 11 F or the bip artite graph G to b e an expander it h as to expand on all sets S of |S | ≤ k . So w e need the pr obabilit y of failure on all set S of |S | ≤ k wh ic h w e can b ound by a u nion b ound as follo ws, if we denote this probability as p . p = k X t =1 N t µ · ǫn dt − ǫdt ≤ k X t =1 e N H ( t N ) − ǫdt log ( µ · ǫn dt ) , (44) where H ( q ) = − q log q − (1 − q ) log (1 − q ) is the Shannon en trop y function in base e logarithms and we b ound the com binatorial term by a b ound d ue to [12]: N N q ≤ e N · H ( q ) , for N ∈ Z + , q ∈ [0 , 1] such that q N ∈ Z + . F rom Lemma 3.3 the order notation imp lies that there exist a constan t C 1 suc h th at d ≥ C 1 ǫn/t . Using this lo w er b ound on d and the b ound H ( x ) < − x log x + x foun d in [4] we upp er b ound (44) as f ollo ws: p ≤ k X t =1 e N ( − t N log ( t N ) + t N ) − C 1 ǫ 2 n log( µ/C 1 ) = k X t =1 e t log ( eN /t ) − C 2 ǫ 2 n , (45) where C 2 = C 1 log ( µ/C 1 ). The function t log ( eN /t ) is monotonically increasing in t ≥ 1 and so its maxim um o ccurs at t = k . Hence w e can up p er b ound (45) as th us p ≤ k e k log( eN /k ) − C 2 ǫ 2 n . (46) F or an expansion probab ility at least 1 − δ w e require p ≤ δ , wh ic h hold if k e k log( eN /k ) − C 2 ǫ 2 n ≤ δ , ⇒ log( k ) + k log ( eN /k ) − C 2 ǫ 2 n ≤ log ( δ ) . (47) W e then c ho ose w eigh ts suc h that s/γ is of the order of k log ( N /k ). Examples of w eigh t and γ c hoices are discuss ed in the next section. This concludes th e pro of. Remark 3.1. The pr o of r e quir es that s/γ to b e of the or d er of k log ( N /k ) , implying that we don ’t gain any r e duction in the sample c omplexity in weighte d sp arse r e c overy over standar d sp a rse r e c o very. This is an artifact of the pr o of te chniqu e . It is c ounter intuitive and the exp eriments (Se ction 4) explicitly show the c ontr ary with weighte d sp arse r e c overy having higher phase tr a nsitions (implying lower sampling r ates) than standar d sp arse r e c overy. Nonetheless, it is inter esting to expr ess sample r ates in terms of the weighte d sp arsity as this wil l guide the choic e of weights. 3.3 Discussion on the c hoice of weigh ts Theorem 3.3 r equires dep end ence of γ on the c hoice of weigh ts, precisely it su ffice to fix the we igh ts suc h that s/γ of the order of k log ( N /k ). Belo w w e discus s the c hoice of w eigh ts and hence th e c hoice of γ , wh er e these c hoices reco v ers existing results, similar to results sh o wn in [5] for Gaussian samplin g matrices. • Uniform weigh ts. In standard sp arse reco v ery using u nw eigh ted ℓ 1 -minimization, the w eigh ts are ω i = 1 for all i ∈ [ N ]. This is a sp ecial case of Theorem 3.3 with s = k and γ = (2 log ( N /k )) − 1 , th us r eco v ering the kno wn samp le complexit y results 12 for stand ard sp ars e reco v ery with adjacency matrices of ( k , d, ǫ )-lossless expander graphs, [3, 6, 1 6]: n = O k log( N /k ) /ǫ 2 , and d = O (log( N /k ) /ǫ ) . (48) • P olynomially growing w eigh ts. The idea of u sing p olynomially gro wing w eigh ts w as prop osed in [26], in the con text of app lication to smo oth fun ction in terp olation. Precisely , the authors p rop osed wei ght s ω i = i α/ 2 for α ≥ 0. Using a num b er theoretic results d u e to [27] we derive the follo wing b ound for a w eigh ted s -spars e set S of cardinalit y k (see details in App endix): X i ∈S ω 2 i = X i ∈S i α ≤ ( k + 1) 1+ α . (49) As such the w eigh ts (or α ) are chosen such that ( k + 1) 1+ α of the order of γ k log ( N /k ) leading to (42). I n terestingly , if α = 0 we r eco v ery the standard sparse reco v ery r esult (48) b y c ho osing γ = (2 log( N /k )) − 1 . F urthermore, since ( k +1) 1+ α ≤ s ⇒ k ≤ s 1 1+ α if we let N = s 1 /α w e hav e that s/γ is of the order of O s 1 1+ α log( s ) , which is similar to a sample complexit y suggested in [26] for dense random matrices. 13 • Sparse reco v ery with prior supp ort estimates. In this case, we k n o w e S as an estimate of the tru e supp ort S and t ypically we assign w eigh ts ω i = w ∈ [0 , 1] for i ∈ e S and ω i = 1 for i ∈ e S c . Note that ω i ≤ 1 for all i ∈ [ N ], con trary to the the setting of this w ork where ω i ≥ 1. Without loss of generalit y , w e normalize by dividing by w (for w > 0) to get ω i = w 1 = 1 for i ∈ e S and ω i = w 2 = 1 /w ≥ 1 for i ∈ e S c (if w = 0, we divide by w + ε with a small n umb er ε > 0). The weig hte d cardinalit y of the su pp ort is X i ∈S ω 2 i = |S ∩ e S | + w − 2 |S ∩ e S c | . (50) Lik e in [26] we can choose we ight s and γ as follo ws. ω 2 i ≥ max { 1 , 2 γ log( j /s ) } , w ith γ = min n 1 , 2 w 2 log( N /s ) − 1 o . (51) F rom Theorem 3.3 w e h a v e sample complexities n = O ( s ) if γ = 1 and the more in teresting case is w hen γ = 2 w 2 log( N /s ) − 1 , th en n = O ( s/γ ) = O sw 2 log( N /s ) = O w 2 |S ∩ e S | + |S ∩ e S c | log( N /s ) . ( 52) Let | e S | = β |S | = β k , and |S ∩ e S | = α | e S | , where α, β ∈ [0 , 1]. Th en th e sampling b ound in (52) is b ound ed ab o v e by n = O w 2 k + r log( N /k ) , (53) where r = |S c ∩ e S | + |S ∩ e S c | represents th e mismatc h b et w een the tru e and estimated supp orts. Getting results similar to results in [21] for Gaussian matrices. • Kno wn supp ort. When the su pp ort of x coincides with the estimated su pp ort exactly , then |S ∩ e S | = s = k and |S ∩ e S c | = 0, and the sample complexit y b ecomes n = O ( s ) = O ( k ) , reco v ering the sample complexit y of stand ard sp arse reco v ery w ith known supp ort. 4 Exp erimen tal results In these exp erimen ts we consider the class of weighte d sp a rse signals mo deled in [5]. Pre- cisely , the p robabilit y f or an index to b e in the su pp ort of the s ignal is prop ortional to the recipro cal of the square of th e we igh ts assigned to that in d ex. W e also considered p o lyno- mial ly gr o wing weights . In p articular, we assign we ight s ω j = j 1 / 5 where the indices are ordered such that the sup p ort corresp onds to the smallest in magnitude set of we igh ts. The goal of the exp eriment s w as to compare the p erformance of we igh ted sparse reco v ery using w eigh ted ℓ 1 -minimization and standard sparse reco v ery using u nw eigh ted ℓ 1 -minimization using b oth Gaussian sensing matrices and sensing matrices that are sp arse binary adja- 14 cency matrices of expander graphs (hence forth referred to as expander matrices) in terms of a) sample complexit y b) computational ru ntimes, and c) accuracy of reconstruction. The m × N Gaussian m atrices ha ve i.i.d. stand ard normal entries scaled by √ m while the expander matrices are generated by putting d ones at u niformly at rand om lo cations in eac h column. W e d ra w signals of dimens ion N from the ab o v e mentio ned mo d el, wher e the n onzero v alues are randomly generated as scale d sum s of Gaussian and uniformly random v ariables without an y n orm alizati on. W e enco de th e signals using th ese matrices and add Gaussian wh ite noise with noise lev el k e k 2 ≤ 10 − 6 =: η 2 and d efine η 1 suc h that k e k 1 ≤ η 1 . F or the weigh ted s p arse reconstruction, we use (WL1) with expanders and use a mo dified v ersion of (WL1), r eplacing th e ℓ 1 b y ℓ 2 and η 1 b y η 2 in the data fidelit y term of (WL1), w ith Gaussian matrices; while the standard sparse r econstruction us ed min z ∈ R N k z k ω , 1 sub ject to k Az − y k p ≤ η p , (L1) with p = 1 for expanders and p = 2 for Gaussian matrices. The follo wing results are a ve raged ov er man y realizations for eac h p roblem instance ( s, m, N ). The d imension of the signal is N = 2 10 . F or th e expander matrices w e fixed d = ⌈ 2 log ( N ) ⌉ and w e v ary the num b er of measurements m suc h that m/ N ∈ [max(2 d/ N , 0 . 05) , 0 . 35]; and for eac h m we v ary the wei ght ed s p arsit y of th e supp ( x ), S , suc h that ω ( S ) /m = s/m ∈ [1 / min( m ) , 2 . 5]. Then w e r ecord k as the largest |S | for a giv en s . W e consider a reconstruction successful if the reco ve ry err or in the ℓ 2 -norm is b elo w 10 η 1 or 10 η 2 for expander or Gaussian matrices resp ectiv ely and a failure other- wise. Then w e compu te the empiric al pr ob abilities as the ratio of the num b er of successful reconstructions to the num b er of realizatio ns. a) Sample complexities via phase transitions: W e p resen t b elo w samp le com- plexit y comparisons using th e ph ase transition framework in the p hase space of ( s/m, m/ N ). Note that in all the figur es we norm alized (standardized) the v alues of s/m in such a wa y that the n ormalized s/m is b et w een 0 and 1 for fair comparison. The left panel of Figure 1 sho ws p hase transition cur v es in the form of con tours of empirical probabilities of 50% (solid cu rv es) and 95% (dashed curves) for expand er and Gaussian matrices using either ℓ 1 or ℓ ω , 1 minimization. Both matrices hav e similar p er f ormance and b y havi ng larger area un der th e con tours, weigh ted sparse reco v ery usin g (WL1) , outp erforms standard sp arse r eco v ery using (L1). Th e result in the left p anel is fu rther elucidated by the plots in the righ t panel of Figur e 1 and left panel of Figure 2. In the latter we sho w a sn ap shot for fixed s/m = 1 . 25 and v arying m wh ile in the former w e sh o w a snap shot for fi x ed m/ N = 0 . 1625 and v arying s . Both plots confirm the comparativ e p erformance of expanders to Gaussian matrices and the sup er iority of weig hte d ℓ 1 minimization o v er u n we igh ted ℓ 1 minimization. b) C omputational runtimes: T o compare runtimes we sum th e generation time of A (Gaussian or expand er), enco ding time of the signal using A , and the reconstruc- tion time, w ith w eigh ted ℓ 1 minimization o ve r unw eigh ted ℓ 1 minimization, and we a v erage th is o v er the num b er of realizatio ns. In th e righ t p anel of Figure 2 we plot 15 0.05 0.1 0.15 0.2 0.25 0.3 0.35 m/ N 0 0.2 0.4 0.6 0.8 1 Normalized s/m ℓ 1 Expander ℓ 1 Gaussian ℓ ω, 1 Expander ℓ ω, 1 Gaussian 0.05 0.1 0.15 0.2 0.25 0.3 0.35 m/ N 0 0.2 0.4 0.6 0.8 1 Recov ery probability ℓ 1 Expander ℓ 1 Gaussian ℓ ω, 1 Expander ℓ ω, 1 Gaussian Figure 1: L eft p anel : Contour plots depicting phase transitions o f 5 0% and 95 % r ecov ery prob- abilities (dashed and s olid curves resp ectively). Right p anel : Recovery probabilities for a fixed s/m = 1 . 25 and v arying m . a v erage runtimes for v arying m / N . This clearly s ho ws that expanders h a v e small runtimes. 0 0.2 0.4 0.6 0.8 1 Normalized s/m 0 0.2 0.4 0.6 0.8 1 Recov ery probability ℓ 1 Expander ℓ 1 Gaussian ℓ ω, 1 Expander ℓ ω, 1 Gaussian 0.05 0.1 0.15 0.2 0.25 0.3 0.35 m/ N 2 4 6 8 10 Normalized s/m ℓ 1 Expander ℓ 1 Gaussian ℓ ω, 1 Expander ℓ ω, 1 Gaussian Figure 2: L eft p anel : Recovery probabilities for a fixed m/ N = 0 . 1 6 25 and v a rying s . Right p anel : Run time comparisons . c) Accuracy of reconstructions: In Figure 3 we plot relativ e appro ximation errors in the ℓ ω , 1 norm (top panel). T he left panel are for a fixed s /m = 1 . 25 and v arying m while in the right panel are for fixed m/ N = 0 . 162 5 and v arying s . In Figure 4 we plot relativ e appro ximation errors in the ℓ 2 norm. S imilarly , the left p anel are f or a fixed s/m = 1 . 25 and v arying m w hile in the right p anel are for fixed m/ N = 0 . 162 5 and v a rying s . In b oth Figures 3 and 4 we see that weigh ted ℓ 1 minimization con v erges faster with smaller num b er of measur emen ts than unw eigh ted ℓ 1 minimization; bu t also we see that Gauss ian sensing matrices ha v e smaller approximat ion err ors than the exp anders. 16 0.05 0.1 0.15 0.2 0.25 0.3 0.35 m/ N 10 -5 10 0 Relative recovery error l 1 Expander l 1 Gaussian l w, 1 Expander l w, 1 Gaussian 0 0.2 0.4 0.6 0.8 1 Normalized s/m 10 -5 10 0 Relative recovery error l 1 Expander l 1 Gaussian l w, 1 Expander l w, 1 Gaussian Figure 3: L eft p anel : Rela tiv e error s for a fixed s/m = 1 . 2 5 and v arying m . Right p anel : Relative error s fo r a fixed m/ N = 0 . 1625 and v arying s . 0.1 0.15 0.2 0.25 0.3 0.35 0.4 m/ N 10 -6 10 -4 10 -2 Relative recovery error l 1 Expander l 1 Gaussian l w, 1 Expander l w, 1 Gaussian 0 0.2 0.4 0.6 0.8 1 Normalized s/m 10 -6 10 -4 10 -2 Relative recovery error l 1 Expander l 1 Gaussian l w, 1 Expander l w, 1 Gaussian Figure 4: L eft p anel : Rela tiv e error s for a fixed s/m = 1 . 2 5 and v arying m . Right p anel : Relative error s fo r a fixed m/ N = 0 . 1625 and v arying s . 5 Conclusion W e giv e the first rigorous error guaran tees for weig hte d ℓ 1 minimization with sparse mea- surement matrices and we ight ed sparse signals. The matrices are computationally efficien t considering their fast application and lo w storage and generation complexities. Th e deriv a- tion of these error guaran tees u ses the w eigh ted robu st n ull space prop ert y p rop osed for the more general setting of w eigh ted sp arse app ro ximations. W e also derived sampling rates for weig hted sparse reco v ery using these m atrices. These sampling b ounds are linear in s and can b e smaller than sampling rates for standard sparse reco v ery dep ending on the c hoice of we ight s. Finally , w e demonstrate exp erimenta lly the v alidit y of our theo- retical results. Moreo ve r, the exp erimenta l results show the computational adv an tage of expander m atrices o ve r Gaussian matrices. 17 Ac kno wledgemen ts The author is p artially s upp orted by Rac hel W ard’s NSF CAREER Gran t, aw ard #12556 31. The author w ould lik e to thank Rac hel W ard, for reading the pap er and giving v aluable feedbac k that imp ro v ed the manuscript. 6 App endix Here we prov e the b ound (49) by restating it as a lemma wh ich w e then p ro v e. Lemma 6.1. L et S b e a weighte d s -sp arse set of c a r dinality k and ω i = i α/ 2 . Then X i ∈S ω 2 i = X i ∈S i α ≤ ( k + 1) 1+ α . ( 54) Pr o of. The pro of u ses th e follo wing num b er theoretic results due to [27]. W e express α = 1 /r where r > 1 is a real num b er and state the resu lts as a lemma. Lemma 6.2. L et r b e a r e al numb er with r ≥ 1 and k b e a p ositive inte ger. Then k X i =1 i 1 /r = r r + 1 ( k + 1) 1+ r r − 1 2 ( k + 1) 1 r − φ k ( r ) , (55) wher e φ k is a function of r with k as a p ar ameter. This function is b ounde d b etwe en 0 and 1 / 2 . 18 Using this results without pro of (the in terested reader is referr ed to [27] for the pro of ) w e ha v e X i ∈S i α = X i ∈S i 1 /r ≤ r r + 1 ( k + 1) 1+ r r − 1 2 ( k + 1) 1 r − φ k ( r ) (56) ≤ ( k + 1) 1+ 1 r − 1 2 ( k + 1) 1 r (57) ≤ k + 1 2 ( k + 1) 1 r (58) ≤ ( k + 1) 1+ 1 r = ( k + 1) 1+ α , (59) as r equired, concluding the pro of. References [1] B en Adco ck. Infinite-dimensional compressed sensing and function in terp olation. arXiv pr epri nt arXiv:1509. 06073 , 201 5. [2] B en Adco ck. Infinite-dimensional ℓ 1 minimization a nd function a pproximation fr o m p oint wise data. arXiv pr eprint arXiv:1503 .02352 , 2015 . [3] B ubacarr Bah a nd Ja red T anner. V a nishingly spa r se matrice s a nd expa nder graphs, with application to compresse d s e nsing. 201 3. [4] B ubacarr Bah and Jared T anner. Bounds o f restricted isometry constants in extreme asymp- totics: formulae for gaussian matrices. Line ar Algebr a and its Applic ations , 441:88 –109, 2 014. [5] B ubacarr Bah a nd Rachel W ar d. The sample complex ity of weight ed spar se approximation. arXiv pr eprint arXiv:150 7.06736 , 201 5. [6] R. Berinde, A.C. Gilb ert, P . Indy k , H. Kar loff, and M.J. Stra uss. Combining geometry a nd combinatorics: A unified approach to sparse signa l recovery . In Communic ation, Contr ol, and Computing, 2008 46th Annual Al lerton Confer enc e on , pages 79 8–805 . IEEE , 200 8. [7] J ean-Luc Bouchot, Benjamin Bykowski, Holger Rauhut, and Chr istoph Sch w ab. Compres sed sensing Petrov-Galer k in a ppr oximations for para metric PDEs. 2015. [8] Ha rry Buhrman, Peter B ro Miltersen, Ja ikumar Radhakr ishnan, and Sriniv asan V enk atesh. Are bitvectors optimal? SIAM Journal on Computing , 31(6 ):1723– 1744, 200 2 . [9] E mmanuel J. Cand` es, Justin Romber g, and T erence T ao . Stable s ig nal recov ery from in- complete and ina ccurate measurements. Communic ations on pure and applie d mathematics , 59(8):120 7–12 2 3, 2 006. [10] Emmanuel J Cand` es, Michael B W akin, and Stephen P Boyd. Enhancing sparsity b y reweigh ted ℓ 1 minimization. Journ al of F ourier analysis and applic atio ns , 1 4(5-6):87 7–90 5 , 2008. [11] V.t Chandar . A negative result conce rning explicit matr ices with the restricted isometry prop erty . pr eprint , 2008. [12] Elliott W ar d Cheney . Introduction to a pproximation theor y . 1966. [13] R.A. DeV ore. Deterministic constructions of compressed sensing matrices. Journal of Com- plexity , 23 (4):918–9 25, 2 007. 19 [14] Marco F Duarte, Ma rk A Dav enp ort, Dharmpal T akhar , Jas on N Lask a, Ting Sun, K evin E Kelly , Richard G Bar aniuk, et a l. Single-pixe l imaging via c ompressive sampling. IEEE Signal Pr o c essing Magazine , 25(2):83 , 2008. [15] Axel Flinth. Optimal choice o f weigh ts for s parse recovery with prio r informatio n. arXiv pr epri nt arXiv:1506. 09054 , 201 5. [16] Simon F ouc a rt a nd Holger Rauhut . A mathematic al intr o duction to c ompr essive sensing . Springer, 20 13. [17] Michael P F riedla nder, Hassan Mansour, Rayan Saab, and Oezguer Yilmaz. Recov ering com- pressively sampled signals using partia l supp ort information. Information The ory, IEEE T r ansactions on , 58(2):112 2–113 4, 2 012. [18] Ishay Haviv and Oded Regev. The r estricted isometr y prop erty of subsampled fourier matr ices. arXiv pr eprint arXiv:150 7.01768 , 201 5. [19] Laurent Jacques. A short note on compress ed sensing with partially k nown signal supp or t. Signal Pr o c essing , 90(12):3 308–3 312, 2010 . [20] Amin M Kha jehnejad, W eiyu Xu, Amir S Avestimehr, and Babak Hassibi. W eig ht ed ℓ 1 minimization for s parse recov ery with prior information. In Information The ory, 2009. ISIT 2009. IEEE Intern ational Symp osium on , pa g es 48 3–487 . IEE E, 2009 . [21] Hassan Ma nsour and Ray an Saab. Recovery analysis for weigh ted ℓ 1 -minimization using a nu ll s pace pro pe r ty . arXiv pr epri nt arXiv:1412.15 65 , 2014. [22] Hassan Manso ur and ¨ Ozg ¨ ur Yilmaz. W eighted- ℓ 1 minimization with mu ltiple weigh ting sets. In SPIE Opt ic al Engine ering + Applic ations , pag es 81 3809– 81380 9. International So ciety for Optics and Photonics, 2011. [23] Ro drigo Mendoza -Smith and Jared T a nner. Expa nder ℓ 0 -deco ding. [24] Samet Oymak , M Amin Kha jehnejad, and Ba bak Hassibi. Re c ov ery thres hold for optimal weigh t ℓ 1 minimization. In Information The ory Pr o c e e dings (ISIT), 2012 IEEE International Symp osium on , pa ges 203 2–203 6. IEEE, 2012. [25] Ji Peng, J errad Hampton, a nd Alireza Do os ta n. A weigh ted ℓ 1 -minimization appr oach for sparse p olyno mial chaos expansions. Jou rn al of Computational Physics , 2 67:92 –111, 2014. [26] Holger Rauhut and Rachel W ard. In terp olation via weigh ted ℓ 1 minimization. Applie d and Computational Harmonic Analysis , 2 015. [27] Snehal Shek a tk ar. The sum of the r ’th ro ots of first n natural n umbers and new formula for factorial. arXiv pr eprint arXiv:120 4.0877 , 2012 . [28] Namrata V aswani a nd W ei Lu. Mo dified-CS: Mo difying compress ive sensing for problems with par tially known supp or t. Signal Pr o c essing, IEEE T ra nsactions on , 58(9):45 95–46 07, 2010. [29] R V on Borries , Jacque s C Miosso , and Cristhia n M Potes. Compressed sensing using prio r information. In Computational Ad vanc es in Multi-Sensor A daptive Pr o c essing, 2007. CAMP- SAP 2007. 2nd IEEE International W orkshop on , pa ges 1 21–12 4. IEE E, 2007 . [30] W eiyu Xu, M Amin Kha jehnejad, Amir Salman Avestimehr, and B abak Hassibi. Brea king through the thresholds: an a nalysis for iterative reweigh ted ℓ 1 minimization via the g rass- mann a ngle framework. In A c oustics Sp e e ch and Signal Pr o c essing (ICASSP), 2010 IEEE International Confer enc e on , page s 5498 –5501 . IEEE, 20 10. 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment