Combating Fraud in Online Social Networks: Detecting Stealthy Facebook Like Farms
As businesses increasingly rely on social networking sites to engage with their customers, it is crucial to understand and counter reputation manipulation activities, including fraudulently boosting the number of Facebook page likes using like farms. To this end, several fraud detection algorithms have been proposed and some deployed by Facebook that use graph co-clustering to distinguish between genuine likes and those generated by farm-controlled profiles. However, as we show in this paper, these tools do not work well with stealthy farms whose users spread likes over longer timespans and like popular pages, aiming to mimic regular users. We present an empirical analysis of the graph-based detection tools used by Facebook and highlight their shortcomings against more sophisticated farms. Next, we focus on characterizing content generated by social networks accounts on their timelines, as an indicator of genuine versus fake social activity. We analyze a wide range of features extracted from timeline posts, which we group into two main classes: lexical and non-lexical. We postulate and verify that like farm accounts tend to often re-share content, use fewer words and poorer vocabulary, and more often generate duplicate comments and likes compared to normal users. We extract relevant lexical and non-lexical features and and use them to build a classifier to detect like farms accounts, achieving significantly higher accuracy, namely, at least 99% precision and 93% recall.
💡 Research Summary
The paper addresses the problem of fraudulent “like” inflation on Facebook pages, a practice carried out by commercial “like farms” that sell paid likes to boost the perceived popularity of pages. While Facebook has deployed detection tools such as CopyCatch and SynchroTrap that rely on graph co‑clustering of the user‑page bipartite graph to spot synchronized liking behavior, the authors demonstrate that these tools fail against “stealthy” farms that spread likes over longer periods and target popular pages to blend in with normal users.
To evaluate this claim, the researchers built on a previous honeypot experiment in which 13 empty Facebook pages were promoted via six campaigns: four commercial farms (BoostLikes, SocialFormula, AuthenticLikes, MammothSocials) each targeting worldwide and U.S. audiences, and five Facebook ad campaigns targeting various regions. The campaigns attracted 5,618 unique users, of which 4,179 were associated with the farms. After a cleaning phase, 3,670 farm accounts remained for analysis. In parallel, a baseline set of 1,408 random “normal” accounts was collected from prior work. For all accounts the authors crawled up to 500 recent timeline posts, the number of comments and likes per post, and the pages each user liked, resulting in roughly 600 K distinct pages and 270 K posts.
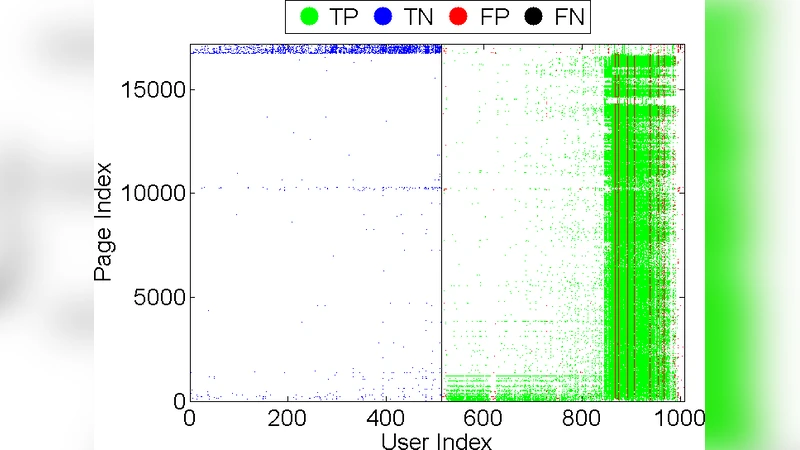
First, the authors applied a standard two‑cluster co‑clustering algorithm to the user‑page graph, mirroring the logic of CopyCatch and SynchroTrap. The results varied dramatically across campaigns. For the AL‑USA farm the algorithm achieved 98 % precision and 99 % recall, but for the BL‑USA campaign precision dropped to 47 % while recall remained high. Visual inspection revealed that false positives clustered around very popular pages (e.g., “Fast & Furious”, “SpongeBob SquarePants”), indicating that stealthy farms deliberately like high‑profile pages to mimic legitimate behavior, thereby breaking the assumption of tightly synchronized, niche‑specific liking patterns that the graph methods depend on.
Recognizing the limitations of purely graph‑based detection, the paper pivots to timeline‑based features. The authors categorize features into non‑lexical (post type distribution, number of comments per post, number of likes per post, proportion of shared content) and lexical (average words per post, vocabulary richness, type‑token ratio, readability scores such as Flesch‑Kincaid). Their analysis shows that farm accounts post significantly fewer original text updates (average ≤10 words per post versus ~17 for normal users), have a higher proportion of links, videos, and shared content, and receive more comments and likes per post—likely a side effect of coordinated activity. Lexically, farm posts exhibit lower vocabulary diversity, poorer readability, and a higher incidence of repeated or duplicated content, consistent with automated or low‑effort posting strategies.
Using these 20 features (10 non‑lexical, 10 lexical), the authors train several supervised classifiers. A Support Vector Machine (SVM) that combines both feature sets achieves the best performance: 99 % precision, 95 % recall, and an F1‑score of 97 %. Models that use only lexical or only non‑lexical features perform noticeably worse, confirming that the two feature families complement each other. The paper also benchmarks alternative algorithms—Decision Tree, Random Forest, AdaBoost, k‑Nearest Neighbors, and Naïve Bayes—finding that none surpass the combined‑feature SVM. Feature importance analysis highlights average word count, unique word ratio, share‑post proportion, and average comments/likes per post as the most discriminative attributes.
In conclusion, the study provides strong empirical evidence that graph‑based co‑clustering alone cannot reliably detect sophisticated, stealthy like farms. By incorporating timeline behavior—both what users write and how their posts are interacted with—detection accuracy improves dramatically. The proposed approach is practical for deployment by social platforms, offering a scalable way to flag suspicious accounts without relying on real‑time synchronization signals that adversaries can easily evade. The authors suggest future work on integrating multimodal signals (image/video metadata), real‑time streaming analysis, and adaptive models to keep pace with evolving farm strategies. This research thus contributes a robust, behavior‑centric methodology to the broader effort of preserving authenticity in online social networks.
Comments & Academic Discussion
Loading comments...
Leave a Comment