Improving Image Captioning by Concept-based Sentence Reranking
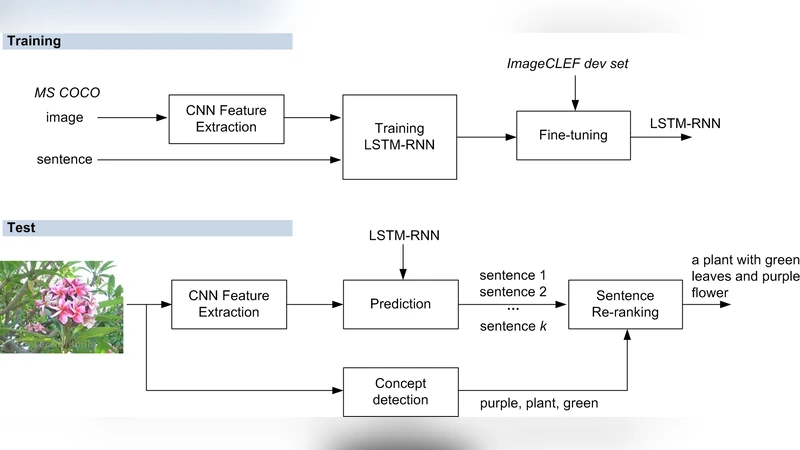
This paper describes our winning entry in the ImageCLEF 2015 image sentence generation task. We improve Google’s CNN-LSTM model by introducing concept-based sentence reranking, a data-driven approach which exploits the large amounts of concept-level annotations on Flickr. Different from previous usage of concept detection that is tailored to specific image captioning models, the propose approach reranks predicted sentences in terms of their matches with detected concepts, essentially treating the underlying model as a black box. This property makes the approach applicable to a number of existing solutions. We also experiment with fine tuning on the deep language model, which improves the performance further. Scoring METEOR of 0.1875 on the ImageCLEF 2015 test set, our system outperforms the runner-up (METEOR of 0.1687) with a clear margin.
💡 Research Summary
The paper presents the winning system for the ImageCLEF 2015 image sentence generation task. The core idea is to improve a state‑of‑the‑art image captioning model (Google’s CNN‑LSTM) by adding a concept‑based sentence reranking stage that treats the caption generator as a black box. First, a CNN‑LSTM model generates a set of k candidate captions for a given image using beam search; each candidate receives a confidence score (sentScore) from the model. In parallel, a separate concept detection module predicts m visual concepts that are likely to be present in the image. Two concept detectors are explored: (1) Neighbor Voting (NeiVote), which retrieves visually similar images from a large Flickr collection and counts the frequency of tags in their annotations, and (2) Hierarchical Semantic Embedding (HierSE), which embeds both images and WordNet concepts into a Word2Vec space and ranks concepts by cosine similarity. For each candidate caption, the average confidence of the concepts that appear in the sentence is computed (concScore). The final reranked score is a linear combination: newScore = θ·concScore + (1‑θ)·sentScore, where θ ∈
Comments & Academic Discussion
Loading comments...
Leave a Comment