Conversational Markers of Constructive Discussions
Group discussions are essential for organizing every aspect of modern life, from faculty meetings to senate debates, from grant review panels to papal conclaves. While costly in terms of time and organization effort, group discussions are commonly se…
Authors: Vlad Niculae, Cristian Danescu-Niculescu-Mizil
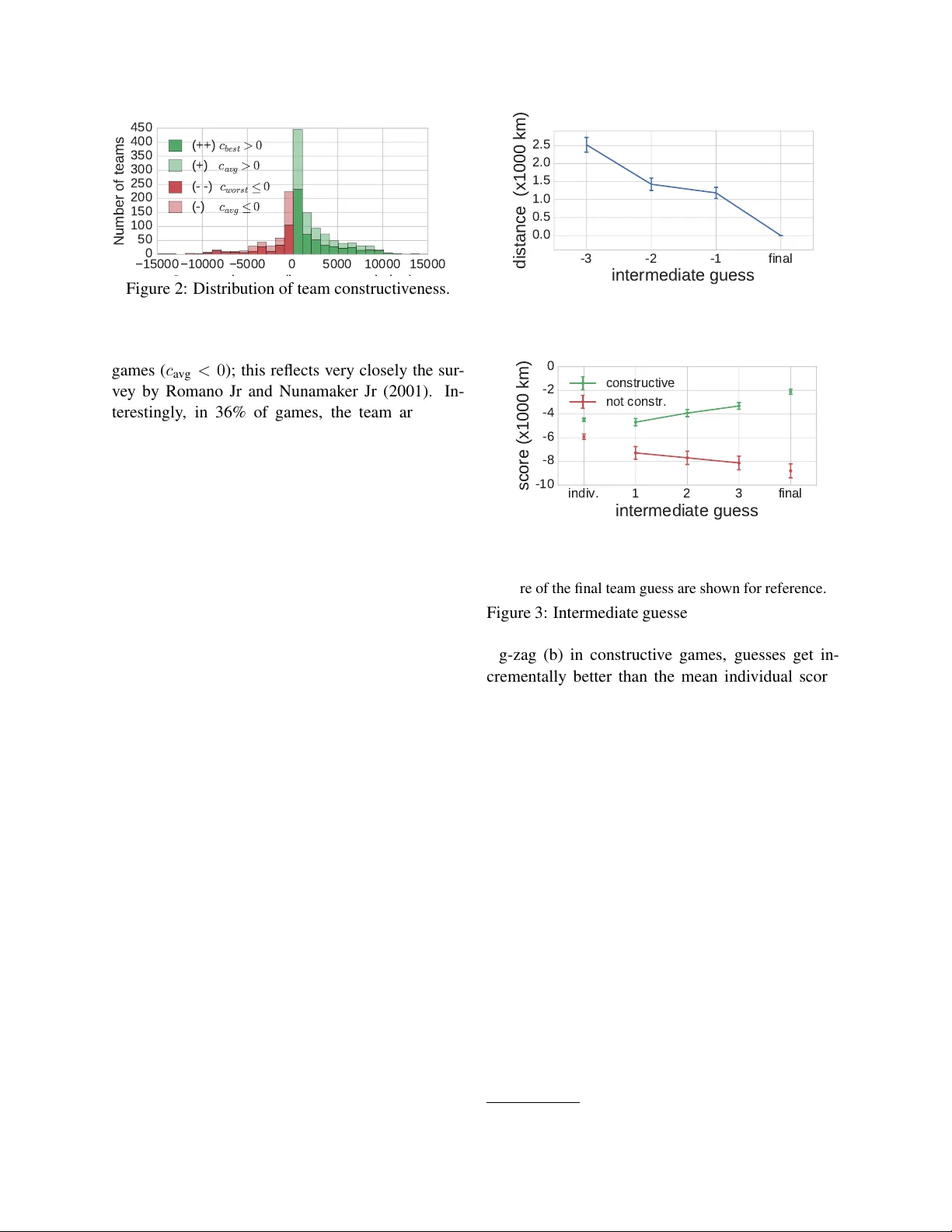
Con versational Mark ers of Constructiv e Discussions Vlad Niculae and Cristian Danescu-Niculescu-Mizil { vlad|cristian } @cs.cornell.edu Cornell Uni versity Abstract Group discussions are essential for organiz- ing ev ery aspect of modern life, from faculty meetings to senate debates, from grant revie w panels to papal conclaves. While costly in terms of time and organization effort, group discussions are commonly seen as a way of reaching better decisions compared to solu- tions that do not require coordination between the individuals (e.g. voting)—through discus- sion, the sum becomes greater than the parts. Howe ver , this assumption is not irrefutable: anecdotal evidence of w asteful discussions abounds, and in our own experiments we find that o ver 30% of discussions are unproductiv e. W e propose a framework for analyzing con- versational dynamics in order to determine whether a given task-oriented discussion is worth having or not. W e exploit conv ersa- tional patterns reflecting the flow of ideas and the balance between the participants, as well as their linguistic choices. W e apply this framew ork to con versations naturally occur- ring in an online collaborativ e world explo- ration game de veloped and deployed to sup- port this research. Using this setting, we sho w that linguistic cues and con versational patterns extracted from the first 20 seconds of a team discussion are predictiv e of whether it will be a wasteful or a producti ve one. 1 Introduction W orking in teams is a common strategy for decision making and problem solving, as building on effec- ti ve social interaction and on the abilities of each member can enable a team to outperform lone in- di viduals. Evidence shows that teams often per- form better than indi viduals (W illiams and Stern- berg, 1988) and ev en hav e high chances of reaching correct answers when all team members were pre- viously wrong (Laughlin and Adamopoulos, 1980). Furthermore, team performance is not a factor of in- di vidual intelligence, but of collective intelligence (W oolley et al., 2010), with interpersonal interac- tions and emotional intelligence playing an impor- tant role (Jordan et al., 2002). Y et, as most people can attest from experience, team interaction is not always smooth, and poor co- ordination can lead to unproductiv e meetings and wasted time. In fact, Romano Jr and Nunamaker Jr (2001) report that one third of work-related meet- ings in the U. S. are considered unproductive, while a 2005 Microsoft employee surve y reports that 69% of meetings are ineffecti ve. 1 As such, many gro w cynical of meetings. Computational methods with the ability to reli- ably recognize unproductiv e discussions could hav e an important impact on our society . Ideally , such a system could provide actionable information as a discussion progresses, indicating whether it is likely to turn out to be producti ve, rather than a waste of time. In this paper we focus on the con versational aspects of productiv e interactions and take the fol- lo wing steps: • introduce a constructiveness framework that al- lo ws us to characterize teams where discussion enables better performance than the indi vidu- als could reach, and, con versely , teams better of f not having discussed at all (Section 3); • create a setting that is conduci ve to decision- making discussions, where all steps of the process (e.g., individual answers, intermedi- ate guesses) are observable to researchers: the Str eetCr owd game (Sections 4–5); 1 money.cnn.com/2005/03/16/technology/survey/ • dev elop a novel framew ork for con versational analysis in small group discussions, studying aspects such as the flow of ideas, con versational dynamics, and group balance (Sections 6–7). W e re veal dif ferences in the collectiv e decision process characteristic of productiv e and unproduc- ti ve teams, and sho w that these differences are re- flected in their con versational patterns. F or e xam- ple, the language used when new ideas are intro- duced and adopted encodes important discrimina- ti ve cues. Measures of interactional balance and language matching (Niederhof fer and Pennebaker , 2002; Danescu-Niculescu-Mizil et al., 2011) also prov e to be informativ e, suggesting that more bal- anced discussions are most producti ve. Our results underline the potential held by computational ap- proaches to con versational dynamics. T o encour- age further work in this direction, we render our dataset of task-oriented discussions and our feature- extraction code publicly a vailable. 2 2 Related W ork Existing computational work on task-oriented group interaction is largely focused on ho w well the team performs. Coetzee et al. (2015) deployed and stud- ied the impact of a chat-based team interaction plat- form in massi ve open online courses, finding that teams reach more correct answers than individuals, and that the experience is more enjoyable. One of- ten studied experimental setting is the HCRC Map T ask Corpus (Anderson et al., 1991), consisting of 128 con versations between pairs of people, where a designated one gi ves directions to the other . This simplified setting avoids issues like role establish- ment and leadership. Reitter and Moore (2007) find that successful dialogs are characterized by long- term adaptation and alignment of linguistic struc- tures at syntactic, lexical and character lev el. A notable feature of this work is the success pr edic- tion task attempted using only the first 5 minutes of con versation. Other attempts use authority le vel features inspired from negotiation theory , experi- mental meta-features, task-specific features (May- field et al., 2011), and sociolinguistic spelling differ - ences (Mayfield et al., 2012). Another research path 2 https://vene.ro/constructive/ uses negotiation tasks from the Inspire dataset (K er- sten and Zhang, 2003), a collection of 1525 online bilateral negotiations where roles are fixed (buyer and seller) and success is defined by the sale going through. Sokolov a et al. (2008) use a bag-of-words model and in vestigate the importance of temporal aspects. Sokolov a and Lapalme (2012) measure in- formati veness, quantified by lexical sets of degrees, scalars and comparati ves. Research on success in groups with more than two members is less common. Friedberg et al. (2012) model the grades of 27 group assignments from a class using measures of av erage entrainment, finding task-specific words to be a strong cue. Jung (2011) sho ws how the affecti ve balance expressed in teams correlates with performance on engineering tasks, in 30 teams of up to 4 students. In a related study the balance in the first 5 minutes of an interaction is found predictiv e of performance (Jung et al., 2012). None of the research we are aware of controls for initial skill or potential of the team members. In management science, network analysis reveals that certain subgraphs found in long-term, structured teams indicate better performance, as rated by se- nior managers (Cummings and Cross, 2003); con- trolled experiments sho w that optimal structures de- pend on the complexity of the task (Guetzko w and Simon, 1955; Bavelas, 1950). These studies, as well as much of the research on effecti ve team cro wd- sourcing (Lasecki et al., 2012; W ang et al., 2011, inter alia ), do not focus on linguistic and conv ersa- tional factors. 3 Constructive Discussions The first hurdle is to reliably quantify how produc- ti ve group con versations are. In problem-solving, the ultimate goal is to find the correct answer, or , failing that, to come as close to it as possible. T o quantify closeness to the correct answer , a scor e is often used, such that better guesses get higher scores; for example, school grades. In contrast, our goal is to measure ho w produc- ti ve a team’ s interaction is. Scores are measures of correctness, so using them as a proxy for interaction quality is not ideal: a team of straight A students can manage to get an A on a project without exchang- ing ideas, while a group of D students getting a B is g 1 g 2 g 3 g 4 true answer score( g 1 ) (best individual guess) Avg[ score( g i ) ] (mean score of individual guesses) t t t discussion start discussion end time score score of team guess c avg (constructiveness) Figure 1: Intuiti ve sketch for constructiveness. The solid green circle corresponds a team guess follow- ing a constructiv e discussion ( c avg > 0 ), the dashed green circle corresponds to the scenario of a team that outperforms its best member ( c best > 0 ), while the dashed red circle corresponds to a team that un- derperforms its worst member ( c worst < 0 ). more interesting. In the latter case, the team’ s im- prov ed performance is likely to come from a good discussion and an ef ficient exchange of complemen- tary ideas—making the sum greater than the parts. T o capture this intuition we say a team discussion is constructive if it results in an improv ement ov er the potential of the individuals. W e can then quan- tify the degree of constructiv eness c avg as the im- prov ement of the team score t over the mean of the initial scores g i of the N individuals in the team: c avg = score( t ) − P N i =1 score( g i ) N . The higher c avg is, the more the team’ s answer , af- ter discussion , improves upon the indi viduals’ aver - age performance befor e discussion ; zero construc- ti veness ( c avg = 0 ) means the team performed no better than its members did before discussing, while negati ve constructiv eness ( c avg < 0 ) corresponds to non-constructiv e discussions. 3 Figure 1 sketches the idea visually: the dark green circle corresponds to the team’ s score after a constructiv e discussion ( c avg > 0 ), being above the av erage individual score. Since indi viduals answers can sometimes vary widely , we also consider the extreme cases of teams 3 From an operational perspecti ve, a team can choose, in- stead of having a discussion, to aggregate individual guesses, e.g., by majority voting or averaging. Non-constructiv e dis- cussions roughly correspond to cases where such an aggregate guess would actually be better than what the team discussion would accomplish. that perform better than the best team member ( c best > 0 ) and worse than the worst member ( c worst < 0 ), where: c best = score( t ) − max i score( g i ) c worst = score( t ) − min i score( g i ) . One way to think of the extreme cases is to imag- ine a team supervisor that collects the indi vidual an- swers and aggregates them, without an y external in- formation. An oracle supervisor can do no better than choosing the best answer . The discussion and interaction of teams where c best > 0 leads to a better answer than such an oracle could achieve. (One such scenario is illustrated by the dashed light green cir- cle in Figure 1.) Similarly , teams where c worst < 0 waste their time completely , as simply picking one of their members’ answers at random is guaranteed to do better . (The dashed red circle in Figure 1 illus- trates this scenario.) The most important aspect of the constructiv e- ness frame work, in contrast to traditional measures of correctness or success, is that all constructi veness measures are designed to control for initial perfor- mance or potential of the team members, in order to focus on the ef fect of the discussion. 4 In settings of importance, the true answer is not kno wn a priori, and this constructi veness cannot be calculated directly . W e therefore seek out to model constructi veness using observable conv ersa- tional and linguistic correlates (Sections 6–7). T o de velop such a model, we design a large-scale exper - imental setting where the true answer is av ailable to researchers, b ut unkno wn by the players (Section 4). 4 Experimental setting 4.1 StreetCro wd In order to study the constructiv eness of task- oriented group discussion, we need a setting that is conduci ve to decision-making discussions, where all steps of the process (individual answers, intermedi- ate guesses, group discussions and decisions) are ob- serv able. Furthermore, to study at scale, we need to 4 Due to its relativ e nature, constructiveness also accounts for variation in task dif ficulty in most scenarios. For example, in terms of c worst , when a team cannot e ven match its w orst per- forming member, this is a sign of poor team interaction even if the task is particularly challenging. find a class of complex tasks with known solutions that can be automatically generated, but that cannot be easily solved by simply querying search engines. W ith these constraints in mind, we b uilt Str eetCr owd , an online multi-player world explo- ration game. 5 Str eetCr owd is played in teams of at least two players and is built around a geographic puzzle: determining your location based on first- person images from the ground le vel. 6 Each location generates a ne w puzzle. Solo phase. Each player has 3 minutes to navi- gate the surroundings, explore, and try to find clues. This happens independently and without communi- cating. At the end, the player is asked to make a guess by placing a marker on the world’ s map, and is prompted for an explanation and for a confidence le vel. The answer is not yet rev ealed. T eam phase. The team must then decide on a single, common guess. T o accomplish this, all teammates are placed in a chatroom and are provided with a map and a shared marker . An y player can mov e the marker at any point during the discussion. The game ends when all players agree on the answer, or when the time limit is reached. An example discussion is gi ven in Figure 4. Guesses are scored according to their distance to the true location using the spherical law of cosines: score( guess , true ) = − Rd ( guess , true ) where d is the arc distance on a sphere, and R de- notes the radius of the earth, assumed spherical. The score is gi ven by the negati ve distance in kilometers, such that higher means better . T o motiv ate players and emphasize collaboration, the main Str eetCr owd page displays a leaderboard consisting of the best team players. The ke y aspects of the Str eetCr owd design are: • The puzzles are complex and can be generated automatically in large numbers; • The true answers are known to researchers, b ut hard to obtain without solving the puzzle, al- lo wing for objectiv e e v aluation of both indi vid- ual and group performance; 5 http://streetcrowd.us/start (the experiment was appro ved by the IRB). 6 W e embed Google Street V iew data. • Scoring is continuous rather than discrete, al- lo wing us to quantify degrees of improv ement and capture incremental ef fects; • Each teammate has a dif ferent solo phase ex- perience and background kno wledge, making it possible for the group discussion to shed light on ne w ideas; • The puzzles are engaging and naturally con- duci ve to collaboration, avoiding the use of monetary incenti ves that can bias beha vior . 4.2 Preprocessing In the first 8 months, over 1400 distinct players par- ticipated in over 2800 Str eetCr owd games. W e tok- enize and part-of-speech tag the con versations. 7 Be- fore analysis, due to the public nature of the game, we perform sev eral filtering and quality check steps. Discarding trivial games. W e remove all games that the dev elopers took part in. W e filter games where the team fails to provide a guess, where fe wer than two team members engage in the team chat, and puzzles with insuf ficient samples. Pre venting and detecting cheating. The Str eetCr owd tutorial asks players to av oid us- ing external resources to look up clues and get an unfair advantage. T o prev ent cheating, we detect and block chat messages that link to websites, and we employ cookies and user accounts to prevent people from playing the same puzzle multiple times. T o identify games that slip through this net, we flag cases where the team, or any individual player , guesses within 10 km of the correct answer , and lea ves the window while playing. W e further remov e a small set of games where the players confess to cheating in the chat. After filtering, our dataset consists of 1450 games on 70 different puzzles, with an a verage of 3.9 games per unique player, and 12.1 messages and 64.5 words in an a verage con versation. 5 Constructiveness in Str eetCrowd W e find that, indeed, most of the games are con- structi ve. There are, howe ver , 32% non-constructive 7 W e use the T weetNLP toolkit (Owoputi et al., 2013) with a tag set developed for T witter data. Manual examination rev eals this approach to be well suited for online chat data. 15000 10000 5000 0 5000 10000 15000 Constructiveness (improvement in km) 0 50 100 150 200 250 300 350 400 450 Number of teams ( + + ) c b e s t > 0 ( + ) c a v g > 0 ( ) c w o r s t 0 ( ) c a v g 0 Figure 2: Distribution of team constructi veness. games ( c avg < 0 ); this reflects very closely the sur- ve y by Romano Jr and Nunamaker Jr (2001). In- terestingly , in 36% of games, the team arri ves at a better answer than any of the individual guesses ( c best > 0 ). The flip side is also remarkably com- mon, with 17% of teams performing ev en worse than the worst individual ( c worst < 0 ). The distrib ution of constructi veness is shown in Figure 2: the fat tails indicate that cases of lar ge improvements and large deterioration are not uncommon. Collective decision process. Due to the full instru- mentation of the game interface, we can in vestigate ho w constructiveness emerges out of the team’ s in- teraction. The team’ s intermediate guesses during discussion confirm that a meaningful process leads to the final team decision: guesses get closer and closer to the final submitted guess (Figure 3a); in other words, the team con ver ges to their final guess. Notably , when considering how corr ect the in- termediate guesses are, we notice an important dif ference between the way constructive and non- constructi ve teams con ver ge to their final guess (Fig- ure 3b). During their collaborativ e decision pro- cess, constructiv e teams make guesses that get closer and closer to the correct answer; in contrast, non- constructi ve teams make guesses that take them far- ther from the correct answer . This observation has two important consequences. First, it shows that the two types of teams behav e dif ferently through- out, suggesting we could potentially detect non- constructi ve discussions early on, using interaction patterns. Second, it emphasizes the potential practi- cal v alue of such a task: stopping a non-constructi ve team early could lead to a better answer than if they would carry on. 3 2 1 final intermediate guess 0.0 0.5 1.0 1.5 2.0 2.5 distance (x1000 km) (a) Distance between the last three intermediate guesses and the final guess. indiv. 1 2 3 final intermediate guess 10 8 6 4 2 0 score (x1000 km) constructive not constr. (b) Score of the first three intermediate guesses; the mean score of the initial individual guesses and the score of the final team guess are shown for reference. Figure 3: Intermediate guesses offer a glimpse at the decision process: (a) guesses con ver ge rather than zig-zag (b) in constructiv e games, guesses get in- crementally better than the mean indi vidual score, while in non-constructiv e games, they get worse. (Games with ≥ 3 intermediate guesses.) 6 Con versation analysis The process of team con ver gence rev ealed in the pre- vious section suggests a relation between the inter- action leading to the final group decision and the rel- ati ve quality of the outcome. In this section, we de- velop a conv ersation analysis framework aimed at characterizing this relation. This frame work relies on con versational patterns and linguistic features, while steering away from lexicalized cues that might not generalize well beyond our e xperimental setting. T o enable reproducibility , we make av ailable the fea- ture extraction code and the hand-crafted resources on which it relies. 8 8 https://vene.ro/constructive/ J: hey E: Hey L: based on the buildings i would say China E: What do you guys think? Yeah, same J: I feel like it is somewhere in south east asia E: In Shanghai the buildings all look like that But Shanghai is too densely urban This is definitely somewhere on the outskirts of the city L: yeap E: any other ideas? J: is there a place more rural with that kind of buildings ? E: haha china is HUGE I couldn't guess J: For sure it is in Asia, but I don't know more... L: let s pick in the subburbs of shanghai E: Yeah J: alright, let's go with this. J: Tropical setting + some asia writing signs E: Lots of similar looking apartments - like outskirts of urban China L: (None given) Reasons Chat Idea flow J E L 1 2 1 Figure 4: Example (constructi ve) con versation and the corresponding flow of ideas. Idea mentions are in bold, and relev ant word classess are un- derlined. Arro w colors map to introducer –adopter pairs, matching the edges in the top-right graph. 6.1 Idea flow T ask-oriented discussions are the the primary way of exchanging ideas and opinions between the group members; some are quickly discarded while others prov e useful to the final guess. The arrows in Fig- ure 4 show how ideas are introduced and discussed in that e xample con versation. W e attempt to cap- ture the shape in which the ideas flow in the discus- sion. In particular , we are interested in how many ideas are discussed, ho w widely they are adopted, who tends to introduce them, and ho w . W e consider as candidate ideas all nouns, proper nouns, adjectiv es and verbs that are not stopwords. As soon as a candidate idea introduced by a player is adopted by another , we count it. Henceforth, we’ll refer to such adopted ideas simply as ideas . In gen- eral chat domains, state-of-the-art models of con ver - sation structure use unsupervised probabilistic mod- els (Ritter et al., 2010; Elsner and Charniak, 2010). Since Str eetCr owd con versations are short and fo- cused, the adoption filter is sufficient to accurately capture what ideas are being discussed; a manual examination of the ideas rev eals almost exclusi vely place names and words such as flag , sign , r oad — highly relev ant clues in the context of Str eetCr owd . In Figure 4, three ideas are adopted: China , build- ings and Shanghai . The only idea adopted by all players is b uildings , a good signal that this was the most important clue. A notable limitation is that this approach cannot capture the connections between Shanghai and China , or buildings and apartments . Further work is needed to rob ustly capture such v ari- ations in idea flo w , as they could rev eal trajectories (discussion getting more specific or more vague) or lexical choice disagreement. Balance in idea contributions between the team members is a good indicator of producti ve discus- sions. In particular, in the best teams (the ones that outperform the best player , i.e., c best > 0 ) the most idea-prolific player introduces fewer ideas, on av erage, than in the rest of the games (Figure 5a, p = 0 . 01 ). 9 In Figure 4, E is the most prolific player and only introduces two ideas. T o further capture the balance in contribution between the team members, we use the entropy of the number ideas introduced by each player . W e also count the number of ideas adopted unanimously as an indicator of con vergence in the con versation. In terms of the ov erall number of ideas dis- cussed, both the best teams (the ones that outper- form the best player) and the worst teams (the ones that perform worse than the worst player) discuss fe wer ideas than the rest (Figure 5b, p = 0 . 006 ). Indeed, an ideal interaction would avoid distract- ing ideas, but in teams with communication break- do wns, members might fail to adequately discuss the ideas that led them to their indi vidual guesses. The language used to introduce ne w ideas can indicate confidence or hesitation; in Figure 4, a hedge ( would ) is used when introducing the build- ings cue. W e find that, in teams that outperform the best player , ideas are less likely to be accom- 9 All p-values reported reported in this section are based on one-sided Mann-Whitney rank statistical significance tests. ++ + 0.8 1.0 1.2 1.4 (a) Ideas by most prolific player ++ + 1.2 1.4 1.6 1.8 2.0 (b) Ideas adopted ++ + 0.2 0.4 0.6 0.8 1.0 (c) Hedged idea introductions ++ + 0.4 0.6 0.8 1.0 1.2 (d) Hedged idea adoptions ++ + 22 24 26 (e) T ime between turns (seconds) ++ + 0.25 0.30 0.35 0.40 (f) Guessing entropy ++ + 0.91 0.92 0.93 0.94 (g) Message entropy ++ + 0.15 0.20 0.25 (h) Max-pair content word matching ++ + 0.8 1.0 1.2 1.4 1.6 (i) Overall POS bigram matching ++ + 0.06 0.07 0.08 (j) Ratio of words related to geography Figure 5: A verages for some of the predicti ve features, based on idea flo w (a-d), balance (e-i), and lexicons (j). Error bars denote standard errors. Legend: (++): teams that do better than their best member ( N = 525 ), (+): constructive ( N = 986 ), (-): non-constructi ve ( N = 464 ), (- -): worse than worst member ( N = 248 ). panied by hedge words when introduced (Figure 5c, p < 10 − 4 ), sho wing less hesitation. Furthermore, the level of confidence used when players adopt oth- ers’ ideas is also informativ e (Figure 5d). Inter- estingly , o verall occurrences of certainty and hedge words (detailed in Section 6.3) are not predictiv e, suggesting that ideas are good selectors for impor- tant discussion segments. 6.2 Interaction dynamics Balance. Interpersonal balance has been sho wn to be predicti ve of team performance (Jung, 2011; Jung et al., 2012) and, similarly , forms of linguistic bal- ance have been shown to characterize stable rela- tionships (Niculae et al., 2015). Here we focus on balance in contrib utions to the discussion and the de- cision process. In search of measures applicable to teams of arbitrary sizes, we use binary indicators of whether all players participate in the discussion and in moving the marker , as well as whether at least two players mov e the marker . T o measure team bal- ance with respect to continuous user-le vel features, we use the entropy of these features: balance( S ) = − X ¯ s ∈ S ¯ s log | S | ¯ s, where, for a given feature, S is the set of its val- ues for each user , normalized to sum to 1. For in- stance, the chat message entropy is 1 if ev erybody chats equally , and decreases toward 0 as one or more players dominate. W e use the entropy of the num- ber of messages, words per message, and number of intermediate guesses. In teams that outperform the best player , users take turns controlling the marker more uniformly (Figure 5f, p = 0 . 006 ), adding fur- ther e vidence that well-balanced teams perform best. Language matching. W e inv estigate matching at stopword, content word, and POS tag bigram level: the stopword matching at a turn is gi ven by the num- ber of stopwords from the earlier message repeated in the reply , di vided by the total number of distinct stopwords to choose from; similarly for the rest. W e micro-av erage over the con versation: matc h = P ( msg , reply ) ∈ T urns | msg ∩ reply | P ( msg , reply ) ∈ T urns | msg | . W e also micro-average at the player-pair le vel, and use the maximum pair value as a feature. This giv es an indication of ho w cohesiv e the closest pair is, which can be a sign of the le vel of po wer imbal- ance between the two (Danescu-Niculescu-Mizil et al., 2012). Figure 5h shows that in teams that out- perform the best individual the most cohesive pair matches fewer content words ( p = 0 . 023 ). Overall matching is also significant, notably in terms of part- of-speech bigrams; in teams that outperform the best indi vidual there is less ov erall matching (Figure 5i, p = 0 . 007 ). These results suggest that in construc- ti ve teams the relationships between the members are less subordinate. Agreement and confidence. W e capture the amount of agreement and disagreement using high-precision ke ywords and filters validated on a subset of the data. (For instance, the word sur e marks agreement if found at the be ginning of a message, b ut not other- wise.) In Figure 4, agreement signals are underlined with purple; the team exhibits no disagreement. The relativ e position of successiv e guesses made can also indicate whether the team is refining a guess or contradicting each other . W e measure the median distance between intermediate guesses, as well as between guesses made by dif ferent players; in con- structi ve teams, the jumps between different player guesses are smaller ( p < 10 − 16 ). Before the discussion starts, players are asked to self-ev aluate their confidence in their individual guesses. Constructi ve teams hav e more confident members on av erage ( p < 10 − 5 ). 6.3 Other linguistic features Length and variation. W e measure the av erage number of words per message, the total number of words used to express the solo phase reasons, and the overall type/token ratio of the con versation. W e also measure responsiveness in terms of the mean time between turns and the total number of turns. Psycholinguistic lexicons. W e use hand-crafted lexicons inspired from LIWC (T ausczik and Pen- nebaker , 2010) to capture certainty and pronoun use. F or example, the con versation in Figure 4 has two confident phrases, underlined in red. W e also use a custom hedging lexicon adapted from Hyland (2005) for conv ersational data; hedging words are underlined in blue in Figure 4. T o estimate how grounded the conv ersation is, we measure the av- erage concreteness of all content nouns, adjecti ves, adverbs and verbs, using scalar word and bigram rat- ings from Brysbaert et al. (2014). 10 Concreteness reflects the degree to which a word denotes some- thing perceptible, as opposed to ideas and concepts. W ords like soil and coconut are highly concrete, while words like trust ha ve lo w concreteness. Game-specific words. W e put together a lexicon of geography terms and place names, to capture task- 10 W e scale the ratings to lie in [0 , 1] . W e e xtrapolate to out- of-vocab ulary words by regressing on dependency-based word embeddings (Levy and Goldber g, 2014); this approach is highly accurate (median absolute error of about 0.1). Full con versation First 20s Features (++) (+) (- -) (++) (+) (- -) Baseline .51 .52 .55 .52 .50 .54 Linguistic .54 .52 .50 .50 .51 .50 Interaction .55 † .56 † .53 .55 † .57 ? .56 POS .55 † .59 ? .55 .54 .54 .53 All .56 ? .60 ? .56 .56 ? .57 ? .57 † T able 1: Cross-v alidation A UC scores. Signifi- cantly better than chance scores after 5000 permu- tations denoted with ? ( p < 0 . 05 ) and † ( p < 0 . 1 ). specific discussion. W e use a small set of words specific to the Str eetCr owd interface, such as map, marker , and game , to capture phatic communica- tion. Figure 5j shows that constructiv e teams tend to use more geography terms ( p = 0 . 008 ), possi- bly because of more on-topic discussion and a more focused vocab ulary . Part-of-speech patterns. W e use n-grams of coarse part-of-speech tags as a general way of capturing common syntactic patterns. 7 Predicting constructi veness 7.1 Experimental setup So far we hav e characterized the relation between a team’ s interaction patterns and its lev el of produc- ti vity . This opens the door to wards recognizing con- structi ve and non-constructi ve interactions in real- istic settings where the true answer is not known. Ideally , such an automatic system could prompt un- producti ve teams to reconsider their approach, or to aggregate their indi vidual answers instead. W ith early detection , non-constructiv e discussions could be stopped or steered on the right track. In order to assess the feasibility of such a challenging task and to compare the predictive po wer of our features, we consider three classification objecti ves: (++): T eam outperforms its best member ( c best > 0 )? (+): T eam is constructiv e ( c avg > 0 )? (- -): T eam underperforms its worst member ( c worst < 0 )? T o in vestigate early detection , we ev aluate the clas- sification performance when using data from only the first 20 seconds of the team’ s interaction. 11 11 Measured from the first chat message or guess. For this ev aluation, we remov e teams where the first 20 seconds contain ov er 75% of the interaction, to av oid distorting the results with Since all three objecti ves are imbalanced (Fig- ure 2), we use the area under the R OC curve (A UC) as the performance metric, and we use logistic regression models. W e perform 20 iterations of puzzle-aw are shuf fled train-validation splitting, fol- lo wed by 5000 iterations on the best models, to esti- mate v ariance. This ensures that the models don’t learn to ov erfit puzzle-specific signals. The com- bined model uses weighted model averaging. W e use grid search for regularization parameters, feature extraction parameters, and combination weights. 7.2 Discussion of the results (T able 1) W e compare to a baseline consisting of the team size, av erage number of messages per player , and con versation duration. For comparison, a bag-of- words classifier does no better than chance and is on par with the baseline. W e refer to idea flow and interaction dynamics features (Section 6.2) as Inter- action , and to linguistic and lexical features (Sec- tion 6.3) as Linguistic . The combination model in- cluding baseline, interaction, linguistic and part-of- speech n-gram features, is consistently the best and significantly outperforms random guessing (A UC .50) in nearly all settings. While overall scores are modest, the results confirm that our con versa- tional analysis framew ork has predictiv e power , and that the high-stakes task of early pr ediction is fea- sible. The language used when introducing and adopting ideas, together with balance and language matching features, are selected in nearly all settings. The least represented class (- -) has the highest vari- ance in prediction, suggesting that more data collec- tion is needed to successfully capture e xtreme cases. Useful POS patterns capture the amount of proper nouns and their contexts: proper nouns at the end of messages are indicativ e of constructiv eness, while proper nouns follo wed by verbs are a negativ e fea- ture. (The constructi ve discussion shown in Figure 4 has most proper nouns at the end of messages.) A manual error analysis of the false positiv es and false negati ves where our best model is most con- fident points to games with very short con versations and spelling mistakes, confirming that the noisy data problem causes learning and modeling dif ficulties. teams who make their decision early , but tak e longer to submit. The 20 second threshold was chosen as a trade-of f in terms of how much interaction it co vers in the games. 8 Conclusions and Future W ork W e dev eloped a framework based on con versational dynamics in order to distinguish between produc- ti ve and unproductiv e task-oriented discussions. By applying it to an online collaborati ve game we de- signed for this study , we rev eal new interactions with con versational patterns. Constructi ve teams are gen- erally well-balanced on multiple aspects, with team- members participating equally in proposing ideas and making guesses and showing little asymmetry in language matching. Also, the flow of ideas between teammates marks predictive linguistic cues, with the most constructi ve teams using fe wer hedges when introducing and adopting ideas. W e show that such cues have predictive power e ven when extracted from the first 20 seconds of the con versations. In future work, improv ed clas- sifiers could lead to a system that can intervene in non-constructi ve discussions early on, steering them on track and pre venting w asted time. Further improving classification performance on such a difficult task will hinge on better con versation processing tools, adequate for the domain and robust to the informal language style. In particular , we plan to dev elop and e v aluate models for idea flo w and (dis)agreement, using more advanced features (e.g., from dependency relations and kno wledge graphs). The Str eetCr owd game is continuously accumu- lating more data, enabling further dev elopment on con versation analysis. Our full control over the game permits manipulation and intervention exper - iments that can further adv ance research on team- work. In future work, we en vision applying our frame work to settings where teamwork takes place online, such as open-source software development, W ikipedia editing, or massiv e open online courses. Acknowledgements W e are particularly grateful to Bob W est for the poolside chat that inspired the de- sign of the game, to Daniel Garay , Jinjing Liang and Neil P arker for participating in its development, and to the numerous passionate players. W e are also grateful to Natalya Bazaro v a, David Byrne, Mala Gaonkar , Lillian Lee, Sendhil Mullainathan, Andreas V eit, Connie Y uan, Justine Zhang and the anonymous revie wers for their insightful sugges- tions. This work was supported in part by a Google Faculty Research A ward. References Anne H Anderson, Miles Bader , Ellen Gurman Bard, Elizabeth Boyle, Gwyneth Doherty , Simon Garrod, Stephen Isard, Jacqueline K owtko, Jan McAllister , and Jim Miller . 1991. The HCRC map task corpus. Lan- guage and speec h , 34(4):351–366. Alex Ba velas. 1950. Communication patterns in task- oriented groups. J ournal of the Acoustical Society of America . Marc Brysbaert, Amy Beth W arriner, and V ictor Kuper- man. 2014. Concreteness ratings for 40 thousand generally known English word lemmas. Behavior Re- sear ch Methods , 46(3):904–911. Derrick Coetzee, Seongtaek Lim, Armando Fox, Bjorn Hartmann, and Marti A Hearst. 2015. Structuring interactions for lar ge-scale synchronous peer learning. In Pr oceedings of CSCW . Jonathon N Cummings and Rob Cross. 2003. Structural properties of work groups and their consequences for performance. Social Networks , 25(3):197–210. Cristian Danescu-Niculescu-Mizil, Michael Gamon, and Susan Dumais. 2011. Mark my words! Linguistic style accommodation in social media. In Pr oceedings of WWW . Cristian Danescu-Niculescu-Mizil, Lillian Lee, Bo Pang, and Jon Kleinberg. 2012. Echoes of po wer: Language effects and power dif ferences in social interaction. In Pr oceedings of WWW . Micha Elsner and Eugene Charniak. 2010. Disentan- gling chat. Computational Linguistics , 36(3):389– 409. Heather Friedber g, Diane Litman, and Susannah BF Paletz. 2012. Lexical entrainment and success in stu- dent engineering groups. In Pr oceedings of the Spoken Language T echnology W orkshop . Harold Guetzko w and Herbert A Simon. 1955. The im- pact of certain communication nets upon or ganization and performance in task-oriented groups. Mana ge- ment Science , 1(3-4):233–250. Ken Hyland. 2005. Metadiscourse: Exploring interac- tion in writing . Continuum. Peter J Jordan, Neal M Ashkanasy , Charmine EJ H ¨ artel, and Gregory S Hooper . 2002. W orkgroup emotional intelligence: Scale de velopment and relationship to team process effecti veness and goal focus. Human Re- sour ce Management Revie w , 12(2):195–214. Malte F Jung, Jan Chong, and Larry Leifer . 2012. Group hedonic balance and pair programming performance: affecti ve interaction dynamics as indicators of perfor- mance. In Pr oceedings of SIGCHI . Malte F Jung. 2011. Engineering team performance and emotion: Affective interaction dynamics as indicators of design team performance . Ph.D. thesis, Stanford Univ ersity . Gregory E Kersten and Grant Zhang. 2003. Mining in- spire data for the determinants of successful internet negotiations. Central Eur opean Journal of Oper ations Resear ch , 11(3). W alter S Lasecki, Christopher D Miller, Adam Sadilek, Andrew Abumoussa, Donato Borrello, Raja Kushal- nagar , and Jeffre y P Bigham. 2012. Real-time cap- tioning by groups of non-experts. In Pr oceedings of UIST . Patrick R Laughlin and John Adamopoulos. 1980. So- cial combination processes and indi vidual learning for six-person cooperati ve groups on an intellecti ve task. Journal of P ersonality and Social Psycholo gy , 38(6):941. Omer Levy and Y oa v Goldberg. 2014. Dependenc y- based word embeddings. In Pr oceedings of ACL . Elijah Mayfield, Michael Garbus, David Adamson, and Carolyn Penstein Ros ´ e. 2011. Data-driv en interac- tion patterns: Authority and information sharing in di- alogue. In Proceedings of AAAI F all Symposium on Building Common Gr ound with Intelligent Agents . Elijah Mayfield, David Adamson, Alexander Rudnicky , and Carolyn Penstein Ros ´ e. 2012. Computational rep- resentation of discourse practices across populations in task-based dialogue. In Pr oceedings of ICIC . Vlad Niculae, Srijan Kumar , Jordan Boyd-Graber , and Cristian Danescu-Niculescu-Mizil. 2015. Linguistic harbingers of betrayal: A case study on an online strat- egy game. In Proceedings of A CL . Kate G Niederhoffer and James W Pennebaker . 2002. Linguistic style matching in social interaction. Jour - nal of Language and Social Psychology , 21(4):337– 360. Olutobi Owoputi, Brendan O’Connor , Chris Dyer, K evin Gimpel, Nathan Schneider, and Noah A Smith. 2013. Improv ed part-of-speech tagging for online con ver- sational te xt with word clusters. In Pr oceedings of N AA CL . David Reitter and Johanna D Moore. 2007. Predicting success in dialogue. In ACL , v olume 45, page 808. Alan Ritter , Colin Cherry , Bill Dolan, et al. 2010. Un- supervised modeling of T witter con versations. In Pr o- ceedings of N AA CL . Nicholas C Romano Jr and Jay F Nunamaker Jr . 2001. Meeting analysis: Findings from research and prac- tice. In Pr oceedings of HICSS . Marina Sokolov a and Guy Lapalme. 2012. How much do we say? Using informativeness of negotiation text records for early prediction of negotiation outcomes. Gr oup Decision and Ne gotiation , 21(3):363–379. Marina Sokolo va, V ivi Nastase, and Stan Szpako wicz. 2008. The telling tail: Signals of success in electronic negotiation te xts. Yla R T ausczik and James W Pennebaker . 2010. The psychological meaning of words: LIWC and comput- erized text analysis methods. Journal of Language and Social Psychology , 29(1):24. Hao-Chuan W ang, Susan R Fussell, and Dan Cosley . 2011. From diversity to creativity: Stimulating group brainstorming with cultural differences and con versationally-retriev ed pictures. In Pr oceedings of CSCW . W endy M W illiams and Robert J Sternberg. 1988. Group intelligence: Why some groups are better than others. Intelligence , 12(4):351–377. Anita Williams W oolley , Christopher F Chabris, Alex Pentland, Nada Hashmi, and Thomas W Malone. 2010. Evidence for a collecti ve intelligence fac- tor in the performance of human groups. Science , 330(6004):686–688.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment