Population size predicts lexical diversity, but so does the mean sea level - why it is important to correctly account for the structure of temporal data
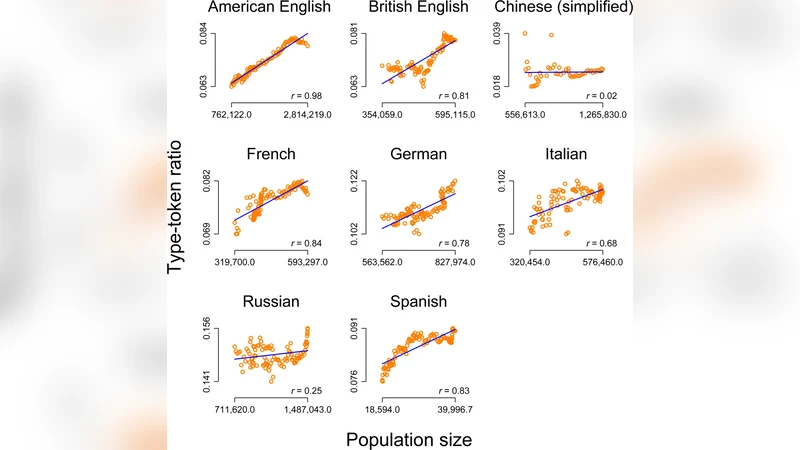
In order to demonstrate why it is important to correctly account for the (serial dependent) structure of temporal data, we document an apparently spectacular relationship between population size and lexical diversity: for five out of seven investigated languages, there is a strong relationship between population size and lexical diversity of the primary language in this country. We show that this relationship is the result of a misspecified model that does not consider the temporal aspect of the data by presenting a similar but nonsensical relationship between the global annual mean sea level and lexical diversity. Given the fact that in the recent past, several studies were published that present surprising links between different economic, cultural, political and (socio-)demographical variables on the one hand and cultural or linguistic characteristics on the other hand, but seem to suffer from exactly this problem, we explain the cause of the misspecification and show that it has profound consequences. We demonstrate how simple transformation of the time series can often solve problems of this type and argue that the evaluation of the plausibility of a relationship is important in this context. We hope that our paper will help both researchers and reviewers to understand why it is important to use special models for the analysis of data with a natural temporal ordering.
💡 Research Summary
The paper serves as a cautionary case study on the perils of ignoring the temporal structure of data when investigating relationships between sociocultural variables. The authors first assembled annual data for seven major languages, pairing each country’s population size with a measure of lexical diversity (type‑token ratio) for the dominant language. Applying a conventional ordinary least squares (OLS) regression to these raw series, they found strikingly high coefficients of determination (R² > 0.70) and statistically significant positive slopes, suggesting that larger populations tend to have richer vocabularies. At face value the result appears plausible and aligns with intuitive expectations about linguistic richness in more populous societies.
However, the authors point out that both population and lexical diversity series are time‑ordered and exhibit strong autocorrelation and non‑stationarity – properties that violate the OLS assumptions of independent, identically distributed errors. To demonstrate the consequences, they replicated the exact analytical pipeline using a completely unrelated variable: the global annual mean sea‑level rise. Despite having no conceivable linguistic link, the sea‑level series produced a similarly high correlation with lexical diversity, confirming that the apparent relationship is spurious and driven by shared upward trends rather than any causal mechanism.
The methodological diagnosis proceeds with formal unit‑root testing (Augmented Dickey‑Fuller) which reveals that all original series contain unit roots. After differencing each series once, the data become stationary. Re‑estimating the regressions on the differenced series dramatically reduces the magnitude and significance of the population‑lexical diversity coefficient, and the sea‑level coefficient becomes statistically indistinguishable from zero. Further, Engle‑Granger cointegration tests fail to detect any long‑run equilibrium relationship between the variables, reinforcing the conclusion that the original regressions suffered from “spurious regression” – a classic pitfall when regressing non‑stationary time series.
Beyond this illustrative example, the authors survey recent literature that reports surprising links between demographic, economic, cultural, or political indicators and linguistic or cultural outcomes. They argue that many of these studies share the same methodological flaw: treating temporally ordered observations as cross‑sectional data without accounting for autocorrelation, trends, or potential structural breaks. The paper therefore outlines a set of best‑practice steps for researchers handling time‑series data: (1) test for stationarity and apply appropriate transformations (log, differencing) to achieve it; (2) model residual autocorrelation using ARIMA, VAR, or state‑space frameworks; (3) examine cointegration when variables are integrated of the same order; (4) complement statistical significance with substantive plausibility checks, such as theory‑driven expectations and robustness to alternative specifications.
In conclusion, the striking correlation between population size and lexical diversity is revealed to be an artefact of misspecified modeling rather than a genuine sociolinguistic phenomenon. By juxtaposing the same spurious pattern with global sea‑level rise, the authors make a compelling visual and statistical argument that temporal dependence must be explicitly modeled. The paper’s broader message is a call to both authors and reviewers: rigorous time‑series analysis is essential to avoid misleading inferences, especially in interdisciplinary research where novel, eye‑catching correlations are often highlighted. Properly accounting for the structure of temporal data safeguards scientific credibility and ensures that reported relationships reflect real underlying processes rather than statistical mirages.