In the mood: the dynamics of collective sentiments on Twitter
We study the relationship between the sentiment levels of Twitter users and the evolving network structure that the users created by @-mentioning each other. We use a large dataset of tweets to which we apply three sentiment scoring algorithms, inclu…
Authors: Nathaniel Charlton, Colin Singleton, Danica Vukadinovic Greetham
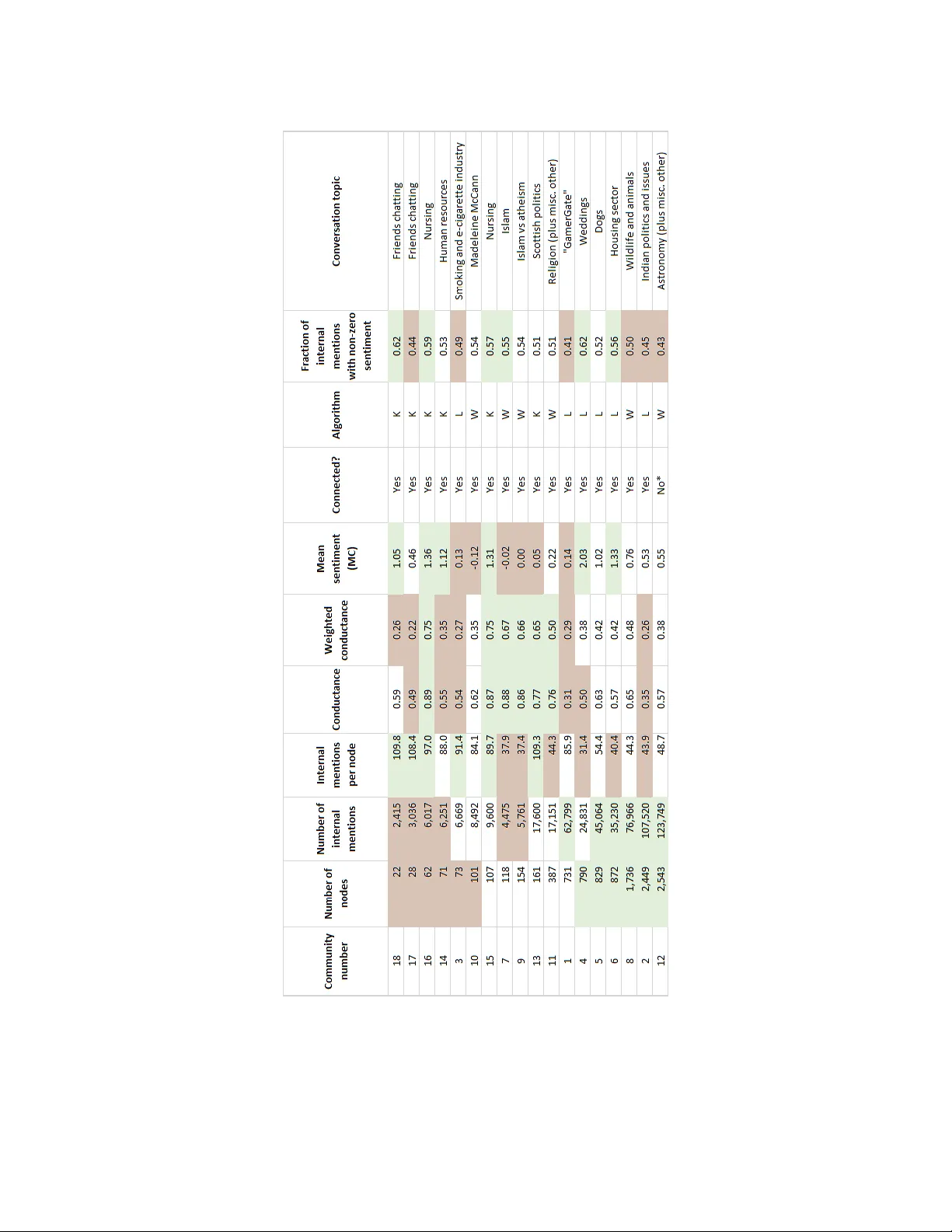
In the mo o d: the dynamics of collectiv e sen timen ts on Twitter Nathaniel Charlton ∗ 1,2 , Colin Singleton † 1,2 , and Danica V uk adino vi ´ c Greetham ‡ 2 1 Coun tingLab Ltd, Reading, UK 2 Cen tre for the Mathematics of Human Behaviour, Departmen t of Mathematics and Statistics, Univ ersity of Reading, UK Marc h 7, 2016 Abstract W e study the relationship b et ween the sentimen t lev els of Twitter users and the evolving net work structure that the users created b y @-men tioning eac h other. W e use a large dataset of t weets to whic h we apply three sentimen t scoring algorithms, including the op en source Sen- tiStrength program. Specifically w e mak e three contributions. Firstly we find that people who ha ve p otentially the largest comm unication reac h (according to a dynamic cen trality measure) use sentimen t differen tly than the av erage user: for example they use p ositiv e sentimen t more often and negativ e sen timent less often. Secondly w e find that when w e follo w structurally stable Twitter comm unities ov er a perio d of mon ths, their sen timen t lev els are also stable, and sudden changes in comm unity sentimen t from one da y to the next can in most cases b e traced to external ev ents affecting the communit y . Thirdly , based on our findings, we create and cali- brate a simple agen t-based model that is capable of reproducing measures of emotive resp onse comparable to those obtained from our empirical dataset. Keywor ds— evolving netw orks, Twitter comm unities, dynamics of collective emotions, com- m unicability , agen t-based mo delling 1 In tro duction It has b een noticed long before the In ternet that emotions app ear to b e contagious (see [6]). While differen t mechanisms w ere prop osed to explain this phenomenon, from complex cognitiv e pro cesses [2], to automatic mimicry and sync hronisation of facial, vocal, p ostural, and instrumental expressions with those around us [10], it is not y et clear ho w reverberating or inhibiting is online so cial media regarding contagion of emotions. Agen t-based mo delling was used to mo del dynamics of sen timents in online forums[16, 17] and to lo ok at the recent rise of the 15M mo vemen t in Spain [1]. It has b een shown in [20] that p ositive and negative affects [18] that are sometimes used to describ e positive and negative mo o d are not complemen tary and follo w differen t dynamics in a so cial net work. F urthermore, it was conjectured in [21] that the p eople with the p oten tially ∗ billiejo ec harlton@gmail.com † c.singleton@reading.ac.uk ‡ d.v.greetham@reading.ac.uk 1 largest reach to all the others in a smaller so cial netw ork o v er a week b elong to the group with the smallest negativ e affect at the b eginning of that perio d. In this work w e in vestigate whether similar conclusions can be disco v ered for large online so cial netw orks, using automatic sen timen t detection algorithms, and to what extent w e can develop a go o d mo del of collectiv e sen timen ts dynamics. Our con tributions are threefold: • Firstly , we apply dynamic c ommunic ability , a centralit y measure for evolving netw orks, to a sno wball-sampled Twitter netw ork, allowing us to iden tify the “top broadcasters” i.e. those users with p oten tially the highest communication reac h in the netw ork. W e find that p eople with the highest communicabilit y broadcast indices sho w differen t patterns of sentimen t use compared to ordinary users. F or example, top broadcasters send positive sentimen t messages more often, and negativ e sen timent messages less often. When they do use p ositiv e sen timen t, it tends to b e stronger. • Secondly , b y using a num ber of communit y detection algorithms in combination, w e w ere able to identify and monitor structurally stable (o ver a time-scale of months) “communities” or “sub-netw orks” of Twitter users. Users within these communities are well-connected and send messages to eac h other frequently compared with ho w frequently they send messages to users not in the comm unity . W e find that eac h such comm unity has its own sen timen t level, whic h is also relativ ely stable ov er time. W e find that when the sentimen t in a communit y temp orarily shows a large deviation from its usual level, this can typically b e traced to a significant identifiable even t affecting the communit y , sometimes an external news ev ent. Some of the communities w e follo wed retained all their users o ver the p erio d of monitoring, but the others lost a v arying (but relatively small) proportion of their users. W e find correlations b et w een the loss of users and the conductance and initial sentimen t of the comm unities. • Finally , an Agen t-Based Mo del of online so cial netw orks is presented. The mo del consists of a p opulation of sim ulated users, each with their o wn individual characteristics, suc h as their tendency to initiate new conv ersations, their tendency to reply when they ha ve b een sent a message, and their usual sentimen t level. The mo del allows for sen timent contagion, where users’ sen timent levels c hange in resp onse to the sentimen t of the messages they receiv e. W e demonstrate that this mo del, when its parameters are fitted to data from a real Twitter comm unity , accurately reproduces v arious aspects of that communit y . App endix A describes the data w e can make a v ailable to support this article. 2 Data The data analysed in this work consists of p osts (“t weets”) from Twitter. Twitter provides a platform for users to p ost short texts (up to 140 characters in length) for viewing by other users. Twitter users often direct or address their public tw eets to other users b y using men tions with the @ symbol. Suppose there are tw o users with usernames Alice and Bob. Alice migh t greet Bob by t weeting: “@Bob Goo d morning, ho w are y ou today?”. Bob migh t reply with “I am feeling splendid @Alice”. Note that although mentions are used to address other users in a t weet, the tw eet itself is still public and the messages may be read and commented on b y other users. W e comissioned a digital marketing agency to collect Twitter data for our exp eriments. This w as done in tw o stages: 2 1. Sno wball sampling of a large set of users. W e b egan with a single seed user. F or the seed user, and eac h time we added a user to our sample, w e retrieved that user’s last 200 public tw eets (or all their t weets if they had p osted fewer than 200 since account creation), and iden tified other users they had men tioned. These users were then added to the sample, and so on. In this manner 669,191 users were sampled and a total of 121,805,832 tw eets collected. Limiting the history collected to the last 200 tw eets enabled us to explore a larger subgraph of the Twitter net work, and ensured that w e would be able to find sufficiently man y in teresting comm unities for study . Informally sp eaking, our snowballed dataset w as broad at the exp ense of being shallow. 2. Obtaining a detailed t w eet history for selected in teresting groups of users. Once we had iden tified interesting communities of users for study (as w e will describ e in Section 4.4.1), con taining altogether 10,000 distinct users, we retreiv ed a detailed tw eet history for these users. W e downloaded each user’s p ervious 3,200 tw eets (a limit imp osed by the Twitter API) obtaining altogether 22,469,713 tw eets. Note that the p erio d cov ered by 3,200 tw eets v aries considerably dep ending on the tw eeting frequency of the user: hea vy users ma y p ost 3,200 tw eets in just a few da ys, whereas for some ligh t users 3,200 t weets extended all the w ay bac k to the year 2006. W e also monitored the users “liv e” for a further p erio d of 30 da ys, logging all their t w eets posted during this time, yielding a further 3,216,136 tw eets. Informally sp eaking, this part of our dataset w as deep (but at the exp ense of b eing narro wer). Using sen timent analysis programs, we assigned three sen timen t measures to each t w eet, named and describ ed as follo ws: (MC) This sentimen t score w as provided b y the mark eting company’s highly tuned proprietary algorithm. The algorithm inv olv es recognising words and phrases that t ypically indicate p ositiv e or negativ e sen timent, but its exact details are not published, as it is commercial IP . The score for each tw eet is an integer ranging from − 25 (extremely negative) through 0 (neutral) up to +25 (extremely p ositiv e). (SS) This sentimen t score w as pro duced by Sen tiStrength 1 program [19]. Sen tiStrength pro vides separate measures of the positive and negativ e sen timent of eac h t weet; w e deriv e a single measure analogous to (MC) by subtracting the strength of the negative sen timent from the strength of the p ositiv e sentimen t. The (SS) measure ranges from − 4 to +4. (L) This sentimen t score w as pro duced b y the LIWC2007 2 program [15]. Lik e SentiStrength, LIW C pro duces separate measures p osemo and ne gemo of p ositiv e and negative emotion; b y subtracting ne gemo from p osemo we derived a single real-v alued measure ranging from − 100 to +100. Although all three sentimen t classifiers are the result of extensive developmen t effort, none of them is p erfect; this is to be exp ected given the subtlety of h uman language. Thus w e think of the sen timent as a v ery “noisy” signal. The w ork describ ed in this pap er tak es a verages ov er large n umbers of t weets and users, so our results do not dep end on the exact score of particular individual t weets; w e require only that on a verage the sen timen t scores reflect the kind of sen timen ts expressed b y users. 1 h ttp://sentistrength.wlv.ac.uk/ 2 h ttp://www.liwc.net/ 3 3 Comm unicabilit y and sen timen t In this section we in vestigate how users with the highest p oten tial comm unication reach tend to use sentimen t in their messages. W e use dynamic c ommunic ability , a cen trality measure for ev olving netw orks, to assign br o adc ast sc or es to users; these scores are one metho d of quan tifying comm unication reac h that has b een inv estigated in the literature. Our inv estigation is motiv ated b y the finding, in three small observed so cial net work studies [21], that the individuals with large broadcast scores in general had very low lev els of negative affect at the beginning of the studies. 3.1 Broadcast scores In this subsection we briefly describe the measure w e used to quantify p oten tial comm unication reac h. The measure, called dynamic c ommunic ability [9], is a centralit y measure for ev olving net works based on Katz cen tralit y [11]. Katz centralit y in static net works coun ts all p ossible paths from and to eac h vertex, p enalising progressively longer paths. Let an evolving netw ork b e represen ted by a sequence of adjacency matrices A t , where t = 1 , . . . , n is the time-step. Then dynamic comm unicability coun ts all the p ossible time-resp ecting paths ov er the ev olving netw ork: suc h a path can mak e for example one hop at time-step t = 1 and the next hop at time-step t = 3, but not vice versa. The formal definition we use for a dynamic comm unicability matrix is Q = n Y t =1 ( I − αA t ) − 1 , where I is identit y matrix, α < ( ρ ( A t )) − 1 is a p enalising factor and ρ ( A t ) is the largest eigenv alue 3 of A t . When α is small, short paths in the netw ork are v alued highly relative to long paths; when α is larger, long paths are giv en a relatively larger w eigh t. Here we use one “snapshot” A t for each da y . Q is a square matrix, with ro ws and columns represen ting v ertices or individuals in the net w ork. The k th ro w and column sums each represen t a measure of communicabilit y for the vertex (user) k . The ro w sum represents the br o adc ast index while the column sum measures the r e c eive index. As the resp ectiv e names suggest, they measure how well the v ertex k is able to broadcast and receive messages o ver the net w ork. 3.2 Extracting a “mentions” net work to analyse broadcast scores Using the @-men tions in the tw eets we collected, w e extracted an evolving so cial net work to use for our in vestigation. This pro cess w as rather inv olv ed, for tw o reasons: 1. Because the snowball sampling data collection pro cess itself to ok sev eral weeks, and b ecause w e collected only the last 200 t weets for each user, the time perio d for which we had data w as not the same for all users. Th us w e needed to balance the desire for an ev olving netw ork co vering a longer perio d with the desire to hav e complete data for as many users as p ossible for that time p eriod. 3 Note that α < ( ρ ( A t )) − 1 , ∀ t = 1 , . . . , n , for the inv erse to exist. F or computational reasons, ( I − αA t ) − 1 = P ∞ i =0 α i A i t is often approximated with a finite truncation of the i first summands, whic h then also allows to relax the p enalising constraint to α < 1. 4 Figure 1: Histogram of the (SS) sentimen t measure scores for the t weets in the mentions netw ork w e analysed. 2. W e wan ted to focus our analysis on ordinary h uman users of Twitter, so w e wan ted to screen out outlier users such as celebrities and b ots. Celebrity accoun ts tend to b e men tioned by a v ast n umber of users, and some types of bot mec hanically mention h uge n um b ers of users. Including these accoun ts could cause the net work structure to b ecome degenerate, with a path of length t wo existing betw een most pairs of users via an intermediate celebrit y or b ot. W e extracted an ev olving men tions netw ork for the seven-da y p erio d from 9th October to 15th Octob er 2014, consisting of 6,052,615 edges b etw een 285,168 users. These edges came from 4,389,362 tw eets (one tw eet can mention m ultiple users, giving rise to more than one edge). Details of the extraction and filtering steps are given in App endix B. W e calculated a broadcast scores for eac h user, using a range of v alues of α : 0.15, 0.3, 0.45, 0.6, 0.75 and 0.9. The distribution of the (SS) scores for all the tw eets in our one-week net work is sho wn in Fig. 1. The mean sen timent was mildly positive for all three measures: 0.297 for (SS), 0.823 for (MC) and 3.669 for (L). The limitations of the sen timent scoring algorithms explain the high prop ortion of t weets assgined a zero score (as shown for example in Fig. 1). Some of these are genuinely t weets with a neutral tone, but some are tw eets where the algorithm cannot detect any sen timent, so we think of the zero score as indicating “neutral or not detected” sentimen t. At the lev el of individual t weets, the Pearson correlation co efficien ts b et w een the three sentimen t measures (MC), (SS) and (L) are as follows: 5 (MC) and (SS): 0.585 (MC) and (L): 0.524 (SS) and (L): 0.564 Although the correlations at the individual tw eet lev el are mo derate, w e will later see in Section 4.4.2 that when we aggregate to groups of tw eets, such as all the tw eets sen t within a particular com- m unity , the correlations b ecome v ery strong. 3.3 Broadcast scores vs. av erage sentimen t Figure 2: The means of the (SS) sen timent attributes for the top 500, 1000 and 5000 broadcasters (for α = 0 . 75) compared with the mean v alues across all users. (The mean absolute sen timent v alues ha v e b een divided by 10 for easier viewing.) W e now compare broadcast scores with users’ sentimen t use. F or this w e need user-level sen ti- men t attributes, but the three sen timent scoring algorithms that w e used assign a sentimen t score to eac h tw eet. Therefore w e aggregated the sentimen t scores of eac h user’s outgoing edges within the net work, to get the follo wing seven attributes (for eac h of the three measures): • Mean sen timen t: the mean of the sentimen t scores for the user’s outgoing edges. • Mean absolute sentimen t: the mean of the absolute v alues of the sen timent scores for the user’s outgoing edges. 6 Figure 3: The means of the (SS) sentimen t fraction attributes for the top 500, 1000 and 5000 broadcasters (for α = 0 . 75) compared with the mean v alues across all users. • P ositiv e sentimen t fraction: the fraction of the user’s outgoing edges having a sen timen t score greater than zero. • Zero sen timent fraction: The fraction of the user’s outgoing edges ha ving a zero sen timent score (indicating a neutral sentimen t or that no sen timent could b e iden tified by the scoring system). • Negativ e sentimen t fraction: the fraction of the user’s outgoing edges having a sen timent score less than zero. • Av erage p ositiv e sen timent strength: the sum of the user’s sen timent scores o v er the outgoing edges with positive scores only , divided by the count of the user’s outgoing edges (this count includes all outgoing edges the user sent, not just those with a positive score). • Av erage negative sen timent strength: the sum of the absolute v alues of the user’s sentimen t scores ov er the outgoing edges with negative scores only , divided by the count of the user’s outgoing edges (this coun t includes all outgoing edges the user sen t, not just those with a negativ e score). The purp ose of the tw o sentimen t strength attributes is to tak e into accoun t not just ho w often a user expresses positive or negative sentimen t, but also how extreme that sen timen t is when it is expressed. 7 Users with no outgoing edges on the first day of our studied sev en-day evolving net w ork are at a disadv an tage in terms of broadcast scores, b ecause their messages hav e only six (or fewer) days to propagate through the netw ork, rather than seven. So for the rest of this section we rep ort on just the 153,691 users who tw eeted within the net work on the first da y . In Fig. 2 and Fig. 3 we compare the means of the ab o ve attributes for the top 500, 1000 and 5000 broadcasters with the means ov er all users, using (SS) and α = 0 . 75. W e see that: • T op broadcasters send messages with p ositiv e sentimen t more frequently , and neutral and negativ e sentimen t less often. • When w e additionally account for the extremity of the sen timent that is used as w ell as the frequency , top broadcasters use more positive sentimen t, and less neutral and negativ e sen timent. The differences are most pronounced for the top 500 broadcasters; as we mov e from the top 500 to the top 1000 and then top 5000, the means for the top broadcasters gradually b ecome closer to the means for the whole p opulation of users. But even for the top 5000 broadcasters there are still substantial differences. T o confirm the statistical significance of this finding, we ha v e used randomisation testing to estimate (one-sided) p-v alues 4 whic h are sho wn as annotations in Fig. 2 and Fig. 3. Note that this do es not mean that ev ery user in the top 500 has a higher p ositiv e sentimen t fraction (i.e. uses p ositiv e sen timent more frequently) than the av erage user. Fig. 4 shows the distribution of positive sentimen t fraction for the top 500 broadcasters, and for all users, using (SS). The distributions ov erlap, of course; in particular there are a few top broadcasters with low p ositiv e sentimen t fractions. Nev ertheless, one can clearly see that the distributions are not the same: the distribution for the top 500 broadcasters is in general shifted to wards the higher end of the horizon tal axis, showing that on a verage top broadcasters use positive sen timent more often. Although w e hav e sho wn the results for (SS) and α = 0 . 75, with one exception the same pattern of results w as found for all tested v alues of α , and also using the other sen timen t measures (MC) and (L) (again for six tested v alues of α ), and the p-v alues w ere all less than 0 . 026. The exception was that for (SS) and α = 0 . 15, the “negative sen timent strength” and “negative sentimen t fraction” attributes for the top 5000 broadcasters were v ery nearly equal to the mean ov er all users. In addition to in vestigating the sen timent use of the top broadcasters, w e looked for general trends relating sentimen t use to broadcast rank. Fig. 5 plots moving a verages of the (SS) sentimen t fraction attributes against broadcast rank, using a windo w of 1000 observ ations to smo oth the noisy data. W e see that from rank 1 to about rank 9000 the p ositiv e sen timent fraction decreases sharply; after this it decreases slowly in an approximately linear wa y . The fraction of tw eets with negative sen timent app ears appro ximately constant at this scale. Fig. 6 plots similar mo ving av erages for the sentimen t strength attributes. The av erage strength of p ositiv e sen timent declines sharply to b egin with and then slo wly , whereas the av erage strength of negative sentimen t is approximately 4 T o explain how these are pro duced, w e shall sketc h the calculation of the p-v alue for one of the attributes, the negative sen timent fraction as sho wn in Fig. 3. The av erage across all users is 0.142, whereas for the top 500 broadcasters it is only 0.119. W e randomly generated 100,000 subsets of the 153,691 users and calculated the means for those subsets. F rom this we estimate how the mean of the attribute is distributed for randomly chosen sets of size 500. F rom this distribution w e calculate the p-v alue as the probability that a randomly selected set of 500 users w ould ha ve a mean equal to 0.119 or more extreme (smaller). This probability is very close to zero (0.00022). Informally , this means w e can be v ery confident that the relationship we hav e found — that the top broadcasters use negativ e sen timent less often — has not simply happ ened “by c hance”; the odds of that are less than 3 in 10,000. 8 Figure 4: Distribution of p ositive sen timent fraction for top the 500 broadcasters (for α = 0 . 75), and for all users, using (SS). constan t. Although the local fluctuations w ere different, the graphs had the same general shap e for all the v alues of α ∈ { 0 . 3 , 0 . 45 , 0 . 6 , 0 . 75 , 0 . 9 } tested. 4 Sen timen t and ev olution of comm unities on Twitter In this section we describ e how we identified meaningful comm unites or “sub-netw orks” of Twitter users, and we presen t the results of our analysis of how these communities evolv ed ov er time, including ho w their sentimen t evolv ed. The existence of communities has b een observed in all kinds of real-world netw orks and identi- fying them has b een the sub ject of considerable researc h effort in recen t years, m uc h of whic h can b e traced bac k to a seminal pap er of Girv an and Newman [8]. In the v ast literature on communit y detection (see e.g. the review article [7]), a communit y is often taken to b e a group of users with t wo c haracteristics: 1. The comm unity is densely connected internally , i.e. p eople within the same communit y talk to eac h other a lot. 2. There are relativ ely few links crossing from the communit y to the outside world, i.e. p eople talk to fello w members of their comm unity more often than they talk to non-mem b ers. 9 Figure 5: The relationship b et w een sentimen t fractions (as a mo ving av erage o ver a windo w of 1000 p oin ts) and broadcast score rank, for α = 0 . 75 based on (SS). 4.1 Ho w w e detected communities and selected a subset for further study Because w e wan ted to find communities that would endure ov er time, we needed to take a longer p eriod of data than the seven days we analysed in Section 3. W e can imagine online discussions that spring up, rage fev erishly for a few da ys and then largely disapp ear 5 , and that is not what w e w anted to find. Y et, as describ ed in Section 2, we had only the last 200 tw eets p er user, so w e needed to limit ourselv es to a p erio d where the data was most complete. W e extracted a men tions net work from 22nd Sept 2014 (inclusiv e) un til the end of our snowball-sampled data, 6th No vem ber 2014, a p eriod of 46 days. The pro cess for creating the net work was the same as describ ed for the sev en-da y net work, describ ed in Appendix B. The resulting netw ork consisted of 491,417 users with 31,299,836 edges b et w een them, coming from 22,594,048 t weets. F or the first 40 days the daily av erage w as 776k edges; for the last 6 days, when data collection was coming to an end, the daily av erage was only 40k edges. The net work has an a verage of 63.7 outgoing edges p er user, corresp onding to 46.0 tw eets p er user, and eac h user mentioned an a verage of 30.9 distinct recipien ts. With the dataset chosen, w e turn to the question of algorithms. Disco vering communities by algorithms requires one to first form ulate a precise definition of how “go o d” a given division of a so cial netw ork in to comm unities is. The most widely used formula for quan tifying the “go o dness” of 5 W e susp ect, for example, that the m uch-reported discussion of “What colour is the dress?” fits into this category; see h ttp://www.bb c.co.uk/news/blogs-trending-31659395. 10 Figure 6: The relationship b et w een sentimen t strengths (as a moving av erage o ver a window of 1000 p oin ts) and broadcast score rank, for α = 0 . 75 based on (SS). a division is called modularity [13] and it compares the fraction of edges that lie within a comm unity in the netw ork with the exp ected fraction of edges that w ould lie within the communit y if the edges w ere placed at random. Many different v ersions of mo dularit y hav e b een prop osed in the last decade. As we lo ok at relatively un balanced divisions (trying to iden tify small p ortions of a large net work), we considered instead a differen t measure called conductance [5] which takes v alues from 0 to 1. Groups of users that are w ell connected internally but well separated from the rest of the net work hav e v alues close to 0, and groups with few in ternal connections but lots of connections to the rest of the netw ork ha ve v alues close to 1. There is also a v arian t of conductance, called w eigh ted conductance, that takes into accoun t the w eights on edges, rather than just their presence or absence. W e use the num ber of messages exc hanged b et w een tw o users (in either direction) as the w eight of the edge b et w een them. Th us w eighted conductance dep ends not only on which users hav e corresp onded with which others, but also on how often. If W ij is the weigh t of the edge from user i to user j , S is a comm unity , and ¯ S denotes the remaining users, the weigh ted conductance of S is P i ∈ S,j ∈ ¯ S W ij min ( a ( S ) , a ( ¯ S )) where a ( S ) = P i ∈ S P j ∈ ¯ S W ij . W e used the following three algorithms to iden tify communities: • The Louv ain metho d on unw eigh ted graphs, describ ed in [4], as implemen ted in Python in 11 the library [3] and in C++ by Lefeb vre and Guillaume 6 . • The Louv ain metho d on weigh ted graphs, using the C++ implementation. • The k-clique-comm unities metho d 7 presen ted in [14] as implemented in the Net w orkX Python library . Using these three metho ds with differen t parameters, we produced a list of 98,078 candidate com- m unities. F or each comm unit y we calculated: • the size of the comm unity (num b er of no des), • the n um b er of in ternal edges (mentions b et w een users), • the num b er of in ternal edges (men tions) per node (this gives a measure of ho w muc h activity there is inside the communit y), • the conductance and the weigh ted conductance of the communit y within the whole netw ork, • the mean sen timen t of edges within the comm unity , using the (MC) measure 8 , • whether the comm unity consisted of a single connected comp onen t (goo d candidate communi- ties will of course b e connected; ho wev er, very infrequently the Louv ain method can generate disconnected communities, by removing a “bridge” no de during its iterativ e refinemen t of its comm unities), • the fraction of in ternal men tions with non-zero sen timen t (some of our candidate comm unities w ere comp osed mainly of users sp eaking a non-English language, and we used this measure to filter them out; t weets in other languages are likely to be assigned a zero sentimen t score, b ecause the sen timen t scoring algorithm do es not find any English w ords with whic h to gauge the sen timent), • some statistics summarising the role play ed in the comm unity b y recen tly registered users, and • a breakdo wn of the frequency of participation of users in the communit y . (F or eac h user in the communit y , we coun ted ho w many distinct days they had b een active on Twitter in our data, and then calculated the p ercen tage of these days on whic h they had p osted within the candidate comm unit y . W e calculated the av erage across all users in the communit y , and also split the users up into five bins.) Based on the ab o v e statistics we short-listed a subset of comm unities and p erformed a manual insp ection of a sample of the tw eets within the communit y , to assess the topics talked ab out, and a visualisation of the communit y , using the program Visone 9 for this subset. 6 This code is freely a v ailable from https://sites.google.com/site/findcommunities/. 7 This algorithm, and some refinements to it, are also implemen ted in the CFinder program, freely a v ailable from h ttp://www.cfinder.org/. 8 Due to time constraints and the large n umber of tw eets inv olv ed in communit y detection, we decided not to calculate the (SS) and (L) scores at this stage. 9 h ttp://visone.info/html/about.html 12 In the end w e selected 18 communities to monitor and study . T able 1 shows most of the statistics listed ab ov e for these 18 communities, in size order. In eac h n umerical column, the highest six v alues are highligh ted in green and the low est six v alues are highligh ted in red (recall that for conductance and w eigh ted conductance, lo wer v alues indicate a more tigh tly-knit comm unity). The “Algorithm” column contains ‘L’ for the Louv ain metho d, ‘W’ for the w eigh ted Louv ain metho d and ‘K’ for the k-clique-comm unities metho d. W e c hose six communities from eac h algorithm. T able 2 shows frequency of participation, with communities ranked by the third column, whic h giv es the av erage user participation. This is expressed as a p ercen tage: the p ercen tage of days on whic h the user was active on Twitter (in our dataset) that they were active in the communit y . The righ tmost five columns show, for each communit y , how the users’ participation lev els break do wn in to five bins. Bins with disproportionately many users in them (i.e. with v alues more than 0.2) are highligh ted in green. W e can see that with the exception of communit y 4 (W eddings), ev ery comm unity has at least a 20% “hard core” of users, who are active in the communit y nearly every da y they are active on Twitter. Once w e had selected the comm unities of interest, w e collected a more detailed t weet history for eac h participating user, as describ ed in Section 2. 4.2 Analysing the endurance of the communities W e analysed w as ho w w ell our comm unities endured o v er time. W e examined a 28-da y p eriod start- ing on 22nd September 2014 (which w e will call the “autumn p erio d”) and a 28-day perio d starting on 2nd F ebruary 2015 (whic h we will call the “spring p eriod”), and compared how many users in eac h comm unity were active (mentioned or w ere men tioned b y other users) within the comm unity . W ould the same users still b e tw eeting each other in the spring, or would the comm unities hav e dissolv ed ov er time? Fig. 7 sho ws a log-log plot of the results. W e see that the communities persisted well from autumn to spring. In three of them, commu- nities 14 (Human resources), 17 (F riends chatting) and 18 (F riends chatting), all the original users w ere still active in the comm unity . These are three out of the four smallest comm unities. The other 15 communities lost b etw een 6.5% (for communit y 16, Nursing) and 39.3% (for communit y 7, Islam) of their users, with an av erage loss of 18.6%. W e can see differences in the communities pro duced by the three algorithms here: the six pro duced by k-clique-communities lost an av erage of 3.8% of their users, compared to 16.4% for the Louv ain metho d and 26.3% for weigh ted Louv ain. Let us say user loss factor to mean the n umber of users activ e in the 28-day autumn perio d divided b y nu mber active in the later 28-da y spring p eriod. When the user loss factor is 1, then the communit y has retained all its users; the higher the v alue, the more users the communit y has lost. W e lo ok ed to see whether the conductance, sen timent or size of comm unities is related to their endurance. In Fig. 8 one can see that conductance is a predictor of what prop ortion of users will stop participating in the communit y , with correlation co efficien t 0 . 42. When conductance is lo wer (so that the comm unit y is more densely connected internally and b etter separated from the rest of the net work) then few er users stopp ed participating on a verage. Similarly , the communit y sentimen t is a predictor of communit y endurance, as sho wn in Fig. 9: the more p ositive the initial sentimen t (measured in the autumn p erio d), the fewer users stopp ed participating on av erage. F or (SS) (as shown in Fig. 9) the correlation co efficien t is − 0 . 60; for (MC) it is − 0 . 48 and for (L) it is − 0 . 58. On the other hand comm unit y size was not correlated to user loss factor; the correlation co efficien t was 0 . 07. W e noted in Section 3.3.2 that the correlations b etw een the three sen timen t measures (MC), 13 T able 1: Selected summary statistics for the 18 comm unities w e selected, in size order. The comm unity mark ed as not connected had 8 no des separated from the rest. 14 T able 2: Figures for frequency of participation, with communities ranked by a verage user partici- pation (the third column). (SS) and (L) at the individual t w eet level w ere only mo derate. The follo wing shows the correlations b et w een the c ommunity sen timents pro duced b y the three measures, in the autumn and spring p eriods: Measures Correlation co efficien t (autumn) Correlation co efficien t (spring) (MC) and (SS) 0.971 0.954 (MC) and (L) 0.972 0.929 (SS) and (L) 0.985 0.948 Th us at the communit y level the three measures are v ery similar. 4.3 Dynamics of sentimen ts in comm unities Here, we analyse the changes in sentimen t/moo d of our communities o ver time (or the lack thereof, as it generally turns out). Fig. 10 plots the mean (SS) sen timent of each communit y o ver the autumn p eriod against the mean (SS) sentimen t ov er the spring perio d. W e see that the sentimen ts p ersisted very strongly: the correlation b et ween the autumn sentimen t and spring sentimen t is 0 . 982. The corresp onding correlation under the (MC) measure was 0 . 982, and under (L) was 0 . 960. W e lo ok ed for explanations for the (small) changes in sen timen ts that did occur. On the v ertical axis of Fig. 11 we show the c hange in mean sen timent b et w een the autumn p eriod and spring p eriod using (MC); a positive n um b er means that the sentimen t b ecame more p ositive ov er time. On the horizon tal axis we show the mean sen timen t during the autumn perio d. What we find is that when the sen timent is initially at the negativ e end of the sp ectrum, it tends to increase slightly; on the other hand if the sentimen t is initially at the p ositiv e end, it tends to decrease slightly . 15 Figure 7: The comm unities we studied endured strongly o v er a 19-week perio d. In fact the sen timen t in 16 of the 18 comm unities mo ved sligh tly to wards a mo derate (MC) v alue of 0.4 (which is appro ximately where the line of b est fit cuts the horizon tal axis in Fig 11). This could b e b ecause extreme sentimen t in a comm unit y is “whipp ed up” b y external ev ents and then, once those even ts are o ver, tends to dissipate naturally with time. W e p oint out how ev er that there is likely also an element of statistical “regression to the mean” o ccurring. W e did not choose our communities at random: w e chose fiv e of them b ecause they were among those with the most extreme sen timent in the autumn perio d 10 . This in tro duces a bias and mak es it more lik ely for the sentimen t in these five comm unities to b ecome more mo derate by the spring perio d (whic h it do es, in all fiv e cases). This bias is una voidable when one disprop ortionately selects comm unities with extreme sen timen t for study . The correlation co efficien t Fig. 11 is − 0 . 71. The relationship was less apparent using the other sentimen t measures, though still present, with corresp onding correlations of − 0 . 59 for (SS) and − 0 . 32 for (L). The robustness of the w eekly sen timent measures suggests that only a limited amoun t of data, sa y for t w o or three weeks, is needed to give a go od idea of the sentimen t of a Twitter communit y , and if a drastic c hange in sentimen t do es o ccur within a communit y , this is a rare even t and may indicate that something imp ortan t has happ ened to or within the communit y . Lo oking at the daily a verage sen timent in each communit y , that is, lo oking at a higher resolution, more detail is evident. Fig. 12 sho ws the daily mean sentimen t in communit y 2 (Indian p olitics), 10 Namely: 4 (W eddings), 7 (Islam), 9 (Islam vs atheism), 10 (Madeleine McCann) and 11 (Religion). 16 Figure 8: Comm unities with higher conductance tended to lose more of their users o ver time. also for the p eriod 22nd September 2014 to 1st March 2015. Large day-to-da y v ariations can b e seen, and we hav e noticed that often such abrupt changes can b e traced to real even ts affecting the comm unity . In Fig. 12 we hav e highlighted five dates where the sen timen t measures show spikes or troughs. By examining the tw eets sent on those dates we identified the significant even t that drov e the sen timent c hange: • 24th Septem b er 2014: India’s Mars Orbiter Mission space prob e entered orbit around Mars, and p eople celebrated. • 23rd October 2014: the b eginning of the Diw ali festiv al. • 16th Decem b er 2014: gunmen affiliated with the T ehrik-i-T aliban conducted a terrorist attack in the north western P akistani city of Pesha war. • 1st Jan uary 2014: New Y ear’s Da y . • 7th January 2015: gunmen attack ed the offices of the F rench satirical weekly newspap er Charlie Heb do in P aris. 17 Figure 9: Comm unities with more negative sentimen t, measured b y (SS), tended to lose more of their users o ver time. 5 An agen t-based mo del of sen timen ts dynamics in comm unities It has b een discov ered time after time that the collectiv e b eha viour of p opulations of interacting individuals is difficult to understand, c hallenging to predict and sometimes even seemingly para- do xical. In order to b e able to predict the likely evolution of sen timent within a communit y and to explore its dynamics under v arious change scenarios, such as the departure of particular users or the arriv al of a new v ocal user, we built an Agen t-Based Mo del (ABM) of our Twitter comm unities. This includes modelling the sentimen t of individuals in the net work, and ho w sentimen t spreads from one user to another. The agents in the mo del represen t Twitter users, and they are arranged in a static undirected graph; only pairs of agen ts connected by an edge are able to exc hange messages. The simulation pro ceeds in discrete time steps; the n um b er of these steps p er da y is a parameter of the mo del. A t eac h time step the following things happ en: • Eac h agen t performs an action whic h consists of sending a burst of messages to all/some/none of its neigh b ours, influenced by the agent’s curren t state. • Eac h agent evolv es in to a new state, influenced by the actions of other agen ts in this step, i.e. influenced b y the messages it has received this step. 18 Figure 10: Graph sho wing that communit y sen timent w as v ery stable o ver the 19-w eek p eriod. The solid line sho ws where the autumn and spring sen timents are equal. Sp ecifically , an action b y an agent consists of: a subset of neigh b ours who will b e messaged at this time step; for each neighbour messaged, the num b er of messages sen t to them at this time step; for eac h neighbour messaged, a sentimen t for the messages sen t to them at this time step. The state of an agent consists of t wo v ariables. The first is a real n umber represen ting the curren t sen timent lev el of the agen t, on the same scale as the sen timen t scores used for mess ages. The second is a record of who sent a message to the agent recen tly: this is the subset of the agent’s neigh b ours who sen t the agen t a message at the previous time step; these are candidates for the agent to reply to. In addition to its evolving state, eac h agent A has a set of constant characteristics that influence its b eha viour but do not evolv e: 1. an initiation probabilit y P ( init, A ) which controls the tendency of the agen t to initiate new con versations with other users when it has receiv ed no messages recently 2. a reply probability P ( r epl y, A ) which controls the tendency of the agent to reply to mes- sages it has received 3. a propagation probability P ( pr op, A ) whic h con trols the tendency of the agen t to prop- agate messages, that is, to message some other user B after b eing prompted b y a message from a differen t user C in the previous time step 19 Figure 11: Graph showing that the sen timen t in 16 of the 18 communities b ecame more mo derate o ver time. This plot uses the (MC) measure. 4. a baseline sentimen t lev el S ( basel ine, A ): this is the sen timent level the agent starts off with, and to which is may reset from time to time (as describ ed below) 5. a neutral sen timen t level S ( neutr al, A ): when the agent receives messages with sentimen t higher than this level, the agent’s sentimen t will b e raised, and when the agent receives messages with sen timent lo w er than this lev el, the agent’s sen timen t will b e low ered The model also has six global parameters: the num b er of iterations (discrete time steps) p er da y , the mean num ber of messages p er burst, a c ontagion of sentiment factor , a sentiment r eset pr ob ability , a sentiment noise level and a neighb our fr e quency thr eshold . The details of the global parameters, ho w the agents decide to send messages and how the agen ts’ sen timents ev olve are giv en in App endix C. The process of using this mo del to sim ulate a real Twitter comm unity is then as follo ws. First we construct the graph from the historical data for the communit y , connecting the users that ha v e ex- c hanged more messages than the neigh b our threshold. W e set the baseline sen timen t S ( basel ine, A ) for each agen t A by computing the mean sen timent of messages sen t b y eac h user, and w e set the neutral sentimen t S ( neutr al , A ) of each agen t to the mean sentimen t of all messages sen t in the comm unity . T o estimate the initiation probabilit y P ( init, A ) for each agent A , we split the his- torical data in to windo ws, with length determined by the num ber of iterations p er day . W e coun t the num b er of opp ortunities A had to initiate a conv ersation (i.e. how many windows there were 20 Figure 12: The daily mean sen timent in communit y 2 (Indian politics) from 22nd September 2014 to 1st Marc h 2015. Five in teresting ev ents are iden tified. 21 in whic h A received no messages), and also ho w man y times out of these A actually initiated a con versation. The reply and propagate probabilities P ( r eply , A ) and P ( prop, A ) are set similarly . T o p erform a simulation run of the mo del, we set all the agents to their initial state, and then w e evolv e the system for the required n umber of steps, recording the messages that w ere sen t for later analysis. The initial state of each agen t is that the agent has received no messages to consider replying to, and its curren t sentimen t is equal to its baseline sen timent. The required num b er of steps is the n umber of da ys in the real data multiplied by the num b er of iterations p er day (so that the time p eriod of the sim ulation matches that of the real data). 5.1 Calibration W e now describe ho w we calibrated our mo del to our Twitter data. The purp ose of the six global parameters is to make our agen t-based mo del “tuneable”, so that w e can fine-tune it to matc h the b eha viour observed in differen t kinds of online communit y . Calibrating the mo del to a particular comm unity means finding the v alues of the six parameters that maximise the match b etw een the mo del and the real data, i.e. the parameter v alues that mak e the sim ulation runs of the mo del most closely resem ble the real data. In our case, the sp ecific metrics that we use to compare the sim ulated data with the real data are: the activit y lev els (num ber of messages sen t p er da y) of eac h individual user, and the day-to-da y volatilit y of this, as w ell as the se n timen t of the whole net work, and its day-to-da y volatilit y . Comparing the real data and sim ulated data in this w ay is an instance of the metho d of simulate d moments . W e therefore prop ose the following function ρ to score a particular simulation run (smaller scores mean a b etter matc h): ρ = α N X i =1 h C i i − h ˆ C i i + β N X i =1 std ( C i ) − std ( ˆ C i ) + γ h E c i − h ˆ E c i + δ std ( E c ) − std ( ˆ E c ) Here N is the num b er of users. W e denote with h C i i , std ( C i ) the av erage and standard deviation resp ectiv ely of the num b er of messages sent each da y b y user i in real data , and with h ˆ C i i , std ( ˆ C i ) the corresp onding v alues in the simulation run. Similarly , h E c i , std ( E c ) denote the av erage and standard deviation of daily comm unit y sentimen t and h ˆ E c i , std ( ˆ E c ) those v alues in the sim ulation run. The relativ e sizes of the constants α , β , γ and δ are set to reflect how we prioritise the v arious asp ects of the comparison b et ween the real and simulated data. W e hav e used α = 1 , β = 0 . 1 , γ = 10 and δ = 100 which means that were are putting a lot of emphasis on matc hing the v olatility of daily comm unity sen timent, and less emphasis on matc hing the lev el of daily comm unity sen timent. Con versely for the n um b er of messages sent p er day by each agent, we prioritise matching the level o ver matc hing the v olatility . W e chose to model a small comm unit y so that w e could trace through the simulations, in order to understand them b etter. W e concen trated on modelling communit y 17 (friends chatting) whic h has 28 use rs. W e calibrated the mo del for each of the three sen timent measures (MC), (SS) and (L). Each calibration w as p erformed with an iterativ e grid search: we used fiv e successiv e grid searc hes, each time zo oming in on the area of the parameter space that app eared most promising in the previous searc h. The initial ranges searc hed for each parameter are given in App endix D. Because the simulation runs are randomised we p erformed 50 simulation runs for each com bination of parameters tested, taking the mean of the resulting 50 scores as the score for the c hoice of parameters. The parameters found b y the rep eated grid search were as follo ws: 22 (MC) (SS) (L) n umber of iterations p er day 1,536 1,536 1,536 mean n umber of messages p er burst 2.1 2.1 2.1 con tagion of sentimen t factor 0.2 0.1 0.1 sen timent reset probabilit y 0.03 0.13 0.15 sen timent noise lev el 1.5 1.0 10.0 neigh b our frequency threshold 18 18 18 Fig. 13 compares the mean daily count of messages sen t for each user, in the real data and a veraged o ver 500 sim ulation runs. As w e can see, the match is extremely close. Fig. 14 similarly compares the standard deviation (v ariability) of the daily coun t of messages sen t for each user, in the real data and av eraged ov er 500 sim ulation runs. The match is less go od here, which reflects the fact that when setting the constan ts α and β in the scoring function we c hose to prioritise matc hing the means instead of the standard deviations. The sen timent statistics of the real data are matched closely b y the simulated data (again av eraged ov er 500 simulation runs), particularly for (MC): (MC) (SS) (L) mean daily sen timent in real data 0.479 0.325 3.24 mean daily sen timent in sim ulation 0.469 0.320 3.17 standard deviation of daily sentimen t in real data 0.160 0.101 0.971 standard deviation of daily sentimen t in simulation 0.161 0.097 0.932 Finally , in Fig. 15 w e plot the initiation probabilit y P ( init, A ) of each agent against the reply probabilit y P ( r eply , A ); recall that these are set from the historical data of the comm unity . W e include this plot to emphasise the lac k of correlation b et w een the t wo. This confirms that users really do app ear to pla y differen t roles in the communit y , with some initiating relatively often but not replying m uch, and others replying readily while initiating but little. 5.2 Predicting the effects of in tro ducing a new user W e now consider a scenario where a new user joins the net w ork, and b ecomes the neigh b our of any three existing communit y members that w e choose. Whic h three communit y mem b ers should our new user b efriend? F or illustration we explore four p ossible c hoices: 1. Befriend the three users with the most p ositiv e sen timent 2. Befriend the three users with the most negativ e sentimen t 3. Befriend the three users with the highest reply probabilities 4. Befriend the three users with the lo west reply probabilities F or the purp oses of this example, w e assume that our user will b e vocal but with sen timent matched to the prev ailing sen timen t of the existing communit y: The new user’s initiation (resp. reply , propagation) probabilit y is set to three times the maximum initiation (resp. reply , propagation) probabilit y found in the existing communit y . Also, the new user’s baseline sen timen t level is set to the existing communit y sentimen t lev el. Figs. 16, 17, 18 and 19 sho w how our four choices of neighbours affect four aspects of the comm unit y: the activity level, the standard deviation 23 Figure 13: The mean daily count of messages sent by each user, in the real data and av eraged ov er 500 sim ulation runs. (v ariability) of the daily activity lev els, the sen timent lev el and the standard deviation (v ariabilit y) of the daily sentimen t levels (all av eraged ov er 100 sim ulation runs, and using (MC)). The results highligh t again the role of net work structure: if our new user befriends the three most p ositiv e users, then the communit y sen timent go es up, and if he b efriends the three most negative users, the communit y sen timen t go es down. Similarly , choosing the users with the highest or lo w est reply probabilities as neigh b ours has a mark edly differen t effect on activity lev els. V alidating our mo del’s predictions ab out the effects of new users on real data is b eyond the scope of this pap er; it is a c hallenging research task in itself and is left as future w ork. 6 Discussion Despite the deluge of data on human communication, dynamics of collective mo o d is still mainly an unc harted area. While different theories of emotion contagion exist in the literature, w e are still far off b eing able to predict the o ccurrences, in tensity and durations of collectiv e compassion, happiness or outrage on Twitter. Here w e presen ted findings from one large Twitter dataset. While w e are conscious of some serious limitations of our approach — the lack of representativ eness of Twitter users, and the noisy nature of sentimen t scores — we b eliev e that our methodology can b e generalised to other datasets of human interactions whic h allow for sen timen t scoring. 24 Figure 14: The standard deviation (v ariabilit y) of the daily coun t of messages sent by each user, in the real data and av eraged ov er 500 simulation runs. Lo oking to wider socio-economic horizons and smart cities opportunities, social media is slo wly but steadily b ecoming an imp ortant c hannel to run p olicy information and e duc ation c amp aigns on a mass sc ale . Additionally , it has b ecome an exclusive c hannel to get the attention of some so cio- demographic groups, esp ecially in the younger p opulation, who decreasingly consume traditional media suc h as lo cal newspap ers and television. F or these reasons, a data driven mo del of collectiv e sen timen t captured through so cial media is one of the most imp ortan t to ols that so cial data analytics can offer to a city leadership. It allows gauging public opinion on different topics and understanding/predicting the dynamics of public opinion. Most imp ortan tly , it can help to uncov er public ev aluation of lo cal decisions. It also allo ws, as men tioned previously , to engage different communities in to a con versation and to reach to under-represented groups. Our framew ork can b e applied ov er a wide range of topics: energy , transp ort, eduction, tourism, local leadership and so on. W e demonstrated that by using a n umber of comm unity detection algorithms in combination with sentimen t scores, w e can identify stable communities of Twitter users. Users within these comm unities are well-connected and send messages to each other frequen tly compared with ho w frequen tly they send messages to users not in the communit y . The comm unities and their “com- m unity sen timent” w ere relatively stable ov er a time-scale of months. More lo ose-knit communities and comm unities with more negativ e sentimen t tended to lose more users o ver time. W e find that when the sentimen t in a communit y temp orarily shows a large deviation from its usual lev el, this 25 Figure 15: Comparing the initiation probabilit y and reply probability for eac h agent. can typically b e traced to a significan t iden tifiable ev en t affecting the comm unity , sometimes an external news ev ent. W e hav e developed an Agent-Based Mo del of online so cial netw orks. The mo del consists of a p opulation of simulated users, each with its o wn individual c haracteristics, suc h as its tendency to initiate new conv ersations, its tendency to reply when messaged, and its usual sentimen t level. The mo del allo ws for sentimen t contagion. W e hav e demonstrated that this mo del, when calibrated with the data from a real Twitter communit y , accurately repro duces activity lev els and sen timent strength of that communit y . W e hav e shown an example of using the Agent-Based Model for exploring “what if. . . ?” scenarios, such as “What if we encourage a new user to interact with particular users in the communit y?”. T o do this w e fit the parameters of the model to a particular so cial net work and then make the corresp onding mo difications to the mo del. By running a large n umber of sim ulations on the mo dified mo del, w e obtain a prediction of the lik ely effect of the c hange on the activity lev els and sentimen t levels of the comm unity . Ac kno wledgmen ts. This w ork w as partly supp orted b y UK Defence Science and T ec hnology Labs under Cen tre for Defence Enterprise gran t CDE36620. W e would lik e to thank Dr Georgios Giasemidis for useful discussions and his help with prepro cessing of the data. 26 Figure 16: The effect on the increase in comm unit y activity level of four options for the neighbours of the newly introduced user. Figure 17: The effect on the standard deviation (v ariability) of daily comm unity activity level of four options for the neighbours of the newly introduced user. 27 Figure 18: The effect on communit y sentimen t level of four options for the neighbours of the newly in tro duced user. Figure 19: The effect on the standard deviation (v ariabilit y) of daily comm unity sentimen t level of four options for the neighbours of the newly introduced user. 28 References [1] R. Alv arez, D. Garcia, Y. Moreno, and F. Sch weitzer. Sentimen t cascades in the 15m mo ve- men t. EPJ Data Scienc e , 4(6), 2015. [2] J. Aronfreed. The so cialization of altruistic and sympathetic b eha vior: Some theoretical and exp erimen tal analyses. In J. M. L. Berk owitz, editor, Altruism and helping b ehavior , pages 103–126. Academic Press, New Y ork, 1970. [3] T. Aynaud. Communit y detection. http://perso.crans.org/aynaud/comm unities/, 2009. On- line; accessed 24 August 2015. [4] V. Blondel, J. Guillaume, R. Lam biotte, and E. Mec h. F ast unfolding of comm unities in large net works. J. Stat. Me ch , page P10008, 2008. [5] U. Brandes and T. Erlebach. Network A nalysis: Metho dolo gic al F oundations (L e ctur e Notes in Computer Scienc e) . Springer-V erlag New Y ork, Inc., Secaucus, NJ, USA, 2005. [6] R. W. Dohert y . The emotional contagion scale: A measure of individual differences. Journal of nonverb al Behavior , 21(2):131–154, 1997. [7] S. F ortunato. Communit y detection in graphs. Physics R ep orts , 486(3-5):75 – 174, 2010. [8] M. Girv an and M. Newman. Communit y structure in so cial and biological net w orks. Pr o- c e e dings of the National A c ademy of Scienc es of the Unite d States of Americ a , 99:7821–7826, 2002. [9] P . Grindrod, D. J. Higham, M. C. Parsons, and E. Estrada. Communicabilit y across ev olving net works. Physic al R eview E , 83, 2011. [10] E. Hatfield, J. Caciopp o, and R. Rapson. Primitive emotional contagion. In M. S. Clark, editor, R eview of p ersonality and so cial psycholo gy . Sage, Newbury Park, CA, 1992. [11] L. Katz. A new index deriv ed from so ciometric data analysis. Psychometrika , 18:39–43, 1953. [12] A. D. I. Kramer, J. E. Guillory , and J. T. Hanco c k. Exp erimental evidence of massive-scale emotional con tagion through so cial netw orks. PNAS , 111:8788–8790, 2014. [13] M. Newman and M. Girv an. Finding and ev aluating comm unity structure in net works. Physic al Review E , 69:026113, 2004. [14] G. Palla, I. Der´ enyi, I. F ark as, and T. Vicsek. Uncov ering the o verlapping comm unity structure of complex net works in nature and so ciet y. Natur e , 435:814–818, June 2005. [15] J. W. P ennebaker, C. K. Ch ung, M. Ireland, A. Gonzales, and R. J. Booth. The dev elopment and psychometric prop erties of LIWC2007. T echnical rep ort, The Universit y of T exas at Austin and The Univ ersity of Auc kland, New Zealand, 2007. [16] F. Sch weitzer and D. Garcia. An agent-based mo del of collectiv e emotions in online commu- nities. The Eur op e an Physic al Journal B , 77(4):533–545, 2010. 29 [17] B. T adi´ c, V. Gligorijevi ´ c, M. Mitrovi ´ c, and M. ˇ Suv ako v. Co-ev olutionary mec hanisms of emotional bursts in online so cial dynamics and net works. Entr opy , 15(12):5084, 2013. [18] A. T ellegen. Structures of moo d and personality and their relev ance to assessing anxiet y , with an emphasis on self-rep ort. In A. H. T uma and J. D. Maser, editors, Anxiety and the A nxiety disor ders , pages 681–706. Hilsdale, 1985. [19] M. Thelwall, K. Buckley , and G. P altoglou. Sentimen t strength detection for the so cial web. J. A m. So c. Inf. Sci. T e chnol. , 63(1):163–173, Jan. 2012. [20] D. V uk adino vi´ c Greetham, R. Hurling, G. Osb orne, and A. Linley . So cial net works and positive and negative affect. Pr o c e dia - So cial and Behavior al Scienc es , 22:4 – 13, 2011. Dynamics of So cial Net w orks 7th Conference on Applications of So cial Net w ork Analysis - ASNA 2010. [21] D. V uk adino vi´ c Greetham, A. Sengupta, R. Hurling, and J. Wilkinson. In terven tions in so cial netw orks: impact on mo o d and netw ork dynamics. A dvanc es in Complex Systems , 18(03n04):1550016, 2015. A The data w e are making a v ailable W e prop ose to make a v ailable the curated data sets used for the v arious analyses in describ ed in this article. These will b e: • The sev en-da y evolving net work used for the comm unicabilit y analysis describ ed in Section 3. • The graph used for comm unity detection, as describ ed in Section 4.4.1. • The tw eets within eac h communit y that w e collected (as describ ed in Section 2); this data co vers the analysis done in Sections 4.4.2, 4.4.3 and 5. F or each tw eet in these data sets, we propose to include the follo wing attributes: 1. an anon ymised t weet ID, 2. a timestamp, 3. who w as the sender (an anonymised user ID), 4. who w as men tioned in the tw eet (anonymised user IDs), and 5. sen timent scores for the three measures (MC), (SS) and (L). B Extracting a men tions net work T o get the b est results, w e hav e chosen for analysis the p eriod with the largest p ossible num b er of users active in our data. Fig. 20 shows the num b er of users active in the data each da y for the p erio d from 22nd April 2014 un til the end of the snowball-sampled data. Fig. 21 sho ws the same thing but “zo omed in” to a restricted range of dates. W e notice that the n umber of users oscillates b et ween w eekdays and week ends, and the w eekly total gradually increases and p eaks on 30 Figure 20: Number of active users p er da y . Dates b efore 22nd April 2014 ha ve fewer than 53,000 activ e users. 15th Octob er 2014. Then the num b er of users falls off quite rapidly . The shap e of Fig. 20 is largely due to the fact that only the last 200 t weets (from the time of the API request) p er user w ere collected. Thus those users who t weet frequently do not show up in the first half of the c hart since their earlier t weets ha v e not b een collected. W e used the Twitter dataset to create an evolving netw ork, where the set of vertices is fixed and the edges b et w een them can change in eac h time-step (a day in our case). In order to choose a fixed set of v ertices, we ha v e chosen the week from 9th Octob er to 15th Octob er 2014 inclusive, whic h is the week with the highest activit y measured by the n umber of tw eets. W e then filtered the data using several criteria in order to fo cus on “regular” human users. A n umber of classes of user with un usual b eha viour were filtered out, as they would sk ew the results of our analyses (and threaten to mak e the net work structure b ecome degenerate, as w e describ ed in Section 2.3.2): • Users with a very high t w eeting frequency . If a user t weets hundreds of t weets in a few hours then these messages might hav e b een automatically generated. This practice is follow ed b y many companies and organisations for adv ertising purp oses, but the messages are not gen uinely represen tative of h uman b eha viour. Fig. 22 sho ws the num b er of da ys (rounded up to the next v alue) b et ween the first tw eet and the last t weet in our snowball-sampled data, just for those users who had p osted at least 200 tw eets since account creation. When setting a threshold on tw eeting frequency to exclude users, we should of course filter out only a small minority of users. W e observe in Fig. 22 a natural “gap” in the data at the v alue 1, with only 48 users app earing in this bin. W e select a da y difference of 1 — equiv alen tly a 31 Figure 21: Num b er of activ e users p er da y for a restricted range of dates. t weeting frequency of 200 tw eets p er day — as our threshold, excluding 1,153 users with a higher t weeting frequency than this. • Users who men tion themselves v ery frequently , who may also b e b ots. W e used a threshold of 0.5 for the ratio of the num b er of self-mentions to the num b er of all mentions made by a user, c hosen b ecause the num b er of users with a self-men tion ratio larger than R drops off rapidly as R increases ab ov e 0.5. The 0.5 threshold also seems to b e a reasonable choice b ecause it indicates that outliers mention themselves more often than they men tion all other users. • Users with a high ratio of in-degree to out-degree. Examples of these users are celebrities or well-kno wn services whic h attract a high num b er of mentions relative to their activit y . Lo oking at Fig. 23, w e observe that the n umber of users smoothly decreases as the in-degree to out-degree ratio increases. Since there is no v alue beyond which the n umber of users dras- tically decreases, there is no clear choice of threshold. W e set the threshold at 50, meaning w e treat as outliers, and exclude, users with in-out ratio greater than 50. In other w ords, w e assume that users that receive mentions 50 times more than they mention others are celebrities/p oliticians or big organisations that skew the netw ork and should b e excluded. Indeed among the users with exceptionally high ratio one can find TheEconomist, Ub er- F acts, May orofLondon, amandabynes, NatGeo, HillaryClin ton, Ed Miliband, BBCPanorama, Da vid Cameron, Junck erEU, BillGates and Y ouT ub e. After these filtering steps 304,349 users remained. W e w anted our ev olving netw ork to reflect users’ c onversations , rather than one-w ay messaging, so we p erformed one more filtering step. W e formed an undirected net work on the remaining users b y using only r e cipr o c ate d mentions; this means that w e put an e dge b et w een users A and B just 32 Figure 22: Histogram of the num b er of da ys b et w een the first t weet and the last t weet in our sno wball-sampled data, for those users who had p osted at least 200 t weets since accoun t creation. when A had mentioned B sometime during the chosen week and also B had men tioned A during the c hosen w eek. Then w e found the largest connected comp onen ts of this graph, which contained 285,168 users (i.e. 94% of the 304,349 users). W e to ok these 285,168 users as our final set of no des; they form a “prop er” so cial netw ork in the sense that there is a path of reciprocal men tions connecting an y pair of users. W e emphasise that the recipro cal men tions as undirected edges were only used for choosing the final no de set; the seven one-da y snapshots that formed the ev olving netw ork we studied did include all the mentions b etw een the chosen users, ev en unrecripro cated ones. C ABM global parameters and rules Here we describe in more detail the global parameters of our agen t-based mo del, and the rules go verning the agen ts’ b eha viour. The six global parameters are as follows: • Num b er of iterations (discrete time steps) p er day . • Mean n umber of messages p er burst ( Me anBurstSize ). When an agent in the mo del decides to send something to another agent, it will issue a burst of one or more messages together. This reflects the fact that tw eets are limited in length, so sometimes a quic k succession of t weets is needed to con vey a though t. This parameter sets the mean n umber of messages in these bursts. • Con tagion of sentimen t factor ( ContagionF actor ). There is evidence of con tagion of emotion through so cial netw orks (see e.g. [12]). This means that users’ mo o ds are raised when they receiv e p ositiv e messages and lo wered when they receiv e negative messages. This parameter con trols the extent to which an agent’s sen timen t is affected by the sentimen t of the messages it receiv es. 33 Figure 23: In-degree to out-degree ratio. The first t wo bars ha ve b een truncated to zoom in on v alues greater than 10. The bin-range starts from the v alue of the previous bin (exclusive) up to the v alue under the bin (inclusive). The increase in the bin heigh t of the last tw o bins is due to the increased range of the bin which includes all users with ratio from 200 to 250 and greater than 250 resp ectiv ely . • Sen timent reset probability ( P ( r eset ) ). W e observ ed that users’ sen timents tend to fluctuate around a (user-sp ecific) baseline level, and that showing sen timent higher or low er than this baseline level do es not “carry ov er” to the next da y . T o make sure that the sen timen ts of our agen ts do not carry ov er either, there is a c hance in each iteration that the agen t’s sen timent will randomly reset to that agent’s baseline sentimen t level. This parameter controls the probabilit y of such a reset. • Sen timent noise level ( SentimentNoiseL evel ). Although they hav e a baseline sen timent, users do not post ev ery tw eet with exactly the same sentimen t; there is some v ariation or noise around the baseline. This parameter con trols the amount of that noise or v ariation. • Neigh b our frequency threshold. This con trols which agen ts will be set up as neigh b ours in the mo del. If the neighbour threshold is 10, for example, then only users who ha ve exchanged at least 10 messages (in either direction) will b e connected in the mo del’s graph. The threshold is included so that, if desired, w e can make sure that only regular corresp onden ts will b e made neighbours in the model. Note that this parameter does not affect the op eration of the mo del, but only the creation of the mo del from the historical data. Let us now explain in detail ho w agents decide when to send messages, and how the sen timent of eac h agent ev olv es ov er time. The rules go verning the sending of messages are as follo ws. • If the agent A has receiv ed messages from an y other agen ts in the last time step, A will decide whether or not to reply to these agen ts, and whether or not to propagate to its other neigh b ours. F or each agen t B who sent A a message, A will reply with probability P ( r eply , A ). F or eac h neighbouring agent C who did not sent A a message, A will propagate a message with probabilit y P ( pr op, A ). 34 • If agent A received no messages in the previous time step, A will decide whether or not to initiate a con versation with its neighbours. F or each neigh b ouring agen t B , A will initiate a con versation with B with probability P ( init, A ). • When an agen t A c ho oses to initiate, reply or propagate to another agen t, it sends a burst of n + 1 messages with n dra wn from a Poisson distribution with mean Me anBurstSize − 1 (this ensures a minim um burst size of 1). • When an agent A c ho oses to initiate, reply or propagate to another agent, the sentimen t of the messages is generated b y taking the agen t’s curren t sentimen t lev el and adding Gaussian noise with standard deviation SentimentNoiseL evel . The resulting v alues are capp ed to the appropriate range: − 25 to +25 for (MC), − 4 to 4 for (SS) and − 100 to 100 for (L). When w orking with the (MC) and (SS) sentimen t measures, which are in teger-v alued, the v alues are also rounded to the nearest integer. The rules that go vern how each agent’s sen timent ev olves from one time step to the next are as follo ws. • With probabilit y P ( r eset ) the agent’s sen timen t level is reset to the agen t’s baseline level S ( basel ine, A ). • Otherwise, the agen t’s current sen timent lev el has a comp onent added to it representing the influence of each message receiv ed in the last time step. The comp onen t for a message receiv ed with sen timent S is ( S − S ( neutr al, A )) × ContagionF actor . D P arameter space for sim ulation runs Num b er of iterations p er da y . In theory this parameter could b e set to an y in teger v alue. Ho wev er, increasing this parameter also increases the execution time of sim ulations, whic h enforces a limit in practice. By starting from 24 iterations p er day and successively doubling, w e arriv ed at a limit of 1,536 iterations p er da y (that is, 24 × 2 6 ). V alues ab o v e this required to o m uc h pro cessing time to b e practical. Mean n umber of messages p er burst . This parameter has a lo w er b ound of 1. W e examined in the real data the num b ers of times eac h user A sent m ultiple messages to another user B within a p erio d of t seconds, for v arious v alues of t . W e decided to test v alues in the range from 1 . 1 to 2 . 8. Neigh b our threshold . W e tested v alues from 1 to 60. Setting the threshold to 60 makes the graph v ery sparse, yielding only 77 edges among the 28 users. Con tagion of sen timent factor . A v alue of 1 for this parameter w ould mean that when a user receiv es a message, the sentimen t of that one message is appro ximately just as imp ortan t to the user’s future sentimen t as the user’s en tire history to date. Thus the v alue 1 seems implausibly high. W e tested v alues from the lo wer bound of 0 up to 0.5. Sen timen t reset probabilit y . This parameter naturally ranges from 0 to 1, but we tested only v alues from 0 to 0.5 for the following reason. V alues greater than 0.5 cause the sen timent to 35 b e reset on the ma jorit y of iterations, whic h means that users’ sentimen t levels nev er mo ve far from their baseline levels. But this situation is already co vered b y the case when the con tagion of sentimen t factor is zero. Sen timen t noise level . The standard deviation of the (MC) sen timent scores of messages sent within the studied comm unit y 17 w as 1.57, so w e knew that v alues of the sentimen t noise lev el parameter muc h larger than this would not p erform well. Th us for (MC) we tested v alues from the low er b ound of 0 up to 2.5. By similar reasoning, we selected the range from 0 to 1.8 for (SS) and from 0 to 13 for (L). 36
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment