A mathematical motivation for complex-valued convolutional networks
A complex-valued convolutional network (convnet) implements the repeated application of the following composition of three operations, recursively applying the composition to an input vector of nonnegative real numbers: (1) convolution with complex-v…
Authors: Joan Bruna, Soumith Chintala, Yann LeCun
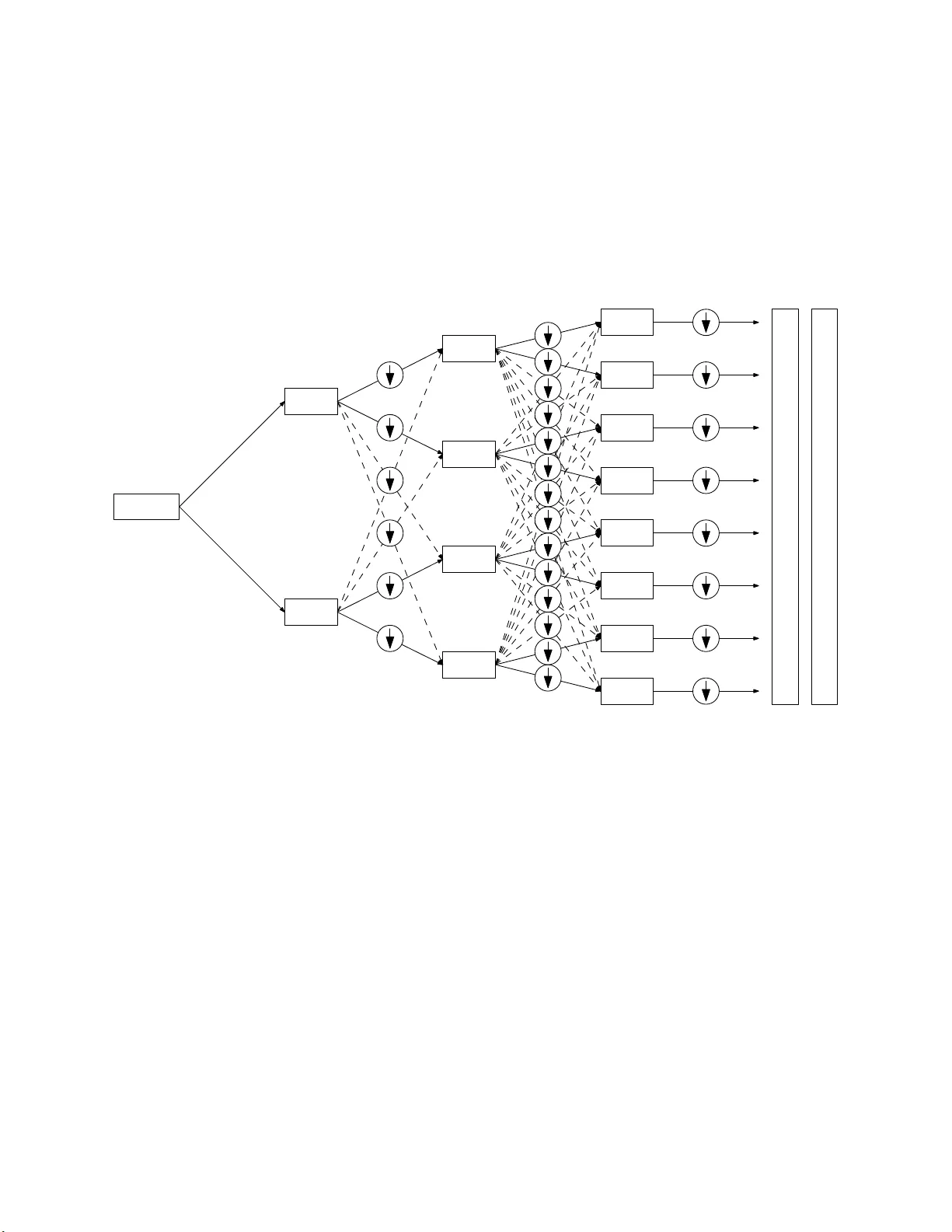
A Mathematical Mo tiv ation for Complex-v alued Con v olutional Net works Joan Bruna, Soumith Chin ta la, Y ann LeCun, Serk an Pian tino, Arth ur Szlam, Mark T ygert F aceb o ok Artificial In tell igence Researc h , 1 F aceb o ok W ay , Menlo Park, California 94025 Keyw ords: dee p learning, neural netw orks, harm onic analysis Abstract: A complex-v alued con v olutio nal net w ork (c on vnet) implemen ts the rep eated application of the follo w ing comp osition of thr ee op erations, recursively applying the comp osition to an inpu t v ector of non n egativ e real n um b ers: (1) con v olution with complex-v alued v ectors follo w ed by (2) taking the absolute v alue of ev ery en try o f the resulting vecto rs follo wed b y (3) lo cal av eraging. F or pro cessing real-v alued random v ect ors, complex-v alued con vnets can b e view ed as “data-driv en m ultiscale wind o w ed p o w er sp ectra,” “data-driv en multiscale windo w ed absolute sp ectra,” “data- driv en m ultiw a v elet absolute v alues,” or (in their most general configuration) “data-driv en nonlin ear m ultiw a v elet pac kets.” In deed, complex-v alued con vnets ca n calculate m ultiscale windo w ed sp ectra when the convnet filters are windo w ed complex-v alued exp onentia ls. S tandard real-v alued con vnets, using rectified linear un its (ReLUs), sigmoidal (for example, logistic or tanh) nonlinearities, max. p o oling, etc., do not obviously exhibit the same exact corresp ondence with d ata-driven wa v elets (whereas for complex-v alued convnets, the corresp onden ce is m uc h more than just a v ague analogy). Courtesy of the exact corresp onden ce, the remark ably rich and rigorous b o dy of mathematical analysis for w a velet s applies directly to (complex-v alued) convnets. 1 In tro duction Con v olutional net works (con vn ets) ha v e b ecome in creasingly imp ortan t to artificial in tellige nce in recen t ye ars, as review ed by LeCun et al. (2015 ). The pr esen t p ap er presents a theoretical argument for complex-v alued convnets and their remark able p erform ance; complex-v alued convnets turn out to calculate “data-driv en multiscale window ed sp ectra” charac terizing certain stochastic pro cesses common in the m o deling of time series (suc h as audio) and natural images (including patterns and textures). W e motiv ate the constru ction of such multiscale sp ectra v ia “local a v erages of m ultiw a v elet absolute v alues” or, more generally , “nonlinear multiw a v elet pac k ets.” A textb ook treatmen t of all concepts and terms used ab o v e and b elo w is giv en by Mallat (2008). F urth er information is a v ailable in the original work of Daub ec hies (1992), Mey er (1993), C oifman et al. (1994) , Coifman and Donoho (1995), Simoncelli and F reeman (1995) , Mey er and Coifman (1997 ), LeCun et al. (1998), Donoho et al. (2003 ), Sriv asta v a et al. (2003), Rabiner and Schafer (2007 ), and Mallat (20 08), for example. The w ork of Haensch and Hellwic h (2010), Malla t (201 0), P oggio et al. (2012 ), Bruna and Malla t (2013), Bruna et al. (20 15), and Chin tala et al. (2 015) also dev elops complex-v alued convnets, p ro viding copious applications and numerical exp eriment s. A related, m ore soph isticated connection (to ren orm alizatio n group theory) is give n by Meht a and Sc h w ab (2014). Our exp osition relies on nothing but the b asic signal pr o cessing treated by Mallat (2008 ). Via th e connections d iscussed b elo w, the ric h, rigorous mathematical analysis survey ed b y Daub echies (1992), Meye r (199 3), Mallat (2008), and others app lies directly to complex-v alued con vnets. 1 Citing such connections, the presen t pap er’s anonymous reviews su ggested viewing complex- v alued convnets as a kind of b aseline arc hitecture f or m uc h of the d eep lea rning reviewed b y LeCun et al. (201 5). Section 6 pr esen ts n umerical analyses corrob orating this viewp oin t. Ha ving su c h a theoretical basis for deep learning could h elp in paring d o wn the com binatorial explosio n o f p ossibilities for future devel opment s, while p robably also illuminating fur th er p ossibilities. The p r esen t pap er p ro ceeds as follo w s: Section 2 r eviews stationary sto c hastic pro cesses and their s p ectra. Section 3 reviews locally stationary stochasti c pro cesses and the connection of their sp ectra to stages in a complex-v alued con vnet. Sec tion 4 in tro duces multiscale (multiple stages in a con vnet). Section 5 describ es th e fitting/learning/training that the connection to convnets facilitat es. Section 6 br iefly compares on a common b enchmark the accuracies for the complex- v alued con vnets of Chinta la et al. (2015) to those for the scattering transforms of Mallat (2010) and for th e standard real-v alued convnets of Kr izhevsky et al. (2012). Section 7 generalizes and summarizes the aforemen tioned sections. 2 Stationary sto c hastic p ro cesses F or simplicit y , w e fi rst limit consideration to the sp ecial case of a doubly infin ite sequence of nonnegativ e random v ariables X k , where k r anges o v er the in tegers. Th is in put data will b e the result of con v olving an unmeasured indep enden t and identica lly distributed (i.i.d.) sequence Z k , where k ranges o v er the int egers, with an u nkno wn sequence of real n umbers f k , where k r anges o v er the inte gers (this latter sequence is kno wn as a “filter,” whereas the i.i.d. sequence is known as “white noise”): X j = ∞ X k = −∞ f j − k Z k (1) for an y int eger j . Such a sequence X k , with k ranging o v er the in tegers, is a (strictly) “stationary sto c hastic pr o cess.” The term in ology “strictly stationary” refers to the fact th at lagging or s hifting the pro cess preserv es the probabilit y distribution of the pro cess: indeed, for any integ er l , the sh ift Y k = X k − l , wh ere k ranges o v er the in tege rs, satisfies Y j = ∞ X k = −∞ f j − k Z ′ k (2) for an y in teger j , wh er e Z ′ k = Z k − l ; the sequence Z ′ k , with k ranging o v er the in tegers, is i.i.d. with the same distribution as Z k , wh ere k ranges o v er the in tege rs. The asso ciated “absolute sp ectrum” is ˜ X ( ω ) = lim n →∞ E 1 √ 2 n + 1 n X k = − n e − ik ω X k (3) for an y real num b er ω (usually we consider not just an y , bu t in stead restrict consider ation to a sequence r unning from 0 to ab out 2 π ). Please n ote that lagging or sh ifting the pr o cess changes neither the probability distribu tion of the pro cess (sin ce the pro cess is stationary) nor the absolute sp ectrum: for any in teger l , the shift Y k = X k − l yields ˜ Y ( ω ) = ˜ X ( ω ) for an y real n um b er ω , due to the absolute v alue in equation 3. Similarly , the asso ciated “p o w er sp ectrum” is ˜ ˜ X ( ω ) = lim n →∞ E 1 √ 2 n + 1 n X k = − n e − ik ω X k 2 (4) 2 for an y real num b er ω ; there is an extra squaring under th e exp ectatio n in equation 4 compared to equation 3. Again, lagging or shiftin g the pro cess change s neither the probability d istribution of the pro cess nor the p o w er sp ectrum: for an y in teg er l , the shift Y k = X k − l yields ˜ ˜ Y ( ω ) = ˜ ˜ X ( ω ) for an y real n um b er ω , due to the absolute v alue in equation 4. The remainder of the p r esen t pap er fo cuses on the absolute sp ectrum; most of the discu s sion applies to the p o w er sp ectrum, too. Remark 1. T he absolute s p ectrum can b e more robust than the p ow er sp ectrum, in the same sense that the mean absolute deviatio n can b e more robu st than the v ariance or standard deviation. The p o w er sp ectrum is more fund amen tal in a certain sense, yet the abs olute sp ectrum ma y b e p referable for applicatio ns to mac hine learning. W e conjecture that b oth can work ab ou t the same. W e fo cus on the absolute sp ectrum to simplify the exp osition. 3 Lo cally stationary sto c hastic pro cesses In practice , the input data is seldom strictly stationary , b ut u sually only locally stationary , that is, equation 1 b ecomes X j = ∞ X k = −∞ f ( j ) j − k Z k (5) for an y inte ger j , where f ( j ) k c hanges m uc h more slowly when c hanging j than when c hanging k . T o accommodate such data, w e introdu ce window ed sp ectra; for an y ev en nonnegativ e-v alued sequence g k , with k ranging through the inte gers — this sequence could b e samples of a Gaussian or any other win do w suitable for Gab or analysis (the data itself will determine g du ring training) — w e consider ˜ X l ( ω ) = 1 2 n + 1 n + l X j = − n + l 1 √ 2 n + 1 ∞ X k = −∞ e − ik ω g k − j X k (6) for an y int eger l , with some p ositiv e integ er n . The extra summation in equation 6 a v erages a wa y noise and is a kind of approxima tion to the exp ected v alue in equation 3. Usually g k is fairly close to 1 for k = − n , − n + 1, . . . , n − 1, n , and g k is fairly close to 0 for | k | > n , making a reasonably smo oth transition b et ween 0 and 1. T he most imp ortan t difference b et w een equation 3 and equation 6 is the absence of a limit in the latter (hence the terminology , “local” sp ectrum ). Due to the absolute v alue, equation 6 is equ iv alen t to ˜ X l ( ω ) = 1 2 n + 1 n + l X j = − n + l 1 √ 2 n + 1 ∞ X k = −∞ g j − k ( ω ) X k (7) for any even nonn egativ e-v alued sequ ence g k , with k ranging th rough the in teg ers, where g k ( ω ) = e ik ω g k (8) for an y intege r k (“ev en” means that g − k = g k for ev ery integ er k ). Please note that the r igh t-hand side of equation 7 is just a conv olution follo w ed by the absolute v alue follo w ed b y local a v eragi ng; this will facilitate fitting/learning/training using d ata — enabling a “data-drive n” approac h — in Section 5. 3 4 Multiscale In most cases, the ideal c hoices of n an d wid th of the window in equation 7, that is, the ideal n um b er of indices for whic h g k is su b stan tially nonzero, are far from ob vious. Often, in fact, m ultiple widths are relev an t (sa y , w ider for lo w er-frequency v ariations than for higher frequency). Not knowing the ideal a priori, we use m ultiple win do ws on m ultiple scales. An esp ecially efficien t m ultiscale implement ation pr o cesses the results of the lo w est-frequency c hannels r ecursiv ely . F or the low est frequency , ω = 0, and when X k is n onnegativ e for ev ery in teger k (for example, the input X k could b e the ˜ X k arising fr om previous pro cessing), equation 7 simplifies to ˜ X l (0) = 1 √ 2 n + 1 ∞ X k = −∞ h l − k X k (9) for any in teger l , where h l = 1 2 n + 1 n + l X j = − n + l g j (10) for an y inte ger l , and again g j , w ith j ran ging thr ough the inte gers, is an even sequence of non- negativ e real num b ers (“ev en” means that g − j = g j for ev ery in teger j ). The result of equation 9 is s im p ly a con v olution with the in p ut sequen ce, and further con v olutions — sa y v ia r ecursiv e pro cessing of the form in equation 7 — can undo this con volution and set the effectiv e wind o w ho w ev er desired in later stage s. The d econ v olution and sub sequen t conv olution w ith the windo w ed exp onenti al of a later s tage is n umerically stable if the later w indo w is wider than the p r eceding. In particular, recurs iv ely p ro cessing the zero-frequency c hannels in this w a y can implemen t a “w a v elet transform” (if ea c h recursiv e stage considers only t w o v alues for ω , one zero and one nonzero — s ee Figure 1) or a “multiw av elet transform ” (if eac h recur s iv e stage consid er s multiple v alues for ω , with one of the v alues b eing zero — see Figure 2). F or m ultidimensional signals, m ultiw a v elets d etect lo cal directionalit y b ey ond w h at w a velet s pr o vide. If we r ecursiv ely p ro cess the higher-frequency c hannels, too, then we obtai n a “nonlinear w a vele t p ac ket transform” or a “nonlinear m ultiw a vele t pac k et transform” — a kind of nonlinear iterated filter b ank — see Figure 3. Linearly reco m bining the d ifferen t frequency c hannels ma y help r ealize lo cal rotation-in v ariance and other p oten tia lly desirable prop erties (indeed, Mallat (2010) did this for rotations and other trans f ormations) — including generating harmonics when pr o cessing audio signals. The transforms jus t discu s sed are undecimated, but in terlea ving appropriate decimation or subsampling applied to the sequences yields th e usual d ecimated transforms. Remark 2. In p r actice, decimation or subsampling is imp ortan t to av oid o v erfitting in the data- driv en approac h d iscussed b elo w, by limiting the n umber of degrees of freedom appropriately . Even when the signal is not a strictly stationary sto chastic pro cess, the av eraging in equation 7 — the leftmost summation — p erforms th e “cycle sp in ning” of Coifman and Donoho (1995) to a v oid artifacts that w ou ld otherwise arise due to win d o ws’ partitioning after subsampling. The a v eraging reduces the v ariance; w ider a v eraging w ould fur ther reduce the v ariance. Remark 3. Sequences that are finite rather than doubly infinite pro vide only enough information for estimating a smo othed version of the s p ectrum. Alternativ ely , a finite amoun t of d ata p ro vides information for estimating multiscale windo w ed sp ectra yielding time-frequency (or space-F ourier) resolution similar to the multiresolution analysis of wa v elets. Remark 4. SIFT, HOG, SURF, etc. of Lo we (1999), Low e (2004), Dalal and T riggs (2005) , Ba y et al. (2008), and others are m ore analogous to the m ultiw a v ele t arc hitecture of Figure 2 th an to the more general w a v elet -pac k et architec ture of Figure 3. 4 5 Fitting/learning/trai ning The “m ultiw a velet transform” constitutes a d esirable baseline m o del. W e can easily adapt to the data th e c hoices of win do ws and ind eed the wh ole r ecursiv e structure of th e p ro cessing (wh ether restricting th e recursion to the zero-frequency c hannels, or also allo wing the recursiv e pro cessing of higher-frequency c hannels). Viewing the co n v olutional filters in equ ation 7 that serv e as wind o w ed exp onenti als as parameters, the d esirable baseline is just one mem b er of a parametric family of mo dels. This parametric family is kno wn as a “complex-v alued con v olutional net w ork.” W e can fit (that is, learn or train) the parameters to the data via optimiza tion pro cedures su c h as sto c has- tic gradient descent in conju nction with “bac kpropagatio n” (bac kpropagation is the c hain ru le of Calculus applied to calculate gradien ts of our recursiv ely comp osed op erations). F or “sup ervised learning,” w e optimize according to a sp ecified ob jective , u sually using the m ultiscale sp ectra as inputs to a scheme for classification or regression, as detailed by LeCun et al. (1998), f or example. Remark 5. In consonance with the “b est-basis” approac h of Coifman et al. (1994) and S aito and Coifman (1995), a p otentia lly m ore efficient p ossibilit y is to restrict the con v olutional fi lters in equ ation 7 to b e windo w ed exp onen tials that are designed completely a priori, aside from one o v erall scaling factor p er filter, fitting/lea rning/training only the scaling factors. Ho w b est to effect this appr oac h is an op en question. 6 Numerical exp erimen ts The follo wing reports t he classification acc uracies for the complex-v alued con vnets of Chin tala et al. (2015), the standard real-v alued convnets of Krizhevsky et al. (2012), and th e scattering transforms of Oy allon and Mallat (20 15), on a b enchmark data set, “CIF AR-10 ,” fr om Krizhevsky (2009 ) (CIF AR-10 conta ins 50,000 images in its training set and 10,000 images in its testing s et; eac h image falls into one of ten classes, is full-color, and consists of a 32 × 32 grid of pixels): According to T able 4 of O y allon and Mallat (2015), the scattering transforms attain an error rate of 18% on the test set, after training their classifiers on the training s et. According to Section 3.3 of Kr izhevsky et al. (2012), a standard real-v alued con vnet attains an err or rate of 13% on the test set without th e “lo cal resp onse normalizati on” of that Section 3.3, an d attains 11% with the lo cal r esp onse normalization. The complex-v alued con vnets d etailed in Chintala et al. (2015) attain an error rate of 12% on th e test set, at least wh en u sing a larger net and training with enou gh iterations for the test error to settle do wn and conv erge (for complex-v alued con vnets, accuracy seems to impro v e as the net b ecomes larger — for the error rate of 12%, a n et eigh t times the size of that rep orted in T able 1 of Ch intala et al. (2015) was sufficien t, usin g the same k ernel sizes and other parameter settings as for T able 1). Augmenting the training images with their mirror images impro v ed con v ergence to the rep orted accuracies. All in all, the extensiv ely trained r eal- and complex-v alued convnets yielded similar error rates, whic h are ab ou t a third less than those wh ich scattering transforms attained. Of course, the fitting/learning/training inv olv ed for classification with the scattering transf orms is muc h less extensiv e. 7 Conclusion While the ab o v e concerns X k , where k ranges o ver th e integers, extension to analyzing X j,k , where j and k r ange o v er th e integ ers, is str aigh tforw ard — the latter could b e a “lo cally homogeneous random fi eld.” Also, th e infi nite range of the integ ers is far from essential; imp lemen tations on computers obvio usly use only fin ite sequences. Moreo v er, the ab o v e construction is ap p ropriate 5 for pr o cessing an y lo cally stationary sto c hastic p ro cess, not j u st filtered wh ite noise. F or instance, the construction can enable a multiresol ution an alysis of “regularit y” (or “smo othness”) that easily distinguishes b et ween low-pass fi ltered i.i.d. Gaussian noise and a pulse train or s in usoid with a random phase offset (for example, X k = 1 + sin( π ( k + J ) / 1000) for an y in teger k , where J is an in teger dra wn un iformly at random f rom 1, 2, . . . , 2000). More generally , the construction should enable discrimin ating b etw een man y int eresting cla sses of sto c hastic pro cesses, commensur ate with the abilit y of m ultiw a v ele t-based multiresol ution analysis to measure “regularit y ,” “in termittency ,” distributional c haracteristics (sa y , Ga ussian versus Poisso n), etc. An y globally stationary sto c hastic pro cess — with or without in termittent fl uctuations — can b e mo d eled as ab o v e as a lo cally stationary stochastic pr o cess (of course, Bruna et al. (2015) treat the former directly , to great adv anta ge in the analysis of homogeneous turb ulence and other p henomena from statistical p h ysics). Ev ery mo del in the p arametric family constituting the complex-v alued con vnet calculates relev ant features, window ed s p ectra of the form in equation 6 and equation 7. The absolute v alues i n equation 6 and equation 7 are the ke y n onlinearit y , a reflection of the lo cal statio narit y — the lo cal translation-in v ariance — of the pro cess and its r elev an t features. Ac kno wledgmen ts W e w ould lik e to th ank Keith Adams, Lub omir Bourdev, Rob F ergu s , Arm and Joulin, Manohar P aluri, Ch ristian Puh rsc h, Marc’Aurelio Ranzato, Ben Rec ht , and Rac hel W ard. 6 ω 6 =0 ω =0 ω 6 =0 ω 6 =0 ω 6 =0 ω =0 ω =0 ω =0 input e f a t u r e v e c t o r s Figure 1: A flo w c hart for the “w a v elet transform” of an inp u t ve ctor: eac h b o x “ ω =0” corresp onds to equation 7 with ω =0 or (equiv alen tly) to equ ation 9; eac h b o x “ ω 6 =0” corresp onds to equation 7 — con v olution follo wed by taking the absolute v alue of ev ery entry follo wed b y lo cal a v eraging; eac h circle “ ↓ ” corresp onds to su b sampling (sa y , retaining only ev ery other en try) 7 3 input e f a t u r e 2 1 0 3 2 1 0 3 2 1 0 s Figure 2: A flow c hart for th e “m ultiw a v elet transform” of an inpu t vec tor: e ac h b o x “0” corre- sp onds to equation 7 with ω =0 or (equiv alen tly) to equ ation 9; eac h b o x “1,” “2,” or “3” corresp onds to equation 7 for different conv olutional fi lters, but alwa ys with conv olution f ollo wed b y taking the absolute v alue of ev ery en try follo w ed by lo cal a v eraging; eac h circle “ ↓ ” corresp onds to subs ampling (sa y , retaining only ev ery four th en tr y) 8 ω 6 =0 input e f a t u r e v e c t o r s ω =0 ω 6 =0 ω =0 ω 6 =0 ω =0 ω 6 =0 ω =0 ω 6 =0 ω =0 ω 6 =0 ω =0 ω 6 =0 ω =0 Figure 3: A flow chart for the “nonlinear wa vel et pac k et t ransform” of an input v ector: eac h b o x “ ω = 0” corresp onds to equation 7 with ω =0 or (equiv alen tly) to equation 9; eac h b o x “ ω 6 =0” corresp onds to equation 7 — co n v olution follo w ed by taking the absolute v alue of e v ery entry follo wed by local a v eraging; eac h circle “ ↓ ” corresp onds to subsampling (sa y , retaining only ev ery other entry); the dashed arrows can in v olv e do wnw eigh ting the asso ciated sum mands (and the con v olutio nal filter can b e different for eve ry arro w); Figure 1 is essentia lly a sp ecial case of the present figu r e for whic h some of the con v olutional fi lters simply d econ v olve the p receding lo cal a v erag ing (omitting some of the subsampling) 9 References Ba y , H., Es s , A., T uytelaa rs, T., and Gool, L. V. (2008). Sp eeded-up robu st features (SURF). Computer Vision Image Understanding , 110(3 ):346–3 59. Bruna, J . and Mal lat, S. (2013). Inv arian t scattering con v olutional netw orks. IE EE T r ans. Pattern Ana lysis Machine Intel. , 35( 8):1872 –1886. Bruna, J., Mallat, S ., Bacry , E., and Muzy , J.-F. (2015). In termitten t pro cess analysis with scat- tering moments. An n. Statist. , 43(1):323 –351. Chinta la, S., Ra nzato, M., Szla m, A., Tian, Y., T ygert, M., a nd Zarem ba, W. (2015). Scale- in v arian t learnin g and con v olutional n etw orks. T echnical Rep ort 150 6.08230 , arXiv. Coifman, R. R. and Donoho, D. (1995) . T ranslation-in v arian t den oising. In Antoniadis, A. and Opp enheim, G., editors, Wavelets and Statistics , volume 103 of L e c tur e Notes in Statistics , pages 125–1 50. Spr inger. Coifman, R. R., Mey er, Y., Qu ak e, S., and Wic k erhauser, M. V. (1994). S ignal pro cessing and compression with w a velet pac k ets. In Byrnes, J. S., Byrn es, J. L., Hargrea ves, K. A., and Berry , K., editors, Wavelets and Their Applic ations , v olume 442 of NA TO ASI Series C: Mathematic al and Physic al Scie nc es , pages 363– 379. Springer. Dalal, N. and T r iggs, B. (2005). Histo grams of orien ted gradient s for h uman detection. In IEEE Computer So ciety Conf. Computer Vision and Pattern R e c o gnition 2005 , v olume 1, pages 886– 893. IEEE. Daub ec hies, I. (1992). T en L e ctur es on Wavelets . CBMS-NSF Regional C onference Series in App lied Mathematics. S IAM. Donoho, D., Mallat, S., von Sachs, R., and Samuelides, Y. (2003). Lo cally stationary co v ariance and signal estimatio n with m acrotiles. IEEE T r ans. Signal Pr o c essing , 51(3):6 14–627 . Haensc h, R. and Hellwic h, O. (201 0). Complex-v alued conv olutional neural netw orks for ob j ect detection in P olSAR data. In 8th Eur op e an Conf. EU SAR , pages 1–4. IEEE. Krizhevsky , A. (2009). Learning multiple la y ers of features from tiny images. T ec hn ical Rep ort Master’s Thesis, Univ ersit y of T oronto Departmen t of Computer Science. Krizhevsky , A., Su tsk ev er, I., and Hin ton, G. (2012). ImageNet classification with deep con v olu- tional neural net w orks. In A dvanc es in Neur al Information Pr o c essing Systems , p ages 1097–11 05. Curran Asso ciates. LeCun, Y., Bengio , Y., and Hin ton, G. (2015). Deep learnin g. Natur e , 521(7 553):43 6–444. LeCun, Y., Bottou, L., Bengio, Y., an d Haffner, P . (1998). Gradien t-based learning applied to do cument recog nition. Pr o c. IEEE , 86(11):22 78–2324. Lo w e, D. G. (1999 ). Ob ject r ecognition from lo cal scale-in v arian t features. In Pr o c. 7th IEEE Internat. Conf. Computer Vision , v olume 2, p ages 1150–11 57. IEE E. Lo w e, D. G. (2004 ). Distinctiv e image features fr om scale-in v arian t keypoints. Internat. J. Com- puter Vision , 60(2):91–11 0. 10 Mallat, S . (2008). A Wavelet T our of Sig nal Pr o c essing: the Sp arse Way . Academic Press, 3rd edition. Mallat, S. (2010). Recursiv e interferometric rep r esen tations. In Pr o c. EUSIPCO Conf. 2010 , pages 716–7 20. EURASIP . Meh ta, P . and Sch w ab , D. J. (2014). An exact mapp ing b et w een the v ariatio nal renormalization group and deep learning. T ec hnical Rep ort 1410.38 31, arXiv. Mey er, Y. (1993). Wavelets and Op er ators , v olume 37 of Cambridge Studies in A dvanc e d Mathe- matics . Cam bridge Univ ersit y Press. Mey er, Y. and Coifman, R. R. (1997). Wavelets: Calder´ on-Zygmund and Multiline ar Op e r ators , v olume 48 of Cambridge Studies in A dvanc e d Mathematics . Cam bridge Universit y Press. Oy allon, E. and Mallat, S. (2015). Deep r oto-translatio n scattering for ob ject classification. In IEEE Computer So ci e ty Conf. Computer Visi on and Pattern R e c o g nition 2015 , vo lume 1, pages 2865– 2873. IEEE. P oggio , T., Mutch, J., Leib o, J., Rosasco, L., and T acc hetti, A. (2012 ). The computational magic of th e v en tral stream: ske tc h of a theory (and w h y some d eep architec tures w ork). T ec h n ical Rep ort MIT-CS AIL-TR-2012-0 35, MIT CSAIL, Cam bridge, MA. Rabiner, L. R. and Sc hafer, R. W. (2007 ). Intr o duction to Digi tal Sp e e ch Pr o c essing , v olume 1 of F oundations and T r ends in Signal Pr o c essing . NO W. Saito, N. and C oifman, R. R. (1995). Lo cal discriminant bases and their applications. J . M ath. Imaging Vision , 5(4 ):337–3 58. Simoncelli, E. P . and F r eeman, W. T. (1995 ). The s teerable pyramid: a flexible architec ture for m ulti-scale d eriv ativ e computation. In Pr o c. Internat. Conf. Image Pr o c essing 1995 , v olume 3, pages 444–447. IEEE. Sriv asta v a, A., Lee, A. B., Sim on celli, E. P ., and Z h u, S. (2003). O n adv ances in statistical mo deling of natural images. J. Math. Imaging Vision , 18(1):17–33 . 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment