Interpretable Deep Neural Networks for Single-Trial EEG Classification
Background: In cognitive neuroscience the potential of Deep Neural Networks (DNNs) for solving complex classification tasks is yet to be fully exploited. The most limiting factor is that DNNs as notorious 'black boxes' do not provide insight into neu…
Authors: Irene Sturm, Sebastian Bach, Wojciech Samek
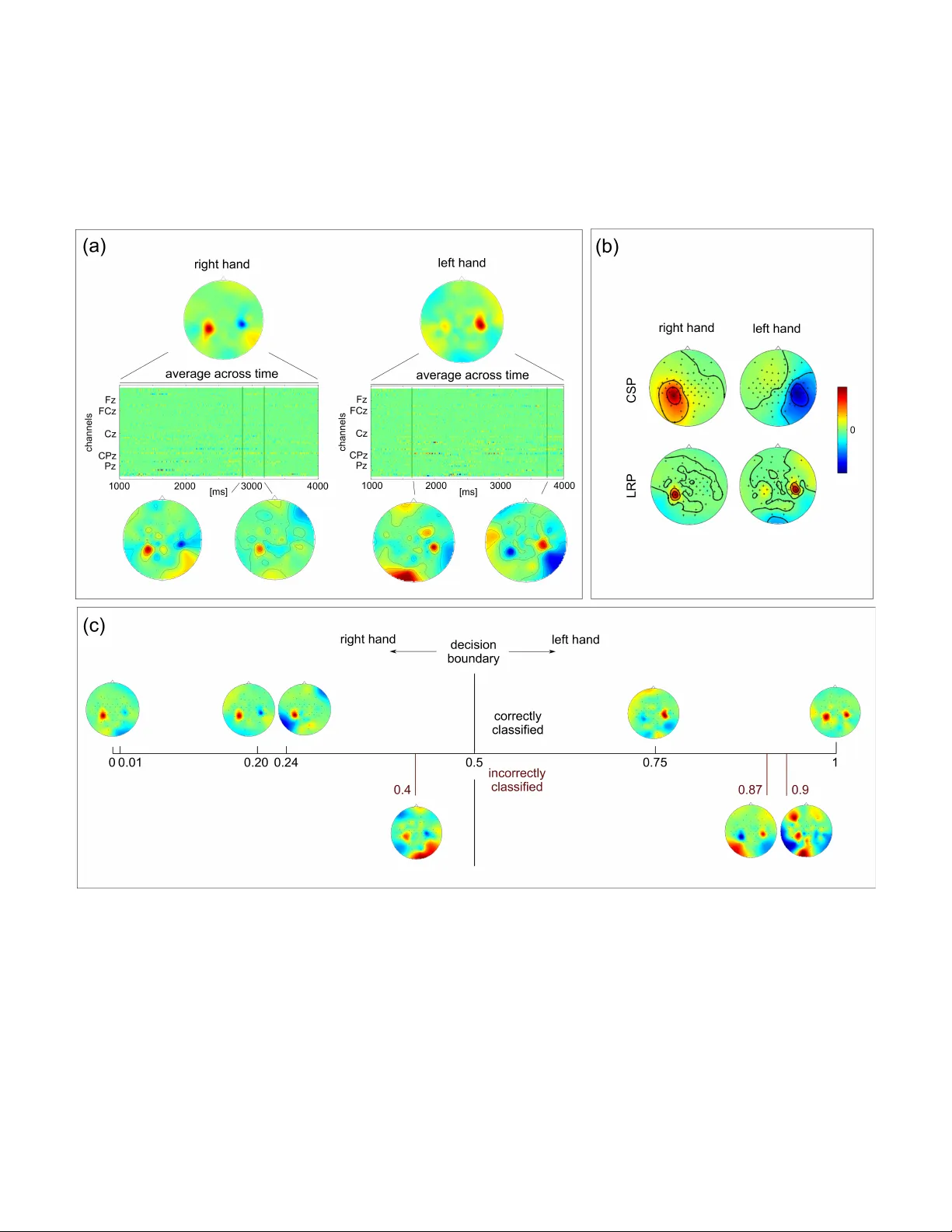
1 Interpretable Deep Neural Networks for Single-T rial EEG Classification Irene Sturm 1 , Sebastian Bach 2 , W ojciech Samek 2 , and Klaus-Robert M ¨ uller 1,3 1 Machine Learning Group, Berlin Institute of T echnology , Berlin, Germany 2 Machine Learning Group, Fraunhofer Heinrich Hertz Institute, Berlin, Germany 3 Department of Brain and Cogniti ve Engineering, K orea Uni versity , Seoul, K orea Abstract — Backgr ound : In cognitive neur oscience the potential of Deep Neural Networks (DNNs) f or solving complex classifica- tion tasks is yet to be fully exploited. The most limiting factor is that DNNs as notorious ‘black boxes’ do not pro vide insight into neurophysiological phenomena underlying a decision. Layer - wise Relev ance Propagation (LRP) has been intr oduced as a novel method to explain individual network decisions. New Method : W e propose the application of DNNs with LRP for the first time for EEG data analysis. Through LRP the single- trial DNN decisions are transf ormed into heatmaps indicating each data point’s rele vance for the outcome of the decision. Results : DNN achieves classification accuracies comparable to those of CSP-LDA. In subjects with low performance subject- to-subject transfer of trained DNNs can impro ve the results. The single-trial LRP heatmaps re veal neurophysiologically plausible patterns, resembling CSP-derived scalp maps. Critically , while CSP patterns repr esent class-wise aggr egated information, LRP heatmaps pinpoint neural patterns to single time points in single trials. Comparison with Existing Method(s) : W e compare the classification performance of DNNs to that of linear CSP-LDA on two data sets related to motor-imaginery BCI. Conclusion : W e hav e demonstrated that DNN is a po werful non- linear tool f or EEG analysis. With LRP a new quality of high- resolution assessment of neural activity can be reached. LRP is a potential remedy f or the lack of interpretability of DNNs that has limited their utility in neuroscientific applications. The extreme specificity of the LRP-derived heatmaps opens up new avenues for in vestigating neural activity underlying complex perception or decision-related processes. I . I N T RO D U C T I O N Deep Neural Networks (DNNs) are powerful methods for solving complex classification tasks in fields such as computer vision [1], natural language processing [2], video analysis [3] and physics [4]. Although researchers hav e recently started introducing this promising technology into the domain of cognitiv e neuroscience [5] and Brain-Computer Interfacing (BCI) [6], [7], most of the current techniques in these fields are still based on linear methods [8], [9]. A limiting factor for the applicability of DNN in these fields is the notion of a DNN as a black box . In the domain of cognitive neuroscience this is a particular drawback because obtaining neurophysiological insights is of utmost importance beyond the classification performance of a system. Recently , the interpretability aspect of deep neural networks has been addressed by the Layer-wise Relev ance Propagation (LRP) [10] method. LRP explains indi vidual classification decisions of a DNN by decomposing its output in terms of input variables. It is a principled method which has close relation to T aylor decomposition [11] and is applicable to arbitrary DNN architectures. From a practitioners perspective LRP adds a new dimension to the application of DNNs (e.g., in computer vision [12], [13]) by making the prediction transparent. W ithin the scope of cognitiv e neuroscience this means that DNN with LRP , may provide not only a highly effecti ve (non-linear) classification technique that is suitable for complex high-dimensional data, but also yield detailed single-trial accounts of the distribution of decision-relev ant information, a feature that is lacking in commonly applied DNN techniques and also in other state-of-the art methods (such as those discussed below). Here we propose using DNN with LRP for the first time for EEG analysis. For that we train a DNN to solve a classification task related to motor-imaginery BCI. On two e xample data sets we compare the classification performance of DNN to that of CSP-LD A, a standard technique [9]. W e then apply LRP to produce heatmaps that indicate the relev ance of each data point of a spatio-temporal EEG epoch for the classifier’ s decision in single trial. W e present sev eral examples of such heatmaps and demonstrate their neurophysiological plausibility . Critically , we point out that the spatio-temporal heatmaps represent a ne w quality of explanatory resolution that allo ws to explain why the classifier reaches a certain decision in a single instance. Note that such information can not be deriv ed from CSP- LD A. Finally , we provide a range of future applications of this technique in neuroscience. W e discuss why equipping the extremely powerful non-linear technology of DNN with the diagnostic power of LRP may contribute to extending the scope of DNN techniques. I I . A D E E P N E U R A L N E T WO R K F O R E E G C L A S S I FI C A T I O N A. Model Details The network applied here consists of two linear sum- pooling layers with bias-inputs, followed by an activ ation or normalization step each. The first linear layer accepts an input of the dimensionality 301 time points × 118 channels EEG features (301 time point × 58 channels for subjects od- obx) as a 33518 (od-obx: 17458) dimensional input vector and produces a 500-dimensional tanh-acti vated output vector . The next layer reduces the 500-dimensional space to a 2- dimensional output space followed by a softmax layer for 2 activ ation in order to produce output probabilities for each class. The network was trained using a standard error back- propagation algorithm using batches of 5 randomly drawn training samples. The abov e prediction accuracy w as achie ved after terminating the training procedure after 3000 iterations [14]. B. Interpr etability The DNN assigns a classification score f ( x ) to e very input data sample x = [ x 1 . . . x N ] at prediction time. Layer-wise Relev ance Propagation decomposes the classifier output f ( x ) in terms of relev ances r i attributing to each input component x i its shar e with which it contributes to the classification decision f ( x ) = X i r i (1) These relev ance values are backpropaged from the network output to the input layer using a local redistribution rule r ( l ) i = X j z ij P i 0 z i 0 j r ( l +1) j with z ij = x (l) i w (l , l+1) ij (2) where j indexes a neuron at a particular layer l + 1 , where P i runs over all lower-layer neurons connected to neuron j , and where w ( l,l +1) ij are parameters specific to pairs of adjacent neurons and learned from the data. This redistrib ution rule has been showed to fulfill the layer-wise conservation property [10] and to be closely related to a deep variant of T aylor decomposition [11]. I I I . E V A L UA T I O N A. Experimental Setup and Pr epr ocessing The application of DNN with LRP on EEG data was demonstrated on dataset IV a from BCI competition III (cued motor imagery data with classes right hand vs. foot from 5 subjects [15]) and on a subset of 5 subjects from [16] where subjects had to perform left and right hand motor imaginery while dealing with different types of distractions. Here, we only analyzed data obtained in the condition ‘no distraction’, a standard motor imaginery BCI setting. As in the competition, we did not use test data for training for dataset IV a (subjects aa, al, av , aw , ay). For the other data set (subjects od, njy , njk, nko, obx) a leave-on-out cross-v alidation was performed. For both data sets the potential of DNN for subject-to-subject transfer was ev aluated: for each subject a DNN was trained on all a vailable data of the other four subjects and e valuated on its own test data. This was was done in a sequential fashion, so that the network was once initialized and then trained on the data of each of the four subjects successively . The entire process of training and testing was repeated fiv e times for different orders of the four subjects and the classification performance on the test data was av eraged. All data sets were downsampled to 100Hz and bandpass filtered in the range of 9-13 Hz. The CSP algorithm was performed on a [1000 4000] ms epoch after the cue and 3 pairs of spatial filters were selected. On the e xtracted features a reg- ularized LD A classifier with analytically determined shrinkage parameter [17] was trained. For training and ev aluating the DNN the en velope of each epoch ([1000 4000] ms after cue) was calculated and an epochwise baseline of [0 300] ms before the cue was subtracted. Each epoch’ s spatio-temporal features (301 time points × 118 channels for aa-ay , 301 time point × 58 channels for subject od-obx) were vectorized into one vector with 33518 (17458) dimensions. Relev ance maps were calculated for each trial from the two-v alued DNN output according to Equation 2. B. Results Classification results for the different methods are summa- rized in T able I. Overall, classification performance of DNN is lower than that of CSP-LD A. Subjects ay and njy , the subjects with the lowest performance, represent an exception: here DNN effects an increase in classification accuracy . The performance of inter-subject DNN is inferior to that of single- subject DNN in 6/10 subjects. In the remaining four subjects inter-subject DNN effects a substantial increase in classifica- tion accuracy . Fig. 1 (a) gives an example of relev ance maps obtained with LRP for two single trials of subject od. The matrices depict the rele v ance of each EEG channel at each time point of the epoch. Note that these relev ance maps dif fer from CSP patterns where the absolute magnitude of a weight determines its rele vance and its sign the polarity . In LRP-deriv ed heatmaps positiv e and negati ve values refer to the relev ance and non- relev ance with respect to the specific decision of the DNN. For instance, in a trial assigned to class ‘right hand’ with high confidence positiv e values may be understood as speaking for class ‘right hand’ membership and negati ve values as speaking against class ‘right hand’ membership. For a gi ven time point the relev ance information can be plotted as a scalp topography . The example scalp maps at the bottom show typical lateralized motor acti v ation patterns that can be related to a single time point in a single trial. The av erage of the spatio-temporal relev ance matrix across the entire epoch (top) rev eals similar scalp patterns. The av erage of all time-av eraged relev ance maps of one class (Fig. 1 (b)) is highly similar in topographical distribution to the patterns of the first pair of CSP filters. Fig. 1 (c) shows examples of time-av eraged rele v ance maps for a selection of correctly/incorrectly classified trials. In those trials that were classified correctly and with high confidence (classifier output 0 or 1), relev ant information is confined to small regions with neurophysiologically highly plausible distribution. In incorrectly or with less confidence classified trials influences outside the sensorimotor areas seem to ha ve influenced the netw ork’ s decision. These are located in occipi- tal and frontal regions and may indicate the influence of visual activity and of eye mov ements. I V . D I S C U S S I O N W e hav e provided the first application of DNN with LRP on EEG data. In terms of classification performance, our relativ ely simple DNN network does not outperform the benchmark methodology of CSP-LD A. Howe ver , we provide some examples that training a netw ork successi vely on se veral 3 T ABLE I C L AS S I FI CATI O N AC C U R AC I ES F O R C S P -L DA , D N N A N D I N T E R - S U B JE C T D N N. D A TAS E T B C I C O M PE T I T IO N I I I I V A : A A , A L , A V , A W , AY . D A TAS E T F RO M [ 1 6 ]: O D , N JY , N J Z , N KO , O B X subject number of samples class. accuray in % train test CSP/LD A DNN inter -subj. DNN aa 168 112 66 62 56 al 224 56 100 93 83 av 84 196 70 66 64 aw 56 124 99 77 71 ay 28 252 55 60 73 od 71 1 96 94 86 njy 71 1 65 69 62 njz 71 1 93 86 91 nko 71 1 81 57 68 obx 71 1 97 85 100 other subjects is adv antageous. For instance, this substantially increased classification accuracy in a subject with particularly low accuracy . This is a first hint that DNN technology may be beneficial for subject-to-subject transfer of learned neural rep- resentations, and, ultimately , may adv ance subject-independent zero training strategies in BCI [18]. The most important and novel contribution in this work is the application of LRP . W e hav e demonstrated that LRP produces neurophysiologically highly plausible explanations of how a DNN reaches a decision. More specifically , LRP produced textbook-like motor imaginery patterns in single instants of single trials. These represent accounts of neural activity at an unprecedented lev el of specificity and detail. In contrast, CSP-LD A (and also other methods) only allow to examine discriminating information at the le vel of the whole ensemble of samples of one class. In a direct application in the BCI context LRP helped to diagnose influences that led to low-confidence or erroneous decisions of the network. Outside BCI DNN with LRP may add a new dimen- sion of explanation in any setting where detailed single- trial information is valued. In clinical applications it may represent a sensiti ve tool for neurophysiological interpretation of anomalies or differences between populations. Here, the opportunity to integrate prior knowledge about clinical popu- lations through inter-subject DNN analyses may be a further advantage. In contexts where the trial-to-trial variability of EEG is not vie wed as a notorious obstacle for analysis, but as a source of information, LRP can contribute high-resolving spatio-temporal representations of underlying neurophysiolog- ical phenomena. In particular , this might be interesting for linking brain indices to single instances of behavioral measures [19], for understanding subtle aspects of complex perceptual processes, such as perception of video or audio quality [20], [21], and of dynamic cognitive processes, such as decision making [22]. Finally , a trained network produces relev ance maps for an y (ev en artificially generated) DNN decision. This means that LRP can deri ve a representation of what a netw ork has learned, e.g., by performing LRP on a ‘ideal’ specimen of a gi ven class or even by systematically exploring the space of possible decisions. This might be an interesting alternative to network visualization techniques [23]. V . C O N C L U S I O N In summary , we have provided a sho wcase of how LRP can add an explanatory layer to the highly effecti ve technique of DNN in the EEG/BCI domain. Our results show that LRP pro- vides highly detailed accounts of relev ant information in high- dimensional EEG data that may be useful in analysis scenarios where single trials need to be considered individually . Acknowledgement This work w as supported by the Brain K orea 21 Plus Program and by the Deutsche Forschungsgemeinschaft (DFG). This publication only reflects the authors vie ws. Funding agencies are not liable for an y use that may be made of the information contained herein. Correspondence to WS and KRM. R E F E R E N C E S [1] A. Krizhevsky , I. Sutskev er, G. E. Hinton, Imagenet classification with deep con volutional neural networks, in: Adv . in NIPS, 2012, pp. 1106– 1114. [2] R. Socher , A. Perelygin, J. W u, J. Chuang, C. D. Manning, A. Y . Ng, C. Potts, Recursive deep models for semantic compositionality over a sentiment treebank, in: Proc. of EMNLP , 2013, pp. 1631–1642. [3] Q. V . Le, W . Y . Zou, S. Y . Y eung, A. Y . Ng, Learning hierarchical in- variant spatio-temporal features for action recognition with independent subspace analysis, in: Proc. of CVPR, 2011, pp. 3361–3368. [4] G. Montavon, M. Rupp, V . Gobre, A. V azquez-Mayagoitia, K. Hansen, A. Tkatchenko, K.-R. M ¨ uller , O. A. von Lilienfeld, Machine learning of molecular electronic properties in chemical compound space, New Journal of Ph ysics 15 (9) (2013) 095003. [5] S. M. Plis, D. R. Hjelm, R. Salakhutdinov , E. A. Allen, H. J. Bockholt, J. D. Long, H. J. Johnson, J. S. Paulsen, J. A. Turner , V . D. Calhoun, Deep learning for neuroimaging: a validation study , Front. Neurosci. 8 (229) (2014) doi:10.3389/fnins.2014.00229. [6] A. Y uksel, T . Olmez, A neural network-based optimal spatial filter design method for motor imagery classification, PLOS ONE 10 (5) (2015) e0125039. [7] H. Y ang, S. Sakhavi, K. K. Ang, C. Guan, On the use of conv olutional neural networks and augmented csp features for multi-class motor imagery of eeg signals classification, in: Proc. of IEEE EMBC, 2015, pp. 2620–2623. [8] L. C. Parra, C. D. Spence, A. D. Gerson, P . Sajda, Recipes for the linear analysis of ee g, NeuroImage 28 (2) (2005) 326–341. [9] B. Blankertz, R. T omioka, S. Lemm, M. Kawanabe, K.-R. M ¨ uller , Optimizing spatial filters for robust EEG single-trial analysis, IEEE Signal Proc. Mag. 25 (1) (2008) 41–56. [10] S. Bach, A. Binder, G. Montav on, F . Klauschen, K.-R. M ¨ uller , W . Samek, On pixel-wise explanations for non-linear classifier deci- sions by layer-wise relev ance propagation, PLOS ONE 10 (7) (2015) e0130140. [11] G. Montav on, S. Bach, A. Binder , W . Samek, K.-R. M ¨ uller , Explaining nonlinear classification decisions with deep taylor decomposition, arXi v preprint (2015) CoRR abs/1512.02479. [12] S. Bach, A. Binder , G. Montav on, K.-R. M ¨ uller , W . Samek, Analyzing classifiers: Fisher vectors and deep neural networks, arXiv preprint (2016) CoRR abs/1512.00172. [13] W . Samek, A. Binder , G. Montavon, S. Bach, K. M ¨ uller , Evaluating the visualization of what a deep neural network has learned, arXi v preprint (2015) CoRR abs/1509.06321. [14] Y . A. LeCun, L. Bottou, G. B. Orr , K.-R. M ¨ uller , Efficient backprop, in: Neural netw orks: T ricks of the trade, Springer, 2012, pp. 9–48. [15] B. Blankertz, K.-R. M ¨ uller , D. Krusienski, G. Schalk, J. R. W olpaw , A. Schl ¨ ogl, G. Pfurtscheller, J. del R. Mill ´ an, M. Schr ¨ oder , N. Bir- baumer , The BCI competition III: V alidating alternative approachs to actual BCI problems, IEEE T rans. Neur . Sys. Reh. 14 (2) (2006) 153– 159. [16] S. Brandl, J. H ¨ ohne, K.-R. M ¨ uller , W . Samek, Bringing BCI into ev eryday life: Motor imagery in a pseudo realistic environment, in: Proc. IEEE Conf. on Neural Eng. (NER), 2015, pp. 224–227. [17] B. Blankertz, S. Lemm, M. S. T reder , S. Haufe, K.-R. M ¨ uller , Single-trial analysis and classification of ERP components – a tutorial, NeuroImage 56 (2011) 814–825. 4 [18] S. Fazli, F . Popescu, M. Dan ´ oczy , B. Blankertz, K.-R. M ¨ uller , C. Grozea, Subject-independent mental state classification in single trials, Neural Networks 22 (9) (2009) 1305–1312. [19] A. Delorme, M. Miyakoshi, T .-P . Jung, S. Makeig, Grand av erage erp- image plotting and statistics: A method for comparing variability in ev ent-related single-trial eeg activities across subjects and conditions, J. Neurosci. Meth. 250 (2014) 3–6. [20] A. K. Porbadnigk, M. S. T reder, B. Blank ertz, J.-N. Antons, R. Schle- icher , S. M ¨ oller , G. Curio, K.-R. M ¨ uller , Single-trial analysis of the neural correlates of speech quality perception, J. Neural Eg. 10 (5) (2013) 056003. [21] L. Acqualagna, S. Bosse, A. K. Porbadnigk, G. Curio, K.-R. M ¨ uller , T . Wie gand, B. Blankertz, EEG-based classification of video quality perception using steady state visual ev oked potentials (SSVEPs), J. Neural Eng. 12 (2) (2015) 026012. [22] A. Tzov ara, M. M. Murray , N. Bourdaud, R. Chav arriaga, J. d. R. Mill ´ an, M. De Lucia, The timing of exploratory decision-making revealed by single-trial topographic EEG analyses, NeuroImage 60 (4) (2012) 1959– 1969. [23] J. Y osinski, J. Clune, A. Nguyen, T . Fuchs, H. Lipson, Understanding neural networks through deep visualization, arXiv preprint (2015) CoRR abs/1506.06579. 5 Fig. 1. (a) Example of LRP relev ance maps for a single trial of each class of subject od. The matrices indicate the rele vance of each time point (ordinate) and EEG channel (abscissa). Below the matrix the rele vance information for two single time points (indicated by the green line) is plotted as a scalp topography . The scalp plot above the matrices depict the average relev ance map across the time windo w of the entire epoch. (b) CSP patterns (top) and relev ance maps (bottom) for subject od. Here, the rele vance maps represent the average of all trials of one class, additionally av eraged across the time windo w of the entire epoch. The CSP pattern represents the whole ensemble of samples of one class. (c) Rele vance maps and DNN output. Examples of (time-averaged) relevance maps for single trials with different classification outcomes. V alues abo ve 0.5 indicate a decision for class ‘left hand’, values below 0.5 for class ‘right hand’. V alues close to the extrema 0 and 1 indicate high confidence of the decision. Correctly classified samples appear above the axis, incorrectly classified samples below .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment