Bounded link prediction for very large networks
Evaluation of link prediction methods is a hard task in very large complex networks because of the inhibitive computational cost. By setting a lower bound of the number of common neighbors (CN), we propose a new framework to efficiently and precisely evaluate the performances of CN-based similarity indices in link prediction for very large heterogeneous networks. Specifically, we propose a fast algorithm based on the parallel computing scheme to obtain all the node pairs with CN values larger than the lower bound. Furthermore, we propose a new measurement, called self-predictability, to quantify the performance of the CN-based similarity indices in link prediction, which on the other side can indicate the link predictability of a network.
💡 Research Summary
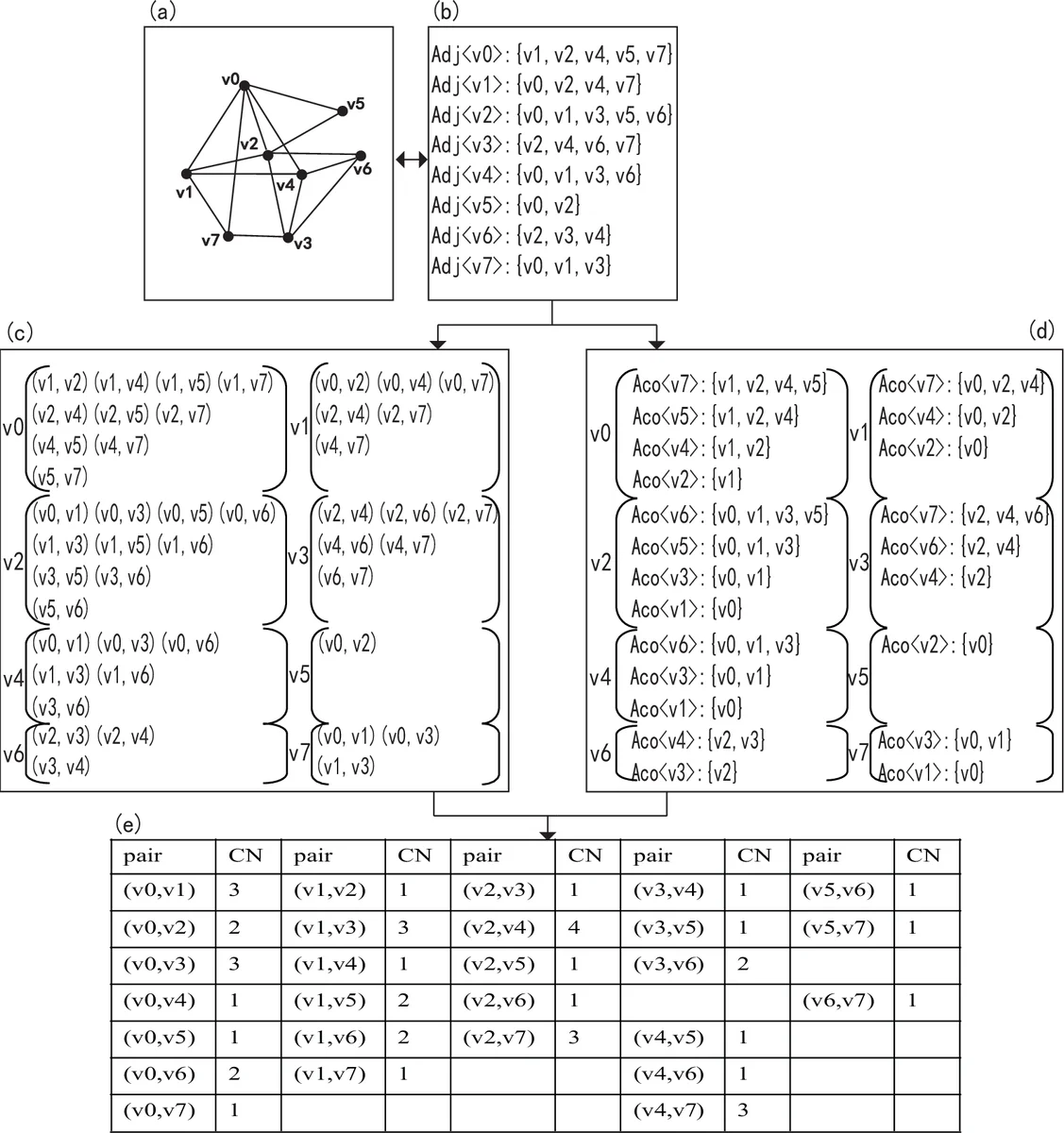
The paper tackles the long‑standing scalability problem of link prediction in massive complex networks, where computing similarity scores for all non‑adjacent node pairs is prohibitively expensive. The authors focus on the simplest and most widely used local similarity measure, the Common Neighbors (CN) index, and introduce a novel “bounded” framework that sets a lower bound L on the CN value. Only node pairs whose CN exceeds L are retained for further processing, dramatically reducing the number of candidate pairs.
To achieve this reduction efficiently, the authors build on the classic MapReduce‑based CN computation schemes (pair‑generating and vectorization). They first observe that real‑world networks are highly heterogeneous and scale‑free: a tiny fraction of “hub” nodes have very high degree, while the majority have low degree. Consequently, the distribution of CN values is heavily skewed—most pairs have small CN, and only a few have large CN. By exploiting this property, the authors devise two lemmas that enable aggressive pre‑filtering before the Map phase. Lemma 1 states that any node whose degree exceeds L cannot belong to a pair with CN > L; therefore all pairs containing such a node can be ignored. Lemma 2 is the converse: if a node appears in at most L adjacency lists after the first filtering, it also cannot contribute to a pair with CN > L. Applying these lemmas removes a large portion of the adjacency information, shrinking both the amount of data shuffled between Map and Reduce and the number of intermediate key‑value pairs.
The resulting algorithm proceeds in four steps: (1) compute node degrees and discard adjacency entries of nodes with degree > L; (2) count how many adjacency lists each remaining node appears in and discard nodes that appear ≤ L times; (3) run the standard Map function on the pruned adjacency lists, emitting (node‑pair, 1) for each neighbor pair; (4) Reduce aggregates the counts to obtain CN values, and finally outputs only those pairs whose CN > L. Because the pruning is performed locally before any network communication, the algorithm scales linearly with the number of edges that survive the filtering, and the MapReduce framework naturally parallelizes the remaining work across a cluster. Empirical tests on six large real‑world networks (social, biological, and scientific collaboration graphs) show that with modest L (e.g., 3–5) the runtime is reduced by an order of magnitude compared with unbounded MapReduce implementations, while memory consumption and network traffic drop dramatically.
Beyond computational efficiency, the authors critique traditional evaluation metrics such as precision and AUC, which become unreliable on huge sparse graphs: precision tends toward zero because the complement graph contains vastly more non‑edges, and AUC exhibits high variance. To address this, they propose a new metric called “self‑predictability.” Self‑predictability is defined as the proportion of node pairs with CN > L that are actually linked in the original graph. In other words, it directly measures how well the CN > L condition predicts real edges in a given network. Experiments reveal self‑predictability values ranging from 0.7 to 0.9 across the test datasets, indicating that the bounded CN criterion captures a substantial amount of the true link structure while discarding the overwhelming majority of irrelevant pairs.
The paper’s contributions are threefold: (1) a theoretically justified, lower‑bound‑driven filtering technique that reduces the effective computational complexity of CN‑based link prediction to near‑linear in the size of the filtered graph; (2) an implementation that integrates this filtering seamlessly into the MapReduce paradigm, achieving substantial speed‑ups on multi‑core clusters for networks with millions of nodes and edges; (3) the introduction of self‑predictability as a network‑specific performance indicator that overcomes the shortcomings of precision and AUC in the large‑scale regime.
Overall, the work provides a practical solution for real‑time or near‑real‑time link recommendation in massive heterogeneous networks, especially when the goal is to identify “hot” nodes (high‑degree hubs) and their likely connections. The bounded approach can be readily combined with other similarity measures or extended to weighted and directed graphs, opening avenues for future research in scalable network inference.
Comments & Academic Discussion
Loading comments...
Leave a Comment