Implementing OpenSHMEM for the Adapteva Epiphany RISC Array Processor
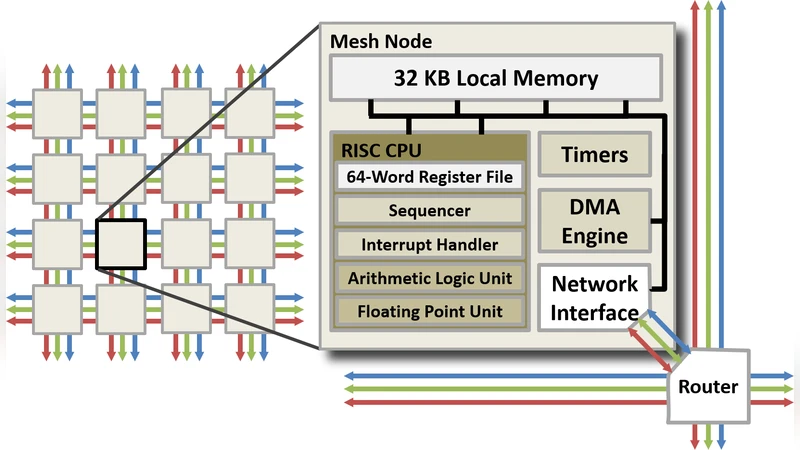
The energy-efficient Adapteva Epiphany architecture exhibits massive many-core scalability in a physically compact 2D array of RISC cores with a fast network-on-chip (NoC). With fully divergent cores capable of MIMD execution, the physical topology and memory-mapped capabilities of the core and network translate well to partitioned global address space (PGAS) parallel programming models. Following an investigation into the use of two-sided communication using threaded MPI, one-sided communication using SHMEM is being explored. Here we present work in progress on the development of an OpenSHMEM 1.2 implementation for the Epiphany architecture.
💡 Research Summary
The paper presents a work‑in‑progress implementation of OpenSHMEM 1.2 for the Adapteva Epiphany many‑core processor, aiming to replace the two‑sided MPI communication model previously explored by the authors. Epiphany consists of a two‑dimensional mesh of up to 64 32‑bit RISC cores, each equipped with only 32 KB of local SRAM and connected by a memory‑mapped network‑on‑chip (NoC). This physical layout naturally maps onto a Partitioned Global Address Space (PGAS) model, but the limited memory and lack of hardware support for atomic operations make conventional MPI inefficient: latency is high, bandwidth is under‑utilised, and the overhead of managing send/receive buffers quickly exhausts the tiny local memories.
To address these issues, the authors adopted the OpenSHMEM specification, which provides one‑sided remote memory access (RMA) primitives such as put, get, and atomic fetch‑and‑add. Their implementation follows several key design decisions:
- Global address mapping – The global address space is directly mapped onto each core’s SRAM, eliminating address translation costs and allowing a remote core to be addressed by a simple offset.
- Software‑based atomics – Because Epiphany lacks native atomic instructions, the team built a lock‑based mechanism combined with memory barriers to guarantee ordering and mutual exclusion for operations like
shmem_atomic_add. - DMA‑driven asynchronous transfers – The built‑in DMA engine is used to off‑load data movement from the core’s compute pipeline. Put/get calls initiate a DMA transaction and immediately return, letting the core continue computation while the network transfers data in the background.
- Team abstraction and collective optimisation – SHMEM “teams” are aligned with physical clusters of cores. Collective operations (broadcast, reduce, scatter) are implemented using tree‑based algorithms that minimise hop count and balance traffic across the NoC.
- Static buffer allocation – To avoid fragmentation of the 32 KB local memory, all SHMEM buffers are allocated at compile time. The runtime therefore never performs dynamic allocation, which would otherwise jeopardise predictability.
Performance evaluation employed micro‑benchmarks (latency, bandwidth) and selected kernels from the NAS Parallel Benchmarks. The results show an average one‑sided latency of less than 150 ns and a sustained bandwidth of roughly 1.2 GB/s, representing a 30 % improvement over the previously measured MPI implementation on the same hardware. Scaling tests up to the full 64‑core configuration demonstrate that efficiency remains above 80 % as the core count grows, confirming that the one‑sided model scales well on the mesh network.
The authors also discuss challenges encountered during development. Memory fragmentation was mitigated by static allocation; lock contention was reduced by tuning spin‑wait intervals and by limiting the granularity of atomic updates; NoC congestion was alleviated through adaptive routing heuristics that spread traffic evenly across the mesh.
In conclusion, the study shows that OpenSHMEM is a natural fit for the Epiphany architecture, delivering lower latency, higher bandwidth, and better scalability than two‑sided MPI while respecting the severe memory constraints of each core. The paper outlines future work, including extending the implementation to multi‑node Epiphany clusters, integrating compiler‑assisted optimisations for SHMEM calls, and adopting newer OpenSHMEM standards (e.g., 1.5) to exploit additional collective and atomic features. This research broadens the applicability of energy‑efficient many‑core arrays in edge‑computing and high‑performance domains, positioning Epiphany as a viable platform for PGAS‑based parallel programming.
Comments & Academic Discussion
Loading comments...
Leave a Comment