The Power of Depth for Feedforward Neural Networks
We show that there is a simple (approximately radial) function on $\reals^d$, expressible by a small 3-layer feedforward neural networks, which cannot be approximated by any 2-layer network, to more than a certain constant accuracy, unless its width is exponential in the dimension. The result holds for virtually all known activation functions, including rectified linear units, sigmoids and thresholds, and formally demonstrates that depth – even if increased by 1 – can be exponentially more valuable than width for standard feedforward neural networks. Moreover, compared to related results in the context of Boolean functions, our result requires fewer assumptions, and the proof techniques and construction are very different.
💡 Research Summary
The paper investigates the expressive power of depth‑bounded feed‑forward neural networks, focusing on the simplest non‑trivial case: the separation between 2‑layer (single hidden layer) and 3‑layer (two hidden layers) fully‑connected networks with a linear output neuron. The authors ask whether a modest increase in depth can dramatically reduce the required width to represent or approximate certain functions. Their main result is a constructive depth‑separation theorem that holds for virtually all standard activation functions (ReLU, sigmoid, threshold, etc.).
First, they formalize the network models. A 2‑layer network of width w computes
(f(x)=\sum_{i=1}^{w} v_i ,\sigma(\langle w_i,x\rangle+b_i)).
A 3‑layer network of the same width computes
(g(x)=\sum_{i=1}^{w} u_i ,\sigma!\Big(\sum_{j=1}^{w} v_{i,j},\sigma(\langle w_{i,j},x\rangle+b_{i,j})+c_i\Big).)
The analysis relies on two mild assumptions about the activation σ: (1) σ is “universal” in the sense that any 1‑dimensional Lipschitz function that is constant outside a bounded interval can be approximated arbitrarily well by a 2‑layer network of width polynomial in the interval length, Lipschitz constant and inverse error; (2) σ grows at most polynomially and is Lebesgue‑measurable. These conditions are satisfied by all common activations.
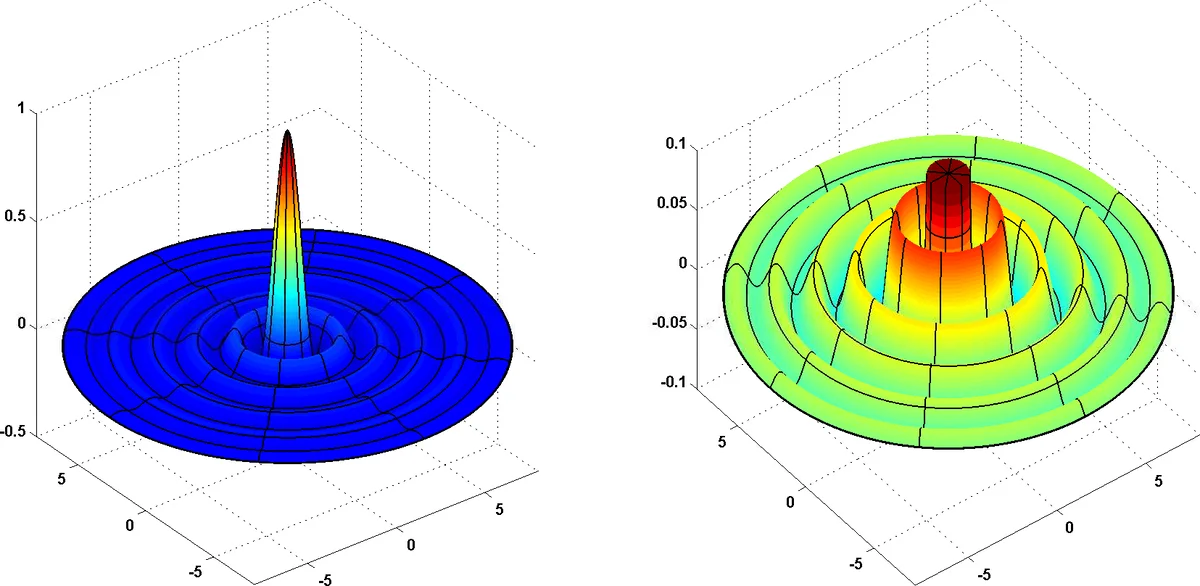
Theorem 1 states that for every sufficiently large dimension d there exists a probability distribution μ on ℝᵈ and a bounded, compactly‑supported function g that can be realized by a 3‑layer network of width O(poly(d)). However, any 2‑layer network of width at most exp(c·d) (for a universal constant c) incurs a constant‑size mean‑square error when approximating g under μ:
(\mathbb{E}_{x\sim\mu}\big
Comments & Academic Discussion
Loading comments...
Leave a Comment