Deep, Convolutional, and Recurrent Models for Human Activity Recognition using Wearables
Human activity recognition (HAR) in ubiquitous computing is beginning to adopt deep learning to substitute for well-established analysis techniques that rely on hand-crafted feature extraction and classification techniques. From these isolated applic…
Authors: Nils Y. Hammerla, Shane Halloran, Thomas Ploetz
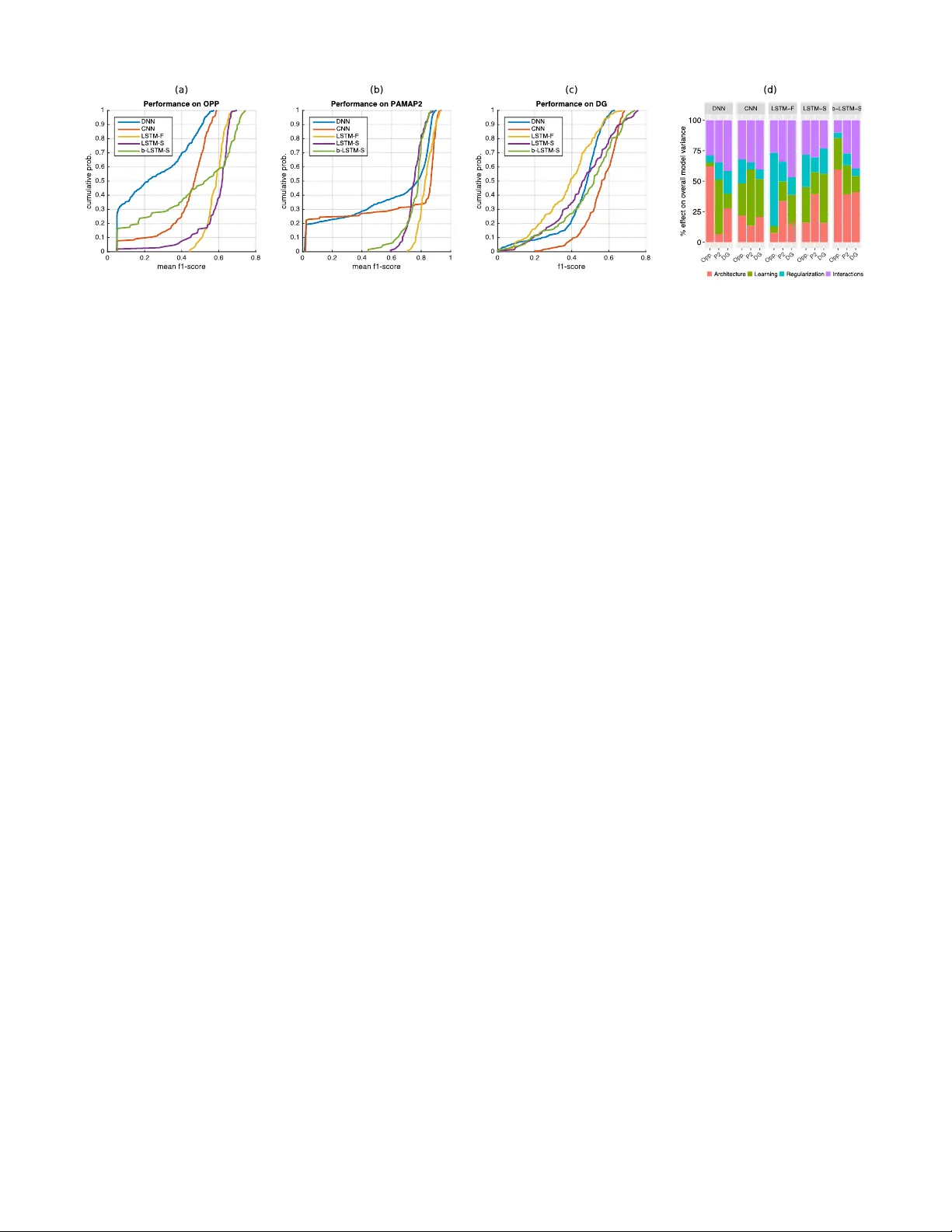
Deep, Con volutional, and Recurr ent Models for Human Acti vity Recognition using W earables Nils Y . Hammerla 1 , 2 , Shane Halloran 2 , Thomas Pl ¨ otz 2 1 babylon health, London, UK 2 Open Lab, School of Computing Science, Ne wcastle Uni versity , UK nils.hammerla@babylonhealth.com Abstract Human activity recognition (HAR) in ubiquitous computing is beginning to adopt deep learning to substitute for well-established analysis techniques that rely on hand-crafted feature extraction and classification techniques. From these isolated ap- plications of custom deep architectures it is, how- ev er, dif ficult to gain an o vervie w of their suit- ability for problems ranging from the recogni- tion of manipulative gestures to the segmentation and identification of physical activities like run- ning or ascending stairs. In this paper we rig- orously explore deep, con volutional, and recur - rent approaches across three representativ e datasets that contain mo vement data captured with wearable sensors. W e describe how to train recurrent ap- proaches in this setting, introduce a novel re gulari- sation approach, and illustrate how the y outperform the state-of-the-art on a lar ge benchmark dataset. Across thousands of recognition experiments with randomly sampled model configurations we in ves- tigate the suitability of each model for different tasks in HAR, explore the impact of hyperparam- eters using the fANO V A framework, and provide guidelines for the practitioner who wants to apply deep learning in their problem setting. 1 Introduction Deep learning represents the biggest trend in machine learn- ing over the past decade. Since the inception of the umbrella term the div ersity of methods it encompasses has increased rapidly , and will continue to do so driv en by the resources of both academic and commercial interests. Deep learning has become accessible to e veryone via machine learning frame- works like T orch7 [ Collobert et al. , 2011 ] , and has had sig- nificant impact on a variety of application domains [ LeCun et al. , 2015 ] . One field that has yet to benefit of deep learning is Human Activity Recognition (HAR) in Ubiquitous Computing (ubi- comp). The dominant technical approach in HAR includes sliding window segmentation of time-series data captured with body-worn sensors, manually designed feature extrac- tion procedures, and a wide variety of (supervised) classifica- tion methods [ Bulling et al. , 2014 ] . In many cases, these rel- ativ ely simple means suffice to obtain impressi ve recognition accuracies. Howe ver , more elaborate behaviours which are, for example, of interest in medical applications, pose a signif- icant challenge to this manually tuned approach [ Hammerla et al. , 2015 ] . Some work has furthermore suggested that the dominant technical approach in HAR benefits from biased ev aluation settings [ Hammerla and Pl ¨ otz, 2015 ] , which may explain some of the apparent inertia in the field of the adop- tion of deep learning techniques. Deep learning has the potential to have significant impact on HAR in ubicomp. It can substitute for manually designed feature extraction procedures which lack the robust physio- logical basis that benefits other fields such as speech recog- nition. Howe ver , for the practitioner it is difficult to select the most suitable deep learning method for their application. W ork that promotes deep learning almost always provides only the performance of the best system, and rarely includes details on how its seemingly optimal parameters were dis- cov ered. As only a single score is reported it remains unclear how this peak performance compares with the average during parameter exploration. In this paper we pro vide the first unbiased and systematic exploration of the peformance of state-of-the-art deep learn- ing approaches on three dif ferent recognition problems typi- cal for HAR in ubicomp. The training process for deep, con- volutional, and recurrent models is described in detail, and we introduce a novel approach to regularisation for recur- rent networks. In more than 4,000 experiments we inv estigate the suitability of each model for dif ferent tasks in HAR, ex- plore the impact each model’ s hyper -parameters have on per - formance, and conclude guidelines for the practitioner who wants to apply deep learning to their application scenario. Over the course of these experiments we discover that re- current netw orks outperform the state-of-the-art and that they allow novel types of real-time application of HAR through sample-by-sample prediction of physical acti vities. 2 Deep Learning in Ubiquitous Computing Mov ement data collected with body-worn sensors are multi- variate time-series data with relati vely high spatial and tem- poral resolution (e.g. 20Hz - 200Hz). Analysis of this data in ubicomp is typically following a pipeline-based approach [ Bulling et al. , 2014 ] . The first step is to segment the time- Figure 1: Models used in this work. From left to right: (a) LSTM network hidden layers containing LSTM cells and a final softmax layer at the top. (b) bi-directional LSTM network with two parallel tracks in both future direction (green) and to the past (red). (c) Con volutional netw orks that contain layers of con volutions and max-pooling, followed by fully-connected layers and a softmax group. (d) Fully connected feed-forward netw ork with hidden (ReLU) layers. series data into contiguous segments (or fr ames ), either dri ven by some signal characteristics such as signal energy [ Pl ¨ otz et al. , 2012 ] , or through a sliding-windo w segmentation ap- proach. From each of the frames a set of features is ex- tracted, which most commonly include statistical features or stem from the frequency domain. The first deep learning approach explored to substitute for this manual feature selection corresponds to deep belief net- works as auto-encoders, trained generativ ely with Restricted Boltzmann Machines (RBMs) [ Pl ¨ otz et al. , 2011 ] . Results were mixed, as in most cases the deep model was outper- formed by a combination of principal component analysis and a statistical feature extraction process. Subsequently a variety of projects have explored the use of pre-trained, fully-connected networks for automatic assessment in Parkin- son’ s Disease [ Hammerla et al. , 2015 ] , as emission model in Hidden Marko v Models (HMMs) [ Zhang et al. , 2015; Alsheikh et al. , 2015 ] , and to model audio data for ubicomp applications [ Lane et al. , 2015 ] . The most popular approach so far in ubicomp relies on con- volutional netw orks. Their performance for a variety of ac- tivity recognition tasks was explored by a number of authors [ Zeng et al. , 2014; Ronao and Cho, 2015; Y ang et al. , 2015; Ronaoo and Cho, 2015 ] . Furthermore, con volutional net- works hav e been applied to specific problem domains, such as the detection of stereotypical mov ements in Autism [ Rad et al. , 2015 ] , where they significantly improved upon the state- of-the-art. Individual frames of mov ement data in ubicomp are usu- ally treated as statistically independent, and applications of sequential modelling techniques like HMMs are rare [ Bulling et al. , 2014 ] . Ho wever , approaches that are able to exploit the temporal dependencies in time-series data appear as the natural choice for modelling human mo vement captured with sensor data. Deep recurrent networks, most notably those that rely on Long Short-T erm Memory cells (LSTMs) [ Hochreiter and Schmidhuber , 1997 ] , have recently achiev ed impressive performance across a variety of scenarios (e.g. [ Gregor et al. , 2015 ] ). Their application to HAR has been e xplored in tw o settings. First, [ Nev erova et al. , 2015 ] in vestigated a v ari- ety of recurrent approaches to identify indi viduals based on mov ement data recorded from their mobile phone in a large- scale dataset. Secondly , [ Ord ´ o ˜ nez and Roggen, 2016 ] com- pared the performance of a recurrent approach to CNNs on two HAR datasets, representing the current state-of-the-art performance on Opportunity , one of the datasets utilised in this work. In both cases, the recurrent network was paired with a con volutional network that encoded the movement data, effecti vely employing the recurrent network to only model temporal dependencies on a more abstract le vel. Re- current networks ha ve so far not been applied to model move- ment data at the lowest possible lev el, which is the sequence of individual samples recorded by the sensor(s). 3 Comparing deep learning f or HAR While there has been some exploration of deep models for a variety of application scenarios in HAR there is still a lack of a systematic e xploration of deep learning capabili- ties. Authors report to e xplore the parameter space in prelim- inary experiments, but usually omit the details. The overall process remains unclear and difficult to replicate. Instead, single instantiations of e.g. CNNs are presented that show good performance in an application scenario. Solely report- ing peak performance figures does, howe ver , not reflect the ov erall suitability of a method for HAR in ubicomp, as it re- mains unclear how much ef fort went into tuning the proposed approach, and how much ef fort went into tuning other ap- proaches it w as compared to. How likely is a practitioner to find a parameter configuration that works similarly well for their application? How representative is the reported perfor- mance across the models compared during parameter e xplo- ration? Which parameters hav e the largest impact on perfor- mance? These questions are important for the practitioner , but so f ar remain unanswered in related work. In this paper we provide the first unbiased comparison of the most popular deep learning approaches on three repre- sentativ e datasets for HAR in ubicomp. The y include typ- ical application scenarios like manipulati ve gestures, repeti- tiv e physical activities, and a medical application of HAR in Parkinson’ s disease. W e compare three types of models that are described belo w . T o explore the suitability of each method we chose reasonable ranges for each of their hyperparameters and randomly sample model configurations. W e report on their performance across thousands of experiments and anal- yse the impact of hyperparameters for each approach 1 . 3.1 Deep feed-f orward networks (DNN) W e implemented deep feed-forward networks, which corre- spond to a neural network with up to fi ve hidden layers fol- lowed by a softmax-group. The DNN represents a sequence of non-linear transformations to the input data of the network. W e follo w con vention and refer to a netw ork with N hidden layers as N-layer network. Each hidden layer contains the same number of units, and corresponds to a linear transfor- mation and a recitified-linear (ReLU) activ ation function. W e use two different regularisation techniques: i) Dropout: dur - ing training each unit in each hidden layer is set to zero with a probability p drop , and during inference the output of each unit is scaled by 1 /p drop [ Sriv astav a et al. , 2014 ] (dropout- rate is fixed to 0 . 5 for all experiments); ii) Max-in norm: Af- ter each mini-batch the incoming weights of each unit in the network are scaled to hav e a maximum euclidean length of d in . T o limit the number of hyperparameters of the approach we chose not to perform any generativ e pre-training and to solely rely on a supervised learning approach. The input data fed into the network corresponds to frames of mo vement data. Each frame consists of a v arying number of s samples from R d , which are simply concatenated into a single vector F t ∈ R s ∗ d . The model is illustrated in figure 1(d). The DNN is trained in a mini-batch approach, where each mini-batch contains 64 frames and is stratified with respect to the class distribution in the training-set. W e minimise the negati ve log likelihood using stochastic gradient descent. 3.2 Con volutional networks (CNN) CNNs aim to introduce a de gree of locality in the patterns matched in the input data and to enable translational inv ari- ance with respect to the precise location (i.e. time of occur - rence) of each pattern within a frame of mov ement data. W e explore the performance of con volutional netw orks and fol- low suggestions by [ Sriv astav a et al. , 2014 ] in architecture and regularisation techniques. The overall CNN architecture is illustrated in figure 1(c). Each CNN contains at least one temporal con volution layer, one pooling layer and at least one fully connected layer prior to a top-lev el softmax-group. The temporal con volution layer corresponds to a con volution of the input sequence with n f different kernels (feature maps) of width k w . Subsequent max-pooling is looking for the maxi- mum within a region of width m w and corresponds to a sub- sampling, introducing translational inv ariance to the system. W idth of the max-pooling was fixed to 2 throughout all exper - iments. The output of each max-pooling layer is transformed using a ReLU activ ation function. The subsequent fully con- nected part ef fectiv ely corresponds to a DNN and follows the same architecture outlined abov e. For re gularisation we apply dropout after each max- pooling or fully-connected layer , where the dropout- probability p i drop in layer i is fixed for all e xperiments 1 Source-code will be made publicly av ailable ( p 1 drop = 0 . 1 , p 2 drop = 0 . 25 , p i> 2 drop = 0 . 5 ). Similar to the DNN we also perform max-in norm regularisation as sug- gested in [ Sriv astav a et al. , 2014 ] . The input data fed into the CNN corresponds to frames of movement data as in the DNN. Ho we ver , instead of concatenating the dif ferent input dimensions the matrix-structure is retained ( F t ∈ R s × R d ). The CNN is trained using stratified mini-batches (64 frames) and stochastic gradient descent to minimise negativ e log like- lihood. 3.3 Recurrent netw orks In order to exploit the temporal dependencies within the mov ement data we implemented recurrent neural networks based on LSTM cells in their vanilla variant that does not contain peephole connections [ Greff et al. , 2015 ] . This archi- tecture is recurrent as some of the connections within the net- work form a directed cycle, where the current timestep t con- siders the states of the network in the previous timestep t − 1 . LSTM cells are designed to counter the effect of diminish- ing gradients if error deriv ativ es are backpropagated through many layers “through time” in recurrent networks [ Hochre- iter et al. , 2001 ] . Each LSTM cell (unit) keeps track of an internal state (the constant error car ousel ) that represents it’ s “memory”. Over time the cells learn to output, overwrite, or null their internal memory based on their current input and the history of past internal states, leading to a system capable of retaining information across hundreds of time-steps [ Hochre- iter and Schmidhuber , 1997 ] . W e implement two flavours of LSTM recurrent networks: i) deep forward LSTMs contain multiple layers of recurrent units and are connected “forward” in time (see figure 1(a)); and ii) bi-directional LSTMs which contain two parallel re- current layers that stretch both into the “future” and into the “past” of the current time-step, follo wed by a layer that con- catenates their internal states for timestep t (see figure 1(b)). Practically these two flav ours dif fer significantly in their application requirements. A forward LSTM contextualises the current time-step based on those it has seen previously , and is inherently suitable for real-time applications where, at inference time, the “future” is not yet kno wn. Bi-directional LSTMs on the other hand use both the future and past conte xt to interpret the input at timestep t , which makes them suitable for offline analysis scenarios. In this work we apply recurrent networks in three dif ferent settings, each of which is trained to minimise the negativ e log likelihood using adagrad [ Duchi et al. , 2011 ] and subject to max-in norm regularisation. In the first case the input data fed into the network at any giv en time t corresponds to the current frame of mov ement data, which stretches a certain length of time and whose di- mensions hav e been concatenated (as in the DNN abov e). W e denote this model as LSTM-F . The second application case of forward LSTMs represents a real-time application, where each sample of movement data is presented to the network in the sequence the y were recorded, denoted LSTM-S . The fi- nal scenario sees the application of bi-directional LSTMs to the same sample-by-sample prediction problem, denoted b- LSTM-S . 3.4 T raining RNNs for HAR Common applications for RNNs include speech recognition and natural language processing. In these settings the context for an input (e.g. a word) is limited to it’ s surrounding enti- ties (e.g. a sentence, paragraph). T raining of RNNs usually treats these contextualised entities as a whole, for example by training an RNN on complete sentences. In HAR the context of an individual sample of mov ement data is not well defined, at least beyond immediate correla- tions between neighbouring samples, and likely depends on the type of mo vement and its wider behavioural conte xt. This is a problem well known in the field, and affects the choice of window length for sliding windo w segmentation [ Bulling et al. , 2014 ] . In order to construct b mini-batches that are used to train the RNN we initialise a number of positions ( p i ) b between the start and end of the training-set. T o construct a mini-batch we extract the L samples that follow each position in ( p i ) b , and increase ( p i ) b by L steps, possibly wrapping around the end of the sequence. W e found that it is important to initialise the positions randomly to a void oscillations in the gradients. While this approach retains the ordering of the samples pre- sented to the RNN it does not allow for stratification of each mini-batch w .r .t. class-distribution. T raining on long sequences has a further issue that is ad- dressed in this work. If we use the approach outlined abo ve to train a sufficiently lar ge RNN it may “memorise” the en- tire input-output sequence implicitly , leading to poor gener- alisation performance. In order to avoid this memorisation we need to introduce “breaks” where the internal states of the RNN are reset to zero: after each mini-batch we decide to retain the internal state of the RNN with a carry-over prob- ability p carry , and reset it to zero otherwise. This is a novel form of re gularisation of RNNs, which should be useful for similar applications of RNNs. 4 Experiments The different hyper-parameters explored in this work are listed in table 1. The last column indicates the number of parameter configurations sampled for each dataset, selected to represent an equal amount of computation time. W e con- duct experiments on three benchmark datasets representative of the problems tyical for HAR (described belo w). Experi- ments were run on a machine with three GPUs (NV idia GTX 980 T i), where two model configurations are run on each GPU except for the lar gest networks. After each epoch of training we e valuate the performance of the model on the validation set. Each model is trained for at least 30 epochs and for a maximum of 300 epochs. After 30 epochs, training stops if there is no increase in v alidation performance for 10 subsequent epochs. W e select the epoch that showed the best v alidation-set performance and apply the corresponding model to the test-set. 4.1 Datasets W e select three datasets typical for HAR in ubicomp for the exploration in this work. Each dataset corresponds to an application of HAR. The first dataset, Opportunity , con- tains manipulativ e gestures like opening and closing doors, which are short in duration and non-repetitive. The second, P AMAP2, contains prolonged and repetiti ve physical acti vi- ties typical for systems aiming to characterise energy expen- diture. The last, Daphnet Gait, corresponds to a medical ap- plication where participants exhibit a typical motor compli- cation in Parkinson’ s disease that is known to hav e a large inter-subject v ariability . Belo w we detail each dataset: The Opportunity dataset (Opp) [ Chav arriaga et al. , 2013 ] consists of annotated recordings from on-body sensors from 4 participants instructed to carry out common kitchen activities. Data is recorded at a frequency of 30Hz from 12 locations on the body , and annotated with 18 mid-level ges- ture annotations (e.g. Open Door / Close Door). For each subject, data from 5 dif ferent runs is recorded. W e used the subset of sensors that did not show any packet-loss, which included accelerometer recordings from the upper limbs, the back, and complete IMU data from both feet. The resulting dataset had 79 dimensions. W e use run 2 from subject 1 as our validation set, and replicate the most popular recognition challenge by using runs 4 and 5 from subject 2 and 3 in our test set. The remaining data is used for training. For frame- by-frame analysis, we created sliding windo ws of duration 1 second and 50% o verlap. The resulting training-set contains approx. 650 k samples ( 43 k frames). The P AMAP2 dataset [ Reiss and Stricker , 2012 ] consists of recordings from 9 participants instructed to carry out 12 lifestyle activities, including household activities and a va- riety of ex ercise activities (Nordic walking, playing soccer , etc). Accelerometer , gyroscope, magnetometer , temperature and heart rate data are recorded from inertial measurement units located on the hand, chest and ankle over 10 hours (in total). The resulting dataset has 52 dimensions. W e used runs 1 and 2 for subject 5 in our validation set and runs 1 and 2 for subject 6 in our test set. The remaining data is used for training. In our analysis, we downsampled the accelerometer data to 33.3Hz in order to hav e a temporal resolution compa- rable to the Opportunity dataset. For frame-by-frame analy- sis, we replicate previous work with non-overlapping sliding windows of 5.12 seconds duration with one second stepping between adjacent windows (78% o verlap) [ Reiss and Stricker , 2012 ] . The training-set contains approx. 473 k samples ( 14 k frames). The Daphnet Gait dataset (DG) [ Bachlin et al. , 2009 ] consists of recordings from 10 participants af fected with Parkinson’ s Disease (PD), instructed to carry out activities which are likely to induce freezing of gait. Freezing is a com- mon motor complication in PD, where affected individuals struggle to initiate mo vements such as walking. The objecti ve is to detect these freezing incidents, with the goal to inform a future situated prompting system. This represents a two- class recognition problem. Accelerometer data was recorded from above the ankle, abov e the knee and on the trunk. The resulting dataset has 9 dimensions. W e used run 1 from sub- ject 9 in our validation set, runs 1 and 2 from subject 2 in our test set, and used the rest for training. In our analysis, we do wnsampled the accelerometer data to 32Hz. For frame- by-frame analysis, we created sliding windows of 1 second LR LR decay L momentum max-in norm p carry #layers #units #con v .-layers kW 1 kW 2 kW 3 nF 1 nF 2 nF 3 #experiments Category Learning Regularisation Architecture log-uniform? y y - - - - - - - - - - - - - DNN max 10 − 1 10 − 3 - 0.99 4.0 - 5 2048 - - - - - - - 1000 min 10 − 4 10 − 5 - 0.0 0.5 - 1 64 - - - - - - - CNN max 10 − 1 10 − 3 - 0.99 4.0 - 3 2048 3 9 5 3 128 128 128 256 min 10 − 4 10 − 5 - 0.0 0.5 - 1 64 1 3 3 3 16 16 16 LSTM-F max 10 − 1 - 64 - 4.0 1.0 3 384 - - - - - - - 128 min 10 − 3 - 8 - 0.5 0.0 1 64 - - - - - - - LSTM-S max 10 − 1 - 196 - 4.0 1.0 3 384 - - - - - - - 128 min 10 − 3 - 32 - 0.5 0.0 1 64 - - - - - - - b-LSTM-S max 10 − 1 - 196 - 4.0 1.0 1 384 - - - - - - - 128 min 10 − 3 - 32 - 0.5 0.0 1 64 - - - - - - - T able 1: Hyper-parameters of the models and the ranges of v alues explored in experiments. duration and 50% overlap. The training-set contains approx. 470 k samples ( 30 k frames). 4.2 Influence of hyper -parameters In order to estimate the impact of each hyperparameter on the performance observ ed across all experiments we apply the fANO V A analysis framew ork. fANO V A [ Hutter et al. , 2014 ] determines the extent to which each hyperparameter contributes to a netw ork’ s performance. It b uilds a predictiv e model (random forest) of the model performance as a func- tion of the model’ s hyperparameters. This non-linear model is then decomposed into marginal and joint interaction func- tions of the hyperparameters, from which the percentage con- tribution to ov erall v ariability of network performance is ob- tained. fANO V A has been used previously to e xplore the hy- perparameters in recurrent networks by [ Greff et al. , 2015 ] . For the practitioner it is important to know which aspect of the model is the most crucial for performance. W e grouped the hyperparameters of each model into one of three cate- gories (see table 1): i) learning , parameters that control the learning process; ii) r egularisation , parameters that limit the modelling capabilities of the model to avoid ov erfitting; and iii) ar chitectur e , parameters that affect the structure of the model. Based on the v ariability observed for each hyperpa- rameter we estimate the variability that can be attributed to each parameter category , and to higher order interactions be- tween categories. 4.3 Perf ormance metrics As the datasets utilised in this work are highly biased we re- quire performance metrics that are independent of the class distribution. W e opted to estimate the mean f1-score: F m = 2 | c | X c prec c × recall c prec c + recall c (1) Related work has previously used the weighted f1-score as primary performance metric (for Opportunity). In order to compare our results to the state-of-the-art we estimate the weighted f1-score: F w = 2 X c N c N total prec c × recall c prec c + recall c , (2) P AMAP2 DG OPP Performance F m F 1 F m F w DNN 0 . 904 0 . 633 0 . 575 0 . 888 CNN 0 . 937 0 . 684 0 . 591 0 . 894 LSTM-F 0 . 929 0 . 673 0 . 672 0 . 908 LSTM-S 0 . 882 0 . 760 0 . 698 0 . 912 b-LSTM-S 0 . 868 0 . 741 0 . 745 0 . 927 CNN [ Y ang et al. , 2015 ] − 0 . 851 CNN [ Ord ´ o ˜ nez and Roggen, 2016 ] 0 . 535 0 . 883 DeepCon vLSTM [ Ord ´ o ˜ nez and Roggen, 2016 ] 0 . 704 0 . 917 Delta from median ∆ F m ∆ F 1 ∆ F m mean DNN 0 . 129 0 . 149 0 . 357 0 . 221 CNN 0 . 071 0 . 122 0 . 120 0 . 104 LSTM-F 0 . 10 0 . 281 0 . 085 0 . 156 LSTM-S 0 . 128 0 . 297 0 . 079 0 . 168 b-LSTM-S 0 . 087 0 . 221 0 . 205 0 . 172 T able 2: Best results obtained for each model and dataset, along with some baselines for comparison. Delta from me- dian (lower part of table) refers to the absolute dif ference be- tween peak and median performance across all experiments. where N c is the number of samples in class c , and N total is the total number of samples. 5 Results Results are illustrated in figure 2. Graphs (a-c) sho w the cu- mulativ e distribution of the main performance metric on each dataset. Graph (d) illustrates the ef fect of each category of hyper-parameter estimated using fANO V A. Overall we observe a large spread of peak performances between models on OPP and DG, with more than 15% mean f1-score between the best performing approach (b-LSTM-S) and the worst (DNN) on OPP (12% on DG) (see table 2). On P AMAP2 this difference is smaller, but still considerable at 7%. The best performing approach on OPP (b-LSTM-S) out- performs the current state-of-the-art by a considerable mar- gin of 4% mean f1-score (1% weighted f1-score). The best CNN discov ered in this work further outperforms previous re- sults reported in the literature for this type of model by more than 5% mean f1-score and weighted f1-score (see table 2). The good performance of recurrent approaches, which model mov ement at the sample le vel, holds the potential for novel (real-time) applications in HAR, as the y alle viate the need for segmentation of the time-series data. Figure 2: (a)-(c): Cumulativ e distrib ution of recognition performance for each dataset. (d): results from fANO V A analysis, illustrating impact of hyperparameter-cate gories on recognition performance (see table 1). The distributions of performance scores dif fer between the models in vestigated in this work. CNNs sho w the most char- acteristic beha viour: a fraction of model configurations do not work at all (e.g. 20% on P AMAP2), while the remaining configurations show little v ariance in their performance. On P AMAP2, for example, the dif ference between the peak and median performance is only 7% mean f1-score (see table 2). The DNNs sho w the largest spread between peak and median performance of all approaches of up to 35.7% on OPP . Both forward RNNs (LSTM-F , LSTM-S) show similar behaviour across the dif ferent datasets. Practically all of their configura- tions explored on P AMAP2 and OPP have non-trivial recog- nition performance. The effect of each category of hyperparameter on the recognition performance is illustrated in figure 2(d). Interest- ingly , we observ e the most consistent ef fect of the parameters in the CNN. In contrast to our e xpectation it is the parameters surrounding the learning process (see table 1) that have the largest main ef fect on performance. W e expected that for this model the rich choice of architectural variants should hav e a larger effect. For DNNs we do not observ e a systematic ef- fect of any category of hyperparameter . On P AMAP2, the correct learning parameters appear to the be the most crucial. On OPP it is the architecture of the model. Interestingly we observed that relativ ely shallow networks outperform deeper variants. There is a drop in performance for networks with more than 3 hidden layers. This may be related to our choice to solely rely on supervised training, where a generati ve pre- training may improv e the performance of deeper networks. The performance of the frame-based RNN (LSTM-F) on OPP depends critically on the carry-ov er probability intro- duced in this work. Both always retaining the internal state and always forgetting the internal state lead to the low per- formance. W e found that p carry of 0.5 works well for most settings. Our findings merit further in vestigation, for exam- ple into a carry-ov er schedule , which may further improv e LSTM performance. Results for sample-based forward LSTMs (LSTM-S) mostly confirm earlier findings for this type of model that found learning-rate to be the most crucial parameter [ Greff et al. , 2015 ] . Howe ver , for bi-directional LSTMs (b-LSTM- S) we observe that the number of units in each layer has a suprisingly large ef fect on performance, which should moti- vate practitioners to first focus on tuning this parameter . 6 Discussion In this work we explored the performance of state-of-the-art deep learning approaches for Human Activity Recognition using wearable sensors. W e described ho w to train recur- rent approaches in this setting and introduced a nov el regular - isation approach. In thousands of experiments we e v aluated the performance of the models with randomly sampled hyper- parameters. W e found that bi-directional LSTMs outperform the current state-of-the-art on Opportunity , a large benchmark dataset, by a considerable margin. Howe ver , interesting from a practitioner’ s point of view is not the peak performance for each model, b ut the process of parameter exploration and insights into their suitability for different tasks in HAR. Recurrent networks outperform con- volutional networks significantly on acti vities that are short in duration but hav e a natural ordering, where a recurrent approach benefits from the ability to contextualise observa- tions across long periods of time. For bi-directional RNNs we found that the number of units per layer has the largest effect on performance across all datasets. F or prolonged and repetitiv e acti vities like walking or running we recommend to use CNNs. Their average performance in this setting makes it more likely that the practitioner discovers a suitable configu- ration, e ven though we found some RNNs that work similarly well or even outperform CNNs in this setting. W e further rec- ommend to start exploring learning-rates, before optimising the architecture of the network, as the learning-parameters had the largest ef fect on performance in our experiments. W e found that models differ in the spread of recognition performance for dif ferent parameter settings. Regular DNNs, a model that is probably the most approachable for a practi- tioner , requires a significant in vestment in parameter explo- ration and sho ws a substantial spread between the peak and median performance. Practitioners should therefore not dis- card the model even if a preliminary e xploration leads to poor recognition performance. More sophisticated approaches like CNNs or RNNs sho w a much smaller spread of performance, and it is more likely to find a configuration that works well with only a few iterations. References [ Alsheikh et al. , 2015 ] Mohammad Abu Alsheikh, Ahmed Selim, Dusit Niyato, Linda Doyle, Shao wei Lin, and Hwee-Pink T an. Deep acti vity recognition models with triaxial accelerometers. , 2015. [ Bachlin et al. , 2009 ] Marc Bachlin, Daniel Roggen, Ger - hard T roster , Meir Plotnik, Noit Inbar , Inbal Meidan, T alia Herman, Marina Brozgol, Eliya Sha viv , Nir Giladi, et al. Potentials of enhanced context a wareness in wearable as- sistants for parkinson’ s disease patients with the freezing of gait syndrome. In ISWC , 2009. [ Bulling et al. , 2014 ] Andreas Bulling, Ulf Blanke, and Bernt Schiele. A tutorial on human activity recognition using body-worn inertial sensors. ACM Computing Sur- ve ys (CSUR) , 46(3):33, 2014. [ Chav arriaga et al. , 2013 ] Ricardo Cha varriaga, Hesam Sagha, Alberto Calatroni, Sundara T ejaswi Digumarti, Gerhard T r ¨ oster , Jos ´ e del R Mill ´ an, and Daniel Roggen. The opportunity challenge: A benchmark database for on-body sensor-based activity recognition. P attern Recognition Letters , 2013. [ Collobert et al. , 2011 ] Ronan Collobert, Koray Kavukcuoglu, and Cl ´ ement Farabet. T orch7: A matlab- like environment for machine learning. In BigLearn, NIPS W orkshop , 2011. [ Duchi et al. , 2011 ] John Duchi, Elad Hazan, and Y oram Singer . Adaptiv e subgradient methods for online learn- ing and stochastic optimization. The J ournal of Machine Learning Resear ch , 12:2121–2159, 2011. [ Greff et al. , 2015 ] Klaus Greff, Rupesh Kumar Sriv astav a, Jan Koutn ´ ık, Bas R Steunebrink, and J ¨ urgen Schmidhu- ber . Lstm: A search space odyssey . arXiv pr eprint arXiv:1503.04069 , 2015. [ Gregor et al. , 2015 ] Karol Gregor , Ivo Danihelka, Alex Grav es, and Daan W ierstra. Draw: A recurrent neural net- work for image generation. , 2015. [ Hammerla and Pl ¨ otz, 2015 ] Nils Y Hammerla and Thomas Pl ¨ otz. Let’ s (not) stick together: pairwise similarity biases cross-validation in activity recognition. In Ubicomp , 2015. [ Hammerla et al. , 2015 ] Nils Y Hammerla, James M Fisher , Peter Andras, L ynn Rochester , Richard W alker , and Thomas Pl ¨ otz. Pd disease state assessment in naturalistic en vironments using deep learning. In AAAI , 2015. [ Hochreiter and Schmidhuber , 1997 ] Sepp Hochreiter and J ¨ urgen Schmidhuber . Long short-term memory . Neural computation , 9(8):1735–1780, 1997. [ Hochreiter et al. , 2001 ] Sepp Hochreiter , Y oshua Bengio, Paolo Frasconi, and J ¨ urgen Schmidhuber . Gradient flo w in recurrent nets: the difficulty of learning long-term de- pendencies, 2001. [ Hutter et al. , 2014 ] Frank Hutter , Holger Hoos, and Ke vin Leyton-Bro wn. An efficient approach for as sessing hyper - parameter importance. In ICML , pages 754–762, 2014. [ Lane et al. , 2015 ] Nicholas D Lane, Petko Georgie v , and Lorena Qendro. Deepear: robust smartphone audio sens- ing in unconstrained acoustic en vironments using deep learning. In Ubicomp , pages 283–294. A CM, 2015. [ LeCun et al. , 2015 ] Y ann LeCun, Y oshua Bengio, and Ge- offre y Hinton. Deep learning. Nature , 2015. [ Nev erova et al. , 2015 ] Natalia Nevero va, Christian W olf, Griffin Lace y , Lex Fridman, Deepak Chandra, Brandon Barbello, and Graham T aylor . Learning human identity from motion patterns. , 2015. [ Ord ´ o ˜ nez and Roggen, 2016 ] Francisco Javier Ord ´ o ˜ nez and Daniel Roggen. Deep con volutional and lstm recurrent neural networks for multimodal wearable activity recog- nition. Sensors , 16(1):115, 2016. [ Pl ¨ otz et al. , 2011 ] Thomas Pl ¨ otz, Nils Y Hammerla, and Patrick Olivier . Feature learning for acti vity recognition in ubiquitous computing. In IJCAI , 2011. [ Pl ¨ otz et al. , 2012 ] Thomas Pl ¨ otz, Nils Y Hammerla, Agata Rozga, Andrea Reavis, Nathan Call, and Gre gory D Abowd. Automatic assessment of problem behavior in individuals with dev elopmental disabilities. In Ubicomp , 2012. [ Rad et al. , 2015 ] Nastaran Mohammadian Rad, Andrea Bizzego, Seyed Mostafa Kia, Giuseppe Jurman, Paola V enuti, and Cesare Furlanello. Con volutional neural network for stereotypical motor movement detection in autism. , 2015. [ Reiss and Stricker , 2012 ] Attila Reiss and Didier Stricker . Introducing a new benchmarked dataset for activit y moni- toring. In ISWC , 2012. [ Ronao and Cho, 2015 ] Charissa Ann Ronao and Sung-Bae Cho. Deep con volutional neural networks for human ac- tivity recognition with smartphone sensors. In Neural In- formation Pr ocessing , pages 46–53. Springer , 2015. [ Ronaoo and Cho, 2015 ] Charissa Ann Ronaoo and Sung- Bae Cho. Evaluation of deep con volutional neural network architectures for human activity recognition with smart- phone sensors. In Pr oc. of the KIISE Kor ea Computer Congr ess , pages 858–860, 2015. [ Sriv astav a et al. , 2014 ] Nitish Sriv astava, Geoffre y Hinton, Alex Krizhe vsky , Ilya Sutskev er , and Ruslan Salakhutdi- nov . Dropout: A simple way to pre vent neural netw orks from ov erfitting. JMLR , 2014. [ Y ang et al. , 2015 ] Jian Bo Y ang, Minh Nhut Nguyen, Phyo Phyo San, Xiao Li Li, and Shonali Krishnaswamy . Deep con volutional neural networks on multichannel time series for human activity recognition. In IJCAI , 2015. [ Zeng et al. , 2014 ] Ming Zeng, Le T Nguyen, Bo Y u, Ole J Mengshoel, Jiang Zhu, Pang W u, and Juyong Zhang. Con- volutional neural networks for human activity recogni- tion using mobile sensors. In MobiCASE , pages 197–205. IEEE, 2014. [ Zhang et al. , 2015 ] Licheng Zhang, Xihong W u, and Ding- sheng Luo. Human activity recognition with hmm-dnn model. In ICCI , pages 192–197. IEEE, 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment